**問題1:**Causal Language Modeling 和 Conditional Generation 、Sequence Classification 的區別是什么?
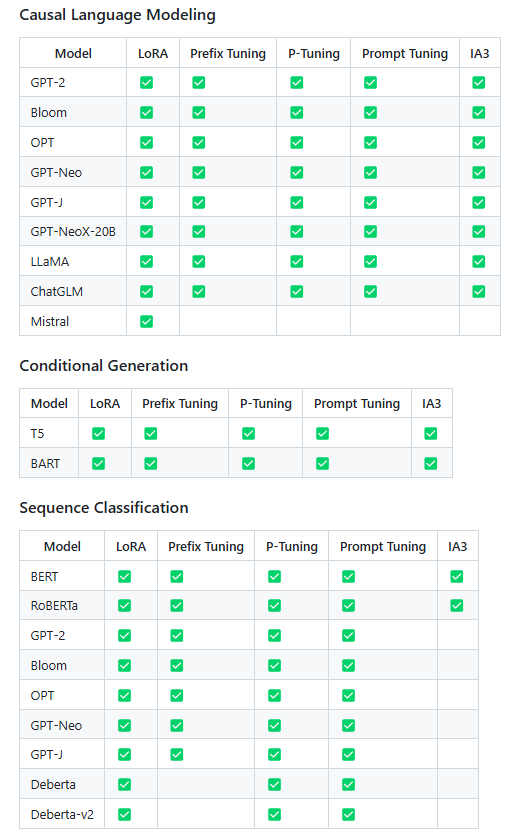
因果語言模型(Causal Language Model): 預測給定文本序列中的下一個字符,一般用于文本生成、補全句子等,模型學習給定文本序列的概率分布,并預測下一個最可能的詞或字符。
條件生成模型(Conditional Generation): 基于給定的條件或輸入生成新的文本,模型不僅學習文本序列的概率分布,還學習如何根據給定的條件生成文本。常見的模型包括T5(Text-to-Text Transfer Transformer)和BART(Bidirectional and Auto-Regressive Transformer)。一般用于翻譯、問答。
序列分類模型(Sequence Classification): 將輸入的文本序列分類到預定義的類別中。常見的模型包括BERT(Bidirectional Encoder Representations from Transformers)和RoBERTa(Robustly Optimized BERT Pretraining Approach)。一般任務為情感分析、文本分類、垃圾郵件檢測。
條件生成模型和因果模型之間的差別:
因果語言模型(Causal Language Model) 與序列到序列模型(Seq2Seq)的區別與聯系_causal language modeling-CSDN博客
淺談NLP中條件語言模型(Conditioned Language Models)的生成和評估 - 知乎
Seq2Seq: 專指 encoder-decoder 架構,和條件生成模型是同一個東西,一般用于翻譯任務和圖生文。從一個序列到另一個序列。
原因: 因為輸入和輸入的數據類型不相同,所以需要 encoder 將其轉為同空間的序列,然后再通過 Decoder 將這個序列展開為輸出的結果。Decoder 生成下一個詞的時候,不僅依賴于歷史序列,還依賴與編碼器提供的外部信息。
Casual Model: Causal Language Model是一種只包含解碼器(Decoder-only)的模型,它的核心思想是根據前面的文本序列來生成后面的文本序列。所以它的特點是,每次生成下一個詞時,模型會考慮前面已經生成的所有詞(上下文)。這種模型本質上是自回歸的,即“基于前面的內容生成后面的內容”。
原因: 完全依賴于自身生成的歷史序列。



 (傳輸協議層:UDP、TCP))






——ViT理解與應用)







)
