Transformer架構。它不僅僅是一個模型,更是一種范式,徹底改變了我們理解和處理自然語言的方式。
2017年,谷歌大腦團隊發表了一篇劃時代的論文,題目就叫《Attention is All You Need》。這標題本身就充滿了力量,宣告了注意力機制的崛起。這篇論文的核心動機,就是要解決當時序列到序列模型,比如RNN、LSTM,在處理長文本時遇到的長距離依賴問題。簡單說,就是讓模型能記住前面說的,才能更好地理解后面的內容。Transformer的出現,直接把NLP的水平拉上了一個臺階,催生了像BERT、GPT這樣的大模型,甚至可以說,沒有Transformer,就沒有今天的ChatGPT。這就是Transformer的經典架構圖。
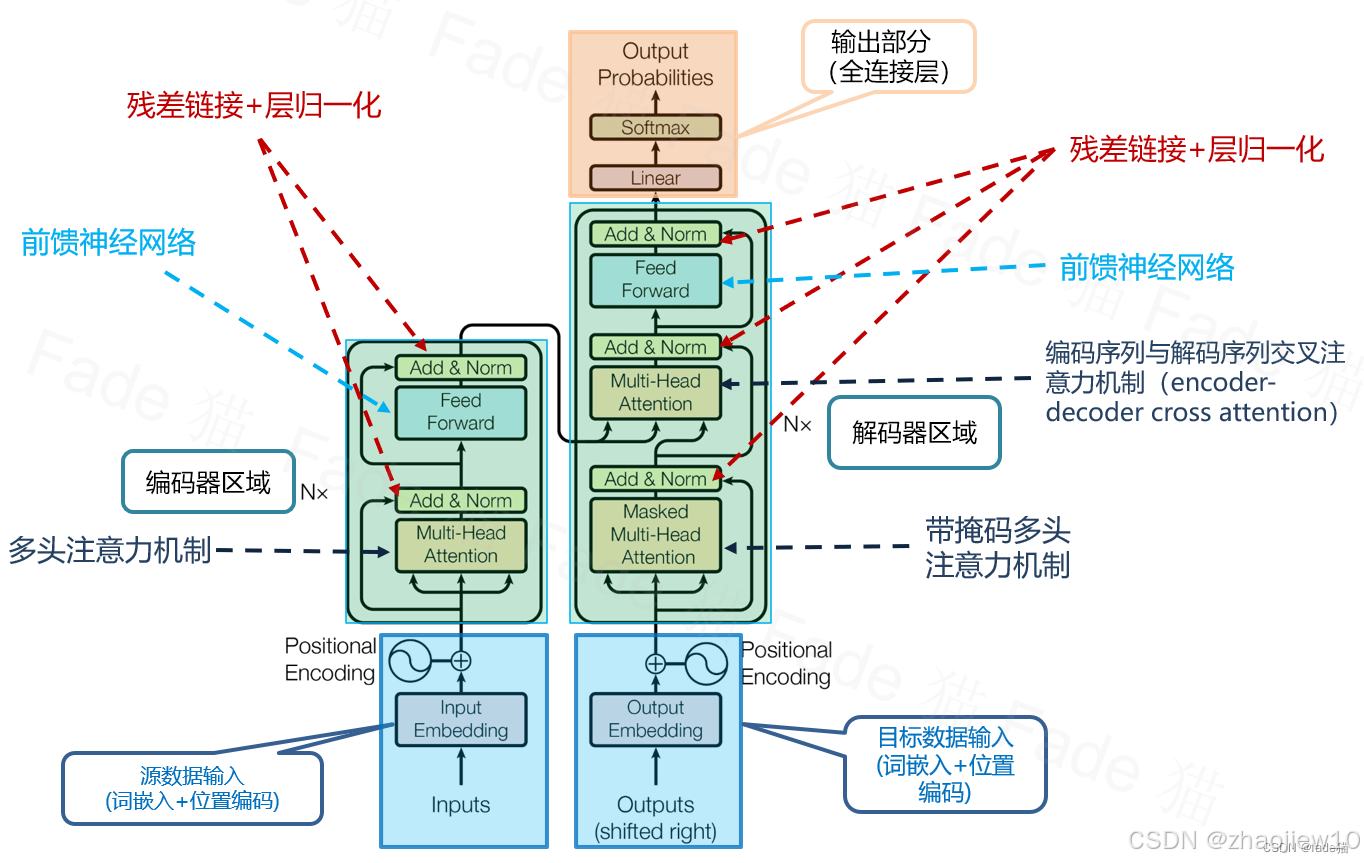
大家可以看到,它主要由兩大部分組成:編碼器和解碼器。
- 輸入的文本首先經過詞嵌入,變成向量表示,然后加上位置編碼,告訴模型每個詞在句子中的位置。
- 這些信息進入編碼器和解碼器,內部充滿了多層自注意力機制和前饋網絡,中間還穿插了殘差連接和層歸一化來穩定訓練。
- 解碼器的輸出經過線性變換和Softmax,得到最終的預測結果。
看起來復雜,但邏輯清晰。Transformer的核心思想是Seq2Seq,也就是序列到序列,這在機器翻譯、文本摘要等任務中很常見。它的任務是把一個輸入序列,比如英文句子,轉換成一個輸出序列,比如中文句子。Transformer的創新在于,它用編碼器和解碼器這兩個獨立模塊來完成這個任務。編碼器負責吃透輸入序列,把信息壓縮成一個濃縮的表示;解碼器則拿著這個表示,一步步生成輸出序列。最關鍵的是,它拋棄了RNN和LSTM那種一個詞一個詞慢慢處理的串行方式,轉而使用并行計算的注意力機制,這大大提升了效率。
注意力機制
注意力機制是Transformer的靈魂所在。它允許模型在處理一個詞時,不僅關注它本身,還能同時關注序列中其他所有詞,根據它們的重要性分配不同的權重。這就像我們閱讀時,會關注關鍵詞,忽略一些無關緊要的詞。Transformer內部有三種主要的注意力機制:
- 自注意力,讓模型在同一個序列內部,比如編碼器內部,自己跟自己對話,找出關聯;
- 多頭注意力,相當于開了多個視角,從不同角度觀察;
- 編碼器-解碼器注意力,讓解碼器能夠回頭看看編碼器處理過的輸入序列,獲取上下文信息。
我們先來看最核心的自注意力機制。它的核心思想是計算一個詞和序列中所有其他詞的關聯度。具體怎么做呢?
- 把每個詞的向量投影到三個空間:Q, K, V,分別代表查詢、鍵和值。
- 計算每個詞的查詢向量Q和所有詞的鍵向量K的相似度,用點積來衡量,再除以一個縮放因子,防止梯度爆炸,得到注意力分數。
- 用softmax函數把這些分數變成概率,也就是注意力權重,保證所有權重加起來等于1。
- 用這些權重去加權對應的值向量V,得到最終的上下文表示。
這個過程讓模型能同時看到所有詞,而不是像RNN那樣只能看一個詞。自注意力子層的內部結構中可以看到,核心是多頭自注意力模塊,它后面跟著一個Add & Norm層。這個Add & Norm層包含了殘差連接和層歸一化。殘差連接讓信息可以直接跳過幾層,避免信息丟失,還能加速訓練。層歸一化則是在每一層內部對數據進行歸一化,讓模型訓練更穩定,不容易過擬合。注意,編碼器和解碼器的自注意力子層略有不同,解碼器需要額外的后續掩碼,防止它在生成當前詞的時候,偷看未來的信息。
多頭注意力
一個注意力頭可能還不夠,就像看問題可能需要多角度思考一樣。所以,Transformer引入了多頭注意力機制。它把自注意力機制復制了多個,比如8個,每個頭都像一個獨立的觀察者,從不同的角度、不同的子空間去關注輸入序列。每個頭有自己的注意力權重,然后把所有頭的注意力結果拼接起來,再通過一個線性層整合,得到最終的輸出。這樣做的好處是,模型能同時捕捉到序列的局部和全局特征,表達能力大大增強。
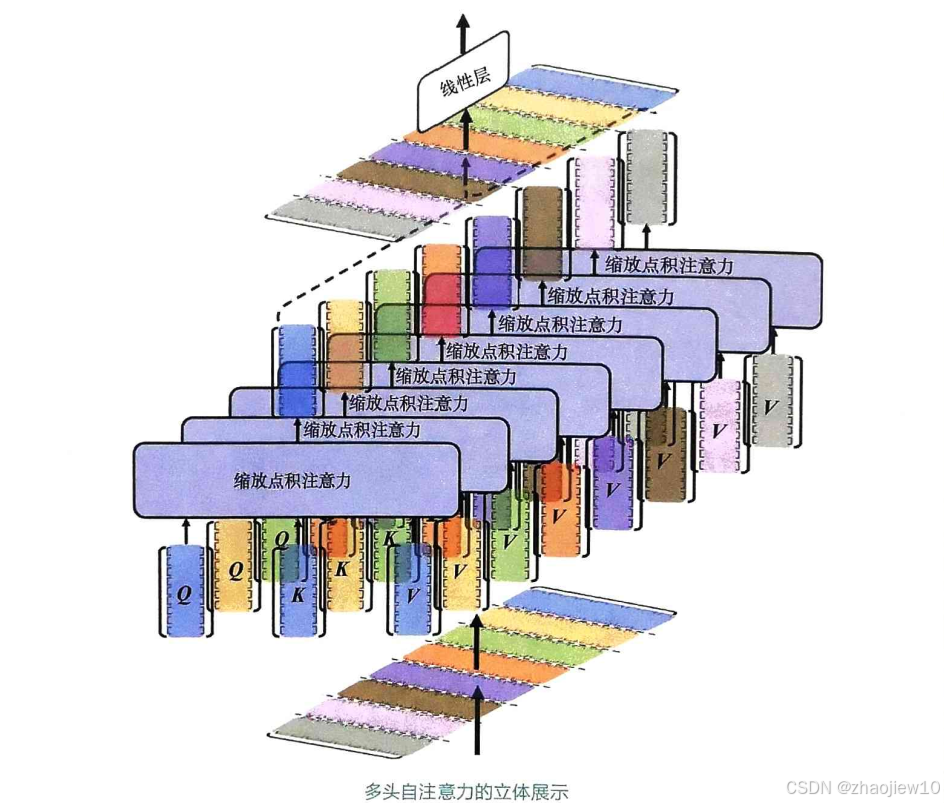
這張圖更直觀地展示了多頭注意力的工作原理。你可以看到多個并行處理的注意力頭,每個頭都處理著不同的輸入,計算出不同的注意力權重。這些權重被用來加權對應的值向量,然后所有頭的輸出被拼接在一起,最后通過一個線性層整合。這種多角度的并行處理方式,使得Transformer能夠處理非常復雜的信息,這也是它在處理長文本時表現出色的原因之一。
解碼器在生成目標序列的時候,不能只看它自己生成的,還得回頭看看輸入的源序列。這時候就需要編碼器-解碼器注意力機制。它的原理是:解碼器把自己當前的注意力狀態作為查詢,去問編碼器:輸入序列里,哪些詞跟我的當前狀態最相關?編碼器會給出回答,也就是用注意力權重來加權它的輸出向量。這樣,解碼器就能在生成每個詞的時候,都回顧一下輸入序列,確保翻譯或生成的內容是基于原始輸入的。
Transformer中的注意力掩碼和因果注意力。在注意力機制中,我們希望告訴模型,哪些信息是當前位置最需要關注的;同時也希望告訴模型,某些特定信息是不需要被關注的,這就是注意力掩碼的作用。
- 填充注意力掩碼(PaddingAttentionMask):當處理變長序列時,通常需要對較短的序列進行填充,使所有序列具有相同的長度,以便進行批量處理。填充的部分對實際任務沒有實際意義,因此我們需要使用填充注意力掩碼來避免模型將這些填充位置考慮進來。填充注意力掩碼用于將填充部分的注意力權重設為極小值,在應用softmax時,這些位置的權重將接近于零,從而避免填充部分對模型輸出產生影響。在Transformer的編碼器中,我們只需要使用填充注意力掩碼。
- 后續注意力掩碼(SubsequentAttentionMask),又稱前瞻注意力掩碼(Look-aheadAttentionMask):在自回歸任務中,例如文本生成,模型需要逐步生成輸出序列。在這種情況下,為了避免模型在生成當前位置的輸出時,
提前獲取未來位置的信息,需要使用前瞻注意力掩碼。前瞻注意力掩碼將當前位置之后的所有位置的注意力權重設為極小值,這樣在計算當前位置的輸出時,模型只能訪問到當前位置之前的信息,從而確保輸出的自回歸性質。在Transformer的解碼器中,不僅需要使用填充注意力掩碼,還需要使用后續注意力掩碼。
Transformer架構
現在我們來看看輸入是怎么進入Transformer的。
嵌入和位置編碼
首先是文本序列,比如一句話。第一步是詞嵌入,就是把每個詞變成一個固定長度的向量,比如512維。這個向量包含了這個詞的語義信息。
但是,Transformer是并行處理的,它不知道每個詞在句子中的位置。所以,第二步是添加位置編碼,給每個位置的詞向量加上一個表示位置信息的向量,這樣模型就能區分句子中不同位置的詞了。位置編碼是Transformer的一個關鍵創新點。因為RNN是按順序處理的,所以它天然知道哪個詞在前面哪個在后面。但Transformer是并行的,它需要顯式地告訴模型每個詞的位置。最常用的方法是正弦和余弦函數編碼。這種方法的好處是,它能平滑地表示位置,而且能保留相對位置信息,比如第i個詞和第i加1個詞的關系。當然,也有其他方法,比如讓模型自己學習位置編碼,但正弦編碼是原始論文中采用的。這個位置編碼就像給每個詞都貼上了一個坐標標簽。
編碼器
編碼器的內部結構非常規整,它是由多個完全相同的層堆疊起來的。每一層都包含兩個核心組件:
一個是多頭自注意力,另一個是前饋神經網絡。輸入的詞向量和位置編碼首先進入第一層的多頭自注意力,然后經過殘差連接和層歸一化。這個過程的輸出再進入前饋神經網絡,同樣經過殘差連接和層歸一化。這一層的處理完成后,結果進入下一層,重復這個過程。這種層層堆疊的設計,讓編碼器能夠逐步深入地提取輸入序列的特征,最終得到一個高質量的上下文表示。
我們再仔細看看這個多頭自注意力和Add & Norm層。多頭注意力負責并行計算,捕捉不同信息。Add & Norm層是關鍵,它包含了殘差連接和層歸一化。殘差連接保證了信息能夠順暢地傳遞下去,即使經過很多層,原始信息也不會丟失太多,還能加速梯度傳播,讓深層網絡更容易訓練。層歸一化則是在每一層內部穩定數據分布,讓模型訓練更穩定,不容易發散。這兩個技術的組合,是Transformer能夠構建深層網絡的基礎。
前饋神經網絡,簡稱FFN,是編碼器和解碼器層中的第二個關鍵組件。它的作用是對多頭注意力的輸出進行進一步的非線性變換,就像給信息做了一個更復雜的加工。通常是一個簡單的兩層網絡,中間夾著一個ReLU激活函數。特別注意的是,這里的前饋網絡是逐位置的,也就是對序列中的每個詞獨立地應用同一個FFN,而不是把整個序列展平了再處理。這樣保證了每個位置的處理是獨立的,不會互相干擾,也保持了序列的順序信息。
經過編碼器層層處理后,我們得到了一個輸出序列,這個序列里的每一個向量,都包含了它所代表的那個詞,以及它在整個輸入序列中的上下文信息。這個信息是通過注意力機制,特別是自注意力機制,從長距離的依賴關系中提取出來的。這個序列就是編碼器的最終成果,它將被傳遞給解碼器,作為解碼器生成目標序列的唯一依據。可以說,編碼器的質量,直接決定了整個Transformer模型的性能上限。
解碼器
解碼器的輸入有點特殊。它不僅要接收來自編碼器的信息,還要自己接收一部分目標序列。這個目標序列的接收方式,通常被稱為向右位移。這是什么意思呢?在訓練時,我們通常會用真實的答案來喂給解碼器,這就是所謂的教師強制。為了讓解碼器學會生成下一個詞,我們會把目標序列向右移動一位,然后在開頭補上一個起始符號,比如sos。比如,目標是I love you,那么解碼器的輸入就是sos I love you。這樣,解碼器在預測I的時候,能看到的是sos,預測love的時候能看到的是sos和I,以此類推,模擬了真實的生成過程。
解碼器的內部結構也和編碼器類似,是多層堆疊的。每一層主要包含三個部分
首先是解碼器自注意力,它處理的是解碼器自身的輸入序列,比如目標序列的前綴,而且這里必須使用后續掩碼,防止它偷看未來。
然后是編碼器-解碼器注意力,它把解碼器自注意力的結果作為查詢,去問編碼器:輸入序列里哪些詞跟我的當前狀態相關?
最后,同樣是一個前饋神經網絡,以及殘差連接和層歸一化。通過這些步驟,解碼器將編碼器的上下文信息和自身生成的序列信息結合起來。
解碼器自注意力層的作用,是讓解碼器在生成當前詞的時候,能夠回顧之前已經生成的詞序列。這非常關鍵,因為解碼器的輸出是逐步生成的,它必須記住之前生成了什么。為了實現這個,我們使用了后續掩碼。這個掩碼的作用是,當計算當前詞的注意力時,強制模型的注意力權重只落在之前生成的詞上,而對后面要生成的詞,權重接近于0。這樣就保證了生成過程的自回歸特性,模型在生成每個詞時,都是基于之前已知的信息。
編碼器-解碼器注意力層是連接編碼器和解碼器的橋梁。它的工作機制是,解碼器把自己的注意力狀態作為查詢,去問編碼器:輸入序列里,哪些詞跟我的當前狀態最相關?編碼器會給出回答,也就是用注意力權重來加權它的輸出。這樣,解碼器在生成每個詞的時候,就能同時考慮到輸入序列和它已經生成的詞序列。這使得它在生成目標序列時,能夠充分利用輸入信息,生成更準確、更符合語境的翻譯或摘要。
輸出層
解碼器經過所有層的處理后,會輸出一個序列,每個位置的輸出是一個向量,這個向量包含了詞匯表中所有詞的概率。為了得到最終的預測結果,我們還需要一個輸出層。這個輸出層通常由一個線性層和一個Softmax層組成。線性層負責把解碼器的輸出向量映射到詞匯表大小,得到每個詞的原始分數。
然后,Softmax函數把這些分數轉換成概率分布,保證所有概率加起來等于1。這樣,我們就能得到每個位置的詞,以及它在詞匯表中每個詞的概率。在實際應用中,比如機器翻譯,通常會選擇概率最高的那個詞作為最終的輸出。Transformer的應用遠不止于機器翻譯。它在文本摘要、文本分類、問答系統、命名實體識別等領域都取得了巨大的成功。
- 在文本摘要任務中,它可以生成簡潔的摘要;在文本分類任務中,它可以判斷情感傾向或主題類別;
- 在問答系統中,它能從文檔中找到答案。
- 甚至在計算機視覺、語音識別、推薦系統等領域,我們也看到了Transformer的身影。
可以說,Transformer已經成為一種通用的序列建模框架,其影響力還在不斷擴展。總結一下Transformer的優勢。
- 它最大的優勢就是能夠高效地處理長距離依賴,這得益于注意力機制。它擁有強大的表達能力,能夠捕捉到序列中復雜的模式。
- 它支持并行計算,大大提高了訓練和推理的效率
- 它具有良好的可擴展性,可以適應不同的任務和規模。
- 它的通用性很強,不僅在NLP領域,還在其他領域展現出強大的潛力
理論講完了,我們來看看如何將這些組件組裝起來,構建一個完整的Transformer模型。
參考附件,Transformer.ipynb
我們已經了解了transformer架構的起源、核心思想、關鍵組件以及內部結構。從注意力機制到多頭注意力,從位置編碼到掩碼機制,再到編碼器-解碼器的層層遞進,Transformer以其獨特的架構和強大的能力,徹底改變了NLP的研究格局。它不僅催生了BERT、GPT等一系列革命性模型,也深刻影響了整個AI領域的發展方向。可以說,Transformer是現代AI技術發展的一個重要里程碑。







)






)
)



)