1. 制造業與供應鏈數字化轉型的必然性
1.1. 核心概念與戰略重要性
制造業的數字化轉型,是利用新一代數字技術(如工業互聯網、人工智能、大數據、云計算、邊緣計算等)對制造業的整體價值鏈進行根本性重塑的過程。這不僅涉及技術的應用,更涵蓋了發展理念、組織架構、經營方式乃至盈利模式的全方位變革。其本質目標在于通過要素的優化配置,提升經濟增長的質量和數量,是推進新型工業化、建設現代化產業體系的關鍵舉措。
在數字經濟時代,市場競爭日益激烈,數字化轉型已成為制造商提升競爭力、實現可持續發展的必由之路。轉型的驅動力源于多方面:一是應對多樣化、個性化的市場需求; 二是提升運營效率,降低成本(如庫存、生產及分銷費用); 三是優化整體流程質量,消除錯誤成本和異常事件; 四是加速產品創新和新產品開發; 五是充分挖掘數據價值,提升生產過程的智能控制水平。
表1:制造業數字化轉型五大驅動力
| 序號 | 驅動因素 | 具體表現 | 預期收益 |
|---|---|---|---|
| 1 | 市場需求變化 | 多樣化、個性化需求增加 | 提高客戶滿意度,增加市場份額 |
| 2 | 運營效率提升 | 降低庫存、生產及分銷費用 | 成本節約,資源優化配置 |
| 3 | 流程質量優化 | 減少錯誤成本和異常事件 | 提高產品質量,降低返工率 |
| 4 | 產品創新加速 | 縮短新產品開發周期 | 增加創新產品比例,提高利潤率 |
| 5 | 數據價值挖掘 | 提升生產過程智能控制 | 實現預測性維護,降低設備故障率 |
制造業數字化轉型并非一蹴而就,而是呈現階段性演進的特征。它通常從點狀應用(單一職能優化)開始,發展到線狀和面狀集成(單一業務、單一組織或企業的運營效率提升、集成化、規范化),最終邁向生態圈層面的協同化、共享化發展。具體而言,企業可能經歷數據集成、信息可視、精益分析、高階分析(如AI驅動的預測與決策)和全面轉型等關鍵階段。最終目標是構建基于5G、工業互聯網等新技術的供應鏈協同制造體系,提升產業整體的整合水平。這種從"點"到"圈"的演進過程表明,孤立的技術應用價值有限,真正的轉型紅利來自于系統性的變革和跨企業的協同,這為后續探討"鏈主"企業的角色奠定了基礎。
圖1:制造業數字化轉型演進路徑
1.2. "鏈主"企業的關鍵作用 (鏈主企業)
在現代供應鏈體系中,“鏈主"企業(或稱核心企業)扮演著至關重要的角色。這些企業通常在資源、市場和技術方面擁有顯著優勢。其核心能力體現為"供應鏈領導力”,即通過影響供應鏈上游供應商和下游客戶的行為與績效,以實現共同供應鏈目標的能力。這種領導力整合了經典的領導力理論和供應鏈管理實踐,是提升供應鏈整體競爭力的重要保障。
表2:鏈主企業的五大核心功能
| 功能類別 | 具體表現 | 影響范圍 | 實現機制 |
|---|---|---|---|
| 目標引領與協同促進 | 設定共同目標,引導伙伴行為 | 整個供應鏈網絡 | 戰略合作協議、績效考核體系 |
| 生態系統構建與協調 | 整合采購、研發、生產、銷售環節 | 上下游企業 | 平臺建設、標準制定、資源共享 |
| 治理與風險控制 | 建立治理機制,協調利益沖突 | 整個供應鏈體系 | 供應鏈金融、合同管理、風險共擔 |
| 創新驅動與能力提升 | 推動技術升級和創新 | 關鍵合作伙伴 | 聯合研發、技術賦能、人才培養 |
| 提升供應鏈整體績效 | 實施戰略性供應鏈管理 | 供應鏈全流程 | KPI體系、共同改進計劃、價值共創 |
"鏈主"企業的功能和重要性體現在多個層面:
- 目標引領與協同促進: 鏈主企業設定共同目標,并引導、影響合作伙伴的行為,以達成這些目標,促進成員間形成良好的協作關系。
- 生態系統構建與協調: 鏈主企業整合從采購、研發、生產到銷售的各個環節,促進鏈上企業的協調發展,優化整個供應鏈的運作。
- 治理與風險控制: 通過建立治理機制(如利用供應鏈金融),協調各方利益沖突,維護鏈上企業的利益,確保供應鏈的穩定運行,降低在復雜全球環境下的風險與混亂。缺乏領導核心的供應鏈將面臨更大的風險。
- 創新驅動與能力提升: 鏈主企業不僅自身進行數字化轉型,還通過其影響力推動鏈上伙伴進行技術升級和創新。這對于國家實現從"制造大國"向"制造強國"的轉變至關重要。
- 提升供應鏈整體績效: 鏈主企業的領導力是實施戰略性供應鏈管理的前提,有助于提升整個鏈條的績效和競爭力。
圖2:鏈主企業在供應鏈生態系統中的角色
鏈主企業通過供應鏈金融等手段進行治理,是其發揮影響力的一個具體體現。通過利用自身的信息和信用優勢,鏈主企業可以幫助上下游伙伴(尤其是中小企業)獲得信貸支持,緩解資金融通的沖突,減少信息不對稱帶來的效率損失,并將資金引導至關鍵的研發和技術創新活動中。這不僅是一種運營層面的影響,更是一種利用金融杠桿推動整個生態系統轉型的戰略手段。理解鏈主企業的核心作用,對于后續分析曼娜內衣案例以及"雙邊溢出效應"的實現機制至關重要。
2. 技術深潛:工業互聯網預測性維護 (PDM)
2.1. PDM 成熟度演進:從監測到預測,再到決策優化
預測性維護(Predictive Maintenance, PDM)并非孤立的技術,而是企業維護策略成熟度演進過程中的一個重要階段。理解這一演進路徑對于成功實施PDM至關重要。該模型最早由Winston Ledet于1999年提出,旨在勾勒資產在其生命周期中處理和維護方式的成熟度級別。
維護成熟度演進路徑
維護成熟度模型通常包含以下幾個關鍵階段:
- 第一級:反應式維護 (Reactive Maintenance):這是最基礎的階段,只有在設備發生故障后才進行維修,即"壞了再修" (run-to-failure)。這種方式雖然在過去很常見,但會導致不可預測的停機時間和高昂的維修成本。
- 第二級:預防性維護 (Preventive Maintenance):基于預定的時間間隔或使用周期進行計劃性維護,在潛在故障發生前進行干預。這種方式旨在主動解決潛在問題,減少意外停機。然而,它可能導致過度維護(在設備狀況良好時進行維護)或維護不足(計劃間隔長于實際故障周期),從而產生不必要的停機時間和成本。
- 第三級:基于狀態的維護 (Condition-Based Maintenance, CBM):通過實時監測設備的關鍵參數(如溫度、振動),當參數超過預設閾值時觸發維護報警。CBM利用實時數據做出更明智的維護決策,比預防性維護更具針對性。但其局限性在于通常只關注單一故障點或模式,缺乏對設備整體健康狀況的全面評估和未來趨勢的預測。
- 第四級:預測性維護 (Predictive Maintenance, PDM):這是向智能化維護邁進的關鍵一步。PDM利用歷史數據和實時監測數據,結合統計模型、機器學習(ML)和人工智能(AI)算法,來預測設備未來可能發生故障的時間和類型。它不僅關注當前狀態,更著眼于未來趨勢,旨在通過分析評估來預測維護需求,然后進行計劃、排程和協調。PDM的目標是優化維護時機,最大限度地減少停機時間,延長設備壽命,并降低維護成本,最終提升整體設備效率(OEE)。
- 第五級:規范性/指令性維護 (Prescriptive Maintenance):這是維護成熟度的最高級別,被認為是維護成熟度模型的最終目標。它不僅預測故障,更能提供具體的、可操作的維護建議(例如,應采取何種修復措施、何時執行、需要哪些資源),甚至能夠建議調整操作參數以規避潛在的故障模式。規范性維護旨在消除缺陷、提高精度、優化設計,并實現資產性能和運營流程的全面優化。它高度依賴先進的AI/ML算法和數字化技術,使設備能夠主動參與自身的維護需求協調。
表1:預測性維護成熟度模型比較
| 級別 | 名稱 | 描述 | 關鍵技術/方法 | 主要目標 | 優點 | 缺點 |
|---|---|---|---|---|---|---|
| 1 | 反應式 (Reactive) | 故障發生后維修 | 手動檢查、基本維修工具 | 恢復功能 | 簡單直接 | 不可預測的停機、高維修成本、潛在安全風險 |
| 2 | 預防性 (Preventive) | 按計劃定期維護 | 時間/使用量計數器、維護計劃 | 預防故障 | 減少意外停機、延長壽命 | 可能過度/不足維護、不必要的停機和成本 |
| 3 | 基于狀態 (CBM) | 基于實時狀態監測和閾值觸發維護 | 傳感器、狀態監測系統 (CMMS) | 基于狀態決策 | 僅在需要時維護、提高效率 | 關注單一故障點、缺乏預測性、仍可能發生意外故障 |
| 4 | 預測性 (PDM) | 利用數據和算法預測未來故障 | IIoT、傳感器、大數據分析、AI/ML | 優化維護時機、最大化正常運行時間 | 顯著減少停機、降低成本、延長壽命 | 需要數據基礎、技術投入和分析能力 |
| 5 | 規范性 (Prescriptive) | 預測故障并提供具體行動建議和優化方案 | 高級AI/ML (含強化學習)、數字孿生 | 優化性能、消除缺陷 | 主動優化、最高效率、企業級協同 | 技術復雜性高、成本高、數據和模型要求極高 |
數據來源: 綜合
這一成熟度模型的演進路徑,不僅僅是技術的迭代升級,更深層次地反映了企業維護理念和組織能力的變革。從被動響應到主動預防,再到基于狀態的干預,直至最終實現基于數據洞察的預測和優化決策,每一步都要求企業在數據采集、數據管理、分析能力、流程整合以及人員技能方面進行相應的投入和提升。因此,向更高級別的維護策略邁進,本身就是一項系統性的組織轉型工程,需要戰略層面的規劃和持續投入。
2.2. 核心使能技術:IIoT、傳感器與數據采集
預測性維護的實現離不開一系列關鍵技術的支撐,其中,工業物聯網(IIoT)、傳感器和高效的數據采集傳輸系統構成了其技術基石。
PDM技術架構圖
- 工業物聯網 (IIoT) 作為骨干: IIoT是將物理世界的工業設備(如機器、傳感器)與數字世界連接起來的網絡和平臺體系。它為PDM提供了基礎架構,實現了數據的互聯互通和共享。一個有效的基于IIoT的PDM系統,需要整合數據采集、設備管理、跨系統(OT/IT/ET)實時集成、數據管理、網絡安全、AI分析、數字孿生以及應用支持等多方面能力。IIoT平臺是實現整體資產績效管理、資產策略和投資規劃的支柱。
傳感器類型及應用
| 傳感器類型 | 監測參數 | 適用設備 | 主要應用場景 |
|---|---|---|---|
| 振動傳感器 | 振動幅度、頻率、相位 | 旋轉機械、電機、渦輪機 | 檢測不平衡、不對中、松動 |
| 溫度傳感器 | 溫度 | 各類設備關鍵部位 | 監測過熱、冷卻系統故障 |
| 壓力傳感器 | 流體/氣體壓力 | 管道、壓力容器、液壓系統 | 檢測泄漏、壓力異常 |
| 聲學/超聲波傳感器 | 聲波、超聲波 | 密封系統、軸承、電氣系統 | 檢測泄漏、軸承磨損、電弧放電 |
| 油液分析傳感器 | 油液成分、污染物 | 潤滑系統、變壓器 | 監測油質變化、設備磨損狀態 |
| 電流/電壓傳感器 | 電流、電壓、功率 | 電氣設備、電機 | 檢測電氣故障、負載異常 |
- 數據采集與傳輸 (Data Acquisition & Transmission): 傳感器收集到的原始數據需要被高效、可靠地采集并傳輸到處理中心(邊緣或云端)。
- 連接協議與網絡: 需要標準化的通信協議(如MQTT, OPC UA)和可靠的網絡連接(如有線網絡,或無線網絡如eLTE、NB-IoT)來傳輸數據。MQTT因其輕量級、發布/訂閱模式等特性,在IIoT領域應用廣泛。
- IIoT平臺/數據管理系統: 這些平臺負責管理連接的設備、收集數據、進行初步處理、提供可視化界面(如儀表盤)和歷史數據分析工具,并將數據輸送給AI分析引擎。例如,華為的智能制造解決方案提供了設備接入、連接管理、數據分析和能力開放等功能。
- 時間序列數據的重要性: PDM的核心在于分析設備狀態隨時間的變化趨勢。因此,連續不斷的時間序列數據(如溫度、振動隨時間的變化)是識別異常模式、預測未來故障的基礎。
數據就緒度評估表
| 評估維度 | 關鍵指標 | 達標標準 | 常見問題 |
|---|---|---|---|
| 數據可用性 | 覆蓋率、采集頻率 | >95%關鍵參數覆蓋 滿足最小采樣頻率要求 | 傳感器部署不足 數據采集中斷 |
| 數據質量 | 準確度、完整性、一致性 | 傳感器校準誤差<5% 缺失值比例<1% | 傳感器失準 數據丟失嚴重 |
| 數據接入 | 數據格式統一性 實時性 | 標準化數據格式 延遲<規定閾值 | 數據格式不兼容 傳輸延遲嚴重 |
| 數據存儲 | 存儲容量 訪問性能 | 滿足預估數據量需求 查詢響應時間達標 | 存儲容量不足 數據庫性能瓶頸 |
| 數據整合 | 多源數據關聯性 上下文信息 | 可實現跨系統數據關聯 包含必要上下文信息 | 數據孤島 缺乏關聯ID |
因此,成功部署高級別的預測性維護(第四、五級),其關鍵瓶頸往往不在于AI算法的潛力本身,而在于前期基礎工作的扎實程度——即確保擁有高質量、可訪問、集成化的數據流,這些數據流來自于可靠的傳感器和穩定的數據采集系統。企業在投入巨資購買復雜AI模型之前或之初,就應高度重視數據基礎設施的建設和數據治理體系的完善。
2.3. AI/ML算法:驅動預測與決策的核心引擎
人工智能(AI)和機器學習(ML)算法是預測性維護(PDM)和規范性維護(RxM)系統的"大腦",它們負責處理從傳感器和IIoT平臺收集的海量數據,識別其中隱藏的復雜模式和細微異常,從而實現故障預測、剩余使用壽命(RUL)估計,并為規范性維護提供行動建議。AI/ML的應用使得維護策略超越了簡單的基于狀態的閾值報警,進入了智能預測和決策優化的新階段。其核心優勢在于能夠從數據中持續學習并提升預測精度。
PDM中的AI/ML算法框架
主要的AI/ML算法類別及其在PDM/RxM中的應用包括:
- 監督學習 (Supervised Learning): 這類算法利用帶有"標簽"的歷史數據進行訓練,即輸入數據(如傳感器讀數、運行參數)與已知的輸出結果(如是否發生故障、故障類型、RUL值)相關聯。
- 分類 (Classification):用于預測設備狀態(如正常、警告、危險)或判斷是否會在特定時間窗口內發生故障。常用算法包括邏輯回歸 (Logistic Regression)、支持向量機 (Support Vector Machines, SVM)、決策樹 (Decision Trees, DT)、隨機森林 (Random Forests, RF)以及各種深度神經網絡 (Deep Neural Networks, DNNs),如前饋神經網絡 (FNN)、卷積神經網絡 (CNN,尤其適用于處理圖像類或振動信號頻譜數據)、循環神經網絡 (RNN) 及其變種長短期記憶網絡 (LSTM,擅長處理時間序列數據)。這些算法是故障診斷 (Fault Diagnosis) 的核心。
- 回歸 (Regression):用于預測連續值,最典型的應用是預測設備的剩余使用壽命 (RUL)。常用算法包括線性回歸 (Linear Regression)、支持向量回歸 (Support Vector Regression, SVR)、決策樹/隨機森林回歸,以及基于回歸任務的神經網絡架構。
監督學習算法對比表
| 算法類型 | 優勢 | 局限性 | PDM適用場景 |
|---|---|---|---|
| 邏輯回歸 | 簡單、易解釋、計算效率高 | 只能處理線性關系、特征工程要求高 | 簡單的故障分類、初篩 |
| 支持向量機(SVM) | 適用于小樣本、高維數據 | 計算成本高、參數調優復雜 | 多類型故障分類 |
| 決策樹/隨機森林 | 可處理非線性關系、特征重要性評估 | 可能過擬合、森林解釋性較差 | 設備狀態分類、健康評估 |
| 神經網絡(DNN) | 可學習復雜模式、自動特征提取 | 需大量數據、計算資源要求高 | 復雜設備故障預測 |
| CNN | 適合處理空間相關數據 | 需大量標記數據、調參復雜 | 圖像型缺陷檢測、振動分析 |
| RNN/LSTM | 適合時序數據處理 | 訓練復雜、計算開銷大 | 時間序列故障預測、RUL估計 |
- 無監督學習 (Unsupervised Learning): 這類算法在沒有標簽的數據上進行訓練,旨在發現數據中隱藏的結構、模式或異常。在缺乏充足故障標簽數據的情況下尤其有用。
- 聚類 (Clustering):將相似的數據點分組。可用于識別設備的不同運行工況或狀態,或者發現與正常狀態不同的數據簇。常用算法包括K-Means、層次聚類 (Hierarchical Clustering)、基于密度的噪聲應用空間聚類 (DBSCAN)、高斯混合模型 (Gaussian Mixture Models, GMMs)以及主成分分析 (Principal Component Analysis, PCA)(常用于降維,也可輔助聚類)。
- 異常檢測 (Anomaly Detection):識別與正常行為模式顯著不同的數據點或序列。這對于發現早期、未知的或罕見的故障跡象至關重要。常用算法包括孤立森林 (Isolation Forest)、單類支持向量機 (One-Class SVM) 以及自編碼器 (Autoencoders,一種神經網絡,通過重構誤差識別異常)。
無監督學習算法適用場景
| 算法類型 | 核心機制 | PDM應用場景 | 數據要求 |
|---|---|---|---|
| K-Means聚類 | 基于距離劃分數據點 | 設備運行工況識別 | 數值型數據、簇形狀規則 |
| DBSCAN | 基于密度識別數據簇 | 復雜工況模式識別 | 適合非規則形狀的簇 |
| 主成分分析(PCA) | 降維、提取主要變異 | 故障特征提取、降噪 | 線性相關性數據 |
| 孤立森林 | 隨機分割空間識別異常 | 快速異常檢測篩查 | 適用于高維數據 |
| 自編碼器 | 通過重構誤差識別異常 | 復雜設備異常檢測 | 需大量正常樣本訓練 |
| Seq2Seq模型 | 序列對序列學習 | 時序數據異常檢測 | 時間序列數據 |
- 強化學習 (Reinforcement Learning, RL): 這類算法通過讓"代理"(Agent)與環境交互,在試錯過程中學習最優策略(一系列行動),以最大化累積獎勵(如最大化設備正常運行時間、最小化維護成本)。RL特別適用于規范性維護(RxM)場景,因為它不僅能預測,還能學習并推薦最優的應對措施。例如,RL可以用來優化維護計劃的制定、動態調整設備運行參數以延長壽命,或者在多種可選維護方案中做出最佳選擇。常用算法包括Q-Learning、深度Q網絡 (Deep Q-Networks, DQN)、策略梯度方法 (Policy Gradient Methods) 等。
AI/ML技術之所以能夠超越傳統的基于狀態的監測(CBM),關鍵在于它們能夠:
- 學習復雜的多變量模式: 能夠識別多個傳感器數據之間以及數據與歷史故障之間的復雜、非線性關系,這是基于單一閾值的CBM難以做到的。
- 預測未來狀態: 監督學習算法可以直接預測未來的故障概率或RUL,而不僅僅是報告當前狀態異常。
- 發現未知異常: 無監督學習算法能夠在沒有先驗知識的情況下,檢測出偏離正常運行模式的早期、微弱信號。
- 提供優化建議: 強化學習等技術能夠評估不同維護決策的長期影響,并推薦最優化的行動方案,實現規范性維護的目標。
通過應用這些先進的AI/ML技術,企業能夠將維護策略從被動響應和固定周期的預防性維護,提升到更主動、更精準、更高效的預測性乃至規范性維護水平,從而實現顯著的成本節約、設備可用性提升和資產可靠性增強。
3. 技術深潛:區塊鏈賦能供應鏈誠信體系
3.1. 提升透明度、可追溯性與信任度
區塊鏈技術通過其獨特的分布式、加密和不可篡改的特性,為解決傳統供應鏈中長期存在的透明度低、追溯困難和信任缺失等問題提供了革命性的解決方案。
區塊鏈技術與傳統中心化系統對比
| 特性 | 傳統中心化系統 | 區塊鏈技術 | 供應鏈價值體現 |
|---|---|---|---|
| 數據存儲架構 | 中心化數據庫 | 分布式賬本 | 提高系統可靠性、避免單點故障 |
| 信息可信度 | 依賴中心化機構 | 密碼學保證 | 降低對中間方的依賴、減少摩擦成本 |
| 數據記錄特性 | 可修改、可刪除 | 不可篡改、永久記錄 | 提供可靠歷史追溯、增強審計能力 |
| 系統安全機制 | 中心化安全防護 | 去中心化共識機制 | 分散風險、提高整體安全性 |
| 數據透明度 | 有限、不對等共享 | 高度透明、共享一致 | 打破信息孤島、增強供應鏈協作 |
| 自動化程度 | 依賴人工處理 | 智能合約自動執行 | 提高流程效率、減少人為干預 |
- 核心機制: 區塊鏈本質上是一個分布式的數字賬本。供應鏈中的每一筆交易或狀態變更(如產品出入庫、質檢認證、物流節點更新)都被記錄為一個"區塊",該區塊通過加密算法(如哈希函數)與前一個區塊鏈接起來,形成一個不可逆的"鏈條"。這個賬本由網絡中的多個參與者共同維護,而非由單一中心機構控制。
- 增強透明度 (Transparency): 區塊鏈為所有獲得授權的供應鏈參與者提供了一個共享的、統一的、實時更新的信息視圖。每一次產品流轉和狀態更新都被記錄在案,且對相關方可見7。這種高度透明性打破了傳統供應鏈中各環節的信息孤島,使得企業和最終消費者都能了解商品的來源、流轉路徑和質量信息,從而建立起基于事實的信任和問責機制。
- 強化可追溯性 (Traceability): 區塊鏈的鏈式結構和時間戳特性使其能夠精確地記錄產品從原材料采購、生產加工、倉儲物流到最終交付給消費者的完整生命周期軌跡。這種端到端的可追溯性對于驗證產品真偽、高效管理產品召回、確保原材料的合規性與道德采購(如環境、社會和治理(ESG)方面的要求)以及打擊假冒偽劣產品至關重要。
- 建立信任 (Trust) 與提升安全 (Security): 區塊鏈的不可篡改性是其建立信任的核心基礎。一旦數據被寫入區塊并添加到鏈上,就極難被單個節點惡意修改或刪除,任何篡改企圖都會被網絡中的其他節點檢測到。數據的加密存儲和傳輸,以及基于共識機制的驗證過程,確保了信息的完整性和安全性。這減少了對傳統中間商或第三方驗證機構的依賴,降低了交易對手方的信任成本,并有效防范了欺詐行為。根據應用場景和隱私需求,可以選擇不同類型的區塊鏈網絡,如完全公開的公有鏈、需要授權訪問的私有鏈或由多個組織共同管理的聯盟鏈,以平衡透明度與數據訪問控制。
- 提高效率與降低成本: 通過自動化流程(例如利用智能合約)和減少對紙質文件及人工核對的依賴,區塊鏈可以簡化供應鏈操作,加快交易速度,減少人為錯誤8。智能合約是嵌入在區塊鏈上的自執行代碼,當預設條件(如貨物送達確認、質量檢驗合格)滿足時,可以自動觸發相應的動作(如支付貨款、放行貨物),從而提高流程效率。
區塊鏈賦能供應鏈流程圖
區塊鏈在供應鏈中的價值,并非僅僅是技術的疊加,而是對傳統基于信任中介、信息不對稱的運作模式的根本性改變。它通過技術手段構建了一個可信的數據基礎,為供應鏈各參與方提供了一個共享的、不可篡改的"單一事實來源",從而解決了長期困擾供應鏈管理的諸多痛點。
3.2. 跨行業應用實例分析
區塊鏈技術在供應鏈領域的應用已經從概念驗證走向實際部署,并在多個行業展現出顯著成效。
- 食品行業: 主要解決食品安全和來源追溯問題。通過區塊鏈記錄食品從農場到餐桌的全過程,消費者掃描產品二維碼即可獲取其產地、加工、物流等信息,提升食品安全透明度和消費者信任。
- 沃爾瑪 (Walmart): 作為早期采用者,沃爾瑪利用基于Hyperledger Fabric的IBM Food Trust平臺追蹤豬肉(在中國市場)和生菜等產品的供應鏈。此舉將問題產品的溯源時間從幾天甚至幾周縮短至幾秒鐘3,極大提高了食品安全事件的響應效率。
- 雀巢 (Nestlé): 在中國市場,為應對嬰兒奶粉信任危機,雀巢利用區塊鏈技術記錄奶粉的生產和流通過程,消費者可通過手機掃描包裝上的芯片查驗產品信息,并結合防偽包裝設計,重塑品牌信任。
- 家樂福 (Carrefour): 同樣加入了IBM Food Trust網絡,提升其產品的可追溯性。
- 星巴克 (Starbucks): 實施"從豆到杯"計劃,利用區塊鏈追蹤咖啡豆從種植、采購、烘焙到最終銷售的全過程。
- 醫藥行業: 核心應用在于打擊假藥、滿足嚴格的監管要求(如美國的DSCSA法案)以及優化藥品召回流程。區塊鏈提供了藥品流通環節中不可篡改的記錄,確保藥品來源的真實性和流通過程的合規性。
- MediLedger聯盟: 由多家領先的制藥公司和分銷商組成,利用區塊鏈技術進行藥品序列化信息的驗證和追蹤,防止假藥流入市場。沃爾瑪也是該聯盟成員。
- IBM Blockchain Transparent Supply: 被多家藥企用于實時追蹤藥品,降低假藥風險。
- SAP Pharma Blockchain: 提供端到端的供應鏈可見性和可追溯性解決方案。
- SkyCell: 結合物聯網傳感器和區塊鏈技術,為溫敏藥品的冷鏈運輸提供智能溫控集裝箱,確保運輸過程中的溫度和濕度得到有效監控和記錄,保障藥品質量。
- FDA DSCSA試點項目: 證明了區塊鏈技術能夠將藥品召回通知時間從幾天縮短至幾秒鐘,顯著提升應急響應能力。
- 唯鏈 (VeChain): 提供企業級區塊鏈解決方案,其智能合約可用于改善醫藥供應鏈的透明度、自動化合規流程和確保產品質量。
- 奢侈品與汽車行業: 主要用于驗證產品真偽和追蹤零部件來源。
- 奢侈品防偽: Aura聯盟(由LVMH、普拉達、卡地亞等品牌組成)利用區塊鏈為奢侈品(如手袋)提供數字真品證書,消費者可掃描驗證。百年靈 (Breitling) 為其手表提供數字護照。戴比爾斯 (De Beers) 追蹤鉆石從礦山到零售的全過程。
- 汽車零部件追溯與可持續性: 汽車制造商利用區塊鏈追蹤零部件的來源和歷史,加強質量控制和安全管理。特斯拉 (Tesla) 利用區塊鏈確保其原材料(如電池金屬)來源的可持續性5。寶馬 (BMW) 的車輛數字護照結合了物聯網和區塊鏈,記錄車輛的里程、維修、事故和保險等完整歷史5。
- 物流與支付: 提升貨物運輸的實時可見性,簡化跨境支付流程。
- 貨運追蹤: 區塊鏈可提供防篡改的實時貨運狀態記錄,減少貨物丟失和延誤8。
- 簡化支付: 澳大利亞汽車制造商Tomcar使用比特幣向部分國際供應商支付貨款,利用其跨境、低費用的特點。智能合約也可用于在滿足交付條件時自動觸發支付。
區塊鏈供應鏈應用案例圖表
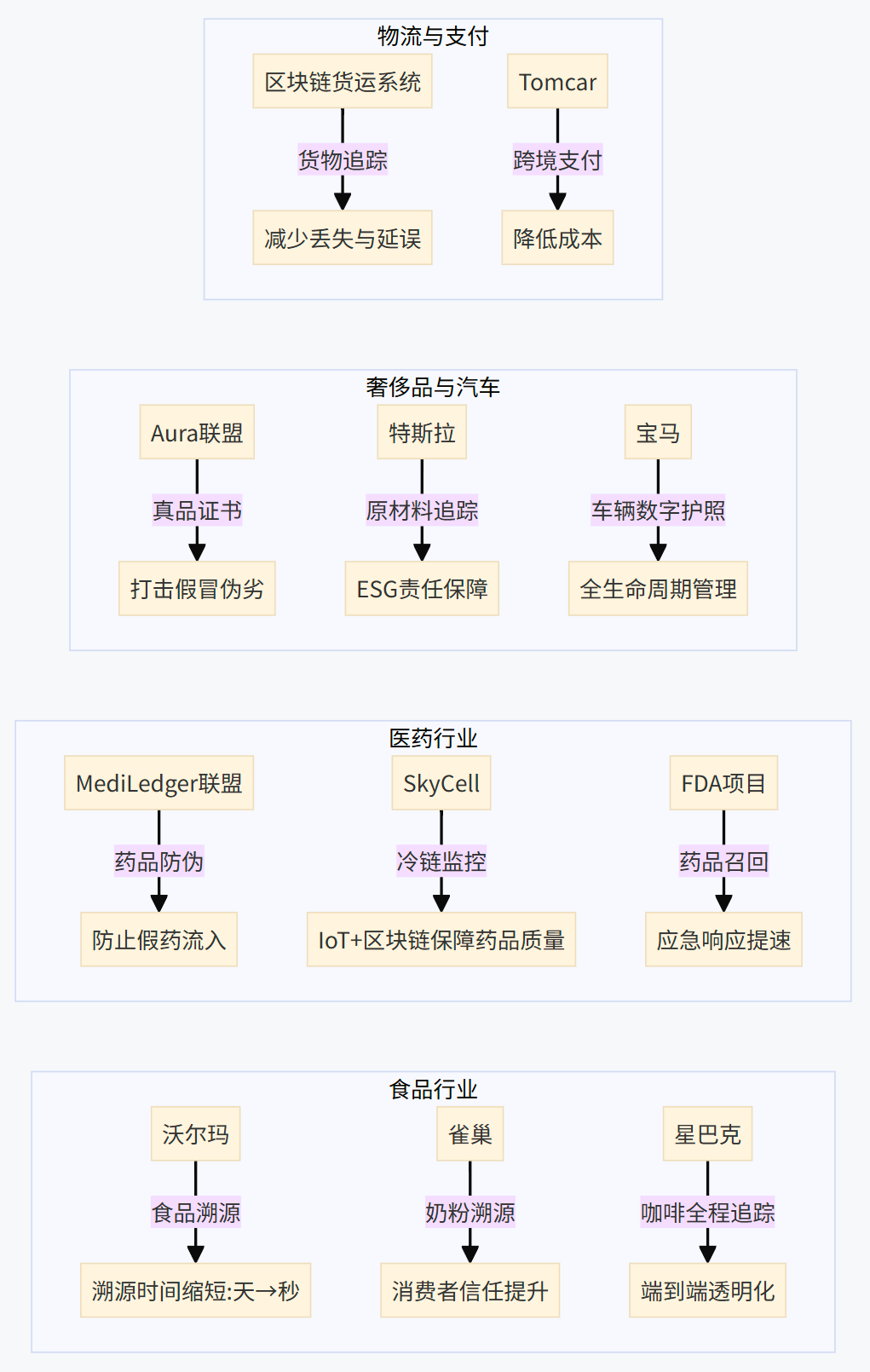
表2:區塊鏈供應鏈應用案例
| 行業 | 具體應用場景 | 案例/計劃 | 展示的關鍵效益 |
|---|---|---|---|
| 🍎 食品 | 產品溯源、食品安全 | 沃爾瑪/IBM Food Trust | 溯源時間大幅縮短 (秒級 vs 天級) |
| 🍎 食品 | 重塑信任、消費者驗證 | 雀巢 (嬰兒奶粉) | 提升消費者信任度 提供透明的產品信息 |
| 🍎 食品 | 咖啡豆全程追蹤 | 星巴克 “Bean-to-Cup” | 端到端供應鏈透明化 |
| 💊 醫藥 | 藥品驗證、防偽、合規 | MediLedger聯盟 | 防止假藥流入 加強產品驗證 |
| 💊 醫藥 | 實時追蹤、降低假藥風險 | IBM Blockchain Transparent Supply | 提升供應鏈實時可見性 |
| 💊 醫藥 | 冷鏈物流監控 | SkyCell | 結合IoT確保溫敏藥品 運輸質量 |
| 👜 奢侈品 | 產品真偽驗證 | Aura聯盟 (LVMH, Prada等) | 提供數字真品證書 打擊假冒 |
| 🚗 汽車 | 零部件追溯、質量控制 | 汽車制造商 | 提升零部件供應鏈 透明度和安全性 |
| 🚗 汽車 | 原材料可持續性追蹤 | 特斯拉 | 確保供應鏈符合ESG要求 |
| 🚗 汽車 | 車輛全生命周期記錄 | 寶馬車輛數字護照 | 結合IoT提供可信的 車輛歷史數據 |
| 🚚 物流/支付 | 跨境支付效率 | Tomcar (比特幣支付) | 降低交易費用 加快支付速度 |
數據來源: 綜合7
區塊鏈應用場景流程示例:食品供應鏈
這些案例清晰地表明,區塊鏈在供應鏈管理中的應用并非空中樓閣,而是能夠切實解決行業痛點、創造商業價值的實用技術。值得注意的是,許多成功的應用案例,如沃爾瑪的食品追溯和醫藥行業的MediLedger聯盟,都體現了行業領導者或聯盟組織在推動標準制定和平臺建設方面的重要作用。這再次印證了在供應鏈這樣一個多方參與的復雜系統中,單靠技術本身往往不夠,強大的組織協調能力和生態構建意愿是技術落地并發揮價值的關鍵前提。此外,區塊鏈與物聯網(如SkyCell案例)、人工智能等其他數字化技術的融合,正在進一步拓展其應用邊界,創造出更為強大的協同效應。
4. 技術深潛:邊緣計算與物聯網 (IoT) 集成
4.1. 邊緣計算在制造與物流中的作用
邊緣計算是一種分布式計算范式,它將數據處理和存儲能力盡可能地部署在靠近數據源(即產生或消費信息的"物"和"人"所在的位置)的網絡邊緣,而不是完全依賴于遙遠的、集中的云計算中心。在工業物聯網 (IIoT) 場景下,邊緣計算通常涉及在工廠車間、倉庫、運輸工具等現場部署邊緣網關、邊緣服務器或其他具備計算能力的設備。
邊緣計算在制造業和物流供應鏈中發揮著關鍵作用,主要得益于以下核心優勢:
| 核心優勢 | 描述 | 工業應用示例 |
|---|---|---|
| 降低延遲 (Reduced Latency) | 通過在數據源附近進行計算處理,顯著減少數據往返云端所需時間,實現近乎實時的響應 | ? 實時質量控制 ? 預測性維護 ? 機器人控制與自動化 ? AR/VR應用支持 |
| 優化帶寬利用 (Bandwidth Optimization) | 在本地進行數據預處理、過濾、聚合和分析,只將有價值的結果或異常數據上傳至云端 | ? 工業相機圖像預處理 ? 傳感器數據降采樣 ? 異常數據優先傳輸 |
| 增強可靠性與韌性 (Enhanced Reliability/Resilience) | 使本地設備和系統能夠在網絡連接不穩定或中斷時繼續運行關鍵任務 | ? 離線運行生產線 ? 本地故障恢復 ? 斷網應急處理 |
| 提升數據安全與隱私保護 (Improved Security/Privacy) | 敏感數據在本地處理,減少傳輸中被截獲或泄露的風險 | ? 生產配方保護 ? 個人信息處理 ? 知識產權數據隔離 |
- 降低延遲 (Reduced Latency): 這是邊緣計算最核心的價值之一。通過在數據源附近進行計算處理,可以顯著減少數據往返云端所需的時間,實現近乎實時的響應7。這對于需要快速決策和控制的工業應用至關重要,例如:
- 實時質量控制: 在生產線上即時分析產品檢測數據,發現偏差后立刻調整生產參數,避免批量次品產生。
- 預測性維護: 在本地快速處理傳感器數據,及時發現設備異常并發出預警。
- 機器人控制與自動化: 保證工業機器人、自動導引車 (AGV) 等設備的快速響應和協同作業。
- 增強現實/虛擬現實 (AR/VR) 應用: 為現場技術人員提供低延遲的AR操作指導或VR培訓,提升工作效率和準確性。
- 優化帶寬利用 (Bandwidth Optimization): 工業設備和傳感器會產生海量數據。將所有原始數據傳輸到云端會消耗巨大的網絡帶寬,成本高昂且可能造成網絡擁堵7。邊緣計算通過在本地進行數據預處理、過濾、聚合和分析,只將有價值的結果或異常數據上傳至云端,從而大幅減少了網絡傳輸負擔。
- 增強可靠性與韌性 (Enhanced Reliability/Resilience): 在某些情況下,工廠或物流節點的網絡連接可能不穩定或中斷。邊緣計算使得本地設備和系統能夠在離線狀態下繼續運行關鍵任務和進行本地決策,提高了系統的整體可靠性和對網絡波動的適應能力。
- 提升數據安全與隱私保護 (Improved Security/Privacy): 某些敏感的生產數據或商業數據可能不適合傳輸到云端。邊緣計算允許在本地處理這些數據,減少了數據在傳輸過程中被截獲或泄露的風險,有助于滿足數據安全和隱私合規要求。
基于以上優勢,邊緣計算在制造和物流領域催生了眾多應用場景:
- 制造業: 除了上述提到的實時質控、PDM、機器人控制、AR/VR支持外,還包括能源管理優化(根據實時需求調整設備能耗)、柔性制造/制造即服務(MaaS,快速部署和調整生產線以響應市場需求) 等。
- 供應鏈與物流: 實時庫存追蹤與管理、運輸途中環境監測(如冷鏈物流中的溫濕度監控)、倉庫自動化(如控制分揀機器人、優化倉儲路徑)、優化配送路線等。
邊緣計算并非要取代云計算,而是作為云計算的延伸和補充。它將計算能力推向網絡的邊緣,與云端協同工作,形成云邊協同的架構。在這種架構中,邊緣負責處理實時性要求高、數據量大或涉及隱私安全的應用,而云端則承擔需要全局數據、復雜模型訓練和長期存儲分析的任務。這種結合能夠最大限度地發揮兩者的優勢,構建更高效、更智能的工業系統。
4.2. 邊緣計算架構模式與參考模型
為了規范和指導邊緣計算系統的設計與部署,業界提出了一些通用的架構模式和參考模型。理解這些架構有助于構建可擴展、可互操作的邊緣計算解決方案。
4.2.1 分層架構 (Layered Architectures)
大多數物聯網和邊緣計算系統可以抽象為分層結構,盡管具體的層級劃分可能略有不同,但核心思想一致:
- 設備層/感知層 (Device/Perception Layer): 位于最底層,包含各種傳感器、執行器、PLC、工業設備等物理實體。它們是數據的原始來源和物理動作的執行者。
- 邊緣層 (Edge Layer): 這是邊緣計算的核心層,介于設備層和云層之間。它負責執行本地的數據處理、分析、過濾、聚合和存儲。邊緣層本身可能包含多個子層級(見下文"分級邊緣")。關鍵組件包括邊緣網關 (Edge Gateways) 和邊緣服務器 (Edge Servers)。
- 網絡/連接層 (Network/Connectivity Layer): 負責在不同層級之間傳輸數據,包括設備到邊緣、邊緣到云的通信。
- 云/企業層 (Cloud/Enterprise Layer): 位于最高層,提供強大的計算資源、大規模數據存儲、復雜的模型訓練、全局數據分析以及與企業級應用(如ERP、MES)的集成。
4.2.2 分級邊緣架構 (Hierarchical Edge Architecture)
認識到邊緣計算并非單一節點,而是一個分布式的計算連續體,業界提出了分級邊緣的概念。數據在從設備流向云端的過程中,會經過不同層級的邊緣節點進行逐步處理和提煉:
- 嵌入式邊緣 (Embedded Edge): 計算發生在設備或傳感器自身內部,進行最基礎的數據處理或信號轉換。
- 網關邊緣 (Gateway Edge): 匯聚來自多個嵌入式邊緣設備的數據,執行初步的數據聚合、過濾、格式轉換或簡單的分析。例如,一個邊緣網關連接工廠車間的多個傳感器。
- 網絡/計算邊緣 (Network/Compute Edge): 部署在更靠近本地網絡核心或區域匯聚點的位置,擁有更強的計算能力,可以執行更復雜的分析、運行本地應用或作為連接云端的橋梁9。這一層可以進一步細分為:
- 遠邊緣 (Far Edge): 更靠近物理設備,如部署在車間或基站的邊緣服務器 (L1),甚至傳感器/控制器本身 (L2),延遲通常在亞毫秒到幾毫秒之間。
- 近邊緣 (Near Edge): 通常指部署在企業本地數據中心 (On-Premises) 的邊緣服務器,距離設備稍遠,延遲在幾毫秒到十幾毫秒。
這種分級處理的目的是"用數據保真度換取可操作的洞察力",即在數據向上流動的過程中,逐步減少數據量,同時提煉出更有價值的信息。
4.2.3 參考架構模型 (Reference Architecture Models)
為了促進標準化和互操作性,多個組織提出了邊緣計算的參考架構模型:
| 參考架構模型 | 提出組織 | 主要特點 | 適用場景 |
|---|---|---|---|
| 工業互聯網參考架構 (IIRA) | 工業互聯網聯盟 (IIC) | ? 四個視角: 業務、功能、使用和實施 ? 三層系統: 邊緣層、平臺層、企業層 ? 定義了多個功能域 | 大型工業系統 需要完整框架的企業級項目 |
| 邊緣計算參考架構模型 (RAMEC) | 學術研究機構 | ? 三維模型: 關注點、層級和級別 ? 全面描述邊緣計算范式 | 研究項目 復雜邊緣計算系統規劃 |
| 邊緣計算產業聯盟參考架構3.0 (ECC) | 邊緣計算產業聯盟 | ? 多維度架構 ? 強調邊緣虛擬化功能(EVF) ? 包含智能服務和服務經緯 | 需要硬件解耦的系統 異構設備環境 |
| 國際數據空間參考架構模型 (IDS-RAM) | 國際數據空間協會 | ? 核心關注數據主權 ? 可信數據共享 ? 支持邊緣節點數據處理 | 需要嚴格數據治理 跨企業數據共享場景 |
- 工業互聯網參考架構 (Industrial Internet Reference Architecture, IIRA): 由工業互聯網聯盟 (IIC) 制定。它從業務、功能、使用和實施四個視角來描述系統架構,并將系統劃分為邊緣層 (Edge Tier)、平臺層 (Platform Tier) 和企業層 (Enterprise Tier) 三個層級。IIRA定義了控制域、操作域、信息域、應用域和業務域等功能域,并提出了一些常見的架構模式,如三層架構模式、網關介導的邊緣連接與管理模式、數字孿生核心作為中間件模式等。
- 邊緣計算參考架構模型 (Reference Architecture Model Edge Computing, RAMEC): 一個提出的三維模型,涵蓋關注點、層級和級別等維度,旨在全面描述邊緣計算范式。
- 邊緣計算產業聯盟 (Edge Computing Consortium, ECC) 參考架構.0: 這是一個多維度的架構,包含智能服務、服務經緯 (Service Fabric)、連接與計算經緯 (Connectivity and Computing Fabric, CCF) 以及邊緣計算節點 (Edge Computing Nodes, ECNs) 等組件。它特別強調通過邊緣虛擬化功能 (Edge Virtualization Function, EVF) 層來實現硬件解耦、連接管理和安全策略6。
- 國際數據空間參考架構模型 (IDS-RAM): 雖然其核心關注點是數據主權和可信數據共享,但IDS-RAM也包含了邊緣計算的概念,允許在靠近數據源的邊緣節點(如IDS連接器)上進行數據處理,同時遵循數據空間的治理規則2。
這些架構模式和參考模型為企業設計和實施邊緣計算系統提供了重要的指導框架,有助于確保系統的結構清晰、功能完整、易于擴展并具備良好的互操作性。選擇哪種架構或參考模型取決于具體的應用場景、性能要求和現有的技術基礎。
4.3. 實踐落地:邊緣計算盒子 (華為、樹莓派) 與協議轉換 (Node-RED)
將邊緣計算理念轉化為實際應用,需要具體的硬件設備和軟件工具。邊緣計算盒子(通常指邊緣網關或小型邊緣服務器)和靈活的集成軟件(如Node-RED)是實踐中的關鍵要素。
4.3.1 邊緣計算硬件平臺對比
邊緣計算硬件平臺根據性能、成本和適用場景有很大差異,下表對比了兩種典型代表:
| 特性 | 華為邊緣計算物聯網解決方案 | 樹莓派 (Raspberry Pi) |
|---|---|---|
| 定位 | 企業級工業物聯網邊緣計算平臺 | 低成本開源單板計算機 |
| 硬件性能 | 高性能處理器、工業級設計 | 中等性能ARM處理器、消費級設計 |
| 可靠性 | 高(工業級溫度范圍、防護等級) | 中(需額外防護措施) |
| 協議支持 | 全面支持工業協議(OPC UA、Modbus等) | 通過擴展模塊和軟件支持 |
| 操作系統 | 專用物聯網操作系統(如LiteOS) | Linux發行版(Raspberry Pi OS) |
| 云平臺集成 | 與華為云緊密集成 | 可與多種云平臺集成(靈活但需配置) |
| 成本 | 高 | 低 |
| 適用場景 | 工業生產環境、大規模部署 | 原型設計、教育、小規模項目 |
| 開發生態 | 華為生態系統 | 開源社區支持 |
| 可擴展性 | 通過模塊化設計擴展 | 通過GPIO接口和HAT擴展板擴展 |
- 邊緣計算硬件平臺:
- 華為邊緣計算物聯網解決方案 (Huawei EC-IoT): 華為提供了一系列邊緣計算網關和解決方案,是其智能制造整體方案的一部分。這些網關通常具備:
- 多協議接入能力: 支持多種工業現場總線協議和接口,方便連接不同類型和年代的設備。
- 邊緣計算能力: 內置計算和存儲資源,可在本地運行應用程序,進行實時數據處理、分析和設備管理維護。
- 集成操作系統: 可能集成華為的物聯網操作系統LiteOS,簡化設備與云平臺的連接和應用開發。
- 云端管理: 通過華為的Agile Controller等平臺進行遠程的設備管理、配置、監控和維護,降低運維成本。
- 樹莓派 (Raspberry Pi): 作為一款低成本、高性價比、功能強大的單板計算機,樹莓派在物聯網和邊緣計算領域得到了廣泛應用,尤其是在原型設計、教育和一些非極端嚴苛的工業場景中。
- 靈活性與可擴展性: 擁有豐富的GPIO接口,可以連接各種傳感器和外設。運行基于Linux的操作系統(如Raspberry Pi OS,原Raspbian),擁有龐大的開源社區支持和豐富的軟件資源。
- 邊緣處理能力: 其CPU、內存和存儲能力足以承擔一定程度的數據采集、預處理、分析和本地決策任務。研究表明,將其用于邊緣層處理數據可以提高效率和響應時間。
- 適用場景: 可作為輕量級邊緣網關、數據采集器、本地控制單元或用于構建邊緣計算集群。但需要注意其工業環境適應性(如溫濕度、穩定性)可能不如專用工業級設備,性能評估對其應用至關重要。
- 華為邊緣計算物聯網解決方案 (Huawei EC-IoT): 華為提供了一系列邊緣計算網關和解決方案,是其智能制造整體方案的一部分。這些網關通常具備:
4.3.2 Node-RED:可視化物聯網集成工具
Node-RED是一個基于Node.js的開源、可視化、流式編程工具,在工業物聯網領域越來越受歡迎,特別是在連接異構設備和系統方面發揮著重要作用。
Node-RED在邊緣計算場景中的典型應用場景:
| 應用場景 | 描述 | 優勢 |
|---|---|---|
| 協議轉換與數據集成 | 連接不同協議設備,實現數據互通 | 豐富節點庫支持多種工業協議 |
| 實時數據監控 | 創建監控儀表盤,展示關鍵設備數據 | 內置Dashboard節點,快速可視化 |
| 設備遠程控制 | 通過Web界面遠程控制工業設備 | 可定制UI,支持權限控制 |
| 能源消耗監測 | 采集能源數據,分析能耗模式 | 支持數據聚合和時間序列分析 |
| 簡單故障預警 | 監測異常數據并發出預警 | 低代碼實現條件邏輯和通知 |
| 邊緣設備邏輯處理 | 在邊緣側實現業務邏輯 | 可部署在資源受限設備上 |
| 機器對機器通信 | 促進設備間自主協作 | 支持多種通信模式和觸發機制 |
| 倉儲物流數據整合 | 整合倉庫設備和系統數據 | 適合異構環境和"棕地"集成 |
- 核心功能:協議轉換與數據處理: Node-RED最大的優勢之一在于其強大的協議轉換能力。工業現場往往存在多種通信協議(如Modbus、OPC UA、西門子S7、MQTT、HTTP、TCP等),Node-RED通過其豐富的節點庫(Nodes),可以輕松地在這些協議之間進行橋接和轉換。用戶可以通過拖拽節點、連接流程的方式,快速構建數據流,實現:
- 數據提取: 從PLC(如WAGO、Phoenix Contact PLCnext)、傳感器或其他設備讀取數據。
- 數據處理與轉換: 對數據進行清洗、格式化、計算、邏輯判斷,或將其統一到標準化的數據模型。
- 數據轉發與集成: 將處理后的數據發送到MQTT代理、數據庫、云平臺,或與上層系統(如MES、ERP,可通過REST API等方式集成)進行交互。
- 重要性與應用場景: Node-RED極大地簡化了在"棕地"環境(即存在大量老舊、異構設備的現有工廠)中實現設備互聯和數據集成的工作。其低代碼特性加速了應用開發和原型驗證。典型應用包括:實時數據采集與監控儀表盤、設備遠程控制與自動化邏輯、能源消耗監測與優化、簡單的故障預警支持、邊緣設備邏輯處理、機器對機器 (M2M) 通信觸發(如AGV調度)、倉儲物流數據整合等。
- 采納趨勢: Node-RED在制造業的應用正在增長,一些PLC制造商甚至開始在其產品中直接支持或集成Node-RED。
雖然華為等提供的工業級邊緣計算解決方案在穩定性、可靠性和環境適應性方面通常更優,但樹莓派等低成本平臺為快速原型驗證和特定場景應用提供了可能。而Node-RED作為強大的"粘合劑",在連接這些硬件、打通協議壁壘、實現數據在邊緣設備、網關和云平臺之間順暢流動方面,扮演著不可或缺的關鍵角色。然而,需要注意的是,雖然Node-RED易于使用且功能強大,但在將其應用于高可靠性、高安全性的關鍵工業控制任務時,仍需審慎評估其性能、穩定性和安全機制,可能需要與更專業的工業控制系統或企業級中間件配合使用。
5. 商業洞察:協同效應與溢出效應
5.1. 理解供應鏈中的"雙邊溢出效應"
在供應鏈數字化轉型的背景下,核心企業(鏈主)的數字化進程不僅提升自身效率,還會對鏈條上的其他伙伴產生積極影響,這種影響被稱為"溢出效應"。特別是,“雙邊溢出效應” (Bilateral Spillover Effect) 理論指出,供應鏈中處于主導地位的企業(鏈主)的數字化轉型,能夠顯著地、正向地影響其主要上游供應商和主要下游客戶的數字化水平。
- 理論定義與背景: 該理論著眼于"鏈式"數字化轉型,即由鏈主企業引領,上下游伙伴共同參與的生態系統級轉型過程。它旨在解釋和解決不同企業間數字化能力差距過大,從而制約供應鏈整體協同效率的問題。該理論將傳統關于鏈主企業對其伙伴影響的研究,擴展到了企業數字化轉型這一新領域。
- 核心觀點: 鏈主企業的數字化投入和能力提升,并不會僅僅停留在企業內部,而是會通過特定的機制,"溢出"到其緊密的合作伙伴,帶動整個供應鏈微觀系統的數字化協同能力和整體競爭力的提升。這種溢出是雙向的,既影響供應商,也影響客戶。
- 重要性與意義: 理解雙邊溢出效應,為我們認識企業"鏈式"數字化轉型提供了一個新的視角。它揭示了鏈主企業在推動整個產業現代化進程中的關鍵杠桿作用,并為政府制定聯合推動企業數字化轉型的政策,以及大型企業引領上下游伙伴共同轉型提供了重要的理論依據和實踐啟示。同時,這種效應也強化了供應鏈伙伴之間的經濟聯動關系。
- 與知識溢出的關聯: 雙邊溢出效應可以看作是供應鏈中知識溢出的一種特定表現形式。知識溢出是指知識或信息在組織間(有意或無意地)傳遞和擴散的過程。在供應鏈這種相互依賴、互動頻繁的環境中,知識溢出尤為重要。數字化轉型本身就蘊含著大量的技術、流程和管理知識,鏈主企業的轉型實踐自然會加速這些知識向合作伙伴的溢出。信任、長期合作關系、相似的技術背景等因素都會促進知識溢出的發生。
- 潛在風險考量: 雖然本報告聚焦于積極的溢出效應,但廣義的知識溢出也可能帶來負面影響,例如"搭便車" (Free-riding) 行為,即合作伙伴在沒有相應投入的情況下,利用了領先企業的知識成果,這可能打擊領先企業的創新積極性。然而,研究明確指出了鏈主企業數字化轉型帶來的顯著 正面 溢出效應。
圖1:供應鏈中的雙邊溢出效應示意圖
雙邊溢出效應理論為我們理解鏈主企業(見1.2節)如何發揮其領導力,將自身的數字化優勢轉化為整個供應鏈生態的共同進步,提供了一個重要的分析框架。它強調了轉型不僅僅是單個企業的行為,更是一個相互影響、相互促進的系統性過程。
5.2. 作用機制:資源共享與需求牽引
雙邊溢出效應并非憑空產生,而是通過具體的機制在供應鏈伙伴之間傳導。研究指出了兩種核心機制:資源共享效應和需求牽引效應。
表1:雙邊溢出效應的核心作用機制對比
| 機制類型 | 資源共享效應 (Resource Sharing Effect) | 需求牽引效應 (Demand-Driven Effect) |
|---|---|---|
| 核心邏輯 | 鏈主企業將數字資源分享給合作伙伴,降低其轉型門檻 | 鏈主企業對合作伙伴提出數字化要求,促使其提升能力 |
| 傳導方向 | 主動推動型(自上而下) | 被動響應型(需求驅動) |
| 具體形式 | ? 信息與知識共享 ? 技術與平臺共享 ? 經驗與最佳實踐共享 | ? 數字接口要求 ? 數據透明度要求 ? 協同效率要求 ? 創新機會驅動 |
| 作用對象 | 主要影響供應商數字技術創新、客戶數字資產投資 | 同時影響供應商和客戶的整體數字化轉型投入 |
| 實施難度 | 需要鏈主企業有意愿分享資源 | 容易實施,但可能引起抵觸情緒 |
| 效果持續性 | 中長期,依賴持續的資源投入 | 立竿見影,但需警惕單純合規而非真正能力提升 |
- 機制一:資源共享效應 (Resource Sharing Effect):
- 核心邏輯: 已經完成或正在進行數字化轉型的鏈主企業,積累了大量的數字資源,包括先進的技術、成熟的平臺、寶貴的實踐經驗和數據洞察。鏈主企業通過與主要供應商和客戶分享這些資源,能夠有效降低合作伙伴進行數字化轉型的門檻和成本。
- 具體體現:
- 信息與知識共享: 分享市場趨勢、消費者洞察、技術路線圖等信息,拓寬伙伴視野。
- 技術與平臺共享: 開放自身的數據平臺接口、提供技術支持或培訓,幫助伙伴快速應用新技術。
- 經驗與最佳實踐共享: 分享自身轉型過程中的經驗教訓,減少伙伴試錯成本。
- 作用效果: 這種資源共享直接促進了主要供應商的數字技術創新(如采用新的軟件、分析工具)和主要客戶的數字資產投資(如升級IT基礎設施、建設電商平臺),從而提升了它們的整體數字化水平。它還有助于促進伙伴間的協同研發。
- 機制二:需求牽引效應 (Demand-Driven Effect / Demand Traction):
- 核心邏輯: 鏈主企業自身數字化能力的提升,會對其合作伙伴產生新的、更高的數字化交互需求和標準。為了維持與鏈主企業的業務關系并滿足其要求,合作伙伴被動或主動地進行自身的數字化升級。
- 具體體現:
- 數字接口要求: 鏈主企業可能要求供應商通過特定的電子平臺接收訂單、提交發貨通知、進行質量追溯等。
- 數據透明度要求: 可能要求物流伙伴提供實時的貨物追蹤數據,或要求制造商提供更詳細的生產過程數據。
- 協同效率要求: 鏈主企業優化的數字化流程(如快速響應、柔性生產)會向上游和下游傳遞壓力,迫使伙伴提升自身的響應速度和協同能力。
- 創新機會驅動: 鏈主企業通過數據分析發現供應鏈中的瓶頸或新的增值機會,并引導合作伙伴進行相應的數字化改造以抓住這些機會。
- 作用效果: 這種需求牽引效應,通過施加渠道壓力或提供創新激勵,增強了合作伙伴進行數字化轉型的決心和投入意愿,促使它們投資于數字技術研發和相關資產,以適應鏈主企業引領的數字化生態。
- 增強因素: 除了上述核心機制,一些外部因素也能顯著增強溢出效應,尤其是在供應商端:
- 地理鄰近性: 物理距離越近,信息、知識和資源的交流越便捷,溢出效應越強。
- 共同審計機構: 共享審計機構可能意味著更一致的業務標準和更強的互信基礎,有助于數字化實踐的傳遞。
- 基礎設施: 良好的交通基礎設施(如高鐵服務)便于人員交流和資源流動,也能促進溢出效應。
- 關系基礎: 長期、互信的合作關系是知識和資源有效共享的前提。
- 最終結果: 通過資源共享和需求牽引的雙重作用,鏈主企業的數字化轉型有效地帶動了主要供應商和客戶的數字化水平提升。雖然鏈主企業自身也能從轉型中直接獲益(例如研究發現其庫存管理效率得到提升),但雙邊溢出效應的核心價值在于其對整個供應鏈生態系統數字化能力的催化和賦能作用。
圖2:雙邊溢出效應的作用機制與增強因素
這兩種機制共同解釋了鏈主企業(第1.2節)如何將其內部的數字化成果轉化為外部影響力,推動整個供應鏈生態的共同進化。鏈主企業既可以主動"推"動資源共享,也可以通過設定標準和需求來"拉"動伙伴轉型。這種推拉結合的策略,使得鏈主企業成為整個供應鏈數字化轉型的關鍵引擎。同時,地理鄰近性等傳統因素依然重要,這提示我們,數字化轉型雖然由技術驅動,但其效果的發揮仍然深刻地嵌入在現實的商業關系和物理環境中。
6. 案例分析:鏈主模式實踐 (以服裝行業為例)
(注:由于提供的研究材料1 未包含關于"曼娜內衣"的具體案例細節,本節將基于前述理論和服裝行業的普遍特征,構建一個說明性的案例,闡述鏈主企業如何通過數據共享驅動上下游伙伴轉型,體現資源共享和需求牽引效應。)
6.1. 鏈主企業通過數據共享驅動伙伴轉型
場景設定: 假設"風尚服飾 (ApparelCo)"是一家在中國市場領先的快時尚服裝品牌企業,扮演著供應鏈"鏈主"的角色。面對市場快速變化、個性化需求增加以及提升供應鏈效率的壓力,ApparelCo決定實施以數據共享為核心的數字化轉型戰略。
圖3:服裝行業鏈主企業數據共享驅動轉型流程圖
數據共享平臺構建: ApparelCo投資建立了一個基于工業互聯網理念 的供應鏈協同平臺。該平臺整合了來自銷售終端 (POS系統、電商平臺)、自有倉庫、第三方物流以及部分核心供應商和制造商的數據。為了確保數據的安全和可信,對于關鍵的溯源或交易數據,平臺可能引入了區塊鏈技術進行記錄。同時,為了處理來自各方的實時數據流并進行快速響應,平臺架構中也融入了邊緣計算節點,用于在數據源附近進行初步處理。
共享數據的類型與目標: ApparelCo選擇性地向其核心合作伙伴(如主要面料供應商、代工廠、核心物流服務商)開放特定數據權限。共享的數據主要包括:
- 實時銷售數據與庫存水平: 各渠道的實時銷售情況、各倉庫及門店的庫存數據。
- 銷售預測與需求趨勢: 基于歷史數據和AI分析得出的短期銷售預測、關鍵款式的需求趨勢。
- 生產計劃與訂單狀態: ApparelCo的生產計劃、向代工廠下達的訂單狀態、物料需求計劃。
- 質量反饋與標準: 來自終端消費者和內部質檢的質量反饋信息、更新的產品質量標準。
目標: 通過數據共享,打破信息壁壘,提升整個供應鏈的透明度和協同效率,實現快速響應市場變化、精準匹配供需、優化庫存管理、提升產品質量的總體目標。
6.2. 資源共享與需求牽引效應的體現
ApparelCo的數據共享戰略,清晰地體現了雙邊溢出效應中的資源共享和需求牽引機制:
- 資源共享效應的實踐:
- 數據即資源: ApparelCo將經過處理的銷售數據、庫存數據和預測數據作為寶貴的數字資源,分享給上游面料供應商和代工廠。供應商可以據此更準確地預測面料需求,優化原材料采購和庫存,減少資金占用和浪費。代工廠可以更合理地安排生產計劃,提高產能利用率和訂單交付準時率。
- 平臺即資源: 提供的協同平臺本身就是一種數字基礎設施資源。合作伙伴接入平臺,可以利用平臺提供的分析工具或API接口,提升自身的數據處理和決策能力。
- 知識與經驗共享: 在推廣平臺應用的過程中,ApparelCo可能會提供相關的技術培訓和實施指導,分享其在數據分析和數字化管理方面的經驗,這本身也是一種知識資源的共享。
- 效果: 這種資源共享,直接推動了合作伙伴在數據分析工具、生產執行系統 (MES) 或企業資源規劃 (ERP) 系統方面的投資和應用(數字資產投資),并可能激發它們在數字化排產、智能化倉儲等方面的技術創新。
- 需求牽引效應的實踐:
- 集成要求: 為了實現端到端的數據貫通,ApparelCo要求核心合作伙伴必須接入其協同平臺,按照約定的數據標準和接口規范,實時或準實時地上傳生產進度、物料庫存、物流狀態等信息。這就形成了明確的數字化需求。
- 響應速度要求: 快時尚行業對供應鏈的響應速度要求極高。ApparelCo通過共享實時銷售數據和快速調整的生產計劃,向上游傳遞了快速反應的市場壓力,迫使供應商和制造商必須提升自身的數字化能力(如采用自動化設備、優化內部流程)來滿足這種需求。
- 質量與追溯要求: 如果ApparelCo利用區塊鏈等技術進行產品溯源或質量追蹤,那么相關環節的合作伙伴(如面料廠、印染廠、代工廠)也必須配合采用相應的技術手段(如RFID標簽、掃碼上傳數據)來滿足鏈主的可追溯性要求。
- 效果: 這些來自鏈主的需求,無論是硬性的集成要求,還是市場傳遞的效率壓力,都強有力地"牽引"著合作伙伴進行數字化升級。合作伙伴為了保住訂單、提升競爭力,不得不加大在自動化、信息化、智能化方面的投入。
案例總結: 在這個說明性案例中,ApparelCo作為服裝行業的鏈主企業,成功地利用數據共享這一核心手段,同時發揮了資源共享和需求牽引的作用。通過開放數據資源、提供平臺支持,它降低了伙伴轉型的門檻(資源共享);通過設定集成標準、傳遞市場壓力,它激發了伙伴轉型的動力(需求牽引)。最終,不僅ApparelCo自身的運營效率和市場響應能力得到提升,整個供應鏈生態系統的數字化水平和協同能力也得到了顯著增強,實現了雙邊溢出效應,共同構筑了更具韌性和競爭力的數字化供應鏈體系。
這個案例也揭示了鏈主企業成功推動數據共享的關鍵前提:首先,鏈主自身需要具備強大的數字化能力和清晰的戰略意圖;其次,需要精心設計共享數據的范圍、粒度和權限,確保數據對伙伴而言是真正有價值且可操作的;最后,也是至關重要的,必須建立起合作伙伴之間的信任基礎以及明確的數據治理規則(詳見第7.1節),以保障數據共享的安全、合規和可持續性。
7. 風險管控與商業化考量
數字化轉型,特別是涉及跨企業數據共享和復雜技術應用的場景,必然伴隨著風險,同時也對技術的商業化落地提出了更高要求。
7.1. 共享環境下的數據所有權與治理
在制造業與供應鏈的數字化轉型中,數據共享是實現協同效應、發揮鏈主引領作用和激發雙邊溢出效應的關鍵。然而,數據的流動和共享也帶來了關于數據所有權、使用權、隱私保護和安全性的嚴峻挑戰3。缺乏明確的規則和有效的治理,數據共享可能引發糾紛、抑制參與意愿,甚至導致法律風險。
表2:數據共享協議 (DSA) 的關鍵要素與示例條款
| 協議要素 | 內容說明 | 示例條款 |
|---|---|---|
| 共享目的與范圍 | 明確界定數據共享的具體用途和允許訪問的數據范圍 | “本協議中共享的銷售數據僅用于供應商優化生產計劃和庫存管理,不得用于其他商業目的” |
| 數據所有權界定 | 明確原始數據和衍生數據的所有權歸屬 | “原始銷售數據的所有權歸屬于數據提供方,基于該數據生成的分析報告所有權歸屬于數據接收方” |
| 數據使用權限 | 規定各方對數據的使用權限和限制 | “接收方可對數據進行內部分析,但不得轉售、再許可或向第三方披露” |
| 保密與安全義務 | 規定數據接收方必須采取的安全措施 | “接收方須采用至少AES-256加密標準存儲數據,并限制訪問權限僅授予必要人員” |
| 合規性承諾 | 確保數據處理活動符合法律法規 | “雙方承諾遵守《個人信息保護法》及相關數據保護法規,及時更新隱私政策” |
| 協議期限與終止 | 明確有效期限及終止后數據處理方式 | “協議有效期為一年,自動續期;終止后30天內,接收方須返還或銷毀所有共享數據” |
| 責任與審計 | 界定違約責任及審計條款 | “提供方有權每季度對接收方數據處理措施進行一次審計;違反協議導致數據泄露,違約方承擔全部責任” |
| 爭議解決機制 | 規定如何處理協議執行中的分歧 | “因本協議引起的爭議,雙方應先通過友好協商解決;協商不成,提交XX仲裁委員會仲裁” |
| 不可抗力條款 | 對不可控因素導致的協議履行障礙的處理 | “因自然災害、政府行為等不可抗力導致無法履行協議義務的,免除相應責任” |
| 通知與聯系方式 | 明確正式溝通渠道和聯系人 | “協議相關的所有通知應通過電子郵件發送至指定的數據保護官郵箱” |
- 核心挑戰:
- 所有權界定模糊: 數據在產生、傳輸、處理、聚合的過程中,其所有權歸屬可能變得復雜。誰擁有原始數據?誰擁有經過處理或分析后產生的新數據或洞察?。
- 數據安全風險: 數據在共享過程中可能面臨未經授權的訪問、泄露、篡改或濫用。
- 隱私合規壓力: 特別是涉及個人信息(如消費者數據、員工數據)時,必須遵守嚴格的隱私法規(如歐盟的GDPR、加州的CCPA以及中國的《個人信息保護法》等),包括獲取明確同意、限制數據用途、保障數據主體權利等3。
- 信任缺失: 合作伙伴可能因擔心數據被濫用或核心商業信息泄露而對共享數據持保留態度。
- 治理框架與協議的重要性: 建立清晰的數據治理框架和具有法律約束力的數據共享協議是應對挑戰的關鍵。
- 數據治理 (Data Governance): 指的是一套管理數據資產生命周期的規則、流程、標準和控制措施。它明確了數據相關的角色和職責(如數據所有者、數據管理員、數據使用者)、數據質量標準(準確性、完整性、一致性、及時性等)、數據分類(根據敏感度定義訪問和處理要求,如公開、受限、機密)以及數據安全策略。
- 數據共享協議 (Data Sharing Agreements / Data Use Agreements - DUAs): 這是規范數據共享行為的法律合同3。一份完善的協議應至少明確以下內容:
- 共享目的與范圍: 清晰界定共享數據的具體用途和允許訪問的數據范圍。
- 數據所有權與使用權: 明確原始數據和衍生數據的所有權歸屬,以及各方對數據的使用權限和限制。
- 保密與安全義務: 規定數據接收方必須采取的安全措施(如加密、訪問控制),以及對數據的保密責任。
- 合規性承諾: 確保數據處理活動符合所有適用的法律法規。
- 協議期限與終止: 明確協議的有效期限以及終止后數據的處理方式(如返還或銷毀)。
- 責任與審計: 界定違約責任,并可能包含審計條款以核查協議遵守情況。
- 新興解決方案:數據空間 (Data Spaces): 為了在保障數據主權的前提下促進更廣泛、更安全的數據共享,數據空間的概念應運而生。數據空間旨在構建一個基于共同規則、標準和信任機制的分布式數據生態系統。
- 核心理念:數據主權: 數據所有者能夠完全自主地決定其數據如何被訪問和使用。
- 關鍵技術與標準:
- 參考架構: 如國際數據空間協會 (IDSA) 的IDS-RAM3 和Gaia-X架構,定義了數據空間的組件和交互方式。
- 核心組件: IDS連接器 (IDS Connectors) 作為參與者接入數據空間的標準化接口,負責執行數據策略和安全通信。
- 通信協議: 數據空間協議 (Dataspace Protocol) 定義了數據發布、策略協商和數據交換的標準流程。
- 信任與身份管理: 利用去中心化標識符 (Decentralized Identifiers, DIDs) 和可驗證憑證 (Verifiable Credentials, VCs)來實現參與者身份認證和授權,通常與eIDAS等現有信任框架兼容。
- 策略執行: 使用如ODRL (Open Digital Rights Language) 等策略語言來定義和執行數據使用控制策略。
- 互操作性: 強調采用W3C (如DCAT, VCs)、OGC等國際標準,確保不同數據空間和平臺間的互操作性。
- 治理組織: IDSA、Gaia-X、FIWARE基金會等組織通過數據空間商業聯盟 (DSBA)等合作,共同推動技術融合和標準制定。
圖4:數據空間架構與數據主權保障機制
數據空間提供了一種更系統化、更安全、更能保障數據主權的方法來應對數據共享的挑戰,被認為是未來數據經濟的重要基礎設施。對于希望在供應鏈中建立深度數據協作的企業,尤其是鏈主企業,了解和參與數據空間的建設將是重要的戰略方向。
7.2. 預測性維護商業化:精度閾值與投資回報 (ROI)
將預測性維護 (PDM) 從技術探索推向商業化應用,需要跨越技術和經濟兩方面的門檻。其中,如何設定合理的預測精度閾值,以及如何清晰地評估和證明其投資回報 (ROI),是商業化成功的關鍵考量因素。
圖5:預測性維護決策流程與閾值設定考量
-
商業化的前提:證明ROI: PDM系統的實施涉及顯著的前期投資,包括購買傳感器、軟件平臺、進行系統集成以及人員培訓等。因此,在決策投入之前,必須進行嚴謹的商業論證,量化PDM可能帶來的經濟效益,即計算其ROI。準確計算ROI本身也存在挑戰,需要全面的成本和收益數據。
-
ROI計算的關鍵要素: ROI的計算邏輯是比較實施PDM后的凈收益(收益增加+成本節約)與實施PDM的總成本(初始投資+持續運營成本)。
- 主要收益/成本節約項 (價值驅動因素):
- 減少非計劃停機時間: 這是最直接的效益,可通過 (停機時間減少量 × 每小時停機成本) 來量化。研究表明PDM可將非計劃停機減少高達50%或35-45%。
- 降低維護成本: 通過優化維護時機,避免不必要的預防性維護和昂貴的緊急維修,可降低總維護成本10-40%7 或25-30%。
- 延長設備壽命: 通過早期干預避免嚴重損壞,可將設備壽命延長20-40%,從而推遲資本支出。
- 提高生產效率/OEE: 設備可用性提高帶來產量增加。
- 提升產品質量: 避免因設備問題導致的生產缺陷。
- 提高安全性與合規性: 減少災難性故障和安全事故。
- 降低備件庫存: 更精準的維護計劃可減少備件庫存持有成本,約10%。
- 提升能源效率: 維護良好的設備運行更高效。
- 主要成本項:
- 初始投資: 傳感器、硬件、軟件平臺購買成本;安裝、集成、校準、測試成本;員工培訓成本。
- 持續成本: 系統維護與支持費用(年度);數據存儲與計算資源費用;數據分析人力成本;傳感器等硬件的更換成本。
- 主要收益/成本節約項 (價值驅動因素):
-
精度閾值與模型性能的影響: PDM模型的預測精度直接關系到其商業價值。模型的性能通常通過以下指標衡量,這些指標之間存在權衡關系:
- 敏感性 (Sensitivity) / 召回率 (Recall): 模型正確識別出實際將要發生故障的能力 (TP / (TP + FN))。高敏感性意味著能捕捉到更多真實故障,減少假陰性 (False Negatives, FN),即漏報。漏報會導致非計劃停機,通常成本高昂1。
- 特異性 (Specificity): 模型正確識別出設備正常運行狀態的能力 (TN / (TN + FP))。高特異性意味著能準確判斷設備無故障,減少假陽性 (False Positives, FP),即誤報。誤報會導致不必要的維護檢查或停機,增加成本并可能降低對系統的信任。
- 精確率 (Precision): 在模型預測為故障的案例中,實際確實是故障的比例 (TP / (TP + FP))。高精確率意味著預測的故障信號更可靠,采取維護行動的決策依據更充分。
- 準確率 (Accuracy): 模型正確預測(包括正確預測故障和正確預測正常)的總體比例 ((TP + TN) / (TP + TN + FP + FN))1。雖然常用,但對于故障通常是小概率事件的PDM場景,單純看準確率可能具有誤導性。
-
設定閾值的考量因素——基于失敗成本的分析: 商業化應用所需的"足夠好"的精度閾值并非絕對,而是需要根據具體場景下的風險和成本進行權衡。
- 失敗成本分析 (Cost of Failure Analysis): 這是設定閾值的核心依據。需要評估不同類型錯誤的經濟后果:
- 假陰性成本 (Cost of FN / Undetected Failure): 通常包括緊急維修成本、生產損失、可能的安全或環境影響、聲譽損失等。對于關鍵設備,此成本可能極高。
- 假陽性成本 (Cost of FP / False Alarm): 通常包括檢查成本、不必要的維護人工和備件成本、以及因誤報導致的短暫停機損失。
- 權衡與決策: 閾值的設定實質上是在假陰性成本和假陽性成本之間尋找平衡點。
- 如果假陰性(漏報)的后果極其嚴重(如安全事故、核心設備停機),則傾向于設置更敏感的閾值(允許更高的誤報率FP,以捕捉盡可能多的真實故障TP,即提高敏感性/召回率)。
- 如果假陽性(誤報)的成本很高(如維護操作復雜昂貴、停機檢查影響大),則傾向于設置更保守的閾值(要求更高的證據才報警,以減少誤報FP,即提高精確率/特異性)。
- 輔助工具與方法:
- 成本函數模型: 將模型性能指標(精確率、召回率)與失敗成本(Cd, k)結合,量化不同閾值下的總成本,輔助找到成本最優的閾值點。
- FMECA分析: 通過評估不同故障模式的發生概率 (Occurrence) 和嚴重性 (Severity/Cost Impact),可以為不同故障模式設定差異化的監控優先級和報警閾值。
- 剩余使用壽命 (RUL) 估計: 閾值也可以基于RUL的預測值來設定,例如當預測RUL低于某個安全裕度時觸發維護。
- 失敗成本分析 (Cost of Failure Analysis): 這是設定閾值的核心依據。需要評估不同類型錯誤的經濟后果:
-
商業化成功的其他因素: 除了ROI和精度,PDM的成功商業化還需要考慮:數據的持續可用性和質量、與現有維護流程和系統(如CMMS)的集成、維護團隊的技能提升和對新技術的接納程度(組織變革管理)、以及選擇合適的技術供應商。
表5:預測性維護ROI場景分析 - 不同類型設備示例
| 設備類型 | 初始投資 (萬元) | 年度運營 成本(萬元) | 非計劃停機 減少 | 維護成本 節約 | 設備壽命 延長 | 投資回報周期 | 關鍵閾值設置考量 |
|---|---|---|---|---|---|---|---|
| 核心生產設備 (高價值生產線) | 80-120 | 15-25 | 40-50% | 25-30% | 20-30% | 9-12個月 | 重點避免漏報(FN), 可接受適度誤報(FP), 敏感性優先 |
| 輔助設備 (動力/空調系統) | 40-60 | 8-12 | 30-35% | 20-25% | 15-20% | 12-18個月 | 平衡漏報與誤報, 成本效益最優化 |
| 周邊設備 (物流傳送設備) | 20-30 | 5-8 | 20-30% | 15-20% | 10-15% | 18-24個月 | 避免過多誤報(FP), 精確率優先, 減少不必要干預 |
| 通用設備 (電機/泵/閥門) | 10-15 | 3-5 | 25-35% | 15-25% | 15-25% | 12-18個月 | 按批次設置差異化閾值, 依據設備重要性和 失效影響程度 |
總之,預測性維護的商業化并非簡單的技術部署,而是一個涉及經濟效益評估、風險權衡、模型性能優化和組織適應的復雜過程。通過嚴謹的ROI分析明確其價值,并基于對失敗成本的深刻理解來科學設定精度閾值,是確保PDM投資能夠帶來預期回報并成功融入企業運營的關鍵。同時,必須認識到模型預測本身存在不確定性,因此建立包含警報驗證、持續學習和人機結合的閉環反饋機制1,對于提升PDM系統的魯棒性和用戶的長期信任至關重要。
表3:預測性維護 (PDM) ROI 計算關鍵因素
| 類別 | 因素 | 指標/衡量方法 | 相關文獻 Snippets |
|---|---|---|---|
| 成本節約/收益 | 減少非計劃停機 | 停機小時減少量 × 每小時停機成本 | |
| 降低維護成本 | 預防性/反應性維護工時減少量 × 人工費率;備件成本降低百分比 | ||
| 延長設備壽命 | 增加的壽命年限 × (年折舊避免額 或 延期購置成本的現值) | ||
| 提高生產效率/OEE | 產量增加百分比 或 OEE提升百分比 | ||
| 提升產品質量 | 次品/返工減少量 × 單位成本 | ||
| 提高安全性/合規性 | 事故/罰款減少帶來的成本避免 (較難量化) | ||
| 降低MRO備件庫存 | 庫存持有成本降低百分比 | ||
| 提升能源效率 | 能耗降低百分比 × 單位能源成本 | ||
| 投資成本 | 硬件成本 (傳感器等) | 設備采購成本 | |
| 軟件成本 (平臺/算法) | 許可證費用 (一次性或訂閱) | ||
| 安裝/集成/校準/測試成本 | 實施服務費用或內部人工成本 | ||
| 員工培訓成本 | 培訓課程費用 + 參訓人員時間成本 | ||
| 系統維護與支持 (持續) | 年度維護合同費用 或 內部運維人工成本 | ||
| 數據存儲與計算 (持續) | 云服務費用 或 本地服務器運維成本 | ||
| 數據分析人力成本 (持續) | 數據科學家/分析師工資福利 |
數據來源: 綜合
表4:預測性維護 (PDM) 警報閾值設定框架
| 輸入因素 | 閾值設定考量 | 相關文獻 Snippets |
|---|---|---|
| 假陽性成本 (Cost of False Positive, FP) | 誤報成本高時 (如維護操作復雜、停機檢查影響大),傾向于提高閾值,要求更強的故障信號才報警,以犧牲部分敏感性來提高精確率/特異性,減少誤報。 | |
| 假陰性成本 (Cost of False Negative, FN) | 漏報成本高時 (如關鍵設備故障、安全風險大),傾向于降低閾值,對較弱的異常信號也報警,以犧牲部分精確率/特異性來提高敏感性/召回率,減少漏報。需要區分可檢測與不可檢測故障成本。 | |
| 模型敏感性 (Sensitivity / Recall) | 模型本身的敏感性能力決定了在特定閾值下能捕捉到多少真實故障。閾值調整直接影響敏感性。 | |
| 模型特異性 (Specificity) | 模型本身的特異性能力決定了在特定閾值下能排除多少正常狀態。閾值調整直接影響特異性。 | |
| 模型精確率 (Precision) | 閾值設定影響精確率,即報警的可靠性。精確率低意味著誤報多。 | |
| 資產重要性 (Asset Criticality) | 通過FMECA等方法評估。高重要性資產通常無法容忍漏報 (FN),傾向于更敏感的閾值。低重要性資產可能允許更高的漏報風險以避免誤報成本。 | |
| 故障發展速度 | 故障發展快的模式需要更低的閾值和更頻繁的監測,以確保有足夠的響應時間。 | |
| 監測間隔與響應時間 | 閾值設定需考慮監測頻率和從報警到采取行動所需的最短響應時間,確保預警足夠提前。 | |
| 數據質量與噪聲水平 | 數據噪聲大或質量不穩定時,過于敏感的閾值可能導致大量誤報,需要更魯棒的算法或更保守的閾值。 | |
| 成本函數優化 | 利用量化成本函數,模擬不同閾值下的總成本(FP成本+FN成本+維護成本),尋找使總成本最小化的閾值點。 |
數據來源: 綜合
8. 綜合路徑:邁向智能制造與智慧供應鏈
8.1. 技術與商業模式的融合
制造業與供應鏈的數字化轉型并非孤立技術的簡單堆砌,而是需要將先進技術與創新的商業模式深度融合,形成協同效應,才能最終實現價值創造。
核心技術對比與協同
| 技術類別 | 主要功能 | 核心價值 | 應用場景 |
|---|---|---|---|
| IIoT/邊緣計算 | 數據采集、實時處理 | 連接物理與數字世界 | 設備監控、實時控制、遠程運維 |
| AI/ML | 數據分析、預測決策 | 智能化升級、優化決策 | PDM、規范性維護、質量預測 |
| 區塊鏈 | 數據共享、信任建立 | 透明度、可追溯性 | 供應鏈協作、產品溯源、合規記錄 |
| 集成工具(如Node-RED) | 系統連接、流程編排 | 技術整合、快速部署 | 跨系統數據流、業務流程自動化 |
- 技術協同發揮價值: 本報告深入探討的幾項關鍵技術——工業物聯網預測性維護 (PDM)、區塊鏈和邊緣計算/物聯網集成——并非相互排斥,而是可以相互補充、協同工作。
- IIoT/邊緣計算 [第4節] 構成了數據獲取的基礎設施,負責連接物理世界和數字世界,并在靠近數據源的地方進行實時處理,為上層應用提供及時、有效的數據輸入。
- AI/ML [第2.3節] 是智能化的核心引擎,利用IIoT/邊緣計算采集的數據進行深度分析,實現精準的預測(如PDM)和優化的決策(如規范性維護)。
- 區塊鏈 [第3節] 則為跨組織的數據共享和協作提供了可信的基礎設施,確保數據的透明度、不可篡改性和可追溯性,解決了多方協作中的信任難題。例如,可以將經過邊緣計算處理的關鍵設備狀態數據或經過AI預測的維護建議,記錄在區塊鏈上,供供應鏈伙伴(如設備供應商、維護服務商)可信地訪問。Node-RED [第4.3節] 等集成工具則扮演著"粘合劑"的角色,將這些不同的技術模塊和數據流連接起來。
技術驅動的商業模式創新
- 技術驅動商業模式創新: 技術的應用最終要服務于商業目標,并可能催生新的商業模式。
- 鏈主引領的生態協同模式: “鏈主"企業 [第1.2節] 利用其技術和市場優勢,通過數據共享和平臺建設,發揮"雙邊溢出效應” [第5節],帶動整個供應鏈生態系統的數字化升級。這本身就是一種基于平臺和生態的商業模式創新。
- 基于數據的增值服務: PDM技術的成熟使得設備制造商或服務商可以從傳統的銷售產品模式,轉向提供基于設備運行狀態和性能的增值服務,例如按需維護、設備健康管理、甚至"設備即服務"(按正常運行時間或產出收費)的模式。邊緣計算使得這種服務的實時性成為可能。
- 可信追溯驅動的品牌價值提升: 區塊鏈技術提供的端到端可追溯性,尤其在食品、醫藥、奢侈品等領域 [第3.2節],可以顯著提升產品的透明度和消費者信任度,從而增強品牌價值和市場競爭力。
- 柔性制造與個性化定制: 邊緣計算、物聯網和AI的結合,使得工廠能夠更靈活地響應個性化訂單,實現小批量、多品種的柔性生產,甚至向"制造即服務"(MaaS) 的模式演進。
整合路徑建議與實施階段
- 整合路徑建議: 企業在推進轉型時,應考慮一個整合的技術與商業演進路徑,而非單點突破。一個可能的階段性路徑是:
. 奠定基礎: 建設穩健的IIoT基礎設施,實現關鍵設備和流程的數據采集與連接,完善數據治理 [第7.1節]。
. 提升效率: 應用CBM和基礎的PDM技術 [第2.1節],結合邊緣計算進行實時監控和早期預警,提升內部運營效率。
. 深化智能: 引入更高級的AI/ML算法,實現更精準的PDM和初步的規范性維護,優化資產管理和維護策略 [第2.3節]。
. 增強信任與透明: 在需要高可信度和可追溯性的環節(如關鍵零部件、質量控制、合規記錄)引入區塊鏈技術 [第3節]。
. 拓展協同: 鏈主企業構建數據共享平臺,利用數據空間理念 [第7.1節] 和技術,發揮雙邊溢出效應,推動供應鏈伙伴協同轉型,探索新的生態商業模式。
8.2. 轉型的關鍵挑戰與成功要素
盡管數字化轉型前景廣闊,但在實踐中企業仍面臨諸多挑戰。識別這些挑戰并掌握關鍵成功要素,對于確保轉型順利推進至關重要。
數字化轉型主要挑戰與應對策略
| 挑戰類別 | 主要表現 | 應對策略 | 關鍵成功要素 |
|---|---|---|---|
| 數據相關 | 數據就緒度低、數據孤島、集成復雜 | 數據治理體系建設、標準化接口開發 | 堅實的數據基礎、統一數據標準 |
| 技術集成 | 新舊系統融合難、缺乏標準化 | 采用開放標準、構建中間層 | 互操作性設計、漸進式架構 |
| 成本與ROI | 高投入、回報不確定 | 分階段實施、價值快速驗證 | 以業務價值為導向、小步快跑 |
| 安全與治理 | 網絡安全風險、數據隱私 | 安全架構設計、合規框架建立 | 風險管控機制、合規優先策略 |
| 人才與技能 | 復合人才缺乏、技能更新慢 | 培訓計劃、專家引進 | 人才培養、組織變革 |
| 組織與文化 | 部門壁壘、抵觸情緒 | 組織重構、文化引導 | 強有力領導、文化塑造 |
| 標準化 | 行業標準缺失、互通難度大 | 參與標準制定、采用開放技術 | 開放合作、生態思維 |
- 主要挑戰:
- 數據相關挑戰: 數據就緒度低(可用性、質量、完整性差)是首要障礙6;數據孤島普遍存在;數據采集和集成的成本與復雜性高;數據過載難以處理。
- 技術集成挑戰: 將新技術(IIoT, AI, Blockchain, Edge)與現有老舊系統(OT/IT)集成難度大,缺乏標準化接口和協議。
- 成本與ROI挑戰: 數字化轉型需要高昂的前期投資,而投資回報(ROI)的量化和證明存在不確定性,使得決策困難。
- 安全與治理挑戰: 數據共享和互聯互通帶來了新的網絡安全風險和數據隱私合規壓力,需要健全的治理框架。
- 人才與技能挑戰: 缺乏既懂業務又懂數字化技術的復合型人才,現有員工技能更新速度跟不上技術發展。
- 組織與文化挑戰: 轉型需要跨部門協作,但組織壁壘和"筒倉效應"普遍存在;員工可能對變革產生抵觸情緒;缺乏數據驅動的決策文化。
- 標準化與互操作性挑戰: 缺乏統一的行業標準和技術規范,導致不同廠商的設備和平臺難以互聯互通,增加了集成成本和生態構建難度。
數字化轉型成功要素框架
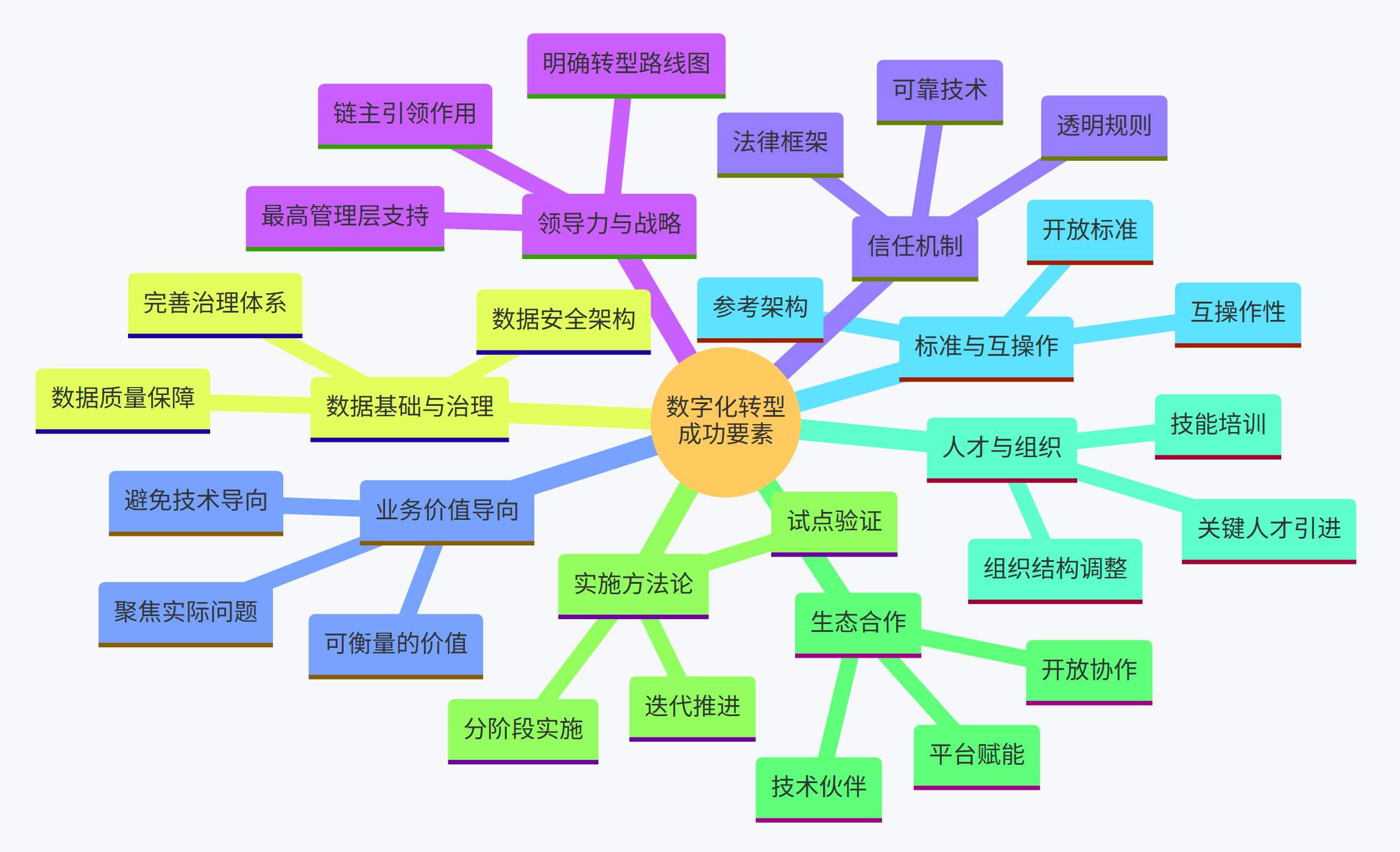
- 關鍵成功要素:
- 強有力的領導力與清晰戰略: 最高管理層的決心和支持是轉型的根本保障;需要制定清晰的、與業務目標緊密結合的數字化轉型戰略和路線圖。鏈主企業的引領作用尤為關鍵。
- 以業務價值為導向: 技術應用應聚焦于解決實際業務問題,創造可衡量的價值(如提升效率、降低成本、改善客戶體驗),而非為技術而技術。
- 堅實的數據基礎與治理: 將數據視為核心資產,優先投入資源建設可靠的數據采集、存儲、管理基礎設施,并建立完善的數據治理體系,確保數據質量和安全6。
- 循序漸進、迭代推進: 采取分階段實施的方法,從試點項目或高價值場景入手,驗證效果、積累經驗、逐步推廣,避免"大爆炸"式變革帶來的風險。
- 開放合作與生態構建: 認識到轉型非一家企業能獨立完成,積極與技術伙伴、供應鏈伙伴開展合作,共同構建開放、互利的數字生態系統。鏈主企業應主動承擔生態構建者的角色。
- 人才培養與組織變革: 持續投資于員工技能培訓,引進關鍵人才;推動組織結構調整,打破部門壁壘;培育擁抱變革、數據驅動的企業文化。
- 重視標準化與互操作性: 在技術選型和系統建設中,優先考慮采用開放標準和具備良好互操作性的解決方案(如遵循IDS、IIRA等參考架構),為未來的集成和擴展奠定基礎。
- 建立信任機制: 在涉及多方數據共享的場景下,通過透明的規則、可靠的技術(如區塊鏈、數據空間)和具有法律效力的協議,建立合作伙伴間的信任關系。
8.3. 對各類企業的戰略建議
基于上述分析,針對不同類型的企業,提出以下戰略建議:
企業數字化轉型戰略矩陣
| 企業類型 | 戰略重點 | 實施要點 | 預期成果 |
|---|---|---|---|
| 所有企業 | 戰略先行、數據為基 | 明確目標、夯實基礎、小步快跑 | 效率提升、成本降低、決策優化 |
| 鏈主企業 | 平臺化思維、生態構建 | 引領行業、標準制定、伙伴賦能 | 生態價值、供應鏈韌性、創新加速 |
| 中小企業 | 緊跟鏈主、聚焦核心 | 差異化定位、平臺利用、資源整合 | 協同提升、降低成本、專業增值 |
- 對所有尋求轉型的企業:
. 戰略先行: 明確數字化轉型的業務目標和戰略優先級,切忌盲目跟風。
. 數據為基: 將數據治理和數據質量提升作為基礎工程來抓,沒有高質量的數據,后續的AI、大數據應用都將是空中樓閣。
. 基建投入: 投資建設靈活、可擴展的IIoT基礎設施,為未來的數據采集和應用奠定基礎。
. 小步快跑: 從能夠快速產生價值的試點項目開始,驗證技術可行性和商業模式,然后逐步推廣。
. 人才賦能: 制定人才培養計劃,提升現有員工的數字技能,同時引進外部專業人才。
. 文化塑造: 培育鼓勵創新、容忍試錯、基于數據進行決策的企業文化。 - 對鏈主企業:
. 擔當引領者: 充分認識并主動發揮自身在供應鏈中的引領作用和"雙邊溢出效應"。
. 平臺化思維: 考慮構建開放的數據共享平臺或參與/主導行業數據空間的建設 [第7.1節],為生態伙伴賦能。
. 善用影響力: 結合運營要求和金融工具(如供應鏈金融),引導和激勵合作伙伴共同進行數字化升級。
. 標準倡導者: 在自身實踐的基礎上,積極參與或推動行業數據標準和技術規范的制定,降低整個生態的協同成本。 - 對中小企業/合作伙伴:
. 緊跟鏈主: 積極響應鏈主企業的數字化要求,將其視為自身轉型升級的契機。
. 聚焦核心能力: 結合自身業務特點和資源限制,優先在能夠直接提升與鏈主協同效率或滿足其核心需求的環節進行數字化投入。
. 借力平臺: 充分利用鏈主企業提供的共享平臺、數據資源和技術支持,降低轉型成本。
. 尋求差異化: 在滿足基本協同要求的基礎上,探索在特定領域(如柔性制造、專業化服務)利用數字化技術建立自身的差異化競爭優勢。
制造業與供應鏈數字化轉型綜合價值模型
結論
制造業與供應鏈的數字化轉型是一場深刻而復雜的系統性變革,技術是驅動力,而商業模式創新和生態協同是實現價值的關鍵。本文深入剖析了預測性維護、區塊鏈、邊緣計算等核心使能技術,并結合鏈主企業模式、雙邊溢出效應等商業洞察,揭示了轉型的內在邏輯和實踐路徑。
成功轉型并非易事,企業需要克服數據、技術、成本、安全、人才和組織等多重挑戰。然而,通過制定清晰的戰略、夯實數據基礎、采取分階段實施、重視生態合作、并建立有效的風險管控和治理機制,企業完全有能力駕馭這場變革。特別是鏈主企業,應勇于擔當,利用其資源和影響力,通過數據共享和平臺賦能,激發雙邊溢出效應,引領整個供應鏈生態邁向更智能、更高效、更具韌性的未來。對于所有參與者而言,擁抱數字化、持續學習、開放合作,將是在這場轉型浪潮中保持競爭力的不二法門。

與 Go 協程的運行原理不同 為何Go 能在低配機器上承接10萬 Websocket 協議連接)

:學會控件的使用(自定義彈窗))
——考試介紹【新】)



)
——DDS信號發生器設計)

)




 (傳輸協議層:UDP、TCP))


