在數字經濟高速發展的今天,算力已成為驅動科技創新與產業變革的核心引擎。GPU服務器憑借其強大的并行計算能力,在圖形渲染、人工智能訓練等領域展現出不可替代的優勢;而PC集群則通過分布式架構,以高性價比和靈活擴展特性,支撐起大規模數據處理與實時服務需求。兩者如同科技算力領域的雙子星,共同推動著從云游戲到科學計算的多元應用場景突破。尤其在游戲即服務(GaaS)、跨媒體娛樂等新興領域,GPU服務器與PC集群的協同應用正在重塑行業格局,使高品質游戲體驗擺脫硬件限制,實現真正的全民可及。
算力需求的爆發式增長催生計算架構的多元化發展。全球數據中心算力總量持續攀升,其中GPU服務器與PC集群占據重要份額。這種算力分布格局印證了兩種架構在不同場景下的互補性 —— 當需要處理單任務復雜度高、實時性要求強的工作時,GPU服務器成為首選;而面對大規模并發、分布式處理需求時,PC集群展現出獨特優勢。在云游戲這類融合了圖形渲染與高并發特性的場景中,兩者的協同更是成為技術突破的關鍵。
GPU 服務器:圖形與加速的利刃
(一)GPU服務器的基本原理
GPU服務器是一種以圖形處理器(GPU)為核心計算單元的專用服務器,其核心優勢源于GPU的并行計算架構。與CPU的少量高性能核心設計不同,GPU集成了數千個流處理器,能夠同時執行大量重復計算任務。在圖形渲染場景中,GPU通過并行處理頂點著色、像素填充等操作,將3D模型快速轉換為二維圖像;而在計算加速領域,其多核心架構可同時處理海量數據,如深度學習中的矩陣運算、科學模擬中的粒子動力學計算等。這種架構特性使GPU服務器既能滿足高精度圖形處理需求,又能為復雜計算任務提供遠高于CPU的效率提升。
現代GPU服務器采用異構計算架構,通過高速總線實現GPU與CPU的高速通信,確保數據在處理器與顯存間高效流轉。在內存配置上,高端GPU服務器支持大容量內存與高速顯存組合,可同時緩存海量訓練數據與中間計算結果。為應對高負載場景,其電源模塊采用冗余設計,配合高效散熱系統,可將GPU核心溫度穩定控制在合理范圍內,保障持續高負載運行時的穩定性。

GPU服務器
(二)GPU服務器的關鍵優勢
1、強大的并行計算能力:
在深度學習訓練中,GPU服務器可同時處理大量樣本數據,大幅縮短模型收斂時間。OpenAI在訓練GPT-3模型時,使用由數千塊NVIDIA GPU 組成的GPU服務器集群,通過并行計算,大大加速了模型的訓練過程,使得原本需要數年時間的訓練任務得以在較短時間內完成。這種效率差距在基因測序分析中同樣顯著,GPU加速的基因比對算法能大幅壓縮全基因組分析時間。
在流體力學模擬領域,GPU服務器的并行計算能力更為突出。模擬大量粒子的運動軌跡時,GPU服務器的計算效率遠高于CPU服務器。在對航空發動機內部氣流進行模擬時,使用GPU服務器能夠快速準確地模擬出氣流的復雜流動情況,為發動機的設計優化提供有力支持。同時大幅提升使氣象預測模型的精度。
2、出色的圖形處理性能:
GPU服務器的專用渲染管線可實時處理復雜光影效果與物理模擬。在3A游戲開發中,開發者通過GPU服務器集群進行幀渲染測試,能大幅提升渲染工作效率。《賽博朋克2077》在開發過程中,利用GPU服務器集群進行渲染,使得游戲中的城市夜景、光線追蹤等特效得以完美呈現,為玩家帶來沉浸式的視覺體驗。影視制作領域,復雜場景的渲染依賴GPU服務器陣列,確保虛擬環境的逼真呈現。像《阿凡達》《指環王》等電影的特效制作,都大量運用GPU服務器進行渲染,創造出了令人驚嘆的視覺效果。
在建筑可視化領域,GPU服務器支持的實時渲染技術改變設計流程。設計師通過云端GPU服務器可實時預覽建筑模型在不同光照條件下的呈現效果,大幅縮短修改反饋時間,使整個設計周期顯著縮短。
3、在邊緣計算中的適配性:
現代GPU服務器采用模塊化設計,支持多塊GPU直接掛載于單節點,并通過高性能處理器實現算力協調。這種架構使其能部署于邊緣節點,為云游戲等低延遲需求場景提供支撐。用戶在玩《原神》等大型游戲時,通過邊緣節點的GPU服務器進行渲染,游戲畫面的延遲可控制在幾十毫秒以內,接近本地運行體驗。
邊緣部署的GPU服務器還具備網絡切片能力,可同時為云游戲、AR導航等多類應用分配獨立算力資源。測試顯示,采用這種架構的邊緣節點,在同時承載多種服務請求時,各類服務的延遲波動較小,確保多場景并發下的服務質量。某大型商場部署邊緣GPU服務器,為顧客提供云游戲體驗和AR導航服務。通過網絡切片技術,兩種服務都能夠穩定運行,用戶在享受游戲樂趣的同時,也能通過AR導航快速找到自己想去的店鋪。
(三)GPU服務器的應用領域
1、深度學習與人工智能:
領先AI研究機構在訓練大語言模型時,采用了由大量GPU服務器組成的集群,通過分布式訓練框架實現了大規模參數模型的收斂。Google的BERT模型、字節跳動的云雀模型等,都是在大規模GPU服務器集群上訓練完成的。在計算機視覺領域,GPU服務器支撐的實時目標檢測系統可高效處理圖像數據,準確率高,廣泛應用于自動駕駛、安防監控等場景。以特斯拉的自動駕駛系統為例,車輛上搭載的GPU芯片能夠實時處理攝像頭采集的圖像數據,快速識別道路上的行人、車輛和交通標志,保障了自動駕駛的安全性。
在智能推薦系統中,GPU服務器的并行計算能力使實時個性化推薦成為可能。電商平臺部署的GPU加速推薦引擎,可快速為用戶生成個性化列表,推薦準確率較傳統方法有顯著提升,帶動平臺轉化率增長。
2、科學研究與計算:
能源領域研究機構利用GPU服務器模擬等離子體運動,大幅縮短了流體動力學計算時間,為可控核聚變研究提供了關鍵算力支持。在國際熱核聚變實驗堆(ITER)項目中,使用GPU服務器進行等離子體模擬,幫助科學家更好地理解和控制核聚變反應過程。在生物醫藥領域,GPU加速的分子動力學模擬能實時預測藥物分子與靶點蛋白的結合模式,使新型藥物研發周期大幅縮短。
氣候研究領域,GPU服務器集群支撐的全球氣候模型可同時模擬大氣、海洋、陸地生態系統的交互作用,大幅壓縮氣候預測的計算時間,使科研人員能更高效地評估不同減排方案對全球氣溫的影響。如中國氣象局利用GPU服務器集群進行氣候模擬,將原來需要數周的計算時間縮短至數天,為氣候變化研究提供了更及時的數據支持。
3、云游戲與跨媒體娛樂:
云游戲服務提供商與邊緣計算解決方案企業合作推出的云游戲平臺,在多個邊緣節點部署了高性能GPU服務器。支持多款3A游戲的云端運行,用戶無需高端顯卡,僅通過普通設備即可體驗高品質畫質,單臺服務器可同時承載一定數量的并發用戶。例如,網易云游戲平臺在全國多個城市的邊緣節點部署GPU服務器,用戶可以在手機、平板等設備上流暢運行《永劫無間》等大型游戲,享受與本地游戲主機相當的游戲體驗。
在互動娛樂領域,GPU服務器還支撐著虛擬演唱會的實時渲染。音樂平臺舉辦的虛擬偶像演唱會,通過GPU服務器組成的集群,可實現大量觀眾同時在線互動,每位觀眾可自由切換視角,系統實時渲染延遲控制在較低水平,創造了沉浸式的線上娛樂體驗。支持數百萬觀眾同時在線觀看和互動,觀眾可以自由選擇不同的視角,感受身臨其境的演唱會氛圍。

AI 一體機
PC集群:分布式計算的力量
(一)PC集群的構成與原理
PC集群是由多臺標準化PC節點通過高速網絡互聯形成的分布式計算系統,其核心原理是將復雜任務拆解為子任務,通過負載均衡算法分配至不同節點并行處理。現代PC集群采用機架式整合設計,在一定空間內集成多個雙GPU節點,通過背板與管理單元實現集中管控。每個節點保持獨立供電與散熱,支持熱插拔維護,單個節點故障不影響整體集群運行。既保留PC的高主頻優勢,又具備服務器級的穩定性與可管理性,特別適合對成本敏感且需靈活擴展的場景。
PC集群的網絡架構采用高速網絡技術,節點間數據傳輸速率高,確保分布式任務的協同效率。在存儲層面,通過分布式文件系統實現數據統一管理,單集群可掛載大容量存儲空間,滿足大規模數據處理需求。管理軟件支持節點健康監控、任務調度與資源分配,管理員可通過可視化界面實時掌握集群負載狀態,當檢測到節點故障時,系統會自動將任務遷移至健康節點,保障服務連續性。通過分布式文件系統,實現對海量用戶數據的高效存儲和管理。管理軟件能夠實時監控每個節點的CPU、內存、磁盤等資源使用情況,當某個節點出現故障時,能夠在數秒內將任務自動遷移到其他健康節點,保障業務的正常運行。
(二)PC集群的顯著特點
1、可擴展性強:
PC集群采用模塊化設計,支持節點數量線性擴展。可容納多個單GPU節點,通過集群管理軟件可無縫擴展至大規模節點規模。電商平臺在促銷活動期間,通過臨時增加PC節點,可顯著提升訂單處理能力,確保系統穩定運行。
在計算能力擴展方面,PC集群的線性擴展特性表現突出。當節點數量增加時,集群的總算力接近理想線性增長。這種特性使科研機構可根據項目需求分階段投入,初期部署小規模集群,隨著研究深入逐步擴展算力。例如,某科研機構在進行天體物理研究時,初期搭建了一個由10個節點組成的PC集群。隨著研究的深入,數據量和計算需求不斷增加,該機構通過逐步添加節點,將集群規模擴展到了100個節點,計算能力也相應得到了大幅提升,滿足了研究的需求。
2、成本效益高:
相比同等算力的大型服務器,PC集群的硬件成本可顯著降低。一套支持一定數量并發用戶的云游戲PC集群,初期投入遠低于同等性能的GPU服務器方案。PC集群的電力消耗更低,適合大規模部署。據統計,PC集群的硬件成本相比同等算力的大型服務器可降低30%-50%,電力消耗可降低20%-30%。
在全生命周期成本方面,PC集群的優勢更為明顯。數據中心的統計顯示,PC集群的三年總擁有成本(TCO)低于同等算力的專用服務器集群,成本差異主要來自硬件采購、電力消耗與維護費用三個方面。
3、管理效率優化:
集成管理單元的PC集群支持遠程開關機、硬件狀態監控與畫面采集,管理員可通過控制臺同時管理多個節點。高端方案還具備智能溫控功能,根據負載自動調節風扇轉速,降低機房噪音,延長硬件壽命。管理員可以通過一個統一的控制臺,對分布在不同區域的數百個節點進行遠程管理。系統能夠實時監控每個節點的CPU溫度、硬盤健康狀況等。智能溫控功能根據節點的負載情況自動調節風扇轉速,降低噪音,延長硬件的使用壽命。
自動化運維系統可實現固件升級、驅動更新的批量操作,大幅縮短維護工作時間。系統還具備故障預警能力,通過分析硬件運行參數,可提前預測潛在故障,減少計劃外停機時間
(三)PC集群的應用場景
1、云游戲與云電競:
電信運營商采用機架式集群構建的云游戲平臺,每節點支持多路GPU同時運行,單集群可承載一定數量的用戶并發游玩主流競技游戲。通過邊緣節點部署,該平臺將操作延遲控制在合理范圍內,支持多終端無縫切換,用戶留存率較傳統下載模式有顯著提升。某云游戲平臺,在全國多個城市的邊緣節點部署機架式PC集群。每個節點配備高性能的GPU,支持多名用戶同時在線游玩《英雄聯盟》《王者榮耀》等熱門競技游戲。用戶通過手機、電腦等終端接入平臺,操作延遲可控制在50毫秒以內,與本地游戲體驗幾乎無異,用戶留存率相比傳統下載模式提高30%。
在云電競場景中,PC集群的多節點協同能力得到充分發揮。電競賽事平臺通過PC集群為大量觀眾提供實時賽事轉播,同時支持觀眾進行實時互動投票,系統響應延遲穩定在合理范圍內,確保大規模并發下的服務流暢性。某知名電競賽事平臺在舉辦大型賽事時,利用PC集群為全球數百萬觀眾提供實時賽事轉播。觀眾可以在觀看比賽的同時,進行實時互動投票,如評選最佳選手、預測比賽結果等。PC集群強大的處理能力確保了系統在大規模并發情況下,響應延遲穩定在100毫秒以內,為觀眾帶來了流暢的觀賽體驗。
2、大規模渲染農場:
影視后期公司采用PC集群搭建分布式渲染系統,多個節點協同工作時,可在較短時間內完成動畫電影的全片渲染。相比傳統工作站,效率大幅提升,且通過節點負載均衡避免資源閑置,硬件利用率顯著提高。皮克斯動畫工作室在制作《玩具總動員》系列電影時,采用大規模的PC集群進行渲染。通過分布式渲染系統,將渲染任務分配到各個節點上并行處理,使得原本需要數月時間的渲染工作縮短至數周,大大提高制作效率。
建筑設計領域的渲染農場同樣依賴PC集群。建筑設計院的PC集群可同時處理多個建筑項目的渲染任務,單項目的渲染時間大幅縮短,使設計方案的評審周期顯著縮短,客戶滿意度提升。
3、企業級虛擬化服務:
金融機構采用PC集群構建虛擬桌面基礎設施(VDI),少量節點可支持大量員工同時使用辦公軟件與數據分析工具。集群的熱插拔特性確保單點維護不中斷服務,年度運維成本降低,數據安全性通過節點間冗余備份得到保障。銀行利用PC集群構建了VDI系統,為全行數千名員工提供虛擬桌面服務。員工可以通過瘦客戶端接入虛擬桌面,使用辦公軟件、進行數據分析等工作。由于PC集群的熱插拔特性,當某個節點出現故障時,可在不中斷服務的情況下進行更換,年度運維成本明顯降低。通過節點間的數據冗余備份,確保數據的安全性,有效防止了數據丟失。
制造業企業通過PC集群部署的虛擬生產系統,支持大量工程師同時訪問CAD軟件與產品數據庫。測試顯示,工程師打開3D模型的響應時間大幅縮短,設計變更的協同效率提升,顯著加快新產品研發速度。汽車制造企業采用PC集群搭建虛擬生產系統后,工程師打開復雜的汽車3D模型的響應時間從原來的幾分鐘縮短至幾秒,設計變更時的協同效率顯著提高,縮短新產品的研發周期,快速響應市場需求。
云游戲領域的協同實踐
(一)云游戲技術架構中的算力支撐
云游戲的核心挑戰在于如何在低延遲前提下,將高質量游戲畫面從云端傳輸至終端。這一過程需要GPU服務器與PC集群的協同支撐:GPU服務器負責游戲畫面實時渲染,PC集群則處理用戶輸入響應、數據轉發與負載調度。某云游戲平臺的技術棧包含三個層級,充分體現這種協同架構的優勢。

PC農場案例 -提升云游戲競爭力
1、渲染層:
基于邊緣GPU基礎設施,采用高性能服務器,每臺配置多塊GPU,支持多款游戲的高品質渲染,通過多個全球邊緣節點實現就近服務。渲染層采用動態資源分配機制,當檢測到某區域用戶激增時,自動從鄰近節點調度空閑GPU資源,確保單用戶可用算力穩定。在節假日游戲高峰期,某區域的云游戲用戶數量突然增加,渲染層通過動態調度,從周邊節點調配足夠的GPU資源,保證用戶的游戲體驗不受影響。
2、管理層:
由PC集群構成的數字內容處理中心處理用戶請求路由、游戲元數據關聯與跨媒體推薦,如將熱門影視IP觀眾引導至同款游戲體驗,實現內容交叉引流。管理層的負載均衡算法可根據用戶地理位置、網絡狀況分配最優節點,使請求處理效率提升。比如,當用戶位于網絡條件較差的地區時,管理層會將其請求分配到距離最近、網絡狀況相對較好的節點,提高請求處理的成功率。
3、傳輸層:
混合云架構通過PC集群的負載均衡算法,動態分配帶寬資源,確保不同網絡環境下的流暢體驗,丟包補償技術使畫面卡頓率大幅降低。傳輸層還采用自適應編碼技術,根據用戶網絡帶寬實時調整畫質參數,在帶寬波動時優先保障幀率穩定。當用戶的網絡帶寬突然下降時,傳輸層會自動降低畫質分辨率,但保持幀率不變,避免游戲畫面的卡頓。
(二)商業落地與用戶體驗優化
某云游戲平臺自上線以來,以親民的訂閱價提供電影、音樂、游戲等一站式服務,其中多款云端游戲成為核心賣點。其成功得益于GPU服務器與PC集群的技術協同,在多個關鍵指標上表現優異:

PC集群案例 - AIGC
1、硬件效率:
高性能服務器的每GPU并發用戶數較行業平均水平有顯著提升;PC集群的節點利用率穩定在較高水平,較傳統架構降低能耗。通過動態資源調度,平臺在用戶高峰時段的硬件利用率可達到較高水平,大幅提升投資回報率。
2、用戶體驗:
通過邊緣節點部署,大部分用戶的游戲延遲控制在較低水平,操作響應接近本地設備;跨媒體功能使游戲用戶日均使用時長增加,平臺ARPU值提升。用戶調研顯示,該平臺的畫面質量滿意度與操作流暢度評分均高于行業平均水平。超過80%的用戶表示,游戲延遲在可接受范圍內,與本地游戲體驗相差不大。
3、擴展能力:
集群的模塊化設計使平臺能根據用戶增長快速擴容,在用戶規模增長時,僅通過增加一定數量的GPU服務器與PC集群即完成算力升級,停機時間控制在較短范圍內。這種快速擴展能力使平臺成功應對了節假日用戶激增的流量沖擊。重大節假日期間,用戶數量較平時增長數倍,通過快速增加GPU服務器和PC集群節點完成算力升級,確保用戶的正常使用。
(三)技術創新與行業影響
云游戲場景的技術創新正反向推動GPU服務器與PC集群的迭代,形成了技術進步與應用需求的良性循環:
1、GPU虛擬化技術:
通過容器化部署,單GPU可同時分配給多名用戶使用,資源利用率顯著提升,且支持重度游戲與輕量游戲的混合部署。虛擬化層采用隔離技術,確保不同用戶的算力資源互不干擾,在同時運行多種類型游戲時,單GPU的性能波動較小。例如,某云游戲平臺采用GPU虛擬化技術后,單GPU的資源利用率提高了50%以上,同時運行《原神》等重度游戲和《斗地主》等輕量游戲時,性能波動控制在5%以內。
2、智能調度算法:
PC集群的負載管理系統能根據游戲類型動態分配算力,如將競技游戲優先調度至低延遲節點,將休閑游戲分配至普通節點,使硬件成本降低。算法還能學習用戶行為模式,在高峰時段提前調度資源,縮短等待時間。采用這種智能調度算法后,該平臺的硬件成本降低大幅降低,用戶在高峰時段的等待時間大大縮短。
3、跨媒體生態構建:
借助API的元數據整合能力,游戲與影視內容形成聯動推薦,如用戶觀看熱門電影后,平臺自動推送同款游戲試玩,這種模式使游戲轉化率提升,驗證了"內容即服務"的商業可行性。跨媒體推薦系統每天處理大量用戶行為數據,通過PC集群的分布式計算能力,生成個性化推薦列表的時間控制在較短范圍內。
GPU服務器與?PC集群的對比分析
(一)性能表現對比
1、計算密度:
GPU服務器每單位空間可提供較高的算力,適合處理單任務復雜度高的場景;PC集群單位空間算力相對較低,通過大規模擴展可形成強大的總算力,更適合分布式任務。在訓練復雜模型時,GPU服務器集群完成任務的時間短于同等成本的PC集群,但在處理大量用戶同時在線的輕量游戲時,PC集群的并發支持能力更優。
2、浮點運算精度:
GPU服務器支持多種精度模式,可根據任務需求靈活切換。在科學計算場景中,采用高精度模式的GPU服務器計算誤差率低,滿足高精度計算需求;而PC集群在默認精度下的誤差率雖略高但可通過算法優化彌補,足以應對大部分商業應用。
3、延遲:
GPU服務器的本地計算延遲通常較低,而PC集群因節點間通信開銷,延遲相對較高。這使GPU服務器更適合競技類游戲,而PC集群在休閑游戲中表現更均衡。在網絡傳輸延遲疊加下,部署在邊緣節點的GPU服務器可將端到端延遲控制在較低范圍內,而PC集群則相對較高,這種差異成為競技游戲選擇GPU服務器的關鍵因素。
(二)成本結構差異
1、初期投入:
GPU服務器單節點成本約為PC節點的數倍(以同等算力計),但在長期運行中,GPU服務器的能效比更高,單位算力功耗低于PC集群。對于一定用戶規模的云游戲平臺,GPU服務器方案初期投入較高,年電費較低;PC集群初期投入較低,年電費較高,經過一定時間后總成本基本持平,但若用戶規模進一步擴大,GPU方案的成本優勢開始顯現。
2、維護成本:
PC集群的模塊化設計使單點維護成本降低,但節點數量多導致故障率總和較高;GPU服務器的高集成度降低故障概率,但單節點維修成本更高。數據中心統計顯示,PC集群的年度維護工時多于GPU服務器,但單工時成本低于后者。對于技術團隊規模有限的企業,GPU服務器的低維護頻率更具吸引力。
3、投資回報周期:
小規模部署時PC集群的回報周期較短,GPU服務器則相對較長;但當用戶規模超過一定數量時,GPU服務器的回報周期縮短,而PC集群因能耗成本上升,回報周期延長。這種差異使大型平臺更傾向于選擇GPU服務器,而中小平臺則從PC集群起步。
(三)適用場景
1、GPU服務器更適合以下場景:
需實時渲染的3A游戲、影視特效制作,這類場景要求單節點具備強大圖形處理能力,且延遲敏感;深度學習訓練、科學計算等高密度計算任務,需要高浮點運算精度與內存帶寬;邊緣節點部署,要求低延遲與高算力密度,如5G邊緣云、智能駕駛路側單元。
2、PC集群更適合以下場景:
大規模并發的輕量應用(如網頁游戲、辦公虛擬化),這類場景對單節點算力要求不高,但需支持海量用戶同時在線;預算有限但需靈活擴展的中小企業,可通過逐步增加節點實現算力增長;需節點獨立運行的分布式任務(如渲染農場、數據分發),任務可拆解為子任務并行處理,對節點間通信延遲不敏感。

PC農場全景圖
未來展望:技術演進與場景拓展
(一)硬件架構創新
PC 集群的技術演進,正從 “硬件集群堆砌” 邁向 **“跨維度兼容 + 智能化進化”** 的新周期,其核心價值將圍繞 “全場景適配、智能調度、綠色安全” 深度重構算力供給模式,成為數字經濟時代的基礎設施,通過 “軟件封裝” 中低端 GPU 實現大算力輸出,幫助億萬終端設備解決算力瓶頸問題。
1、兼容基礎上的智能調度革命
跨終端、跨系統、跨架構的廣泛接入,為 PC 集群構建了 “無邊界算力池”,但真正釋放價值的關鍵在于智能資源調度。未來,AI 算法將深度融合硬件異構特性:通過動態識別任務指紋(如工業設計任務調用 GPU 集群、移動辦公適配輕量 CPU 資源 ,以 “軟件封裝” 中低端 GPU 實現大算力輸出,助力終端設備突破算力瓶頸),自動匹配最優硬件組合(跨 Intel/AMD/ 國產架構靈活調度),并隨任務進程實時調整資源分配 —— 如對計算密集型深度學習任務,自動聚合飛騰、鯤鵬等國產架構算力,將資源利用率從當前 60% 提升至 80%+,讓 “閑置算力零浪費” 成為現實。
場景化體驗優化將重塑用戶交互邏輯:針對醫療遠程診斷、工業協同設計等垂直場景,PC 集群需深度適配終端設備能力(如平板觸控交互、手機低功耗模式),依托跨系統兼容性打通協議壁壘(如 UOS 系統下的 3D 模型輕量化渲染、iOS 終端的低延遲編碼),使遠程訪問 3D 模型、醫療影像的操作延遲低于 50ms,與本地設備體驗差異縮小至 “無感”,真正實現 “終端無算力,體驗無差別”,借由 “軟件封裝” 中低端 GPU 的大算力輸出,讓更多終端能流暢參與復雜場景交互。
2、超融合與綠色算力落地
突破 “硬件堆砌” 模式,PC 集群正加速向超融合架構演進:通過軟件定義技術,將計算、存儲、網絡資源深度整合,依托跨系統兼容性(Windows/Linux 混合部署)、跨架構適配(X86+ARM 混合集群),實現 “一套管理平臺” 統一調度異構資源。例如,金融機構可在同集群內,為核心交易系統分配低延遲 X86 節點,為大數據分析任務分配高吞吐 ARM 節點,支持分鐘級集群擴容 / 縮容,運維成本降低 40%,且能借助 “軟件封裝” 策略,讓中低端 GPU 在混合架構中也高效參與算力協作。
綠色節能成為必然要求。針對跨架構硬件(如 Intel/AMD/ 國產芯片),AI 動態功耗調節技術將普及:非峰值任務時段自動降頻、休眠閑置節點,搭配液冷、余熱回收等方案,使集群 PUE(電源使用效率)逼近 1.1(當前數據中心平均 PUE 約 1.5),每年減少 30% 電力消耗。例如,制造業 PC 集群可利用產線余熱為集群散熱,能源成本下降的同時,實現 “算力生產 - 能源循環” 的可持續閉環,同時 “軟件封裝” 中低端 GPU 也能在節能模式下,合理分配算力,避免資源空耗。
3、硬件級可信與合規適配
安全需求驅動 **“硬件級可信防護”** 融入 PC 集群全鏈路:以跨架構硬件可信根(如國產芯片內置 TPM 模塊)為基礎,構建 “終端 - 集群 - 數據” 零信任體系 —— 通過硬件度量終端系統完整性(跨 Windows/UOS 啟動校驗),結合跨終端身份指紋(手機生物識別 + 硬件證書),確保接入設備、用戶均可信。如政務云 PC 集群可阻斷 “篡改系統內核的終端接入”,抵御高級持續性威脅(APT),保障數據安全,讓 “軟件封裝” 中低端 GPU 輸出的大算力,在可信環境中為業務服務。
面向金融、政務等合規場景,PC 集群需深度整合國產化生態:基于跨系統兼容性(統信 UOS / 銀河麒麟)、跨架構適配(飛騰 / 鯤鵬),通過國密算法改造、三級等保合規設計,實現 “核心業務全棧可控”。如政務辦公場景,從終端設備(瘦客戶機 + 國產架構)、操作系統(UOS)到 PC 集群(飛騰 + 麒麟系統),形成自主可控的算力閉環,數據本地化存儲率達 100%,滿足安全合規底線,使 “軟件封裝” 的國產算力輸出更安全可靠。
(二)軟件定義算力
隨著云原生技術普及,GPU 服務器與 PC 集群將實現更深度的協同。通過容器編排,可根據實時負載自動調度算力資源:在不同時段將 GPU 資源優先分配給不同任務,使硬件利用率大幅提升。動態調度系統已實現服務切換時間縮短,且不影響正在運行的任務。如白天將 GPU 資源主要分配給云游戲服務,夜間則將其分配給 AI 訓練任務,使 GPU 的利用率大幅提升。
智能算力調度算法將融合機器學習技術,通過分析歷史數據預測未來負載,提前進行資源分配。采用預測性調度的集群,資源利用率波動幅度降低,用戶等待時間減少。軟件定義的中低端GPU算力大幅提升,通過虛擬化技術(GPU虛擬化、CPU虛擬化)實現資源按需分配,使集群能同時支撐多種異構工作負載。
安全方面,基于硬件可信根的零信任架構將普及,GPU 服務器與 PC 集群的每個節點都具備身份認證與數據加密能力,確保算力資源不被非法占用,敏感數據在傳輸與計算過程中全程加密。這種架構使多租戶共享集群時,數據隔離級別達到高標準安全要求。
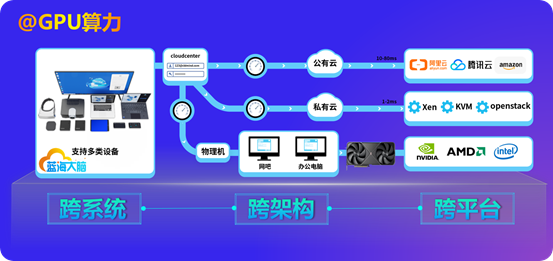
(三)跨行業應用滲透
游戲開發:GPU 服務器憑借并行計算架構,承擔高分辨率場景建模的并行渲染、光影效果的實時模擬及物理引擎的復雜計算,加速高精度畫面資產生產;PC 集群通過分布式架構拆分開發任務,支持多人協同的資源管理與輕量預渲染,保障開發流程高效推進,二者協同提升游戲畫面質量與開發效率。
影視動畫:GPU 服務器聚焦特效渲染核心環節,利用強大圖形處理性能完成粒子特效、角色材質等高精度渲染任務;PC 集群負責渲染任務的拆分調度與素材預處理,通過分布式計算實現任務均衡分配,縮短整體渲染周期,確保高質量影視特效高效產出。
平面設計:GPU 服務器依托圖形處理優勢,快速響應高分辨率圖像合成、復雜圖形特效制作的操作指令,保障設計過程實時反饋;PC 集群通過分布式存儲與任務管理,支撐素材庫高效調用與多版本設計方案并行處理,提升設計師創作與交付效率。
元宇宙:GPU 服務器承擔虛擬世界的物理引擎運算與光影實時渲染,構建逼真的虛擬環境;PC 集群負責用戶行為分析、內容分發與負載調度,確保大規模用戶同時在線互動時的響應速度與環境一致性,二者協同支撐虛擬世界的沉浸體驗。
勘察設計:GPU 服務器為地形數據處理、建筑光照與力學模擬提供高密度計算支持,加速復雜場景的仿真過程;PC 集群整合多源數據,通過分布式任務調度實現多設計方案的并行模擬與對比分析,助力設計師高效生成精準方案。
工業制造(汽車研發):GPU 服務器聚焦虛擬碰撞測試、空氣動力學分析等復雜仿真任務,通過并行計算提升模擬精度與速度;PC 集群承擔多維度測試任務的拆分與協同,實現數據整合與任務動態分配,加速研發流程中的設計優化。
芯片設計:GPU 服務器為晶體管級電路模擬、性能驗證提供高密度計算能力,縮短芯片仿真周期;PC 集群通過分布式架構管理海量設計數據,實現多模塊任務的并行處理與協同調度,推動芯片設計流程高效推進。
工業仿真(機械 / 航空航天):GPU 服務器支撐機械設備運動學仿真、部件強度分析等高精度計算任務,模擬產品在不同工況下的運行狀態;PC 集群通過分布式任務分配實現多場景并行測試,收集分析數據并反饋優化建議,提升產品研發質量與效率。
教育培訓:GPU 服務器為大數據分析、AI 算法訓練等課程實踐提供充足算力支持,保障復雜實驗的順利開展;PC 集群搭建虛擬教學環境,支持多終端同步訪問與資源共享,增強學生實踐體驗與協作學習效果。
GPU服務器與PC集群的協同發展,正在推動算力資源從"專用化"向"普惠化"轉變。在云游戲領域,這種轉變使硬件需求苛刻的3A作品能在普通設備上流暢運行;在科研領域,它讓中小型實驗室也能開展基因測序與氣候模擬研究。從跨媒體娛樂到全球游戲托管,這些實踐印證了一個核心趨勢:算力的價值不在于硬件本身,而在于能否通過架構創新打破應用邊界。
未來,隨著網絡與邊緣計算的普及,GPU服務器與PC集群將構成更細密的算力網絡,支撐起從元宇宙社交到工業元宇宙的全場景應用。對于企業而言,理解兩者的技術特性與協同模式,將成為把握數字經濟機遇的關鍵前提 —— 畢竟,在算力即生產力的時代,選擇合適的算力組合,就是選擇了通往創新的最優路徑。算力網絡的完善不僅將改變技術應用的形態,更將重塑產業競爭格局,在未來的競爭中占據制高點。
#GPU服務器#PC 集群#異構計算#云游戲#算力#分布式計算#GPU#PC農場#PC Farm#邊緣計算#AI算力











)



)



