文章目錄
- 摘要
- 項目地址
- 實戰代碼(初級版)
- 實戰代碼(進階版)
摘要
- 本文介紹了一個完整的機器學習流程項目,重點涵蓋了多元線性回歸的建模與評估方法。項目詳細講解了特征工程中的多項實用技巧,包括:通過np.log變換使數據符合正態分布、離散型數據的one-hot編碼處理、缺失值處理、數據標準化歸一化、以及多項式回歸升維等關鍵技術。此外,項目還特別介紹了使用正則化方法提高模型泛化能力的重要技巧。該研究為機器學習實踐者提供了一個全面的技術參考,特別是在數據預處理和模型優化方面具有較高的實用價值。
項目地址
- 人工智能學習代碼庫
實戰代碼(初級版)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, PolynomialFeatures# 設置全局字體為支持中文的字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑體
plt.rcParams['axes.unicode_minus'] = False # 解決負號 '-' 顯示為方塊的問題# 設置顯示寬度: 解決數據顯示不完整
pd.set_option('display.max_columns', None) # 顯示所有列
pd.set_option('display.width', None) # 自動調整顯示寬度# 1 讀取數據
data =pd.read_csv("./data/insurance.csv")
print(data.head(3))# 2 EDA數探索
# 2.1 原數據右偏
plt.hist(data["charges"])
plt.title("原數據 'charges' 的分布")
plt.xlabel("charges")
plt.ylabel("頻數")
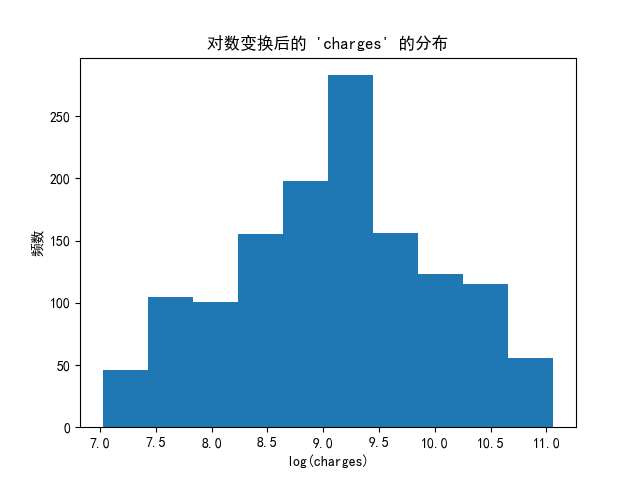
plt.show()# 2.2 矯正后的數據
plt.hist(np.log(data["charges"]))
plt.title("對數變換后的 'charges' 的分布")
plt.xlabel("log(charges)")
plt.ylabel("頻數")
plt.show()# 3 特征工程# 3.1 非數值型的列離散化
data=pd.get_dummies(data,columns=["sex","smoker","region"])
data.head(3)# 3.2 刪除目標列 花銷一列
x=data.drop("charges",axis=1)
y=data['charges']# 3.3 缺失值填充
x.fillna(0,inplace=True)
y.fillna(0,inplace=True)
# 3.4 數據切分 訓練集(70%)和測試集(30%)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)# 3.5 標準歸一化(均值歸一化+方差歸一化) 確保訓練集和測試集的均值和方差相同
scaler=StandardScaler(with_mean=True,with_std=True).fit(x_train)
# 對訓練集進行擬合并轉換
x_train_scaled = scaler.transform(x_train)
# 對測試集進行轉換(使用訓練集的均值和標準差)
x_test_scaled = scaler.transform(x_test)# 3.6 升維 增加Y的維度或因素 利用線性模型做回歸
polynomial_features = PolynomialFeatures(degree=2, include_bias=False)
x_train_scaled = polynomial_features.fit_transform(x_train_scaled)
x_test_scaled = polynomial_features.fit_transform(x_test_scaled)# 4 模型訓練 Ridge=LinearRegression+L2正則化reg=Ridge(alpha=10.0)
reg.fit(x_train_scaled,np.log1p(y_train)) #np.log1p對log函數的優化
y_predict=reg.predict(x_test_scaled)# 5 模型評估
'''
RMSE(均方根誤差)和 MSE(均方誤差)是常用的模型評估指標,用于衡量模型預測值與真實值之間的差異。''''''
對數變換后的 RMSE
重要性:這些指標衡量了模型在對數變換后的目標變量上的預測誤差。對數變換通常用于處理右偏分布的數據,使其更接近正態分布。因此,這些指標可以幫助你了解模型在對數空間中的表現。
適用場景:當你希望模型在對數空間中表現良好時,這些指標非常重要。
'''# 計算訓練集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
rmse_train_log = np.sqrt(mean_squared_error(y_true=np.log1p(y_train), y_pred=reg.predict(x_train_scaled)))
print(f"訓練集上對數變換后的 RMSE: {rmse_train_log}")# 計算測試集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
rmse_test_log = np.sqrt(mean_squared_error(y_true=np.log1p(y_test), y_pred=y_predict))
print(f"測試集上對數變換后的 RMSE: {rmse_test_log}")# 計算訓練集上對數變換后的真實值與預測值之間的均方誤差(MSE)
mse_train_log = mean_squared_error(y_true=np.log1p(y_train), y_pred=reg.predict(x_train_scaled))
print(f"訓練集上對數變換后的 MSE: {mse_train_log}")# 計算測試集上對數變換后的真實值與預測值之間的均方誤差(MSE)
mse_test_log = mean_squared_error(y_true=np.log1p(y_test), y_pred=y_predict)
print(f"測試集上對數變換后的 MSE: {mse_test_log}")'''
還原后的 RMSE
重要性:這些指標衡量了模型在原始目標變量上的預測誤差。還原后的 RMSE 更直觀地反映了模型在實際數據尺度上的表現。
適用場景:當你希望模型在原始數據尺度上表現良好時,這些指標非常重要。
'''# 計算訓練集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
rmse_train_exp = np.sqrt(mean_squared_error(y_true=y_train, y_pred=np.exp(reg.predict(x_train_scaled))))
print(f"訓練集上還原后的 RMSE: {rmse_train_exp}")# 計算測試集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
rmse_test_exp = np.sqrt(mean_squared_error(y_true=y_test, y_pred=np.exp(y_predict)))
print(f"測試集上還原后的 RMSE: {rmse_test_exp}")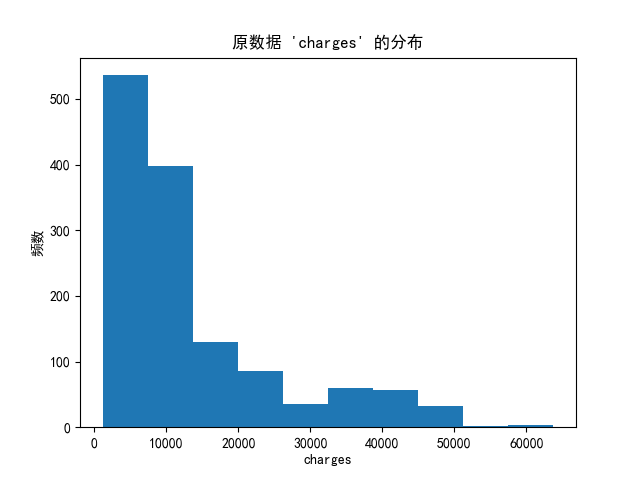
age sex bmi children smoker region charges
0 19 female 27.90 0 yes southwest 16884.9240
1 18 male 33.77 1 no southeast 1725.5523
2 28 male 33.00 3 no southeast 4449.4620
訓練集上對數變換后的 RMSE: 0.35492916766241805
測試集上對數變換后的 RMSE: 0.3896820204464227
訓練集上對數變換后的 MSE: 0.12597471405753685
測試集上對數變換后的 MSE: 0.1518520770592062
訓練集上還原后的 RMSE: 4940.399449726374
測試集上還原后的 RMSE: 5243.354576700596
實戰代碼(進階版)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures# 設置全局字體為支持中文的字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑體
plt.rcParams['axes.unicode_minus'] = False # 解決負號 '-' 顯示為方塊的問題# 設置顯示寬度: 解決數據顯示不完整
pd.set_option('display.max_columns', None) # 顯示所有列
pd.set_option('display.width', None) # 自動調整顯示寬度# 1 讀取數據
data = pd.read_csv("./data/insurance.csv")
print("原數據:")
print(data.head(3))# 2 EDA數探索
# 2.1 原數據右偏
plt.hist(data["charges"])
plt.title("原數據 'charges' 的分布")
plt.xlabel("charges")
plt.ylabel("頻數")
plt.show()# 2.2 矯正后的數據
plt.hist(np.log(data["charges"]))
plt.title("對數變換后的 'charges' 的分布")
plt.xlabel("log(charges)")
plt.ylabel("頻數")
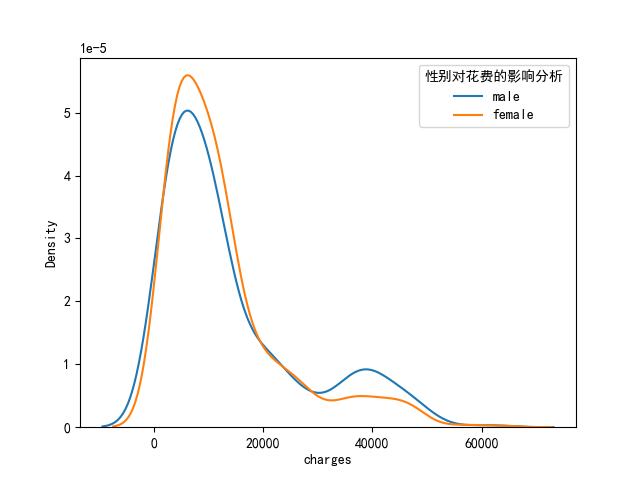
plt.show()# 2.2 性別對花費的影響分析
sns.kdeplot(data.loc[data.sex == "male", "charges"], label='male')
sns.kdeplot(data.loc[data.sex == "female", "charges"], label='female')
plt.legend(title="性別對花費的影響分析")
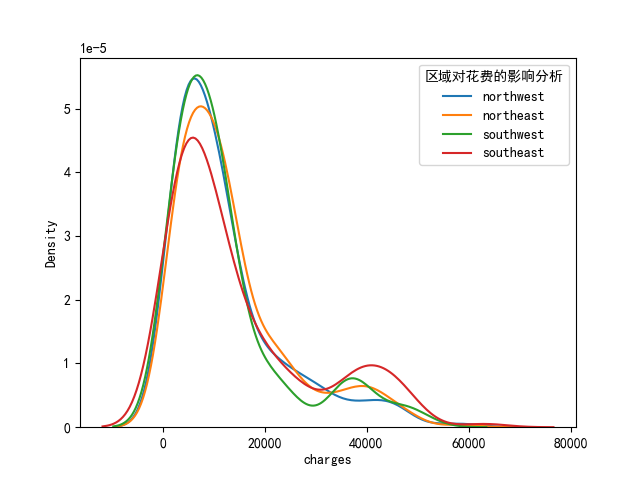
plt.show()# 2.3 區域對花費的影響分析
sns.kdeplot(data.loc[data.region == "northwest", "charges"], label='northwest')
sns.kdeplot(data.loc[data.region == "northeast", "charges"], label='northeast')
sns.kdeplot(data.loc[data.region == "southwest", "charges"], label='southwest')
sns.kdeplot(data.loc[data.region == "southeast", "charges"], label='southeast')
plt.legend(title="區域對花費的影響分析")
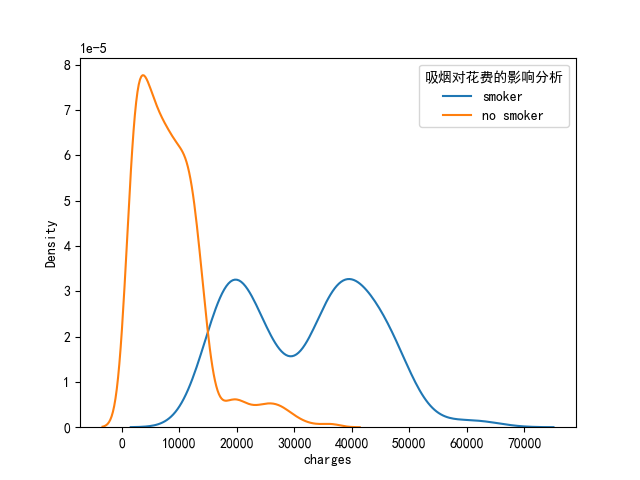
plt.show()# 2.4 吸煙對花費的影響分析
sns.kdeplot(data.loc[data.smoker == "yes", "charges"], label='smoker')
sns.kdeplot(data.loc[data.smoker == "no", "charges"], label='no smoker')
plt.legend(title="吸煙對花費的影響分析")
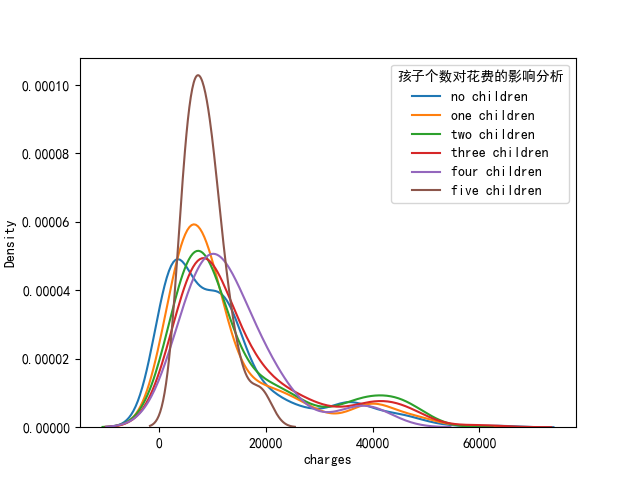
plt.show()# 2.5 孩子個數對花費的影響分析
sns.kdeplot(data.loc[data.children == 0, "charges"], label='no children')
sns.kdeplot(data.loc[data.children == 1, "charges"], label='one children')
sns.kdeplot(data.loc[data.children == 2, "charges"], label='two children')
sns.kdeplot(data.loc[data.children == 3, "charges"], label='three children')
sns.kdeplot(data.loc[data.children == 4, "charges"], label='four children')
sns.kdeplot(data.loc[data.children == 5, "charges"], label='five children')
plt.legend(title="孩子個數對花費的影響分析")
plt.show()# 3 特征工程
# 3.1 刪除系數相關低的列 region、sex
data = data.drop(["region", "sex"], axis=1)
print("刪除系數相關低的列 region、sex")
print(data.head(3))# 3.2 降噪 連續值變為離散值
def greater(df, bmi, num_child):df['bmi'] = 'over' if df['bmi'] >= bmi else 'under'df['children'] = 'no' if df['children'] == num_child else 'yes'return dfdata = data.apply(greater, axis=1, args=(30, 0))# 3.3 非數值型的列離散化
data = pd.get_dummies(data)
print("bmi,num_child連續值變為離散值")
print(data.head(3))# 3.4 刪除目標列 花銷一列
x = data.drop("charges", axis=1)
y = data['charges']# 3.5 缺失值填充
x.fillna(0, inplace=True)
y.fillna(0, inplace=True)# 3.6 數據切分 訓練集(70%)和測試集(30%)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)# 3.7 升維 增加Y的維度 利用線性模型做回歸
polynomial_features = PolynomialFeatures(degree=2, include_bias=False)
x_train_poly = polynomial_features.fit_transform(x_train)
x_test_poly = polynomial_features.fit_transform(x_test)# 4 模型訓練 Ridge=LinearRegression+L2正則化
reg = Ridge(alpha=10.0)reg.fit(x_train_poly, np.log1p(y_train)) # np.log1p對log函數的優化
y_predict = reg.predict(x_test_poly)# 5 模型評估
# 計算訓練集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
print("計算訓練集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)")
print(np.sqrt(mean_squared_error(y_true=np.log1p(y_train), y_pred=reg.predict(x_train_poly))))# 計算測試集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
print("計算測試集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)")
print(np.sqrt(mean_squared_error(y_true=np.log1p(y_test), y_pred=y_predict)))# 計算訓練集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
print("計算訓練集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)")
print(np.sqrt(mean_squared_error(y_true=y_train, y_pred=np.exp(reg.predict(x_train_poly)))))# 計算測試集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
print("計算測試集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)")
print(np.sqrt(mean_squared_error(y_true=y_test, y_pred=np.exp(y_predict))))
原數據:age sex bmi children smoker region charges
0 19 female 27.90 0 yes southwest 16884.9240
1 18 male 33.77 1 no southeast 1725.5523
2 28 male 33.00 3 no southeast 4449.4620
刪除系數相關低的列 region、sexage bmi children smoker charges
0 19 27.90 0 yes 16884.9240
1 18 33.77 1 no 1725.5523
2 28 33.00 3 no 4449.4620
bmi,num_child連續值變為離散值age charges bmi_over bmi_under children_no children_yes smoker_no smoker_yes
0 19 16884.9240 False True True False False True
1 18 1725.5523 True False False True True False
2 28 4449.4620 True False False True True False
計算訓練集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
0.38316517904805586
計算測試集上對數變換后的真實值與預測值之間的均方根誤差(RMSE)
0.3812317453220069
計算訓練集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
4746.576620613462
計算測試集上真實值與預測值(經過指數變換還原)之間的均方根誤差(RMSE)
4899.862272153837






)






- 正確用法 - 年均收益18%)


)


