LoRA微調:加入參數式微調
凍結原始網絡參數,對Attention層中QKV等添加旁支,包含兩個低維度的矩陣A和矩陣B,微調過程中僅更新A、B 矩陣
效果:訓練參數被大幅降低,資源消耗較低。
對attention的參數加入如下圖所示,使用兩個A,B矩陣來擬合原始QKV矩陣,其中A,B矩陣中的兩個參數r,lora_alpha為重要參數,一般情況下,lora_alpha為r的兩倍以上。
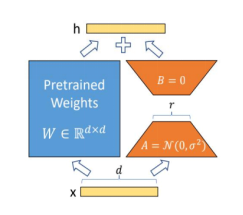
Mindspore中的實現代碼如下圖所示:
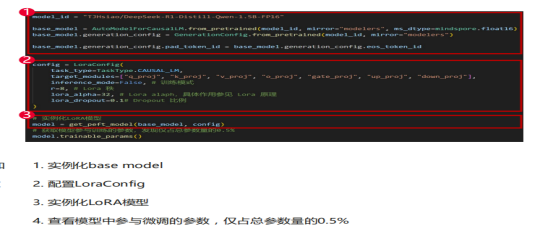

整體流程代碼部分:
數據導入和載入分詞模型及配置:
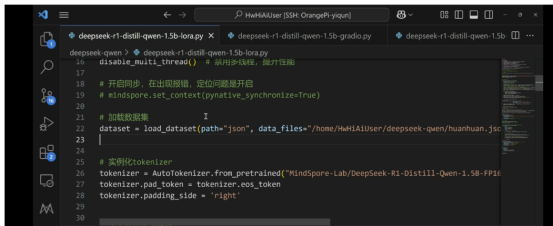 \
\
數據樣式:
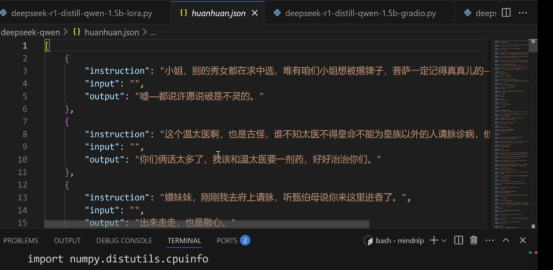
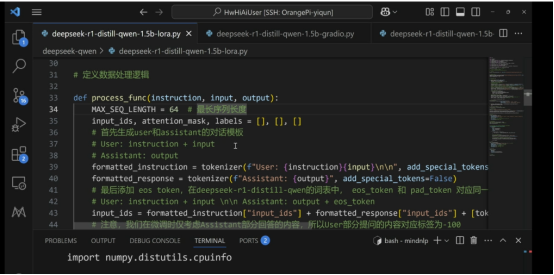
數據處理邏輯部分:
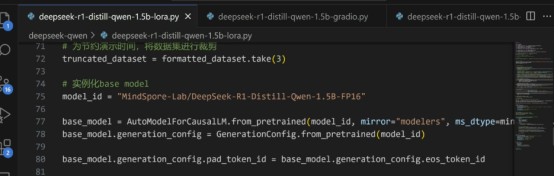
訓練模型參數及配置載入:
訓練參數及配置:

香橙派板子上運行模型優化策略:
香橙派AIpro的host側和device側共享,所以在host側的內存占用(如python的多進程,模型加載等)也會影響到顯存。
優化策略:
1. 在加載模型時,直接加載fp16的權重,而非加載fp32權重再轉成fp16。
2.如何限制拉起的python進程數,從而控制額外的內存占用,減少對顯存的影響
3.在開啟新的終端時,手動限制進程最大內存占用,開了swap然后再限制內存就可以空出來給NPU用。
學習心得:
- 了解lora模型訓練基礎原理
- 對mindspore上進行模型微調的代碼進行分析和確認,方便后續代碼的升級和維護
- 對香橙派板子上進行微調的具體流程,包含數據預處理、模型參數及配置加載、訓練參數和保存等。
- 對香橙派板子上運行的模型優化策略有一定了解,例如權重加載、限制進程數、限制內存等。



![[論文閱讀] 人工智能 + 軟件工程 | NoCode-bench:評估LLM無代碼功能添加能力的新基準](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | NoCode-bench:評估LLM無代碼功能添加能力的新基準)















