五、基于深度學習的目標檢測代碼實現
5.1 開發環境搭建
開發基于深度學習的目標檢測項目,首先需要搭建合適的開發環境,確保所需的工具和庫能夠正常運行。以下將詳細介紹 Python、PyTorch 等關鍵開發工具和庫的安裝與配置過程。
Python 是一種廣泛應用于深度學習領域的高級編程語言,因其簡潔的語法、豐富的庫資源和強大的生態系統而備受青睞 。安裝 Python 時,建議前往 Python 官方網站(Welcome to Python.org?)下載最新版本的 Python 安裝包 。若使用 Windows 系統,下載完成后,雙擊安裝包啟動安裝程序 。在安裝界面中,務必勾選 “Add Python to PATH” 選項,此操作可將 Python 添加到系統環境變量中,使我們能夠在命令行中直接使用 Python 命令 。之后點擊 “Install Now” 開始安裝,安裝完成后點擊 “Close” 關閉安裝程序 。對于 macOS 系統,同樣雙擊下載的安裝包,按照提示完成安裝過程 。大多數 Linux 系統自帶 Python 解釋器,可在終端輸入 “python3 --version” 查看 Python 版本 。若未安裝 Python,在基于 Debian 的系統(如 Ubuntu)上,可使用命令 “sudo apt - get update” 更新軟件包列表,然后使用 “sudo apt - get install python3” 安裝 Python 。在基于 RHEL 的系統(如 CentOS)上,可使用 “sudo yum update” 更新軟件包,再使用 “sudo yum install python3” 進行安裝 。安裝完成后,在命令行(Windows)或終端(macOS 和 Linux)中輸入 “python” 或 “python3”(取決于系統和安裝版本),若能看到 Python 版本信息,如 “Python 3.9.7 (default, Sep 3 2021, 12:37:55)[Clang 11.0.0 (clang - 1100.0.33.17)] on darwin”,則說明 Python 已成功安裝 。
PyTorch 是一個基于 Python 的深度學習框架,提供了張量計算和深度神經網絡的構建、訓練等功能,在目標檢測領域有著廣泛的應用 。安裝 PyTorch 前,需根據自身的硬件條件(如是否有 NVIDIA GPU)和 Python 版本選擇合適的安裝命令 。若有 NVIDIA GPU 且已安裝 CUDA(Compute Unified Device Architecture),可前往 PyTorch 官網(PyTorch?),在 “Get Started” 頁面選擇相應的配置,如操作系統、包管理器(如 pip、conda)、PyTorch 版本、CUDA 版本等 。假設使用 pip 包管理器,Python 版本為 3.9,CUDA 版本為 11.3,可在命令行中輸入以下命令進行安裝:
| pip install torch torchvision torchaudio --extra - index - urls https://download.pytorch.org/whl/cu113 |
此命令將從指定的 URL 下載并安裝 PyTorch 及其相關庫 torchvision 和 torchaudio 。若沒有 NVIDIA GPU,可選擇安裝 CPU 版本的 PyTorch,在命令行中輸入:
| pip install torch torchvision torchaudio |
安裝過程中,pip 會自動下載并安裝所需的依賴項 。安裝完成后,可在 Python 環境中導入 PyTorch 進行測試,輸入以下代碼:
| import torch print(torch.__version__) |
若能正常輸出 PyTorch 的版本號,說明安裝成功 。
除了 Python 和 PyTorch,還需要安裝一些其他的依賴庫,以支持目標檢測項目的開發 。如 NumPy 是 Python 的一種開源的數值計算擴展庫,用于處理多維數組和矩陣運算,在深度學習中常用于數據處理和計算 。可使用 pip 命令安裝:
| pip install numpy |
OpenCV 是一個用于計算機視覺任務的庫,提供了豐富的圖像處理和計算機視覺算法,在目標檢測中常用于圖像的讀取、預處理和后處理等操作 。安裝命令如下:
| pip install opencv - python |
此外,根據所使用的目標檢測算法,還可能需要安裝其他特定的庫 。如使用 YOLO 系列算法,可能需要安裝一些與模型結構和訓練相關的庫 。在安裝這些庫時,需仔細閱讀官方文檔,確保安裝的庫版本與 Python 和 PyTorch 版本兼容 。在使用 yolov5 時,可能需要安裝一些特定的依賴庫,可通過克隆 yolov5 的 GitHub 倉庫,并在倉庫目錄下執行 “pip install - r requirements.txt” 命令來安裝所需的所有依賴庫 。
在搭建開發環境時,還可以使用一些集成開發環境(IDE)來提高開發效率 。PyCharm 是一款功能強大的 Python IDE,提供了代碼編輯、調試、版本控制等豐富的功能 。可前往 JetBrains 官網(PyCharm: The only Python IDE you need?)下載并安裝 PyCharm 。安裝完成后,打開 PyCharm,創建一個新的 Python 項目 。在項目設置中,可選擇之前安裝的 Python 解釋器,確保項目能夠正確引用所需的庫 。在項目開發過程中,PyCharm 的代碼智能提示和調試功能能夠幫助開發者快速定位和解決問題,提高開發效率 。
搭建一個完善的目標檢測開發環境需要正確安裝和配置 Python、PyTorch 以及其他相關依賴庫,并選擇合適的 IDE 。通過上述步驟,能夠確保開發環境的穩定性和兼容性,為后續的目標檢測算法實現和模型訓練奠定堅實的基礎 。
5.2 以 YOLOv5 為例的代碼實現
5.2.1 模型構建
YOLOv5 的網絡結構是其實現高效目標檢測的關鍵,通過代碼實現能夠深入理解其構建原理 。YOLOv5 的網絡結構主要包括輸入層(Input)、骨干網絡(Backbone)、頸部網絡(Neck)和頭部網絡(Head) 。輸入層負責接收圖像數據,通常將圖像進行預處理后輸入到網絡中 。骨干網絡用于提取圖像的基礎特征,頸部網絡對骨干網絡提取的特征進行進一步的處理和融合,頭部網絡則根據融合后的特征進行目標的分類和定位預測 。
在代碼實現中,首先需要定義各個網絡模塊 。以 PyTorch 框架為例,以下是定義骨干網絡中卷積模塊(Conv)的代碼示例:
|
在上述代碼中,Conv類繼承自nn.Module,定義了一個標準的卷積模塊 。__init__方法初始化了卷積層(nn.Conv2d)、批歸一化層(nn.BatchNorm2d)和激活函數 。forward方法定義了前向傳播過程,首先對輸入數據進行卷積操作,然后進行批歸一化處理,最后通過激活函數得到輸出 。forward_fuse方法則是在模型推理時進行融合操作,提高推理速度 。
骨干網絡中的 C3 模塊是 YOLOv5 的重要組成部分,其代碼實現如下:
|
C3 模塊包含多個卷積層和 Bottleneck 模塊 。__init__方法中,首先定義了三個卷積層cv1、cv2和cv3,以及一個由多個 Bottleneck 模塊組成的序列m?。forward方法將輸入數據x分別經過cv1和cv2卷積層處理,然后將cv1處理后的結果經過 Bottleneck 模塊序列m,最后將m的輸出和cv2的輸出在通道維度上進行拼接,再經過cv3卷積層得到最終輸出 。Bottleneck 模塊是一個標準的瓶頸結構,包含兩個卷積層cv1和cv2,并且在輸入和輸出維度相同且shortcut為True時,將輸入和卷積后的結果相加 。
SPPF(Spatial Pyramid Pooling - Fast)模塊也是骨干網絡的一部分,用于提高網絡對不同尺度目標的適應性,其代碼實現如下:
|
SPPF 模塊首先通過cv1卷積層對輸入數據進行降維,然后使用最大池化層m對降維后的數據進行多次池化操作,將不同尺度的特征進行融合,最后通過cv2卷積層得到最終輸出 。
頸部網絡中的 FPN(Feature Pyramid Network)和 PAN(Path Aggregation Network)模塊用于特征融合,以下是相關代碼示例:
|
FPN 模塊通過側向連接和上采樣操作,將不同尺度的特征圖進行融合,以增強對小目標的檢測能力 。__init__方法中定義了側向卷積層lateral_convs和輸出卷積層output_convs?。forward方法中,首先對輸入的不同尺度特征圖進行側向卷積,然后通過上采樣和逐元素相加的方式將高層特征圖與低層特征圖進行融合,最后經過輸出卷積層得到融合后的特征圖 。PAN 模塊則是在 FPN 的基礎上,通過下采樣和卷積操作進一步融合特征,增強對大目標的檢測能力 。__init__方法中定義了上采樣卷積層up_convs和下采樣卷積層down_convs?。forward方法中,通過上采樣、拼接和下采樣卷積操作,將不同尺度的特征圖進行進一步的融合 。
頭部網絡的 Detect 模塊負責目標的檢測,其代碼實現如下:
|
Detect 模塊根據輸入的特征圖進行目標檢測 。__init__方法中初始化了一些參數,如類別數nc、每個錨框的輸出維度no、檢測層數nl、錨框數na等 。還定義了輸出卷積層m,用于對輸入特征圖進行卷積操作,得到預測結果 。forward方法中,首先對每個檢測層的輸入特征圖進行卷積操作,然后將輸出的特征圖進行維度變換 。在推理階段,根據網格和錨框信息對預測結果進行解碼,得到目標的坐標、置信度和類別概率 。最后,將所有檢測層的結果進行拼接,返回最終的檢測結果 。
通過以上代碼實現,能夠構建出完整的 YOLOv5 網絡結構,為目標檢測任務提供強大的模型支持 。在實際應用中,可以根據具體需求對網絡結構進行調整和優化,以提高目標檢測的性能 。
5.2.2 數據加載與預處理
數據加載與預處理是目標檢測任務中的重要環節,直接影響模型的訓練效果和檢測性能 。在 YOLOv5 中,通過代碼實現高效的數據加載和豐富的數據預處理操作,能夠增強數據的多樣性,提高模型的泛化能力 。
數據加載部分,通常使用torch.utils.data.Dataset和torch.utils.data.DataLoader來構建數據加載器 。以下是定義自定義數據集類的代碼示例:
|
在上述代碼中,YOLODataset類繼承自Dataset,__init__方法初始化了圖像路徑列表img_paths、標簽路徑列表label_paths、圖像大小img_size和是否進行數據增強的標志augment?。__len__方法返回數據集的大小,即圖像的數量 。__getitem__方法根據索引idx加載對應的圖像和標簽 。首先使用cv2.imread讀取圖像,并將其從 BGR 格式轉換為 RGB 格式 。如果augment為True,則進行數據增強操作,如隨機水平翻轉和隨機裁剪 。然后將圖像調整大小為img_size,并進行歸一化處理,將像素值從 0 - 255 映射到 0 - 1 之間 。接著將圖像的通道維度調整到前面,并轉換為torch.Tensor類型 。對于標簽,首先使用np.loadtxt加載標簽數據,然后根據圖像大小對標簽中的邊界框坐標進行調整,最后將標簽轉換為torch.Tensor類型 。返回處理后的圖像和標簽 。
構建數據加載器的代碼如下:
5.3 代碼分析與結果展示
在完成 YOLOv5 的代碼實現并進行訓練后,對代碼運行結果進行深入分析以及直觀展示檢測效果和性能指標,有助于全面評估模型的性能,為進一步優化和應用提供依據。
通過運行訓練代碼,模型在訓練集上不斷學習和優化參數,以最小化損失函數。在訓練過程中,記錄損失值的變化情況是分析代碼運行結果的重要環節。通常,損失值會隨著訓練輪數的增加而逐漸減小,這表明模型在不斷學習并提高對目標的檢測能力 。可以使用 Python 的繪圖庫(如 Matplotlib)繪制損失曲線,橫坐標表示訓練輪數(Epoch),縱坐標表示損失值(Loss) 。在訓練初期,由于模型參數是隨機初始化的,對數據的擬合能力較差,損失值通常較高 。隨著訓練的進行,模型逐漸學習到數據中的特征和規律,損失值開始下降 。在某個訓練階段,損失值可能會趨于穩定,不再明顯下降,這可能表示模型已經收斂,達到了一個相對較好的性能狀態 。若損失值在訓練過程中出現波動甚至上升的情況,可能是由于學習率設置不當、數據增強過度或模型過擬合等原因導致的 。若學習率過大,模型在更新參數時可能會跳過最優解,導致損失值波動;若數據增強過度,可能會使模型學習到過多的噪聲信息,影響模型的收斂;若模型過擬合,會在訓練集上表現良好,但在驗證集上損失值較高,泛化能力較差 。
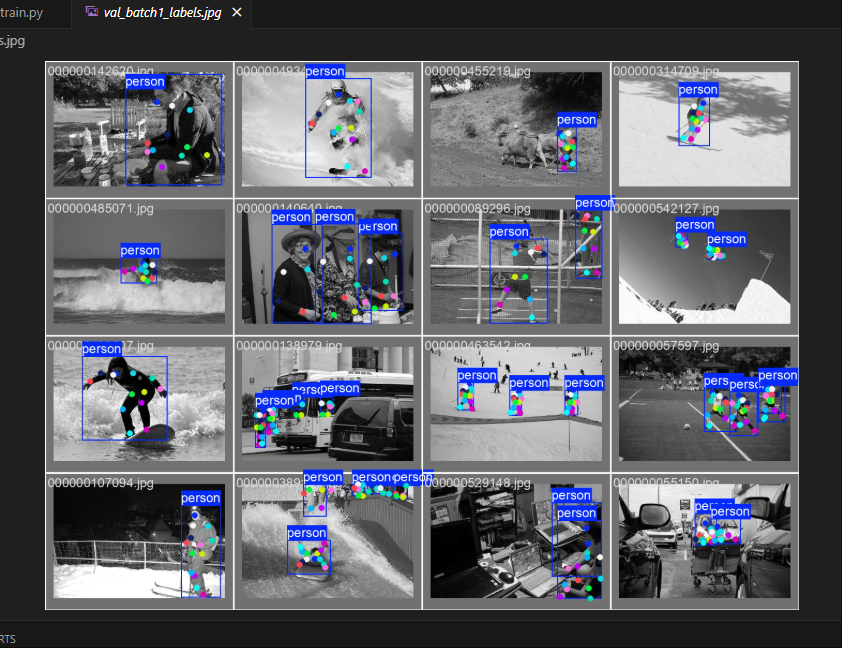
在測試階段,使用訓練好的模型對測試集進行檢測,得到檢測結果。可以通過可視化的方式展示檢測效果,以便直觀地觀察模型的性能 。對于圖像檢測結果,可以使用 OpenCV 庫將檢測到的目標邊界框繪制在原始圖像上,并標注出目標的類別和置信度 。對于一張包含行人、車輛的圖像,模型檢測到行人后,會在行人周圍繪制一個矩形邊界框,框的顏色可以根據類別進行區分,如行人用綠色框,車輛用紅色框 。在邊界框旁邊,標注出類別名稱(如 “person”“car”)和置信度數值(如 0.95) 。通過展示多張測試圖像的檢測結果,可以觀察模型在不同場景下對不同目標的檢測能力 。在復雜背景的圖像中,觀察模型是否能夠準確地檢測出目標,是否存在誤檢(將背景或其他物體誤判為目標)和漏檢(未檢測到實際存在的目標)的情況 。在光照條件變化較大的圖像中,評估模型對不同光照環境的適應性 。
為了定量評估模型的性能,需要計算一系列性能指標,如平均精度均值(mAP)、精確率(Precision)、召回率(Recall)和交并比(IoU)等 。使用相關的評估工具或自行編寫代碼來計算這些指標 。在 COCO 數據集的評估中,可以使用 COCO API 提供的評估函數來計算 mAP 等指標 。首先,將模型的檢測結果按照置信度從高到低進行排序 。然后,在不同的置信度閾值下,計算預測框與真實框的 IoU 。當 IoU 大于設定的閾值(如 0.5)時,認為檢測正確,是真正例(TP);否則為假正例(FP) 。根據 TP、FP 和假反例(FN)的數量,可以計算出精確率和召回率 。通過在不同置信度閾值下計算精確率和召回率,繪制精確率 - 召回率曲線(PR 曲線),進而計算出平均精度(AP) 。將所有類別的 AP 值求平均,得到 mAP 。在計算 mAP 時,通常會計算不同 IoU 閾值下的 mAP,如 mAP0.5(IoU 閾值為 0.5)和 mAP0.5:0.95(IoU 閾值從 0.5 到 0.95,步長為 0.05) 。mAP0.5主要衡量模型在寬松 IoU 閾值下的性能,而 mAP0.5:0.95則更全面地評估模型在不同 IoU 閾值下的性能,反映了模型對目標定位的精確程度 。
假設在某個目標檢測任務中,模型在測試集上的 mAP0.5為 0.85,mAP0.5:0.95為 0.78 。精確率在置信度閾值為 0.5 時為 0.8,召回率為 0.82 。這些指標表明模型在該任務中具有較好的性能,能夠準確地檢測出大部分目標,并且在目標定位上也有較高的精度 。但同時也可以看到,mAP0.5:0.95相對 mAP0.5略低,說明在更嚴格的 IoU 閾值下,模型的性能有所下降,可能在目標定位的精確性上還有提升空間 。通過對這些性能指標的分析,可以明確模型的優勢和不足,為后續的優化提供方向 。若精確率較低,可能需要調整模型的分類策略,如優化損失函數或調整置信度閾值;若召回率較低,則可能需要改進模型對目標的檢測能力,如優化特征提取網絡或增加訓練數據 。
六、目標檢測技術的應用領域與案例分析
6.1 自動駕駛中的目標檢測
在自動駕駛領域,目標檢測技術是實現車輛安全、高效行駛的核心關鍵技術之一,它如同車輛的 “眼睛”,賦予車輛對周圍環境的感知能力,使其能夠實時準確地識別交通標志、車輛和行人等各類目標,為后續的決策和控制提供至關重要的信息 。
交通標志的準確識別是自動駕駛系統安全運行的基礎保障 。交通標志包含了豐富的交通規則和指示信息,如限速標志、禁止通行標志、轉彎標志等 。自動駕駛車輛需要通過目標檢測技術,快速準確地識別這些交通標志,并根據標志信息做出相應的駕駛決策 。在實際應用中,深度學習算法被廣泛應用于交通標志檢測 。以卷積神經網絡(CNN)為例,它能夠自動學習交通標志的特征 。在訓練階段,大量不同類型、不同場景下的交通標志圖像被輸入到 CNN 中,網絡通過卷積層、池化層和全連接層的層層處理,提取出交通標志的獨特特征,如形狀、顏色和圖案等 。在識別限速標志時,CNN 可以學習到限速標志的圓形形狀、紅色邊框以及數字信息等特征 。通過對這些特征的學習和分析,CNN 能夠在實際行駛過程中,快速準確地識別出交通標志,并將其類別信息傳遞給自動駕駛系統的決策模塊 。當檢測到限速 60 的標志時,決策模塊會根據這一信息調整車輛的行駛速度,確保車輛在規定的速度范圍內行駛 。
車輛檢測在自動駕駛中起著至關重要的作用,它直接關系到車輛的行駛安全和交通效率 。自動駕駛車輛需要實時檢測周圍的車輛,包括前方、后方和側方的車輛,準確獲取它們的位置、速度和行駛方向等信息 。在復雜的交通場景中,車輛的類型、顏色和姿態各異,這對車輛檢測算法提出了很高的要求 。基于深度學習的目標檢測算法在車輛檢測方面表現出色 。以 Faster R - CNN 算法為例,它通過區域生成網絡(RPN)在圖像中生成可能包含車輛的候選區域,然后對這些候選區域進行特征提取和分類,準確地判斷出哪些區域包含車輛 。在高速公路場景下,Faster R - CNN 可以快速檢測到前方不同距離的車輛,并且能夠根據車輛的邊界框信息計算出車輛之間的距離和相對速度 。這些信息對于自動駕駛車輛的跟車、超車和避障等決策具有重要意義 。當檢測到前方車輛減速時,自動駕駛車輛可以根據距離和速度信息,及時調整自身的速度,保持安全的跟車距離 。
行人檢測是自動駕駛中的又一關鍵任務,由于行人的行為具有不確定性,且在不同場景下的外觀變化較大,行人檢測一直是目標檢測領域的挑戰之一 。在城市道路和居民區等場景中,行人的出現頻率較高,自動駕駛車輛必須能夠準確檢測到行人,避免發生碰撞事故 。深度學習算法在行人檢測中取得了顯著的成果 。YOLO 系列算法以其快速的檢測速度和較高的準確性,在行人檢測中得到了廣泛應用 。YOLOv5 通過對圖像進行一次前向傳播,直接預測出行人的邊界框和類別概率 。在復雜的城市街道場景中,YOLOv5 能夠快速檢測到不同姿態和穿著的行人,并且對遮擋情況下的行人也有一定的檢測能力 。為了提高行人檢測的準確性和魯棒性,一些算法還結合了多模態信息,如將攝像頭圖像與激光雷達點云數據進行融合 。激光雷達可以提供行人的三維位置信息,與攝像頭圖像中的二維信息相互補充,從而更準確地檢測和定位行人 。在夜間或低光照條件下,激光雷達能夠彌補攝像頭圖像的不足,提高行人檢測的可靠性 。
除了上述主要目標的檢測,自動駕駛中的目標檢測技術還涉及到對交通信號燈、道路邊界和障礙物等的檢測 。交通信號燈的檢測可以幫助自動駕駛車輛判斷何時停車、何時行駛,確保交通的順暢和安全 。道路邊界的檢測能夠幫助車輛保持在正確的車道內行駛,避免偏離車道 。障礙物檢測則可以及時發現道路上的異物、坑洼等,保障車輛的行駛安全 。隨著深度學習技術的不斷發展和創新,自動駕駛中的目標檢測技術將不斷提升,為實現完全自動駕駛奠定堅實的基礎 。未來,目標檢測技術有望在更復雜的交通場景中準確工作,如在惡劣天氣條件下(雨、雪、霧等)和復雜的城市道路環境中,實現對各類目標的可靠檢測 。結合更先進的傳感器技術和多模態信息融合方法,目標檢測的準確性和魯棒性將進一步提高,推動自動駕駛技術向更高水平發展 。
6.2 安防監控領域的應用
在安防監控領域,目標檢測技術發揮著舉足輕重的作用,它為公共安全提供了強有力的支持,能夠實現對人員行為的精準分析以及對入侵行為的及時檢測,有效提升了安防監控系統的智能化水平和安全性 。
在人員行為分析方面,目標檢測技術能夠實時監測視頻畫面中的人員動作和行為模式,通過對人員的姿態、動作、軌跡等特征的提取和分析,實現對異常行為的預警和識別 。在公共場所,利用目標檢測算法可以實時檢測人員是否存在摔倒、奔跑、斗毆等異常行為 。通過對人員骨骼關鍵點的檢測和分析,判斷人員是否摔倒 。當檢測到人員摔倒時,系統立即發出警報,通知相關人員及時處理,避免因無人發現而導致的嚴重后果 。在人群密集的場所,如商場、車站等,通過對人員軌跡的分析,可以監測人群的流動方向和密度變化 。當發現人群出現異常聚集或疏散時,系統能夠及時預警,幫助管理人員采取相應的措施,保障人員的安全 。還可以對人員的身份進行識別,結合人臉識別技術,在安防監控系統中實現對特定人員的追蹤和監控 。通過將目標檢測與人臉識別相結合,系統能夠在大量人群中快速準確地識別出目標人員,并實時追蹤其行動軌跡,為安防工作提供有力支持 。
入侵檢測是安防監控領域的另一重要應用場景 。目標檢測技術能夠對監控區域進行實時監測,及時發現非法入侵行為 。在重要設施、建筑物或園區的周邊,通過部署監控攝像頭,利用目標檢測算法對監控畫面進行實時分析 。當檢測到有未經授權的人員或物體進入設定的警戒區域時,系統立即觸發警報,通知安保人員進行處理 。在邊界安防監控中,通過對視頻圖像的分析,檢測是否有人員翻越圍欄、穿越警戒線等入侵行為 。利用目標檢測算法對邊界區域的視頻圖像進行實時處理,當檢測到異常目標進入邊界區域時,系統自動發出警報,并可聯動其他安防設備,如燈光、警笛等,對入侵行為進行威懾和警示 。還可以結合紅外傳感器等其他安防設備,提高入侵檢測的準確性和可靠性 。紅外傳感器可以檢測到人體發出的紅外信號,當有人員進入紅外探測范圍時,傳感器將信號傳輸給目標檢測系統,系統進一步分析視頻圖像,確認是否存在入侵行為 。通過這種多傳感器融合的方式,可以有效減少誤報率,提高安防監控系統的性能 。
在實際應用中,安防監控系統通常會部署多個攝像頭,覆蓋不同的區域和角度,以實現對監控場景的全面監測 。這些攝像頭采集的視頻數據會實時傳輸到后端的服務器或邊緣計算設備上,由目標檢測算法進行處理和分析 。為了提高檢測效率和實時性,通常會采用分布式計算或邊緣計算技術 。分布式計算將檢測任務分配到多個計算節點上并行處理,提高計算效率;邊緣計算則將部分計算任務在攝像頭附近的邊緣設備上完成,減少數據傳輸延遲,實現實時檢測 。在一個大型園區的安防監控系統中,部署了數十個攝像頭,通過分布式計算和邊緣計算技術,能夠實時對所有攝像頭采集的視頻數據進行目標檢測和分析,及時發現異常行為和入侵事件 。
目標檢測技術在安防監控領域的應用,不僅提高了安防工作的效率和準確性,還能夠實現對安全事件的提前預警和快速響應,為保障社會公共安全發揮了重要作用 。隨著目標檢測技術的不斷發展和創新,其在安防監控領域的應用前景將更加廣闊,有望為安防行業帶來更多的變革和提升 。
6.3 工業檢測與質量控制
在工業制造領域,目標檢測技術正發揮著越來越重要的作用,為產品質量控制和生產效率提升提供了強大的技術支持。通過對生產線上的產品進行實時檢測,目標檢測技術能夠快速、準確地識別產品缺陷、測量產品尺寸,確保產品符合質量標準,有效降低生產成本,提高企業的市場競爭力。
在產品缺陷檢測方面,目標檢測技術能夠自動識別產品表面的劃痕、裂紋、孔洞等各類缺陷。傳統的人工檢測方法不僅效率低下,而且容易受到人為因素的影響,難以保證檢測的準確性和一致性。而基于深度學習的目標檢測算法可以通過大量的缺陷樣本訓練,學習到不同類型缺陷的特征模式,從而實現對缺陷的精準檢測。在電子元件生產中,芯片表面的微小劃痕或孔洞可能會影響其性能和可靠性。利用目標檢測技術,通過對芯片圖像的分析,能夠快速檢測出這些缺陷,及時發現不合格產品,避免其流入下一道工序。在機械零部件制造中,目標檢測技術可以檢測出零部件表面的裂紋,這些裂紋在早期可能并不明顯,但隨著使用時間的增加,可能會導致零部件失效,引發嚴重的安全事故。通過目標檢測技術的實時監測,能夠及時發現這些潛在的安全隱患,保障產品的質量和使用安全。
尺寸測量是工業生產中的另一個重要環節,目標檢測技術為其提供了高精度、高效率的解決方案。在傳統的尺寸測量方法中,通常需要使用卡尺、千分尺等工具進行人工測量,這種方法不僅耗時費力,而且對于復雜形狀的產品測量難度較大。而基于目標檢測的尺寸測量技術,通過對產品圖像的分析,能夠快速、準確地測量產品的長度、寬度、高度等尺寸參數。在汽車制造中,對于車身零部件的尺寸精度要求極高,任何尺寸偏差都可能影響車身的裝配和性能。利用目標檢測技術,通過對車身零部件圖像的處理和分析,能夠精確測量其尺寸,確保零部件的尺寸符合設計要求。在航空航天領域,對于零部件的尺寸精度要求更加嚴格,目標檢測技術可以實現對航空零部件的高精度尺寸測量,為航空航天產品的質量提供有力保障。
為了實現高效準確的工業檢測與質量控制,目標檢測算法在工業場景中還需要進行針對性的優化。由于工業生產環境復雜,可能存在光照不均、噪聲干擾等問題,因此需要對算法進行優化,提高其對復雜環境的適應性。可以采用自適應光照補償算法,根據圖像的光照情況自動調整亮度和對比度,減少光照不均對檢測結果的影響。在圖像預處理階段,采用濾波算法去除噪聲,提高圖像的質量。針對工業產品的多樣性和特殊性,需要收集大量的樣本數據進行訓練,以提高算法的泛化能力和準確性。在訓練過程中,可以采用遷移學習、數據增強等技術,減少對大規模標注數據的依賴,提高模型的訓練效率和性能。
以某電子產品制造企業為例,該企業在生產過程中引入了基于目標檢測技術的質量檢測系統。該系統通過對生產線上的電子產品進行實時圖像采集和分析,能夠快速檢測出產品表面的劃痕、污漬、缺件等缺陷,以及零部件的尺寸偏差。在引入該系統之前,企業采用人工檢測的方式,檢測效率低,且漏檢率較高。引入目標檢測系統后,檢測效率提高了數倍,漏檢率大幅降低,產品質量得到了顯著提升。該系統還能夠對檢測數據進行實時統計和分析,為企業的生產管理提供數據支持,幫助企業優化生產流程,降低生產成本。
七、挑戰與展望
7.1 現存挑戰分析
盡管深度學習在目標檢測領域取得了顯著進展,但當前仍然面臨著諸多嚴峻挑戰,這些挑戰限制了目標檢測技術在更廣泛場景下的應用和性能提升。
實時性是目標檢測在許多實際應用中面臨的關鍵挑戰之一。在自動駕駛、實時監控等場景中,需要模型能夠快速處理大量的圖像或視頻數據,以滿足實時決策的需求 。然而,隨著模型復雜度的不斷增加,尤其是一些基于兩階段的目標檢測算法(如 Faster R - CNN),其在生成候選區域、特征提取和分類回歸等過程中需要進行大量的計算,導致檢測速度較慢,難以滿足實時性要求 。在自動駕駛場景中,車輛以較高速度行駛,需要在極短時間內檢測到前方的車輛、行人、交通標志等目標,若檢測速度過慢,可能導致車輛無法及時做出反應,引發交通事故 。即使是一些以速度見長的單階段檢測算法(如 YOLO 系列),在處理高分辨率圖像或復雜場景時,檢測速度也會受到一定影響 。當圖像分辨率較高時,模型需要處理的數據量大幅增加,計算時間相應延長,從而影響實時性 。在復雜的城市交通場景中,存在大量的目標和背景干擾,模型需要花費更多時間進行特征提取和判斷,導致檢測速度下降 。
小目標檢測一直是目標檢測領域的難點問題 。小目標在圖像中所占像素較少,特征信息不明顯,容易被模型忽略或誤檢 。小目標的特征相對較弱,難以與背景噪聲區分開來,使得模型在提取小目標特征時面臨較大困難 。在遙感圖像中,一些小型建筑物、車輛等目標由于距離較遠,在圖像中表現為很小的像素區域,其邊緣、紋理等特征模糊,模型很難準確提取這些小目標的有效特征 。小目標的上下文信息有限,模型難以利用周圍環境信息來輔助檢測 。在自然場景圖像中,小目標周圍的背景可能非常復雜,且與小目標本身的相關性較弱,模型難以通過上下文推理來準確檢測小目標 。現有的目標檢測算法在設計時,往往更側重于對大目標的檢測,對小目標的檢測能力相對不足 。一些基于特征金字塔網絡(FPN)的算法雖然在一定程度上提高了小目標檢測性能,但仍無法完全解決小目標檢測的難題 。FPN 通過融合不同尺度的特征圖來增強對小目標的檢測能力,但在實際應用中,由于小目標特征在不同尺度特征圖中的分布不均勻,以及特征融合過程中的信息損失,小目標檢測效果仍有待提高 。
算法復雜度是限制目標檢測技術在資源受限設備上應用的重要因素 。深度學習模型通常包含大量的參數和復雜的計算操作,這使得模型的訓練和推理需要消耗大量的計算資源和內存 。在移動設備、嵌入式系統等資源受限的環境中,硬件的計算能力和內存容量有限,難以支持復雜的深度學習模型運行 。一些高端智能手機雖然具備一定的計算能力,但在運行復雜的目標檢測模型時,仍然會出現卡頓、發熱等問題,影響用戶體驗 。降低算法復雜度往往會導致模型性能的下降,如何在保證模型性能的前提下,有效降低算法復雜度,是當前目標檢測領域亟待解決的問題 。在模型壓縮和加速過程中,采用剪枝、量化等技術雖然可以減少模型的參數數量和計算量,但可能會導致模型精度下降,影響目標檢測的準確性 。在使用剪枝技術時,若裁剪掉過多的重要連接或神經元,可能會破壞模型的特征提取能力,導致模型對目標的檢測能力降低 。
遮擋問題也是目標檢測面臨的一大挑戰 。當目標被部分或完全遮擋時,其可見部分的特征信息不完整,模型難以準確識別和定位目標 。在遮擋情況下,目標的部分關鍵特征被遮擋,模型無法獲取完整的目標特征,容易導致誤檢或漏檢 。在人群密集場景中,行人之間相互遮擋的情況較為常見,模型可能會將被遮擋的行人誤判為其他物體,或者完全漏檢被遮擋的行人 。遮擋還會導致目標之間的空間關系發生變化,增加了模型理解場景的難度 。在交通場景中,當車輛被其他車輛或障礙物遮擋時,模型不僅要檢測出被遮擋的車輛,還要準確判斷其與周圍其他目標的位置關系,這對模型的推理能力提出了更高的要求 。目前,雖然有一些方法嘗試通過多模態信息融合(如結合可見光圖像和紅外圖像)或上下文推理來解決遮擋問題,但在復雜遮擋情況下,檢測性能仍然有待提高 。在多模態信息融合中,不同模態數據之間的配準和融合難度較大,且在某些情況下,紅外圖像等輔助模態數據也可能受到遮擋的影響,無法提供有效的信息補充 。
類別不平衡問題在目標檢測數據集中普遍存在,即不同類別的樣本數量差異較大 。在這種情況下,模型在訓練過程中會傾向于學習數量較多的類別,而對數量較少的類別關注不足,導致對少數類別的檢測性能較差 。在工業缺陷檢測中,正常產品的樣本數量往往遠遠多于缺陷產品的樣本數量,模型在訓練時容易過度擬合正常樣本的特征,而對缺陷樣本的特征學習不夠充分,從而在檢測缺陷產品時出現較高的漏檢率和誤檢率 。類別不平衡還會導致模型的決策邊界偏向多數類,使得少數類樣本更容易被誤分類 。在自然場景圖像中,背景類別的樣本數量通常較多,而一些稀有類別的樣本數量較少,模型在判斷稀有類別樣本時,容易將其誤判為背景 。雖然已經提出了一些方法來緩解類別不平衡問題,如過采樣少數類、欠采樣多數類、調整損失函數權重等,但這些方法在實際應用中仍然存在一定的局限性 。過采樣可能會導致模型過擬合少數類樣本,欠采樣則可能丟失多數類樣本的一些重要信息,而調整損失函數權重的方法需要根據具體數據集進行大量的實驗和調參,且效果也受到數據集特性的影響 。
6.1 自動駕駛中的目標檢測
在自動駕駛領域,目標檢測技術是實現車輛安全、高效行駛的核心關鍵技術之一,它如同車輛的 “眼睛”,賦予車輛對周圍環境的感知能力,使其能夠實時準確地識別交通標志、車輛和行人等各類目標,為后續的決策和控制提供至關重要的信息 。
交通標志的準確識別是自動駕駛系統安全運行的基礎保障 。交通標志包含了豐富的交通規則和指示信息,如限速標志、禁止通行標志、轉彎標志等,車輛必須及時、準確地識別這些標志,才能遵守交通規則,確保行駛安全 。深度學習在交通標志檢測中發揮著重要作用,基于卷積神經網絡(CNN)的目標檢測算法能夠自動學習交通標志的特征,實現高精度的檢測 。MobileNet - SSD 算法結合了 MobileNet 輕量級網絡結構和 SSD 目標檢測框架,在保證一定檢測精度的同時,大大減少了計算量,提高了檢測速度,非常適合在資源受限的車載設備上運行 。在實際應用中,自動駕駛車輛通過攝像頭獲取道路圖像,將圖像輸入到基于 MobileNet - SSD 的交通標志檢測模型中,模型能夠快速準確地檢測出圖像中的交通標志,并識別其類型和含義 。當檢測到限速 60 的標志時,車輛的控制系統會根據這一信息調整行駛速度,確保車輛在規定的速度范圍內行駛 。
車輛檢測是自動駕駛中的另一項關鍵任務,它對于避免碰撞、保持安全車距以及實現高效的交通流控制至關重要 。在復雜的交通場景中,車輛檢測算法需要能夠準確地識別不同類型的車輛,包括轎車、卡車、公交車等,并實時跟蹤它們的位置和運動狀態 。Faster R - CNN 算法通過區域生成網絡(RPN)快速生成候選區域,并利用卷積神經網絡對候選區域進行特征提取和分類,在車輛檢測中表現出了較高的精度和魯棒性 。一些自動駕駛系統采用多傳感器融合的方式,將攝像頭圖像與激光雷達點云數據相結合,進一步提高車輛檢測的準確性和可靠性 。激光雷達能夠提供車輛周圍環境的三維信息,與攝像頭的二維圖像信息互補,能夠更準確地檢測出車輛的位置和距離 。在實際行駛過程中,自動駕駛車輛通過攝像頭和激光雷達獲取周圍環境信息,利用 Faster R - CNN 算法對攝像頭圖像進行車輛檢測,同時結合激光雷達點云數據進行驗證和補充,從而實現對周圍車輛的精確檢測和跟蹤 。當檢測到前方車輛減速時,自動駕駛車輛能夠及時做出反應,減速或保持安全距離 。
行人檢測在自動駕駛中同樣具有重要意義,因為行人的行為具有不確定性,容易引發交通事故 。自動駕駛系統需要能夠快速、準確地檢測到行人,并預測他們的行為,以便及時采取制動或避讓措施 。YOLO 系列算法以其快速的檢測速度和較高的檢測精度,在行人檢測中得到了廣泛應用 。例如,YOLOv5 通過優化網絡結構和訓練策略,能夠在復雜的城市交通場景中快速檢測出行人 。一些先進的行人檢測算法還結合了人體姿態估計和行為分析技術,不僅能夠檢測出行人,還能預測行人的行走方向和速度,為自動駕駛車輛的決策提供更全面的信息 。在行人密集的路口,自動駕駛車輛通過 YOLOv5 算法檢測出行人,并利用人體姿態估計技術分析行人的行走方向和速度,從而提前做好減速或避讓的準備,確保行人的安全 。
以特斯拉的 Autopilot 自動駕駛輔助系統為例,該系統大量應用了目標檢測技術 。它通過多個攝像頭和傳感器獲取車輛周圍的環境信息,利用深度學習算法對圖像和數據進行處理,實現對交通標志、車輛和行人的實時檢測和識別 。在高速公路上,Autopilot 系統能夠檢測到前方車輛的距離和速度,自動調整車速,保持安全車距 。當檢測到交通標志時,系統會根據標志的信息進行相應的操作,如限速提示、車道變更提示等 。在城市道路中,系統能夠檢測到行人的位置和運動狀態,當檢測到行人可能進入車輛行駛路徑時,會及時發出警報并采取制動措施 。特斯拉還不斷通過軟件更新優化目標檢測算法,提高系統的性能和安全性 。通過收集大量的實際行駛數據,對算法進行訓練和優化,使其能夠更好地適應各種復雜的交通場景 。
自動駕駛中的目標檢測技術是一個復雜而關鍵的領域,通過不斷創新和優化算法,結合多傳感器融合技術,能夠實現對交通標志、車輛和行人的高精度檢測和識別,為自動駕駛的發展提供堅實的技術支持,推動智能交通的進步 。
6.2 安防監控中的目標檢測
在安防監控領域,目標檢測技術是保障公共安全、維護社會秩序的重要手段,它能夠實時、準確地識別監控視頻中的人員、車輛等目標,及時發現異常行為,為安全管理提供有力支持 。
人員檢測與行為分析是安防監控的核心任務之一 。在公共場所,如機場、火車站、商場等人員密集區域,通過部署攝像頭和目標檢測系統,能夠實時監測人員的活動情況 。基于深度學習的目標檢測算法,如 Faster R - CNN、YOLO 系列等,能夠快速準確地檢測出視頻中的人員 。這些算法通過對大量包含人員的圖像進行訓練,學習到人員的特征模式,從而能夠在復雜背景下準確識別人員 。一些先進的安防監控系統不僅能夠檢測人員,還能對人員的行為進行分析 。通過人體姿態估計和行為識別技術,系統可以判斷人員是否存在異常行為,如奔跑、摔倒、斗毆等 。基于姿態關鍵點檢測的方法,通過分析人體關節點的位置和運動軌跡,判斷人員的行為動作 。在機場的監控場景中,當檢測到有人在非緊急情況下奔跑時,系統會自動發出警報,提醒安保人員注意,以便及時處理可能出現的安全問題 。
車輛檢測與追蹤在安防監控中也起著重要作用 。在交通要道、停車場等場所,通過對車輛的檢測和追蹤,可以實現交通流量統計、車輛違規行為監測以及車輛追蹤定位等功能 。基于卷積神經網絡的目標檢測算法能夠準確檢測出視頻中的車輛,并識別車輛的類型,如轎車、卡車、公交車等 。結合目標追蹤算法,如卡爾曼濾波、匈牙利算法等,系統可以對檢測到的車輛進行實時追蹤,記錄車輛的行駛軌跡 。在交通路口的監控中,通過對車輛的檢測和追蹤,系統可以統計不同方向的交通流量,為交通管理部門提供數據支持,以便優化交通信號燈的配時 。當檢測到車輛闖紅燈、超速等違規行為時,系統可以自動記錄車輛的車牌號碼和違規時間,為交通執法提供證據 。
異常事件檢測是安防監控的關鍵功能之一,目標檢測技術在這方面發揮著重要作用 。通過對監控視頻中的目標行為進行分析,系統可以及時發現異常事件,如入侵、盜竊、火災等 。在入侵檢測中,系統通過檢測人員是否進入了設定的禁區來判斷是否發生入侵行為 。利用背景差分法和目標檢測算法,系統可以實時監測場景中的目標變化,當檢測到有人員進入禁區時,立即發出警報 。在火災檢測中,通過對視頻中的火焰和煙霧進行檢測,系統可以及時發現火災隱患 。基于深度學習的火焰和煙霧檢測算法,通過學習火焰和煙霧的特征,能夠在早期階段準確檢測到火災的發生 。在倉庫的監控中,當檢測到火焰或煙霧時,系統會迅速發出警報,并通知消防部門,以便及時采取滅火措施,減少損失 。
以海康威視的智能安防監控系統為例,該系統廣泛應用了目標檢測技術 。在城市安防監控中,海康威視的攝像頭部署在各個重要區域,通過實時采集視頻圖像,并將圖像傳輸到后端的智能分析平臺 。平臺利用基于深度學習的目標檢測算法,對視頻中的人員、車輛進行實時檢測和分析 。在人員檢測方面,系統能夠準確識別人員的身份、行為和位置信息 。通過人臉識別技術,系統可以對重點人員進行實時追蹤和預警 。在車輛檢測方面,系統能夠檢測車輛的類型、車牌號碼,并對車輛的行駛軌跡進行追蹤 。當檢測到車輛違規行為時,系統會自動記錄相關信息,并通知交通管理部門 。海康威視的智能安防監控系統還具備強大的異常事件檢測功能,能夠及時發現入侵、火災等異常情況,并迅速發出警報 。通過對監控視頻的實時分析,系統可以在第一時間發現異常事件,為安全管理提供有力的支持,有效提升了城市的安全防范水平 。
6.3 工業制造中的目標檢測
在工業制造領域,目標檢測技術扮演著至關重要的角色,它為產品質量檢測、生產過程監控以及工業自動化提供了強大的技術支持,能夠有效提高生產效率、降低生產成本、保障產品質量 。
產品缺陷檢測是工業制造中目標檢測技術的重要應用之一 。在生產線上,各類產品在制造過程中可能會出現各種缺陷,如裂紋、劃痕、孔洞等,這些缺陷會影響產品的性能和質量 。基于深度學習的目標檢測算法能夠對產品圖像進行分析,準確檢測出產品表面的缺陷 。在電子元件生產中,利用卷積神經網絡(CNN)對電路板進行檢測,能夠快速識別出電路板上的短路、斷路、元件缺失等缺陷 。在訓練模型時,使用大量包含缺陷和正常產品的圖像數據進行訓練,讓模型學習到缺陷的特征模式 。在實際檢測中,將生產線上的電路板圖像輸入到訓練好的模型中,模型能夠自動判斷電路板是否存在缺陷,并定位缺陷的位置 。一些先進的缺陷檢測系統還能夠對缺陷進行分類和評估,根據缺陷的類型和嚴重程度,采取相應的處理措施,如修復、返工或報廢 。
尺寸測量與質量評估也是工業制造中目標檢測技術的重要應用 。在機械制造、汽車制造等行業,對零部件的尺寸精度要求極高 。通過目標檢測技術,結合圖像處理和計算機視覺算法,可以對零部件的尺寸進行精確測量,并評估其質量是否符合標準 。在汽車零部件制造中,利用基于深度學習的目標檢測算法對汽車發動機缸體進行檢測,能夠準確測量缸體的內徑、外徑、高度等尺寸參數 。通過將測量結果與標準尺寸進行對比,判斷零部件是否合格 。一些先進的尺寸測量系統還能夠實現自動化測量和數據分析,將測量數據實時反饋到生產控制系統中,以便及時調整生產工藝,保證產品質量的穩定性 。在生產過程中,如果發現某個零部件的尺寸偏差超出允許范圍,系統會自動報警,并提示操作人員進行調整,從而避免生產出不合格產品 。
生產過程監控是保障工業生產順利進行的關鍵環節 。目標檢測技術可以實時監測生產線上的設備運行狀態、物料流動情況以及工人的操作行為,及時發現生產過程中的異常情況,如設備故障、物料堵塞、工人違規操作等 。在化工生產中,通過對反應釜、管道等設備的圖像進行實時監測,利用目標檢測算法檢測設備表面是否有泄漏、變形等異常情況 。當檢測到異常時,系統會立即發出警報,并通知相關人員進行處理,避免事故的發生 。在生產線上,通過對物料的檢測和追蹤,系統可以實時監控物料的流動情況,確保生產過程的連續性 。在裝配車間,通過對工人操作行為的分析,系統可以判斷工人是否按照標準操作流程進行操作,提高生產效率和產品質量 。
以富士康的工業互聯網平臺為例,該平臺在工業制造中廣泛應用了目標檢測技術 。在電子產品制造過程中,富士康利用基于深度學習的目標檢測算法對產品進行質量檢測 。通過在生產線上部署高清攝像頭,實時采集產品圖像,并將圖像傳輸到工業互聯網平臺進行分析 。平臺利用訓練好的目標檢測模型,能夠快速準確地檢測出產品表面的缺陷,如劃痕、氣泡等 。對于檢測出的缺陷產品,系統會自動進行標記,并將相關數據反饋到生產控制系統中,以便對生產工藝進行調整 。在生產過程監控方面,富士康的工業互聯網平臺利用目標檢測技術對生產線上的設備運行狀態進行實時監測 。通過對設備的關鍵部位進行圖像采集和分析,系統可以及時發現設備的異常情況,如零部件松動、溫度過高等 。當檢測到異常時,系統會立即發出警報,并提供相應的解決方案,保障生產過程的安全和穩定 。富士康還利用目標檢測技術對工人的操作行為進行分析,通過識別工人的動作和姿態,判斷工人是否按照標準操作流程進行操作,提高生產效率和產品質量 。
七、結論與展望
7.1 研究成果總結
本研究圍繞深度學習在目標檢測領域的應用展開,通過對主流目標檢測算法的深入剖析、性能評估與優化策略的探討以及代碼實現與應用案例分析,取得了一系列具有重要理論和實踐意義的研究成果 。
在主流目標檢測算法剖析方面,全面而深入地研究了基于區域提議的 R - CNN 系列算法(R - CNN、Fast R - CNN、Faster R - CNN)以及單階段檢測算法(YOLO 系列、SSD ) 。詳細解析了它們的網絡結構、工作流程、特征提取方式以及損失函數設計等關鍵要素 。深入分析了 Faster R - CNN 的區域生成網絡(RPN)如何高效生成候選區域,以及 RoI 池化層怎樣將不同大小的候選區域映射到固定大小的特征向量,實現端到端的目標檢測 。對于 YOLO 系列算法,探究了其將目標檢測視為單一回歸問題,在一次前向傳播中直接從完整圖像預測邊界框和類概率的原理,以及不同版本(如 YOLOv2、YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOv7、YOLOv8 )在網絡結構、特征融合方式、損失函數改進等方面的演進和優化 。通過對這些主流算法的深入剖析,清晰地認識到它們的優勢與不足,為后續的算法改進和創新提供了堅實的理論基礎 。
在性能評估與優化策略研究中,明確了平均精度均值(mAP)、精確率、召回率和交并比(IoU)等性能評估指標在衡量目標檢測算法性能方面的重要作用 。深入探討了數據增強技術、模型壓縮與加速以及損失函數優化等優化策略 。在數據增強技術方面,研究了隨機翻轉、隨機裁剪、隨機縮放以及光度變換等方法,通過這些方法擴充了數據集的規模和多樣性,有效提升了模型的泛化能力和魯棒性 。在模型壓縮與加速方面,探討了剪枝、量化和知識蒸餾等方法,通過去除模型中不重要的連接或神經元、將參數和激活值用低比特表示以及將教師模型的知識轉移到學生模型中等方式,減少了模型的大小和計算量,提高了模型的推理效率 。在損失函數優化方面,研究了交叉熵損失、IoU 損失以及它們的改進版本(如 Focal Loss、GIoU 損失、DIoU 損失和 CIoU 損失等) 。通過對這些損失函數的優化和改進,有效提高了模型在目標檢測任務中的分類和定位精度 。
在代碼實現與應用案例分析中,成功搭建了基于 Python 和 PyTorch 的目標檢測開發環境,并以 YOLOv5 為例進行了詳細的代碼實現 。包括模型構建、數據加載與預處理等關鍵環節的代碼實現,通過這些代碼能夠構建出完整的 YOLOv5 網絡結構,并對數據進行有效的加載和預處理,為模型的訓練和測試提供支持 。對代碼運行結果進行了深入分析,通過繪制損失曲線觀察模型的訓練過程,使用可視化方式展示檢測效果,并計算 mAP、精確率、召回率等性能指標來定量評估模型的性能 。將目標檢測技術應用于自動駕駛、安防監控和工業制造等領域,通過具體案例分析展示了目標檢測技術在這些領域的實際應用效果 。在自動駕駛中,實現了對交通標志、車輛和行人的準確檢測和識別,為車輛的安全行駛提供了保障;在安防監控中,實現了對人員、車輛的檢測與行為分析,以及異常事件的及時發現,為公共安全提供了支持;在工業制造中,實現了產品缺陷檢測、尺寸測量與質量評估以及生產過程監控,提高了生產效率和產品質量 。
本研究在目標檢測領域取得了較為全面和深入的研究成果,為目標檢測技術的進一步發展和應用提供了理論支持、技術方法和實踐經驗 。
7.2 未來研究方向展望
隨著深度學習技術的不斷發展和應用場景的日益拓展,目標檢測領域也面臨著新的機遇和挑戰,未來的研究方向具有廣闊的探索空間。
融合多模態信息是未來目標檢測的重要研究方向之一 。當前的目標檢測算法主要依賴于單一模態的數據,如可見光圖像,然而在復雜場景下,單一模態數據往往存在局限性 。例如,在夜間或惡劣天氣條件下,可見光圖像的質量會受到很大影響,導致目標檢測性能下降 。融合多模態信息,如將可見光圖像與紅外圖像、激光雷達點云數據等相結合,可以充分利用不同模態數據的互補性,提高目標檢測的準確性和魯棒性 。紅外圖像對溫度敏感,在夜間或低光照條件下能夠清晰地顯示目標物體的輪廓,與可見光圖像融合后,可以增強對目標的檢測能力 。激光雷達點云數據能夠提供目標物體的三維信息,與二維圖像數據融合,可以更準確地定位目標物體的位置 。未來的研究可以致力于開發更有效的多模態信息融合算法和模型架構,實現不同模態數據的深度融合和協同處理 。
設計輕量級網絡以適應資源受限環境也是未來的重要研究方向 。隨著物聯網設備、移動設備和嵌入式系統的廣泛應用,對目標檢測算法的計算資源和功耗要求越來越高 。傳統的深度學習模型通常計算復雜度較高,難以在資源受限的設備上運行 。因此,設計輕量級網絡,在保證一定檢測精度的前提下,減少模型的參數數量和計算量,是未來的研究重點 。可以通過優化網絡結構,如采用深度可分離卷積、MobileNet、ShuffleNet 等輕量級網絡結構,減少卷積操作的計算量 。還可以結合模型壓縮技術,如剪枝、量化等,進一步減少模型的大小和計算量 。研究如何在輕量級網絡中有效地提取和融合特征,以提高檢測精度,也是未來需要解決的問題 。
小目標檢測和遮擋目標檢測
八、結論
本研究深入探究深度學習目標檢測技術,對其核心算法進行剖析,提出針對性優化策略,并通過代碼實現與應用案例驗證,取得了一系列成果,展現出該技術在多領域的重要價值與廣闊應用前景。
通過對主流深度學習目標檢測算法的全面剖析,明確了各算法的優勢與局限 。R - CNN 系列算法以區域提議為基礎,逐步實現端到端的目標檢測,從 R - CNN 到 Fast R - CNN 再到 Faster R - CNN,檢測精度和速度不斷提升 。YOLO 系列算法則將目標檢測視為單一回歸問題,檢測速度極快,如 YOLOv1 開啟了實時檢測的先河,后續版本(如 YOLOv2、YOLOv3 及更高版本)在網絡結構、特征融合和訓練策略等方面持續優化,不斷提高檢測精度和對小目標的檢測能力 。SSD 算法在不同尺度特征圖上進行多尺度檢測,兼顧了檢測速度和精度 。這些算法為目標檢測技術的發展奠定了堅實基礎,也為后續的研究和應用提供了多樣化的選擇 。
針對目標檢測中的關鍵挑戰,探索并提出了一系列有效的優化策略 。數據增強技術通過隨機翻轉、裁剪、縮放和光度變換等操作,擴充了數據集的規模和多樣性,顯著提升了模型的泛化能力 。模型壓縮與加速技術,如剪枝、量化和知識蒸餾等,在保持模型性能的前提下,減少了模型的大小和計算量,提高了推理效率,使其能夠更好地應用于資源受限的環境 。損失函數優化方面,Focal Loss 有效緩解了類別不平衡問題,GIoU、DIoU 和 CIoU 等改進的 IoU 損失則提升了目標定位的精度 。這些優化策略從不同角度提升了目標檢測算法的性能,為實際應用提供了更可靠的技術支持 。
以 YOLOv5 為例進行代碼實現,涵蓋模型構建、數據加載與預處理以及訓練與測試等關鍵環節 。通過詳細的代碼展示和分析,深入理解了 YOLOv5 的網絡結構和工作原理,包括骨干網絡、頸部網絡和頭部網絡的構建,以及數據的加載、增強和模型的訓練過程 。代碼運行結果的分析和檢測效果的展示,直觀地評估了模型的性能,為算法的優化和應用提供了實踐經驗 。
目標檢測技術在自動駕駛、安防監控和工業制造等領域有著廣泛且重要的應用 。在自動駕駛中,準確識別交通標志、車輛和行人,為自動駕駛系統提供關鍵信息,保障行車安全;安防監控中,實時監測異常行為,維護公共安全;工業制造中,實現產品缺陷檢測和質量控制,提高生產效率和產品質量 。這些應用案例充分展示了目標檢測技術的實際價值和巨大潛力,也推動了各領域的智能化發展 。
深度學習目標檢測技術在理論研究和實際應用方面都取得了顯著成果,但仍面臨諸多挑戰 。小目標檢測、遮擋問題和類別不平衡等挑戰依然存在,需要進一步探索更有效的解決方案 。未來,隨著深度學習技術的不斷發展,以及與其他領域的交叉融合,目標檢測技術有望取得更大的突破 。在模型架構方面,可能會出現更加高效、輕量級且具有更強特征提取能力的網絡結構,以適應不同場景和硬件設備的需求 。在多模態數據融合方面,將進一步探索如何更有效地融合可見光圖像、紅外圖像、激光雷達點云等多種模態的數據,充分發揮各模態數據的優勢,提高目標檢測的準確性和魯棒性 。隨著量子計算、腦機接口等新興技術的發展,目標檢測技術也可能會與之融合,開辟新的研究方向和應用領域 。目標檢測技術將在推動人工智能技術發展和各行業智能化轉型中發揮更加重要的作用 。
)

![[java八股文][Java虛擬機面試篇]垃圾回收](http://pic.xiahunao.cn/[java八股文][Java虛擬機面試篇]垃圾回收)





:Android Things開發探索)










