Training Large Networks in Parallel
計算機集群上高效訓練大型深度神經網絡(DNN)的方法和技術。從神經網絡的基本概念出發,逐步深入到并行訓練的具體實現策略,包括數據并行、模型并行以及參數服務器的設計等。
研究背景與動機
- 大型神經網絡的挑戰:現代深度神經網絡(DNN)包含數百萬甚至數十億的參數,訓練這些網絡需要大量的計算資源和時間。例如,VGG-16網絡的參數需要約500MB的內存,而訓練過程可能需要數天時間。
- 并行訓練的需求:為了加速訓練過程,研究人員探索了在多個計算節點上并行訓練DNN的方法。這不僅可以減少訓練時間,還可以擴展到更大的數據集和更復雜的模型。
神經網絡基礎
- 教授分類任務:文章通過一個簡單的例子引入了神經網絡的基本概念,即根據教授的外貌特征將其分類為“容易”、“刻薄”、“無聊”或“書呆子”。
- 網絡結構:介紹了神經網絡的基本結構,包括卷積層、最大池化層和全連接層。文章中提到的模型包含多個卷積層和全連接層,每層的神經元數量分別為253440、186624、64896、64896、43264、4096、4096和1000。
- 訓練目標:訓練的目標是最小化網絡輸出與真實標簽之間的損失函數。文章中使用了softmax損失函數作為示例。
梯度下降與反向傳播
- 梯度下降:介紹了梯度下降的基本思想,即通過調整網絡參數以減少損失函數的值。文章通過一個簡單的函數示例解釋了如何使用梯度下降來優化參數。
- 反向傳播:詳細描述了反向傳播算法,這是計算神經網絡中每個參數梯度的關鍵步驟。文章通過圖示和公式解釋了如何通過鏈式法則計算梯度,并通過矩陣形式展示了反向傳播的計算過程。
并行訓練策略
- 數據并行:將訓練數據分割成多個小批次(mini-batch),并將這些小批次分配給不同的計算節點。每個節點獨立計算其分配數據的梯度,然后通過全局同步點(如參數服務器)匯總梯度并更新參數。
- 模型并行:當模型參數過多,無法在單個節點上存儲時,可以將模型分割成多個部分,分別存儲在不同的節點上。文章提到,通過使用小尺寸卷積(如1x1卷積)和減少全連接層的大小,可以減少節點間的通信量。
- 參數服務器:介紹了參數服務器的設計,它負責存儲全局參數,并接收來自各個工作節點的梯度更新。參數服務器可以被切分成多個部分,以減少單個服務器的負載。
異步執行與優化
- 異步更新:為了避免全局同步帶來的延遲,文章提出了異步更新策略。在這種策略下,工作節點在計算梯度后立即將其發送給參數服務器,而無需等待其他節點完成計算。這種策略可以提高系統的吞吐量,但可能會對訓練的收斂性產生影響。
- 分片參數服務器:為了進一步優化參數服務器的性能,文章提出了將參數服務器分片的策略。每個分片負責存儲和更新一部分參數,從而減少了單個服務器的負載。
實驗與結果
- FireCaffe實驗:文章通過在Titan超級計算機上使用FireCaffe框架進行實驗,展示了并行訓練的加速效果。實驗結果表明,在128個GPU上訓練GoogLeNet時,與單GPU訓練相比,可以實現47倍的加速,同時保持相同的準確率。
- 通信開銷比較:文章還比較了使用參數服務器和使用減少樹(reduction tree)進行梯度匯總的通信開銷。結果顯示,減少樹在通信效率上具有優勢。
DNN Accelerator Architectures 1
1. DNN加速器的核心問題
深度神經網絡(DNN)的計算效率主要受限于內存訪問瓶頸。由于DNN計算需要頻繁讀寫數據(如權重、激活值和中間結果),內存訪問(尤其是DRAM訪問)成為主要的性能瓶頸。例如,AlexNet需要724M次MAC操作,但需要2896M次DRAM訪問。
2. 內存訪問瓶頸的解決方案
為了減少內存訪問,DNN加速器通常采用以下策略:
- 本地內存層次結構:通過引入多級本地內存(如寄存器文件、全局緩沖區)來重用數據,減少對DRAM的訪問。
- 數據重用:最大化數據的重用,例如:
- 卷積重用:在卷積層中利用滑動窗口技術。
- Fmap重用:在卷積層和全連接層中重用激活值。
- 濾波器重用:在批量處理中重用濾波器權重。
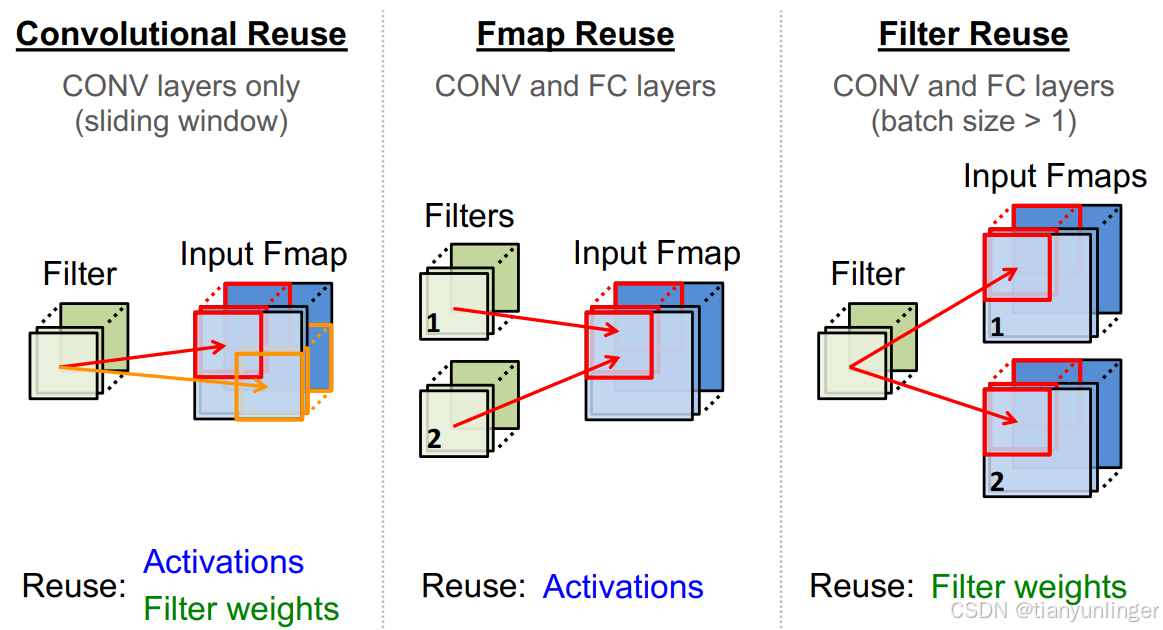
3. DNN加速器的架構設計
- 空間架構:通過并行計算單元(PE)和片上網絡(NoC)實現高效的數據流動。 PE單元負責執行基本的算術運算,而NoC負責PE單元之間的高效通信,兩者協同工作以實現DNN加速器的整體性能提升。
- 多級內存訪問:從DRAM到全局緩沖區,再到PE內的寄存器文件,每層訪問成本差異顯著。
4. 數據流分類
數據流的設計是DNN加速器的關鍵,主要分為以下三類:
- 輸出 stationary(OS):最小化部分和的讀寫能耗,適合最大化本地累積。例如,ShiDianNao和ENVISION。
- 權重 stationary(WS):最小化權重讀取能耗,適合最大化權重重用。例如,NeuFlow和NVDLA。
- 輸入 stationary(IS):最小化激活讀取能耗,適合最大化輸入激活的重用。例如,SCNN。
5. 數據流的應用示例
- OS數據流:ShiDianNao通過保持輸出特征圖的部分和,減少對DRAM的訪問。
- WS數據流:NVDLA通過保持權重,循環輸入和輸出特征圖,減少權重的重復讀取。
- IS數據流:SCNN利用稀疏CNN的特性,減少激活值的讀取。
6. 并行計算的應用
并行計算在DNN加速器中通過以下方式實現:
- 任務并行:將計算任務分配到多個PE中并行執行。
- 數據并行:將數據分割成多個部分,分別在不同PE上處理。
7. 優化策略
- 內存優化:通過分層內存結構和數據重用,減少內存訪問。
- 算法優化:選擇適合硬件架構的算法,例如稀疏CNN。
- 硬件優化:利用高性能處理器和高速存儲設備提升性能。
補充圖表
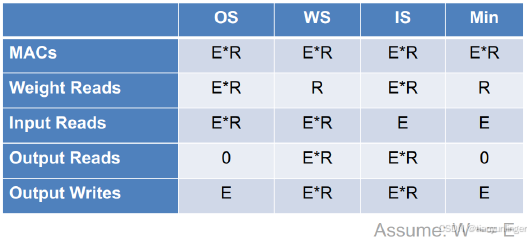
這個表格展示了不同數據流(Output Stationary (OS)、Weight Stationary (WS)、Input Stationary (IS))在執行1-D卷積操作時的性能指標對比。表格中的變量E和R分別代表輸出長度和濾波器長度。以下是逐行解釋:
-
MAC操作數:
- 所有數據流類型(OS、WS、IS)的MAC操作數都是E*R(E 和 R 是與1-D卷積操作相關的兩個關鍵參數,分別表示:E (Output Length):輸出特征圖(output feature map)的長度。R (Filter Length):濾波器(filter)的長度。),這是固定的計算量,與數據流類型無關。
-
權重讀取次數:
- OS:需要讀取E*R次權重,因為每個權重在每個輸出位置都需要讀取一次。
- WS:只需要讀取R次權重,因為權重在PE陣列中被廣播并重用。
- IS:需要讀取E*R次權重,因為權重在每個輸入位置都需要讀取一次。
-
輸入讀取次數:
- OS:需要讀取E*R次輸入,因為輸入在每個輸出位置都需要讀取一次。
- WS:需要讀取E*R次輸入,因為輸入在每個輸出位置都需要讀取一次。
- IS:只需要讀取E次輸入,因為輸入在PE陣列中被廣播并重用。
-
輸出讀取次數:
- OS:不需要讀取輸出(0次),因為輸出在本地累積。
- WS:需要讀取E*R次輸出,因為輸出在PE陣列中需要多次讀取。
- IS:需要讀取E*R次輸出,因為輸出在PE陣列中需要多次讀取。
-
輸出寫入次數:
- OS:需要寫入E次輸出,因為每個輸出只寫入一次。
- WS:需要寫入E*R次輸出,因為輸出在PE陣列中需要多次寫入。
- IS:需要寫入E*R次輸出,因為輸出在PE陣列中需要多次寫入。
總結:
- OS在權重讀取和輸出讀取方面表現最佳,因為它最小化了部分和的讀寫。
- WS在權重讀取方面表現最佳,因為它最小化了權重的讀取。
- IS在輸入讀取方面表現最佳,因為它最小化了輸入的讀取。
- Min列顯示了每個指標的最小值,表明哪種數據流類型在特定指標上表現最好。
補充偽代碼
- Output Stationary (OS) 代碼
for (e = 0; e < E; e++)for (r = 0; r < R; r++)O[e] += I[e+r] * W[r];
- 外層循環:遍歷輸出索引
e,從0到E-1。 - 內層循環:遍歷濾波器索引
r,從0到R-1。 - 操作:對于每個輸出索引
e和濾波器索引r,將輸入I[e+r]和權重W[r]的乘積累加到輸出O[e]中。 - 特點:輸出
O[e]在每個周期中被多次更新,權重和輸入被讀取。
- Weight Stationary (WS) 代碼
for (r = 0; r < R; r++)for (e = 0; e < E; e++)O[e] += I[e+r] * W[r];
- 外層循環:遍歷濾波器索引
r,從0到R-1。 - 內層循環:遍歷輸出索引
e,從0到E-1。 - 操作:對于每個濾波器索引
r和輸出索引e,將輸入I[e+r]和權重W[r]的乘積累加到輸出O[e]中。 - 特點:權重
W[r]在每個周期中被多次重用,減少了權重的讀取次數。
- Input Stationary (IS) 代碼
for (h = 0; h < H; h++)for (r = 0; r < R; r++)O[h-r] += I[h] * W[r];
- 外層循環:遍歷輸入索引
h,從0到H-1。 - 內層循環:遍歷濾波器索引
r,從0到R-1。 - 操作:對于每個輸入索引
h和濾波器索引r,將輸入I[h]和權重W[r]的乘積累加到輸出O[h-r]中。 - 特點:輸入
I[h]在每個周期中被多次重用,減少了輸入的讀取次數。
總結
- Output Stationary (OS):輸出部分和在本地累積,減少對全局緩沖區的訪問。
- Weight Stationary (WS):權重被多次重用,減少權重的讀取次數。
- Input Stationary (IS):輸入激活被多次重用,減少輸入的讀取次數。
這些代碼展示了不同數據流(OS、WS、IS)在1-D卷積中的實現方式,通過改變循環的順序和數據的訪問模式來優化性能和能效。
DNN Accelerator Architectures 2
1. 數據流分類與優化
-
數據流分類:
- 數據流分為三種類型:激活數據(Activation)、權重數據(Weight)和部分和(Partial Sum, psum)。
- 根據數據復用的方式,數據流可以分為輸入駐留(Input Stationary)、權重駐留(Weight Stationary)和行駐留(Row Stationary)。
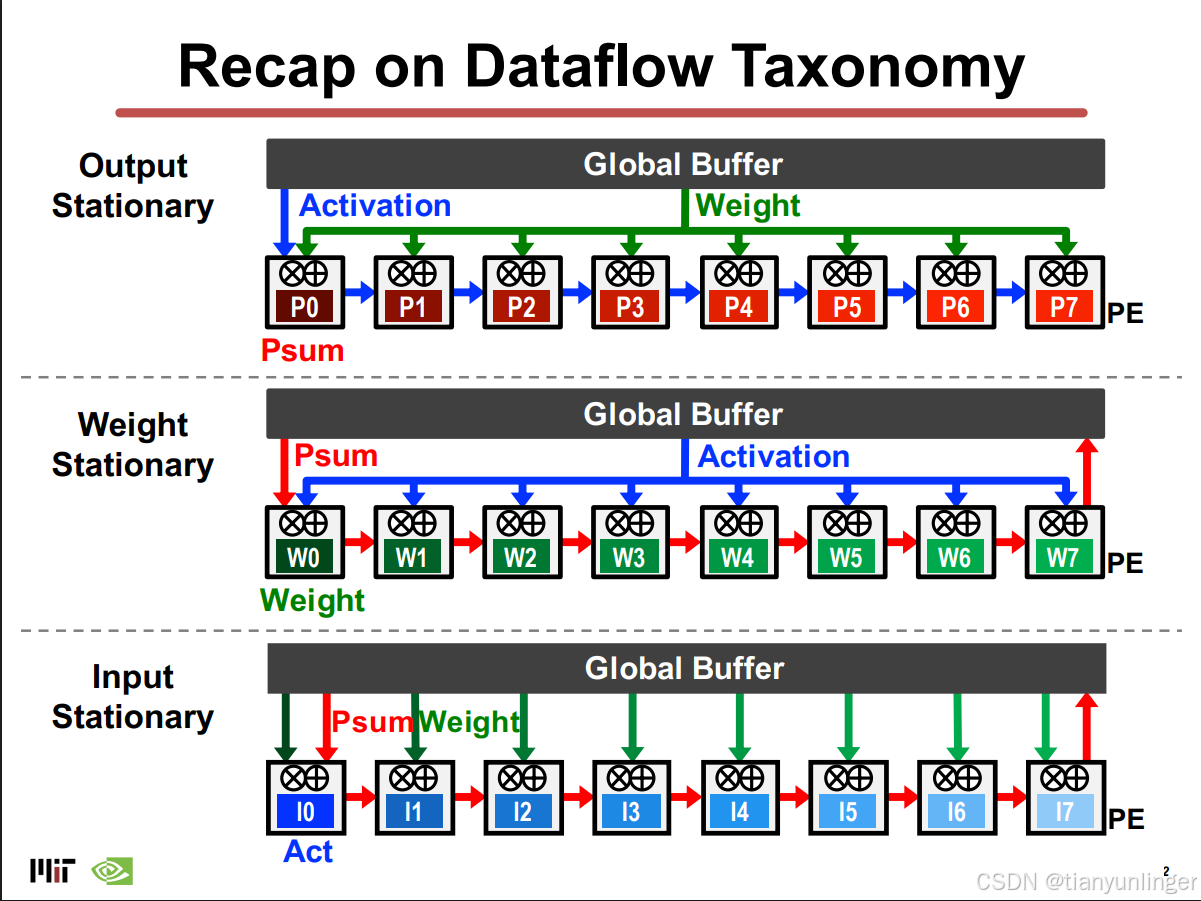
-
行駐留(Row Stationary, RS)數據流:
- 優化目標:最大化數據復用,優化整體能效,而非僅針對某一類型數據。
- 實現方式:
- 在寄存器文件(RF)中保留濾波器行和特征圖滑動窗口,減少數據頻繁讀取。
- 最大化行卷積復用和部分和積累。
2. PE陣列中的卷積計算
-
1D行卷積:
- 在PE(Processing Element)中,通過寄存器文件(Reg File)存儲濾波器行和特征圖滑動窗口,計算部分和。
- 示例:濾波器行為
a b c,特征圖行為a b c d e,通過滑動窗口計算部分和。
-
2D卷積:
- 在PE陣列中,通過多行濾波器和特征圖的組合,完成二維卷積計算。
- 示例:PE陣列中,每行PE處理不同的濾波器行和特征圖行,逐步積累部分和。
3. 多通道和多特征圖的處理
-
濾波器復用:
- 在PE中,濾波器行可以在多個特征圖中復用。
- 示例:濾波器行
Row 1可以在特征圖Fmap 1和Fmap 2中復用。
-
特征圖復用:
- 在PE中,特征圖行可以在多個濾波器中復用。
- 示例:特征圖行
Row 1可以在濾波器Filter 1和Filter 2中復用。
-
通道累積:
- 在PE中,不同通道的部分和可以通過交替通道的方式進行累積。
- 示例:通道1和通道2的部分和可以累積為最終結果。
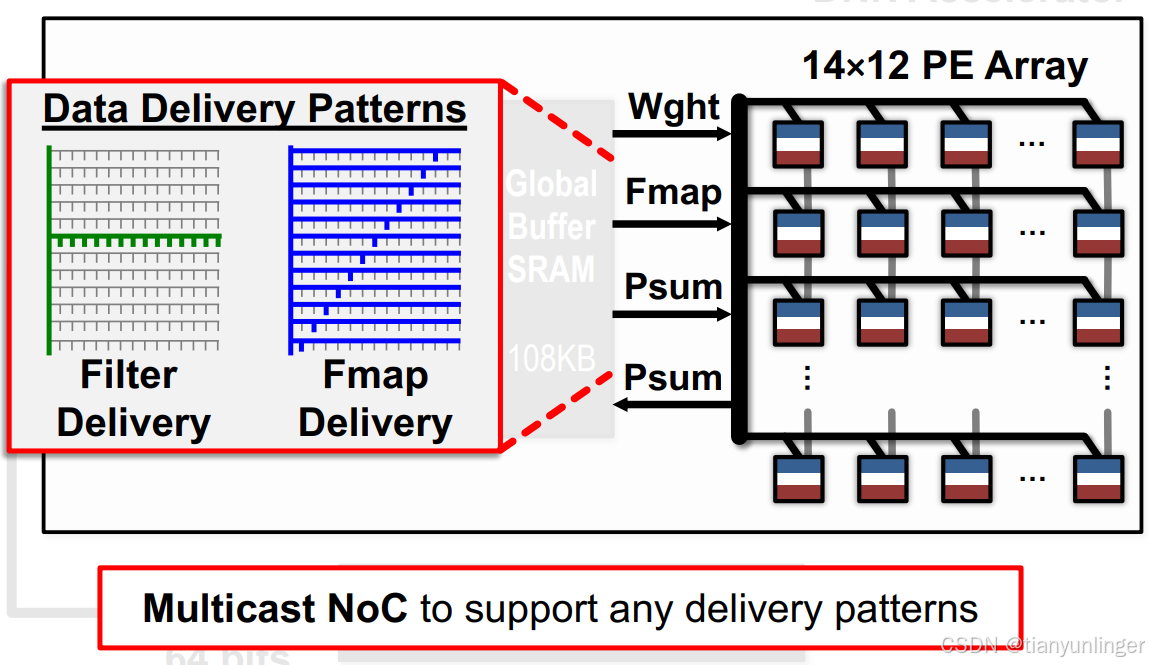
4. 編譯器與硬件協同設計
-
編譯器的作用:
- 根據DNN的形狀和大小,優化映射配置(Mapping Config),將計算任務分配到PE陣列中。
- 示例:將多個特征圖、濾波器和通道映射到同一個PE中,以利用不同的數據復用和局部累積。
-
硬件資源:
- 包括ALU(算術邏輯單元)、全局緩沖區(Global Buffer)等。
- 示例:通過全局緩沖區存儲輸入特征圖、輸出特征圖和權重數據。
5. 性能評估框架(Eyexam)
-
評估目標:
- 快速理解DNN加速器在不同工作負載下的性能限制。
- 示例:通過分析MAC(乘積累加操作)每周期的性能和數據每周期的性能,評估硬件的計算能力和帶寬限制。
-
評估步驟:
- 最大工作負載并行性。
- 最大數據流并行性。
- 在有限PE陣列尺寸下的激活PE數量。
- 在固定PE陣列尺寸下的激活PE數量。
- 在有限存儲容量下的激活PE數量。
- 由于平均帶寬不足導致的激活PE利用率降低。
- 由于瞬時帶寬不足導致的激活PE利用率降低。

6. 片上網絡(NoC)設計
-
傳統網絡的局限性:
- 單播(Unicast)和廣播(Broadcast)網絡難以同時滿足高復用和高帶寬的需求。
- 示例:廣播網絡適合高復用場景,但帶寬較低;全連接網絡適合高帶寬場景,但擴展性差。

-
提出的解決方案:
- 層次化網格網絡(Hierarchical Mesh Network):
- 支持從高復用到高帶寬的各種數據傳輸模式。
- 通過分層設計,降低復雜性并提高擴展性。
- 示例:
- 高帶寬模式:支持所有PE之間的全連接通信。
- 高復用模式:支持從單一源到多個目標的高效數據傳輸。
- 組播和交織多播模式:適應不同的數據復用和帶寬需求。
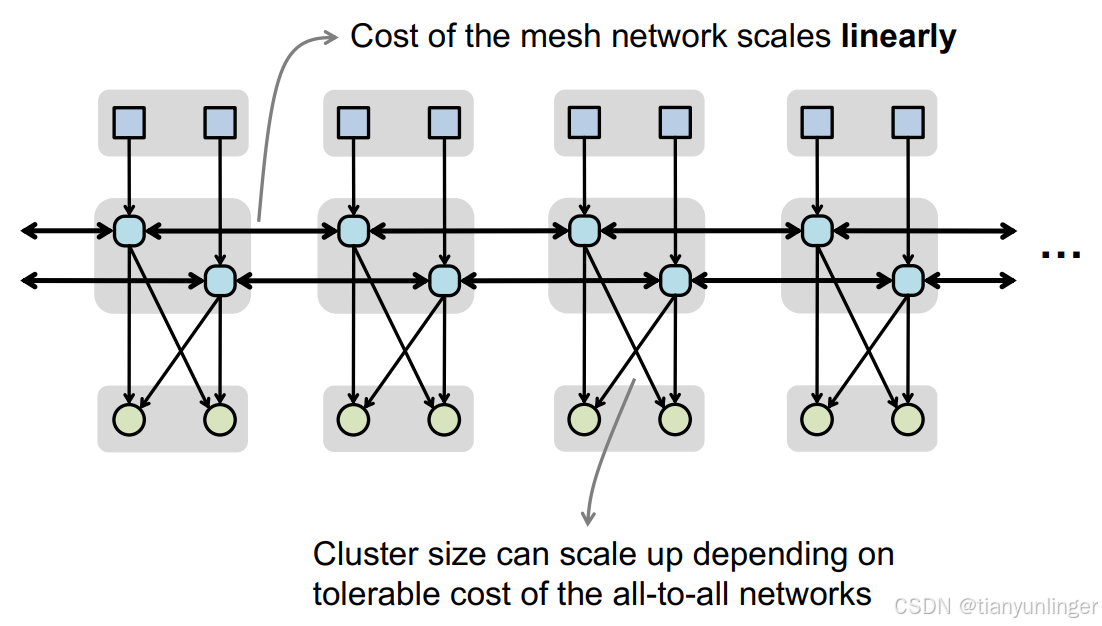
- 層次化網格網絡(Hierarchical Mesh Network):
-
Eyeriss加速器的改進:
- Eyeriss v2采用層次化網格網絡,相比v1在性能和能效方面有顯著提升。
- 示例:AlexNet的加速比為6.9倍,能效提升2.6倍;MobileNet的加速比為5.6倍,能效提升1.8倍。
7. 總結
- 關鍵點:
- 數據復用是實現高能效的關鍵。
- 通過靈活的片上網絡設計,可以提高PE利用率,從而實現高性能。
- 數據流與硬件的協同設計對于優化DNN加速器的性能、能效和靈活性至關重要。
)


)




 : Super Scientific Software Laboratory (SSSLab))



鏈式工作流構建——打造智能對話的強大引擎)
的chan-tylor,三維環境,附完整代碼)





