文章目錄
- 讀寫分離架構
- 什么是讀寫分離結構
- 架構模型
- 優缺點
- 優點
- 缺點
- 技術案例
- 寫情況
- 讀情況
- 冷熱分離架構
- 什么是冷熱分離架構?
- 架構模型
- 優缺點
- 優點
- 缺點
- 技術案例
- 讀數據
- 寫數據
讀寫分離架構
什么是讀寫分離結構
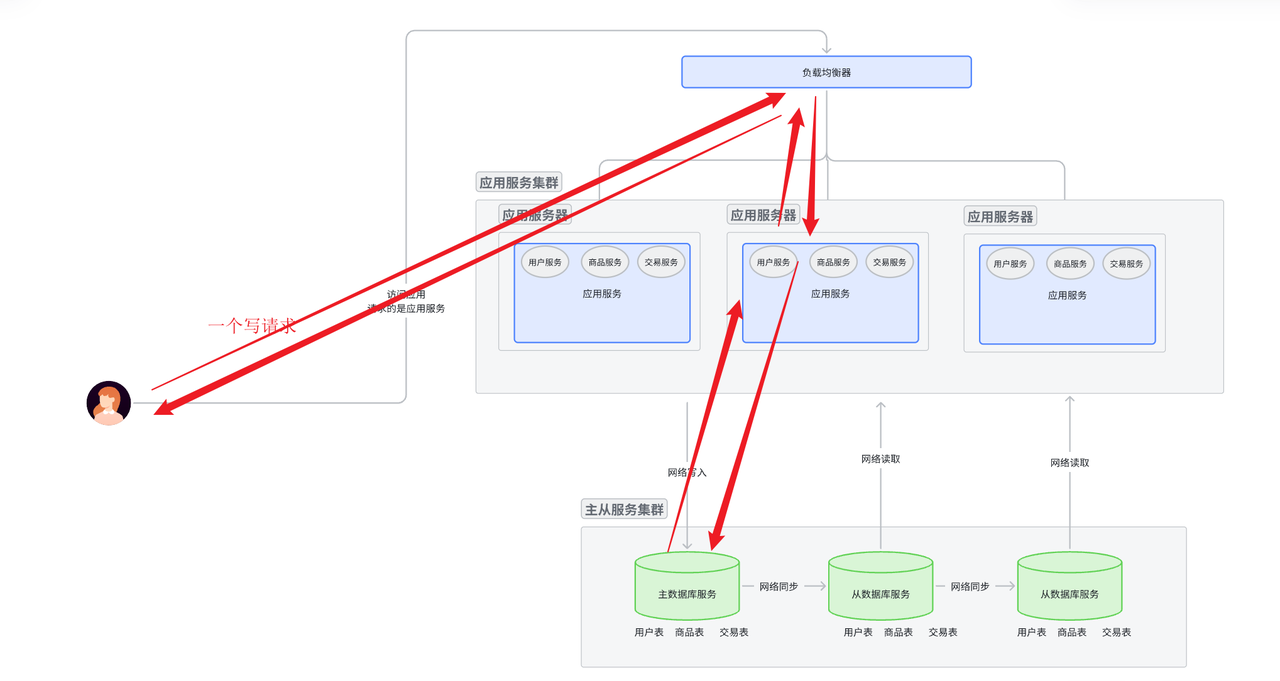
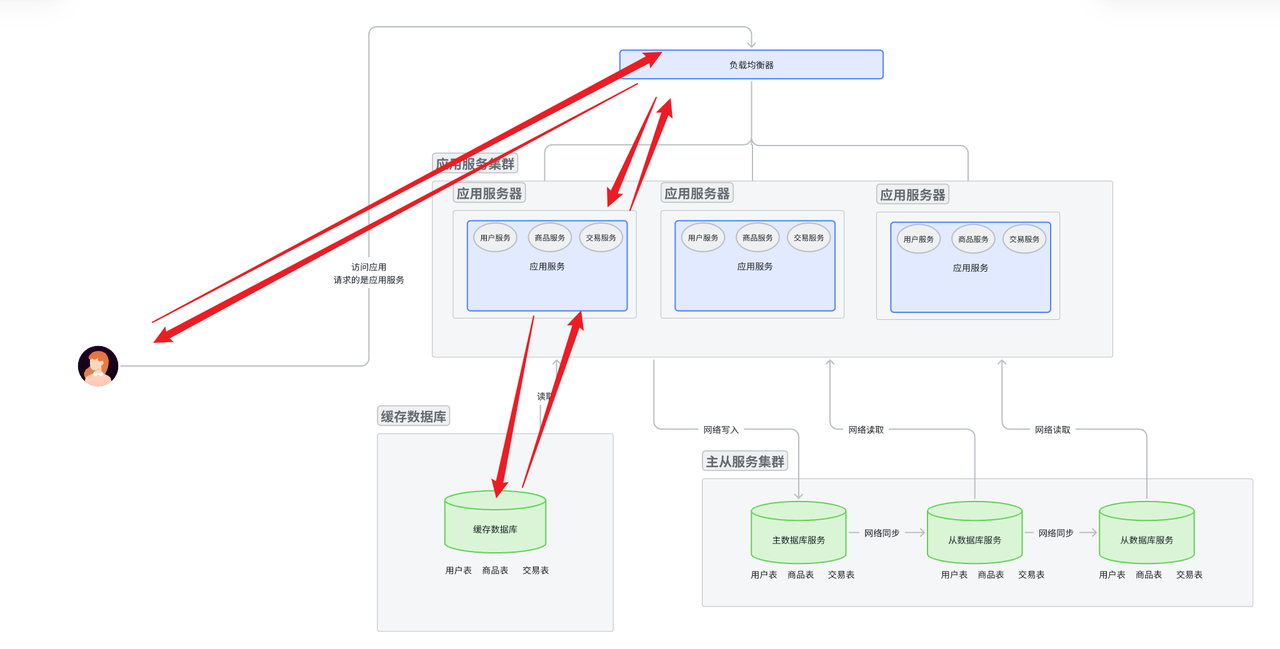
讀寫分離架構針對于數據庫。數據庫原本負責讀寫兩個功能。 讀寫分離架構就是添加多臺數據庫服務器, 其中主數據庫一般負責寫, 從數據庫一般負責讀。
讀寫分離架構也叫做主從分離架構, 一臺數據庫服務器作為主服務器, 然后為這臺主服務器添加冗余(從服務器)。 這樣做的好處有很多, 下面優缺點提到。
架構模型
優缺點
優點
- 可以應對更高的并發量, 讀寫分離,從數據庫分擔了主數據庫的讀請求。
- 高可用性, 增加了系統的冗余, 當主數據庫崩潰時, 從數據快速頂替主數據庫,不影響用戶體驗。
- 從數據庫可以進行橫向擴展,使數據庫對于讀具有擴展性。讀請求理論上不再稱為瓶頸。
- 主數據和從數據庫通過網絡實現數據同步一致。
缺點
- 硬件資源的成本增加, 運維成本增加
- 單點寫瓶頸, 寫并發極高時主數據稱為瓶頸
- 數據不一致性, 數據網絡同步需要時間, 用戶寫入后想要立即讀取,可能讀取不到最新更新信息。
- 主數據庫同步時崩潰會導致數據丟失。
技術案例
寫情況
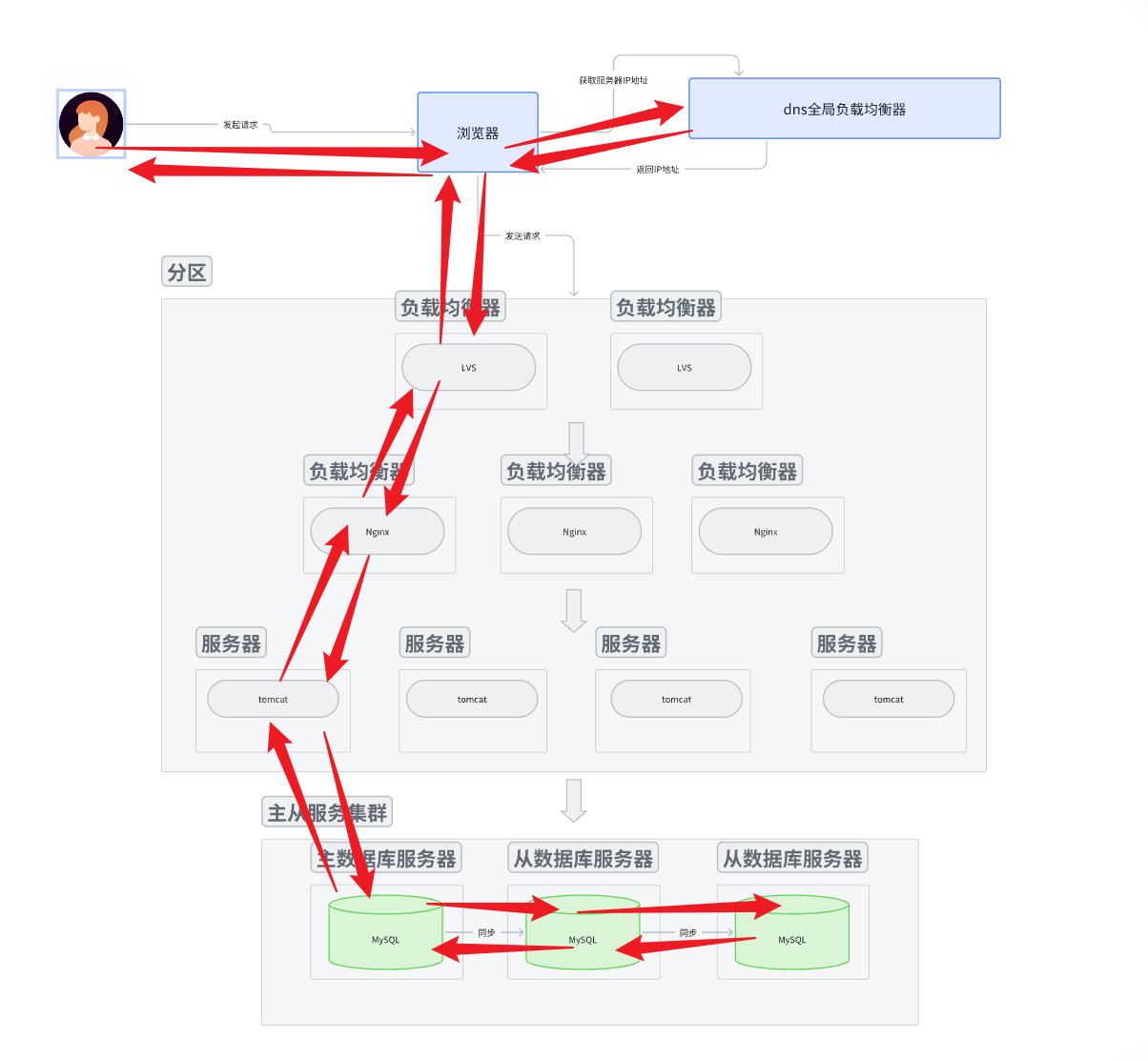
- 用戶使用域名訪問服務器,先訪問dns, dns返回一個IP地址。
- 用IP地址進行路由訪問應用服務器。訪問哪一個? 先到達最外層的負載均衡服務器, 由最外層的負載均衡服務器將這個請求分發下層自己管理的某個服務器。
- 這個服務器接收到請求, 如果這個服務器還是一個負載均衡服務器, 就重復剛剛類似的操作。
- 如果這個服務器是一個應用服務器, 那么應用服務器對請求進行解析。
- 如果是寫請求, 就去主數據庫中寫入數據,將數據通過網絡發送給主數據庫服務器。 然后就返回寫入情況, 是寫入成功還是失敗。對于應用服務集群來說, 應用服務器集群一層一層向上返回請求處理情況; 對于主從數據庫集群來說, 主數據庫要將剛剛寫入的數據同步給從數據庫。
讀情況
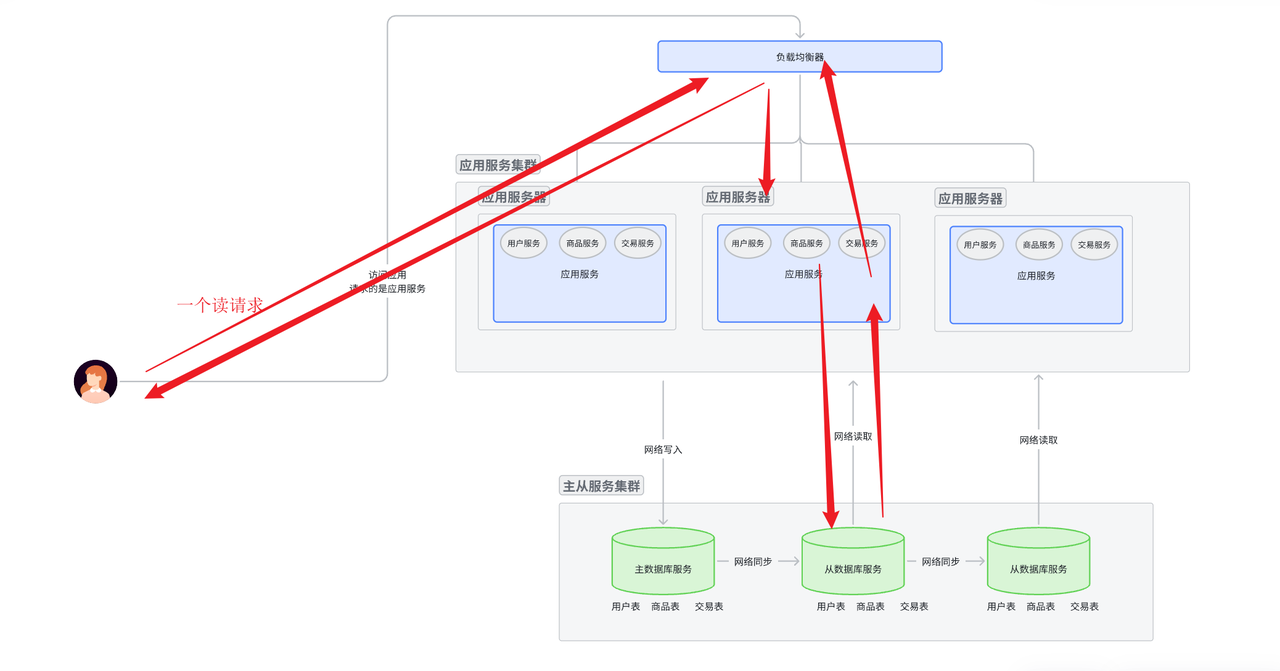
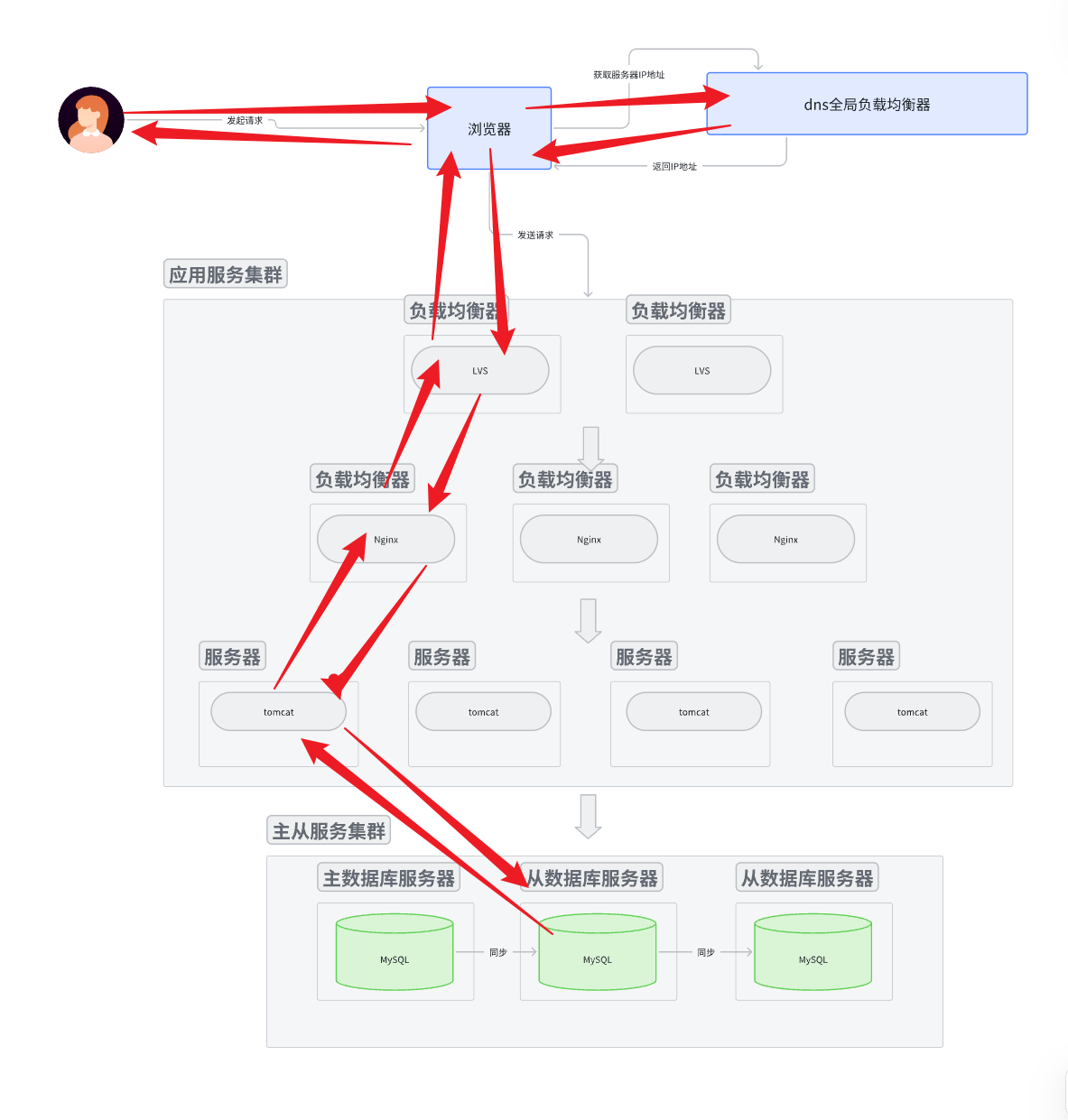
- 用戶拿著 域名 訪問應用服務器, 然后域名交給dns進行解析, 返回IP地址。
- 瀏覽器用IP地址路由到對應的服務集群中。 具體訪問哪一個應用服務節點, 由上層的負載均衡服務器一層
一層向下分發決定。
- 應用服務節點拿到請求后, 對請求進行解析。 解析成功認為是讀請求, 那么就直接去主從數據庫集群里面的從數據庫節點讀取數據。 然后返回讀取結果。
冷熱分離架構
什么是冷熱分離架構?
冷熱分離是將數據分為冷數據和熱數據。 熱數據存放在內存緩存中。 冷數據放在磁盤中。 一個數據庫服務器或者集群作為緩存數據庫服務器, 存儲熱數據。 然后另一個數據庫集群用來存儲冷數據。
架構模型
優缺點
優點
- 分擔了讀取的壓力, 減少了從庫的數量, 優化成本。
- 利用內存存儲數據, 內存的讀取速度遠高于磁盤IO。 提高了數據查詢的效率, 優化效率。
缺點
- 增加系統的復雜性, 增加運維成本。
- 數據同步過程中如果數據庫崩潰, 造成數據丟失和數據不一致問題。
- 寫的高并發仍然可能是系統的瓶頸。
技術案例
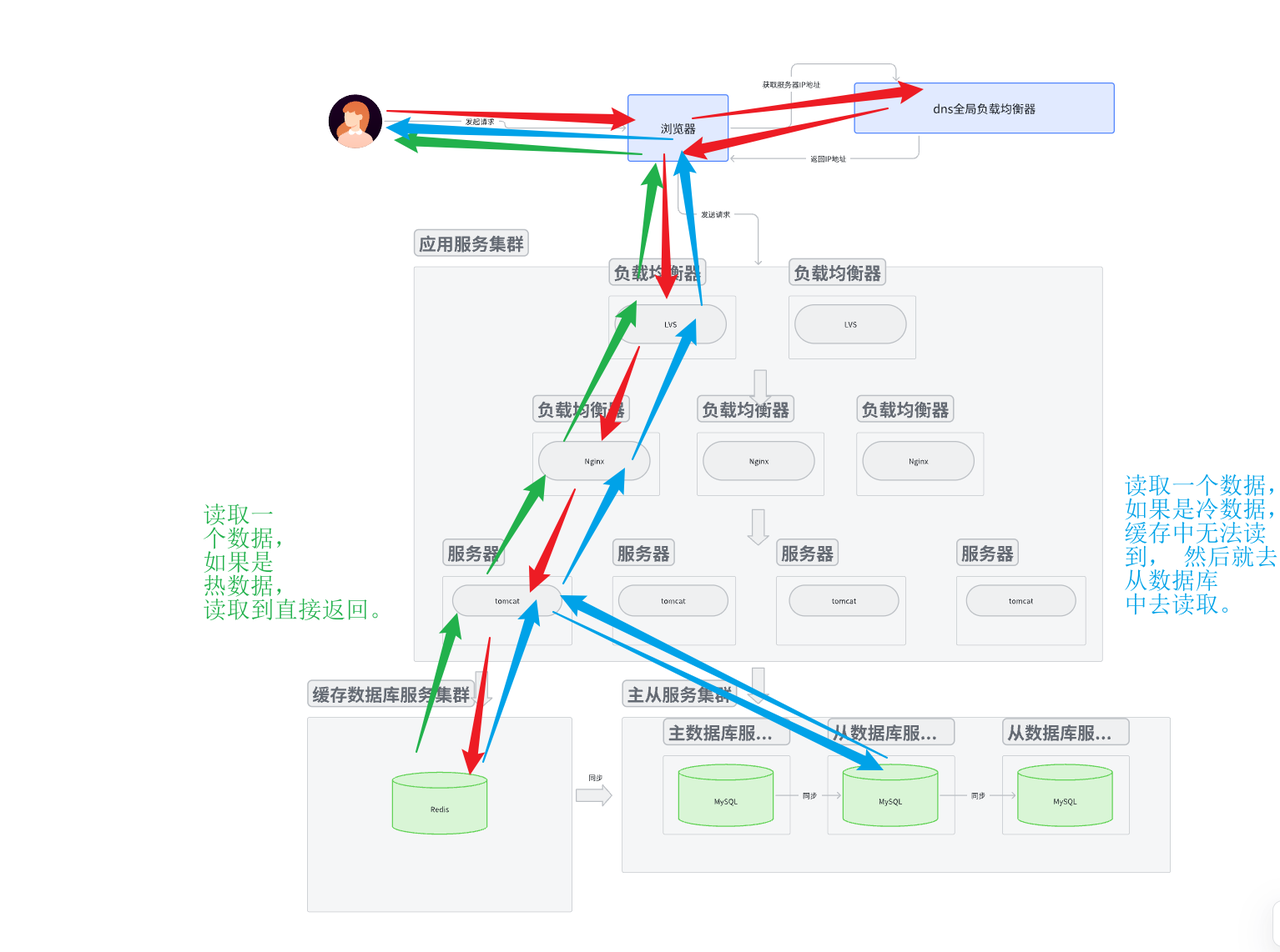
讀數據
- 發送請求, dns返回IP地址, 然后路由到應用服務集群, 應用服務集群再一系列分發處理將請求送到應用服務器。
- 當解析后, 如果是讀數據, 那么就看一下緩存服務器中是否有這個數據, 如果有直接返回。
- 如果沒有找到對應的數據, 就要去主從數據庫集群中去讀取數據。
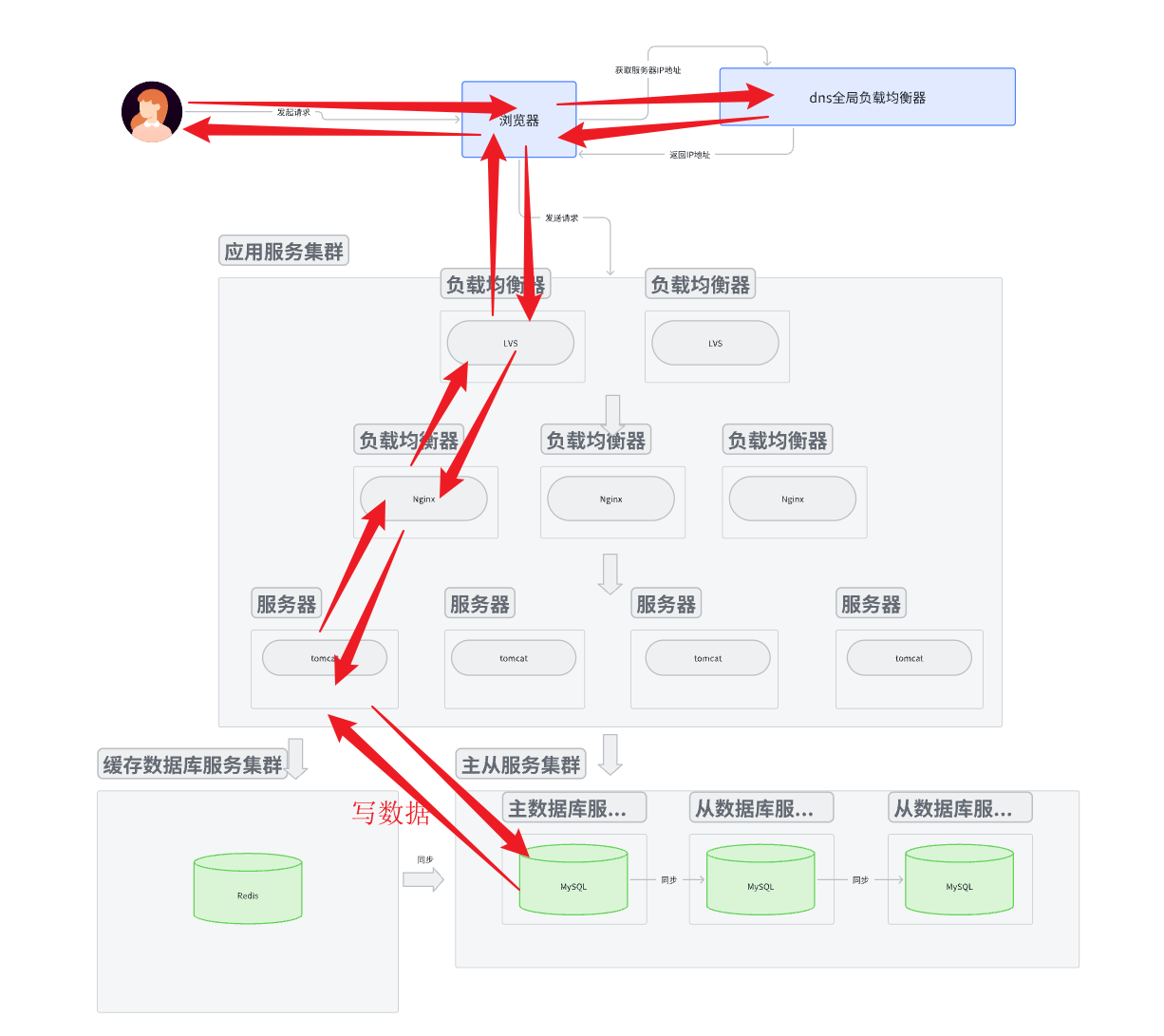
寫數據
- 寫入數據時是否寫入到緩存數據中還是寫入到主數據庫中根據業務場景決定, 一般情況下直接寫入到主數據庫。
- 寫入到主數據庫后, 主數據庫有兩種策略: 一種是直接同步到緩存數據庫, 一種是給緩存數據庫發送一個數據失效標記。 第一種的優點是高一致性, 但是高延遲。 第二種的優點是低延遲, 但是最終一致性(允許數據短暫不一致)

















![[吾愛出品] 【鍵鼠自動化工具】支持識別窗口、識圖、發送文本、按鍵組合等](http://pic.xiahunao.cn/[吾愛出品] 【鍵鼠自動化工具】支持識別窗口、識圖、發送文本、按鍵組合等)

