project4目錄
- Task1
- Task2
- Reconstruct
- SeqScan
- Task3
- Insert
- Commit
- TxnMgrDbg
- GenerateNewUndoLog And GenerateUpdateUndoLog
- Update And Delete
- 垃圾回收
- Task4
- Index Insert
- 并發控制
- Index Scan
- Delete、Update并發控制
- 主鍵更新
- Bonus 1
- Bonus 2
- 處理寫傾斜
感謝CMU的教授們給我們分享了如此精彩的一門課程, 希望您能尊重教授們和TAs的勞動成果!
本篇文章記錄本人對實驗中各個板塊的理解以及踩坑, 如果您發現我過多的涉及到了實驗的內容, 有違學術誠信, 請告訴我!
正文
project4整體實現了一個OCC版本的MVCC, 即樂觀版本的多版本并發控制為事務提供支持。
- Task1要求實現時間戳和水印;
- Task2要求元組重構方法和撤銷日志收集方法, 以及重構project3中實現的SeqScan執行器。
- Task3要求實現MVCC執行器, 分成一個個小任務就是:重構insert、delete、Update執行器, 實現Commit提交操作, Undolog生成和更新函數、 垃圾回收機制。
- Task4引入主鍵, 并實現主鍵更新和插入
- Bonus1為abort事務回滾, Bonus2為Serializable Verification序列化驗證。
Task1
首先要看一下讀取時間戳到底怎么工作。 對于事務來說, 事務有一個事務id, 一個讀取時間戳, 一個提交時間戳。 事務被創建時, 會被事務管理器分配一個遞增的事務id,用來唯一標記事務, 這個事務管理器就是DBMS里面管理所有事物的對象。 事務啟動時, 也會被分配一個讀取時間戳,這個讀取時間戳是整個全局中, 上一個事務的提交時間戳。 而提交時間戳, 同樣是由事務管理器分配, 并且每次事務提交都會遞增, 保證全局唯一。

如上圖, 每一次有事務提交, 那么last_commits_ts_就會加一, 同時一個事務啟動, next_txn_id也會加一。 然后讀取時間戳就可以在啟動的時候直接賦值last_commit_ts即可。
Task1中需要理解的是watermark水位線。水位線用來判斷DBMS中有哪些數據版本不再被所有活躍事務需要。其中current_reads里面包括了當前活躍事務中,讀取時間戳與讀取時間戳個數的對應關系。如果獲取水位線, 那么就返回current_reads中的最小值, 如果current_reads中沒有數據, 直接返回。
我需要做的就是, 在Commit函數中, 提交時間戳加一,并將事務的提交時間戳設置為該時間戳。然后更新水位線中的commits設置為提交時間戳。最后要移除水位線中的該事務read_ds計數。在Begin函數中設置read_ds即可。
Task2
Task2的主要任務有兩個, 一個是元組重構方法Reconstruct、一個是重構順序掃描方法SeqScan。
Reconstruct
理解元組重構就要先理解undolog。undolog就是將元組改變前和改變后的“差異“保存下來, 比如當T1將A的四列元組改變了兩列, 則將:改變了哪些列、改變之前該列的值、該槽位的版本鏈、當前事務的事務ID保存為一個undolog(撤銷日志), 然后將這個撤銷日志保存到當前的事務里面, 并將該撤銷日志添加到對應槽位的版本鏈中。注意該版本連由當前DBMS的事務管理器維護。就是下圖中的version_map:
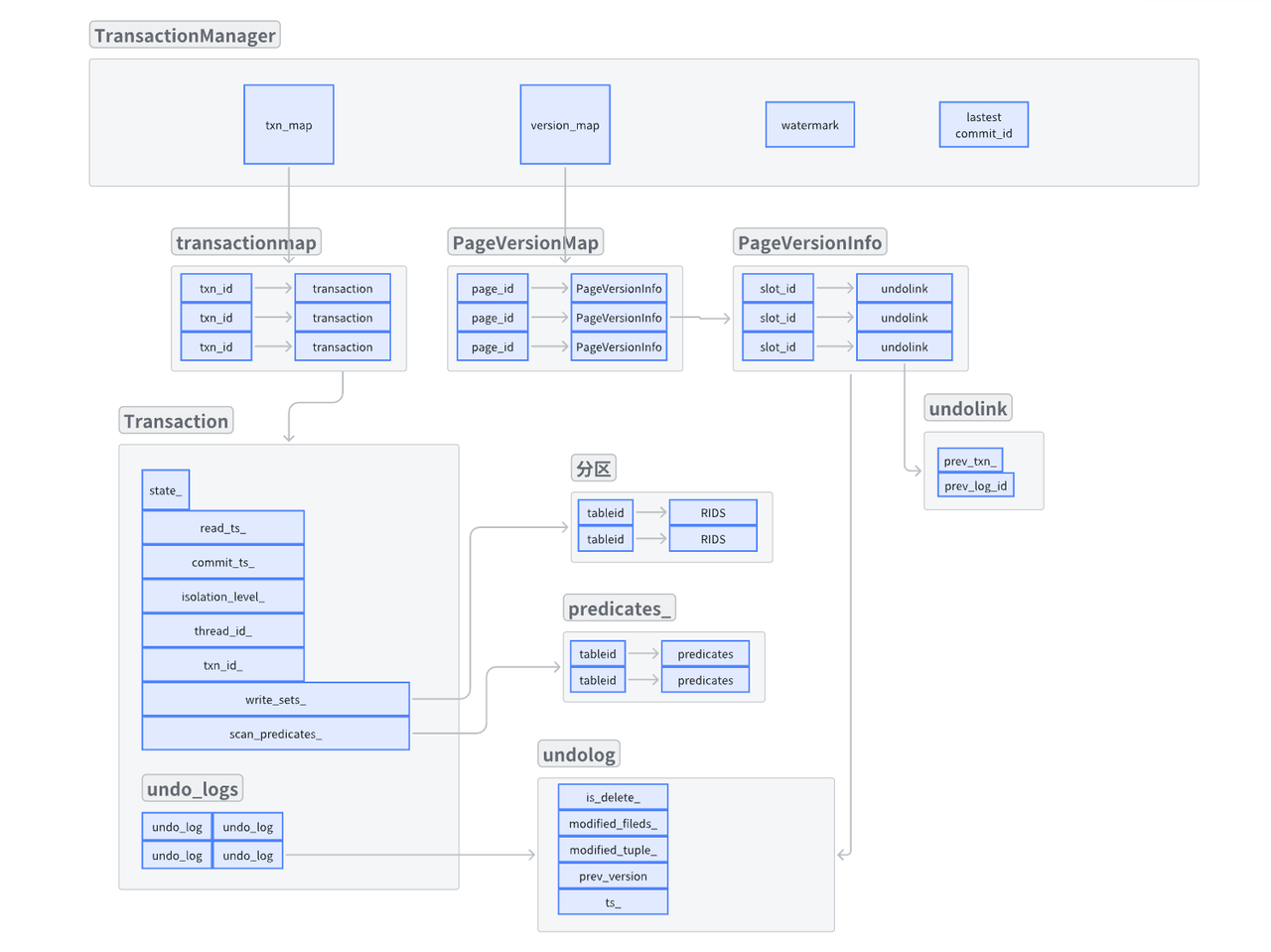
Reconstruct就是拿到一組撤銷日志(undolog), 根據undolog中的差異, 將basetuple恢復成舊元組并返回。
具體實現細節就是:
- 如果undolog的is_delete標記為true, 說明舊元組為空,那么就構建一個空tuple。
- 否則依次根據拿到undolog中的差異列的值, 和無差異列的值。 構建出一個舊元組。 最后遍歷整個”undo_logs", 直到遍歷完為止。
SeqScan
我認為SeqScan是所有的算子的基礎, 因為除了Insert, 其他的算子的最底層都是SeqScan或者IndexScan。 大部分算子都是從SeqScan拉取數據。 SeqScan中要處理:哪些元組看的見、哪些元組看不見。
因為我之前p3實現的是無MVCC的掃描, 掃描每一個槽位時, 該槽位是什么拿到什么就可以了, 如果為空, 則繼續遍歷下一個槽位即可。 但是對于MVCC控制的SeqScan, 同樣是遍歷每一個槽位, 但是每個槽位還要深入遍歷它的版本鏈, 即undolog鏈。
具體實現細節如下:
-
對于每一個槽位, 先看當前tuple能否看到
- 能看到并且不為空, 就返回; 能看到但是為空, 檢查下一個槽位。
-
如果看不到, 那么就檢查undolog。
-
一邊回溯版本鏈, 一遍收集undolog, 直到當前undolog能夠看到。
- 如果最舊的undolog也看不到, 那么就檢查下一個元組。
-
利用收集到的undolog構建舊元組, 返回即可。
這里要注意的是, 文檔中說解釋了CollectUndolog,并要求實現了。

所以我可以實現該函數,方便SeqScan的編寫。
實現流程就是
- 從DBMS的事務管理器中拿到整個該槽位的版本鏈。
- 遍歷整個版本鏈, 如果看不到, 則加入到“return_undologs(返回undolog數組)”中, 如果能看到,則返回該數組就可。
Task3
Task3要求實現MVCC版本的執行器, 前面實現的SeqScan也是MVCC版本的執行器的一部分, Task3中要求實現Insert、Update、Delete的MVCC版本執行器。 并且要實現一下垃圾回收機制以及提交。
Insert
Insert不需要構建undolog, 因為Insert只是在一個新的槽位插入新元組。 與p3不同的是, 要注意設置該槽位的時間戳為事務ID, 并且要把該槽位的修改記錄添加到事務中。
這里不需要注意并發, 因為InsertTuple是在一個新槽位插入數據。 并發沖突只存在一種情況: 多個事務同時向內部插入數據。而InsertTuple本身為原子的, 所以無需注意并發控制。
Commit
關于Commit, 要注意一點就是要先更新事務以及更新元組的提交實踐戳。 然后才能更新全局的提交時間戳以及watermark里面的最新提交時間戳commit_ts。 因為對于一個事務,如果先更新了全局提交時間戳, 那么此時另一個事務就會獲得這個全局提交時間戳作為read_ts。
另外,Commit一定是原子的, 并且更新元組的提交時間戳一定是原子的。當前一個事務修改了元組后,假如一共修改了幾個元組, 但是只更新了一個元組的提交時間戳。 那么另一個新事物, 就永遠不能讀取這些沒有更新提交時間戳的元組了。所以要么Commit完成, 要么沒有Commit, 不存在Commit一半的情況。
TxnMgrDbg
TxnMgrDbg就是回溯整個版本鏈, 對于版本連上的每一個版本, 都要打印出對應的元組。 一直到版本鏈結束。該函數為輔助調試函數,可以不實現, 但是建議實現, 方便調試。
GenerateNewUndoLog And GenerateUpdateUndoLog
GenerateNewUndoLog和GeenerateUpdateUndoLog用來當Update和delete對元組進行改變時, 保存舊元組與新元組的差異。 保存的方法就是創建undolog, 并將undolog連接到版本鏈中。
GenerateNewUndolog的參數為basetuple和targettuple, 根據兩者構建一個undolog。
GenerateUpdateUndoLog的參數為basetuple、targettuple、undolog。 需要先利用undolog和basetuple構建出舊元組, 然后根據舊元組和targettuple生成新undolog并返回。
具體實現細節如下:
-
GenerateNewUndoLog
- 如果basetuple為空, 那么創建一個undolog的is_delete為true, 并且modifys_filed為schema.columns.size()。 并且每個列對應的modify_value為空。鏈接版本鏈后返回即可。
- 如果targettuple為空, 那么創建undolog的is_delete為false, 并且modify_filed為schema.columns.size()。 并且每個對應的modify_value為basetuple對應列的值, 鏈接版本鏈后返回。
- 如果兩者都不為空, 則遍歷兩tuple的每一列,標記每一列是否有差異, 并將有差異的列的basetuple對應的列收集起來,構造undolog。
-
GenerateUpdateUndoLog
-
先構造舊元組。
-
然后調用重復一遍GenerateNewUndoLog的邏輯即可。
-
Update And Delete
update和delete在執行主邏輯之前, 我們要檢查一下 寫寫 沖突。

判斷條件就是當前要修改的元組的提交時間戳大于自己的讀取時間戳, 并且提交時間戳不為自己的事務ID。 那么就說明這個元組要么正在被其他事務修改, 要么已經被其他事務修改并且事務已經提交了。 發生了寫寫沖突。
- Delete: 當槽位處的提交時間戳為當前的事務ID, 那么更新undolog,直接更新槽位處的元組即可。如果槽位處的提交時間戳為某個已經提交的事務的提交時間戳, 那么就以target為nullptr, 原元組為basetuple構建undolog, 注意要添加寫集合與將undolog添加到當前事務中。最后更新當前槽位處元組。
- Update:當槽位處的提交時間戳為當前的事務ID, 那么更新undolog, 并且更新槽位處的元組即可。 如果槽位處的提交時間戳為某個已經提交的事務的提交時間戳, 那么以target為newtuple, 原元組為basetuple創建undolog, 并且更新undolog。然后更新當前槽位元組即可。
需要注意的是更新元組的函數中Check參數填成nullptr即可。 OCC的并發控制不需要加鎖, 只需要在需要并發控制時添加一個Check函數即可。
垃圾回收
對于垃圾回收就是回收某個不需要的事務。 如果該事務內部所有的undolog都不會被當前活躍事務看到, 那么該事務以及內部所有的undolog就可以被回收了。
實現策略為:
- 遍歷DBMS中所有的已經提交事務, 并將事務修改的table和rid保存下來。
- 遍歷所有table以及rid,拿到對應槽位的版本連上面的提交時間戳ts。 查看watermark, 如果存在watermark > ts, 則該時間戳對應的已提交事務不應被回收, 進行標記。
最后回收所有未被標記為不可回收的提交事務。
Task4
Task4引入主鍵, 并且引入并發控制。
Index Insert
如果存在主鍵,此時進行插入要考慮插入數據的主鍵列所對應的Value(以后叫作Key)是否已經存在索引中。 如果已經存在索引中, 則要拿到索引中Key指向的槽位,看看是否槽位處為delete, 如果為delete,則更新該槽位的數據和元數據即可。同時要注意并發控制。如果不為delete, 說明有數據, 那么就是 寫寫 沖突。
如果不在索引中, 則類似于無主鍵索引的插入。
并發控制
OCC的并發控制是在提交階段之前進行驗證,驗證是否與之前已經提交的事務有 寫寫沖突。這里要做的就是先拿到該槽位原本的元數據, 將這個元數據作為Check的固定參數。 Check函數就是檢查原本的元數據是否與新拿到的元數據是否相同。
Index Scan
Index Scan和SeqScan實現的邏輯相同, 對于每一個元組要檢查版本鏈。
- 如果版本可見并且不為delete, 則返回, 如果版本可見但是delete, 檢查下一個槽位。
- 如果版本不可見, 遍歷到版本鏈的下一個位置, 當版本連為末位, 則檢查下一個槽位。
Delete、Update并發控制
Task4中我需要重構Delete、Update, 將兩者設計為支持并發控制的版本。 我需要改動的地方很少, 只需要類似于Insert設計一個綁定了元組元數據的可調用對象作為Check即可。 并且Check內部邏輯為比較新的元數據是否與舊的元數據是否相同。
我這里理解的意思就是, 當前事務在修改該槽位的過程中, 如果其他事務已經對該槽位進行了修改, 即便沒有提交。此時就類似于當前事務正在修改一個已經被修改的元組,該元組不應該被當前事務可見, 相當于剛剛進入函數時寫寫沖突的判斷, 直接設置abort退出即可。
主鍵更新
主鍵更新分為三種情況, insert、delete、update。
- insert時如果新元組的索引列對應的Value不存在主鍵索引中,還需要將Value添加到索引中。 并指向新的RID。
- delete時對于主鍵列不進行刪除。
- update時, 如果主鍵更改, 那么要先將所有更改的元組刪除, 然后再將所有新元組添加。這里刪一個插入一個的話, 會導致新插入的元組與已經存在的元組索引列沖突, 出現邏輯錯誤。
Bonus 1
發生寫寫沖突后, 調用abort函數回滾。
遍歷該事務的寫集合, 拿到每個槽位。 拿到槽位對應的元組。 此時會有三種情況:
-
如果槽位沒有版本鏈, 說明該事務在該槽位進行了插入, 則將該位置設置為delete。
- 否則為delete或者update。 拿到undolog, 重構tuple并進行滾滾即可。 即利用tuple更新槽位即可。
Bonus 2
檢查每一個槽位, 以及槽位對應的版本鏈; 對于序列化來說, 要保證事務讀取元組的順序和事務按照啟動順序序列化執行結果相同。快照隔離的實現中已經處理 寫 - 寫沖突 。 所以要保證序列化, 就要處理 寫傾斜 。
所以要認識什么是寫傾斜, 下面是關于寫傾斜的理解, 對比 寫寫沖突 來理解:
-
寫 - 寫沖突 :事務T1正在修改表1中的第三行, 事務T2稍后啟動, 也想要修改表1中的第三行。 此時T1尚未提交, 或者已經提交但T1.commit_ts > T2.read_ts, T2直接abort。
-
寫傾斜 :寫寫沖突是針對同一行, 寫傾斜則是針對不同行。 假如一個表中有四行數據:
-
col1 | col2 | 1 | 0 || 1 | 0 | | 0 | 0 || 0 | 0 | - 現在T1想要將col1全部設置為0, T2想要將col!全部設置為1。 T1先執行 -> "update t1 set col1 = 0 where col1 != 0; 然后底層seq_scan執行器通過遍歷 + 過濾讀取到了第一二行元組。元組通過管道回傳給上層 update執行器。然后執行器更新了表中的第一二行。 然后T2執行 -> “update t1 set col1 = 1 where col1 != 1” , 由于T1未提交, 所以表中的一二行被鎖定,T2的seq_scan執行器只能讀取到第三四行元組并且交給update執行器, 然后update執行器更新三四行。 最后的表中的結果就如下:
-
col1 | col2 | 0 | 0 | uncommited -> modified by T1| 0 | 0 | uncommited -> modified by T1 | 1 | 0 | uncommited -> modified by T2| 1 | 0 | uncommited -> modified by T2 - 但是我們想要的是什么呢? 我們想要的是先執行T1, 然后T1把表中所有數據修改為0, 然后執行T2, T2把表中所有數據修改為1, 最后表中的數據應該全都為1:
-
col1 | col2 | 1 | 0 || 1 | 0 || 1 | 0 || 1 | 0 |
-
處理寫傾斜
了解了實現序列化要解決寫傾斜的問題。 然后下面具體談如何處理寫傾斜。
我們從上面的例子中就能看到, 其實寫傾斜發生的條件就是在T1的修改的元組里面, 有些元組其實滿足了T2的過濾條件, 但是由于uncommited, 所以無法被T2修改。 此時T1先執行,能夠正確修改, 但是T2因為uncommited不能正確修改, 有寫傾斜。 所以如何判斷寫傾斜? 就是判斷可能沖突的事務修改的元組里面, 如果有能夠被我們正在判斷的事務所成功過濾的, 但是又因為uncommited, 所以沒有讀取到的這些元組。 那么就是發生了寫傾斜。
我們處理的驗證邏輯就是, 在提交的時候判斷是否與序列化的結果一致。 因為如果沖突事務T2修改過某個元組, 并且這個元組符合檢查事務T1的過濾條件, 又uncommited無法被檢查事務T1讀取, 那么就不符合序列化。
- 所以在提交階段, 先拿到所有的沖突事務。即uncommit的事務。
- 判斷每一個沖突事務的修改過的元組(寫集合), 是否滿足檢查事務的過濾條件。
- 如果滿足, 說明發生寫傾斜,事務中止。 如果所有的元組都不滿足, 則說明沒有發生寫傾斜, 可以正常提交。




技術解析)

)

![[實戰] 用1 PPS 馴服本地恒溫晶振(OCXO/TCXO)](http://pic.xiahunao.cn/[實戰] 用1 PPS 馴服本地恒溫晶振(OCXO/TCXO))



)


)



