DataX 是一個異構數據源離線同步(ETL)工具,實現了包括關系型數據庫(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各種異構數據源之間穩定高效的數據同步功能。它也是阿里云 DataWorks 數據集成功能的開源版本。
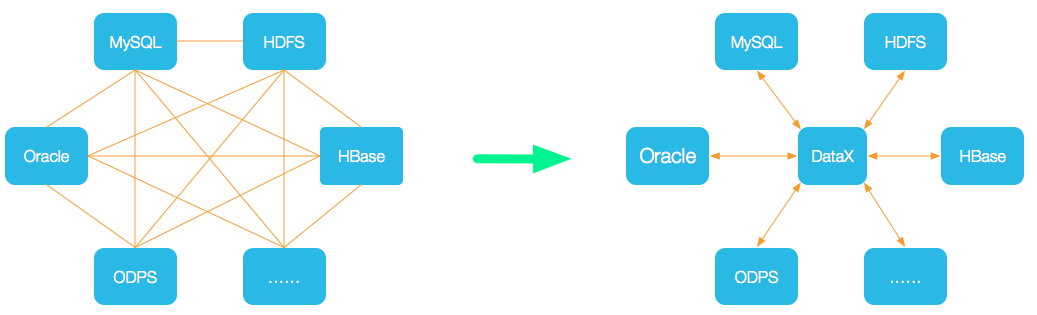
為了解決異構數據源同步問題,DataX 將復雜的網狀的同步鏈路變成了星型數據鏈路,DataX 作為中間傳輸載體負責連接各種數據源。當需要接入一個新的數據源的時候,只需要將此數據源對接到 DataX,便能跟已有的數據源做到無縫數據同步。
體系原理
DataX 本身作為離線數據同步框架,采用 Framework + Plugin 架構構建。將數據源讀取和寫入抽象成為 Reader/Writer 插件,納入到整個同步框架中,如下圖所示:

其中,
- Reader:Reader 為數據采集模塊,負責采集數據源的數據,將數據發送給 Framework 模塊。
- Framework:Framework 用于連接 Reader 和 Writer,作為兩者的數據傳輸通道,并處理緩沖、流控、并發、數據轉換等核心技術問題。
- Writer: Writer 為數據寫入模塊,負責不斷地向 Framework 獲取數據,并將數據寫入到目的端。
DataX 開源版本支持單機多線程模式完成同步作業運行,以下是一個 DataX 作業生命周期的時序圖:
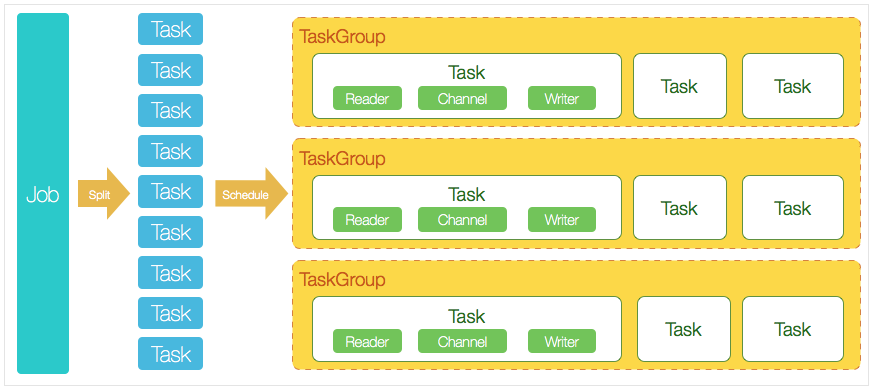
其中涉及的核心模塊和流程如下:
- DataX 完成單個數據同步的作業稱之為 Job,DataX 接受到一個 Job 之后,將啟動一個進程來完成整個作業同步過程。DataX
Job 模塊是單個作業的中樞管理節點,承擔了數據清理、子任務切分(將單一作業計算轉化為多個子 Task)、TaskGroup 管理等功能。 - DataX Job啟動后,會根據不同的源端切分策略,將 Job 切分成多個小的 Task(子任務),以便于并發執行。Task 是作業的最小單元,每一個 Task 都會負責一部分數據的同步工作。
- 切分多個 Task 之后,DataX Job會調用 Scheduler 模塊,根據配置的并發數據量,將拆分成的 Task 重新組合,組裝成 TaskGroup(任務組)。每一個 TaskGroup 負責以一定的并發運行完畢分配好的所有 Task,默認單個任務組的并發數量為 5。
- 每一個 Task 都由 TaskGroup 負責啟動,Task 啟動后,會固定啟動 Reader—>Channel—>Writer 的線程來完成任務同步工作。
- DataX 作業運行起來之后,Job 監控并等待多個 TaskGroup 模塊任務完成,等待所有 TaskGroup 任務完成后 Job 成功退出。否則,異常退出,進程退出值為非零。
舉例來說,用戶提交了一個 DataX 作業,并且配置了 20 個并發,目的是將一個 100 張分表的 MySQL 數據同步到 MaxCompute 里面。 DataX 的調度決策思路是:DataX Job 根據分庫分表切分成了 100 個子任務;根據 20 個并發,DataX 計算共需要分配 4 個 TaskGroup;4個任務組平分切分好的 100 個子任務,每一個任務組負責以 5 個并發共計運行 25 個子任務。
數據源
經過多年的積累,DataX 目前已經有了比較全面的插件體系,主流的 RDBMS 數據庫、NOSQL、大數據計算系統都已經接入。DataX 目前支持數據如下:
- 關系型數據庫:包括 MySQL、Oracle、OceanBase、SQL Server、PostgreSQL、DRDS、金倉、高斯以及通用的 RDBMS 等;
- 阿里云數倉數據存儲:包括 MaxCompute、AnalyticDB for MySQL、ADS、OSS、OCS、Hologres、AnalyticDB for PostgreSQL 等;
- 阿里云中間件:數據總線 DataHub、日志服務 SLS;
- 圖數據庫:阿里云 Graph Database、Neo4j;
- NoSQL:阿里云 OTS、Hbase、Phoenix、MongoDB、Cassandra 等;
- 數倉數據存儲:StarRocks、Apache Doris、ClickHouse、Databend、Hive、SelectDB 等;
- 無結構化數據存儲:TxtFile、FTP、HDFS、Elasticsearch;
- 時序數據庫:OpenTSDB、TSDB、TDengine。
DataX 框架提供了簡單的插件接入機制,只需要任意加上一種插件,就能無縫對接其他數據源。插件開發可以參考以下文章:
https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
快速體驗
通過 GitHub 或者直接輸入以下網址下載 DataX 工具包:
http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解壓之后進入 bin 目錄即可運行作業,作業通過配置文件進行設置,可以通過以下命令查看配置模板:
$ cd {YOUR_DATAX_HOME}/bin$ python datax.py -r streamreader -w streamwriter
DataX (UNKNOWN_DATAX_VERSION), From Alibaba !
Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [], "sliceRecordCount": ""}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "", "print": true}}}], "setting": {"speed": {"channel": ""}}}
}
其中,-r 用于指定 Reader,-w用于指定 Writer,示例中兩個都是 streamreader。安裝目錄下的 plugin 子目錄包含了所有的 Reader 和 Writer。
job 目錄提供了一個默認的作業配置 job.json,使用以下命令運行示例作業:
$ python datax.py ../job/job.json2025-05-17 15:00:02.135 [job-0] INFO JobContainer -
任務啟動時刻 : 2025-05-17 15:00:02
任務結束時刻 : 2025-05-17 15:00:22
任務總計耗時 : 20s
任務平均流量 : 545/s
記錄寫入速度 : 5000rec/s
讀出記錄總數 : 100000
讀寫失敗總數 : 0
其他類型的數據源也可以按照相同的方式進行配置。
除了使用命令行和配置文件的方式運行作業之外,還可以通過圖形化的調度工具(例如 DataX-Web、Apache DolphinScheduler)進行管理。

)








線性表-鏈表-單鏈表)

)
)





流編輯器系統)