文章目錄
- Pre
- 1. 引言
- 2. 緩沖概念與類比
- 3. Java I/O 中的緩沖實現
- 3.1 FileReader vs BufferedReader:裝飾者模式設計
- 3.2 BufferedInputStream 源碼剖析
- 3.2.1 緩沖區大小的權衡與默認值
- 4. 異步日志中的緩沖:Logback 異步日志原理與配置要點
- 4.1 Logback 異步日志原理
- 4.2 核心配置示例
- 4.2.1 三個關鍵參數
- 5. 緩沖區設計思路—同步 vs 異步
- 5.1 同步緩沖
- 5.2 異步緩沖
- 6. Kafka 生產者緩沖示例
- 6.1 Kafka 生產者緩沖原理
- 6.2 緩沖區丟數據風險
- 6.3 緩沖區過載與業務可用性
- 7. 其他緩沖場景與示例
- 8. 注意事項與異常場景
- 9. 小結

Pre
性能優化 - 理論篇:常見指標及切入點
性能優化 - 理論篇:性能優化的七類技術手段
性能優化 - 理論篇:CPU、內存、I/O診斷手段
性能優化 - 工具篇:常用的性能測試工具
性能優化 - 工具篇:基準測試 JMH
- 引言:重溫緩沖本質與設計動機;
- 緩沖概念與類比:蓄水池與生產線示例;
- Java I/O 中的緩沖實現:
3.1 FileReader vs BufferedReader,裝飾者模式設計;
3.2 BufferedInputStream 源碼剖析(fill() 邏輯與緩沖區擴容);
3.3 緩沖區大小的權衡與默認值(8KB); - 異步日志中的緩沖:Logback 異步日志原理與配置要點(queueSize、maxFlushTime、discardingThreshold);
- 緩沖區設計思路—同步 vs 異步:
5.1 同步緩沖:單線程或方法內批量觸發策略;
5.2 異步緩沖:生產者策略(拋棄/阻塞/異常)與多線程消費者的同步問題; - Kafka 生產者緩沖示例:batch.size、linger.ms 如何影響消息丟失與可用性;
- 其他緩沖場景與示例:StringBuilder/StringBuffer、操作系統網絡緩沖、數據庫 Buffer Pool、ID 生成器緩存;
- 注意事項與異常場景:緩沖區數據丟失風險、預寫日志與 WAL 簡述;
- 小結:緩沖區優化的收益與權衡;
1. 引言
在 性能優化 - 理論篇:性能優化的七類技術手段 中,已經初步了解“復用優化”領域下的兩大子方向:緩存(Cache) 與 緩沖(Buffer)。
接下來我們聚焦于“緩沖”這一個技術手段,深入理解它在 Java 語言與中間件中的各類應用場景,以及在設計時需要注意的權衡與異常處理。
為什么要用緩沖?
- 設備之間速度差異:CPU/內存讀寫速度?磁盤或網絡 I/O;
- 頻繁、小量的隨機 I/O 會導致尋道或上下文切換開銷巨大;
- 緩沖通過在內存中聚合數據,批量順序寫/讀,顯著提高吞吐。
接下來,將從概念、源碼、配置與設計思路幾個維度展開,對“緩沖”有一個系統化的認識。
2. 緩沖概念與類比
緩沖(Buffer)最本質的作用,是將“生產方”與“消費方”之間的不一致速度,化解為一個容量有限的“中間池”。
-
蓄水池比喻:
- 放水端(消費方):以恒定速率流出,就如程序中讀取緩沖區后進行處理;
- 進水端(生產方):速率不確定,可能快也可能慢,就如磁盤或網絡向緩沖寫數據;
- 緩沖區(蓄水池)大小:當進水過快或消費端處理慢時,水就會在池中積累;當池滿時,生產方必須等待或做其他處理。
-
包餃子流水線:
- 搟皮工序 vs 包餡工序,如果一搟一交彼此就停止,效率低;
- 加入一個盆子作為中間緩沖,搟皮不斷往盆里扔,包餡者隨時取用,兩者最大限度保持各自節奏。
從宏觀而言,Java 的堆本身也可視作一個“對象緩沖區”——應用線程在其中不斷分配對象,而垃圾回收線程(GC)則以另一種節奏“消費”這些對象。
對比于“緩存(Cache)”,緩沖側重于寫(或讀)過程中的批量與順序,讓慢速設備前端獲得“可持續的小幅流量”。
3. Java I/O 中的緩沖實現
在 Java 中,緩沖最常見的應用場景就是文件與網絡 I/O。底層設備(如磁盤、Socket)本身速度較慢,而 Java I/O 通過裝飾者模式,將原始流包裝為“帶緩沖的流”,讓單次 read()/write() 調用變為“先讀/寫到內存緩沖區,再批量交給底層設備”。
3.1 FileReader vs BufferedReader:裝飾者模式設計
-
FileReader:直接從磁盤逐個字符讀取,一次
read()需要:- 操作系統觸發文件系統尋道,讀取一個字節到內核緩沖;
- 再從內核緩沖拷貝到用戶空間;
- 返回給應用。
由于每調用一次
read()都要重復上述步驟,效率極低。 -
BufferedReader:以
Reader reader = new BufferedReader(new FileReader(path))方式包裝后:- 在首次
read()時,會一次性將后續buffer.length個字節(默認 8KB)讀入 Java 堆內存中的 byte[] buffer; - 之后的多次調用
read(),只需從內存buffer中讀取字符,直到pos >= count,才觸發下次fill(); - 大多數情況下,減少了對磁盤和內核空間的多次交互。
這種添加功能而不修改原類代碼的模式,就是裝飾者(Decorator)模式。
public class Demo {public int readWithoutBuffer(String path) throws IOException {int result = 0;try (Reader reader = new FileReader(path)) {int value;while ((value = reader.read()) != -1) {result += value;}}return result;}public int readWithBuffer(String path) throws IOException {int result = 0;try (Reader reader = new BufferedReader(new FileReader(path))) {int value;while ((value = reader.read()) != -1) {result += value;}}return result;} }- 如果將兩段代碼用 JMH 對比測試,后者在絕大多數文件大小與硬件環境下,都能以數倍乃至十數倍的速度勝出(未考慮 OS page cache)。
- 在首次
3.2 BufferedInputStream 源碼剖析
以 BufferedInputStream 為例,下面我們重點關注它的 read() 與 fill() 實現,理解緩沖區如何管理數據。
public synchronized int read() throws IOException {if (pos >= count) {fill();if (pos >= count)return -1;}return getBufIfOpen()[pos++] & 0xff;
}private void fill() throws IOException {byte[] buffer = getBufIfOpen();if (markpos < 0)pos = 0; /* no mark: throw away the buffer */else if (pos >= buffer.length) /* no room left in buffer */if (markpos > 0) { /* can throw away early part of buffer */int sz = pos - markpos;System.arraycopy(buffer, markpos, buffer, 0, sz);pos = sz;markpos = 0;} else if (buffer.length >= marklimit) {markpos = -1; /* buffer got too big, invalidate mark */pos = 0; /* drop buffer contents */} else if (buffer.length >= MAX_BUFFER_SIZE) {throw new OutOfMemoryError("Required array size too large");} else { /* grow buffer */int nsz = (pos <= MAX_BUFFER_SIZE - pos)? pos * 2 : MAX_BUFFER_SIZE;if (nsz > marklimit)nsz = marklimit;byte nbuf[] = new byte[nsz];System.arraycopy(buffer, 0, nbuf, 0, pos);buf = nbuf;buffer = nbuf;}count = pos;int n = getInIfOpen().read(buffer, pos, buffer.length - pos);if (n > 0)count = n + pos;
}
-
pos與count:pos:當前緩沖區已經消費到的位置索引;count:緩沖區中實際可用字節數(讀取自底層 InputStream)。
-
當
pos >= count時,調用fill():- 無 mark 邏輯:如果未在流上調用過
mark(),則直接pos = 0,丟棄舊緩沖區內容; - 有 mark 邏輯:如果調用過
mark()并且buffer尚未超過marklimit,會先將buffer[markpos, pos)部分拷貝到buffer[0, sz),保留標記區域;否則當buffer大小接近marklimit,會放棄緩存并重置markpos = -1。 - 緩沖區擴容:若
buffer.length < marklimit且pos >= buffer.length,則按pos*2或marklimit的大小擴容,以承載更多數據(最大不超過MAX_BUFFER_SIZE)。
- 無 mark 邏輯:如果未在流上調用過
-
從底層流讀取數據:
- 調用
getInIfOpen().read(buffer, pos, buffer.length - pos),一次性將盡量多的數據填入buffer[pos, buffer.length); - 讀取后把
count = pos + n,表示新的緩沖區可讀取字節數。 - 隨后
read()方法從內存buffer中依次提供單字節給調用者。
- 調用
這樣,絕大多數 reader.read() 調用都不會觸發一次真正的磁盤或網絡 I/O,而是走內存讀取,直到緩沖耗盡才會調用一次底層的 read(...)。
3.2.1 緩沖區大小的權衡與默認值
-
為什么不一次性把整個文件都讀到緩沖?
- 緩沖區太小時,需要頻繁地調用
fill(),失去緩沖效果; - 緩沖區太大,單次
fill()就涉及大量內存分配并可能導致垃圾回收壓力; - 默認緩沖區大小一般為 8192 字節(8KB),是工業界常見的折中值,既能減少單次
fill()帶來的系統調用開銷,又不會占用過多堆內存。
- 緩沖區太小時,需要頻繁地調用
-
調整緩沖區大小的思路:
- 對于小文件或小 HTTP 響應,可將緩沖區設置為 4KB 或更小,減少內存消耗;
- 對于大文件復制、視頻流處理等場景,可適當增大為 32KB 或 64KB,以減少 I/O 調用頻率;
- 但文件過大時,緩存整個文件到內存會導致 OOM,因此需結合實際業務與可用堆內存大小,謹慎配置。
4. 異步日志中的緩沖:Logback 異步日志原理與配置要點
在高并發服務中,同步日志會成為性能瓶頸:
- 每次調用
logger.info(...)都要先拼接日志消息,再調用底層 I/O 將文本寫入磁盤; - 如果并發量大,業務線程在等待磁盤 I/O 完成時被阻塞,整體延遲顯著增加;
- 即便日志輸出到控制臺,也會占用 CPU 時間來格式化。這時可以引入“異步日志”來解耦業務線程與磁盤寫入。
4.1 Logback 異步日志原理
Logback 的異步日志基于 AsyncAppender,其核心思路:
- 業務線程(生產者):調用
logger時,只需將待寫入的日志事件先放入內存中的阻塞隊列(ArrayBlockingQueue); - 異步 Worker 線程(消費者):在后臺單線程循環不斷地從隊列
poll()日志事件,然后批量地將它們寫入磁盤。
這樣,業務線程僅關心向緩沖隊列“放入”日志,I/O 寫入由獨立線程異步完成。
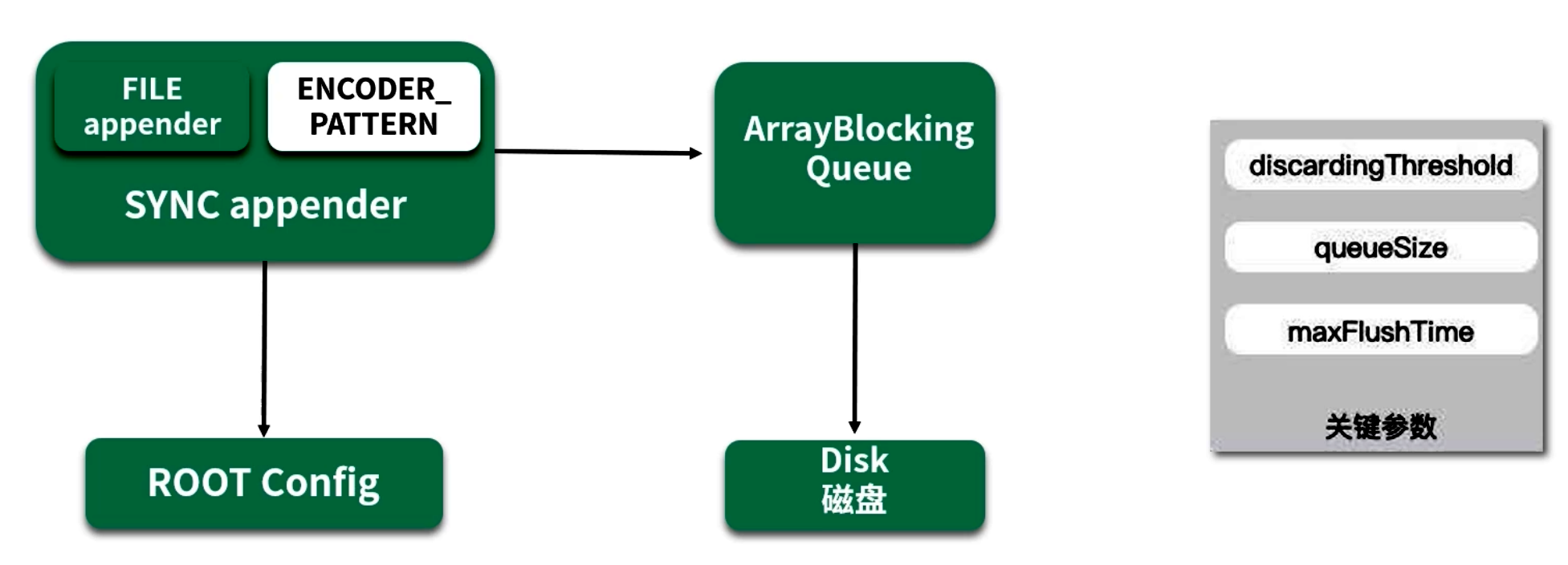
4.2 核心配置示例
在 logback.xml 中添加如下內容:
<!-- 定義一個 FileAppender,負責將日志寫入磁盤 -->
<appender name="FILE" class="ch.qos.logback.core.FileAppender"><file>app.log</file><encoder><pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder>
</appender><!-- 定義一個 AsyncAppender,將日志事件緩沖到隊列 -->
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender"><!-- 當隊列中的事件數量達到 discardingThreshold 時,可以丟棄低級別日志 --><discardingThreshold>0</discardingThreshold><!-- 隊列大小:最多容納 512 條事件 --><queueSize>512</queueSize><!-- 指定要異步包裝的目標 appender --><appender-ref ref="FILE"/>
</appender><root level="INFO"><!-- 使用異步日志器 --><appender-ref ref="ASYNC"/>
</root>
4.2.1 三個關鍵參數
-
queueSize(隊列容量):- 默認值為 256;當待寫入事件數量超過
queueSize時,生產者線程會根據discardingThreshold策略進行處理; - 如果設置過大,進程突然斷電,隊列內未落盤的日志全部丟失風險增大;
- 默認值為 256;當待寫入事件數量超過
-
discardingThreshold(丟棄閾值):- 取值范圍
0 <= discardingThreshold <= queueSize; - 當隊列長度 ≥
discardingThreshold時,低于或等于設定級別的日志事件可被丟棄,以保護高優先級日志; - 默認值為
queueSize × 0.8,即隊列達到 80% 時開始丟棄低級別日志;若設置為0,則不丟棄任何事件,但可能導致生產者阻塞或拋出異常;
- 取值范圍
-
maxFlushTime(關閉時最長等待時間):- 當應用優雅關閉時,
AsyncAppender會調用worker.join(maxFlushTime),等待后臺線程將剩余日志寫完; - 如果等待超時,應用仍會強制退出,此時緩沖區中未落盤的日志將丟失;
- 合理設置該值(如 5 秒或 10 秒),在性能與丟失風險之間權衡。
- 當應用優雅關閉時,
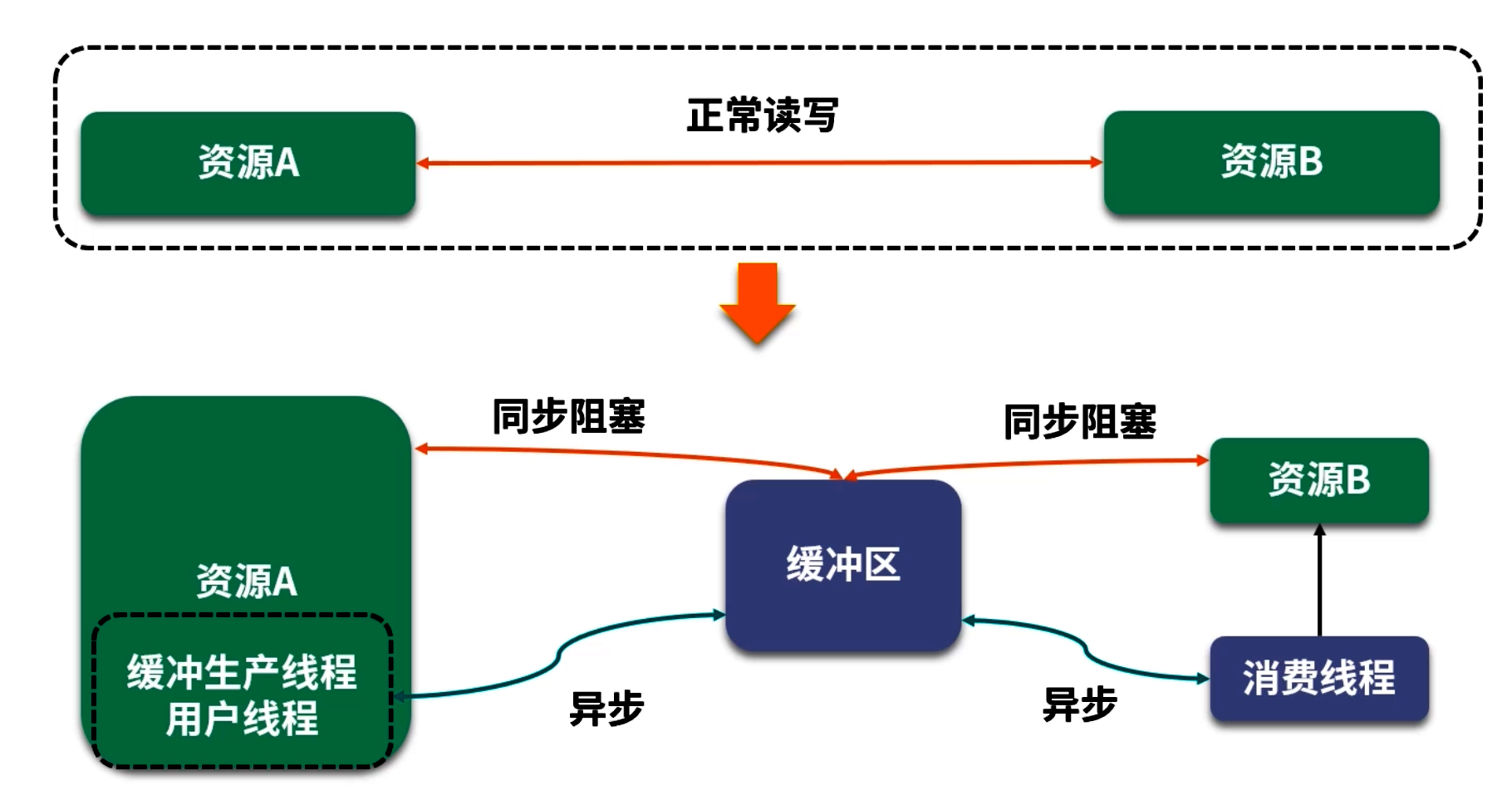
5. 緩沖區設計思路—同步 vs 異步
緩沖區優化常見于需要對“生產端”和“消費端”解耦的場景。但在設計時,需要考慮“同步緩沖”與“異步緩沖”兩種模式,取舍點在于編程模型復雜度與性能收益。
5.1 同步緩沖
-
模型示意:
生產者 →→ [緩沖區] →→ 消費者
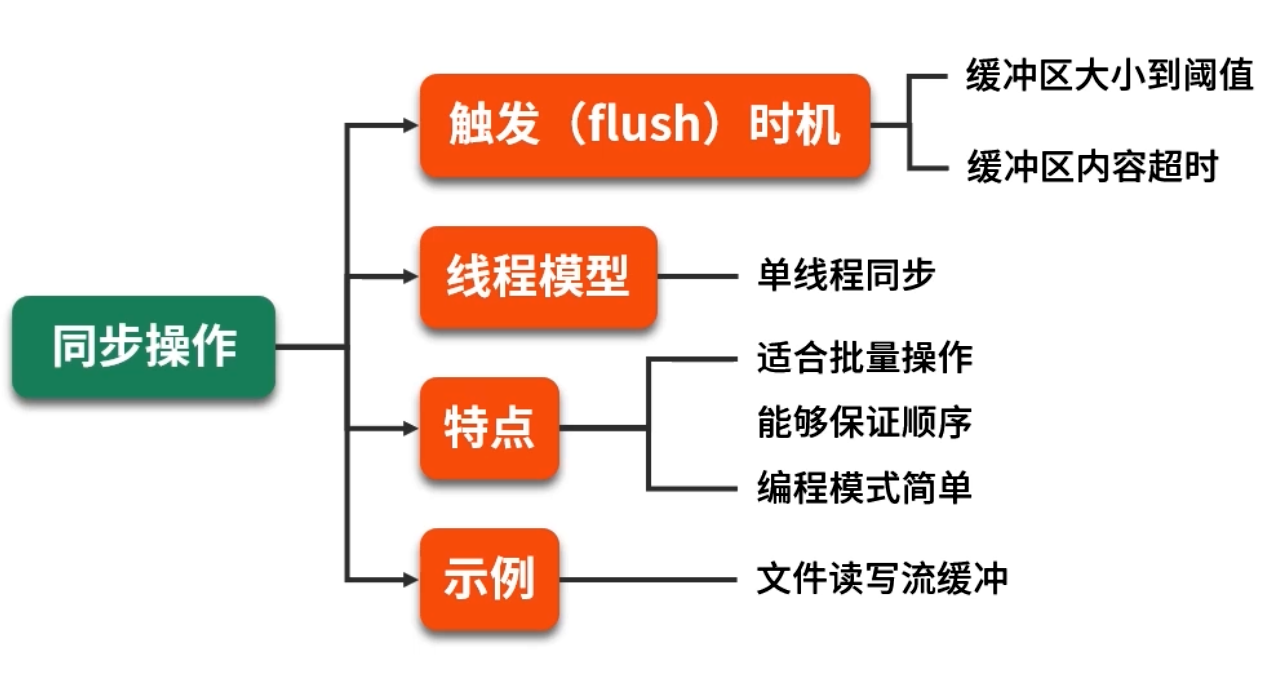
整個過程在同一個線程或調用鏈中執行。常見策略:
- 閾值觸發寫入:當緩沖區積累元素數量 ≥
flushThreshold,或累積字節數 ≥byteThreshold時,一次性批量寫入底層資源; - 定時觸發寫入:如果緩沖區在
maxIdleTime內未達到flushThreshold,則定時將已有數據寫出,保證高延遲數據得以及時消費;
-
優缺點:
- 優點:編程模型直觀、邏輯簡單,無額外線程;
- 缺點:當底層寫入耗時出現波動(如突發磁盤抖動),會阻塞生產者線程,導致整體響應能力下降。
-
示例:
- 字符串拼接時使用
StringBuilder,一次性將多次append()的結果通過toString()寫入磁盤; - JDBC 批量插入:在內存中將多條 SQL 語句緩存在
PreparedStatement中,達到batchSize時通過executeBatch()一次性寫入數據庫。
- 字符串拼接時使用
5.2 異步緩沖
-
模型示意:
生產者(線程 A) →→ [緩沖區(隊列)] →→ 消費者(后臺線程 B)
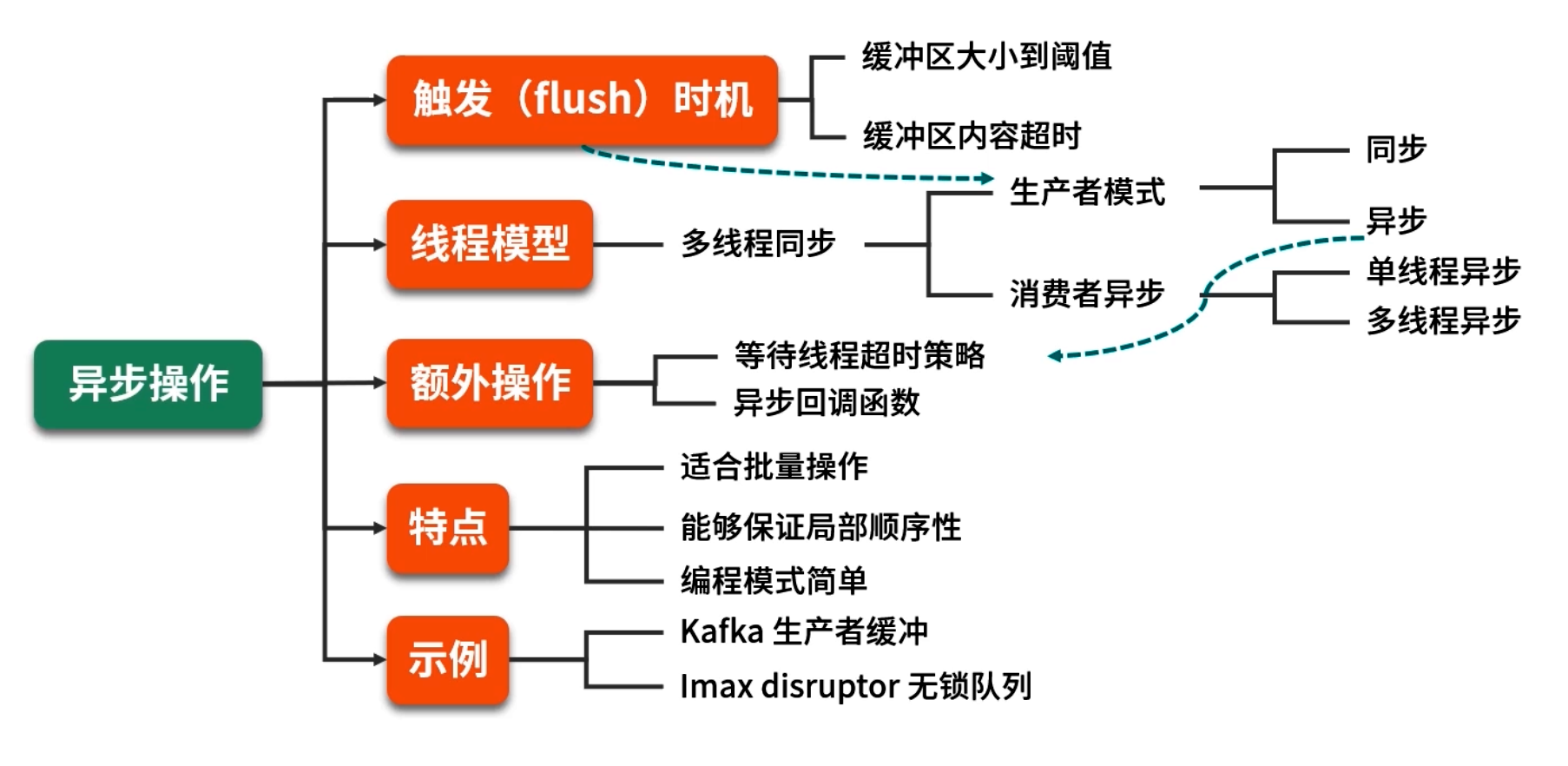
生產者僅負責往緩沖區寫入;消費者由獨立線程不斷從緩沖區讀取并寫出。
-
生產者策略:
- 阻塞:當隊列已滿,生產者調用
put()時會阻塞,直到有空位; - 非阻塞失敗:調用
offer(),若緩沖區已滿則返回false,讓上層邏輯根據返回值做重試或丟棄; - 異常拋出:直接在
put()或自定義方法中拋出RejectedExecutionException等,通知調用方“緩沖已滿”; - 回調機制:在生產者線程注冊回調,當數據真正被消費后才觸發,也可以用于跟蹤已消費數據。
- 阻塞:當隊列已滿,生產者調用
-
消費者設計:
- 啟動單線程或線程池,不斷從隊列
poll()數據; - 處理邏輯應考慮批量拉取,以減少 I/O 寫入次數,例如
drainTo(); - 若消費者處理速度不足,隊列會持續積壓;生產者需根據業務側容忍值判斷是否阻塞或快速失敗。
- 啟動單線程或線程池,不斷從隊列
-
多消費者與同步問題:
- 當緩沖區被多個消費者并發讀寫時,需要保證數據順序或一致性;
- 可使用有序隊列(如基于
BlockingQueue)或根據分區(Partition)分流; - 同時考慮多個消費者線程各自的吞吐能力與負載均衡。
6. Kafka 生產者緩沖示例
Kafka 生產者客戶端的“批量發送”與“緩沖區”設計。下面以常見參數 batch.size 與 linger.ms 為例,說明緩沖區對性能與可靠性的影響。
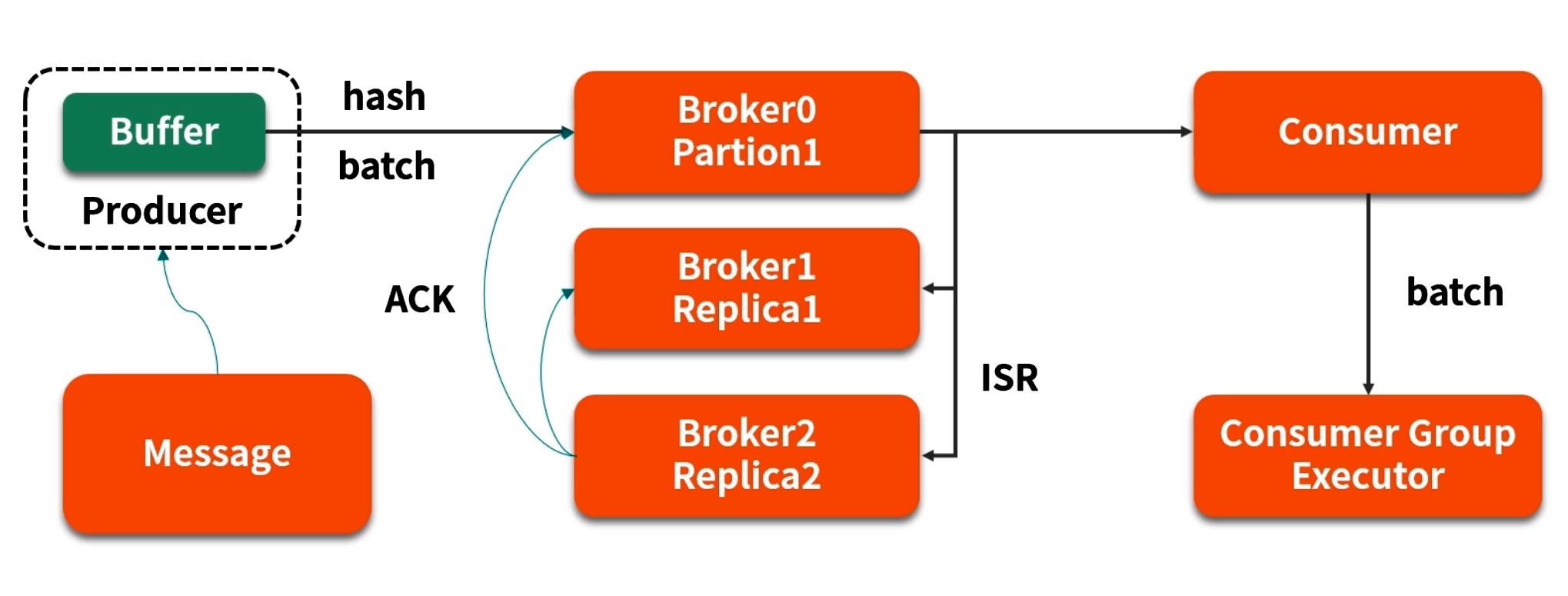
6.1 Kafka 生產者緩沖原理
- batch.size(字節):指定針對每個 partition 為單個批次消息設置的最大字節容量,默認為 16KB。當該容量被填滿后,生產者立即將該 batch 發送給對應的 broker。
- linger.ms(毫秒):指定“批次最大等待時間”,即在
batch.size未被填滿的情況下,生產者也會等待linger.ms后把已積累的消息強制發送,以減少每條消息都立刻網絡發送帶來的開銷。
具體流程:
- 當調用
producer.send(record)時,Kafka 生產者客戶端先把 record 序列化后放入對應 partition 的緩沖隊列(內存); - 如果當前 batch 的累積字節數 ≥
batch.size,則立即觸發發送; - 若
batch.size未滿,且當前時間超過linger.ms,也會把已累積消息發送; - 發送出發后會異步等待 broker ACK 確認或重試。
6.2 緩沖區丟數據風險
假設生產者程序發生以下情況:
- 機器突然斷電;
- JVM 進程被
kill -9殺死;
此時如果緩沖隊列中仍有尚未被 send() 到 Broker 或未獲 ACK 的消息,全部會丟失。默認情況下,緩沖區大小為 16KB,如果生產方業務持續產生大量消息,且 broker 短暫不可用,就會導致緩沖區快速填滿。
解決方案:
- 縮小
batch.size:使得緩沖隊列更頻繁地發送,雖然犧牲吞吐量,但可減少丟失概率; - 降低
linger.ms:即使在低流量情況下,也會在較短等待后發送,保證消息盡快到達 broker; - 開啟冪等性與 ACK 配置:設置
enable.idempotence=true并且acks=all,讓 broker 等待所有 ISR(in-sync replicas)確認后再 ACK,確保至少寫入一個副本或多副本; - 生產者寫入前落盤預寫日志:在生產者本地先記錄“即將發送的消息”,待發送成功后再刪除,重啟后可根據預寫日志補發;
- 使用電池或 UPS:在極端斷電場景下保證機器有足夠時間將緩沖持久化到磁盤。
6.3 緩沖區過載與業務可用性
當 broker 暫時不可用或網絡抖動時,生產者緩沖區會不斷積累消息,直至達到 buffer.memory(內存緩沖池)或達成 max.block.ms,此時默認行為是阻塞調用線程。若業務對等待較敏感,可能導致線程被長時間阻塞,最終耗盡線程池資源,從而引起整個服務不可用。
可選對策:
- 調整
max.block.ms:一旦超時則拋出TimeoutException告知調用方“消息積壓,發送超時”; - 限流策略:在業務層做流控(如令牌桶),防止短時間內壓入大量消息;
- 異步重試:將消息暫存在本地隊列或數據庫,后臺線程定時重試投遞;
7. 其他緩沖場景與示例
除了文件 I/O 與消息中間件,緩沖思想在常見的 Java 開發中無處不在:
-
StringBuilder / StringBuffer:
- 在 Java 中,頻繁使用
String做拼接會產生大量臨時對象; StringBuilder通過在內存中維護一個char[]緩沖,每次append()寫入緩沖中,最后一次性toString()時整體創建一個String,顯著提高拼接性能。
- 在 Java 中,頻繁使用
-
操作系統網絡緩沖(SO_SNDBUF / SO_RCVBUF):
- TCP Socket 在內核中會分配發送與接收緩沖區大小,可通過
socket.setSendBufferSize(...)/socket.setReceiveBufferSize(...)進行調優; - 適當增大操作系統緩沖區,可應對應用端瞬時突發流量,減少 packet drop;但過大會占用更多內核內存。
- TCP Socket 在內核中會分配發送與接收緩沖區大小,可通過
-
數據庫 InnoDB Buffer Pool:
- MySQL InnoDB 存儲引擎通過
innodb_buffer_pool_size配置,將數據頁和索引頁緩存在內存中,減少磁盤讀取; - 合理將
buffer_pool_size設置為物理內存的 60%~80%,能顯著提升查詢和寫入性能。
- MySQL InnoDB 存儲引擎通過
-
ID 生成器緩存:
- 常見的全局遞增 ID 生成,如 Twitter Snowflake 或數據庫自增 ID,為了減少每次網絡交互,往往將一段 ID(如 1000 個)一次性從數據庫或中央服務拉取到本地緩沖;
- 應用只需從本地緩沖取得下一個 ID,當耗盡后再異步從中央服務拉取下一段,減少延遲。
8. 注意事項與異常場景
雖然緩沖區能帶來明顯性能提升,但在設計時還要考慮以下幾方面的風險與權衡:
-
緩沖區數據丟失
- 突發斷電、
kill -9等強制銷毀進程時,緩沖區中的數據尚未落盤或未發送,全部丟失; - 對金融、訂單類等對數據可靠性要求極高的系統,可通過“先寫 WAL 日志再入緩沖”來保證數據不丟;
- 突發斷電、
-
緩沖區內存占用與 OOM
- 大容量緩沖區占用堆內存較大,可能導致垃圾回收壓力增大或堆內存不足;
- 需根據可用物理內存與業務吞吐量合理設置,如 8KB
64KB、512MB2GB 等;
-
順序與一致性問題
- 在多線程/多消費者場景下,若需要保證“消息順序”,必須使用單隊列或分區隊列;
- 對于都依賴同一緩存狀態的讀寫,需要在并發消費者之間做好狀態一致性或加鎖、防重入等處理;
-
性能收益遞減
- 緩沖區過小則頻繁交互;過大則內存占用過高;需要在吞吐與延遲之間做折中;
- 在高并發網絡場景,Socket / OS 層面也會加入多級緩沖,需要一體化考慮。
-
預寫日志與數據恢復
- 常見做法是在寫入緩沖前,先將關鍵元數據(例如 Kafka 消息 key)寫到本地磁盤日志;待緩沖數據真正被提交到 broker 后,再標記該日志為成功。重啟后掃描日志,補發未成功消息。
- 這種“先 WAL 后緩存”的策略會帶來額外寫盤開銷,需要衡量業務對丟失率的容忍度。
9. 小結
系統地探討了**緩沖(Buffer)**在 Java 語言與中間件中的典型應用:
-
緩沖本質與類比:
- 緩沖區是解耦生產者與消費者速度差異的內存“蓄水池”;
- 讓慢速設備接收“小而頻繁” → “大而順序” 的 I/O 請求,大幅提高吞吐。
-
Java I/O 緩沖實現:
BufferedReader/BufferedInputStream通過fill()方法一次性從底層流讀入 8KB(默認)數據到內存;- 通過
pos、count指針管理緩沖區消費位置;自動擴容至marklimit,在保證性能的同時兼容mark()/reset()。
-
異步日志緩沖:
- Logback
AsyncAppender將日志事件先緩存在ArrayBlockingQueue中,后臺線程異步寫入磁盤; - 重要參數:
queueSize(隊列容量)、discardingThreshold(丟棄閾值)、maxFlushTime(關閉時等待時間)。
- Logback
-
緩沖設計思路—同步 vs 異步:
- 同步緩沖:批量觸發策略簡單,但會阻塞生產者;
- 異步緩沖:解耦寫入與消費,需設計生產者滿載后的處理策略與多消費者同步。
-
Kafka 生產者緩沖示例:
- 通過
batch.size+linger.ms實現消息批量發送; - 緩沖區滿或超時觸發網絡發送,帶來吞吐與延遲權衡;
- 在斷電或
kill -9場景下,緩沖中消息或未獲 ACK 消息會丟失,可結合寫盤預寫日志或副本策略降低風險。
- 通過
-
其他緩沖場景:
StringBuilder/StringBuffer字符串拼接;- 操作系統 Socket 緩沖(SO_SNDBUF/SO_RCVBUF);
- 數據庫 InnoDB Buffer Pool;
- ID 生成器段緩存等。
-
注意事項與異常場景:
- 緩沖區丟失風險、內存占用風險;
- 順序一致性與并發讀寫沖突;
- 性能收益遞減點;
- WAL/預寫日志策略平衡可靠性與性能。
總之,緩沖區優化是 Java 性能優化中一項非常重要的技術手段,它既能顯著提高磁盤與網絡 I/O 吞吐,也帶來了異步設計下的編程復雜度與故障恢復挑戰。
在實際項目中,應結合業務對“數據丟失概率”與“延遲/吞吐”之間的容忍度,合理設置緩沖大小與處理策略。


Day13)

)

)





)
(A-D))






)