
目錄
一、概述
1.1、軟件介紹
1.2、解決問題?
1.3、軟件特性?
1.4、使用用戶
1.5、產品對比
二、架構
2.1、運行流程
2.2、連接器?
2.3、引擎
2.3.1、設計理念
2.3.2、集群管理?
2.3.3、核心功能?
2.3.4、引擎對比
三、軟件部署
3.1、Docker部署
3.2、發布包部署
3.2.1、Apache SeaTunnel部署與使用?
3.2.1.1、軟件解壓
3.2.1.2、安裝插件
3.2.1.2.1 更換maven地址?
3.2.1.2.2 減少插件下載
3.2.1.3、測試
3.2.1.4、啟動服務
3.2.2、?SeaTunnel-Web部署與使用
1、下載解壓
2、配置環境變量?
3、 初始化數據庫腳本
4、修改?application.yml文件
5、配置引擎配置信息
6、配置版本號
7、下載依賴包?
8、拷貝依賴包?
9、啟動web服務
10、檢驗
11、瀏覽器驗證
一、概述
1.1、軟件介紹
SeaTunnel是一個非常易用、超高性能的分布式數據集成平臺,支持實時海量數據同步。 每天可穩定高效同步數百億數據,已被近百家企業應用于生產。
Apache SeaTunnel是中國開發者主導的項目,也是Apache基金會中第一個誕生自中國的數據集成平臺項目。
SeaTunnel原名Waterdrop,于2017年由樂視創建,并于同年在GitHub上開源
2021年10月改名為SeaTunnel
2021年12月9日SeaTunnel進入Apache孵化
2023年6月1日Apache SeaTunnel 畢業成為 Apache 頂級項目
Seatunnel的中文是"水滴",來自中國當代科幻小說作家劉慈欣的《三體》系列,它是三體人制造的宇宙探測器,會反射幾乎全部的電磁波,表面絕對光滑,溫度處于絕對零度,全部由被強互作用力緊密鎖死的質子與中子構成,無堅不摧。在末日之戰中,僅一個水滴就摧毀了人類太空武裝力量近2千艘戰艦
官網地址:
Apache SeaTunnel | Apache SeaTunnel
1.2、解決問題?
SeaTunnel專注于數據集成和數據同步,主要旨在解決數據集成領域的常見問題:
- 數據源多樣:常用數據源有數百種,版本不兼容。 隨著新技術的出現,更多的數據源不斷出現。 用戶很難找到一個能夠全面、快速支持這些數據源的工具。
- 同步場景復雜:數據同步需要支持離線全量同步、離線增量同步、CDC、實時同步、全庫同步等多種同步場景。
- 資源需求高:現有的數據集成和數據同步工具往往需要大量的計算資源或JDBC連接資源來完成海量小表的實時同步。 這增加了企業的負擔。
- 缺乏質量和監控:數據集成和同步過程經常會出現數據丟失或重復的情況。 同步過程缺乏監控,無法直觀了解任務過程中數據的真實情況。
- 技術棧復雜:企業使用的技術組件不同,用戶需要針對不同組件開發相應的同步程序來完成數據集成。
- 管理和維護困難:受限于底層技術組件(Flink/Spark)不同,離線同步和實時同步往往需要分開開發和管理,增加了管理和維護的難度。
1.3、軟件特性?
- 豐富且可擴展的Connector:SeaTunnel提供了不依賴于特定執行引擎的Connector API。 基于該API開發的Connector(Source、Transform、Sink)可以運行在很多不同的引擎上,例如目前支持的SeaTunnel引擎(Zeta)、Flink、Spark等。
- Connector插件:插件式設計讓用戶可以輕松開發自己的Connector并將其集成到SeaTunnel項目中。 目前,SeaTunnel 支持超過 100 個連接器,并且數量正在激增。
- 批流集成:基于SeaTunnel Connector API開發的Connector完美兼容離線同步、實時同步、全量同步、增量同步等場景。 它們大大降低了管理數據集成任務的難度。
- 支持分布式快照算法,保證數據一致性。
- 多引擎支持:SeaTunnel默認使用SeaTunnel引擎(Zeta)進行數據同步。 SeaTunnel還支持使用Flink或Spark作為Connector的執行引擎,以適應企業現有的技術組件。 SeaTunnel 支持 Spark 和 Flink 的多個版本。
- JDBC復用、數據庫日志多表解析:SeaTunnel支持多表或全庫同步,解決了過度JDBC連接的問題; 支持多表或全庫日志讀取解析,解決了CDC多表同步場景下需要處理日志重復讀取解析的問題。
- 高吞吐量、低延遲:SeaTunnel支持并行讀寫,提供穩定可靠、高吞吐量、低延遲的數據同步能力。
- 完善的實時監控:SeaTunnel支持數據同步過程中每一步的詳細監控信息,讓用戶輕松了解同步任務讀寫的數據數量、數據大小、QPS等信息。
- 支持兩種作業開發方法:編碼和畫布設計。 SeaTunnel Web 項目?GitHub - apache/seatunnel-web: SeaTunnel is a distributed, high-performance data integration platform for the synchronization and transformation of massive data (offline & real-time).?提供作業、調度、運行和監控功能的可視化管理。
1.4、使用用戶
SeaTunnel 擁有大量用戶

1.5、產品對比
| 對比項 | Apache SeaTunnel | DataX | Apache Sqoop | Apache Flume | Flink CDC |
| 部署難度 | 容易 | 容易 | 中等,依賴于 Hadoop 生態系統 | 容易 | 中等,依賴于 Hadoop 生態系統 |
| 運行模式 | 分布式,也支持單機 | 單機 | 本身不是分布式框架,依賴 Hadoop MR 實現分布式 | 分布式,也支持單機 | 分布式,也支持單機 |
| 健壯的容錯機制 | 無中心化的高可用架構設計,有完善的容錯機制 | 易受比如網絡閃斷、數據源不穩定等因素影響 | MR 模式重,出錯處理麻煩 | 有一定的容錯機制 | 主從模式的架構設計,容錯粒度比較粗,容易造成延時 |
| 支持的數據源豐富度 | 支持 MySQL、PostgreSQL、Oracle、SQLServer、Hive、S3、RedShift、HBase、Clickhouse等過 100 種數據源 | 支持 MySQL、ODPS、PostgreSQL、Oracle、Hive 等 20+ 種數據源 | 僅支持 MySQL、Oracle、DB2、Hive、HBase、S3 等幾種數據源 | 支持 Kafka、File、HTTP、Avro、HDFS、Hive、HBase等幾種數據源 | 支持 MySQL、PostgresSQL、MongoDB、SQLServer 等 10+ 種數據源 |
| 內存資源占用 | 少 | 多 | 多 | 中等 | 多 |
| 數據庫連接占用 | 少(可以共享 JDBC 連接) | 多 | 多 | 多 | 多(每個表需一個連接) |
| 自動建表 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 整庫同步 | 支持 | 不支持 | 不支持 | 不支持 | 不支持(每個表需配置一次) |
| 斷點續傳 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 多引擎支持 | 支持 SeaTunnel Zeta、Flink、Spark 3 個引擎選其一作為運行時 | 只能運行在 DataX 自己引擎上 | 自身無引擎,需運行在 Hadoop MR 上,任務啟動速度非常慢 | 支持 Flume 自身引擎 | 只能運行在 Flink 上 |
| 數據轉換算子(Transform) | 支持 Copy、Filter、Replace、Split、SQL 、自定義 UDF 等算子 | 支持補全,過濾等算子,可以 groovy 自定義算子 | 只有列映射、數據類型轉換和數據過濾基本算子 | 只支持 Interceptor 方式簡單轉換操作 | 支持 Filter、Null、SQL、自定義 UDF 等算子 |
| 單機性能 | 比 DataX 高 40%? - 80% | 較好 | 一般 | 一般 | 較好 |
| 離線同步 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 增量同步 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 實時同步 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| CDC同步 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 批流一體 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 精確一致性 | MySQL、Kafka、Hive、HDFS、File 等連接器支持 | 不支持 | 不支持 | 不支持精確,提供一定程度的一致性 | MySQL、PostgreSQL、Kakfa 等連接器支持 |
| 可擴展性 | 插件機制非常易擴展 | 易擴展 | 擴展性有限,Sqoop主要用于將數據在Apache Hadoop和關系型數據庫之間傳輸 | 易擴展 | 易擴展 |
| 統計信息 | 有 | 有 | 無 | 有 | 無 |
| Web UI | 正在實現中(拖拉拽即可完成) | 無 | 無 | 無 | 無 |
| 與調度系統集成度 | 已經與 DolphinScheduler 集成,后續也會支持其他調度系統 | 不支持 | 不支持 | 不支持 | 無 |
| 社區 | 非常活躍 | 非常不活躍 | 已經從 Apache 退役 | 非常不活躍 | 非常活躍 |
二、架構
2.1、運行流程
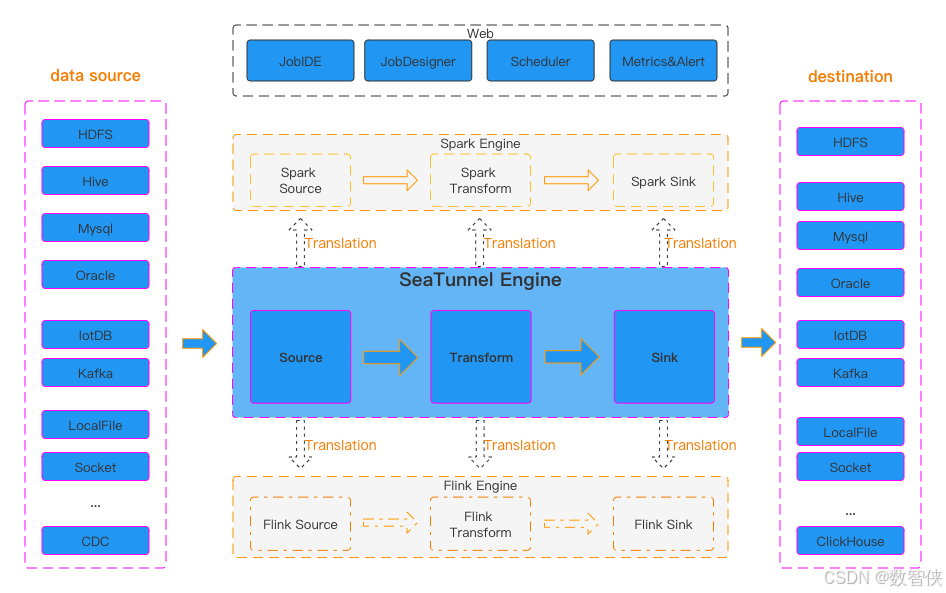
SeaTunnel的運行流程如上圖所示。
用戶配置作業信息并選擇提交作業的執行引擎。
Source Connector負責并行讀取數據并將數據發送到下游Transform或直接發送到Sink,Sink將數據寫入目的地。 值得注意的是,Source、Transform 和 Sink 可以很容易地自行開發和擴展。
SeaTunnel 是一個 EL(T) 數據集成平臺。 因此,在SeaTunnel中,Transform只能用于對數據進行一些簡單的轉換,例如將一列的數據轉換為大寫或小寫,更改列名,或者將一列拆分為多列。
SeaTunnel 使用的默認引擎是?SeaTunnel Engine。 如果您選擇使用Flink或Spark引擎,SeaTunnel會將Connector打包成Flink或Spark程序并提交給Flink或Spark運行。
2.2、連接器?
-
源連接器?SeaTunnel 支持從各種關系、圖形、NoSQL、文檔和內存數據庫讀取數據; 分布式文件系統,例如HDFS; 以及各種云存儲解決方案,例如S3和OSS。 我們還支持很多常見SaaS服務的數據讀取。 您可以在[此處]?訪問詳細列表。 如果您愿意,您可以開發自己的源連接器并將其輕松集成到 SeaTunnel 中。
-
轉換連接器?如果源和接收器之間的架構不同,您可以使用轉換連接器更改從源讀取的架構,使其與接收器架構相同。
-
Sink Connector?SeaTunnel 支持將數據寫入各種關系型、圖形、NoSQL、文檔和內存數據庫; 分布式文件系統,例如HDFS; 以及各種云存儲解決方案,例如S3和OSS。 我們還支持將數據寫入許多常見的 SaaS 服務。 您可以在[此處]訪問詳細列表。 如果您愿意,您可以開發自己的 Sink 連接器并輕松將其集成到 SeaTunnel 中。
2.3、引擎
2.3.1、設計理念
SeaTunnel Engine 是一個由社區開發的用于數據同步場景的引擎,作為 SeaTunnel 的默認引擎,它支持高吞吐量、低延遲和強一致性的數據同步作業操作,更快、更穩定、更節省資源且易于使用。
SeaTunnel Engine 的整體設計遵循以下路徑:
- 更快,SeaTunnel Engine 的執行計劃優化器旨在減少數據網絡傳輸,從而減少由于數據序列化和反序列化造成的整體同步性能損失,使用戶能夠更快地完成數據同步操作。同時,支持速度限制,以合理速度同步數據。
- 更穩定,SeaTunnel Engine 使用 Pipeline 作為數據同步任務的最小粒度的檢查點和容錯。任務的失敗只會影響其上游和下游任務,避免了任務失敗導致整個作業失敗或回滾的情況。同時,SeaTunnel Engine 還支持數據緩存,用于源數據有存儲時間限制的場景。當啟用緩存時,從源讀取的數據將自動緩存,然后由下游任務讀取并寫入目標。在這種情況下,即使由于目標失敗而無法寫入數據,也不會影響源的常規讀取,防止源數據過期被刪除。
- 節省空間,SeaTunnel Engine 內部使用動態線程共享技術。在實時同步場景中,對于每個表數據量很大但每個表數據量很小的表,SeaTunnel Engine 將在共享線程中運行這些同步任務,以減少不必要的線程創建并節省系統空間。在讀取和寫入數據方面,SeaTunnel Engine 的設計目標是最小化 JDBC 連接的數量;在 CDC 場景中,SeaTunnel Engine 將重用日志讀取和解析資源。
- 簡單易用,SeaTunnel Engine 減少了對第三方服務的依賴,并且可以獨立于如 Zookeeper 和 HDFS 等大數據組件實現集群管理、快照存儲和集群 HA 功能。這對于目前缺乏大數據平臺的用戶,或者不愿意依賴大數據平臺進行數據同步的用戶來說非常有用。
未來,SeaTunnel Engine 將進一步優化其功能,以支持離線批同步的全量同步和增量同步、實時同步和 CDC。
2.3.2、集群管理?
- 支持獨立運行;
- 支持集群運行;
- 支持自治集群(去中心化),使用戶無需為 SeaTunnel Engine 集群指定主節點,因為它可以在運行過程中自行選擇主節點,并且在主節點失敗時自動選擇新的主節點;
- 自治集群節點發現和具有相同 cluster_name 的節點將自動形成集群。
2.3.3、核心功能?
- 支持在本地模式下運行作業,作業完成后集群自動銷毀;
- 支持在集群模式下運行作業(單機或集群),通過 SeaTunnel 客戶端將作業提交給 SeaTunnel Engine 服務,作業完成后服務繼續運行并等待下一個作業提交;
- 支持離線批同步;
- 支持實時同步;
- 批流一體,所有 SeaTunnel V2 Connector 均可在 SeaTunnel Engine 中運行;
- 支持分布式快照算法,并支持與 SeaTunnel V2 Connector 的兩階段提交,確保數據只執行一次。
- 支持在 Pipeline 級別調用作業,以確保即使在資源有限的情況下也能啟動;
- 支持在 Pipeline 級別對作業進行容錯。任務失敗只影響其所在 Pipeline,只需要回滾 Pipeline 下的任務;
- 支持動態線程共享,以實時同步大量小數據集。
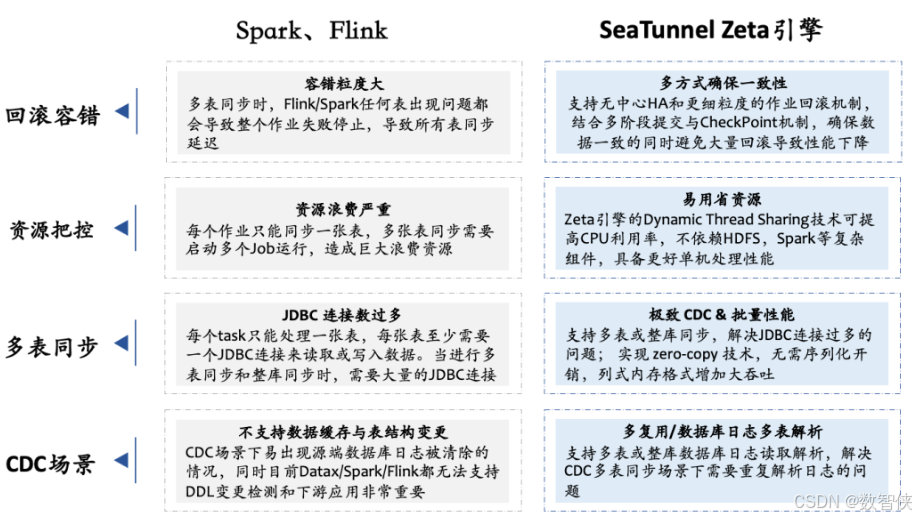
2.3.4、引擎對比
Apache SeaTunne默認使用的是自研的SeaTunne Zeta引擎,還支持Spark、Flink計算引擎
三、軟件部署
3.1、Docker部署
參考:使用Docker進行部署 | Apache SeaTunnel
3.2、發布包部署
下載地址:
Apache SeaTunnel
或:
apache-seatunnel-2.3.11安裝包下載_開源鏡像站-阿里云
3.2.1、Apache SeaTunnel部署與使用?
3.2.1.1、軟件解壓
cd usr/local/soft/
tar -zxvf apache-seatunnel-2.3.11-bin.tar.gz3.2.1.2、安裝插件
安裝插件前需要進行Maven鏡像地址更換與一些不用的插件不需要下載
cd /usr/local/soft/apache-seatunnel-2.3.11/
sh bin/install-plugin.sh3.2.1.2.1 更換maven地址?
整個過程非常慢…從國外maven中央倉庫下載東西,可以使用maven的阿里云鏡像
setting文件地址:/root/.m2/wrapper/dists/apache-maven-3.8.4-bin/52ccbt68d252mdldqsfsn03jlf/apache-maven-3.8.4/conf/
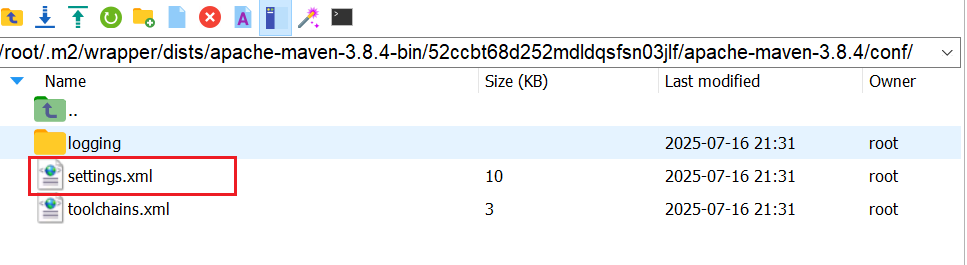
?換成阿里云鏡像
<mirror><id>alimaven</id><mirrorOf>central</mirrorOf><name>aliyun maven</name><url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror> <id>aliyun-maven</id><mirrorOf>*</mirrorOf> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>?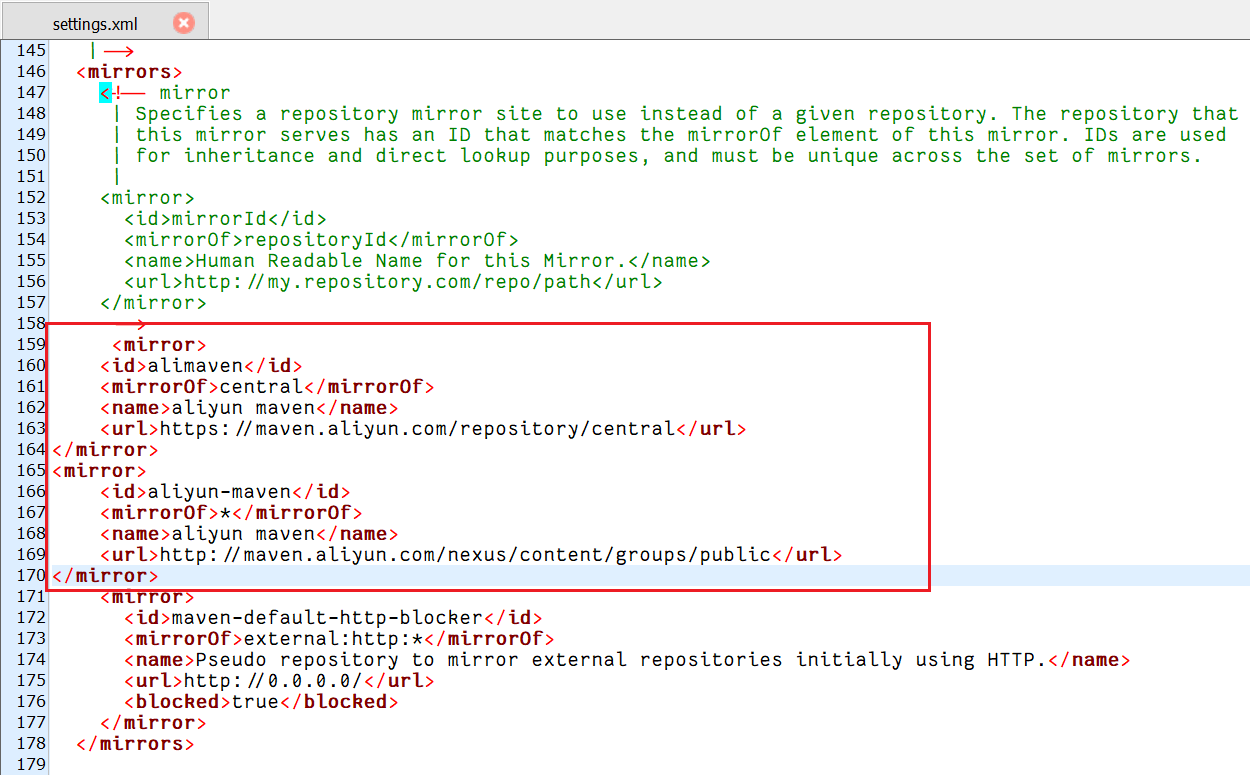
更換后再下載速度很快
3.2.1.2.2 減少插件下載
默認插件全部下載,如果自己用不到,可以注釋掉,因為即便下載了也不用,占用空間,如果下載有需要可以再下載,配置地址如下:/usr/local/soft/apache-seatunnel-2.3.11/config/plugin_config
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
#
# This mapping is used to resolve the Jar package name without version (or call artifactId)
#
# corresponding to the module in the user Config, helping SeaTunnel to load the correct Jar package.
# Don't modify the delimiter " -- ", just select the plugin you need
--connectors-v2--
#connector-amazondynamodb
connector-assert
#connector-cassandra
connector-cdc-mysql
connector-cdc-mongodb
#connector-cdc-sqlserver
connector-cdc-postgres
#connector-cdc-oracle
#connector-cdc-tidb
connector-clickhouse
connector-datahub
connector-dingtalk
#connector-doris
connector-elasticsearch
connector-email
connector-file-ftp
connector-file-hadoop
connector-file-local
connector-file-oss
connector-file-jindo-oss
#connector-file-s3
connector-file-sftp
connector-file-obs
#connector-google-sheets
#connector-google-firestore
connector-hive
connector-http-base
connector-http-feishu
connector-http-gitlab
connector-http-github
connector-http-jira
connector-http-klaviyo
connector-http-lemlist
connector-http-myhours
connector-http-notion
connector-http-onesignal
connector-http-wechat
connector-hudi
connector-iceberg
connector-influxdb
connector-iotdb
connector-jdbc
connector-kafka
connector-kudu
#connector-maxcompute
connector-mongodb
connector-neo4j
#connector-openmldb
#connector-pulsar
connector-rabbitmq
connector-redis
connector-druid
#connector-s3-redshift
#connector-sentry
#connector-slack
connector-socket
#connector-starrocks
#connector-tablestore
#connector-selectdb-cloud
connector-hbase
#connector-amazonsqs
#connector-easysearch
#connector-paimon
#connector-rocketmq
#connector-tdengine
connector-web3j
#connector-milvus
#connector-activemq
#connector-sls
#connector-qdrant
#connector-typesense
#connector-cdc-opengauss
連接器下載到/usr/local/soft/apache-seatunnel-2.3.11/connectors/,可以單獨保存,以后安裝就不用再下載
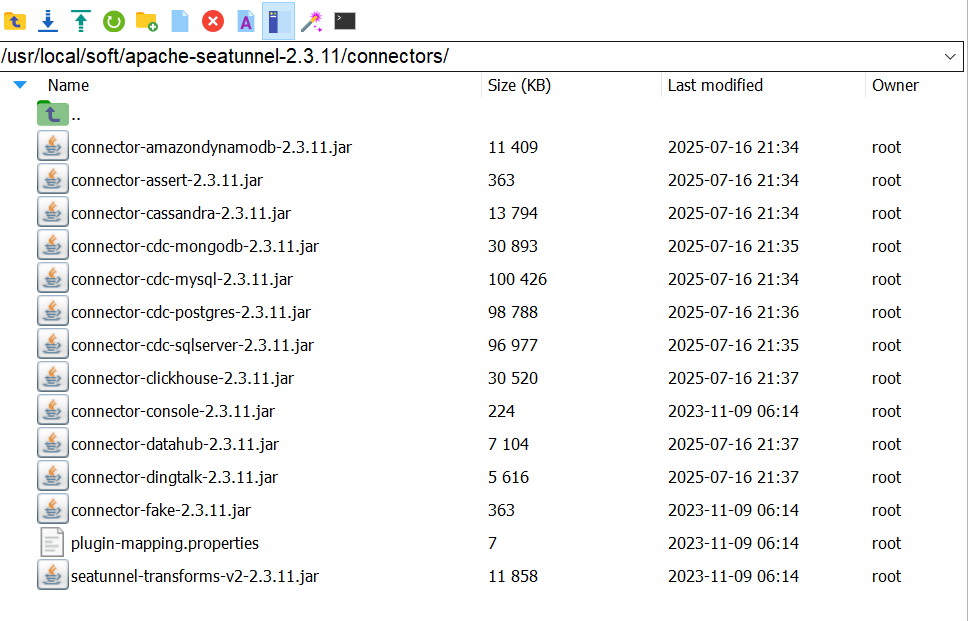
上述內容也可以直接上傳,地址如下
鏈接: https://pan.baidu.com/s/1Q4lTMtiBWlP5-3epmCC6jw?pwd=ejkx 提取碼: ejkx?
3.2.1.3、修改配置文件
vi /usr/local/soft/apache-seatunnel-2.3.11/config/seatunnel-env.sh修改路徑
# Home directory of spark distribution.
SPARK_HOME=${SPARK_HOME:-/usr/local/soft/spark-4.0.0-bin-hadoop3}
# Home directory of flink distribution.
FLINK_HOME=${FLINK_HOME:-/opt/flink}3.2.1.3、測試
cd /usr/local/soft/apache-seatunnel-2.3.11/
./bin/seatunnel.sh --config ./config/v2.batch.config.template -m local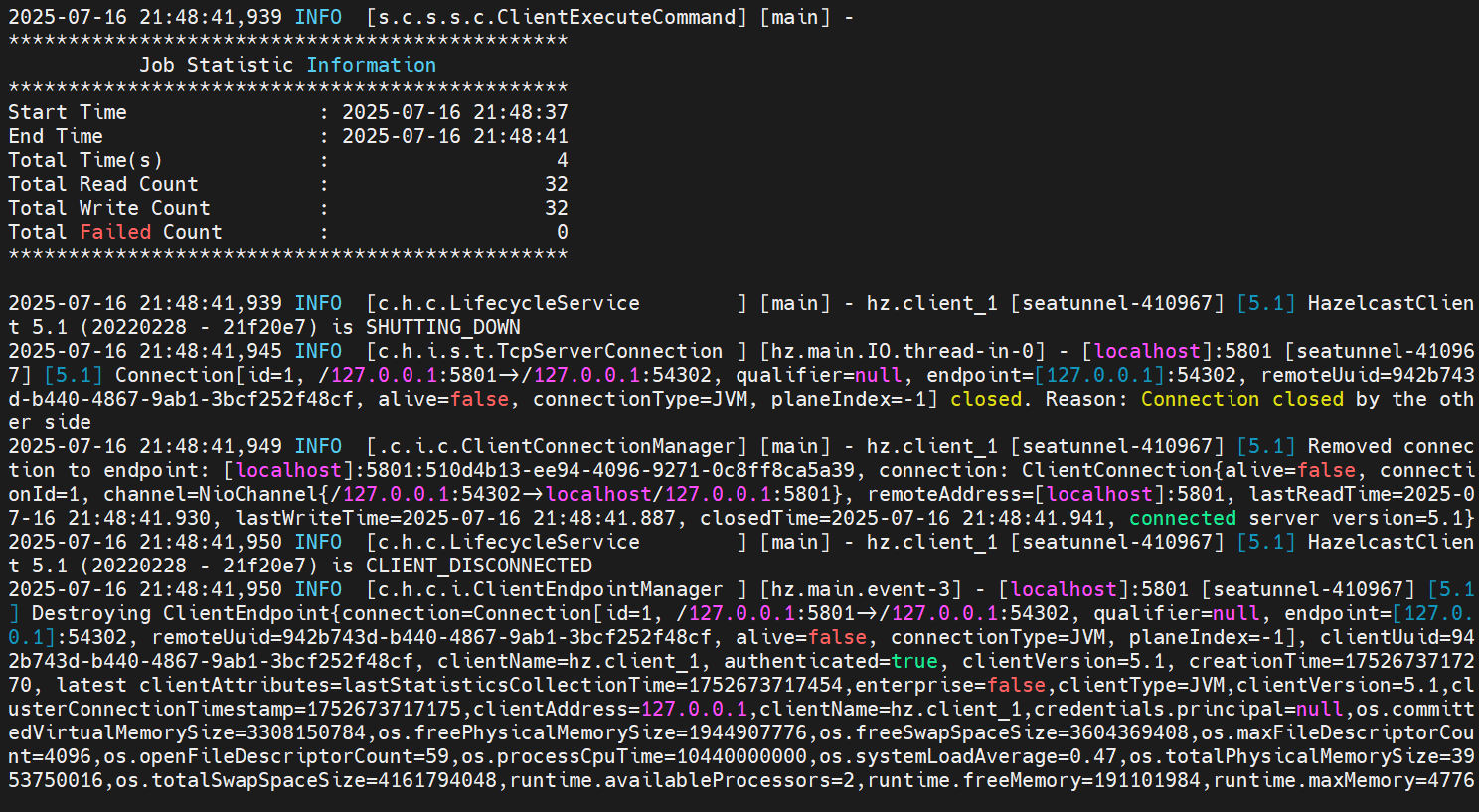
3.2.1.4、啟動服務
用于web端連接
seatunnel-cluster.sh或?
cd /usr/local/soft/apache-seatunnel-2.3.11/bin/
nohup sh seatunnel-cluster.sh 2>&1 &關閉
stop-seatunnel-cluster.sh3.2.2、?SeaTunnel-Web部署與使用
1、下載解壓
下載地址:Apache SeaTunnel
或:apache-seatunnel-seatunnel-web-1.0.2安裝包下載_開源鏡像站-阿里云
cd?/usr/local/soft/
tar -zxvf apache-seatunnel-web-1.0.2-bin.tar.gz
2、配置環境變量?
vim /etc/profile
添加
export SEATUNNEL_HOME=/usr/local/soft/apache-seatunnel-2.3.11
export SEATUNNEL_WEB_HOME=/usr/local/soft/apache-seatunnel-web-1.0.2-bin
export PATH=$PATH:$SEATUNNEL_HOME/bin:$SEATUNNEL_WEB_HOME/bin使環境變量生效
source /etc/profile
3、 初始化數據庫腳本
登錄數據庫
mysql -u root -p輸入密碼后執行腳本
source /usr/local/soft/apache-seatunnel-web-1.0.2-bin/script/seatunnel_server_mysql.sql?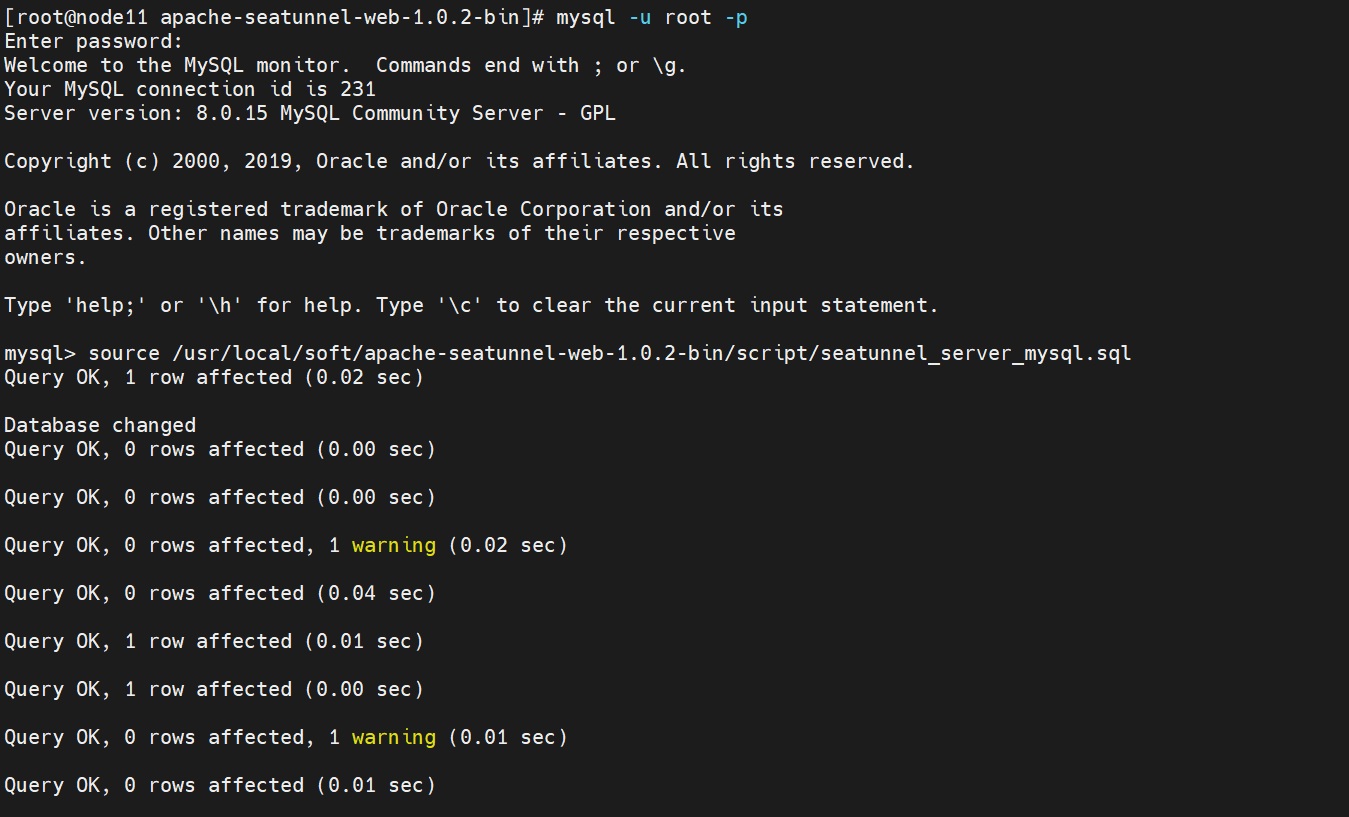
4、修改?application.yml文件
?vi /usr/local/soft/apache-seatunnel-web-1.0.2-bin/conf/application.yml修改數據庫相關參數?
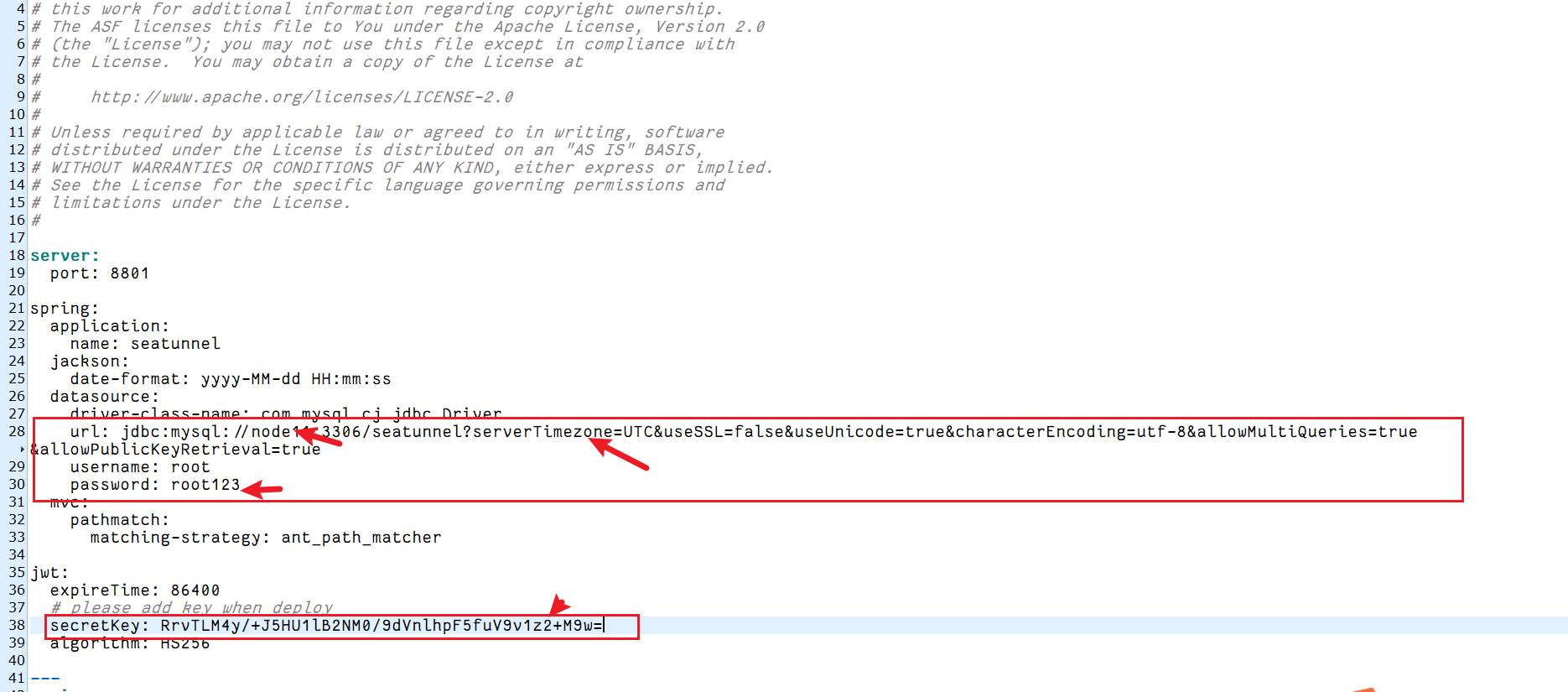 添加secretkey
添加secretkey
代碼生成:
<dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt-api</artifactId><version>0.11.2</version></dependency><dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt-impl</artifactId><version>0.11.2</version></dependency>import io.jsonwebtoken.SignatureAlgorithm;
import io.jsonwebtoken.security.Keys;import javax.crypto.SecretKey;
import java.util.Base64;public class App {public static void main(String[] args) {SecretKey secretKey = Keys.secretKeyFor(SignatureAlgorithm.HS256);String key = Base64.getEncoder().encodeToString(secretKey.getEncoded());System.out.println(key);}}
?運行結果

RrvTLM4y/+J5HU1lB2NM0/9dVnlhpF5fuV9v1z2+M9w=5、配置引擎配置信息
cp /usr/local/soft/apache-seatunnel-2.3.11/config/hazelcast-client.yaml /usr/local/soft/apache-seatunnel-web-1.0.2-bin/conf/
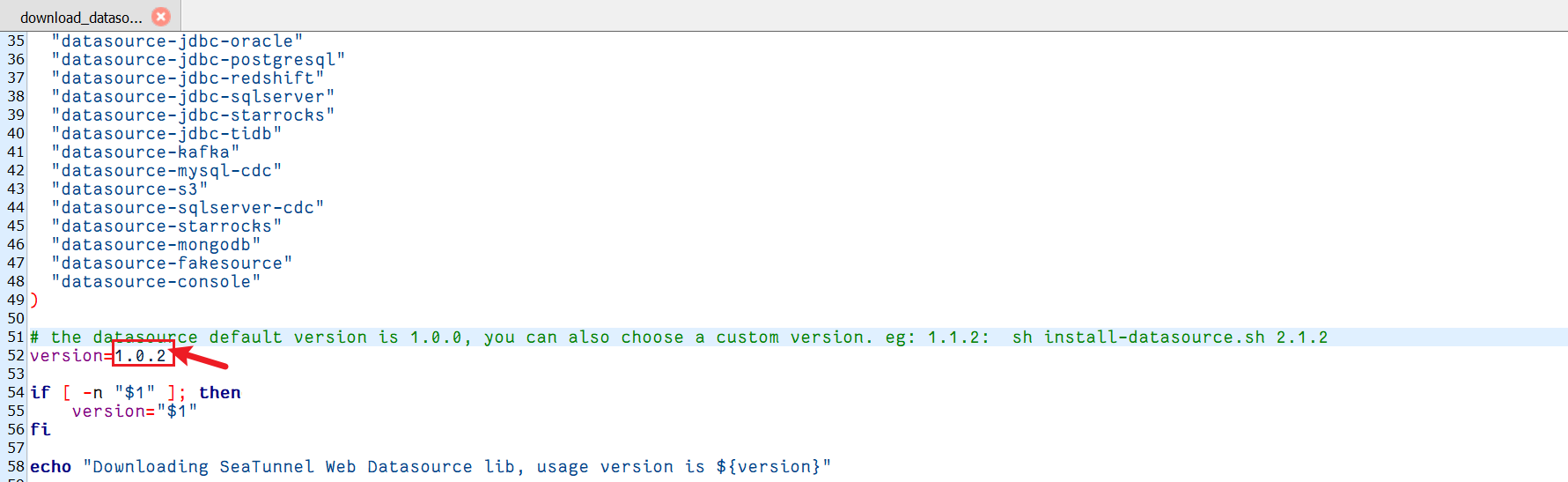
cp /usr/local/soft/apache-seatunnel-2.3.11/connectors/plugin-mapping.properties /usr/local/soft/apache-seatunnel-web-1.0.2-bin/conf/6、配置版本號
vi /usr/local/soft/apache-seatunnel-web-1.0.2-bin/bin/download_datasource.sh修改版本號為1.0.2?
7、下載依賴包?
cd /usr/local/soft/apache-seatunnel-web-1.0.2-bin/bin/
download_datasource.sh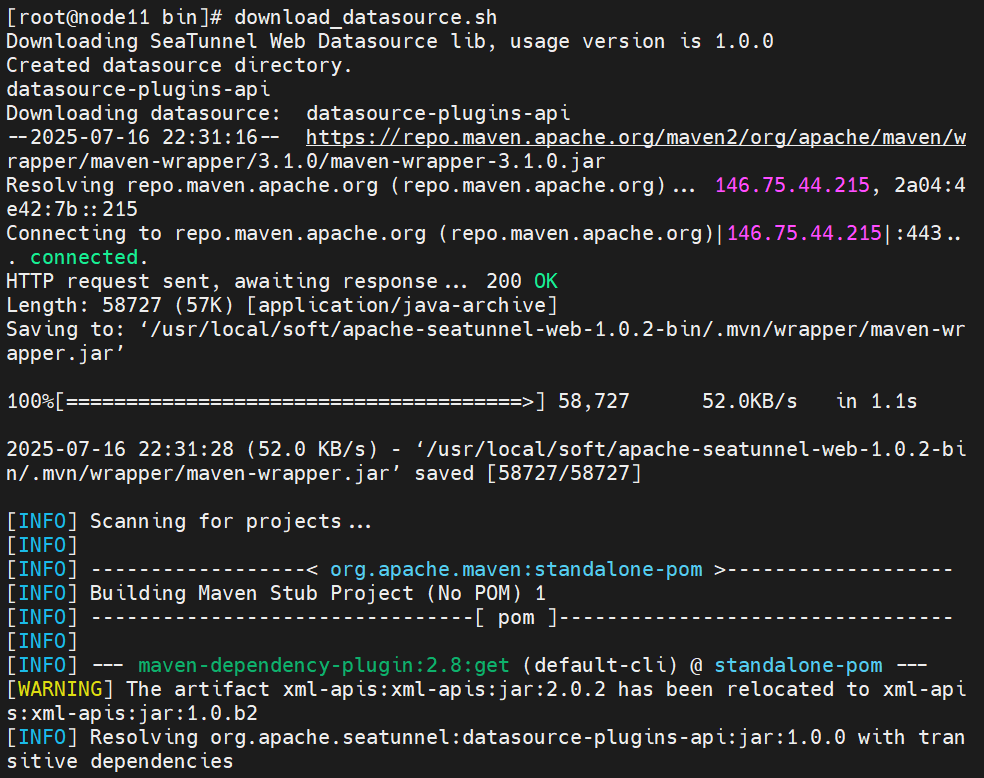 ?下載后的包在/usr/local/soft/apache-seatunnel-web-1.0.2-bin/datasource/文件夾中
?下載后的包在/usr/local/soft/apache-seatunnel-web-1.0.2-bin/datasource/文件夾中
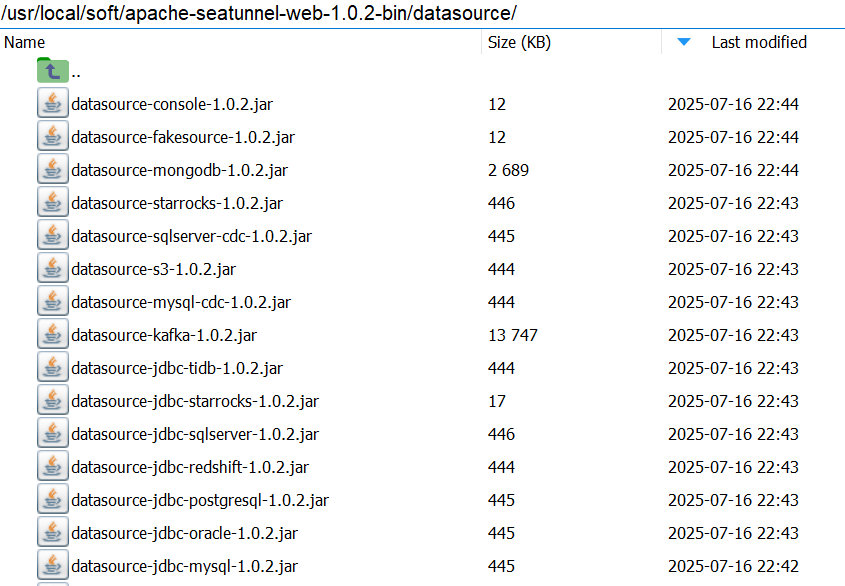
8、拷貝依賴包?
將/usr/local/soft/apache-seatunnel-web-1.0.2-bin/datasource/所有文件拷貝到/usr/local/soft/apache-seatunnel-web-1.0.2-bin/libs/文件夾下
cp /usr/local/soft/apache-seatunnel-web-1.0.2-bin/datasource/* /usr/local/soft/apache-seatunnel-web-1.0.2-bin/libs/
cp /usr/local/soft/apache-seatunnel-web-1.0.2-bin/datasource/* /usr/local/soft/apache-seatunnel-2.3.11/lib/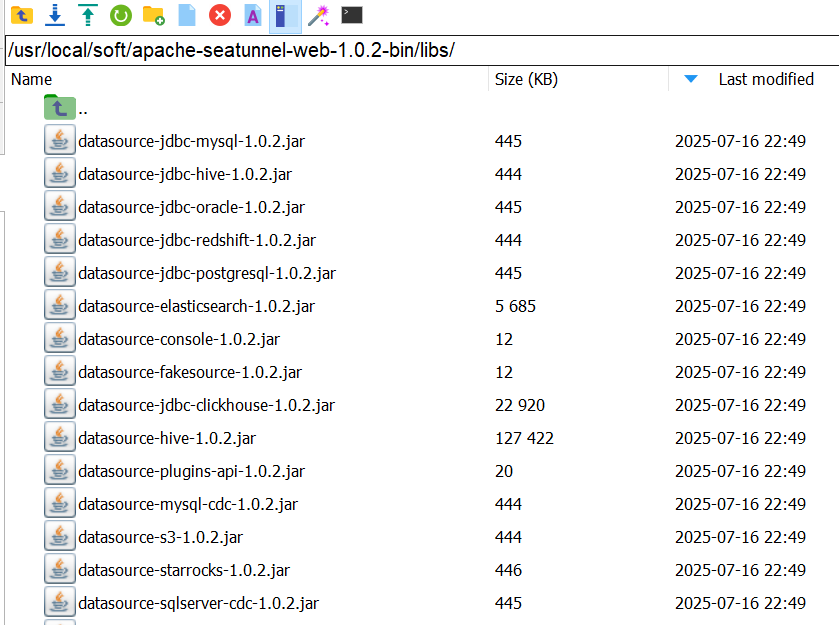
配置MySQL依賴包
同時將準備好的mysql-connector-java-8.0.15.jar添加到/usr/local/soft/apache-seatunnel-web-1.0.2-bin/libs/文件夾中
9、啟動web服務
seatunnel-backend-daemon.sh start?10、檢驗
jps
11、瀏覽器驗證
瀏覽器輸入:http://node11:8801/
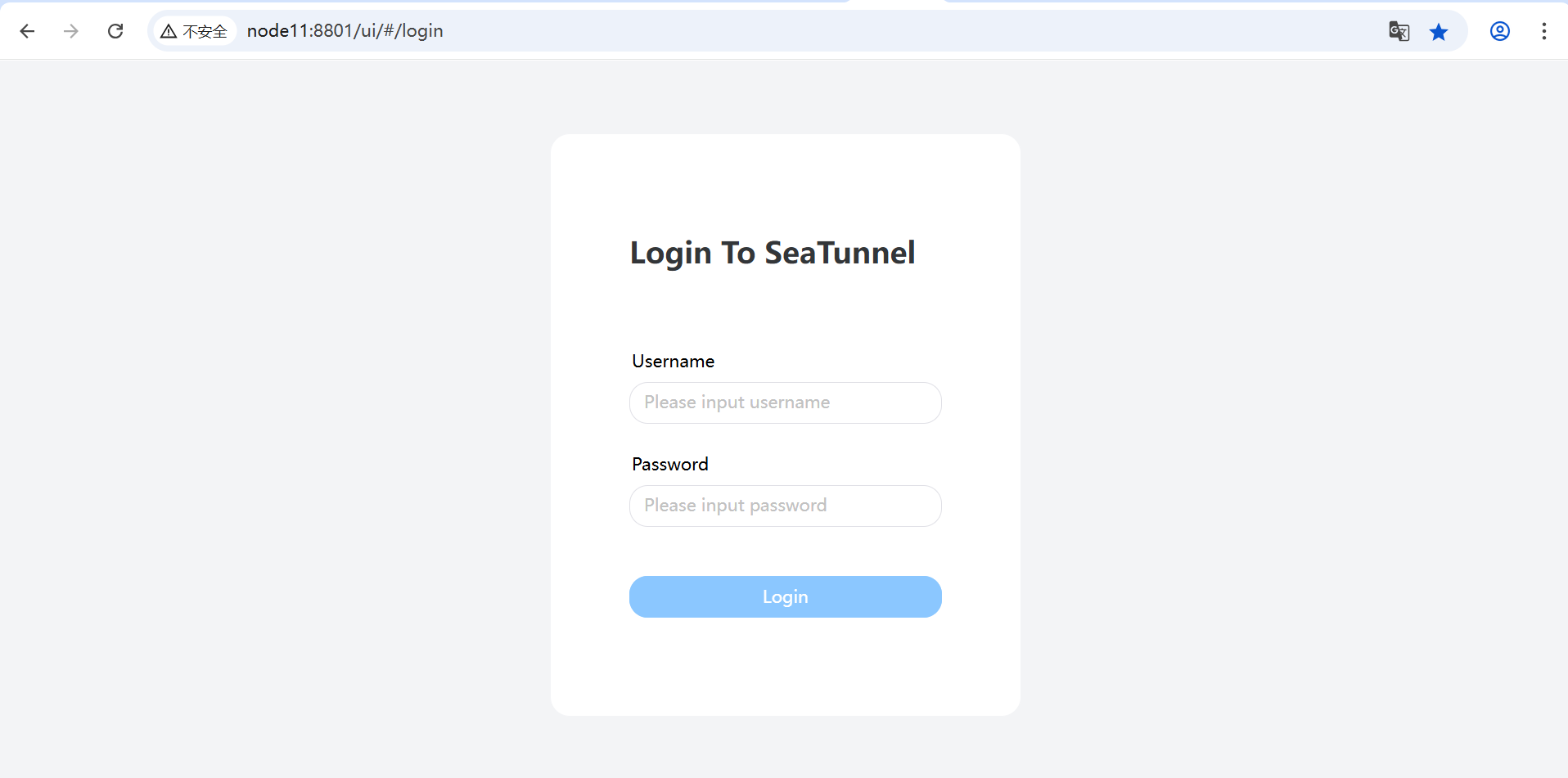
默認登錄的用戶名和密碼:admin
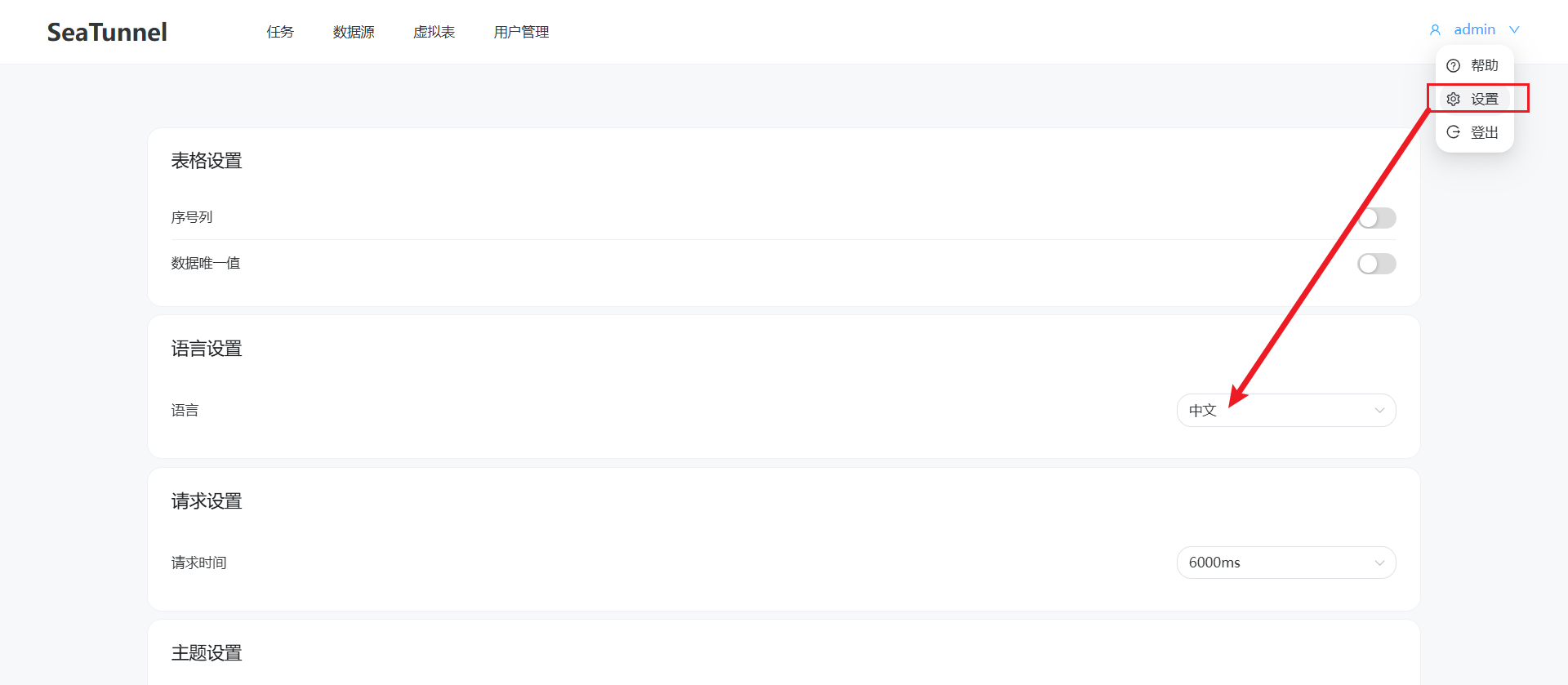
設置中文
FAQ:
1、

解決方案:
url: jdbc:mysql://node11:3306/seatunnel?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&allowPublicKeyRetrieval=true

![[C/C++安全編程]_[中級]_[如何避免出現野指針]](http://pic.xiahunao.cn/[C/C++安全編程]_[中級]_[如何避免出現野指針])


)
的聯系與區別(詳細版))

簡單工廠模式)
)




)





