Hadoop 2.X 與 Hadoop 3.X 深度對比:版本特性、架構與性能剖析
在大數據處理的浪潮中,Hadoop 憑借其分布式存儲與計算的強大能力,成為了業界的核心框架之一。隨著技術的不斷演進,Hadoop 也經歷了多個重要版本的迭代。其中,Hadoop 2.X 和 Hadoop 3.X 無疑是兩個具有里程碑意義的代表。本文將深入對比這兩個主要版本在核心特性、架構設計以及性能表現上的差異,并結合相關架構圖和性能對比圖進行直觀的輔助說明。
一、版本核心特性:演進與革新
Hadoop 的每一次大版本升級,都伴隨著一系列關鍵特性的引入和優化,旨在提升其易用性、可靠性、性能和可擴展性。
(一) Hadoop 2.X:奠定現代 Hadoop 基石
Hadoop 2.X 版本是Hadoop 發展史上的一個重要轉折點,它引入了諸多革命性的特性:
- YARN (Yet Another Resource Negotiator):這無疑是 Hadoop 2.X 最核心的變革。YARN 將資源管理 (ResourceManager) 和作業調度/監控 (ApplicationMaster) 徹底分離,使得 Hadoop 不再僅僅是 MapReduce 的專屬平臺。它演變為一個通用的資源管理系統,能夠支持如 Spark、Flink、Tez 等多種計算框架在同一個集群上高效運行,極大地提升了集群的資源利用率和靈活性。
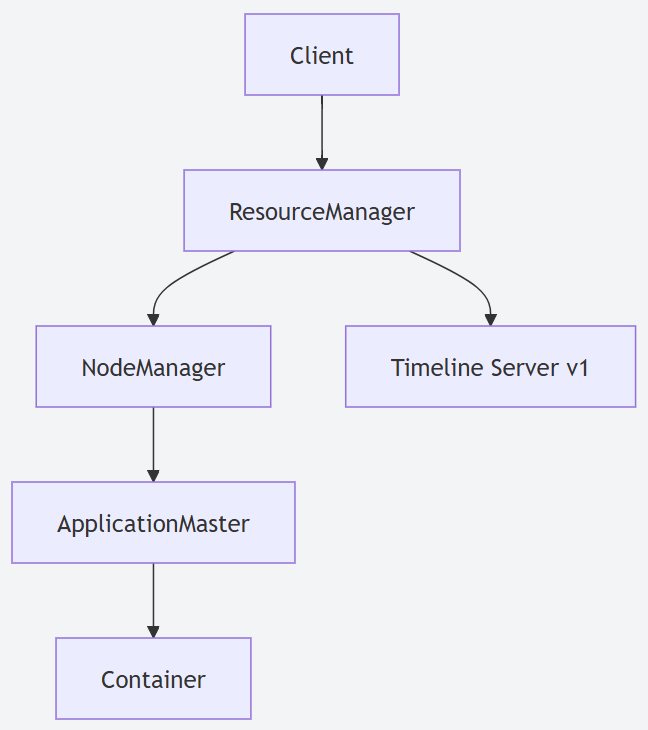
-
HDFS NameNode 高可用 (High Availability):針對 Hadoop 1.X 中 NameNode 的單點故障問題,Hadoop 2.X 引入了Active-Standby NameNode 架構。通過共享存儲 (如 QJM - Quorum Journal Manager 或 NFS) 同步元數據,當Active NameNode 發生故障時,Standby NameNode 能夠快速接管,保證了 HDFS 服務的連續性和高可用性。
-
HDFS 快照 (Snapshots):提供了對文件系統特定時間點的只讀鏡像創建功能。快照可以用于數據備份、災難恢復以及防止用戶誤操作導致的數據丟失。
-
支持多種計算模型并存:得益于 YARN,Hadoop 2.X 生態得以蓬勃發展,除了傳統的 MapReduce,更高效的DAG 執行引擎 Tez、內存計算框架 Spark 等都能在 YARN 上良好運行,滿足了日益多樣化的數據處理需求。
(二) Hadoop 3.X:全面優化與特性增強
Hadoop 3.X 在繼承 Hadoop 2.X 優秀特性的基礎上,進行了更深層次的優化和功能增強:
- HDFS 糾刪碼 (Erasure Coding):這是 Hadoop 3.X 最具吸引力的存儲特性之一。相比傳統的3副本策略,糾刪碼可以在保證同等數據可靠性 (甚至更高) 的前提下,顯著降低存儲開銷 (通常可節省約 50% 的存儲空間)。例如,采用 (6,3) 策略 (6個數據塊,3個校驗塊) 存儲數據,其存儲冗余度遠低于3副本。
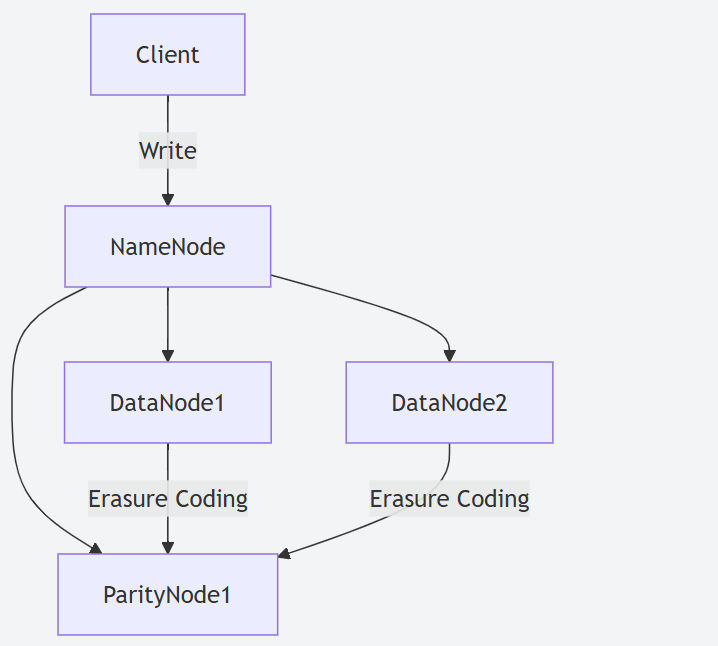
-
更強的 NameNode 高可用性:Hadoop 3.X 支持多個 Standby NameNode (例如,一個 Active,兩個 Standby),進一步提升了 NameNode 故障切換的可靠性和容錯能力。
-
YARN Timeline Service v2 (ATSv2):對應用程序歷史信息的存儲和查詢服務進行了重構和增強。ATSv2 提供了更好的可擴展性、可靠性和性能,使用可插拔的存儲后端 (如 HBase),能夠更有效地管理大量應用程序的歷史元數據。
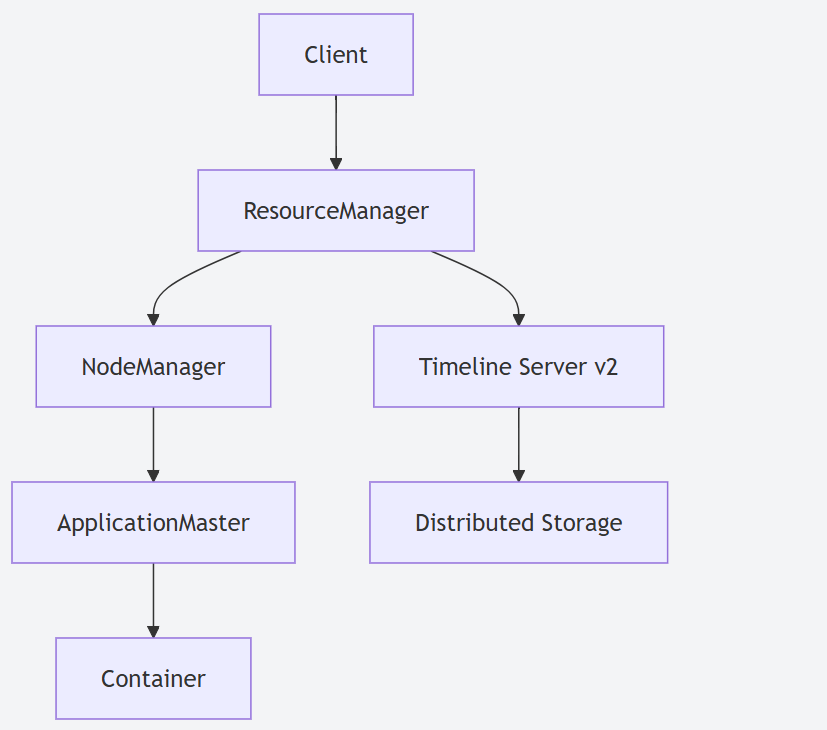
-
MapReduce 性能優化:針對Shuffle密集型作業,MapReduce 的map output collector (包括 Spill, Sort, IFile 等) 可以切換到C/C++ 實現,據稱可帶來高達30% 的性能提升。同時,MapReduce 任務的內存參數可以自動推斷,簡化了配置并避免了資源浪費。
-
精簡內核與依賴管理:Hadoop 3.X 移除了過時的 API 和實現,優化了默認組件。引入了Classpath Isolation機制,有效避免了不同版本 JAR 包 (如 Guava) 之間的沖突問題,增強了生態組件的兼容性。
-
Shell 腳本重構與默認端口變更:對管理腳本進行了重構,修復了bug并增加了新特性。多個服務的默認端口被移出了Linux 臨時端口范圍,減少了端口沖突的可能性。
二、核心架構差異:存儲與資源管理
Hadoop 2.X 和 3.X 在底層架構層面也存在一些顯著差異,主要體現在存儲機制和資源管理服務的演進上。
(一) 存儲架構的進化:從副本到糾刪碼
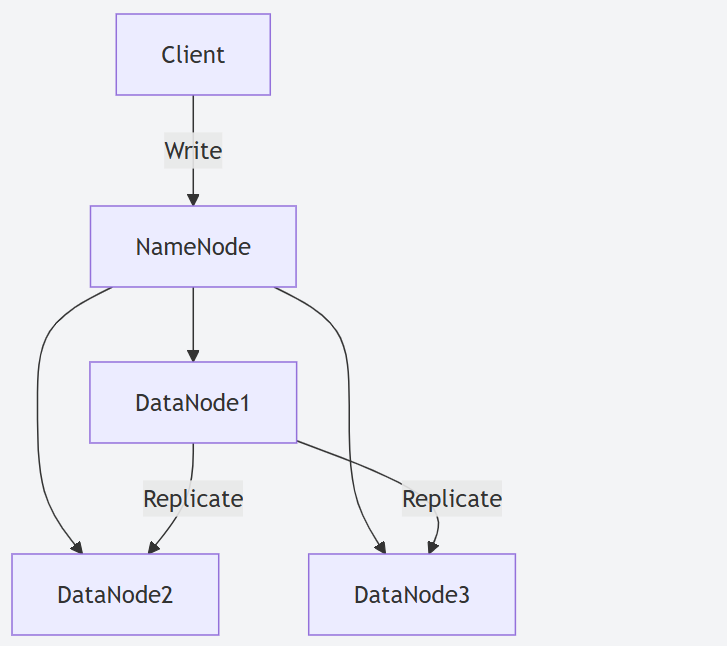
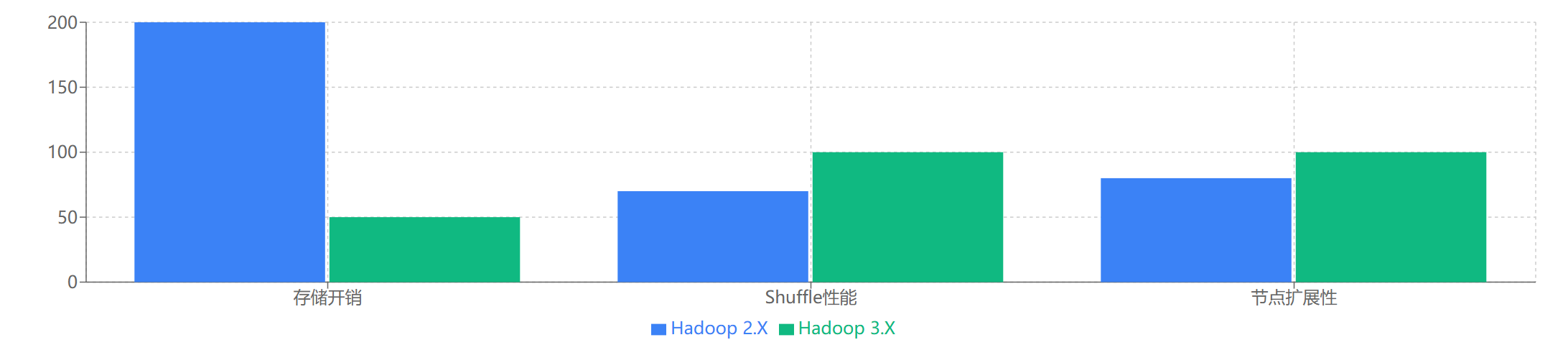
- Hadoop 2.X 存儲:依賴于經典的三副本策略來保證數據可靠性。這意味著每份數據在集群中存儲三份,存儲開銷高達 200%。雖然可靠性高,但存儲成本也相應較高。
- Hadoop 3.X 存儲:引入了HDFS 糾刪碼 (Erasure Coding)。通過數學編碼的方式,可以用更少的冗余數據 (校驗塊) 來實現同等甚至更高的數據容錯能力。這使得存儲開銷可以大幅降低 (例如,從 200% 降至 50% 左右),對于大規模冷數據存儲尤其具有吸引力。
(二) 資源管理與歷史服務的升級
-
Hadoop 2.X 資源管理:YARN 雖然帶來了革命性的資源統一管理,但其早期的Timeline Service v1 (ATSv1) 在可擴展性和可靠性方面存在一些不足,尤其是在超大規模集群和大量應用的場景下可能成為瓶頸。
-
Hadoop 3.X 資源管理:全面采用了YARN Timeline Service v2 (ATSv2)。ATSv2 經過重新設計,顯著提升了寫入和讀取應用程序歷史數據的性能和可擴展性,并支持更靈活的數據存儲后端,更好地服務于集群的監控和診斷。
三、性能表現對比:效率與擴展的提升
性能是衡量大數據框架優劣的關鍵指標。Hadoop 3.X 在多個方面都展現出相較于 2.X 的性能優勢。
(一) 存儲效率與開銷
- Hadoop 2.X:三副本策略導致存儲利用率低 (僅約 33%),網絡帶寬消耗也較大 (寫入一份數據需要傳輸三份)。
- Hadoop 3.X:糾刪碼的引入大幅提高了存儲利用率 (例如,(6,3) 策略下利用率可達 66%),顯著減少了存儲成本和網絡I/O。
(二) 計算性能 (以 MapReduce 為例)
- Hadoop 2.X:MapReduce 在Shuffle階段的性能以及內存管理方面存在優化空間。
- Hadoop 3.X:通過可選的 C/C++ 實現的 map output collector 和自動推斷的內存參數,MapReduce 作業 (尤其是 Shuffle 密集型) 的執行效率得到了明顯提升。
(三) 集群可擴展性
- Hadoop 2.X:理論上,YARN 支持上萬節點的集群,但 NameNode 的元數據管理能力 (尤其是內存限制) 和 ATSv1 的擴展性可能成為實際瓶頸。
- Hadoop 3.X:通過多 Standby NameNode、ATSv2 的改進以及其他優化,Hadoop 3.X 能夠更好地支持和管理更大規模的集群 (官方宣稱可支持超過 10000 個節點,并持續優化中)。
四、組件信息概覽 (簡要對比)
| 核心關注點 | Hadoop 2.X | Hadoop 3.X |
|---|---|---|
| HDFS 可靠性 | 雙 NameNode (Active/Standby), 3副本 | 多 Standby NameNode, 糾刪碼 + 副本可選 |
| HDFS 存儲成本 | 高 (200% 冗余) | 低 (糾刪碼下約 50% 冗余) |
| YARN 核心服務 | ResourceManager, NodeManager, ATSv1 | ResourceManager, NodeManager, ATSv2 (更優) |
| MapReduce 性能 | Java 實現 Shuffle, 手動內存配置 | 可選 C/C++ 實現 Shuffle, 自動內存推斷 |
| 依賴沖突 | 可能存在 (如 Guava 版本) | Classpath Isolation 機制緩解 |
| 集群規模支持 | 良好,但可能受 NameNode/ATSv1 限制 | 更優,設計上支持更大規模 |
五、總結與選擇建議
毋庸置疑,Hadoop 3.X 在存儲效率、計算性能、可擴展性、可靠性以及易用性等多個維度都對 Hadoop 2.X 進行了顯著的優化和增強。對于新建的大數據平臺,或者對存儲成本、性能有較高要求的現有集群,升級或選擇 Hadoop 3.X 無疑是更具前瞻性的決策。
然而,版本升級并非輕而易舉,企業在決策時仍需綜合考量:
- 現有系統兼容性:評估上層應用和生態組件與 Hadoop 3.X 的兼容情況。
- 升級成本與風險:包括人力投入、時間成本、數據遷移以及潛在的穩定性風險。
- 團隊技術棧與運維能力:新特性可能需要團隊學習新的知識和積累運維經驗。
如果現有 Hadoop 2.X 集群運行穩定,且當前性能和存儲成本仍在可接受范圍內,維持現狀或分階段、小范圍試點升級可能是更穩妥的策略。但長遠來看,Hadoop 3.X 代表了更先進的技術方向和更優的綜合效益。






)






)
)

)


