一、神經網絡
神經網絡(Neural Network)是一種受生物神經系統(尤其是大腦神經元連接方式)啟發的機器學習模型,是深度學習的核心基礎。它通過模擬大量 “人工神經元” 的互聯結構,學習數據中的復雜模式和規律,從而實現分類、預測、生成等任務。
本項目采用的是全連接神經網絡(Fully Connected Network)
每一層的神經元與下一層所有神經元連接。
應用:簡單分類 / 回歸任務(如房價預測、鳶尾花分類)。
大概模型如下圖所示:
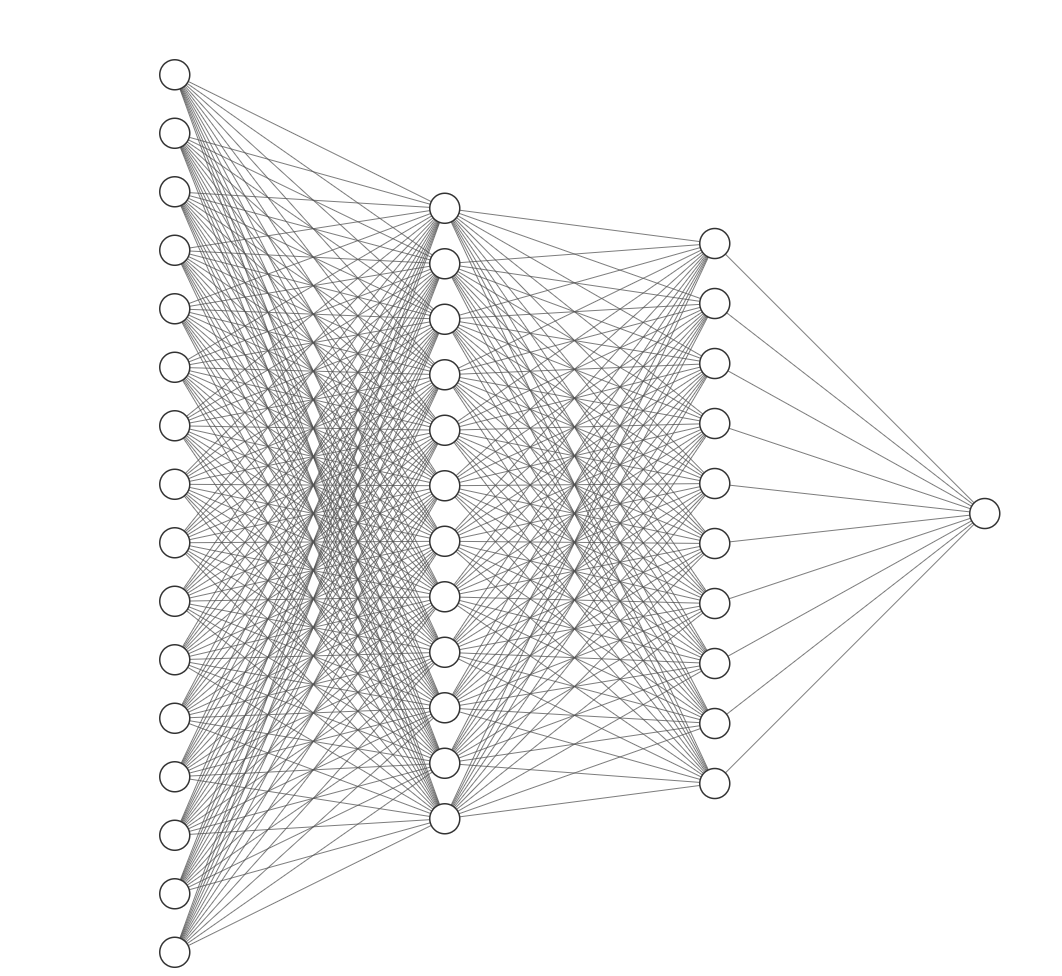
1.輸入層(Input Layer):?
接收原始數據(如圖像的像素值、文本的詞向量),不進行計算,僅傳遞數據。
神經元數量 = 輸入數據的維度(例如:28*28?的彩色圖像輸入層有 28*28=784個神經元)。
2.隱藏層(Hidden Layer):
- 位于輸入層和輸出層之間,負責提取數據的特征(如邊緣、紋理、語義等)。
- 共有2層,其中第一層設置了250個節點,第二層設置了200層。
3.輸出層(Output Layer):
- 輸出模型的最終結果(如分類任務的類別概率、回歸任務的預測值)。
- 神經元數量 = 任務目標的維度(10 類分類任務輸出層有 10 個神經元)。
4.激活函數
激活函數是神經網絡能擬合復雜模式的關鍵,其核心作用是引入非線性變換(否則多層網絡等價于單層線性模型)。本項目所使用的激活函數是relu函數:
5.計算損失(Loss Calculation)
- 用損失函數(Loss Function)衡量預測結果與真實標簽的差距(例如:分類任務用交叉熵損失,回歸任務用均方誤差)。
- 損失越小,模型預測越準。
在 PyTorch 中,CrossEntropyLoss是用于分類任務的常用損失函數,尤其適用于多類別分類(也可用于二分類)。它的設計非常靈活,內部集成了log_softmax和NLLLoss的功能,簡化了模型輸出與損失計算的流程。
CrossEntropyLoss?=?NLLLoss(log_softmax(logits), targets)
6.正則化
用于防止模型過擬合,提高泛化能力。
L2 正則化(Ridge Regression):傾向于減小參數值
- 參數平滑性:L2 正則化會使參數值變小,但不會完全為 0,從而使模型更加平滑。
- 幾何解釋:L2 的約束區域是一個圓形,與損失函數的等高線相交時,參數更可能落在非零的位置。
在損失函數中添加參數的平方和作為懲罰項:損失函數= 原始損失?+
7.優化器
Adam(Adaptive Moment Estimation)是深度學習中最流行的優化算法之一,結合了 Adagrad 和 RMSProp 的優點,能夠自適應地調整每個參數的學習率。它在實踐中表現出色,廣泛應用于各種神經網絡訓練任務。
二、代碼
網絡模型
單獨新建一個Python文件用于存儲網絡模型,其中定義了兩個隱藏層,都使用全連接神經網絡,第一個隱藏層有250個節點,第二隱藏層有200個節點,從最后一個隱藏層到輸出層同樣使用全連接神經網絡
self.fc1=nn.Linear(28*28,250)
self.fc2=nn.Linear(250,200)
self.fc3=nn.Linear(200,10)?前兩層(輸入層->第一個隱藏層->第二個隱藏層)都使用relu激活函數,第二個隱藏層到輸出層暫不使用激活函數,這樣做可以減少loss的計算誤差
x =F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)?完整代碼如下:
class network1(nn.Module):def __init__(self):super(network1, self).__init__()self.fc1=nn.Linear(28*28,250)self.fc2=nn.Linear(250,200)self.fc3=nn.Linear(200,10)def forward(self, x):x =F.relu(self.fc1(x))x=F.relu(self.fc2(x))x=self.fc3(x)return x訓練模型
工具模塊
import torchvisionfrom model import *
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader數據處理,將圖片數據轉換成tensor數據類型
trans=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])?導入數據,并獲取數據長度
train_dataset=torchvision.datasets.MNIST("./data",train=True,transform=trans,download=True)
test_dataset=torchvision.datasets.MNIST("./data",train=False,transform=trans,download=True)train_data_size=len(train_dataset)
test_data_size=len(test_dataset)加載數據,并設置批量大小為64,設置?打亂數據順序,因為數據集大小不能被64整除,設置丟棄多余數據
train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True,drop_last=True)
test_dataloader=DataLoader(test_dataset,batch_size=64,shuffle=True,drop_last=True)聲明網絡模型變量,設置損失函數,使用adam優化,設置l2正則
model=network1()loss_fn=nn.CrossEntropyLoss()learning_rate=1e-2
l2_lambda=1e-5
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate,weight_decay=l2_lambda)?設置訓練過程中可能用到的變量
total_train_step=0
total_test_step=0
epoch=50??創建SummaryWriter,指定日志保存目錄
writer=SummaryWriter("./mini_logs")?在迭代器中取出數據和標簽,將數據展成一維的,使其符合網絡模型的輸入,將其放入模型中
for data in train_dataloader:imgs,targets=dataimgs=torch.reshape(imgs,(64,-1))outputs=model(imgs)計算損失值
loss = loss_fn(outputs, targets)
total_train_loss+=loss?計算準確率
accuracy = ((outputs.argmax(1) == targets).sum())
total_train_accuracy += accuracy
total_train_step+=1更新梯度,進行參數優化
optimizer.zero_grad()
loss.backward()
optimizer.step()?輸出訓練數據,并將訓練誤差和準確率添加到tensorboard上
# 100輪輸出一次,防止數據太多 if total_train_step % 100 == 0:print('訓練次數:{},Loss:{}'.format(total_train_step, loss.item())) print("整體訓練集上的Loss為:{}".format(total_train_loss))print("整體訓練集上的正確率為:{}".format(total_train_accuracy / train_data_size))writer.add_scalar("Loss/train_loss", total_train_loss, total_test_step)#使用test_step是為了對齊測試誤差,下同writer.add_scalar("Ac/train_accuracy", total_train_accuracy / train_data_size, total_test_step)?在test數據集上測試參數效果,過程與訓練過程相似,需要注意的是,在測試過程中可以不計算梯度,加快計算效率
total_test_loss=0total_test_accuracy=0with torch.no_grad():for data in test_dataloader:imgs,targets=dataimgs = torch.reshape(imgs, (64, -1))outputs=model(imgs)loss=loss_fn(outputs,targets)total_test_loss+=lossaccuracy = ((outputs.argmax(1) == targets).sum())total_test_accuracy += accuracyprint("整體測試集上的Loss為:{}".format(total_test_loss))print("整體測試集上的正確率為:{}".format(total_test_accuracy / test_data_size))writer.add_scalar("Loss/test_loss", total_test_loss, total_test_step)writer.add_scalar("Ac/test_accuracy", total_test_accuracy / test_data_size, total_test_step)最后保存模型并關閉SummaryWriter
torch.save(model,"minst_weight/net_{}.pth".format(i))print("模型已保存")writer.close()?完整代碼如下:
import torchvisionfrom model import *
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoadertrans=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])train_dataset=torchvision.datasets.MNIST("./data",train=True,transform=trans,download=True)
test_dataset=torchvision.datasets.MNIST("./data",train=False,transform=trans,download=True)train_data_size=len(train_dataset)
test_data_size=len(test_dataset)train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True,drop_last=True)
test_dataloader=DataLoader(test_dataset,batch_size=64,shuffle=True,drop_last=True)model=network1()loss_fn=nn.CrossEntropyLoss()learning_rate=1e-2
l2_lambda=1e-5
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate,weight_decay=l2_lambda)total_train_step=0
total_test_step=0
epoch=50writer=SummaryWriter("./mini_logs")for i in range(epoch):print('--------第{}輪訓練開始--------'.format(i))total_train_loss = 0total_train_accuracy=0for data in train_dataloader:imgs,targets=dataimgs=torch.reshape(imgs,(64,-1))outputs=model(imgs)loss = loss_fn(outputs, targets)total_train_loss+=lossaccuracy = ((outputs.argmax(1) == targets).sum())total_train_accuracy += accuracytotal_train_step+=1optimizer.zero_grad()loss.backward()optimizer.step()if total_train_step % 100 == 0:print('訓練次數:{},Loss:{}'.format(total_train_step, loss.item())) # 100輪輸出一次,防止數據太多print("整體訓練集上的Loss為:{}".format(total_train_loss))print("整體訓練集上的正確率為:{}".format(total_train_accuracy / train_data_size))writer.add_scalar("Loss/train_loss", total_train_loss, total_test_step)#使用test_step是為了對齊測試誤差,下同writer.add_scalar("Ac/train_accuracy", total_train_accuracy / train_data_size, total_test_step)total_test_loss=0total_test_accuracy=0with torch.no_grad():for data in test_dataloader:imgs,targets=dataimgs = torch.reshape(imgs, (64, -1))outputs=model(imgs)loss=loss_fn(outputs,targets)total_test_loss+=lossaccuracy = ((outputs.argmax(1) == targets).sum())total_test_accuracy += accuracyprint("整體測試集上的Loss為:{}".format(total_test_loss))print("整體測試集上的正確率為:{}".format(total_test_accuracy / test_data_size))writer.add_scalar("Loss/test_loss", total_test_loss, total_test_step)writer.add_scalar("Ac/test_accuracy", total_test_accuracy / test_data_size, total_test_step)total_test_step += 1torch.save(model,"minst_weight/net_{}.pth".format(i))print("模型已保存")writer.close()訓練結果如下圖所示:
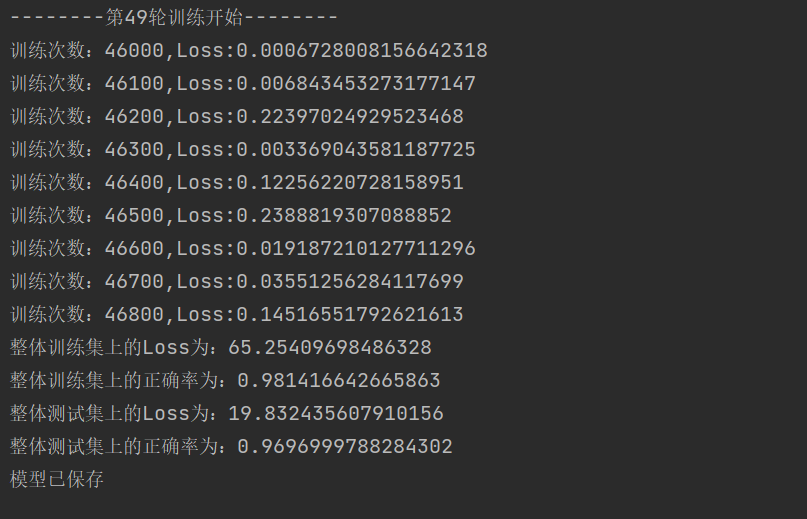
可以看到在test數據集上,該模型的準確率還是非常高的
模型測試
在網頁上隨便截取幾張手寫數字,測試一下其效果,效果可能與test數據集測試的效果相差較大,是因為網上的數據與訓練的數據相差太大,所以這個實驗可能并沒有什么參考價值,可以練練手
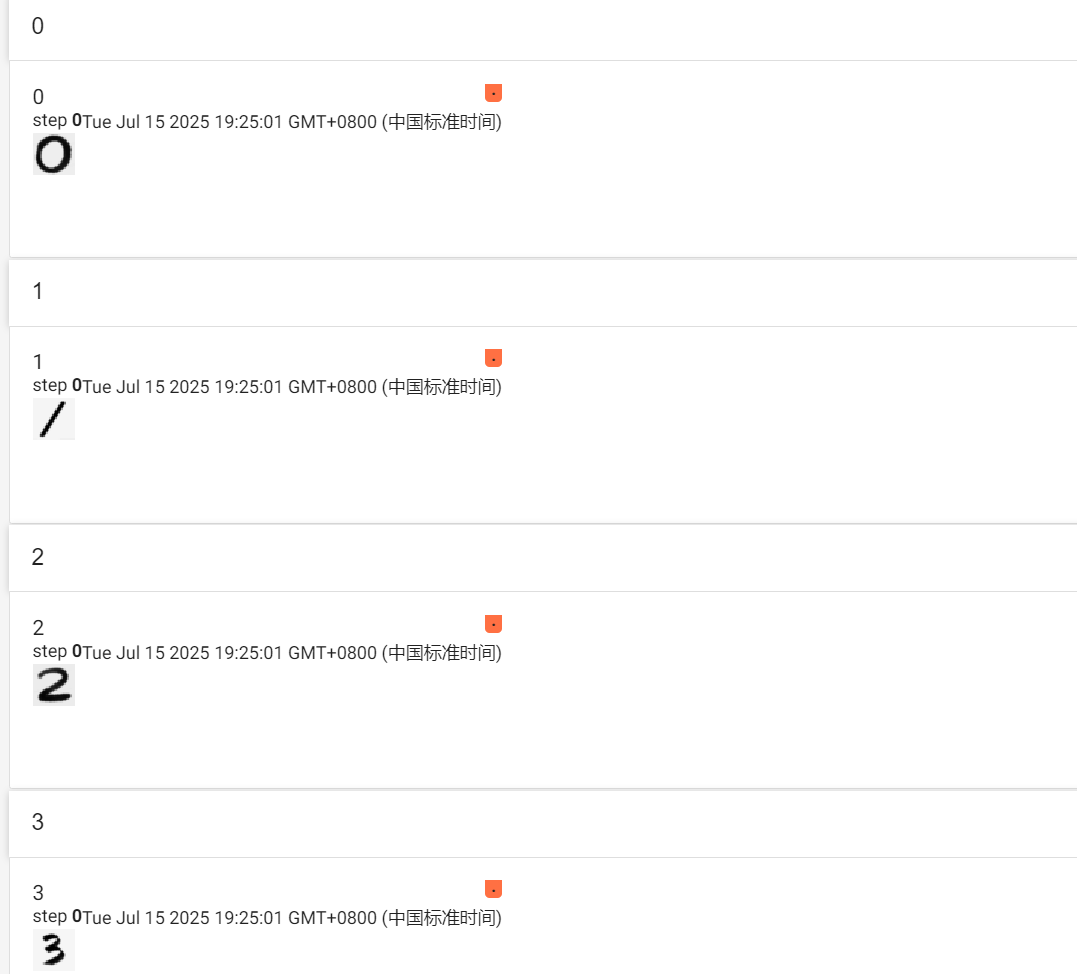
數據描述:在網上截取了0-9的圖片,并命名為img_0這種格式
第一步:獲取數據
image_path= 'imgs/img_{}.png'.format(i)image=Image.open(image_path)第二步:數據預處理,將彩色圖轉為灰度圖,裁剪其尺寸為28*28,然后將其轉換成tensor數據類型
image=image.convert("L")trans=torchvision.transforms.Compose([torchvision.transforms.Resize((28,28)),torchvision.transforms.ToTensor()])image=trans(image)第三步:可以查看一下處理完的數據,由于add_image要求數據是三維的,所以需要先處理一下數據
image=torch.reshape(image,(1,28,-1))writer=SummaryWriter("mini_show")writer.add_image("{}".format(i),image)writer.close()第四步:加載模型,并輸出訓練結果
image=torch.reshape(image,(1,-1))model=torch.load('minst_weight/net_40.pth')model.eval()with torch.no_grad():output=model(image)print('{}預測的值是:{}'.format(i,output.argmax(1).item()))完整代碼如下:?
import torch
import torchvision
from PIL import Image
from torch.utils.tensorboard import SummaryWriterfrom model import *
for i in range(10):image_path= 'imgs/img_{}.png'.format(i)image=Image.open(image_path)image=image.convert("L")trans=torchvision.transforms.Compose([torchvision.transforms.Resize((28,28)),torchvision.transforms.ToTensor()])image=trans(image)image=torch.reshape(image,(1,28,-1))writer=SummaryWriter("mini_show")writer.add_image("{}".format(i),image)writer.close()image=torch.reshape(image,(1,-1))model=torch.load('minst_weight/net_40.pth')model.eval()with torch.no_grad():output=model(image)print('{}預測的值是:{}'.format(i,output.argmax(1).item()))截取并預處理后的圖片:?
![[C/C++安全編程]_[中級]_[如何避免出現野指針]](http://pic.xiahunao.cn/[C/C++安全編程]_[中級]_[如何避免出現野指針])


)
的聯系與區別(詳細版))

簡單工廠模式)
)




)






