?一.?慢查詢
在MySQL中,如何定位慢查詢?
?出現慢查詢的情況有以下幾種:
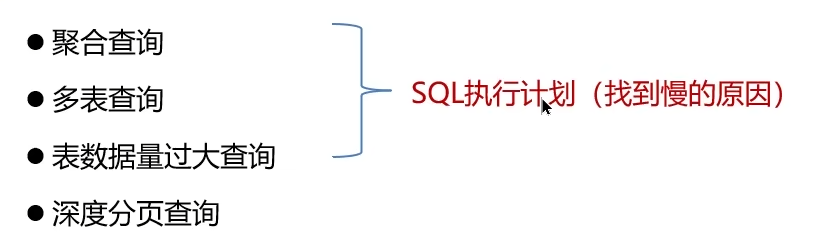
- 聚合查詢
- 多表查詢
- 表數據量過大查詢
- 深度分頁查詢
表象:頁面加載過慢,接口壓測響應時間過長(超過1s)
1.2 如何定位慢查詢?
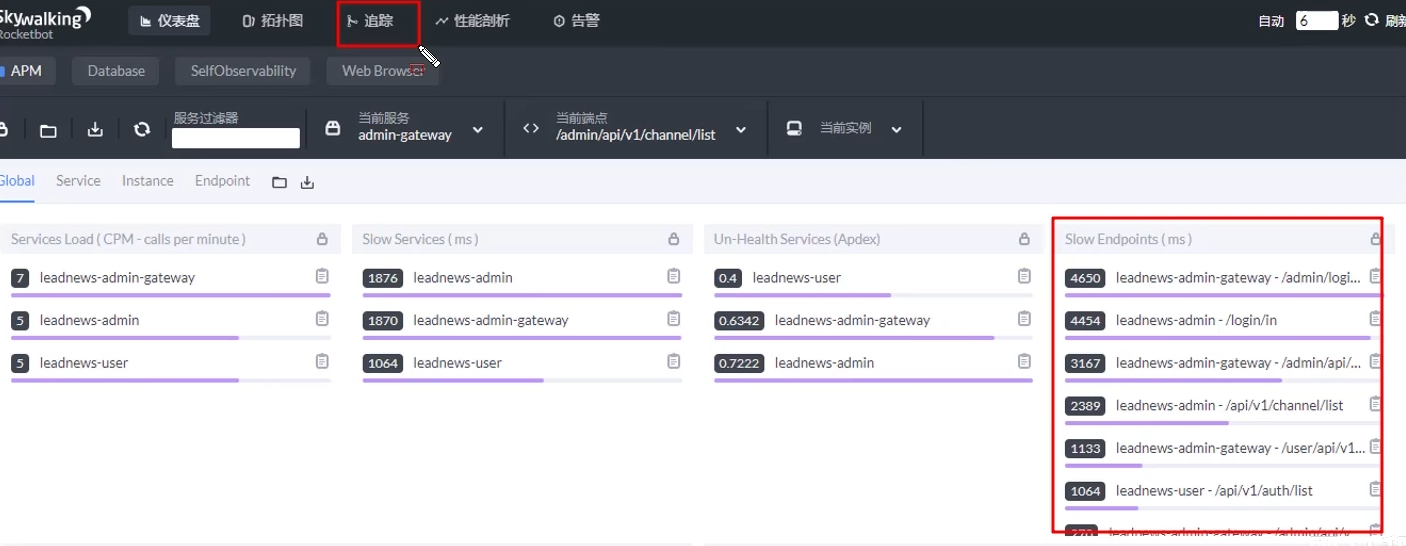
方案一:開源工具
- 調試工具:Arthas
- 運維工具:Prometheus、Skywalking
方案二:MySQL自帶慢日志
? ? ? ? 慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句的日志,如果要開啟慢查詢日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:

? ? ? ? 配置完畢之后,通過一下指令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息 /var/lib/mysql/localhost-slow.log。

總結

面試官:MySQL中,如何定義慢查詢?
候選人:嗯~,我們當時做壓測的時候有的接口非常的慢,接口的響應時間超過了2秒以上,因為我們當時的系統部署了運維的監控系統Skywalking,在展示的報表中可以看到是哪一個接口比較慢,并且可以分析這個接口哪部分比較慢,這里可以看到SQL的具體的執行時間,所以可以定位是哪個sql出了問題。
? ? ? ? 如果,項目中沒有這種運維的監控系統,其實在MySQL中也提供了慢日志查詢功能,可以在MySQL的系統配置文件中開啟這個慢日志的功能,并且也可以設置SQL執行超過多少時間來記錄到一個日志文件中,我記得上一個項目配置的是2秒,只要SQL執行的時間超過了2秒就會記錄到日志文件中,我們就可以在日志文件找到執行比較慢的SQL了。
二. SQL語句執行很慢,如何分析
那這個SQL語句執行很慢,如何分析呢?
2.1 分析

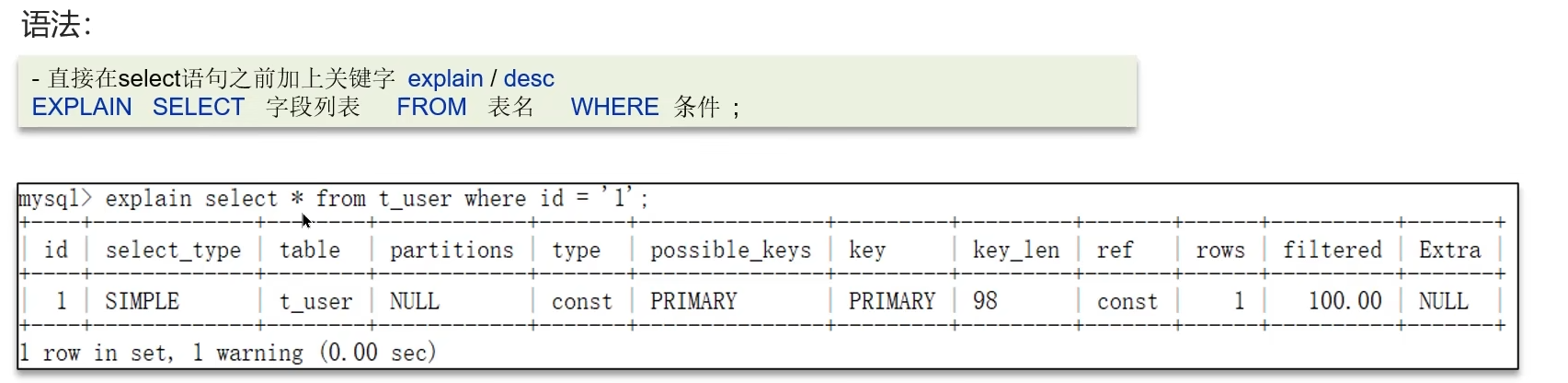
? ? ? ? ?可以采用WXPLAIN或者DESC命令獲取MySQL如何執行SELECT語句的信息

總結

面試官:那這個SQL語句執行很慢,如何分析呢?
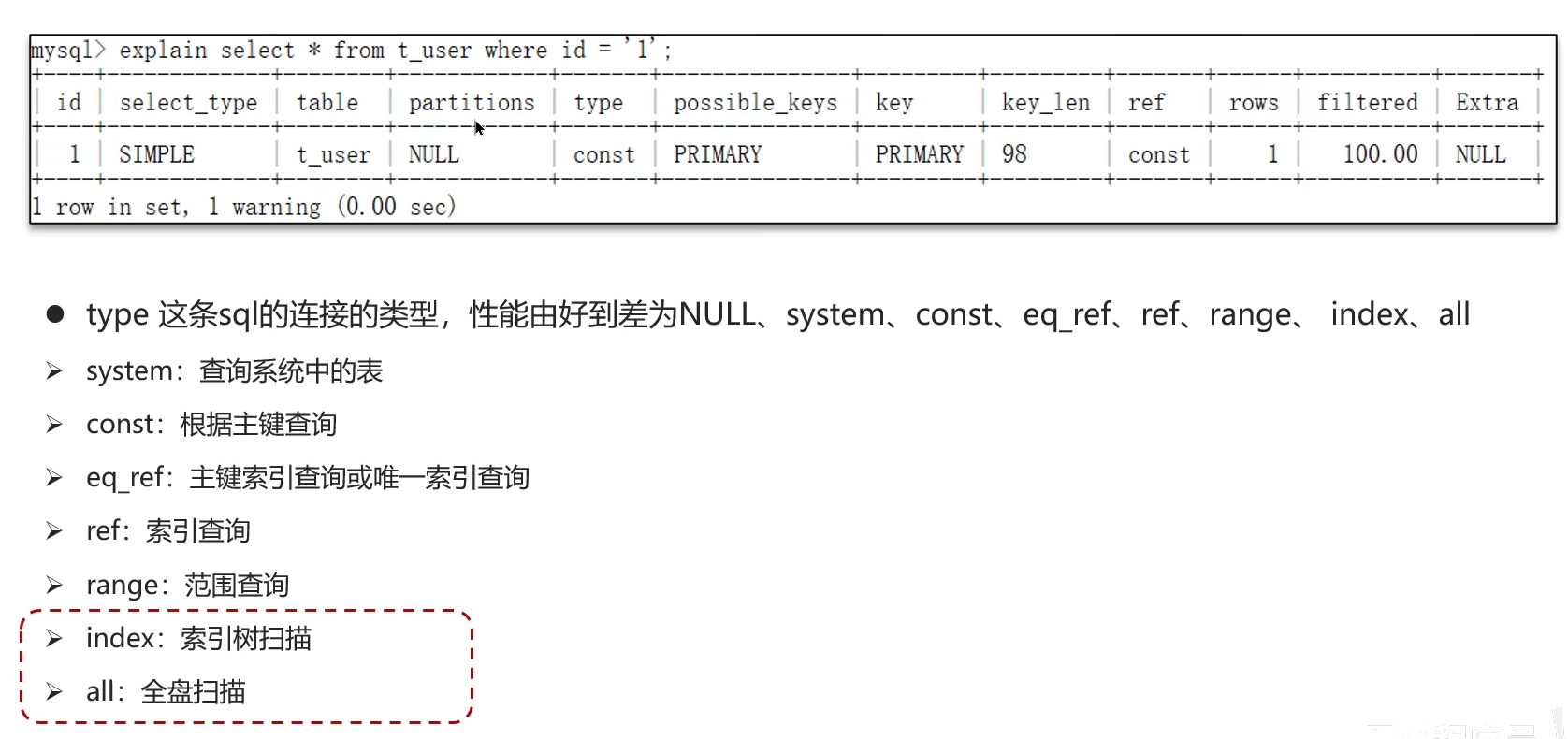
候選人:如果一條sql執行很慢的話,我們通常會使用mysql自動的執行計劃explain來去查看這條sql的執行情況,比如在這里面可以通過key和key_len檢查是否命中了索引,如果本身已經添加了索引,也可以判斷是否有失效的情況,第二個,可以通過type字段查看sql是否有進一步的優化空間,是否存在全索引或全盤掃描,第三個可以通過extra建議來判斷,是否出現了回表的情況,如果出現了,可以嘗試添加索引或修改返回字段來修復
?三. 了解過索引嗎?(什么是索引)
了解過索引嗎?(什么是索引)
? ? ? ? ?索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構(B+樹),這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據上實現高級查找算法,這種數據結構就是索引。

索引的底層數據結構了解過嗎?
3.1 數據結構對比
? ? ? ? MySQL默認使用的索引底層數據結構是B+樹。再聊B+樹之前,先聊聊二叉樹和B樹
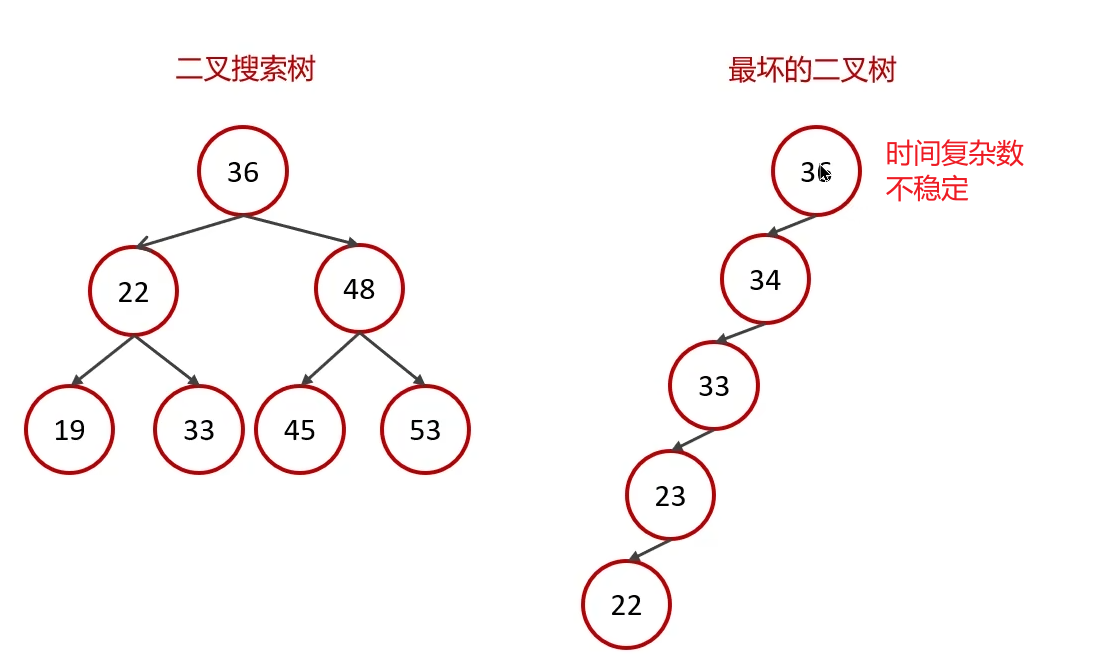
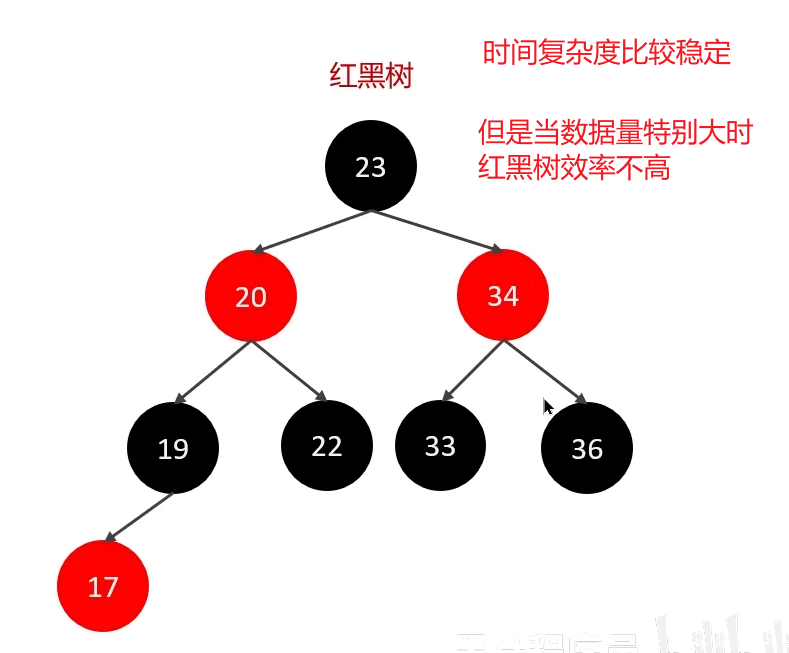
? ? ? ? B-Tree,B樹是一種多叉路衡查找樹,相對于二叉樹,B樹每個節點可以有多個分支,即多叉。以一顆最大度數(max-degree)為5(5階)的b-tree為例,那這個B樹每個節點最多存儲4個key
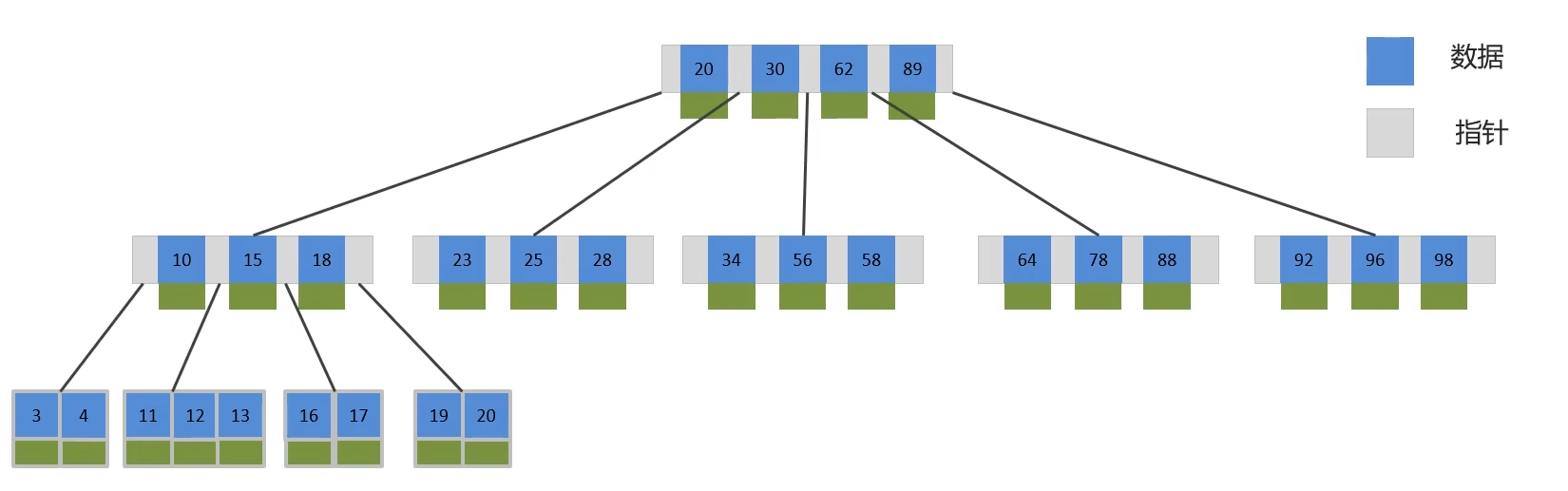
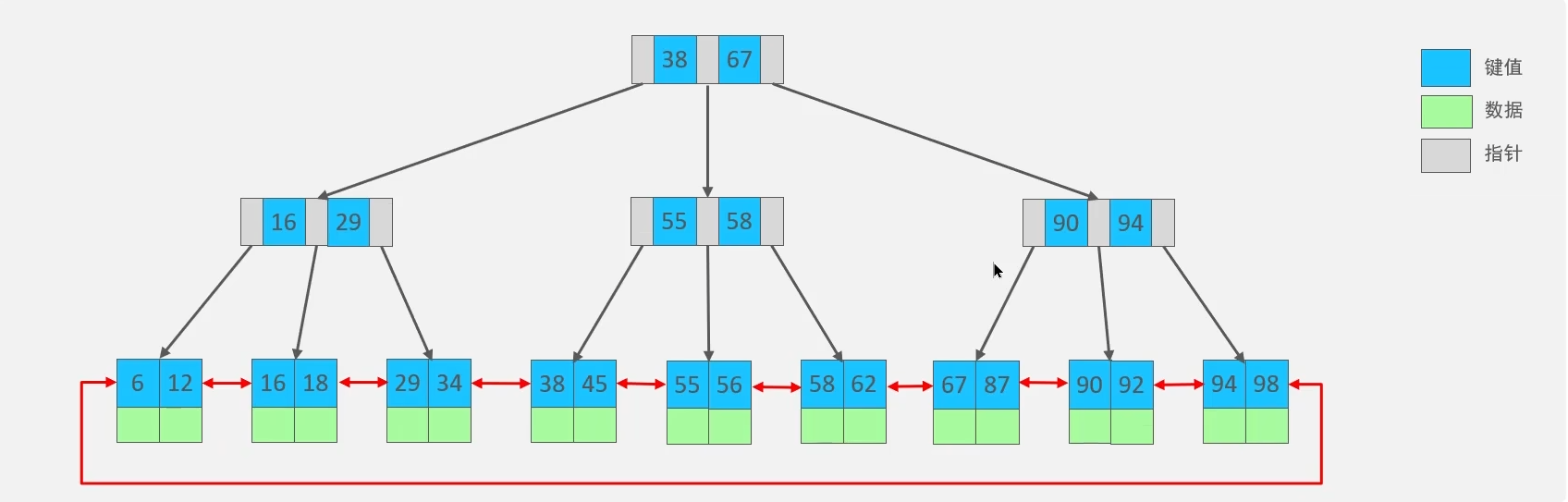
????????? B+Tree是在BTree基礎上的一種優化,使其更適合實現外存儲索引結構,InnoDB存儲引擎就是用B+Tree實現其索引結構

總結


四. 聚簇索引和非聚簇索引
什么是 聚簇索引和非聚簇索引?
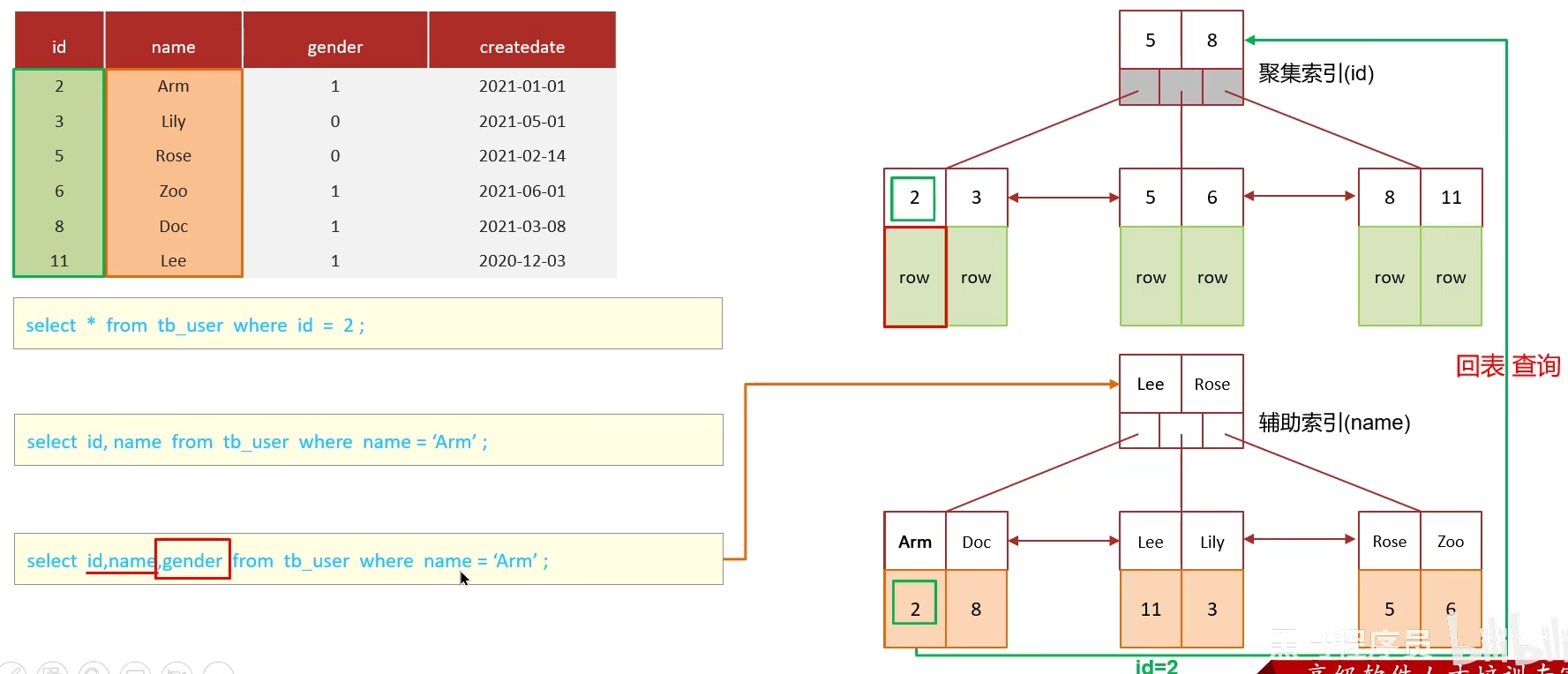
什么是聚集索引,什么是二級索引(非聚集索引)
什么是回表
4.1?聚集索引,二級索引(非聚集索引)


4.2 回表查詢
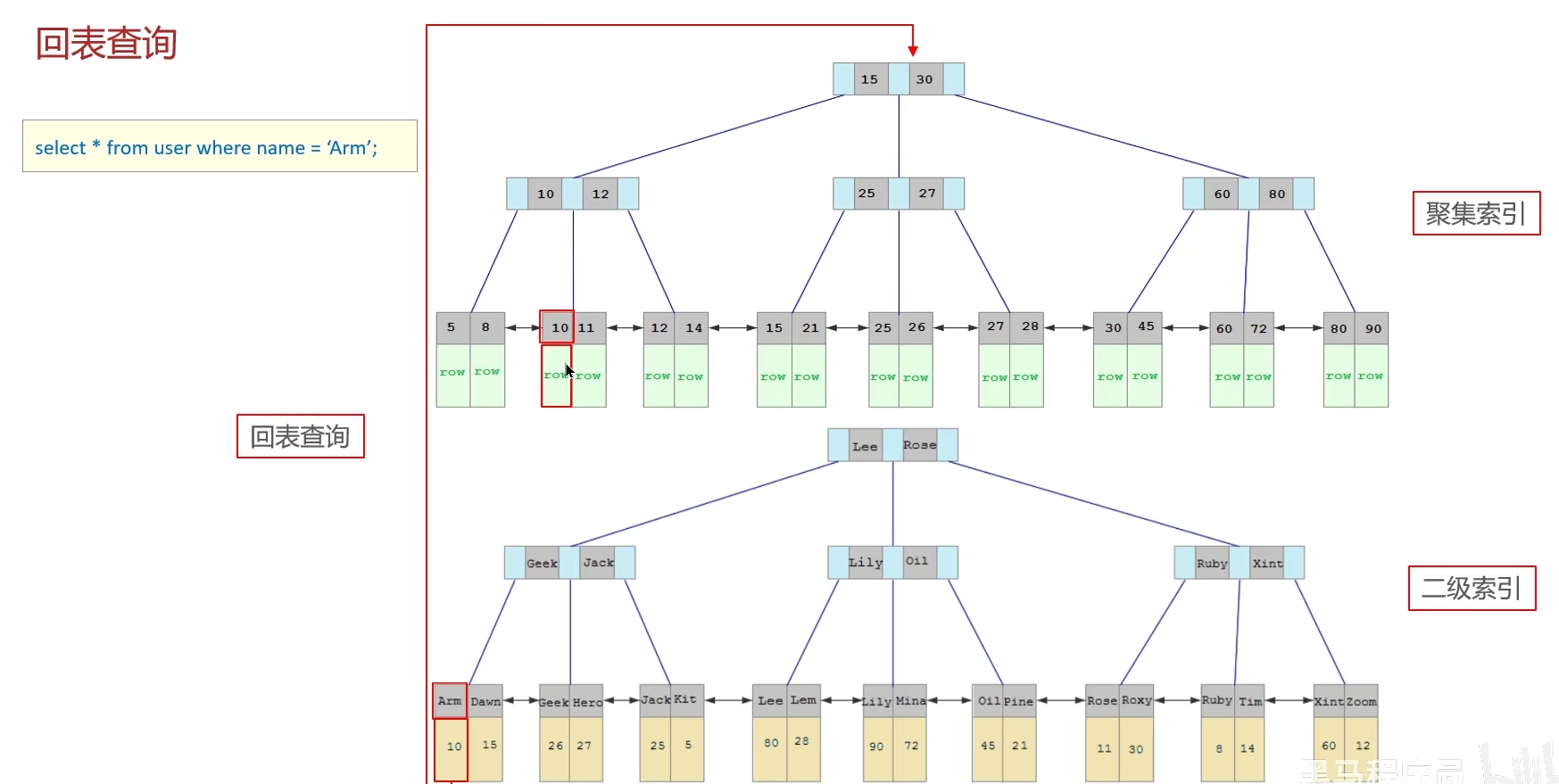
總結

注意:如果面試官直接問什么是回表查詢,要先解釋一下聚集索引和二級索引

五. 覆蓋索引
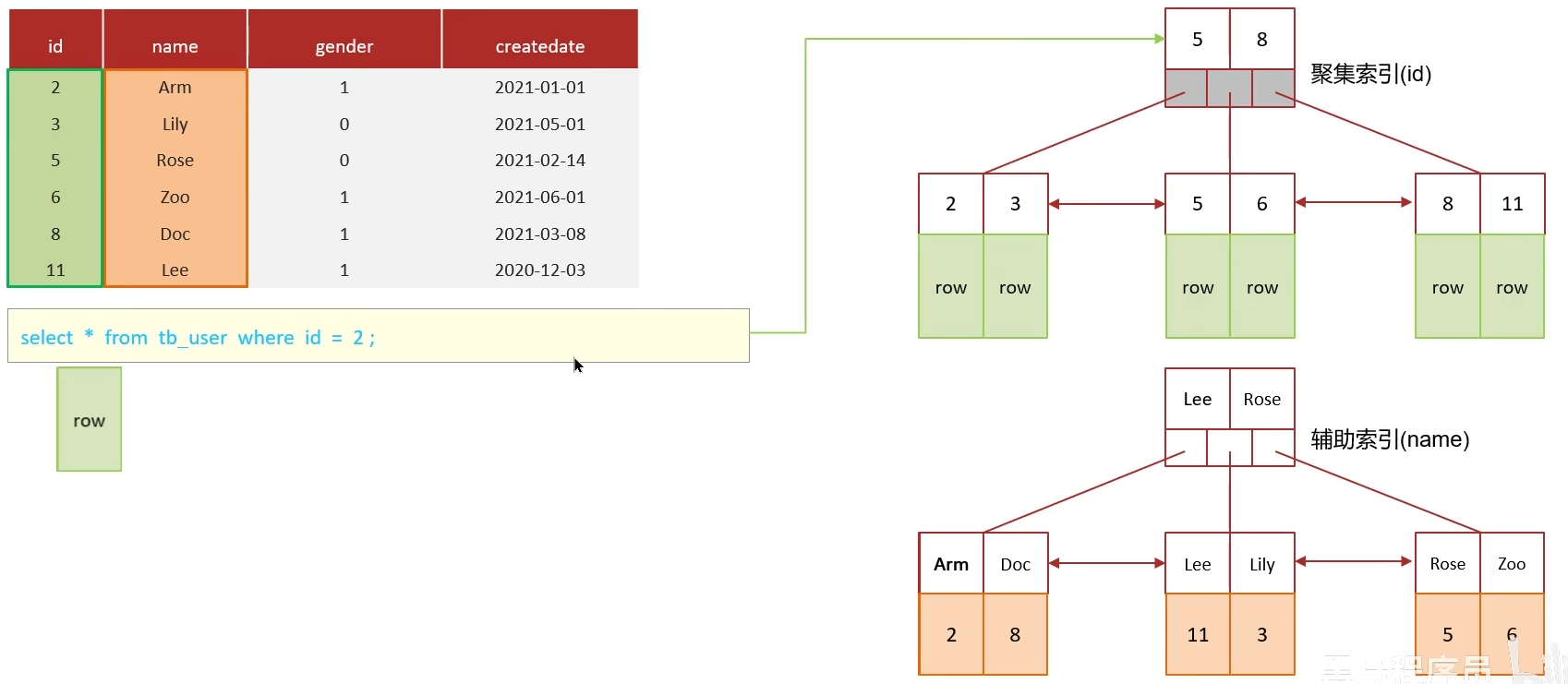
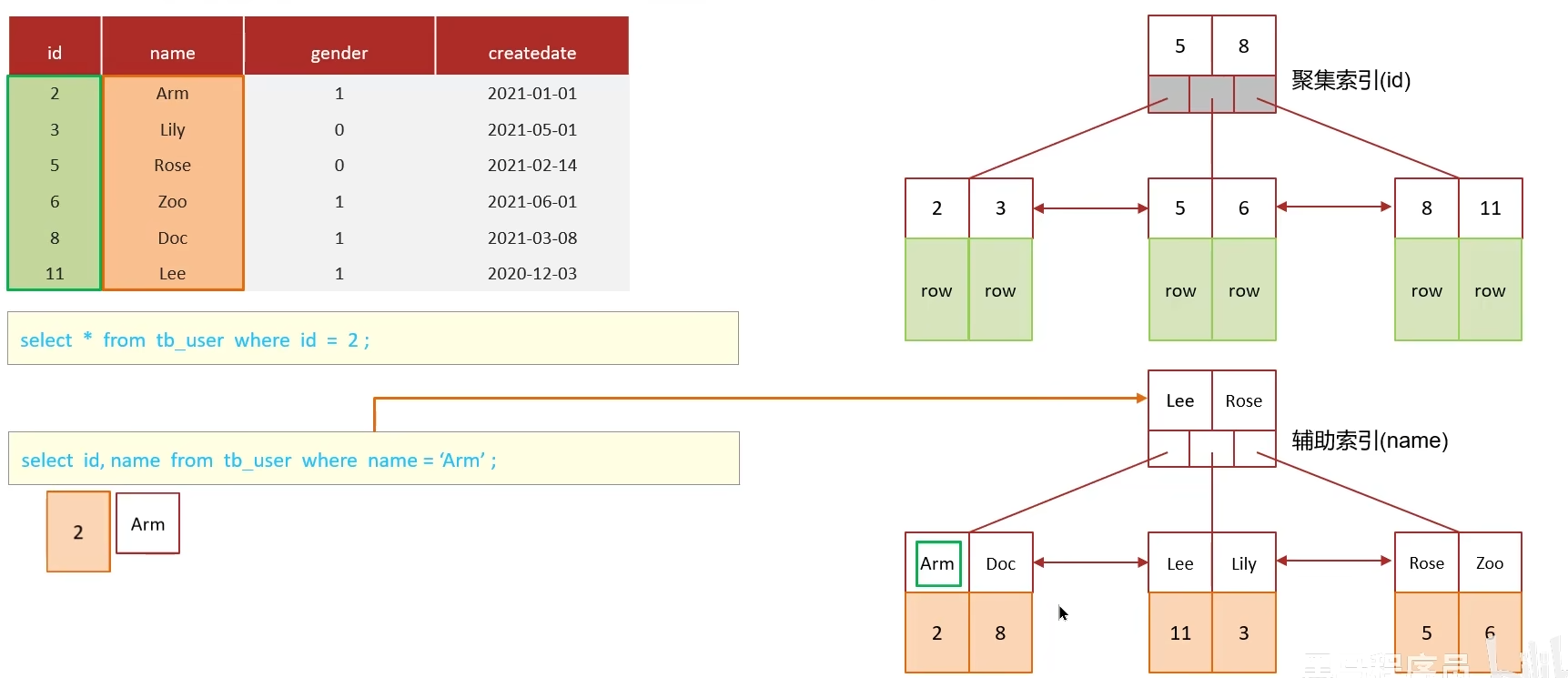
5.1 覆蓋索引
? ? ? ? 查詢使用了索引,并且需要返回的列,在該索引中已經全部能夠找到。

?
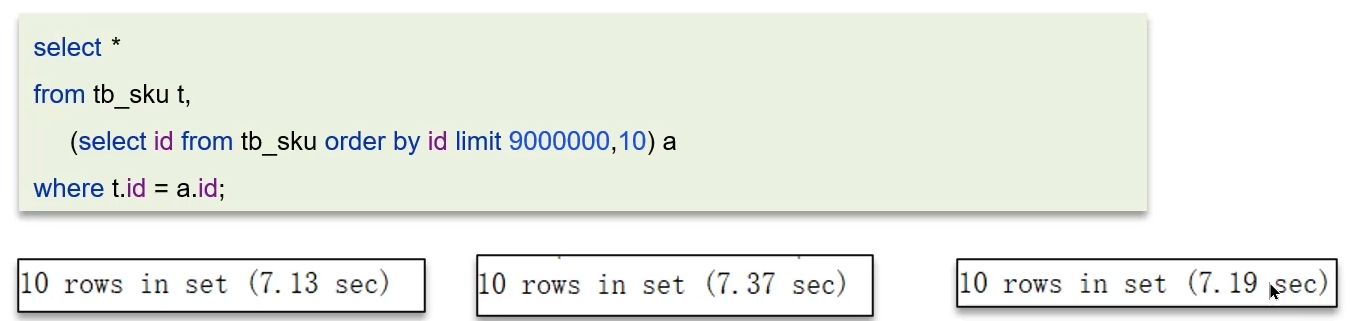
5.2 MYSQL超大分頁處理
? ? ? ? 在數據量比較大時,如果進行limit分頁查詢,在查詢時,越往后,分頁查詢效率越低。

? ? ? ? 優化思路:一般分頁查詢時,通過創建覆蓋索引 能夠比較好的提高性能,可以通過覆蓋索引加子查詢形式進行優化
總結


六. 索引創建原則
索引創建原則有哪些?
????????回答這個問題,首先要陳述一下自己在實際的工作中是怎么用的,比如用到了主鍵索引、唯一索引或者是根據業務創建的索引(復合索引)
- 針對于數據量較大,且查詢比較頻繁的表建立索引。? ? ? ? 單表超過10萬數據(增加用戶體驗)
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引。
- 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高。
- 如果是字符串類型的字段,字段的長度較長,可以針對于字段的特點,建立前綴索引。
- 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲時間,避免回表,提高查詢效率
- 要控制索引的數量,所以并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率
- 如果索引不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好的確定哪個索引最有效的用于查詢
總結


七. 索引失效
在什么情況下,索引會失效?
????????索引失效的情況有很多,可以說一些自己遇到過的,不要張口就說一推背誦好的面試題(適當的思考一下,更真實)

1)違反最左前綴法則

?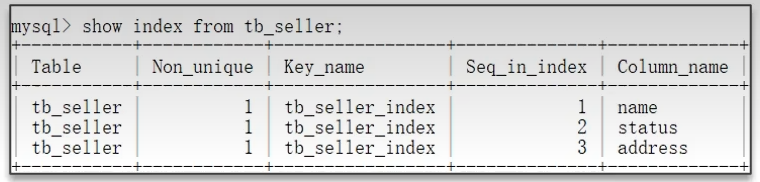

?? ? ? ? 違反最左前綴法則,索引失效:

2)范圍查詢右邊的列,不能使用索引。

3)不要咋索引列上進行運算操作,索引將失效
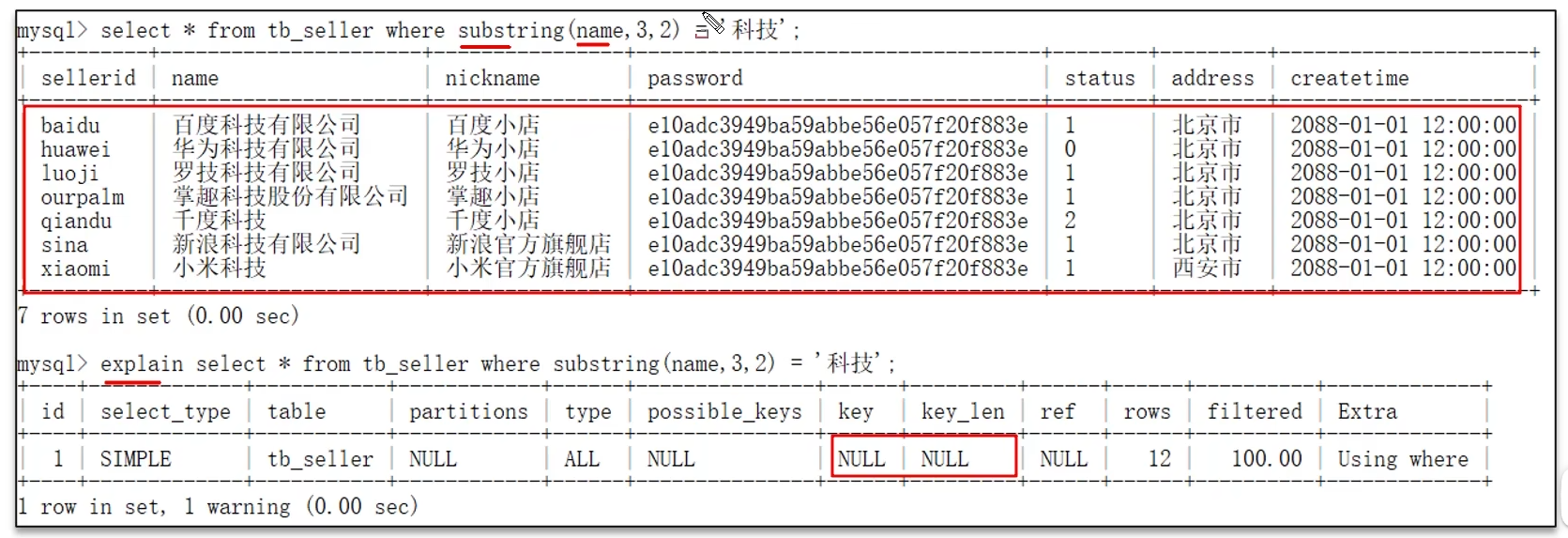
4)字符串不加單引號,造成索引失效。

?5)以%開頭的Like模糊查詢,索引失效。如果僅僅是尾部模糊匹配,索引不會失效。如果是頭部模糊匹配,索引失效
?
總結

?

八. 談一談對sql優化的經驗
?談一談對sql優化的經驗
8.1 表的設計優化
? ? ? ? 參考阿里開發手冊《嵩山版》
8.2 索引優化
8.3 SQL語句優化

8.4 主從復制、讀寫分離
? ? ? ? 如果數據庫的使用場景讀的操作比較多的時候,為了避免寫的操作所造成的性能影響,可以采用讀寫分離的架構。讀寫分離解決的是,數據庫的寫入,影響了查詢的效率。
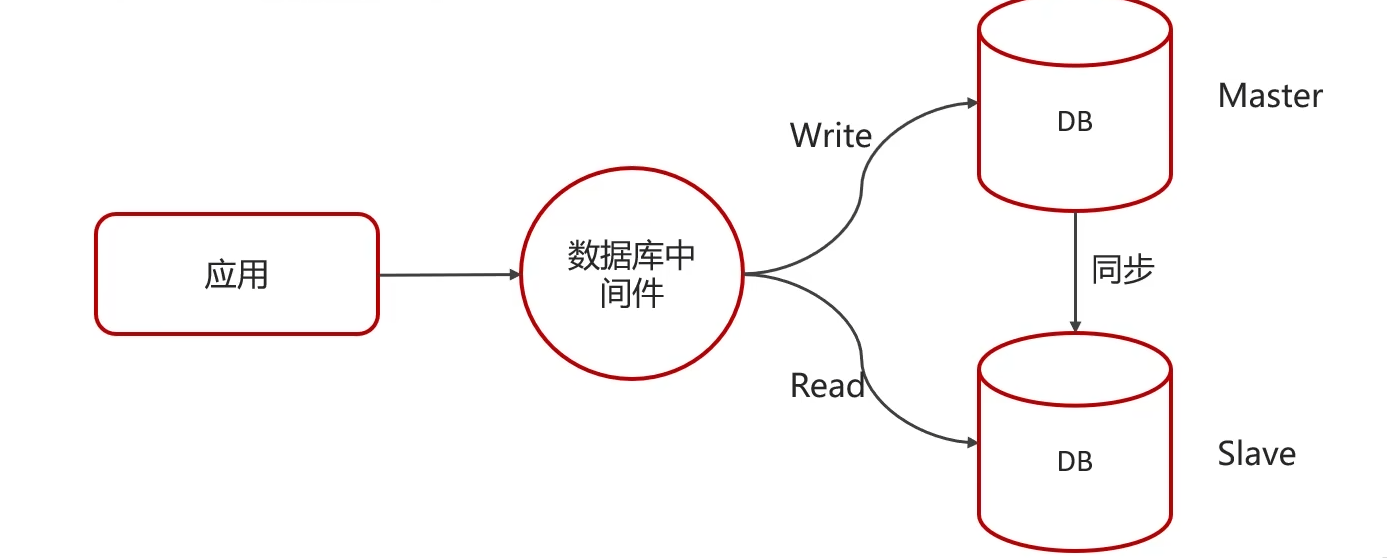










)






)
)

