橫掃SQL面試
📌 連續性登錄問題

在互聯網公司的SQL面試中,連續性問題堪稱“必考之王”。💻🔍
用戶連續登錄7天送優惠券🌟,服務器連續報警3次觸發熔斷??,圖書館連續3天人流破百開啟限流?” …
既考察你對窗口函數的靈活運用,又考驗你能否將業務場景抽象為數學模型。
博主總結一些經典題型,幫列位小伙伴拿下這類題目🤣 🤣 🤣 🤣
Tips:
暴力解法(如自連接、逐行遍歷)在數據量小時勉強可用,但面對百萬級📈數據時:
- 性能災難:自連接時間復雜度達O(n2),1萬行數據需1億次計算 🔥
- 邏輯漏洞:簡單
lag/lead無法處理連續多天的復雜中斷
而真正的工業級解法,只需一行窗口函數 + 虛擬分組標記,就能以O(n)時間復雜度解決問題! 🚀
🌟 連續問題通用解法框架
| 步驟 | 核心操作 🔑 | 適用場景 |
|---|---|---|
| 生成連續標記 | date - row_number() over(...) | 映射連續日期到同一虛擬組 |
| 分組統計 | group by 虛擬組標記 | 計算連續天數/次數 |
| 結果篩選 | having count(*) >= N | 過濾滿足條件的連續事件 |
話不多說——直接上題:🎈🎈🎈🎈🎈🎈🎈
🎯1. 最長連續登錄天數
你正在搭建一個用戶活躍度的畫像,其中一個與活躍度相關的特征是“最長連續登錄天數”
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
tb_dau | fdate | 登錄日期 | DATE |
user_id | 用戶唯一標識 | INT |
計算用戶在指定時間段內的最長連續登錄天數。例如:統計用戶2023年1月的最長連續登錄記錄。
| fdate | user_id |
|---|---|
| 2023-01-01 | 10000 |
| 2023-01-02 | 10000 |
| 2023-01-04 | 10000 |
預期結果🔑
| user_id | max_consec_days |
|---|---|
| 10000 | 2 |
博主按照解題框架 一步一步帶大家看哈~🤣🤣🤣
步驟1:生成連續標記(CTE t1)🧩
為每個用戶的登錄日期生成序號,標記連續登錄的潛在分組。
with t1 as (selectuser_id,fdate,-- 默認大家都是有基礎的哈 窗口函數應該都會哈row_number() over(partition by user_id order by fdate) as rnfrom tb_dauwhere fdate between '2023-01-01' and '2023-01-31'
)
臨時表 t1:?
| user_id | fdate | rn |
|---|---|---|
| 10000 | 2023-01-01 | 1 |
| 10000 | 2023-01-02 | 2 |
| 10000 | 2023-01-04 | 3 |

rn表示用戶按日期排序后的登錄次數序號。- 連續日期的
rn差值等于日期差值(例如:2023-01-02 是第2次登錄,日期差為1天)。
步驟2:計算虛擬起始點(CTE t2)🧩
通過 date_sub(fdate, interval rn day) 將連續日期映射到同一虛擬起始點。
t2 as (selectuser_id,fdate,date_sub(fdate, interval rn day) as start_datefrom t1
)
臨時表 t2:?
| user_id | fdate | start_date |
|---|---|---|
| 10000 | 2023-01-01 | 2022-12-31 |
| 10000 | 2023-01-02 | 2022-12-31 |
| 10000 | 2023-01-04 | 2023-01-01 |

- 連續日期的
start_date相同(如1月1日和1月2日均映射到2022-12-31)。 - 非連續日期的
start_date不同(如1月4日映射到2023-01-01)。
步驟3:統計連續天數(CTE t3)🧩
按用戶和虛擬起始點分組,統計每組中的記錄數(即連續天數)。
t3 as (selectuser_id,start_date,count(*) as cntfrom t2group by user_id, start_date
)
臨時表 t3:?
| user_id | start_date | cnt |
|---|---|---|
| 10000 | 2022-12-31 | 2 |
| 10000 | 2023-01-01 | 1 |

cnt表示每個虛擬起始點對應的連續登錄天數。- 用戶10000有兩個連續區間:2天和1天。
最終結果取每個用戶的最大連續天數。🧩
selectuser_id,max(cnt) as max_consec_days
from t3
group by user_id;
輸出結果:?

| user_id | max_consec_days |
|---|---|
| 10000 | 2 |
技術本質🧩
通過 date_sub(fdate, interval rn day),將連續日期的差值抵消,映射到同一虛擬起始點:
- 連續日期:
fdate - rn恒定?(如 1月1日-1天=12月31日,1月2日-2天=12月31日)。 - 非連續日期:
fdate - rn不同(如1月4日-3天=1月1日)。
將連續性問題轉化為分組計數問題,時間復雜度僅為 O(n)。?
完整代碼 ~
-- 定義第一個公共表表達式 (CTE) t1,用于計算每個用戶登錄日期的排序
with t1 as (selectuser_id, -- 用戶IDfdate, -- 登錄日期row_number() over(partition by user_id order by fdate) as rn -- 為每個用戶的登錄日期生成排序編號from tb_dauwhere fdate between '2023-01-01' and '2023-01-31' -- 選擇指定日期范圍內的記錄
), -- 定義第二個公共表表達式 (CTE) t2,用于計算每個登錄日期的起始日期
t2 as (selectuser_id, -- 用戶IDfdate, -- 登錄日期date_sub(fdate, interval rn day) as start_date -- 計算起始日期:將登錄日期減去排序編號天數from t1
), -- 定義第三個公共表表達式 (CTE) t3,用于計算每個用戶在相同起始日期下的連續登錄天數
t3 as (selectuser_id, -- 用戶IDcount(*) as cnt -- 計算連續登錄天數from t2group by user_id, start_date -- 按用戶和起始日期分組
)-- 從 t3 表中選擇用戶ID和其最大連續登錄天數
selectuser_id, -- 用戶IDmax(cnt) as max_consec_days -- 最大連續登錄天數
from t3
group by user_id; -- 按用戶ID分組
🎯2. 連續出現的數字
從數字序列中找出至少連續出現3次的數字。例如:[1, 1, 1, 2, 2, 3] 中,1 連續出現3次。
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
logs | id | 記錄序號 | INT |
num | 數字值 | INT |
| id | num |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
| 6 | 3 |
| ConsecutiveNums |
|---|
| 1 |
這題同理~連續性問題解法框架:
1.💡 標記連續性:使用 row_number() 生成序號。
2. 🔍生成虛擬組:通過差值(如 id - rn)抵消連續增量。
3. 🛠?分組統計:按虛擬組聚合,篩選滿足條件的結果。
步驟1:生成連續標記(CTE t1)🚀
為每個數字按 id 排序生成行號,標記連續出現的潛在分組。
with t1 as (selectnum,id,row_number() over(partition by num order by id) as rnfrom logs
)
臨時表 t1:?
| num | id | rn |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 3 | 3 |
| 2 | 4 | 1 |
| 2 | 5 | 2 |
| 3 | 6 | 1 |

rn表示相同數字(num)按id排序后的出現次數序號。- 連續相同數字的
id與rn的差值恒定(例如:num=1時,id - rn = 0)。
步驟2:計算虛擬分組標記(CTE t2)🚀
通過 id - rn 生成分組標記 group_id,將連續相同數字映射到同一虛擬組。
t2 as (selectnum,id - rn as group_idfrom t1
)
臨時表 t2:?
| num | group_id |
|---|---|
| 1 | 0 |
| 1 | 0 |
| 1 | 0 |
| 2 | 3 |
| 2 | 3 |
| 3 | 5 |

- 連續相同數字的
group_id相同(如num=1的3條記錄均為group_id=0)。 - 非連續或不同數字的
group_id不同(如num=2和num=3)。
步驟3:統計連續出現次數(最終查詢)🚀
按 num 和 group_id 分組,篩選出出現次數≥3的組,并去重輸出結果。
select distinct num as ConsecutiveNums
from t2
group by num, group_id
having count(*) >= 3;
分組統計結果:?
| num | group_id | count(*) |
|---|---|---|
| 1 | 0 | 3 |
| 2 | 3 | 2 |
| 3 | 5 | 1 |

最終輸出:?
| ConsecutiveNums |
|---|
| 1 |
技術本質🚀
通過 id - row_number(),將連續相同數字的差值抵消,映射到同一虛擬分組:
- 連續相同數字:
id - rn恒定🔥(如num=1時,id=1,2,3→1-1=0,2-2=0,3-3=0)。 - 非連續或不同數字:
id - rn不同(如num=2時,id=4,5→4-1=3,5-2=3,但次數不足)。
如果題目要求連續出現4次,只需修改 having 條件:
having count(*) >= 4 -- 篩選連續出現4次的數字
🎯3. 新注冊用戶連續登錄不少于3天
篩選出新注冊用戶在注冊后至少連續登錄3天的用戶列表。例如:用戶注冊后連續登錄了2023-01-01、01-02、01-03三天。
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
tb_users | user_id | 用戶唯一標識 | INT |
reg_date | 用戶注冊日期 | DATE | |
tb_login | user_id | 用戶唯一標識 | INT |
login_date | 用戶登錄日期 | DATE |
用戶表 (tb_users)?
| user_id | reg_date |
|---|---|
| 10001 | 2023-01-01 |
| 10002 | 2023-01-05 |
登錄表 (tb_login)?
| user_id | login_date |
|---|---|
| 10001 | 2023-01-01 |
| 10001 | 2023-01-02 |
| 10001 | 2023-01-03 |
| 10002 | 2023-01-05 |
| 10002 | 2023-01-06 |
預期結果
| user_id |
|---|
| 10001 |
步驟1:關聯用戶與登錄數據(CTE login_sequence)?
篩選注冊后7天內的登錄記錄,并為每個用戶的登錄日期生成行號。
with login_sequence as (selectu.user_id,l.login_date,-- 為每個用戶的登錄日期生成行號(按日期排序)row_number() over(partition by u.user_id order by l.login_date) as rnfrom tb_users ujoin tb_login l on u.user_id = l.user_idand l.login_date between u.reg_date and u.reg_date + interval 7 day
)
臨時表 login_sequence:?
| user_id | login_date | rn |
|---|---|---|
| 10001 | 2023-01-01 | 1 |
| 10001 | 2023-01-02 | 2 |
| 10001 | 2023-01-03 | 3 |
| 10002 | 2023-01-05 | 1 |
| 10002 | 2023-01-06 | 2 |
rn表示用戶按登錄日期排序后的連續次數。login_date between reg_date and reg_date + 7 day限定注冊后7天內的登錄行為。
限定用戶注冊后7天內的登錄行為,聚焦新用戶關鍵活躍期,數據進入窗口函數前剔除無效數據,避免對全量數據排序。聚焦核心業務目標(如新用戶激活率、首周留存率)
步驟2:生成虛擬分組標記(CTE consec_groups)🚀
計算 login_date - rn,將連續日期映射到同一虛擬起始點。
consec_groups as (selectuser_id,login_date,-- 計算虛擬分組標記(連續日期的差值為0)date_sub(login_date, interval rn day) as group_idfrom login_sequence
)
臨時表 consec_groups:?
| user_id | login_date | group_id |
|---|---|---|
| 10001 | 2023-01-01 | 2022-12-31 |
| 10001 | 2023-01-02 | 2022-12-31 |
| 10001 | 2023-01-03 | 2022-12-31 |
| 10002 | 2023-01-05 | 2023-01-04 |
| 10002 | 2023-01-06 | 2023-01-04 |
- 連續登錄的日期差值相同(如用戶10001的3次登錄均映射到
2022-12-31)。🚀🚀🚀 - 非連續登錄的日期差值不同(如用戶10002的2次登錄映射到
2023-01-04)。
步驟3:統計連續登錄天數(最終查詢)
按用戶和虛擬分組標記統計連續天數,篩選≥3天的用戶。
distinct user_id 確保用戶多次滿足條件時只輸出一次。
select distinct user_id
from consec_groups
group by user_id, group_id
having count(*) >= 3;
分組統計結果:?
| user_id | group_id | count(*) |
|---|---|---|
| 10001 | 2022-12-31 | 3 |
| 10002 | 2023-01-04 | 2 |
最終輸出:?
| user_id |
|---|
| 10001 |
💡 關鍵邏輯
虛擬分組標記:
date_sub(login_date, interval rn day) 將連續日期映射到同一虛擬起始點,本質是公式:
連續天數 = 最大登錄日期 - 最小登錄日期 + 1 (若連續,則 login_date - rn 恒定)
🎯4. 圖書館高峰期檢測
找出圖書館連續3天及以上人流量≥100的高峰時段。例如:2023-01-02至2023-01-04連續三天人流量達標。
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
info | date | 日期 | DATE |
people | 人流量 | INT |
| date | people |
|---|---|
| 2023-01-01 | 70 |
| 2023-01-02 | 100 |
| 2023-01-03 | 120 |
| 2023-01-04 | 120 |
| 2023-01-05 | 90 |
預期結果
| start_date | end_date | consecutive_days |
|---|---|---|
| 2023-01-02 | 2023-01-04 | 3 |
后面博主就不再啰嗦啦 大家可以發現 套路是不是都一樣~🤣🤣🤣 “標記→分組→過濾”???
with valid_days as (select date,date - row_number() over(order by date) as grpfrom infowhere people >= 100
),
consec_groups as (selectmin(date) as start_date,max(date) as end_date,count(*) as consecutive_daysfrom valid_daysgroup by grphaving count(*) >= 3
)
select * from consec_groups;
- 篩選有效日期:過濾人流量≥100的天數。
- 生成連續組標記:
date - row_number()將連續有效日期映射到同一組。 - 統計連續時段:按組統計起止日期和持續天數。
🎯5. 用戶指標檢測
從訂單表中篩選出連續三天及以上每天總下單金額均超過100元的用戶。例如:用戶A在2023-01-01至2023-01-03每天的總消費分別為120元、150元、110元,滿足條件。
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
order_table | id | 訂單編號 | INT |
dt | 下單日期 | DATE | |
amount | 訂單金額 | INT |
| id | dt | amount |
|---|---|---|
| 1001 | 2021-12-12 | 123 |
| 1002 | 2021-12-12 | 45 |
| 1001 | 2021-12-13 | 43 |
| 1001 | 2021-12-13 | 45 |
| 1001 | 2021-12-14 | 230 |
預期結果
| user_id |
|---|
| 1001 |
-- 步驟1:按用戶和日期匯總金額,過濾每天金額>100的記錄
with daily_summary as (selectid as user_id,dt,sum(amount) as total_amountfrom order_tablegroup by user_id, dthaving sum(amount) > 100
),
-- 步驟2:生成連續標記
sequence_marker as (selectuser_id,dt,date_sub(dt, interval row_number() over(partition by user_id order by dt) day) as grpfrom daily_summary
),
-- 步驟3:統計連續天數
consec_groups as (selectuser_id,grp,count(*) as consec_days,min(dt) as start_date,max(dt) as end_datefrom sequence_markergroup by user_id, grphaving count(*) >= 3 -- 連續3天及以上
)
-- 步驟4:輸出結果
select distinct user_id
from consec_groups;
- 按天匯總金額:
group by user_id, dt處理一天多筆訂單。 - 生成虛擬分組:
date_sub(dt, interval row_number() day)將連續日期映射到同一虛擬組。 - 統計連續天數:篩選連續≥3天的用戶。
🎯6. 用戶最大連續繳費次數
計算每個用戶的最長連續繳費天數。例如:用戶U002在2023-01-03至2023-01-05連續繳費3天,結果為3。
| 表名 | 字段名 | 描述 | 數據類型 |
|---|---|---|---|
payment_log | user_id | 用戶唯一標識 | VARCHAR |
pay_date | 繳費日期 | DATE | |
amount | 繳費金額 | INT |
| user_id | pay_date | amount |
|---|---|---|
| U001 | 2023-01-01 | 100 |
| U001 | 2023-01-02 | 200 |
| U001 | 2023-01-04 | 150 |
| U002 | 2023-01-03 | 80 |
| U002 | 2023-01-04 | 90 |
| U002 | 2023-01-05 | 120 |
預期結果
| user_id | max_consec_days |
|---|---|
| U001 | 2 |
| U002 | 3 |
with payment_sequence as (selectuser_id,pay_date,date_sub(pay_date, interval row_number() over(partition by user_id order by pay_date) day) as grpfrom payment_log
),
consec_groups as (selectuser_id,grp,count(*) as consec_daysfrom payment_sequencegroup by user_id, grp
)
selectuser_id,max(consec_days) as max_consec_days
from consec_groups
group by user_id;
- 生成虛擬分組:
date_sub(pay_date, interval row_number() day)標記連續繳費序列。 - 統計連續天數:按用戶和虛擬組計算連續繳費次數。
- 取最大值:
max(consec_days)獲取每個用戶的最大連續天數。
🧩 連續性問題的通用解法框架
| 步驟 | 核心操作 | 適用場景 |
|---|---|---|
| 數據清洗 | 按業務需求聚合數據(如按天匯總金額) | 處理多筆記錄/噪聲數據 |
| 生成連續標記 | date - row_number() 映射連續日期到虛擬組 | 統一連續序列的時空標識 |
| 分組統計 | group by 虛擬組標記 | 計算連續天數/次數 |
| 結果篩選 | having 或 max() 過濾目標結果 | 輸出滿足條件的用戶或時段 |
這一套組合拳下來??? 相信列位面試在遇到連續性登錄問題 絲毫不慌了😂
留個作業~ 有些難度哈——合并用戶停留位置
給定用戶位置停留記錄,需要對同一個用戶在同一個位置的連續多條記錄進行合并,合并原則為開始時間取最早時間,停留時長加和。
| 表名 | 字段名 | 字段含義 | 數據類型 |
|---|---|---|---|
| 用戶位置停留記錄表 | user | 用戶標識 | VARCHAR |
location | 位置標識 | VARCHAR | |
start_time | 停留開始時間 | DATETIME | |
stay_duration | 停留的時長(分鐘) | INT |
| user | location | start_time | stay_duration |
|---|---|---|---|
| UserA | LocationA | 2018-01-01 08:00:00 | 60 |
| UserA | LocationA | 2018-01-01 09:00:00 | 60 |
| UserA | LocationB | 2018-01-01 10:00:00 | 60 |
| UserA | LocationA | 2018-01-01 11:00:00 | 60 |
結果預期:
| user | location | start_time | stay_duration |
|---|---|---|---|
| UserA | LocationA | 2018-01-01 08:00:00 | 120(08:00:00 開始的 60 分鐘和 09:00:00 開始的 60 分鐘合并) |
| UserA | LocationB | 2018-01-01 10:00:00 | 60 |
| UserA | LocationA | 2018-01-01 11:00:00 | 60 |
很熟悉的套路啦
第一步:按照 用戶 、 地點 分組 起始時間 去排序。
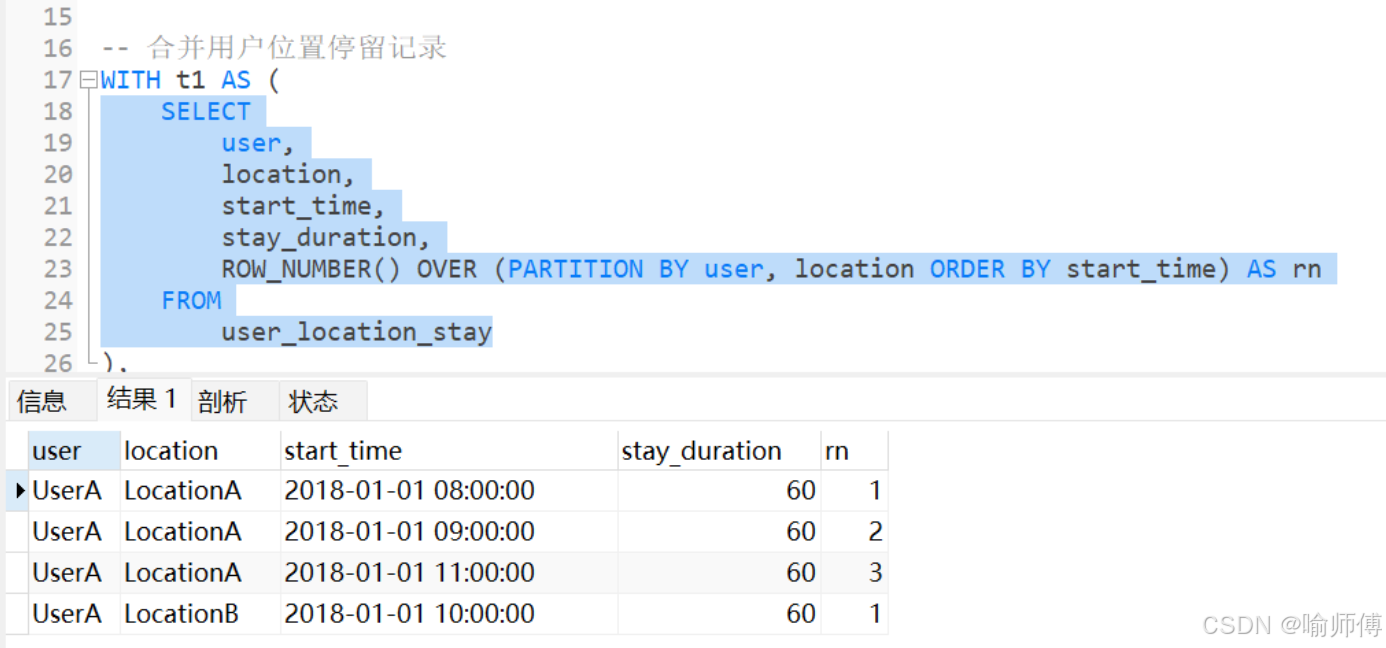
第二步:按照連續登錄問題 A列 - 排序列 做一個 分組標記
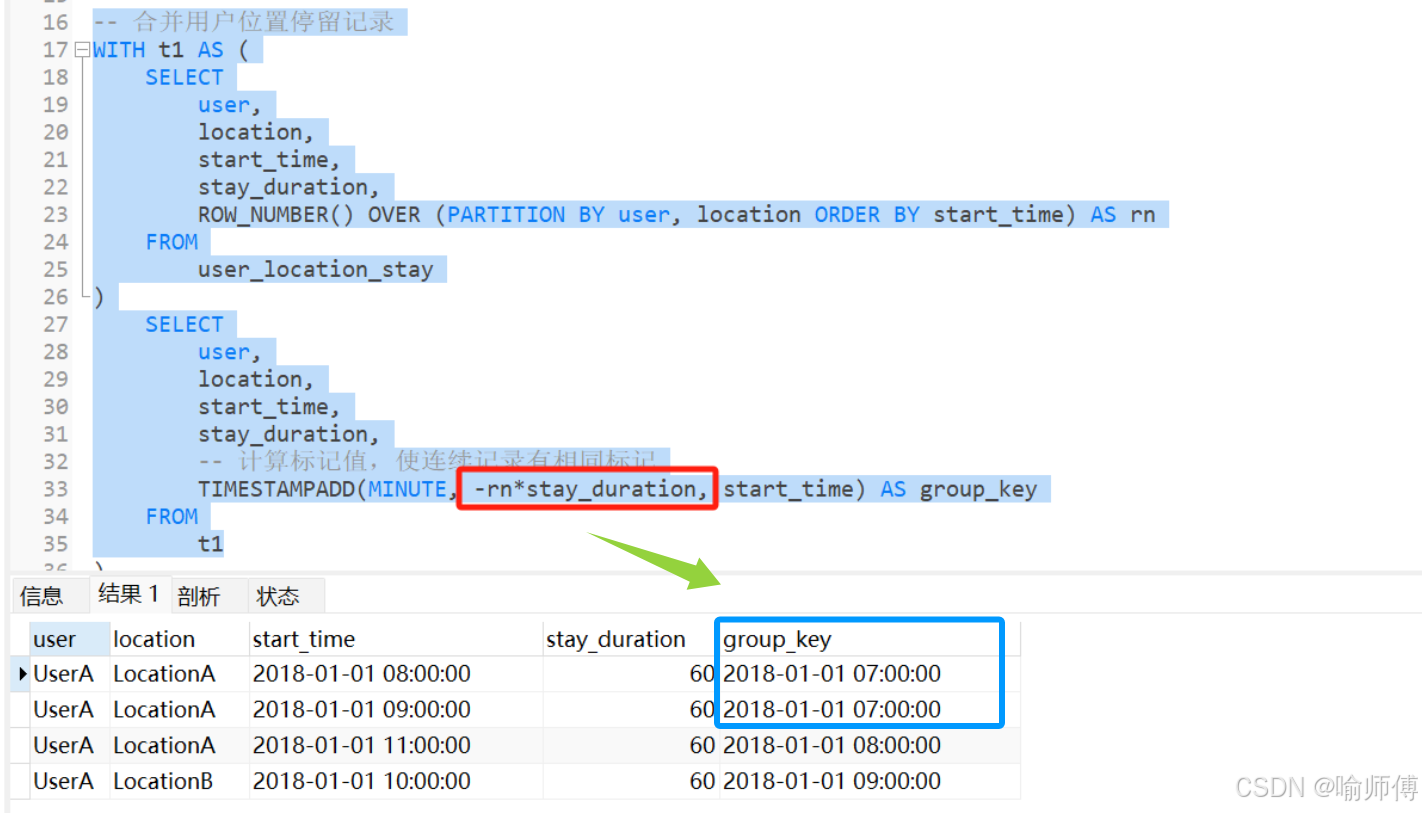
第3步 分組之后 min sum聚合即可~





:字符串切片)


)




)


)



