官方倉庫:
https://github.com/alibaba/DataX?tab=readme-ov-file
1. 介紹
1.1. 基本介紹:
DadaX 是阿里云 DataWorks 數據集成 的開源版本(異構數據同步、離線數據同步工具 / 平臺)。主要抽象為 Reader 和 Writer 插件,管理源數據和目標數據的讀和寫。
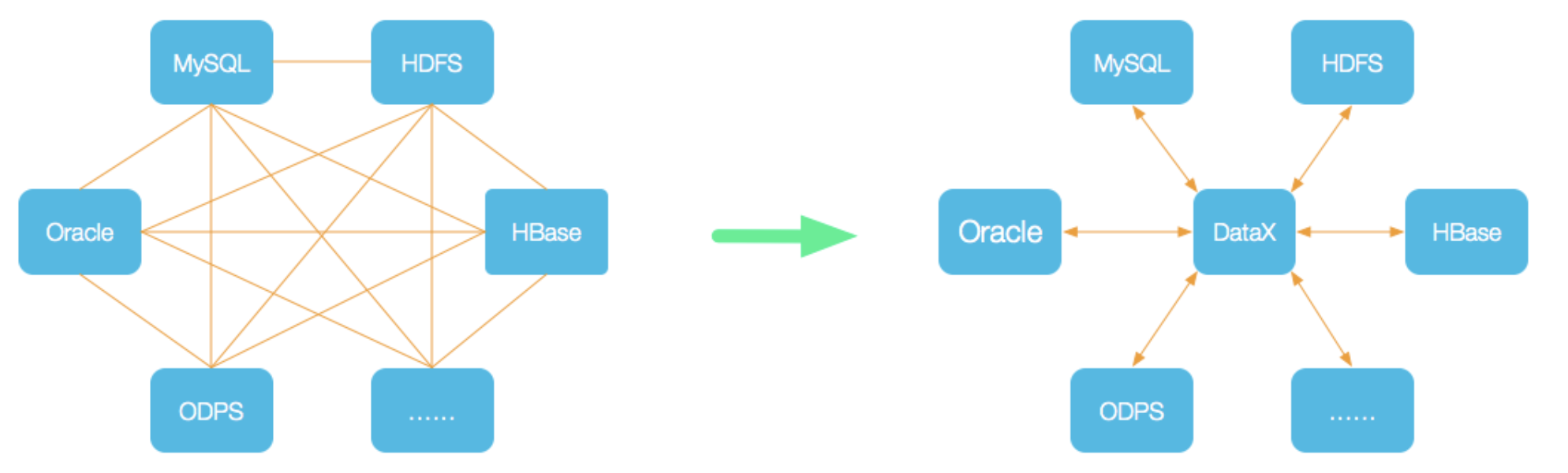
1.2. DataX 3.0 框架(插件式、Reader、writer ):
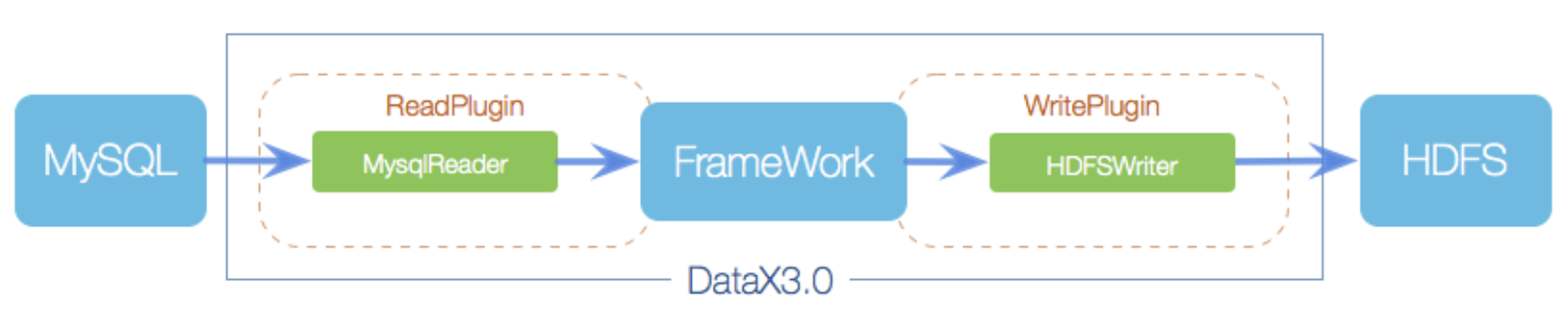
Reader:Reader 為數據采集模塊,負責采集數據源的數據,將數據發送給 Framework。
- Writer: Writer 為數據寫入模塊,負責不斷向 Framework 取數據,并將數據寫入到目的端
- Framework:Framework 用于連接 reader 和 writer,作為兩者的數據傳輸通道,并處理緩沖,流控,并發,數據轉換等核心技術問題。目前支持單機多線程的模式完成同步作業任務。
1.2.1. 官方例子:
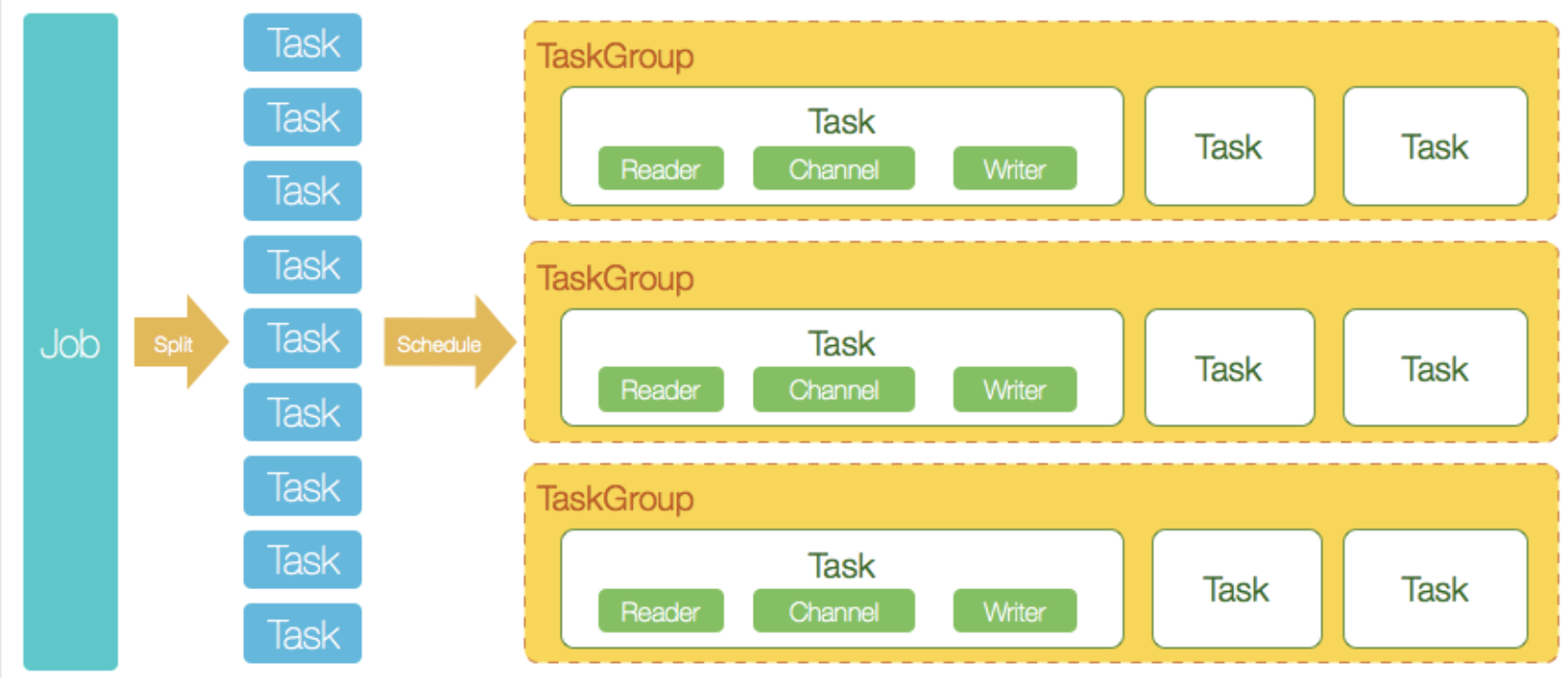
- 單個 Job 可以分為多個 task,一個 TaskGroup 可以按設置的并發度執行任務。
- 核心模塊介紹:
- DataX完成單個數據同步的作業,我們稱之為Job,DataX接受到一個Job之后,將啟動一個進程來完成整個作業同步過程。DataX Job模塊是單個作業的中樞管理節點,承擔了數據清理、子任務切分(將單一作業計算轉化為多個子Task)、TaskGroup管理等功能。
- DataX作業運行起來之后, Job監控并等待多個TaskGroup模塊任務完成,等待所有TaskGroup任務完成后Job成功退出。否則,異常退出,進程退出值非0
- 每一個Task都由TaskGroup負責啟動,Task啟動后,會固定啟動Reader—>Channel—>Writer的線程來完成任務同步工作。
- 切分多個Task之后,DataX Job會調用Scheduler模塊,根據配置的并發數據量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。每一個TaskGroup負責以一定的并發運行完畢分配好的所有Task,默認單個任務組的并發數量為5。
- DataXJob啟動后,會根據不同的源端切分策略,將Job切分成多個小的Task(子任務),以便于并發執行。Task便是DataX作業的最小單元,每一個Task都會負責一部分數據的同步工作。
- DataX調度流程:
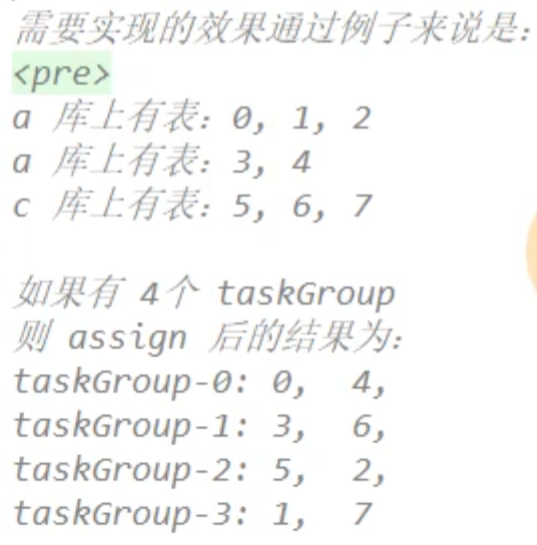
舉例來說,用戶提交了一個DataX作業,并且配置了20個并發,目的是將一個100張分表的mysql數據同步到odps里面。 DataX的調度決策思路是:
- DataXJob根據分庫分表切分成了100個Task。
- 4個TaskGroup平分切分好的100個Task,每一個TaskGroup負責以5個并發共計運行25個Task。
- 根據20個并發,DataX計算共需要分配4個TaskGroup。
- 數據來源多、封裝成網頁平臺(數據平臺)優先選擇 DataX (單進程多線程、日志完善)
1.3. 安裝使用
- 由于 datax 依賴于 java 1.8 及 以上,和 python 2 (3) 均可以,需要提前安裝 JDK 和 Conda 環境。
- datax 安裝:直接下載 DataX工具包:DataX下載地址 下載后解壓至本地某個目錄,進入bin目錄,即可運行同步作業:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
# 自檢腳本:
$ python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json2. 案例 Demo
2.1. Stream To Stream Demo
- 可以在
datax目錄下使用bin/datax.py -r YOURreader -w YOURwriter查看當前組合的 json 配置模板。
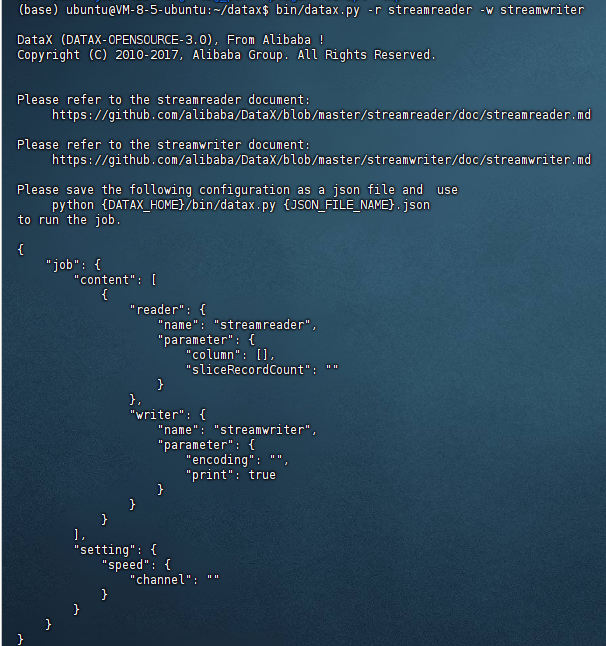
- 書寫配置文件,將配置文件放入
datax/job路徑下,執行python bin/datax.py job/demo.json命令。
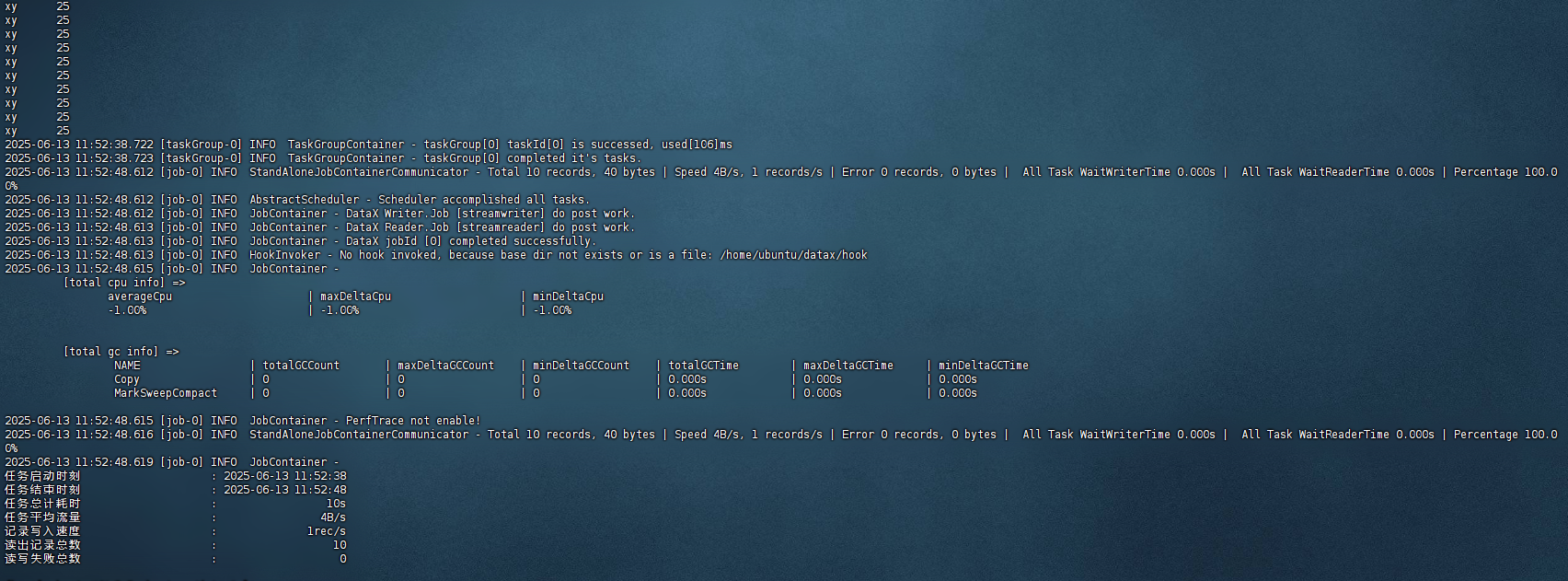
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"column": [{"type": "string","value": "xy"},{"type": "string","value": "25"}],"sliceRecordCount": "10"}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": "1"}}}
}
2.2. 從 Mysql 讀取數據存放到 HDFS
- HDFS 是為大數據而生的分布式文件系統,具備高容錯、高吞吐、強擴展性,適合存儲海量的結構化和非結構化數據

- mysqlreader 參數解析:

- hdfswrite 參數解析:

- 其參數配置如下:
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": [],"connection": [{"jdbcUrl": [],"table": [],"querySql":[]}],"password": "","username": "","where": ""}},"writer": {"name": "hdfswriter","parameter": {"column": [],"compress": "","defaultFS": "","fieldDelimiter": "","fileName": "","fileType": "","path": "","writeMode": ""}}}],"setting": {"speed": {"channel": ""}}}
}
- 如何鏈路中有部分線程的內容失敗,datax 會回滾部分成功的數據。
2.2.1. Mysql (準備) 建庫建表
$ mysql -uroot -p
create database datax;
use datax;
create table student(id int, name varchar(20));
// 插入數據
insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');2.2.2. hdfs 準備
- 安裝 hdfs 需要前置準備 Java 8+。
- 下載并解壓 Hadoop:
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz
tar -zxvf hadoop-3.4.1.tar.gz -C ~ # 解壓到根路徑下
cd hadoop-3.4.1- 配置環境變量:
vim ~/.bashrc
# 加入以下內容:
export HADOOP_HOME=你的路徑/hadoop-3.4.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHsource ~/.bashrc- 配置 HDFS , 進入
$HADOOP_HOME/etc/hadoop/,修改如下文件 :
core-site.xml:
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>hdfs-site.xml:
<configuration><property><name>dfs.replication</name><value>1</value> <!-- 單節點設為 1 --></property><property><name>dfs.namenode.name.dir</name><value>file:///home/YOURUSER/hadoopdata/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:///home/YOURUSER/hadoopdata/hdfs/datanode</value></property>
</configuration>替換 youruser 為當前用戶名,并確保創建了對應目錄:
mkdir -p ~/hadoopdata/hdfs/namenode
mkdir -p ~/hadoopdata/hdfs/datanode5. 格式化并啟動 HDFS,并驗證啟動。
# 格式化 HDFS
hdfs namenode -format# 啟動 NameNode 和 DataNode
start-dfs.sh# 查看 Java 進程(有 namenode 和 datanode 即成功)
jps# 輸出類似:
12345 NameNode
12346 DataNode# 測試命令是否可用:
hdfs dfs -mkdir /demo
hdfs dfs -ls /
6. 測試 JSON,以及測試結果
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": ["id","name"],"connection": [{"jdbcUrl": ["jdbc:mysql://localhost:3306/datax?useUnicode=true&characterEncoding=UTF-8"],"table": ["student"]}],"password": "123456","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "int"},{"name": "name","type": "string"}],"defaultFS": "hdfs://localhost:9000","fieldDelimiter": "|","fileName": "student.txt","fileType": "text","path": "/","writeMode": "append"}}}],"setting": {"speed": {"channel": "1"}}}
}
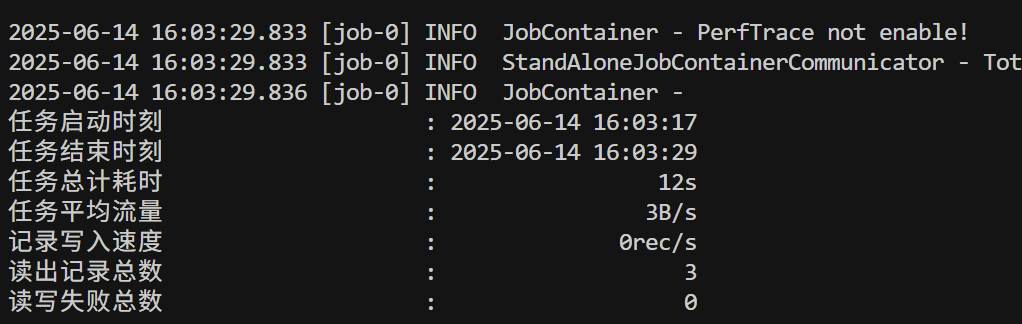
內部有保證數據一致性的判斷,當多線程環境執行完后需要對比是否全部任務成功,否則觸發回滾機制。
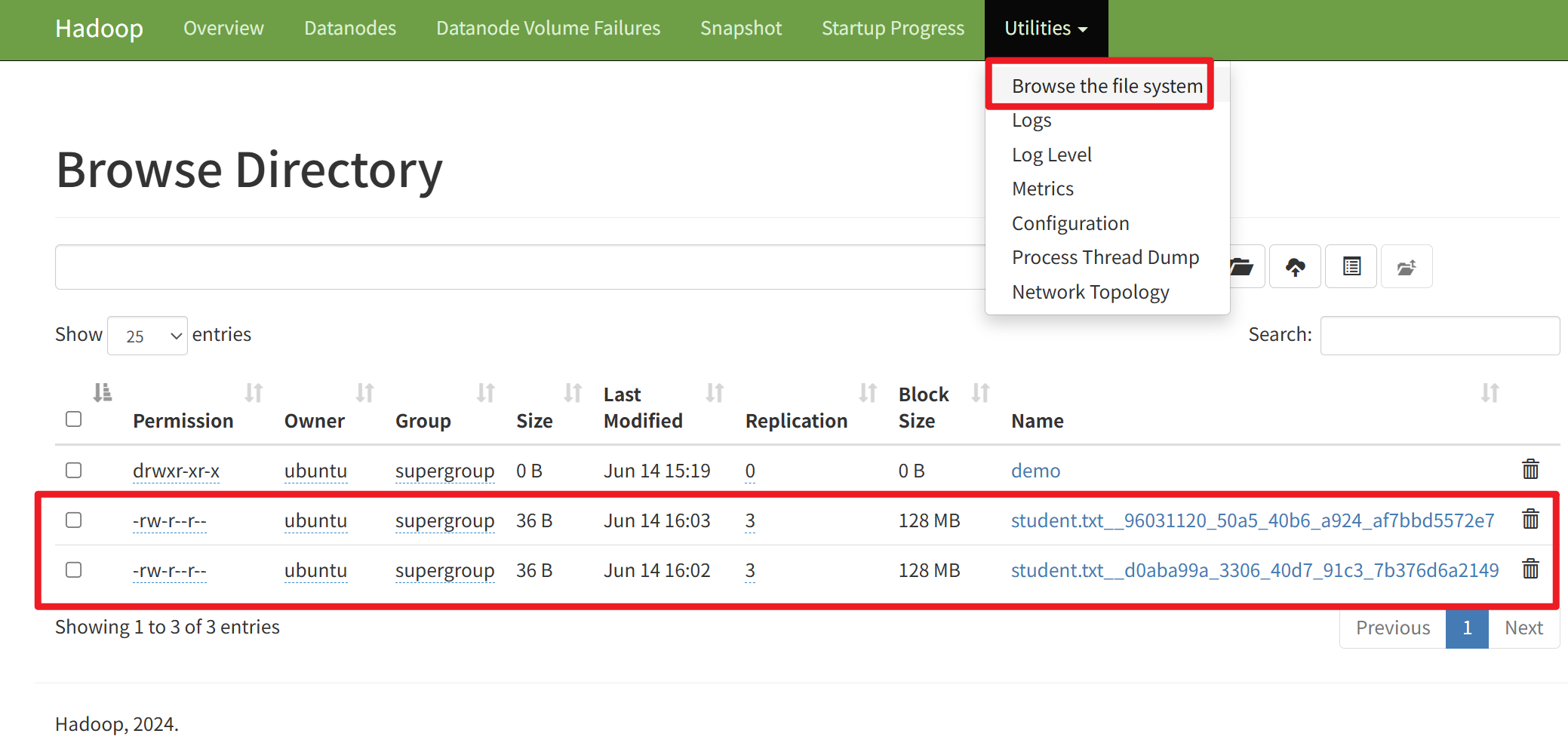
- 可以看到管理界面下有成功同步的兩個 student 文件。
3. DataX 原理分析
3.1. datax.py
- 配置參數:
-j可以指定 jvm 參數,可以用于配置堆內存。- 在該文件中啟動了 java 執行
com.alibaba.datax.core.Engine啟動類。
3.2. JobContainor
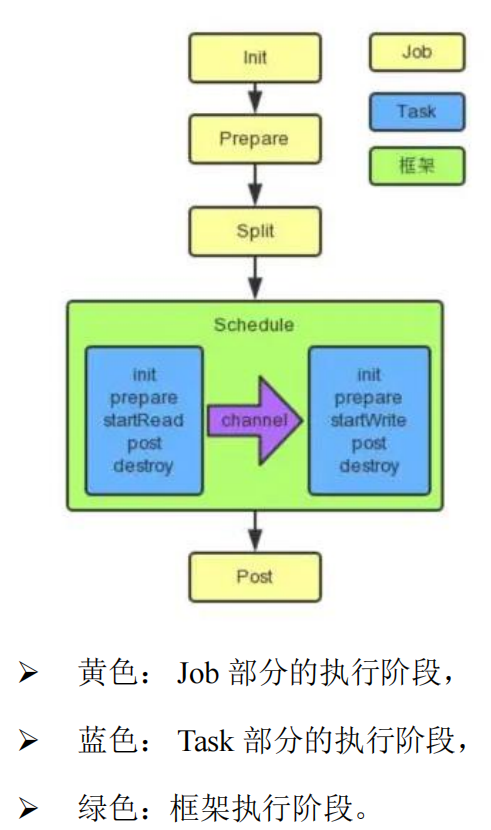
有完整的生命周期管理(對應上方結構圖的描述):
- init()
-
- reader 初始化。(根據不同的配置文件)
- writer 初始化。
- prepare()
-
- 調用插件,做一些基本準備工作,清理等。
- split()
-
- task 切分邏輯
- schedule()
- post()
3.2.1. Task 切分
- 調整 channel 數量(并發數的確定)
在配置中主要分三個模塊 reader writer setting,setting 中可以配置 channel、byte、record(數據條數),源碼中選擇如果設定了 數據量或帶寬的速度,算出來的 channel 以小的為主。直接指定channel 的優先級最低。

3.2.2. Schedule 調度
根據拆分中計算的任務數和并發數取最小值,避免資源浪費。
- assignFairly 將 task 公平的分配到 taskgroup

3.3. 優化(并發、限流)
- job.setting.speed.channel : channel 并發數
- job.setting.speed.record : 全局配置 channel 的 record 限速
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- core.transport.channel.speed.record:單個 channel 的 record 限速
- core.transport.channel.speed.byte:單個 channel 的 byte 限速
3.3.1. 優化1:提升每個 channel 的速度
在 DataX 內部對每個 Channel 會有嚴格的速度控制,
- 控制每秒同步的記錄數 record。
- 每秒同步的字節數 byte,默認的速度限制是 1MB/s,可以根據具體硬件情況設
置這個 byte 速度或者 record 速度,一般設置 byte 速度,比如:我們可以把單個 Channel 的
速度上限配置為 5MB。
3.3.2. 優化 2:提升 DataX Job 內 Channel 并發數
并發數 = taskGroup 的數量 * 每個 TaskGroup 并發執行的 Task 數 (默認為 5)。
提升 job 內 Channel 并發有三種配置方式:
- Channel 個數 = 全局 Byte 限速 / 單 Channel Byte 限速。
- Channel 個數 = 全局 Record 限速 / 單 Channel Record 限速。
- 直接配置 Channel 個數。
3.3.3. 優化 3:提高 JVM 堆內存
當提升 DataX Job 內 Channel 并發數時,內存的占用會顯著增加,因為 DataX 作為數據
交換通道,在內存中會緩存較多的數據。例如 Channel 中會有一個 Buffer,作為臨時的數據
交換的緩沖區,而在部分 Reader 和 Writer 的中,也會存在一些 Buffer,為了防止 OOM 等錯
誤,調大 JVM 的堆內存。
建議將內存設置為 4G 或者 8G,這個也可以根據實際情況來調整。
調整 JVM xms xmx 參數的兩種方式:一種是直接更改 datax.py 腳本;另一種是在啟動
的時候,加上對應的參數,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json
-Xms8G JVM 堆內存 初始大小
-Xmx8G JVM 堆內存 最大大小
設置一致防止內存抖動 。



—資料分析(第二節課))









)
)




