內容來自@浙大疏錦行python打卡訓練營
@浙大疏錦行
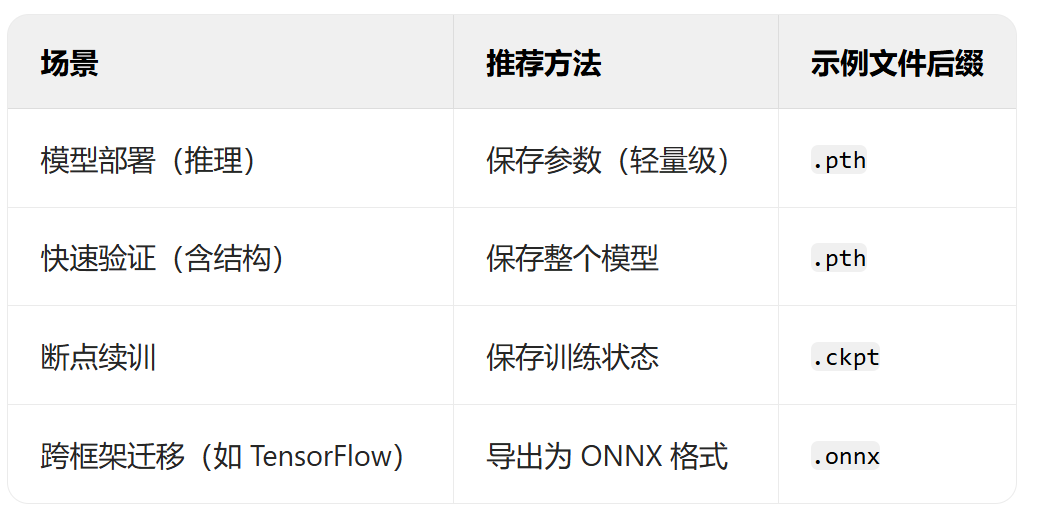
- 過擬合的判斷:測試集和訓練集同步打印指標
- 模型的保存和加載
- 僅保存權重
- 保存權重和模型
- 保存全部信息checkpoint,還包含訓練狀態
- 早停策略
我今天的筆記是用cpu訓練的,請自行修改為gpu訓練
仍然是循序漸進,先復習之前的代碼
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 導入tqdm庫用于進度條顯示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 加載鳶尾花數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 標簽數據# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 將數據轉換為PyTorch張量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 輸入層到隱藏層self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隱藏層到輸出層def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 實例化模型并移至GPU
model = MLP().to(device)# 分類問題使用交叉熵損失函數
criterion = nn.CrossEntropyLoss()# 使用隨機梯度下降優化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 訓練模型
num_epochs = 20000 # 訓練的輪數# 用于存儲每100個epoch的損失值和對應的epoch數
losses = []
epochs = []start_time = time.time() # 記錄開始時間# 創建tqdm進度條
with tqdm(total=num_epochs, desc="訓練進度", unit="epoch") as pbar:# 訓練模型for epoch in range(num_epochs):# 前向傳播outputs = model(X_train) # 隱式調用forward函數loss = criterion(outputs, y_train)# 反向傳播和優化optimizer.zero_grad()loss.backward()optimizer.step()# 記錄損失值并更新進度條if (epoch + 1) % 200 == 0:losses.append(loss.item())epochs.append(epoch + 1)# 更新進度條的描述信息pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 每1000個epoch更新一次進度條if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新進度條# 確保進度條達到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 計算剩余的進度并更新time_all = time.time() - start_time # 計算訓練時間
print(f'Training time: {time_all:.2f} seconds')# 可視化損失曲線
plt.figure(figsize=(10, 6))
plt.plot(epochs, losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.grid(True)
plt.show()# 在測試集上評估模型,此時model內部已經是訓練好的參數了
# 評估模型
model.eval() # 設置模型為評估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度計算,可以提高模型推理速度outputs = model(X_test) # 對測試數據進行前向傳播,獲得預測結果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和對應的索引#這個函數返回2個值,分別是最大值和對應索引,參數1是在第1維度(行)上找最大值,_ 是Python的約定,表示忽略這個返回值,所以這個寫法是找到每一行最大值的下標# 此時outputs是一個tensor,p每一行是一個樣本,每一行有3個值,分別是屬于3個類別的概率,取最大值的下標就是預測的類別# predicted == y_test判斷預測值和真實值是否相等,返回一個tensor,1表示相等,0表示不等,然后求和,再除以y_test.size(0)得到準確率# 因為這個時候數據是tensor,所以需要用item()方法將tensor轉化為Python的標量# 之所以不用sklearn的accuracy_score函數,是因為這個函數是在CPU上運行的,需要將數據轉移到CPU上,這樣會慢一些# size(0)獲取第0維的長度,即樣本數量correct = (predicted == y_test).sum().item() # 計算預測正確的樣本數accuracy = correct / y_test.size(0)print(f'測試集準確率: {accuracy * 100:.2f}%')
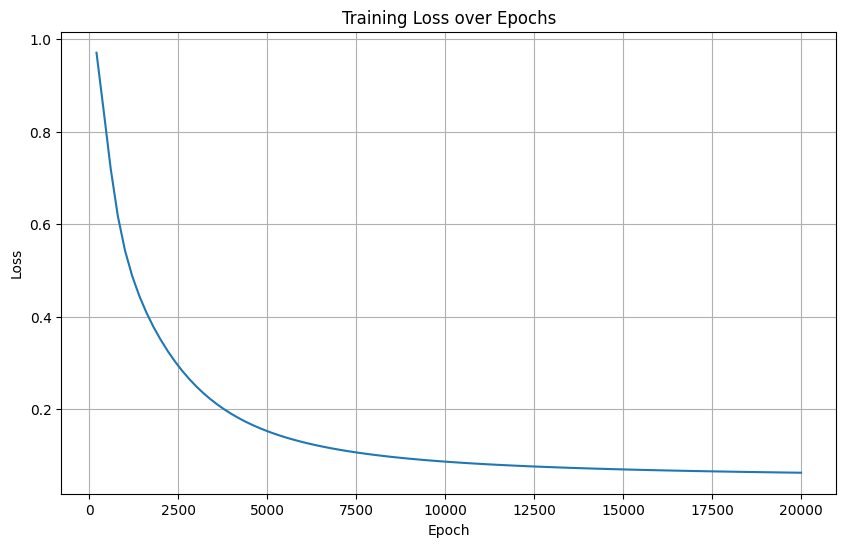
訓練集的loss在下降,但是有可能出現過擬合現象:模型過度學習了訓練集的信息,導致在測試集上表現不理想。
所以很自然的,我們想同步打印測試集的loss,以判斷是否出現過擬合現象。
過擬合的判斷
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 導入tqdm庫用于進度條顯示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 加載鳶尾花數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 標簽數據# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 將數據轉換為PyTorch張量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 輸入層到隱藏層self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隱藏層到輸出層def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 實例化模型并移至GPU
model = MLP().to(device)# 分類問題使用交叉熵損失函數
criterion = nn.CrossEntropyLoss()# 使用隨機梯度下降優化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 訓練模型
num_epochs = 20000 # 訓練的輪數# 用于存儲每200個epoch的損失值和對應的epoch數
train_losses = [] # 存儲訓練集損失
test_losses = [] # 新增:存儲測試集損失
epochs = []start_time = time.time() # 記錄開始時間# 創建tqdm進度條
with tqdm(total=num_epochs, desc="訓練進度", unit="epoch") as pbar:# 訓練模型for epoch in range(num_epochs):# 前向傳播outputs = model(X_train) # 隱式調用forward函數train_loss = criterion(outputs, y_train)# 反向傳播和優化optimizer.zero_grad()train_loss.backward()optimizer.step()# 記錄損失值并更新進度條if (epoch + 1) % 200 == 0:# 計算測試集損失,新增代碼model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新進度條的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# 每1000個epoch更新一次進度條if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新進度條# 確保進度條達到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 計算剩余的進度并更新time_all = time.time() - start_time # 計算訓練時間
print(f'Training time: {time_all:.2f} seconds')# 可視化損失曲線
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss') # 原始代碼已有
plt.plot(epochs, test_losses, label='Test Loss') # 新增:測試集損失曲線
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend() # 新增:顯示圖例
plt.grid(True)
plt.show()# 在測試集上評估模型,此時model內部已經是訓練好的參數了
# 評估模型
model.eval() # 設置模型為評估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度計算,可以提高模型推理速度outputs = model(X_test) # 對測試數據進行前向傳播,獲得預測結果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和對應的索引correct = (predicted == y_test).sum().item() # 計算預測正確的樣本數accuracy = correct / y_test.size(0)print(f'測試集準確率: {accuracy * 100:.2f}%') 
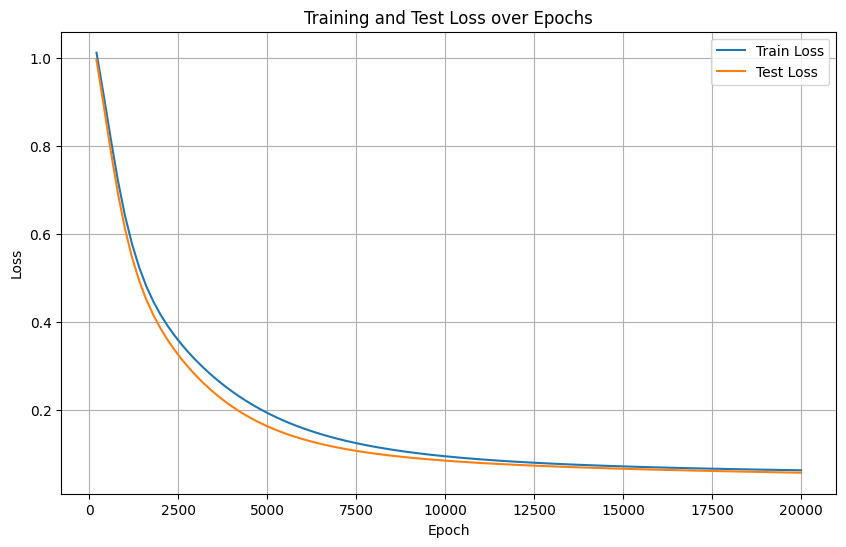
實際上,打印測試集的loss和同步打印測試集的評估指標,是一個邏輯,但是打印loss可以體現在一個圖中。
模型的保存和加載
深度學習中模型的保存與加載主要涉及參數(權重)和整個模型結構的存儲,同時需兼顧訓練狀態(如優化器參數、輪次等)以支持斷點續訓。
僅保存模型參數(推薦)
- 原理:保存模型的權重參數,不保存模型結構代碼。加載時需提前定義與訓練時一致的模型類。
- 優點:文件體積小(僅含參數),跨框架兼容性強(需自行定義模型結構)。
# 保存模型參數
torch.save(model.state_dict(), "model_weights.pth")# 加載參數(需先定義模型結構)
model = MLP() # 初始化與訓練時相同的模型結構
model.load_state_dict(torch.load("model_weights.pth"))
# model.eval() # 切換至推理模式(可選)![]()
保存模型+權重
- 原理:保存模型結構及參數
- 優點:加載時無需提前定義模型類
- 缺點:文件體積大,依賴訓練時的代碼環境(如自定義層可能報錯)
# 保存整個模型
torch.save(model, "full_model.pth")# 加載模型(無需提前定義類,但需確保環境一致)
model = torch.load("full_model.pth")
model.eval() # 切換至推理模式(可選)
保存訓練狀態(斷點續訓)
- 原理:保存模型參數、優化器狀態(學習率、動量)、訓練輪次、損失值等完整訓練狀態,用于中斷后繼續訓練。
- 適用場景:長時間訓練任務(如分布式訓練、算力中斷)。
# 保存訓練狀態
checkpoint = {"model_state_dict": model.state_dict(),"optimizer_state_dict": optimizer.state_dict(),"epoch": epoch,"loss": best_loss,
}
torch.save(checkpoint, "checkpoint.pth")# 加載并續訓
model = MLP()
optimizer = torch.optim.Adam(model.parameters())
checkpoint = torch.load("checkpoint.pth")model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
start_epoch = checkpoint["epoch"] + 1 # 從下一輪開始訓練
best_loss = checkpoint["loss"]# 繼續訓練循環
for epoch in range(start_epoch, num_epochs):train(model, optimizer, ...)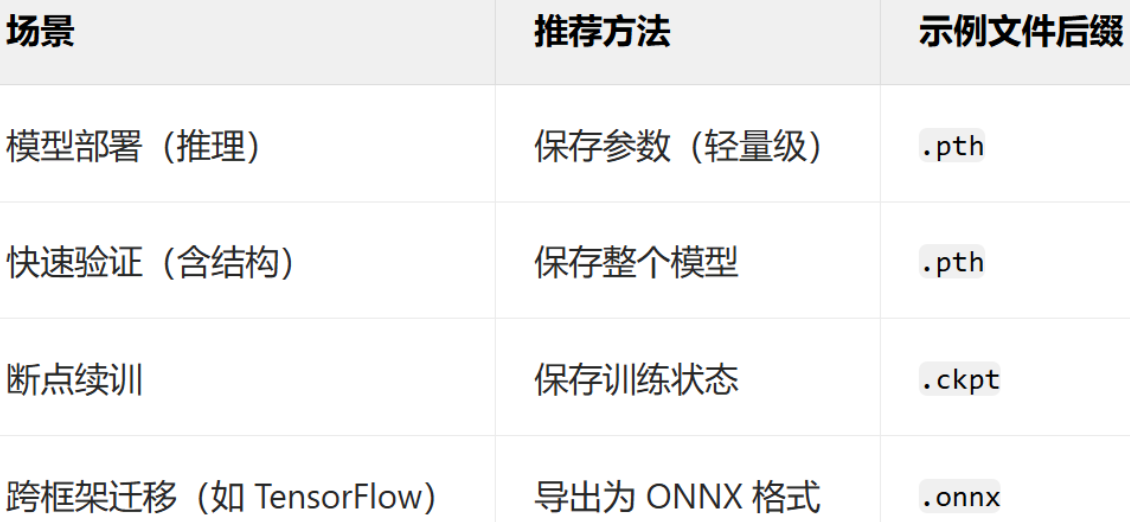
早停法(early stop)
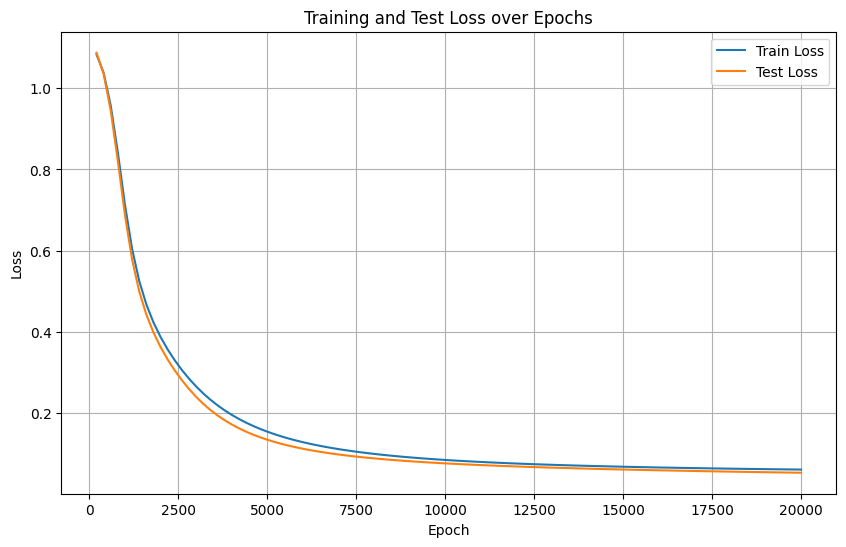
我們梳理下過擬合的情況
- 正常情況:訓練集和測試集損失同步下降,最終趨于穩定。
- 過擬合:訓練集損失持續下降,但測試集損失在某一時刻開始上升(或不再下降)。
如果可以監控驗證集的指標不再變好,此時提前終止訓練,避免模型對訓練集過度擬合。----監控的對象是驗證集的指標。這種策略叫早停法。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 導入tqdm庫用于進度條顯示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 加載鳶尾花數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 標簽數據# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 將數據轉換為PyTorch張量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 輸入層到隱藏層self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隱藏層到輸出層def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 實例化模型并移至GPU
model = MLP().to(device)# 分類問題使用交叉熵損失函數
criterion = nn.CrossEntropyLoss()# 使用隨機梯度下降優化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 訓練模型
num_epochs = 20000 # 訓練的輪數# 用于存儲每200個epoch的損失值和對應的epoch數
train_losses = [] # 存儲訓練集損失
test_losses = [] # 存儲測試集損失
epochs = []# ===== 新增早停相關參數 =====
best_test_loss = float('inf') # 記錄最佳測試集損失
best_epoch = 0 # 記錄最佳epoch
patience = 50 # 早停耐心值(連續多少輪測試集損失未改善時停止訓練)
counter = 0 # 早停計數器
early_stopped = False # 是否早停標志
# ==========================start_time = time.time() # 記錄開始時間# 創建tqdm進度條
with tqdm(total=num_epochs, desc="訓練進度", unit="epoch") as pbar:# 訓練模型for epoch in range(num_epochs):# 前向傳播outputs = model(X_train) # 隱式調用forward函數train_loss = criterion(outputs, y_train)# 反向傳播和優化optimizer.zero_grad()train_loss.backward()optimizer.step()# 記錄損失值并更新進度條if (epoch + 1) % 200 == 0:# 計算測試集損失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新進度條的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# ===== 新增早停邏輯 =====if test_loss.item() < best_test_loss: # 如果當前測試集損失小于最佳損失best_test_loss = test_loss.item() # 更新最佳損失best_epoch = epoch + 1 # 更新最佳epochcounter = 0 # 重置計數器# 保存最佳模型torch.save(model.state_dict(), 'best_model.pth')else:counter += 1if counter >= patience:print(f"早停觸發!在第{epoch+1}輪,測試集損失已有{patience}輪未改善。")print(f"最佳測試集損失出現在第{best_epoch}輪,損失值為{best_test_loss:.4f}")early_stopped = Truebreak # 終止訓練循環# ======================# 每1000個epoch更新一次進度條if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新進度條# 確保進度條達到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 計算剩余的進度并更新time_all = time.time() - start_time # 計算訓練時間
print(f'Training time: {time_all:.2f} seconds')# ===== 新增:加載最佳模型用于最終評估 =====
if early_stopped:print(f"加載第{best_epoch}輪的最佳模型進行最終評估...")model.load_state_dict(torch.load('best_model.pth'))
# ================================# 可視化損失曲線
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()# 在測試集上評估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'測試集準確率: {accuracy * 100:.2f}%') 
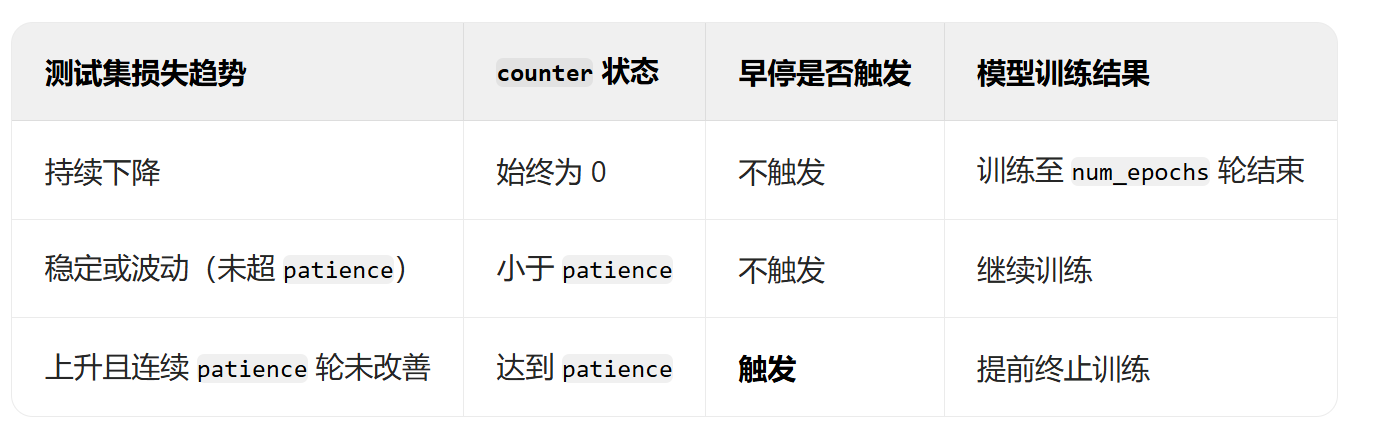
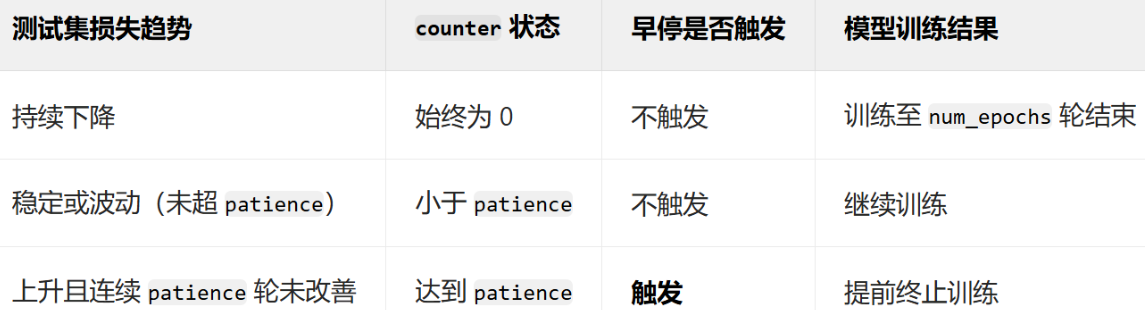
上述早停策略的具體邏輯如下
- 首先初始一個計數器counter。
- 每 200 輪訓練執行一次判斷:比較當前損失與歷史最佳損失。
? ? ? ?- 若當前損失更低,保存模型參數。
? ? ? ?- 若當前損失更高或相等,計數器加 1。
? ? ? ?- 若計數器達到最大容許的閾值patience,則停止訓練。
之所以設置閾值patience,是因為訓練過程中存在波動,不能完全停止訓練。同時每隔固定的訓練輪次都會保存模型參數,下次可以接著這里訓練,縮小訓練的范圍。
我這里之所以沒有觸發早停策略,有以下幾個原因:
1. 測試集損失在訓練中持續下降或震蕩,但未出現連續 patience 輪不改善
2. patience值過大,需要調小
實際上,在早停策略中,保存 checkpoint(檢查點) 是更優選擇,因為它不僅保存了模型參數,還記錄了訓練狀態(如優化器參數、輪次、損失值等),一但出現了過擬合,方便后續繼續訓練。


)


)
,VSCODE+Claude3.5+deepseek開發edge擴展插件V2)





:Proxy-Wasm Go SDK)



)

)
