系列文章目錄
文章目錄
- 系列文章目錄
- 一、torch.autograd.function
- 代碼實例
??在開始正文之前,請各位姥爺動動手指,給小店增加一點訪問量吧,點擊小店,同時希望我的文章對你的學習有所幫助。本文也很簡單,主要講解pytorch的前向傳播張量計算,和后向傳播獲取梯度計算。
一、torch.autograd.function
每一個原始的自動求導運算實際上是兩個對 Tensor 操作的函數
- forward 函數計算輸入Tensor,一些列操作后得到輸出Tensor
- backward 接收輸出 Tensor ,獲取某個標量的梯度,并且計算輸入Tensor相對于相同標量的梯度值。
使用 apply 執行相應的運算
代碼實例
??這個實例實現了重寫line的功能,在以后的深度學習和構建扔工神經網絡中常常使用。對 line 類重構,兩個方法 forward 和 backward 都是靜態的。實現的功能就是把三個張量運算: w * x + b.代碼中在 return 中體現。
- forward 傳遞的 ctx 用于保存上下文的管理器,調用
ctx.save_for_backward(變量名)可以存儲變量,調用ctx.saved_tensors可以把對應的張量取出來。 - grad_output 是上一層的梯度,返回回來應該遵循鏈式法則。
- 導數計算:把 y 看做是因變量(編程中省略這個變量,具體體現 w * x + b),w, x, b 都看做是自變量。使用高數中的求導公式,大家就知道乘的系數是什么了。
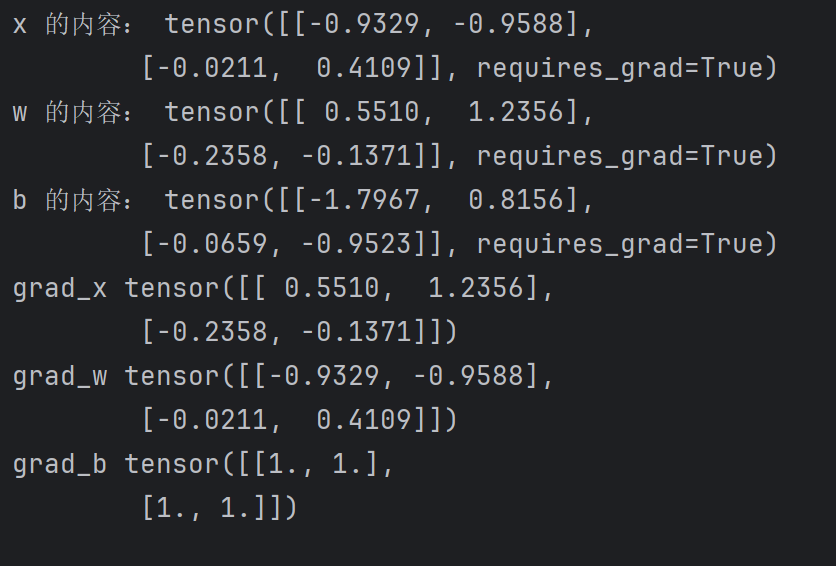
import torchclass line(torch.autograd.Function):@staticmethoddef forward(ctx,w,x,b):# 第一個參數是管理器,對變量進行存儲# y = w*x+bctx.save_for_backward(w,x,b)# 定義前向運算return w*x+b@staticmethoddef backward(ctx, grad_output):# 上下文管理器,第二個參數是上一級梯度,表達了一個鏈式法則# 我們計算梯度,需要乘上一級梯度w,x,b = ctx.saved_tensors# dy/dw = xgrad_w = grad_output * x# dy/dx = wgrad_x = grad_output * w# dy/db = 1grad_b = grad_output * 1return grad_w,grad_x,grad_bw = torch.randn(2,2,requires_grad=True)
x = torch.randn(2,2,requires_grad=True)
b = torch.randn(2,2,requires_grad=True)# 調用重寫的line函數
out = line.apply(w,x,b)
out.backward(torch.ones(2,2))print("x 的內容:",x)
print("w 的內容:",w)
print("b 的內容:",b)
print("grad_x",x.grad)
print("grad_w",w.grad)
print("grad_b",b.grad)








)
)









