CNN原理
從DNN到CNN
- 卷積層與匯聚
- 深度神經網絡DNN中,相鄰層的所有神經元之間都有連接,這叫全連接;卷積神經網絡 CNN 中,新增了卷積層(Convolution)與匯聚(Pooling)。
- DNN 的全連接層對應 CNN 的卷積層,匯聚是與激活函數類似的附件;單個卷積層的結構是:卷積層-激活函數-(匯聚),其中匯聚可省略。
2.CNN:專攻多維數據
在深度神經網絡 DNN 課程的最后一章,使用 DNN 進行了手寫數字的識別。但是,圖像至少就有二維,向全連接層輸入時,需要多維數據拉平為 1 維數據,這樣一來,圖像的形狀就被忽視了,很多特征是隱藏在空間屬性里的,如下圖所示。
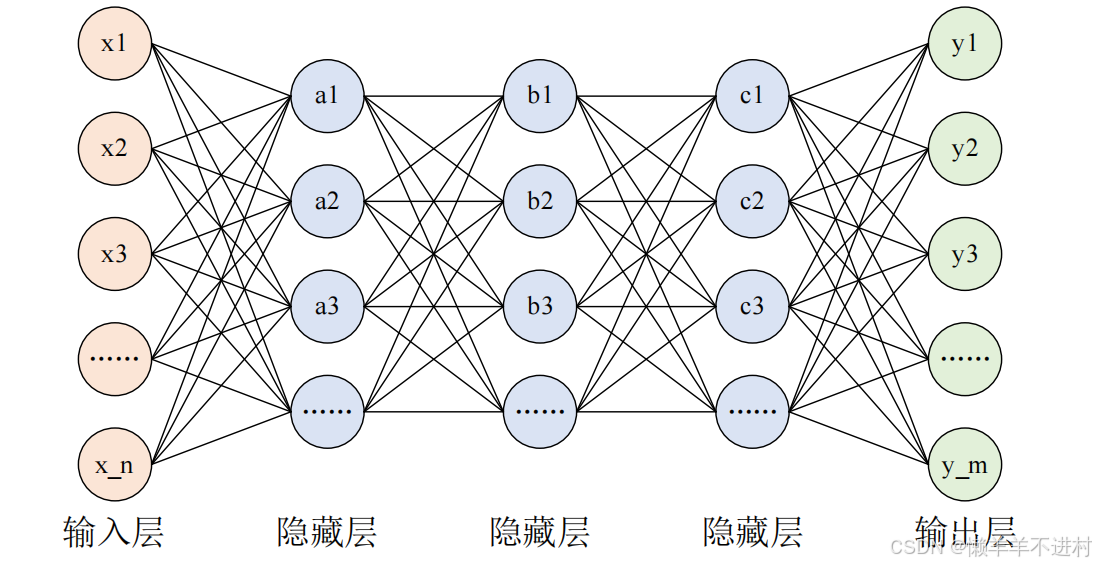
而卷積層可以保持輸入數據的維數不變,當輸入數據是二維圖像時,卷積層會以多維數據的形式接收輸入數據,并同樣以多維數據的形式輸出至下一層,如下圖所示。
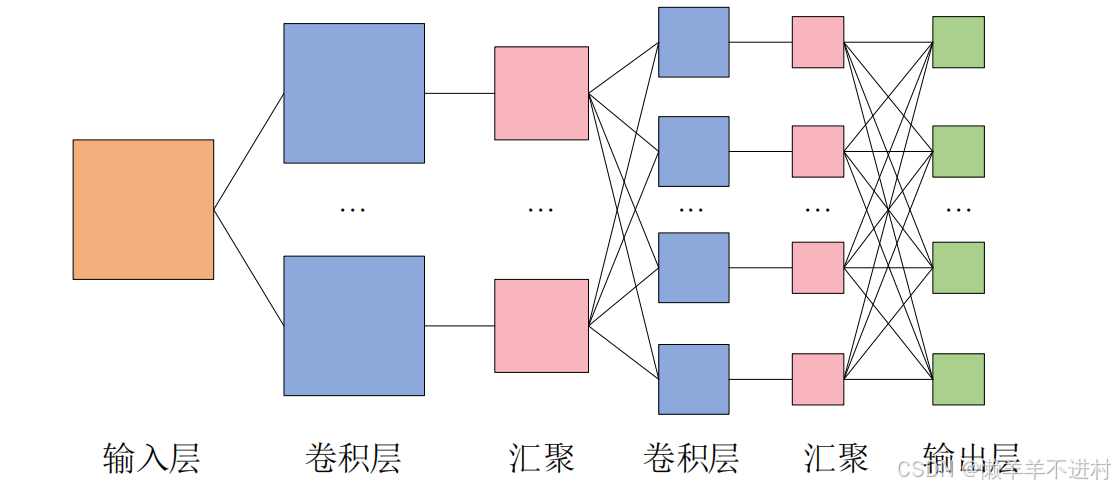
卷積層
CNN 中的卷積層與 DNN 中的全連接層是平級關系,全連接層中的權重與偏置即y = ω1x1 + ω2x2 + ω3x3 + b中的 ω 與 b,卷積層中的權重與偏置變得稍微復雜。
-
內部參數:權重(卷積核)
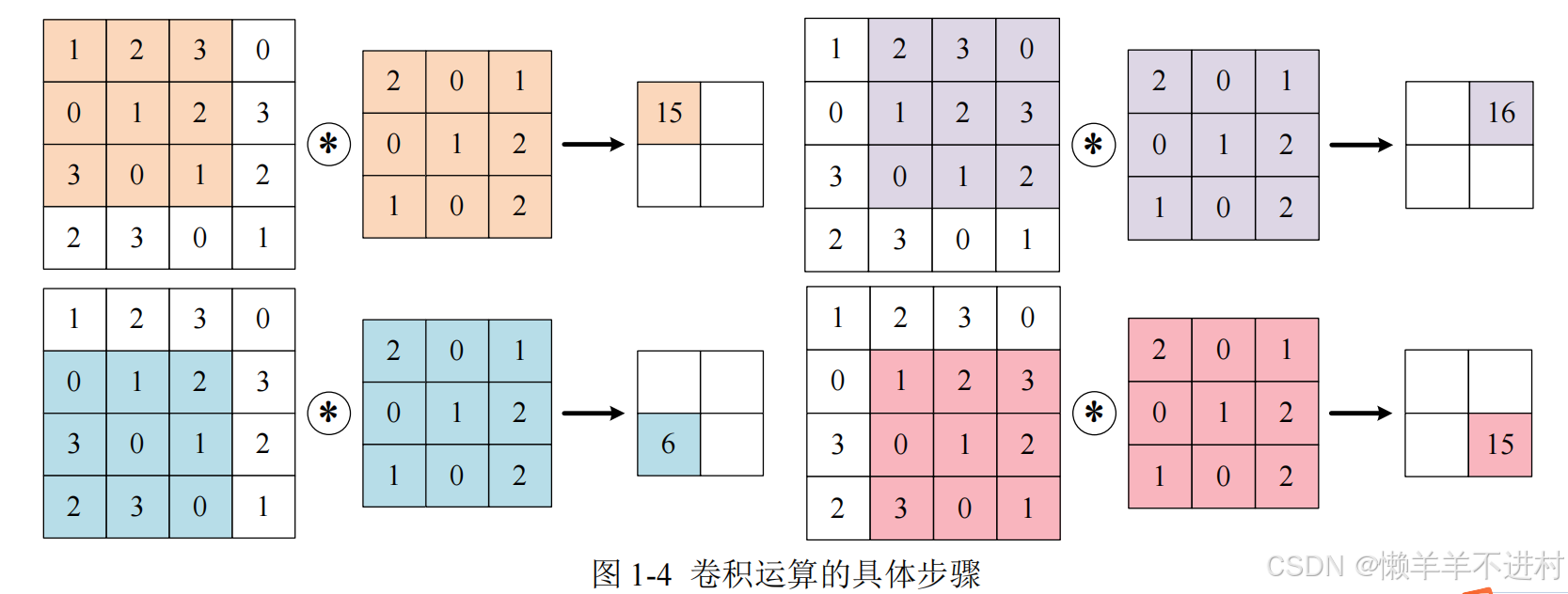
當輸入數據進入卷積層后,輸入數據會與卷積核進行卷積運算,如下圖:

上圖中的輸入大小是(4,4),卷積核大小事(3,3),輸出大小是(2,2)卷積運算的原理是逐元素乘積后再相加。
-
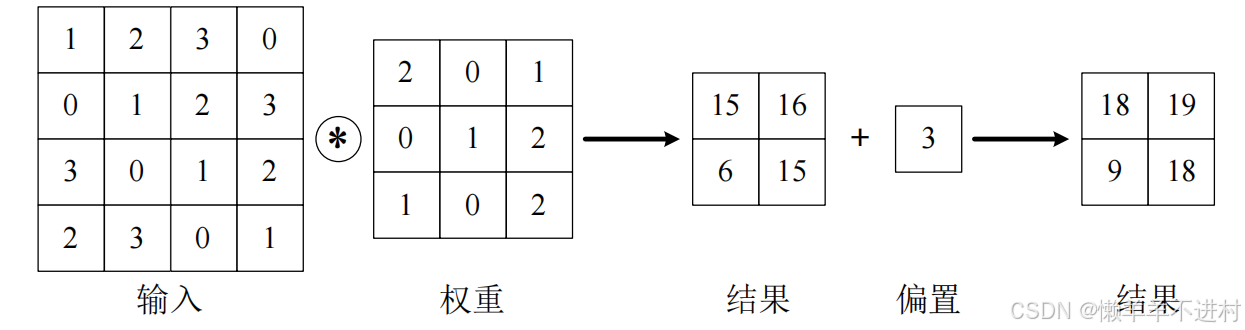
內部參數:偏置
在卷積運算的過程中也存在偏置,如下圖所示:
-
外部參數:補充
為了防止經過多個卷積層后圖像越卷越小,可以在進行卷積層的處理之前,向輸入數據的周圍填入固定的數據(比如 0),這稱為填充(padding)。
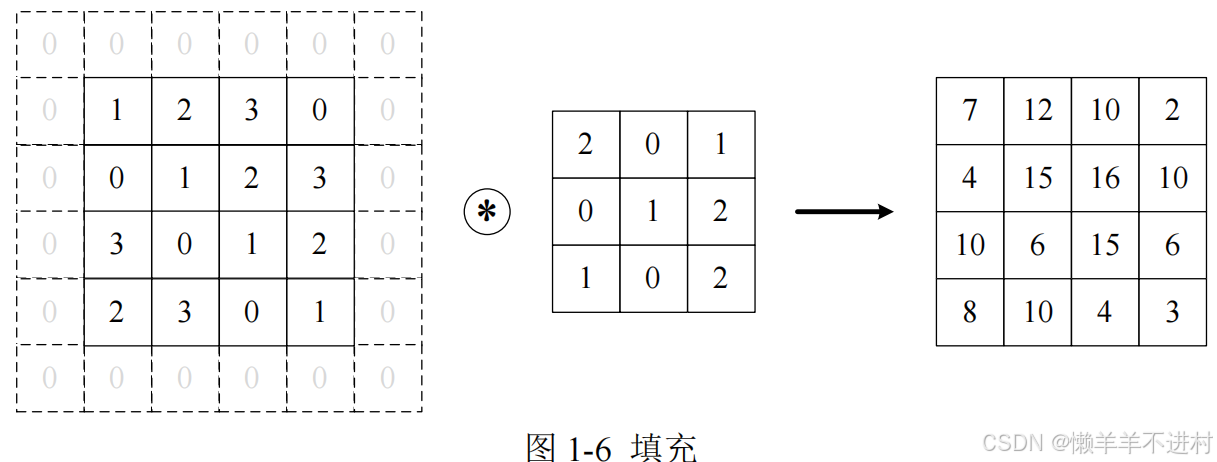
對上圖大小為(4, 4)的輸入數據應用了幅度為 1 的填充,填充值為 0。 -
外部參數:步幅
使用卷積核的位置間隔被稱為步幅(stride),之前的例子中步幅都是 1,如果將步幅設為 2,此時使用卷積核的窗口的間隔變為 2。
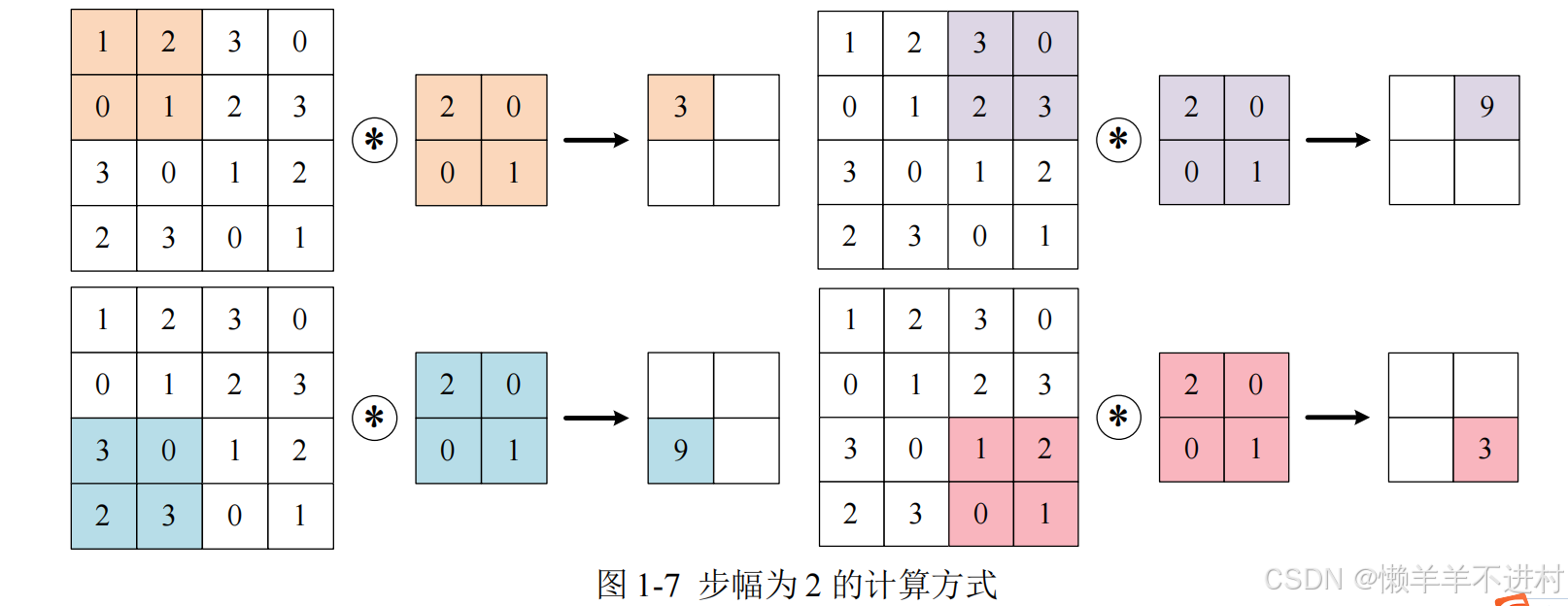
綜上,增大填充后,輸出尺寸會變大;而增大步幅后,輸出尺寸會變小 -
輸入與輸出尺寸的關系
假設輸入尺寸為(H, W),卷積核的尺寸為(FH, FW),填充為 P,步幅為 S。則輸出尺寸(OH, OW)的計算公式為
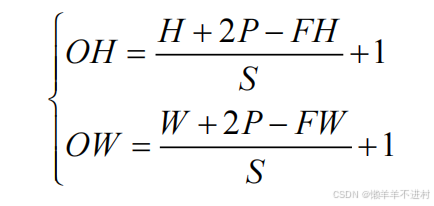
多通道
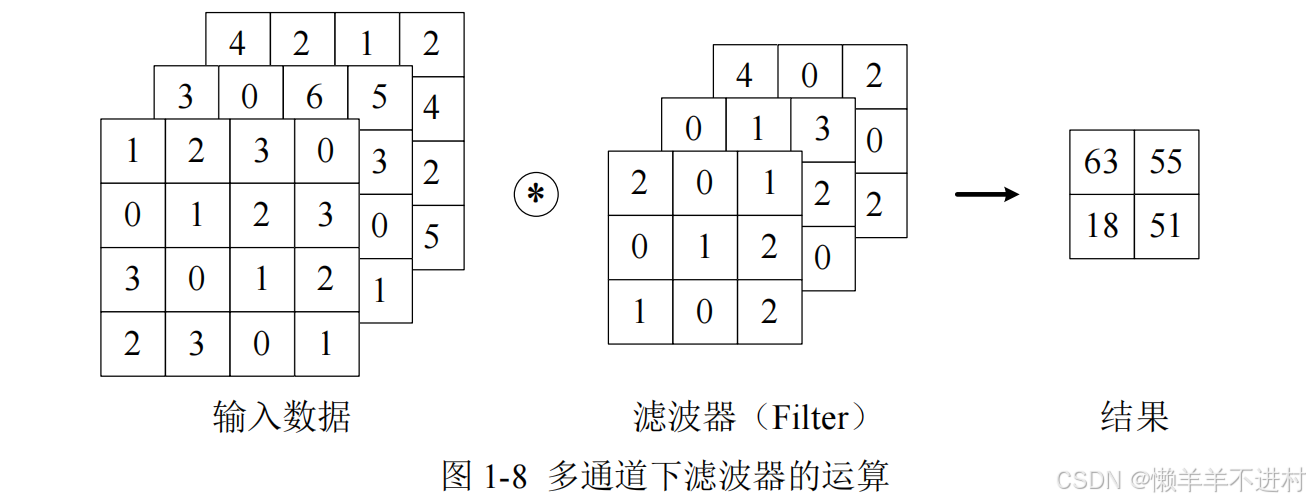
在上一小節講的卷積層,僅僅針對二維的輸入與輸出數據(一般是灰度圖像),可稱之為單通道。
但是,彩色圖像除了高、長兩個維度之外,還有第三個維度:通道(channel)。例如,以 RGB 三原色為基礎的彩色圖像,其通道方向就有紅、黃、藍三部分,可視為 3 個單通道二維圖像的混合疊加。一般的,當輸入數據是二維時,權重被稱為卷積核(Kernel);當輸入數據是三維或更高時,權重被稱為濾波器(Filter)。
1.多通道輸入
對三維數據的卷積操作如圖 1-8 所示,輸入數據與濾波器的通道數必須要設為相同的值,可以發現,這種情況下的輸出結果降級為了二維
將數據和濾波器看作長方體,如圖 1-9 所示

C、H、W 是固定的順序,通道數要寫在高與寬的前面
圖 1-9 可看出,僅通過一個卷積層,三維就被降成二維了。大多數時候我們想讓三維的特征多經過幾個卷積層,因此就需要多通道輸出,如圖 1-10 所示。
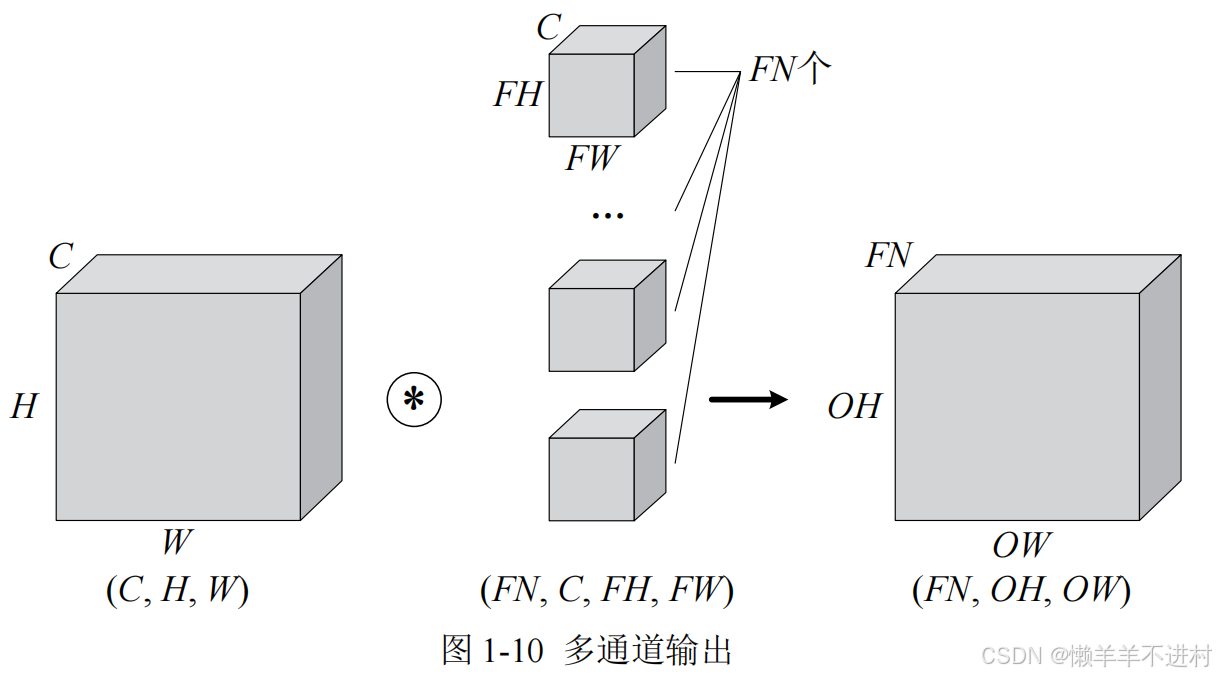
別忘了,卷積運算中存在偏置,如果進一步追加偏置的加法運算處理,則結果如圖 1-11 所示,每個通道都有一個單獨的偏置。

匯聚(很多教材也叫做池化)
匯聚(Pooling)僅僅是從一定范圍內提取一個特征值,所以不存在要學習的內部參數。一般有平均匯聚與最大值匯聚。
-
平均匯聚
一個以步幅為2進行的2*2窗口的平均匯聚,如圖1-12所示

-
最大值匯聚
一個以步幅為 2 進行 2*2 窗口的最大值匯聚,如圖 1-13 所示
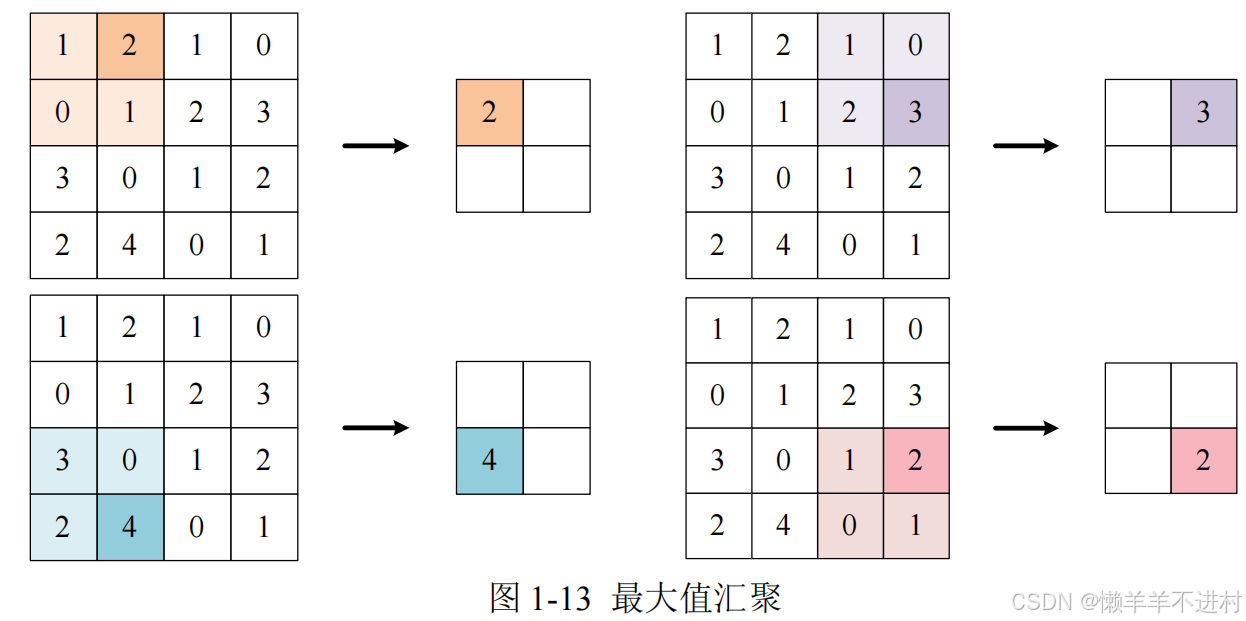
匯聚對圖像的高 H 和寬 W 進行特征提取,不改變通道數 C。
尺寸變換總結
- 卷積層
現假設卷積層的填充為P,步幅為S,由
- 輸入數據的尺寸是:( C,H,W) 。
- 濾波器的尺寸是:(FN,C,FH,FW)。
- 輸出數據的尺寸是:(FN,OH,OW) 。
可得
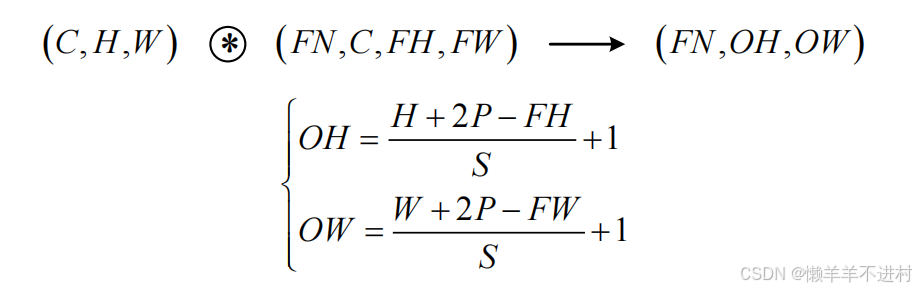
2. 匯聚
現假設匯聚的步幅為 S,由
- 輸入數據的尺寸是:( C,H,W) 。
- 輸出數據的尺寸是:(C,OH,OW) 。
可得
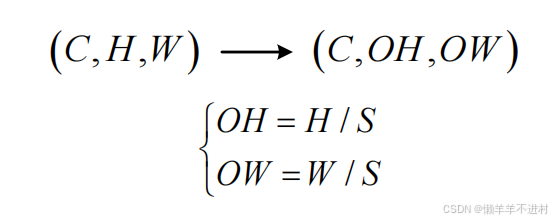
LeNet-5
網絡結構
LeNet-5 雖誕生于 1998 年,但基于它的手寫數字識別系統則非常成功。
該網絡共 7 層,輸入圖像尺寸為 28×28,輸出則是 10 個神經元,分別表示某手寫數字是 0 至 9 的概率。
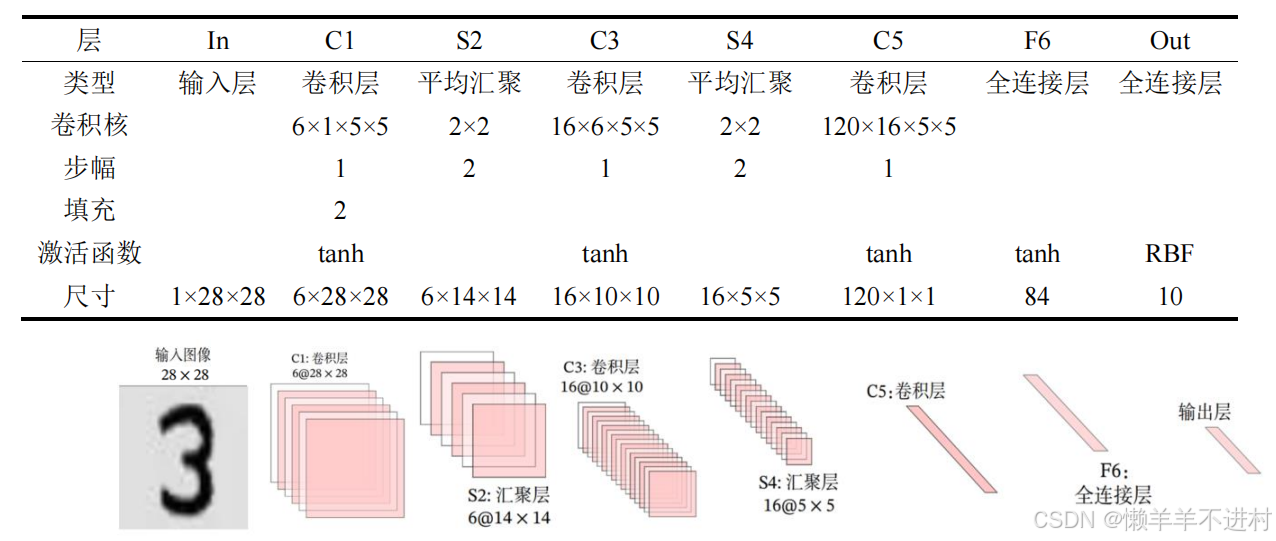
PS:輸出層由 10 個徑向基函數 RBF 組成,用于歸一化最終的結果,目前RBF 已被 Softmax 取代。
根據網絡結構,在 PyTorch 的 nn.Sequential 中編寫為
self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(), # C1:卷積層nn.AvgPool2d(kernel_size=2, stride=2), # S2:平均匯聚nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(), # C3:卷積層nn.AvgPool2d(kernel_size=2, stride=2), # S4:平均匯聚nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(), # C5:卷積層nn.Flatten(), # 把圖像鋪平成一維nn.Linear(120, 84), nn.Tanh(), # F5:全連接層nn.Linear(84, 10) # F6:全連接層
)
其中,nn.Conv2d( )需要四個參數,分別為
- in_channel:此層輸入圖像的通道數;
- out_channel:此層輸出圖像的通道數;
- kernel_size:卷積核尺寸;
- padding:填充;
- stride:步幅。
制作數據集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清圖
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作數據集
# 數據集轉換參數
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.1307, 0.3081)
])
# 下載訓練集與測試集
train_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下載路徑train = True, # 是 train 集download = True, # 如果該路徑沒有該數據集,就下載transform = transform # 數據集轉換參數
)
test_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下載路徑train = False, # 是 test 集download = True, # 如果該路徑沒有該數據集,就下載transform = transform # 數據集轉換參數
)
# 批次加載器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
搭建神經網絡
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10))def forward(self, x):y = self.net(x)return y
# 查看網絡結構
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )

# 創建子類的實例,并搬到 GPU 上
model = CNN().to('cuda:0')
訓練網絡
# 損失函數的選擇
loss_fn = nn.CrossEntropyLoss() # 自帶 softmax 激活函數
# 優化算法的選擇
learning_rate = 0.9 # 設置學習率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 訓練網絡
epochs = 5
losses = [] # 記錄損失函數變化的列表
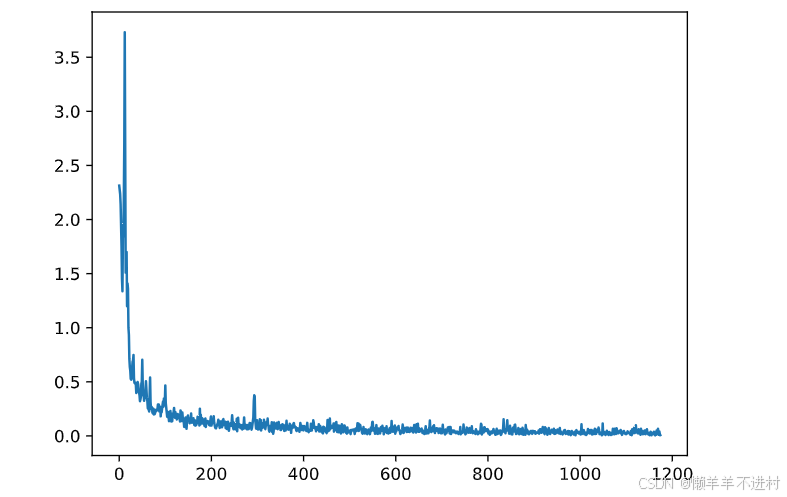
for epoch in range(epochs):for (x, y) in train_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)loss = loss_fn(Pred, y) # 計算損失函數losses.append(loss.item()) # 記錄損失函數的變化optimizer.zero_grad() # 清理上一輪滯留的梯度loss.backward() # 一次反向傳播optimizer.step() # 優化內部參數
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
測試網絡
# 測試網絡
correct = 0
total = 0
with torch.no_grad(): # 該局部關閉梯度計算功能for (x, y) in test_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0) print(f'測試集精準度: {100*correct/total} %') #OUT:測試集精準度: 9.569999694824219 %
AlexNet
網絡結構
AlexNet 是第一個現代深度卷積網絡模型,其首次使用了很多現代網絡的技術方法,作為 2012 年 ImageNet 圖像分類競賽冠軍,輸入為 3×224×224 的圖像,輸出為 1000 個類別的條件概率。
考慮到如果使用 ImageNet 訓練集會導致訓練時間過長,這里使用稍低億檔的 1×28×28 的 MNIST 數據集,并手動將其分辨率從 1×28×28 提到 1×224×224,同時輸出從 1000 個類別降到 10 個,修改后的網絡結構見下表。
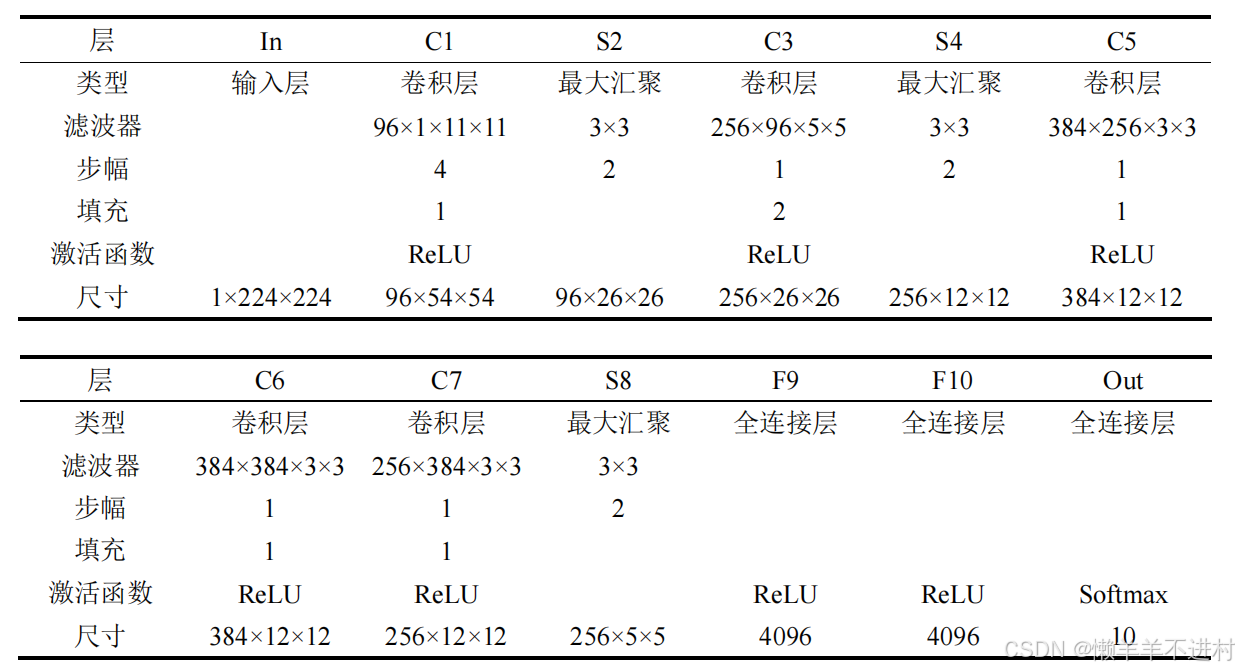
根據網絡結構,在 PyTorch 的 nn.Sequential 中編寫為
self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5), # Dropout——隨機丟棄權重nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5), # 按概率 p 隨機丟棄突觸nn.Linear(4096, 10)
)
制作數據集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清圖
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作數據集
# 數據集轉換參數
transform = transforms.Compose([transforms.ToTensor(),transforms.Resize(224),transforms.Normalize(0.1307, 0.3081)
])
# 下載訓練集與測試集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加載器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神經網絡
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))def forward(self, x):y = self.net(x)return y
# 查看網絡結構
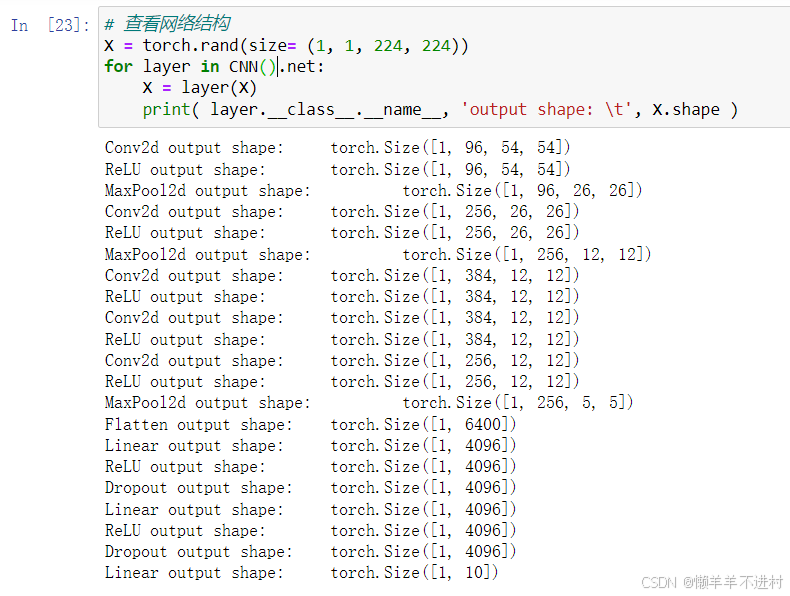
X = torch.rand(size= (1, 1, 224, 224))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 創建子類的實例,并搬到 GPU 上
model = CNN().to('cuda:0')
訓練網絡
# 損失函數的選擇
loss_fn = nn.CrossEntropyLoss() # 自帶 softmax 激活函數
# 優化算法的選擇
learning_rate = 0.1 # 設置學習率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 訓練網絡
epochs = 10
losses = [] # 記錄損失函數變化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)loss = loss_fn(Pred, y) # 計算損失函數losses.append(loss.item()) # 記錄損失函數的變化optimizer.zero_grad() # 清理上一輪滯留的梯度loss.backward() # 一次反向傳播optimizer.step() # 優化內部參數
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
測試網絡
# 測試網絡
correct = 0
total = 0
with torch.no_grad(): # 該局部關閉梯度計算功能for (x, y) in test_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'測試集精準度: {100*correct/total} %')
GoogLeNet
網絡結構
2014 年,獲得 ImageNet 圖像分類競賽的冠軍是 GoogLeNet,其解決了一個重要問題:濾波器超參數選擇困難,如何能夠自動找到最佳的情況。
其在網絡中引入了一個小網絡——Inception 塊,由 4 條并行路徑組成,4 條路徑互不干擾。這樣一來,超參數最好的分支的那條分支,其權重會在訓練過程中不斷增加,這就類似于幫我們挑選最佳的超參數,如示例所示。
# 一個 Inception 塊
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
此外,分支 2 和分支 3 上增加了額外 1×1 的濾波器,這是為了減少通道數,降低模型復雜度。
GoogLeNet 之所以叫 GoogLeNet,是為了向 LeNet 致敬,其網絡結構為
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10) )def forward(self, x):y = self.net(x)return y
制作數據集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清圖
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作數據集
# 數據集轉換參數
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下載訓練集與測試集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加載器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神經網絡
# 一個 Inception 塊
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10))def forward(self, x):y = self.net(x) return y
# 查看網絡結構
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 創建子類的實例,并搬到 GPU 上
model = CNN().to('cuda:0')
訓練網絡
# 損失函數的選擇
loss_fn = nn.CrossEntropyLoss()
# 優化算法的選擇
learning_rate = 0.1 # 設置學習率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 訓練網絡
epochs = 10
losses = [] # 記錄損失函數變化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)loss = loss_fn(Pred, y) # 計算損失函數losses.append(loss.item()) # 記錄損失函數的變化optimizer.zero_grad() # 清理上一輪滯留的梯度loss.backward() # 一次反向傳播optimizer.step() # 優化內部參數
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
測試網絡
# 測試網絡
correct = 0
total = 0
with torch.no_grad(): # 該局部關閉梯度計算功能for (x, y) in test_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)print(f'測試集精準度: {100*correct/total} %')
ResNet
網絡結構
殘差網絡(Residual Network,ResNet)榮獲 2015 年的 ImageNet 圖像分類競賽冠軍,其可以緩解深度神經網絡中增加深度帶來的“梯度消失”問題。
在反向傳播計算梯度時,梯度是不斷相乘的,假如訓練到后期,各層的梯度均小于 1,則其相乘起來就會不斷趨于 0。因此,深度學習的隱藏層并非越多越好,隱藏層越深,梯度越趨于 0,此之謂“梯度消失”。
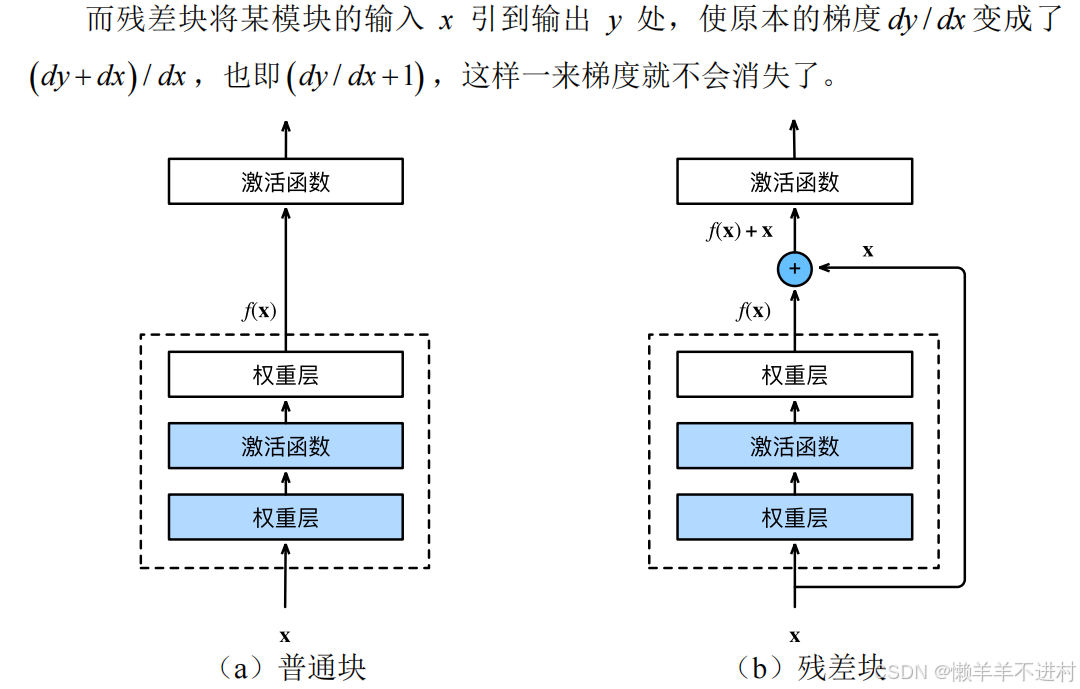
制作數據集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清圖
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作數據集
# 數據集轉換參數
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下載訓練集與測試集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加載器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神經網絡
# 殘差塊
class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.net = nn.Sequential(nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(channels, channels, kernel_size=3, padding=1),)def forward(self, x):y = self.net(x)return nn.functional.relu(x+y)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(16),nn.Conv2d(16, 32, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(32),nn.Flatten(),nn.Linear(512, 10))def forward(self, x):y = self.net(x) return y
# 查看網絡結構
X = torch.rand(size= (1, 1, 28, 28))for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 創建子類的實例,并搬到 GPU 上
model = CNN().to('cuda:0')
訓練網絡
# 損失函數的選擇
loss_fn = nn.CrossEntropyLoss()
# 優化算法的選擇
learning_rate = 0.1 # 設置學習率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 訓練網絡
epochs = 10
losses = [] # 記錄損失函數變化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)loss = loss_fn(Pred, y) # 計算損失函數losses.append(loss.item()) # 記錄損失函數的變化optimizer.zero_grad() # 清理上一輪滯留的梯度loss.backward() # 一次反向傳播optimizer.step() # 優化內部參數
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
測試網絡
# 測試網絡
correct = 0
total = 0
with torch.no_grad(): # 該局部關閉梯度計算功能for (x, y) in test_loader: # 獲取小批次的 x 與 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向傳播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'測試集精準度: {100*correct/total} %')
)






)


零基礎入門系列第十二篇(完結篇):數據統計功能實現)








