進程的概念與原理
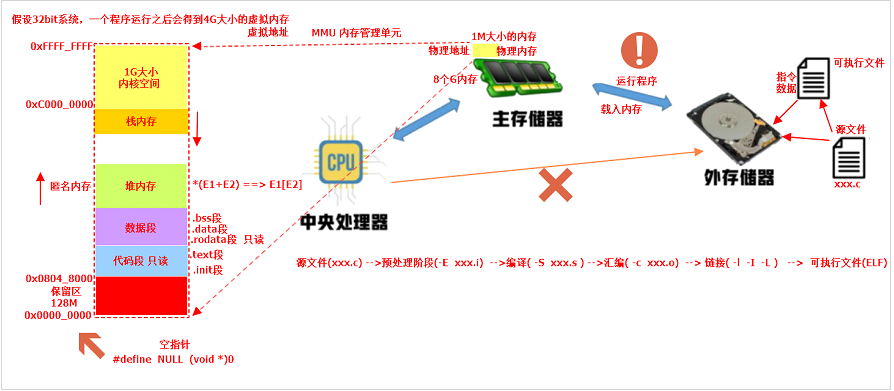
計算機組成部分一般遵循馮諾依曼結構,也就是由控制器、運算器、存儲器、輸入設備、輸出設備五個部分組成。
? 程序的編譯
一般在編寫出程序之后,并不能直接運行,而是需要把程序通過編譯器進行編譯,生成可執行文件才能運行。而對于嵌入式學習,一般都是在Linux系統下使用GCC編譯器對程序進行編譯。

GCC編譯器是Linux系統默認的C/C++編譯器,大部分Linux發行版本中都是默認安裝的。GCC編譯器主要以Linux命令的形式在shell終端中使用,所以需要大家掌握關于GCC編譯器的相關參數。


C語言程序編譯過程:源程序 ---- 預處理 — 編譯 — 匯編 — 鏈接 — 可執行文件
預處理:
對源碼進行簡單的加工,GCC編譯器會調用預處理器cpp對程序進行預處理,其實就是解釋源程序中所有的預處理指令,如#include(文件包含)、#define(宏定義)、#if(條件編譯)等以#號開頭的預處理語句。
這些預處理指令將會在預處理階段被解釋掉,如會把被包含的文件拷貝進來,覆蓋掉原來的#include語句,把所有的宏定義展開,所有的條件編譯語句被執行,GCC還會把所有的注釋刪掉,添加必要的調試信息。
預處理指令: gcc -E xxx.c -o xxx.i 會生成預處理文件 xxx.i
編譯:
就是對經過預處理之后的.i文件進行進一步翻譯,也就是對語法、詞法的分析,最終生成對應硬件平臺的匯編文件,具體生成什么平臺的匯編文件取決于編譯器,比如X86平臺使用gcc編譯器,而ARM平臺使用交叉編譯工具arm-linux-gcc。
編譯指令:gcc -S xxx.i -o xxx.s 會生成對應匯編文件 xxx.s
匯編:
GCC編譯器會調用匯編器as將匯編文件翻譯成可重定位文件,其實就是把.s文件的匯編代碼翻譯為相應的指令。
編譯指令:gcc -c xxx.s -o xxx.o 會生成匯編后的文件 xxx.o
鏈接:
經過匯編步驟后生成的.o文件其實是ELF格式的可重定位文件,雖然已經生成了指令流,但是需要重定位函數地址等,所以需要鏈接系統提供的標準C庫和其他的gcc基本庫文件等,并且還要把其他的.o文件一起進行鏈接。-lc -lgcc 是默認的,可以省略
編譯指令:gcc hello.o -o hello -lc -lgcc 會得到可執行文件 xxx // l是lib的縮寫
? 程序的格式
一般對源文件進行編譯和匯編之后,就會得到對應的目標文件xxx.o,目標文件也被稱為可重定位文件,就是指還未完成鏈接的中間文件,用戶可以把這些目標文件制作成在Linux系統下使用的靜態庫libxxx.a或者動態庫libxxx.so。
其實目標文件和可執行文件的內容和結構非常相似,所以Linux系統下把目標文件xxx.o和可執行文件都稱為ELF文件,ELF指的是Executable Linkable Format的縮寫,中文翻譯為可執行可鏈接格式。
注意:可以在linux系統中利用查看文件格式的指令: file 查閱目標文件和可執行文件的區別:
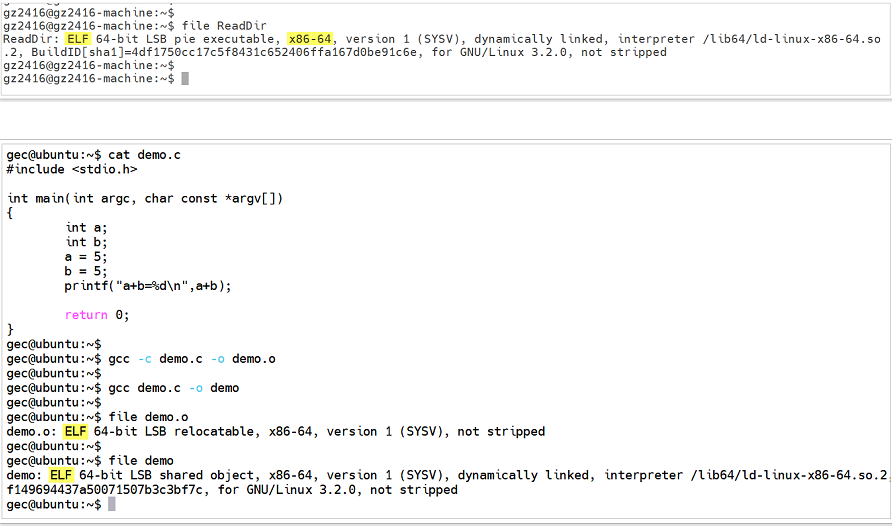
思考:還未完成鏈接的目標文件中存儲了哪些內容,以及如何查看目標文件中的內容信息???
回答:目標文件中的內容至少有編譯后的機器指令代碼、數據。除了這些內容以外,目標文件中還包括了鏈接時所需要的一些信息,比如符號表、調試信息、字符串等。一般目標文件將這些信息按不同的屬性,以“節”(Section)的形式存儲,有時候也叫“段”(Segment),一般情況下,它們都表示一個一定長度的區域,基本上不加以區別。
程序源代碼編譯后的機器指令經常被放在代碼段(Code Section)里,代碼段常見的名字有“.code”或“.text”。全局變量和局部靜態變量數據經常放在數據段(Data Section),數據段一般名字都叫“.data”。
注意:linux系統的GCC編譯套件有一款工具叫做objdump,可以查看目標文件內部的數據!
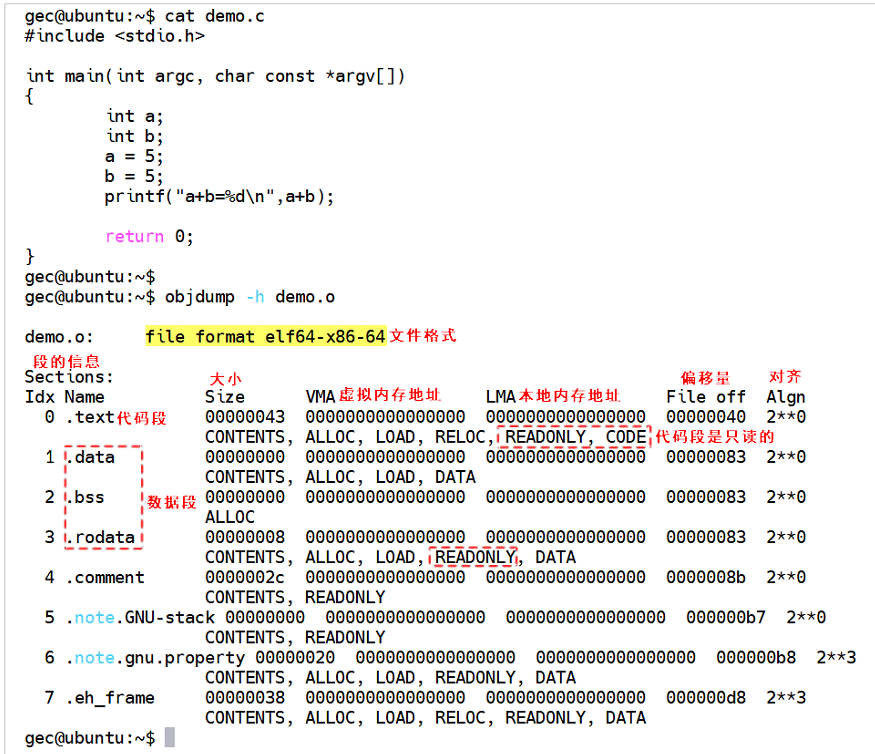
數據段中有一個叫做.bss段, bss以前其實是匯編偽指令,作用是為某些數據預留一塊空間,bss其實是Block Started by Symbol,也就是用于存儲未被初始化的全局變量和靜態局部變量,但是在程序編譯階段是沒有分配空間的,在程序運行時會得到空間。
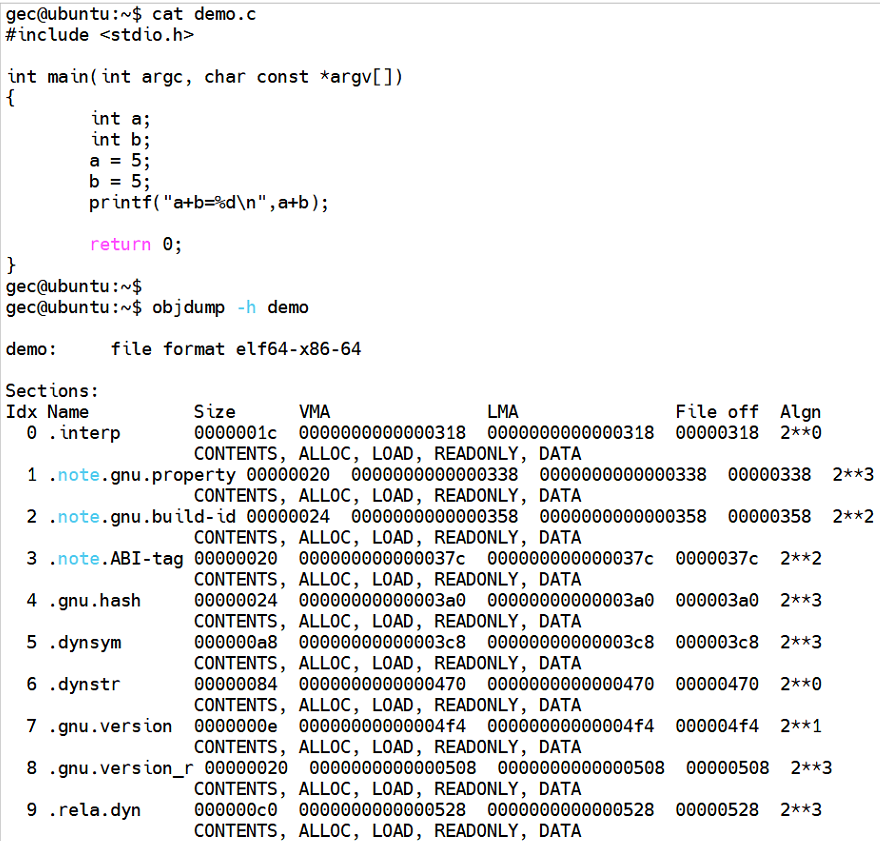
另外,objdump工具也可以實現把可執行文件進行反匯編,可以把得到的反匯編代碼重定向到某個文本中進行查看 “objdump -D demo > > xxx.txt”
? 進程的概念
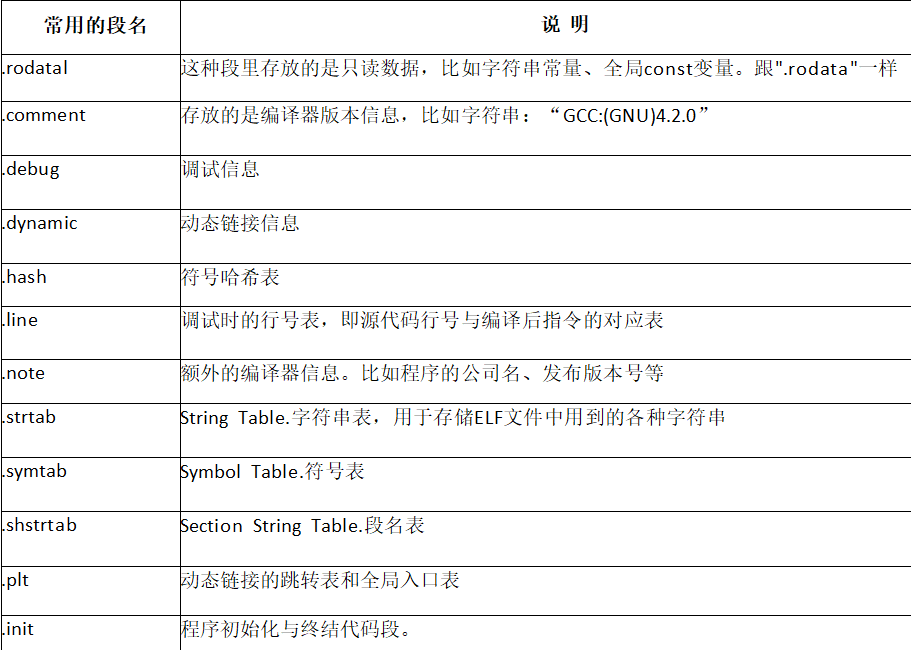
當源文件編譯通過并且完成鏈接動作之后,則得到一個可以執行的ELF文件,ELF文件中包含了程序的指令和數據以及相關函數接口的跳轉地址等信息,當用戶運行程序時,操作系統就會把程序相關的指令和數據載入內存,并為程序分配對應的內存空間,然后通知CPU完成程序的相關動作。
用戶編寫的源文件是存儲在外存(磁盤)中的,而使用編譯器生成的ELF可執行文件也是存儲在外存中的,這兩者都是靜態的,操作系統也并沒有為兩者分配系統資源。
當可執行文件得到運行,操作系統才會把可執行文件中的指令和數據從外存中讀取出來并寫入內存,并且會為程序分配系統資源(內存空間、CPU使用權等),所以程序從靜態變為動態,這種正在進行中的程序,操作系統就把其稱之為進程(process)。也可以理解為進程是程序在處理器上的一次執行過程。
進程定義:進程是一個具有一定獨立功能的程序在一個數據集合上依次動態執行的過程。進程是一個正在執行程序的實例。
注意:進程是操作系統分配資源的基本單位!操作系統是以進程為單位來分配系統資源的,比如內存空間、CPU使用權等。 線程是操作系統調度資源的最小單位! 進程包含線程!
? 進程的特征
進程具有四個基本特征,分別是動態性、并發性、獨立性、異步性,具體的區別如下所示:
(1) 動態性:進程是程序在處理器上的一次執行過程,因而是動態的。比如進程會在程序運行時被創建出來,當無法獲取足夠的系統資源時進程會暫停,當得到資源后會繼續執行。
(2) 并發性:多個進程同時存在于內存中,目的是與其他程序并發執行,提高資源的利用率。
(3) 獨立性:進程是一個能獨立運行的基本單位,也是系統進行資源分配和調度的獨立單位。
(4) 異步性:指的是進程以各自獨立的、不可預知的速度向前推進。一個進程的執行過程可能是無法被預測的,因為會受到各方面因素的影響,比如當系統資源不夠時或者出現其他進程搶占資源時,都會影響進程的執行進度。
? 進程的組成
思考:操作系統中可能會有n個進程同時執行,請問操作系統如何掌握這些進程的執行情況?
回答:一般進程在創建之后,操作系統都會為進程分配一塊內存來記錄進程的各項參數信息,所以這塊內存被稱為進程控制塊(Processing Control Block,縮寫為PCB)。每個進程都有PCB,用于標識進程的存在以及記錄進程的信息。
在Linux系統中進程控制塊PCB是以一個名稱叫做struct task_struct的結構體作為載體來存儲信息的,該結構體被定義在一個名稱叫做sched.h的頭文件中。
進程一般由三個部分組成,分別是進程控制塊、代碼段、數據段。代碼段指的是進程中能被調度程序調度到CPU上執行的程序代碼段,數據段指的是進程對應的程序原始數據或者程序執行過程中產生的中間數據等。
不同操作系統對于一個進程的信息記錄是不同的,也就是PCB中的內容會有一些區別,但是大同小異,基本都會包含以下內容:
- 進程標識符
每個進程都有一個有系統分配的唯一的PID進程標識符(process identifier),用于區分系統中的其他進程,這個PID也是Linux內核提供給用戶訪問進程的一個接口,用戶可以通過PID控制進程。
比如Windows系統可以通過任務管理器了解系統中正在執行的進程的數量以及進程的狀態:
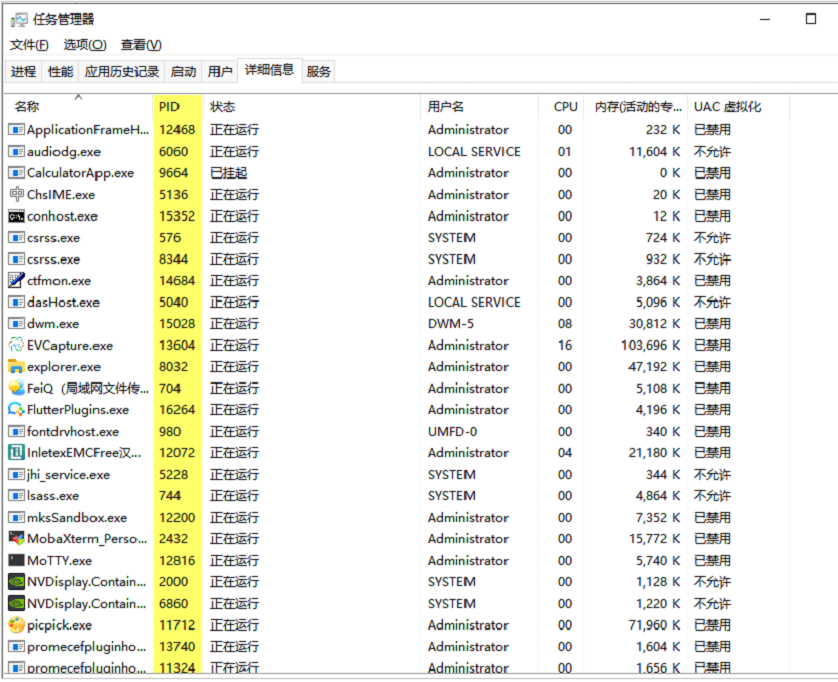
思考:windows系統下可以通過任務管理器查看進程的PID,那Linux系統如何查看進程PID?
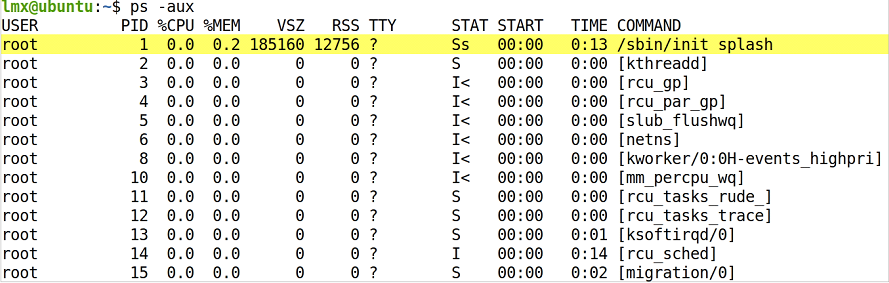
回答:Linux系統中提供了關于獲取進程狀態的shell命令:ps ,該命令的使用方法詳見man手冊,一般使用 ps -ef 或者 ps -aux來查看Linux系統中所有用戶相關的進程的所有信息。
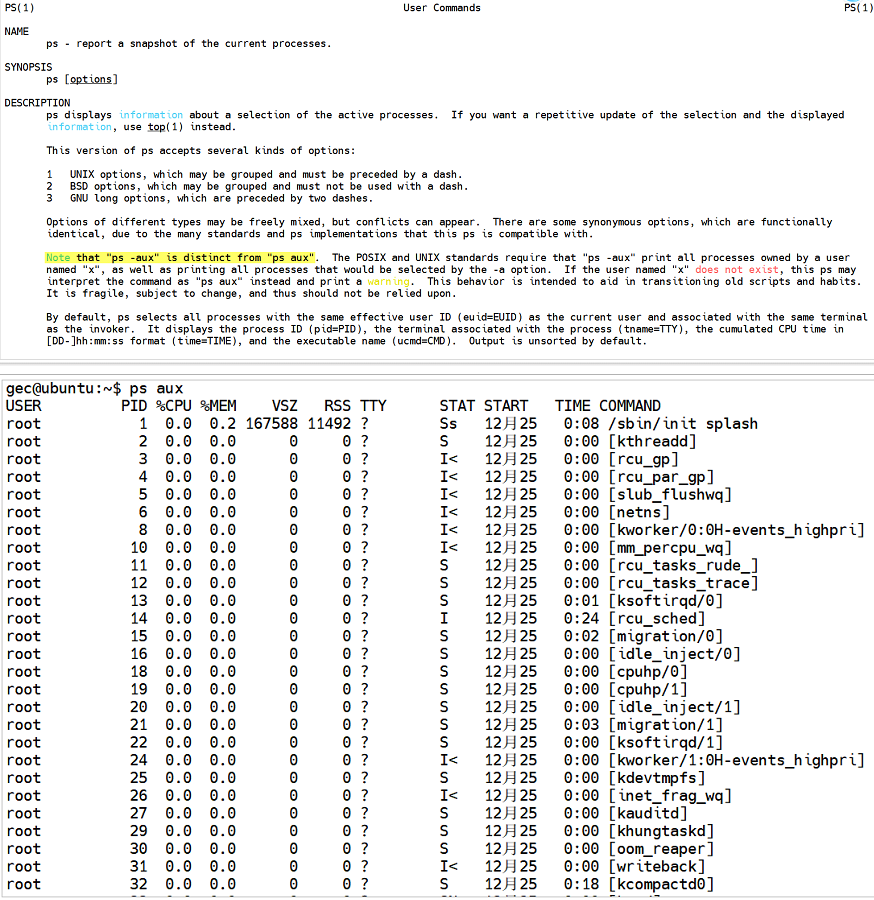
2) 進程當前狀態
在進程的運行過程中由于系統中多個進程的并發運行和相互制約的結果,所以使進程的狀態不斷發生變化。操作系統以進程的狀態來作為調度程序分配處理器的依據。
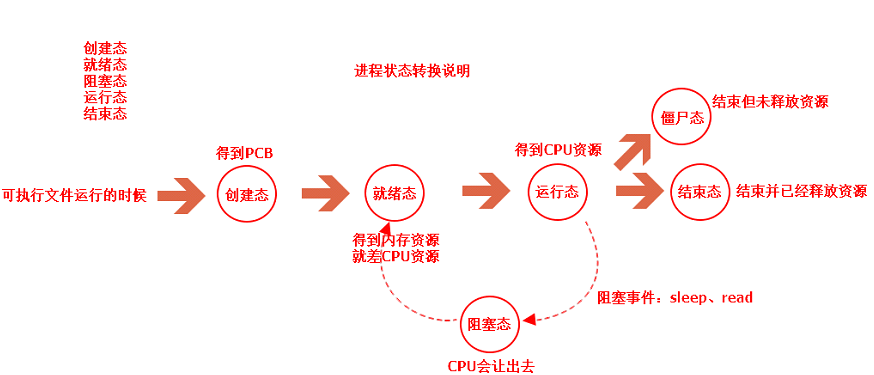
通常一個運行中的進程至少可劃分為5種基本狀態:就緒態、運行態、阻塞態、創建態、結束態。當然進程狀態的叫法是比較靈活的,大家不用死記硬背,重在理解相關概念。
A. 創建態
指的是進程正在被創建,但是還沒有準備好,也就是還沒有達到就緒狀態,此時系統申請進程PCB需要的內存空間,并向PCB中填寫關于進程的管理信息,然后系統分配進程運行需要的資源,最后把進程轉換為就緒狀態。
B. 就緒態
指的是進程已經獲得了除了處理器之外的其他資源,相當于“萬事俱備,只欠東風”,只要進程獲得處理器資源,就可以立即執行。
C.執行態
執行態也被稱為運行態,指的是進程已經獲得了其他資源和處理器資源,并正在被CPU執行的狀態。
D.阻塞態
阻塞態也被稱為暫停態,指的是進程在執行過程中由于某個事件導致無法繼續執行下去,此時進程處于暫時停止的狀態。
E. 結束態
指的是進程正在從系統中消失,原因可能是進程正常退出或者由于其他問題中斷退出運行。有一種情況比較特殊,就是如果該進程退出之后資源還沒有釋放,但是此時進程已經無法被調度和運行,進程就會進入僵尸態,此時用戶需要對這類進程進行處理,避免占用過多資源。
思考:Linux系統下運行了n個進程,每個進程的狀態都不同,請問如何區分進程的狀態???
回答:在Linux系統的終端中輸入shell指令: ps -aux,就可以看到當前系統中運行的進程狀態。
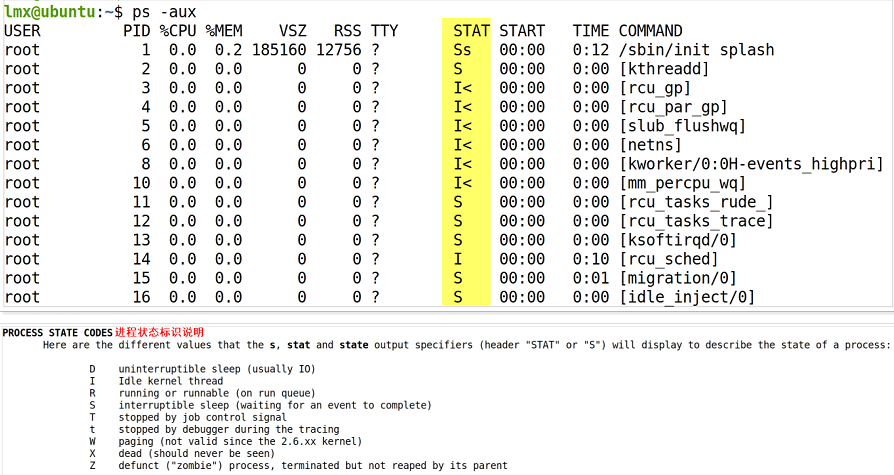
注意:進程不是一直處于某一個狀態,進程的狀態會受到外界因素和執行進度的影響而發生改變,當然,進程的狀態在某一個時刻是唯一的,也就是在某一時刻進程必須且只能處于一種狀態。
? 進程的控制
進程控制指的是對系統中的所有進程實施有效的管理,其功能一般包括進程的創建、進程的撤銷、進程的阻塞與喚醒等。這些功能一般是由操作系統的內核來實現的。
- 進程的創建
Linux系統中的一個進程中可以創建若干個新進程,新創建的進程中又可以創建子進程,所以一般使用進程前趨圖來描述創建的進程之間的關系。進程前趨圖也被稱為進程樹,是為了描述進程家族關系的樹。
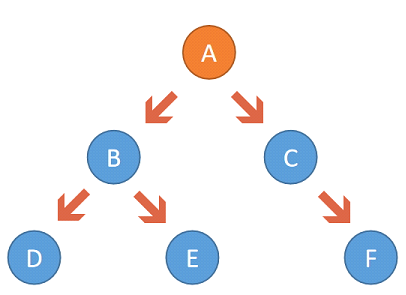
比如在進程A中創建了一個新進程B,則進程B就是進程A的子進程,進程A就是進程B的父進程。
如果在進程A中創建了2個子進程B和C,進程B中創建了2個子進程D和E,進程C中創建了1個子進程F,則進程A就是該進程家族的祖先。
在Linux系統中運行的所有進程也可以構成一個進程樹,并且該進程樹也有一個祖先,用戶可以通過Linux系統提供的shell命令:pstree 來打印進程關系。

可以發現,Linux系統中的所有進程都和一個進程有關系,那就是systemd進程,該進程是Linux系統運行的第一個進程,英文全稱是system daemon,中文翻譯為系統守護進程,系統中其他進程都是該進程的子進程。
守護進程也被翻譯為精靈進程或者后臺進程,是一種旨在運行于相對干凈環境、不受終端影響的、常駐內存的進程,就像神話中的精靈擁有不死的特性,長期穩定提供某種功能或服務。
systemd其實是一個 Linux 系統基礎組件的集合,它提供了一個系統和服務管理器,然后運行為 PID 1的進程,負責在系統啟動或運行時激活系統資源,并且管理服務器進程和其它進程。
注意:Linux系統中只有進程才可以在系統運行,所以一個程序想要運行,就必須為該程序創建進程。linux內核提供了一個名字叫做fork()的系統調用接口,該接口可以在進程中創建一個子進程。
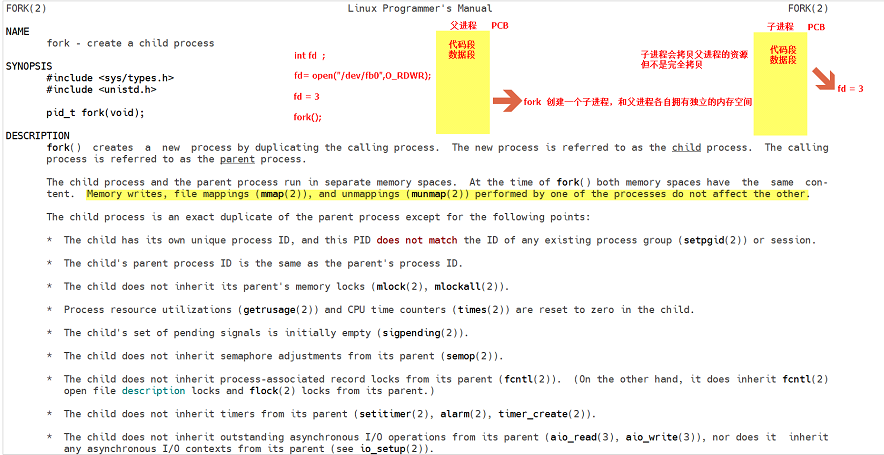

可以看到fork函數的返回值對于父進程和子進程而言是不同的,fork函數在父進程中返回的是創建成功的子進程的PID,fork函數在子進程中的返回值是0,當然,如果子進程失敗則返回-1。
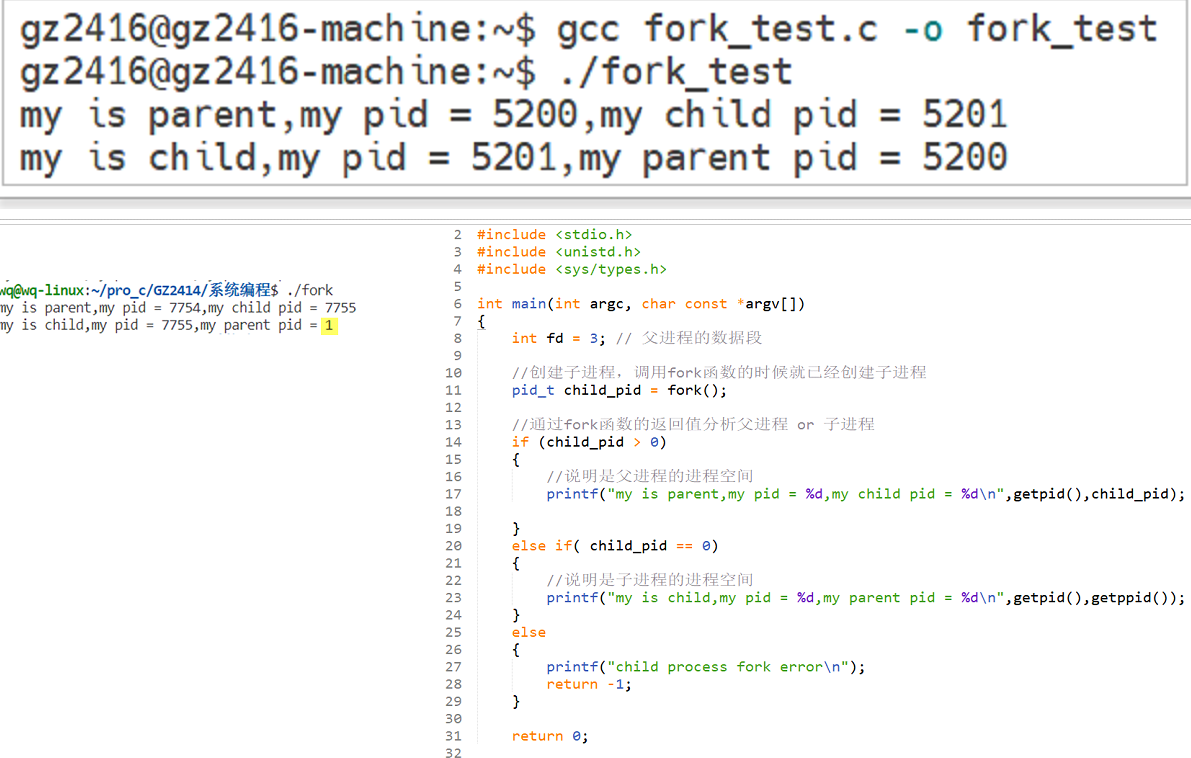
思考:由于子進程會拷貝父進程的代碼段和數據段,所以父進程剩余的程序會執行兩遍,請問如何區分到底是哪個進程在執行程序?是否父進程的程序會優先于子進程執行?
回答:通過fork函數的返回值來區分父進程和子進程,父進程和子進程的執行順序是由操作系統的調度器決定的。也可以選擇利用某些機制來調整執行順序。
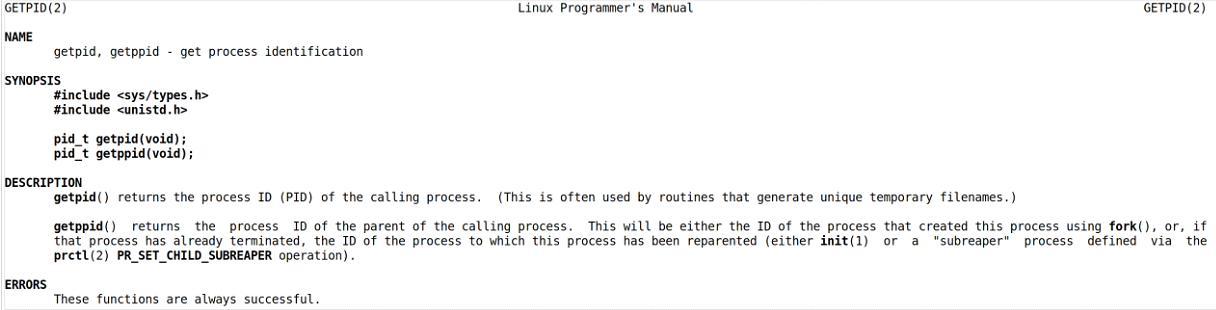
獲取當前進程PID的函數接口getpid(),獲取當前進程的父進程PID的函數接口是getppid()
思考:調用fork函數之后可以創建一個子進程,但是調用了一次fork函數為什么會有兩個不同的返回值?
回答:就是調用fork的時候子進程已經拷貝了父進程的代碼段、數據段、堆棧段,所以fork函數還沒有執行完成,就會在兩個進程空間繼續執行,就會得到兩個不同的返回值。
- 進程的撤銷
一個進程在完成自身任務之后應該及時撤銷,這樣就可以及時的釋放進程的資源,此時可以分為兩種情況:一種是撤銷指定進程,另一種是撤銷指定進程以及該進程的所有子孫進程。不管是哪種情況,都應該及時回收進程占用的資源。
Linux系統中提供了一個名稱叫做wait()的系統調用接口,該接口用于讓父進程等待子進程的狀態改變并獲取已經改變狀態的子進程的信息。
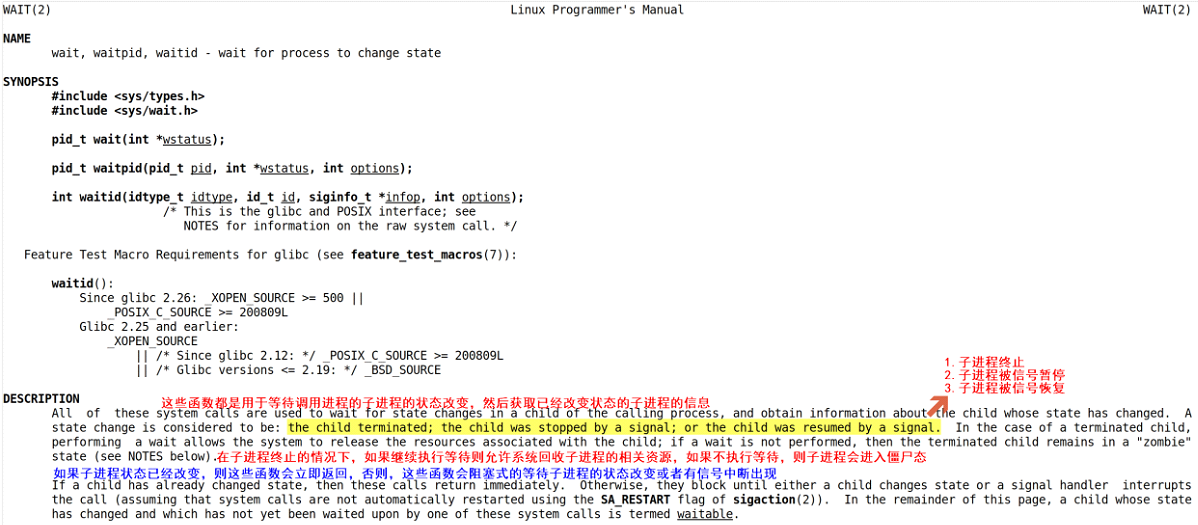
僵尸態指的是進程終止但是并未釋放相關資源的一種狀態,此時由系統內核對處于僵尸態的進程進行維護,處于僵尸態的進程會占用創建進程的資源和數量,如果僵尸態進程數量太多,則會導致系統無法創建新進程。
所以父進程應該及時的對終止的子進程進行等待,這樣就可以回收子進程占用的資源,當然,如果父進程終止,則處于僵尸態的子進程會由系統內核完成資源的回收。
注意:如果當前進程沒有子進程,則wait函數立即返回,如果當前進程有很多個子進程則wait函數會回收第一個變為僵尸態的子進程資源。
wait函數的參數是一個指針,用于記錄子進程的退出狀態,如果該參數為NULL,則表示當前進程放棄子進程的退出狀態。對于該指針中記錄的值,用戶可以通過系統提供的宏定義來分析子進程的退出狀態。

通過man手冊可以發現Linux內核還提供了另一個叫做waitpid()的系統調用函數,該函數也可以等待子進程狀態改變并回收子進程的系統資源,只不過該函數的針對性更強,可以指定回收某個子進程的系統資源。


3) 進程的執行
思考:既然在一個進程中可以創建多個子進程,并且子進程和父進程的數據段和代碼段是相同的,也就是一份程序會執行兩次,一般情況下是沒有意義和必要的,請問能否讓子進程單獨的加載新的程序的代碼段和數據段,如果可以,應該如何實現?
回答:當然是可以的,Linux系統標準庫中提供了一組函數接口來實現在進程中加載和執行指定的程序。
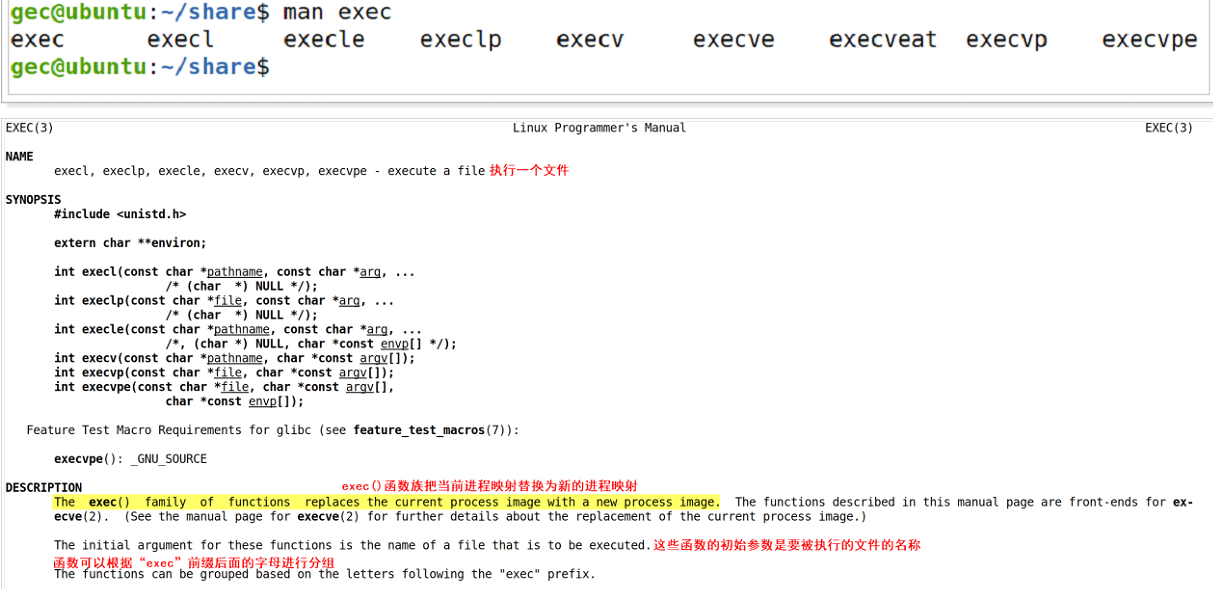
這組接口可以把exec作為前綴,然后以exec后面的字符進行分類,比如l指的是list的縮寫,p指的是path的縮寫,e指的是environment的縮寫,v指的是vector的縮寫。
(1) l : 以列表的方式來組織指定程序的參數
(2) v: 以數組的方式來組織指定程序的參數
(3) e: 執行指定程序前順便設置環境變量
(4) p: 執行程序時可自動搜索環境變量PATH的路徑

以 execl(const char *pathname, const char *arg, …) 為例,參數pathname是需要加載的指定程序,而arg則是該程序運行時的命令行參數,命令行參數包括程序名本身,并且全部是字符串,其實和帶參數的main函數通過命令行傳參的流程類似,但是函數的參數列表必須以NULL結束,也就是函數的最后一個參數填NULL即可。
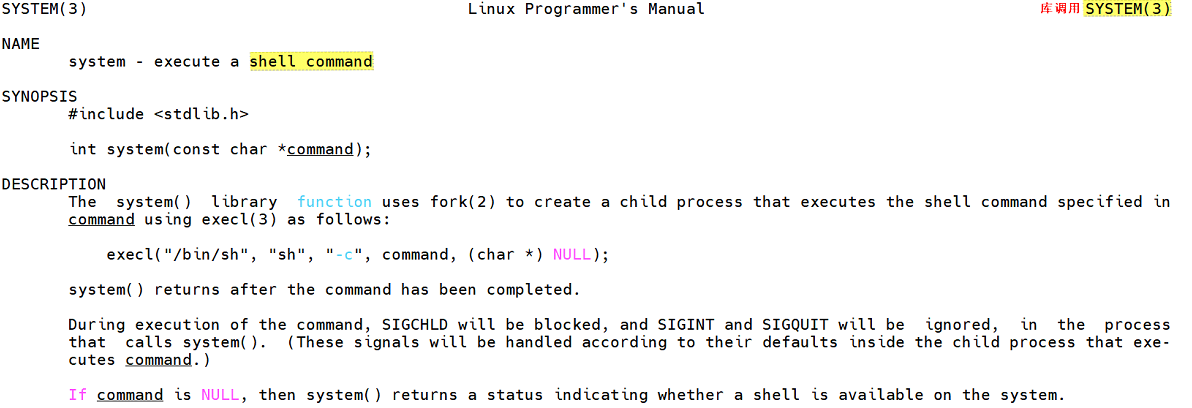
其實,linux系統還提供一個函數,名稱叫做system(),這個函數也可以讓新進程執行shell命令。


零基礎入門系列第十二篇(完結篇):數據統計功能實現)










 介紹與使用示例)
操作圖像像素)



