論文地址:https://github.com/hustvl/VAD
代碼地址:https://arxiv.org/pdf/2303.12077
1. 摘要
自動駕駛需要對周圍環境進行全面理解,以實現可靠的軌跡規劃。以往的方法依賴于密集的柵格化場景表示(如:占據圖、語義地圖)來進行規劃,這種方式計算量大,且缺乏實例級的結構信息。
本文提出了 VAD(Vectorized Autonomous Driving),一種端到端的向量化自動駕駛范式,將駕駛場景建模為完全向量化的表示方式。這一范式具有兩大優勢:
一方面,VAD 利用向量化的動態目標運動信息與地圖元素作為顯式的實例級規劃約束,從而有效提升了規劃的安全性;
另一方面,VAD 摒棄了計算密集的柵格表示和手工設計的后處理步驟,因此比以往端到端方法運行速度更快。
在 nuScenes 數據集上,VAD 實現了當前最優的端到端規劃性能,在多個指標上大幅超越現有最優方法。基礎模型 VAD-Base 將平均碰撞率降低了 29.0%,運行速度提升了 2.5 倍;而輕量版本 VAD-Tiny 在保持可比規劃性能的同時,實現了高達 9.3 倍的推理速度提升。
2. 方法
VAD 的整體框架如圖 2所示。輸入為多幀、多視角的圖像,輸出為自車未來的規劃軌跡。VAD 的框架分為四個階段:
Backbone:提取圖像特征并投影為 BEV(Bird’s-Eye View)特征;
Vectorized Scene Learning:構建向量化的地圖與運動表示;
Planning(推理階段):通過 ego query 與地圖/目標交互,生成未來軌跡;
Planning(訓練階段):引入三種向量化約束,對軌跡進行訓練正則化。
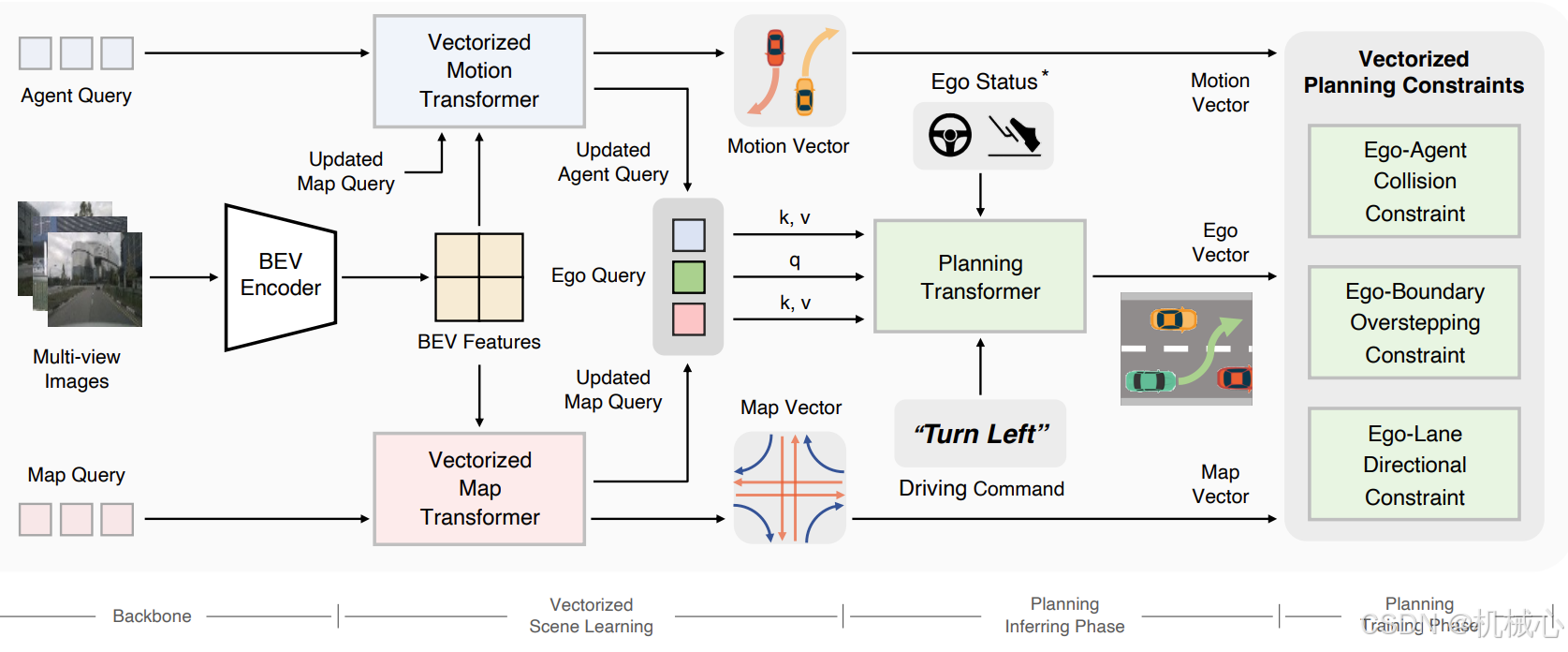
2.1?向量化場景學習
VAD使用 ResNet50 提取圖像特征,經過多層卷積神經網絡提取圖像的低級和高級特征。使用 BEV Encoder 將圖像特征通過空間映射轉換為 Bird’s Eye View(BEV)特征圖,并使用 Transformer 對其進行進一步的處理,學習圖像的全局語義和空間關系。
向量化地圖
相比柵格化語義地圖,向量化表示能保留更細致的結構信息。論文使用一組 Map Query?,從 BEV 特征中提取地圖元素,如:車道線(lane divider)、道路邊界(road boundary)以及人行道(pedestrian crossing),每個地圖元素表示為 一組點(polyline),并附帶類別信息。
是可學習的embedding,類似 DETR 中的 Object Query,維度為100xC(例如100個地圖目標),Vecorized Map Transformer使用的是典型的Transformer Decoder結構,先進行self-attention,然后在進行cross-attention,最終輸出向量維度為MxD,然后經過地圖head可以解析出來就是100x20x2,也就是100個目標,每個目標數據點個數為20個,二維坐標。
向量化交通參與者運動預測
為了高效預測交通參與者(如其他車輛、行人等)的未來軌跡,VAD 使用了一種基于向量化表示的方法來描述它們的運動。這一部分的目標是通過 Agent Queries(交通參與者查詢)來學習每個交通參與者的運動特征,并通過 Deformable Attention 機制與環境的 BEV(Bird's-Eye View)特征進行交互,從而預測它們的未來行為。
Agent Queries 是一組表示交通參與者(例如其他車輛、行人等)運動特征的查詢向量,每個 Agent Query 用來捕捉交通參與者的狀態信息,如位置、速度、加速度、方向等。論文采用一組可學習的向量,首先進行self-attention,獲得agent-agent之間的交互,然后query與BEV特征和更新的map queries進行交叉注意力,其中與BEV特征進行交叉注意力采用deformable attention的方法,最終獲得輸出的特征向量AxD。經過運動預測head輸出維度為300x6x12,300個目標,每個目標6個模態,每個模態6幀,每幀2個坐標點。
交互式規劃
在預測模塊之后,VAD 使用一個規劃模塊來為自車(ego vehicle)規劃一條可行的軌跡。與預測模塊中用于運動建模的 Motion Queries 相似,引入了一個專用于 ego vehicle 的查詢向量,稱為 Ego Query,它被輸入到一個新的 Transformer 解碼器中,用于軌跡規劃。為了捕捉自車與其他交通參與者之間的相互作用(agent-agent interaction),將預測模塊中輸出的 Motion Queries 作為上下文(context)輸入到規劃模塊的解碼器中。該機制允許 ego vehicle 考慮其他交通參與者的未來意圖,并進行反應。論文采用一組可學習的向量,維度為
,其中
表示時間步數,如取6。
先進行self-attention,然后ego-agent和ego-map分別進行cross-attention,輸出維度為
。經過軌跡規劃head,輸出為3*6*2,3個模態,每個莫模態6個時間步,每步2個坐標點,其中3個模態論文中設定為右轉、左轉和直行。
3. 總結
論文探索了一種完全向量化的駕駛場景表示方法,以及如何有效地將這種向量化場景信息融合到系統中以提升自動駕駛的規劃性能。VAD 同時達成了高性能與高效率的結合,使用 NVIDIA GeForce RTX 3090 GPU,VAD-Tiny推理時間在50-60ms之間。此外,VAD 支持對其他動態交通參與者的多模態運動軌跡預測。與此同時,如何將更多的交通信息(例如:車道圖、交通標志、信號燈、限速信息等)融入此類自動駕駛系統,也是一個具有發展前景的研究方向。




機器學習---決策樹和隨機森林)





)



)


)

