目錄
- 1.摘要
- 2.MapReduce-Modified Particle Swarm Optimization (MR-MPSO)
- 3.結果展示
- 4.參考文獻
- 5.算法輔導·應用定制·讀者交流

1.摘要
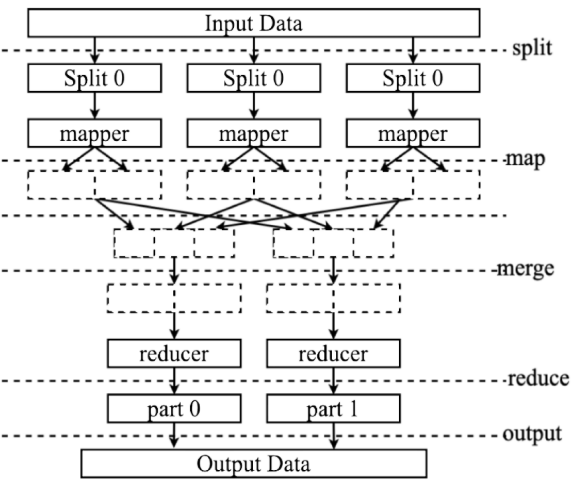
大數據的迅猛增長帶來了嚴峻的數據管理挑戰,尤其是在數據分布不均的龐大數據庫中。由于這種不匹配,傳統軟件系統的效率大打折扣,導致數據處理復雜且低效。為解決這一問題,本文提出了一種MapReduce-增強粒子群算法(MR-MPSO),MR-MPSO方法不僅有效提升了大規模數據集的管理能力,還解決了數據不平衡帶來的復雜性問題。MR框架用于處理大規模數據任務,MR-MPSO則優化map和reduce函數。
2.MapReduce-Modified Particle Swarm Optimization (MR-MPSO)
傳統基于MapReduce的優化方法在面對龐大數據處理任務時常常遇到挑戰,而PSO因其能夠在多個搜索區域之間有效導航,且在探索與開發之間取得平衡,成為一種流行選擇。結合MapReduce的可擴展性和靈活性,使其成為大數據應用的理想工具。然而,PSO在MapReduce框架中的應用面臨優化離散問題和資源分配時的困難。為此,本文提出了MR-MPSO,專為MapReduce大規模數據處理需求設計。
權重系數:
W(t)=WStart?(WStart??WEndMaxIterations)?tW(t)=W_{Start}-\left(\frac{W_{Start}--W_{End}}{\text{MaxIterations}}\right)*t W(t)=WStart??(MaxIterationsWStart???WEnd??)?t
學習率:
c1=c1,Start?tMaxIterations(c1,Start?c1,End)c_1=c_{1,Start}-\frac{t}{\text{MaxIterations}}(c_{1,Start}-c_{1,End}) c1?=c1,Start??MaxIterationst?(c1,Start??c1,End?)
c2=c2,Start?tMaxIterations(c2,Start?c2,End)c_2=c_{2,Start}-\frac{t}{\text{MaxIterations}}\left(c_{2,Start}-c_{2,End}\right) c2?=c2,Start??MaxIterationst?(c2,Start??c2,End?)
MR-MPSO算法主要目標是通過減少執行時間和提高吞吐量,同時保持I/O操作的一致性,從而提升MapReduce框架的性能,適應不同數據大小的需求。在傳統MR配置中參數設置經常導致低效,特別是對于具有不同數據量和I/O需求的應用程序。通過動態調整關鍵的MR參數,如減少器的數量和數據分區技術,所提出的方法克服了這些困難。優化問題定義如下:
- 目標:減少執行時間,增加I/O;
- 約束:避免數據丟失或溢出,MR設置必須在可接受的范圍內;
- 性能度量:吞吐量(MB/秒)、平均I/O速率、I/O速率標準差和總執行時間。
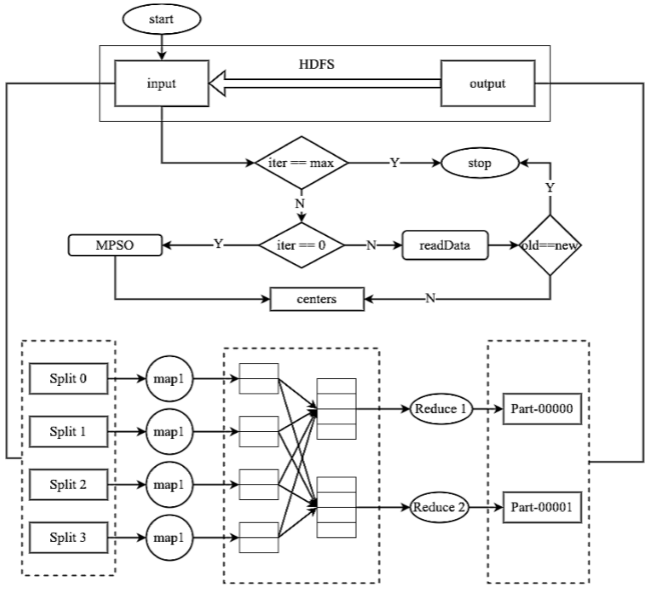
MR-MPSO算法通過進化迭代優化MapReduce的參數配置。每個粒子代表一個潛在的配置,初始時粒子隨機初始化,在預定義的參數范圍內搜索。每個粒子評估其位置的性能,并根據個體和全局最佳位置更新速度和位置。隨著迭代的進行,粒子不斷調整其位置,直到找到最優配置并完成MapReduce任務。

3.結果展示

4.參考文獻
[1] Diwaker C, Hasanpuri V, Gulzar Y, et al. Optimizing MapReduce efficiency and reducing complexity with enhanced particle Swarm Optimization (MR-MPSO)[J]. Swarm and Evolutionary Computation, 2025, 95: 101917.

)

![[C/C++安全編程]_[中級]_[如何避免出現野指針]](http://pic.xiahunao.cn/[C/C++安全編程]_[中級]_[如何避免出現野指針])


)
的聯系與區別(詳細版))

簡單工廠模式)
)




)



