目錄
- 5.4 定位編輯法:ROME
- 5.4.1 知識存儲位置
- 1)因果跟蹤實驗
- 2)阻斷實驗
- 5.4.2 知識存儲機制
- 5.4.3 精準知識編輯
- 1)確定鍵向量
- 2)優化值向量
- 3)插入知識
5.4 定位編輯法:ROME
定位編輯:
-
首先定位知識存儲在神經網絡中的哪些參數中,
-
然后再針對這些定位到的參數進行精確的編輯。
ROME(Rank-One Model Editing)是其中的代表性方法。
.
5.4.1 知識存儲位置
通過對知識進行定位,可以揭示模型內部的運作機制,這是理解和編輯模型的關鍵步驟。
ROME 通過因果跟蹤實驗和阻斷實驗發現知識存儲于模型中間層的全連接前饋層。
.
1)因果跟蹤實驗
ROME通過因果跟蹤實驗探究模型中不同結構與知識在推理過程中的相關性。實驗包含三個步驟:
-
正常推理:保存模型未受干擾時的內部狀態,用于后續恢復。
-
干擾推理:干擾模型的所有內部狀態,作為基準線。
-
恢復推理:逐步恢復內部狀態,對比恢復前后的輸出差異,評估每個模塊與知識回憶的相關性。
最終目標是確定知識在模型中的具體位置。
實驗中,每個知識被表示為知 識元組 t = (s, r, o),其中 s 為 主體, r 為 關系,o 為客體。輸入問題為 q = (s, r),q^(i) 表示 q 的第 i 個 Token。我們期望模型在處理問題 q 時能 夠輸出對應的客體 o 作為答案。具體地,因果跟蹤實驗的步驟如下:
-
正常推理:輸入問題 q=(s,r),讓其預測出 o。此過程,保存模型內部所有模塊的正常輸出。
-
干擾推理:向 s 的嵌入層添加噪聲,破壞輸入向量,形成干擾狀態。
-
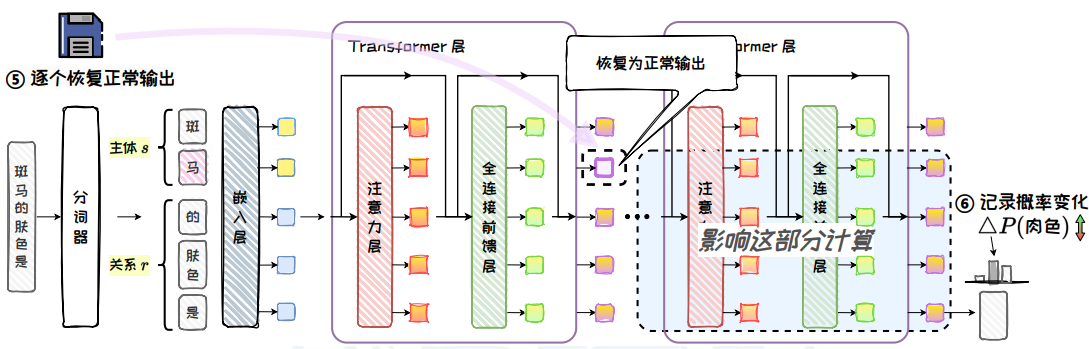
恢復推理:在干擾狀態下,逐個恢復輸入問題中每個 Token q^(i) 的輸出向量至“干凈”狀態,并記錄恢復前后模型對答案預測概率的增量(稱為模塊的因果效應),用于評估各模塊對知識回憶的貢獻。
以問題“斑馬的膚色是”為例,其因果跟蹤過程如下:
圖 5.12: 正常推理
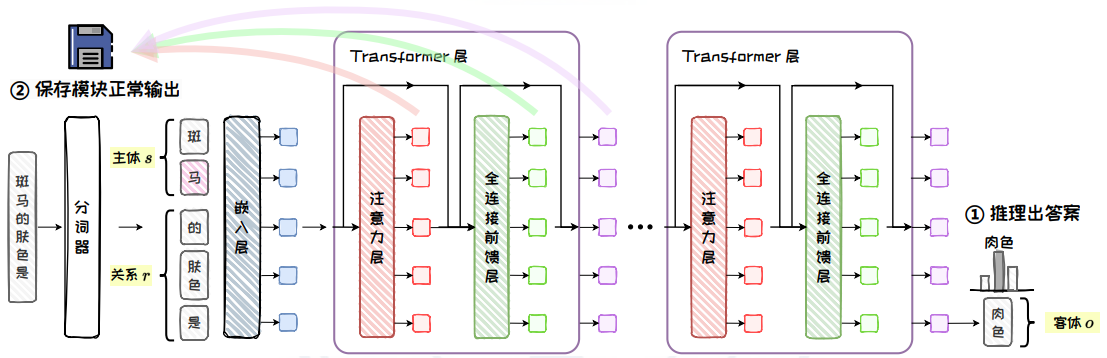
圖 5.13: 干擾推理
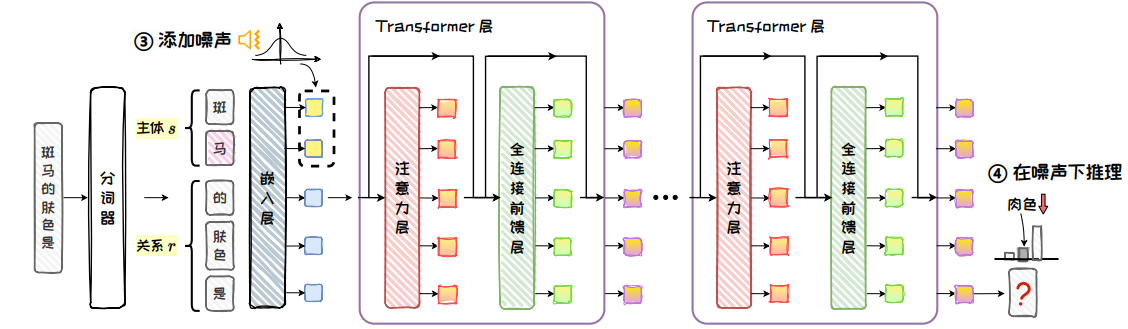
圖 5.14: 恢復推理
ROME在1000個知識陳述上對三種模塊進行因果跟蹤實驗,發現:
-
中間層Transformer在處理主體s的最后一個Token s?1時,因果效應顯著。
-
末尾層Transformer在處理輸入問題q的最后一個Token q?1時,因果效應也很強,但這在意料之中。
-
中間層Transformer在處理s?1時的因果效應主要來自全連接前饋層。
-
注意力層主要對末尾層Transformer處理q?1產生貢獻。
基于這些發現,ROME認為模型中間層的全連接前饋層可能是模型中存儲知識的關鍵位置。
.
2)阻斷實驗
為區分全連接前饋層和注意力層在 s^(?1) 處的因果效應中所起到的作用,并且驗證全連接前饋層的主導性,ROME 對兩種模型結構進行了阻斷實驗。
阻斷實驗原理
在恢復某一層Transformer處理s^(-1)的輸出后,將后續的全連接前饋層(或注意力層)凍結為干擾狀態,即隔離其計算,觀察模型性能下降程度,從而明確各層的關鍵作用。
圖 5.15: 阻斷實驗

實驗分析
比較阻斷前后的因果效應,ROME 發現:
-
如果沒后續全連接前饋層的計算,中間層在處理 s^(?1) 時就會失去因果效應,而末尾層的因果效應幾乎不受全連接前饋層缺失的影響。
-
而在阻斷注意力層時,模型各層處理 s^(?1) 時的因果效應只有較小的下降。
.
基于上述,ROME 認為在大語言模型中:
-
知識存儲于模型的中間層,其關鍵參數位于全連接前饋層,
-
而且特定中間層的全連接前饋層在處理主體的末尾 Token 時發生作用。
.
5.4.2 知識存儲機制
基于在此之前研究成果,ROME 結合知識定位實驗中的結論,推測知識以鍵值映射的形式等價地存儲在任何一個中間層的全連接前饋層中,并對知識存儲機制做出假設:
-
首先,起始的 Transformer 層中的注意力層收集主體 s 的信息,將其匯入至主體的最后一個 Token 的向量表示中。
-
接著,位于中間層的全連接前饋層對這個編碼主體的向量表示進行查詢,將查詢到的相關信息融入殘差流(Residual Stream)中。
-
最后,末尾的注意力層捕獲并整理隱藏狀態中的信息,以生成最終的輸出。
.
5.4.3 精準知識編輯
與 T-Patcher 相似,ROME 同樣將全連接前饋層視為鍵值存儲體。不同的是:
-
T-patcher 將上投影矩陣的參數向量看作鍵向量,將下投影矩陣的參數向量看作值向量,
-
而 ROME 則是將下投影矩陣的輸入向量看作鍵向量,將其輸出向量看作值向量。
具體地,ROME 認為上投影矩陣 W f c W_{fc} Wfc? 和激活函數 σ 能夠計算出鍵向量 k?,而下投影矩陣 W p r o j W_{proj} Wproj? 會與鍵向量運算并輸出值向量 v?,類似信息的查詢。
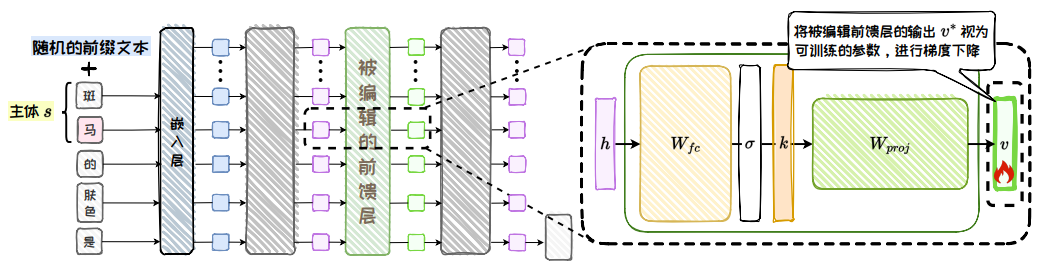
為了實現模型編輯,ROME 通過因果跟蹤實驗定位編輯位置,然后確定鍵向量,優化值向量,并通過插入新的鍵值對完成知識更新。其核心步驟包括:1. 確定鍵向量;2. 優化值向量;3. 插入知識。
圖 5.16: ROME 模型編輯方法
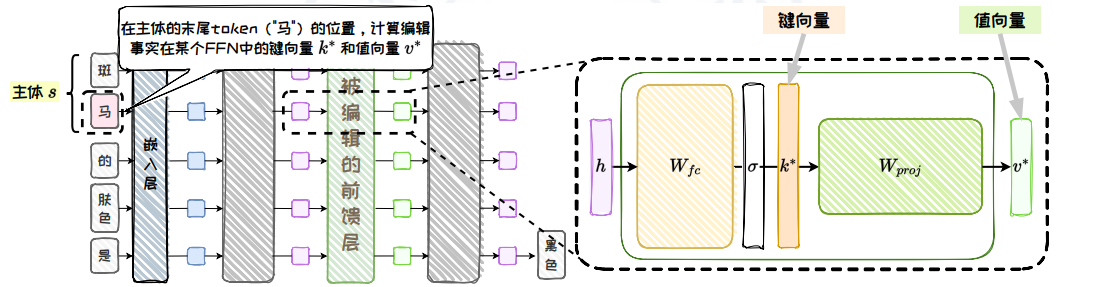
.
1)確定鍵向量
首先,需要確定 s (?1) 在被編輯的全連接前饋層中的向量表示 k*。
鍵向量 k* **是通過將 s 輸入模型并讀取其在全連接前饋層激活函數后的向量表示來確定的。
為了提高泛化性,會在 s 前拼接隨機的不同前綴文本,多次推理后計算平均向量作為 k*。
鍵向量的計算公式如下:
k ? = 1 N ∑ j = 1 N k ( x j + s ) k^* = \frac{1}{N} \sum_{j=1}^N k(x_j + s) k?=N1?j=1∑N?k(xj?+s)
其中:
-
N 為樣本數量,
-
j 為前綴文本索引,
-
x_j 為隨機前綴文本,
-
k(x_j + s) 代表在拼接前綴文本 x_j 時,s 的末尾 Token 在被編輯的全連接前饋層中的激活函數輸出,即下投影矩陣 W p r o j W_{proj} Wproj? 的輸入。
.
2)優化值向量
然后,需要確定一個值向量 v?,作為下投影矩陣 W p r o j W_{proj} Wproj? 與 k? 運算后的期望結果。ROME 通過優化全連接前饋層的輸出向量獲得 v?。
訓練過程中,ROME 通過設計損失函數 L(v) = L1(v) + L2(v) 以確保編輯的準確性和局部性,如圖 5.18。其中 v 是優化變量,用于替換全連接前饋層的輸出。
圖 5.18: 優化值向量
損失函數 L ( v ) \mathcal{L}(v) L(v) 的公式如下:
L ( v ) = L 1 ( v ) + L 2 ( v ) \mathcal{L}(v) = \mathcal{L}_1(v) + \mathcal{L}_2(v) L(v)=L1?(v)+L2?(v)
L 1 ( v ) = 1 N ∑ j = 1 N ? log ? P M ′ ( o ∣ x j + p ) \mathcal{L}_1(v) = \frac{1}{N} \sum_{j=1}^N -\log \mathbb{P}_{M'}(o \mid x_j + p) L1?(v)=N1?j=1∑N??logPM′?(o∣xj?+p)
L 2 ( v ) = D K L ( P M ′ ( x ∣ p ′ ) ∣ ∣ P M ( x ∣ p ′ ) ) \mathcal{L}_2(v) = D_{KL}(\mathbb{P}_{M'}(x \mid p') ||\mathbb{P}_M(x \mid p')) L2?(v)=DKL?(PM′?(x∣p′)∣∣PM?(x∣p′))
其中:
-
M 為原始模型;
-
M’ 為優化 v 時的模型;
-
o 為客體,即目標答案;
-
p 為所編輯的目標問題 prompt;
-
D K L D_{KL} DKL? 為 KL 散度;
-
p’ 是有關 s 的含義的 prompt。
圖 5.19: 值向量損失函數
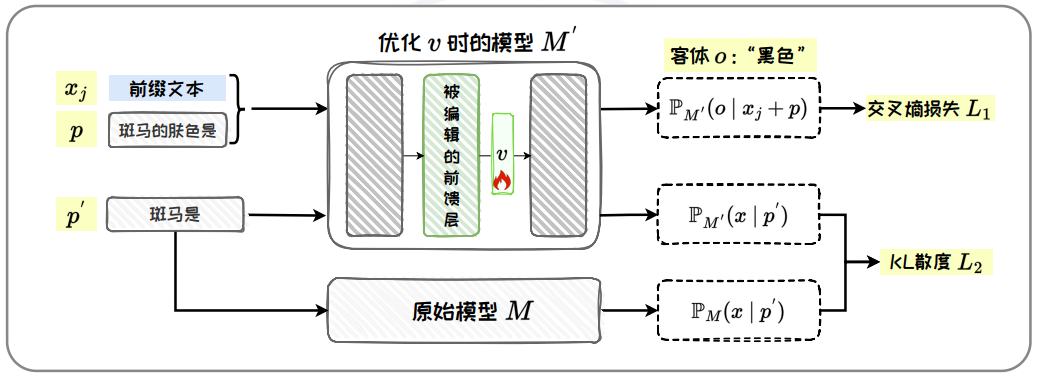
如圖 5.19, 在 L(v) 中:
-
為了確保準確性,L1(v) 旨在最大化 o 的概率,通過優化 v 使網絡對所編輯的問題 prompt p 做出正確的預測,與計算 k? 時相同,也會在 p 之前拼接不同前綴文本;
-
為了確保局部性,L2(v) 在 p′ =“{s} 是”這種 prompt 下,最小化 M′ 與 M 輸出的 KL 散度,以避免模型對 s 本身的理解發生偏移, 從而確保局部性。
.
3)插入知識
確定了知識在編輯位置的向量表示 k? 和 v? 之后,ROME 的目標是調整全連接前饋層中的下投影矩陣 W p r o j W_{proj} Wproj?,使得 W p r o j k ? = v ? W_{proj} k^? = v^? Wproj?k?=v?,從而將新知識插入到全連接前饋層中。
然而,在插入新知識的同時,需要盡量避免影響 W p r o j W_{proj} Wproj? 中的原有信息。
過程可抽象為一個帶約束的最小二乘問題,其形式如下:
確保最小影響: min ? ∥ W ^ K ? V ∥ 確保最小影響:\quad \min \| \hat{W} K - V \| 確保最小影響:min∥W^K?V∥
滿足 W p r o j k ? = v ? 關系: s.t. W ^ k ? = v ? 滿足W_{proj} k^? = v^?關系:\quad \text{s.t.} \quad \hat{W} k^* = v^* 滿足Wproj?k?=v?關系:s.t.W^k?=v?
該問題可推導出閉式解為:
W ^ = W + Λ ( C ? 1 k ? ) T \hat{W} = W + \Lambda (C^{-1} k^*)^T W^=W+Λ(C?1k?)T
其中:
-
Λ = v ? ? W k ? ( C ? 1 k ? ) T k ? \Lambda = \frac{v^* - W k^*}{(C^{-1} k^*)^T k^*} Λ=(C?1k?)Tk?v??Wk??
-
W 為原始的權重矩陣
-
W ^ \hat{W} W^ 為更新后的權重矩陣
-
C = K K T C = K K^T C=KKT 是一個預先計算的常數,基于維基百科中的大量文本樣本 k 的去中心化協方差矩陣進行估計
利用這一簡代數方法,ROME 能直接插入代表知識元組的鍵值對 (k*, v*),實現對模型知識的精確編輯。
.
其他參考:【大模型基礎_毛玉仁】系列文章
聲明:資源可能存在第三方來源,若有侵權請聯系刪除!





:字符串切片)


)




)


)


