一、狀態的概念
Flink的狀態其實你就可以將其想象為中間結果就可以了。在Flink中,算子的任務可以分為無狀態和有狀態兩種情況。
無狀態算子任務在計算過程中是不依賴于其他數據的,只根據當前的輸入數據就可以得到結果輸出。比如之前講到的Map、FlatMap、Filter算子等。
有狀態算子任務,在計算的過程中需要依賴一些其他的數據,然后再結合當前的輸入數據得到最終的執行結果。比如聚合算子、窗口算子都是有狀態的算子。
有狀態算子的一般處理流程是:
? ? ? ? (1)、算子任務接收上游輸入的數據;
? ? ? ? (2)、獲取當前的狀態信息;
? ? ? ? (3)、根據業務邏輯進行處理并更新狀態信息;
二、狀態的分類
Flink總體來說有兩種分類狀態:托管狀態、原始狀態。
托管狀態就是由Flink來進行狀態的統一管理。狀態的存儲訪問、故障恢復和重組等一系列問題都由Flink來實現,開發者只用去調接口就可以了;原始狀態是自定義的,相當于就是自己開辟一塊內存,然后由開發者自己來管理狀態信息,自己實現狀態的序列化和故障恢復。
但是大部分情況下,我們都是使用的托管狀態,就是由Flink來管理狀態信息。
那在托管狀態下其實又把狀態分成了兩類,分別是算子狀態(Operator State)和按鍵分區狀態(Keyed State)。
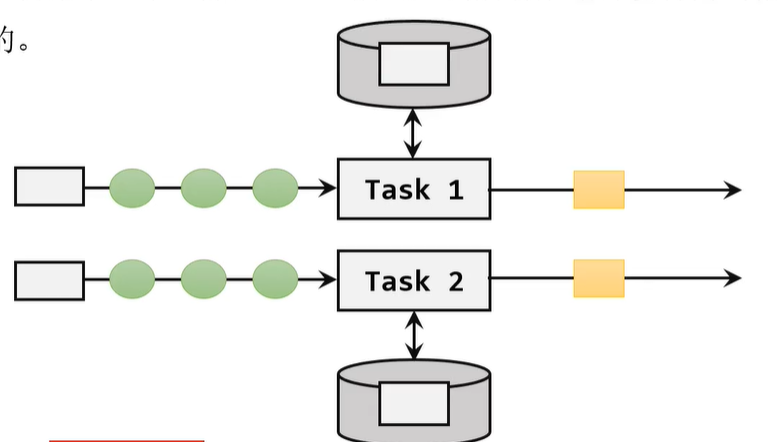
這兩種狀態的區別很簡單,就是看狀態的獲取是否要按照Key來獲取,不同的Key之間不能獲取到同一個狀態的。下面的這個就是算子狀態的示意圖。在這個圖中,流入同一個子任務的數據共享同一個狀態。
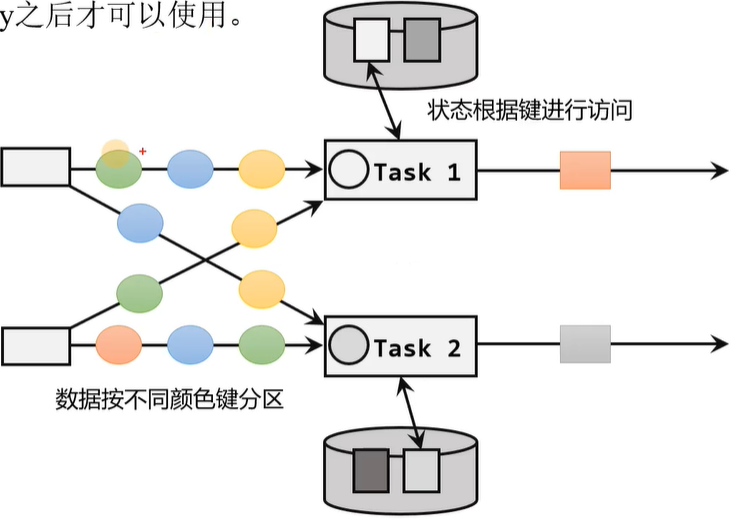
下面是按鍵分區狀態的示意圖,就能看到雖然數據會發往同一個子任務中,但是在這個子任務中依然會按照Key值來獲取不同的狀態信息。
三、狀態的生存時間
在實際的應用中,狀態會隨著時間的推移而漸漸增多,如果不對其加以限制,狀態就會把存儲空間耗盡。開始的優化思路是直接在代碼中調用.clear()方法去清除狀態,但是有的時候我們的邏輯不希望將狀態直接給清除掉,這時就需要配置一個狀態的“生存時間”(time-to-live,TTL)。也就是說,超出這一時間之后狀態才會被清除。那這里又出現了一個問題,就是我們需要怎么去監測這個狀態信息的生存時間到了呢?如果用一個進程不停地掃描所有的狀態看是否過期,這樣會消耗大量的資源在做這種無用功。所有我們給狀態加了一個屬性,也就是狀態的“失效時間”。狀態創建時,設置失效時間=當前時間+TTL;之后如果有對狀態的訪問和修改,我們再對失效時間進行更新;當需要拿數據進行操作的時候或者每隔一段時間掃描檢查狀態是否失效的操作要執行時,就可以判斷狀態是否失效,從而確定是否需要將狀態清除。









跳過登錄微軟賬戶,創建本地賬戶)









