1.環境準備
1.1 安裝Streamlit
在安裝Streamlit之前,請確保您的系統中已經正確安裝了Python和pip。您可以在終端或命令行中運行以下命令來驗證它們是否已安裝
python --version
pip --version
一旦您已經準備好環境,現在可以使用pip來安裝Streamlit了。在終端或命令行中運行以下命令:
pip install streamlit
安裝完成后,您可以使用以下命令驗證Streamlit是否成功安裝:
streamlit version
Streamlit運行文件方式
streamlit run app.py
1.2 安裝Ollama
curl -fsSL https://ollama.com/install.sh | sh可能會出現斷傳,建議下載模型文件然后手動安裝
官網下載速度慢的話可以訪問?國內下載地址?下載
- 直接下載后將壓縮包 傳到服務器上的文件夾上,解壓到usr目錄,輸入:
sudo tar -C /usr -xzvf 你的壓縮包所在位置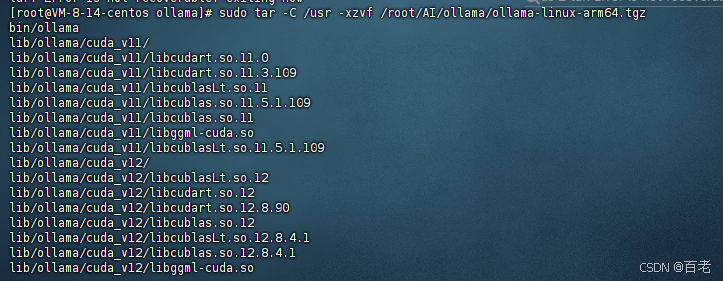
sudo systemctl daemon-reload
sudo systemctl enable ollama服務啟停
2.python程序
import os
# 調用私有化的ollama
os.environ['OLLAMA_HOST'] = 'http://192.168.4.201:11434'
import ollamadef get_chat_response(messages, model):# 調用ollama對話接口,以流的方式交互并直接返回stream = ollama.chat(model= model, messages=messages, stream=True)return streamdef get_model():# 獲取deepseek 模型版本model_name = []result = ollama.list().modelsfor a in result:model_name.append(a.model)return tuple(model_name)
以下streamlit_ollama.py?是streamlit run 執行的文件
import streamlit as stfrom utils import get_chat_response, get_modelcontent = ''
# 這個方法是接收ollama的流,是一個generator,然后遍歷這個generator,提取其中的content字段,
# 通過yield關鍵字重新生成一個generator,交給 write_stream()方法流式輸出
def getContent(stream):global contentfor chunk in stream:c = chunk['message']['content']content += cyield cst.title("聊天機器人")# 從導航欄選擇要交互的模型版本
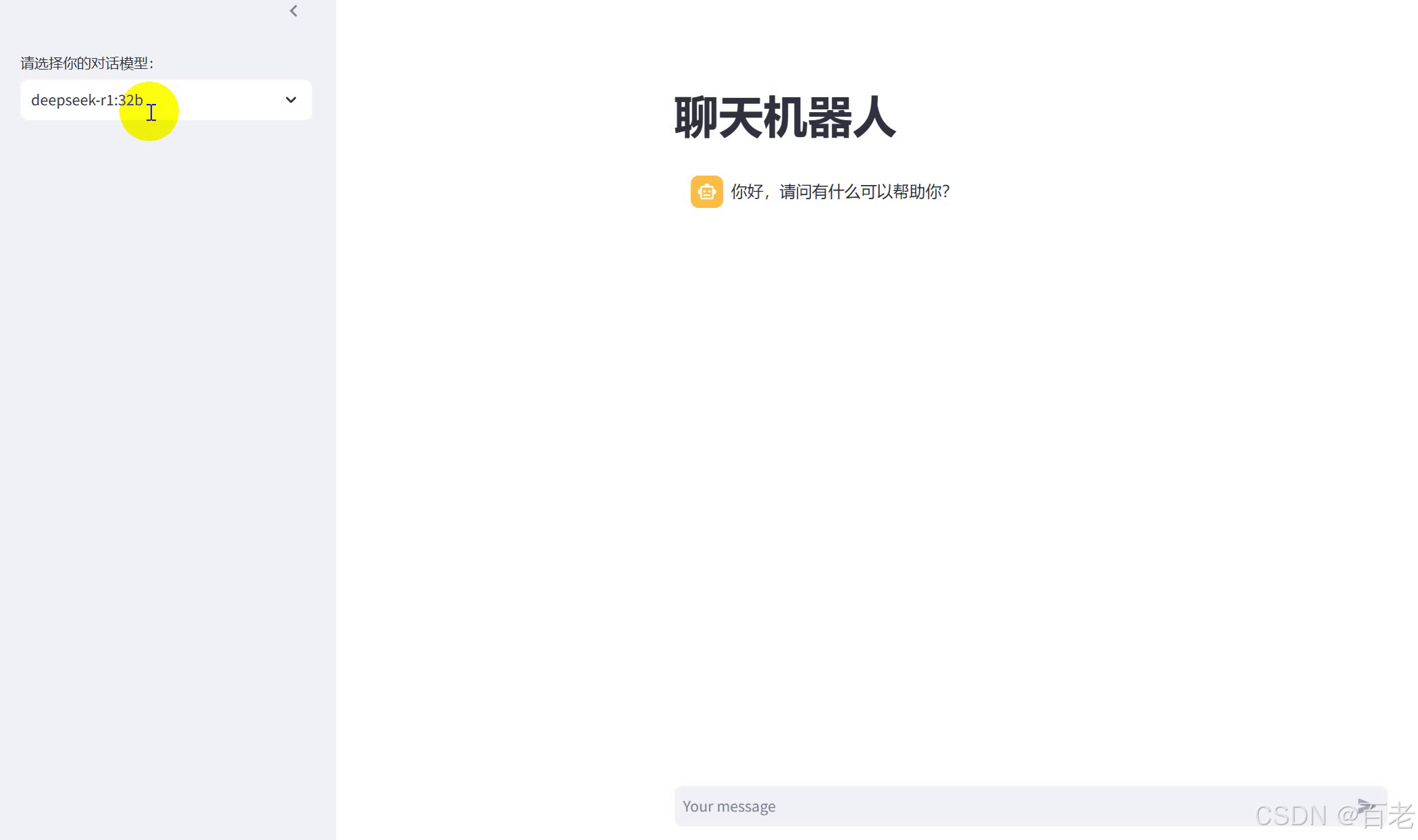
with st.sidebar:model = st.selectbox('請選擇你的對話模型:',get_model())
# 記錄對話歷史
if "messages" not in st.session_state:st.session_state['messages'] = [{'role':'assistant', 'content':'你好,請問有什么可以幫助你?'}]for message in st.session_state['messages']:st.chat_message(message['role']).write(message['content'])# 等待用戶輸入
prompt = st.chat_input()if prompt:st.session_state['messages'].append({'role':'user','content':prompt})st.chat_message('user').write(prompt)with st.spinner("思考中"):stream = get_chat_response(st.session_state['messages'], model)st.chat_message('assistant').write_stream(getContent(stream))st.session_state['messages'].append({'role':'assistant','content':content})content=''
最終效果
)














` 函數)



