例1.2 為了研究全國31個省、市、自治區2018年城鎮居民生活消費的分布規律,根據調查資料做區域消費類型劃分。
指標:
食品x1:人均食品支出(元/人) ?
衣著x2:人均衣著商品支出(元/人)
居住x3:人均居住支出(元/人)
生活x4:人均家庭設備用品及服務支出(元/人)
交通x5:人均交通和通訊支出(元/人)
教育x6:人均娛樂教育文化服務支出(元/人)
醫療x7:人均醫療保健支出(元/人) ?
其他x8:人均雜項商品和服務支出(元/人)
地區
x1
x2
x3
x4
x5
x6
x7
x8
北京
8064.9
2175.5
14110.3
2371.9
4767.4
3999.4
3274.5
1078.6
天津
8647.5
1990.0
6406.3
1818.4
4280.9
3186.6
2676.9
896.3
河北
4271.3
1257.4
4050.4
1138.7
2355.4
1734.5
1540.5
373.8
山西
3688.2
1261.0
3228.5
855.6
1845.2
1940.0
1635.1
356.4
內蒙古
5324.3
1751.2
3680.0
1204.6
3074.3
2245.4
1847.5
537.9
遼寧
5727.8
1628.1
4169.5
1259.4
2968.2
2708.0
2257.1
680.2
吉林
4417.4
1397.0
3294.8
899.4
2479.7
2193.4
2012.0
506.7
黑龍江
4573.2
1405.4
3176.3
866.4
2196.6
2030.3
2235.3
490.4
上海
10728.2
2036.8
14208.5
2095.5
4881.2
5049.4
3070.2
1281.5
江蘇
6529.8
1541.0
6731.2
1493.3
3522.8
2582.6
2016.4
590.4
浙江
8198.3
1813.5
7721.2
1652.4
4302.0
3031.3
2059.4
692.6
安徽
5414.7
1137.4
3941.9
1041.2
2082.1
1810.4
1224.0
392.8
福建
7572.9
1212.1
6130.0
1223.1
2923.3
2194.0
1234.8
505.8
江西
4809.0
1074.1
3795.2
1047.7
1872.1
1813.0
1000.0
381.0
山東
5030.9
1391.8
3928.5
1394.3
2834.3
2174.4
1627.6
398.1
河南
3959.8
1172.8
3512.0
1054.4
1838.0
1769.1
1541.5
321.0
湖北
5491.3
1316.2
4310.6
1253.2
2584.1
2187.5
1907.9
487.0
湖南
5260.0
1215.5
3976.1
1190.2
2322.9
2786.2
1705.5
351.5
廣東
8480.8
1135.3
6643.3
1440.8
3423.9
2750.9
1520.8
658.2
廣西
4545.7
616.7
3268.5
898.2
2150.1
1798.9
1364.6
291.9
海南
6552.2
655.9
3744.0
826.6
1919.0
2185.5
1236.1
409.2
重慶
6220.8
1454.5
3498.8
1338.9
2545.0
2087.8
1660.0
442.8
四川
5937.9
1173.8
3368.0
1182.2
2398.8
1599.7
1568.6
434.5
貴州
3792.9
934.7
2760.7
878.1
2408.0
1660.0
1083.5
280.1
云南
3983.4
789.1
3081.1
859.9
2212.8
1772.7
1267.7
283.2
西藏
4330.5
1285.2
2102.6
622.3
1847.7
609.3
460.1
262.6
陜西
4292.5
1141.1
3388.2
1200.8
2005.8
2008.8
1749.4
373.2
甘肅
4253.3
1111.5
3095.0
896.9
1640.7
1710.3
1573.9
342.4
青海
4671.6
1350.6
2990.0
932.0
2671.4
1655.6
1842.0
444.0
寧夏
4234.1
1388.2
3014.3
1067.1
2724.4
2139.5
1727.1
420.4
新疆
4691.6
1456.0
2894.3
1082.8
2274.4
1762.5
1592.6
434.9
數據讀入X=read.table('biao1.2.txt',header=T)
R 函數筆記 | read.table()函數 - 簡書 (jianshu.com)
file填要打開的文件名,如"data"
options填操作
參數 功能 header 邏輯值,指示表格是否包含文件第一行中的變量名稱 sep 分隔數據值的分隔符。默認值為sep =“ ”,表示一個或多個空格、制表符、換行符或回車符。使用sep =“,”來讀取被逗號","分隔的文件,使用sep =“\t”來讀取制表符分隔的文件 row.names 一個可選參數,指定一個或多個變量來表示行標識符 col.names 如果數據文件的第一行不包含變量名(header = FALSE),則可以使用col.names指定包含變量名的字符向量。如果header = FALSE并且省略了col.names選項,則變量將命名為V1,V2,依此類推。 na.strings 指示缺失值代碼的可選字符向量。例如,na.strings = c(“9”,“?”)轉換每個9和?讀取數據時的值為NA colClasses 分配給列的類的可選向量。例如,colClasses = c(“numeric”,“numeric”,“character”,“NULL”,“numeric”)將前兩列讀取為numeric,將第三列讀取為character,跳過第四列,并讀取 第五列為numeric。 如果數據中有五列以上,則第六列重新從colClasses的第一個numeric開始 quote 用于分隔包含特殊字符的字符串的字符。默認情況下,這是雙引號"或單引號' skip 在開始讀取數據之前要跳過的文本文件中的行數。此選項對于跳過文件中的標題注釋很有用 stringsAsFactors 邏輯值,指示是否應將字符變量轉換為因子。除非被colClasses覆蓋,否則默認值為TRUE。處理大型文本文件時,設置stringsAsFactors = FALSE可以加快處理速度 text 指定要處理的文本字符串的字符串 comment.char 關閉注釋 X=read.table(file, options)
1.散布矩陣圖
散布矩陣圖在一張圖上給出p個變量相互之間的散點圖,由此可以直觀看出p個變量兩兩之間的相關關系。
R語言 pairs()用法及代碼示例 - 純凈天空 (vimsky.com)
pairs(X) #畫散布矩陣圖R語言中的pairs()函數用于返回一個繪圖矩陣,由每個 DataFrame 對應的散點圖組成。
用法: pairs(data)
從該圖可以看出,食品支出與生活用品及服務支出、教育及文化娛樂支出之間存在顯著線性相關關系,而教育及文化娛樂支出又與居住支出、其他支出之間存在顯著線性相關關系,等等。
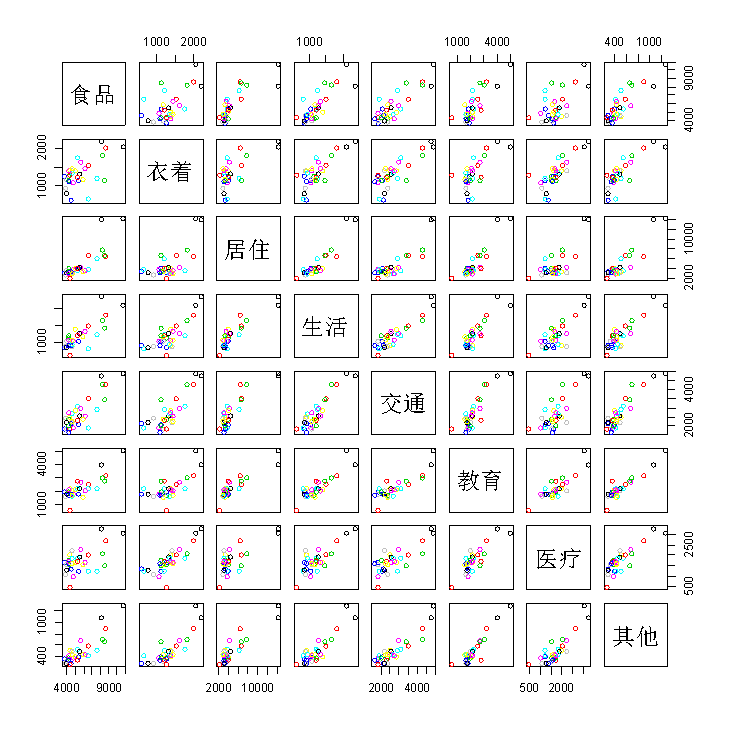
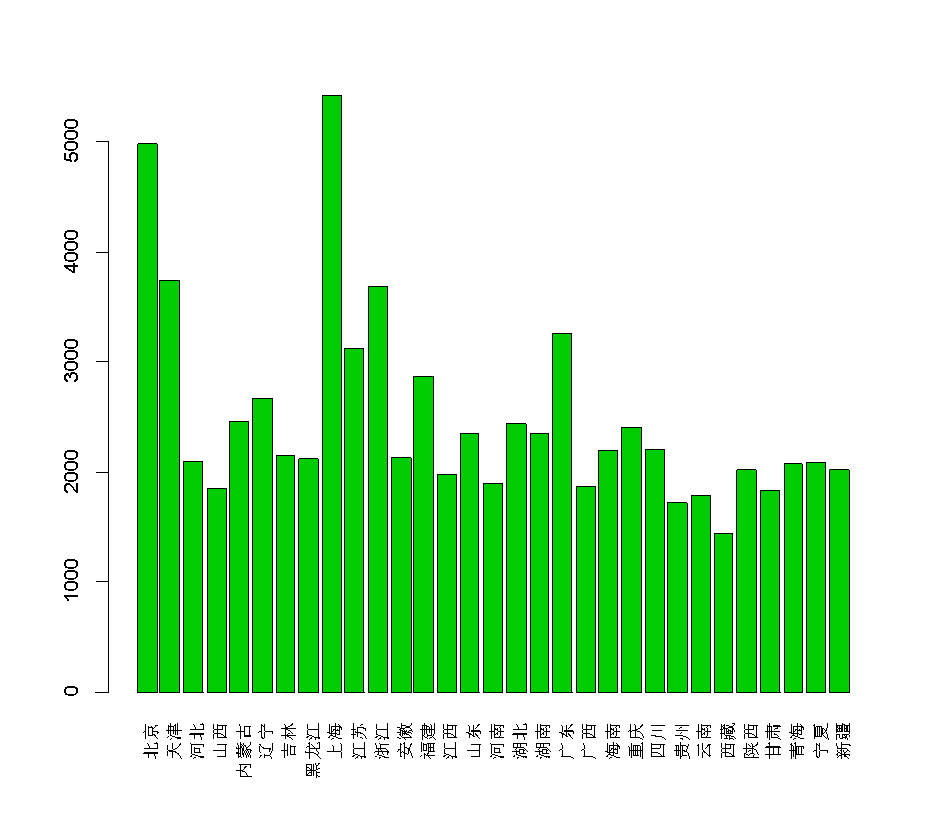
2.均值條形圖
均值條形圖常用來比較各個樣本的樣本均值的大小,也可以比較各個變量的樣本均值的大小。
R語言:使用barplot()繪制柱狀圖(條形圖) - 知乎 (zhihu.com)
barplot(apply(X,1,mean),las=3)barplot(height, # 柱子的高度names.arg = NULL, # 柱子的名稱col = NULL, # 柱子的填充顏色border = par("fg"), # 柱子的輪廓顏色main = NULL, # 柱狀圖主標題xlab = NULL, # X軸標簽ylab = NULL, # Y軸標簽xlim = NULL, # X軸取值范圍ylim = NULL, # Y軸取值范圍horiz = FALSE, # 柱子是否為水平legend.text = NULL, # 圖例文本beside = FALSE, # 柱子是否為平行放置)
但是這里我們是直接用的apply函數R 數據處理(二十)—— apply - 知乎 (zhihu.com)
apply(X, MARGIN, FUN, ...)
X: 數組、矩陣、數據框,數據至少是二維的MARGIN: 按行計算或按列計算,1?表示按行,2?表示按列FUN: 自定義的調用函數...:?FUN?的可選參數
組合一下,有:
按行做均值條圖
barplot(apply(X,1,mean))按列做均值條圖
barplot(apply(X,2,mean))這里圖1就是按行的,圖二按列

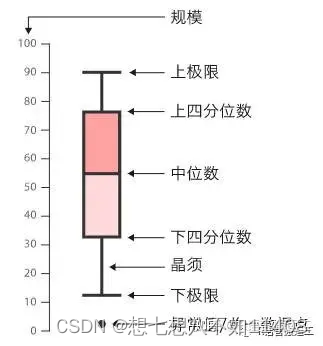
?3.箱線圖
箱線圖可以比較清晰地展示數據的分布特征。
R語言 boxplo函數用法及箱線圖介紹_r gg_boxplot_col()-CSDN博客
boxplot(X) #按列做垂直箱線圖 boxplot(X,horizontal=T)#水平箱線圖boxplot(x, ..., range = 1.5, width = NULL, varwidth = FALSE, notch = FALSE, outline = TRUE, names, plot = TRUE, border = par("fg"), col = NULL, log = "", pars = list(boxwex = 0.8, staplewex = 0.5, outwex = 0.5), horizontal = FALSE, add = FALSE, at = NULL)
主要參數的含義:
x: 向量,列表或數據框。
formula: 公式,形如y~grp,其中y為向量,grp是數據的分組,通常為因子。
data: 數據框或列表,用于提供公式中的數據。
range: 數值,默認為1.5,表示觸須的范圍,即range × (Q3 - Q1)
width: 箱體的相對寬度,當有多個箱體時,有效。
varwidth: 邏輯值,控制箱體的寬度, 只有圖中有多個箱體時才發揮作用,默認為FALSE, 所有箱體的寬度相同,當其值為TRUE時,代表每個箱體的樣本量作為其相對寬度
notch: 邏輯值,如果該參數設置為TRUE,則在箱體兩側會出現凹口。默認為FALSE。
outline: 邏輯值,如果該參數設置為FALSE,則箱線圖中不會繪制離群值。默認為TRUE。
names:繪制在每個箱線圖下方的分組標簽。
plot : 邏輯值,是否繪制箱線圖,如設置為FALSE,則不繪制箱線圖,而給出繪制箱線圖的相關信息,如5個點的信息等。
border:箱線圖的邊框顏色。
col:箱線圖的填充色。
horizontal:邏輯值,指定箱線圖是否水平繪制,默認為FALSE。


4.星相圖
星相圖是雷達圖的多元表現形式,它將各個觀測樣品點表現為一個圖形,n個樣本點就有n個圖形,每個圖形的每個角表示一個變量。?
R stars 星圖(蜘蛛圖/雷達圖)和線段圖 - 純凈天空 (vimsky.com)
stars(X,full=F,key.loc=c(13,1.5))stars(x, full = TRUE, scale = TRUE, radius = TRUE,labels = dimnames(x)[[1]], locations = NULL,nrow = NULL, ncol = NULL, len = 1,key.loc = NULL, key.labels = dimnames(x)[[2]],key.xpd = TRUE,xlim = NULL, ylim = NULL, flip.labels = NULL,draw.segments = FALSE,col.segments = 1:n.seg, col.stars = NA, col.lines = NA,axes = FALSE, frame.plot = axes,main = NULL, sub = NULL, xlab = "", ylab = "",cex = 0.8, lwd = 0.25, lty = par("lty"), xpd = FALSE,mar = pmin(par("mar"),1.1+ c(2*axes+ (xlab != ""),2*axes+ (ylab != ""), 1, 0)),add = FALSE, plot = TRUE, ...)
x數據的矩陣或 DataFrame 。將為?
x?的每一行生成一個星形圖或線段圖。允許缺失值 (?NA?),但它們被視為 0(縮放后,如果相關的話)。full邏輯標志:如果
TRUE,線段圖將占據一整圈。否則,它們僅占據(上)半圓。scale邏輯標志:如果?
TRUE?,則數據矩陣的列獨立縮放,以便每列中的最大值為 1,最小值為 0。如果?FALSE?,則假設數據已被其他某個縮放算法范圍??。radius邏輯標志:在
TRUE中,將繪制數據中每個變量對應的半徑。labels用于標記圖的字符串向量。與 S 函數?
stars?不同,如果?labels = NULL?則不會嘗試構造標簽。locations具有用于放置每個線段圖的 x 和 y 坐標的兩列矩陣;或長度為 2 的數字,此時所有圖都應疊加(對于“蜘蛛圖”)。默認情況下,?
locations = NULL?,線段圖將放置在矩形網格中。nrow, ncol給出當?
locations?為?NULL?時要使用的行數和列數的整數。默認情況下,?nrow == ncol?,將使用方形布局。len半徑或線段長度的比例因子。
key.loc帶有單位鍵的 x 和 y 坐標的向量。
key.labels用于標記單位鍵段的字符串向量。如果省略,則使用?
dimnames(x)?的第二個組件(如果可用)。key.xpd單位鍵的剪輯開關(繪圖和標簽),請參閱
par("xpd")。xlim具有要繪制的 x 坐標范圍的向量。
ylim具有要繪制的 y 坐標范圍的向量。
flip.labels邏輯指示標簽位置是否應在圖表之間上下翻轉。默認為有點智能的啟發式。
draw.segments合乎邏輯的。如
TRUE畫一個線段圖。col.segments顏色向量(整數或字符,請參閱?
par?),每個向量指定其中一個段(變量)的顏色。如果?draw.segments = FALSE?則忽略。col.stars顏色向量(整數或字符,請參閱?
par?),每個向量指定其中一顆星星(案例)的顏色。如果?draw.segments = TRUE?則忽略。col.lines顏色向量(整數或字符,請參閱?
par?),每個向量指定其中一條線(案例)的顏色。如果?draw.segments = TRUE?則忽略。axes邏輯標志:是否將?
TRUE?軸添加到圖中。frame.plot邏輯標志:如果?
TRUE?,則繪圖區域被加框。main情節的主要標題。
sub情節的副標題。
xlabx 軸的標簽。
ylaby 軸的標簽。
cex標簽的字符擴展因子。
lwd用于繪圖的線寬。
lty用于繪圖的線型。
xpd邏輯或 NA 指示是否應進行裁剪,請參閱?
par(xpd = .)?。mar
par(mar = *)?的參數,通常選擇比默認情況更小的邊距。...更多參數,傳遞給?
plot()?的第一次調用,請參見plot.default,如果?frame.plot?為 true,則傳遞給?box()。add邏輯上,如果?
TRUE?將星星添加到當前繪圖中。plot邏輯上,如果?
FALSE?,則不會繪制任何內容。
從該圖中可以看出,北京上海天津浙江廣東五個地區的消費支出較高。另外,有些地區在各項消費指標上的支出比較均勻,比如北京上海,有些地方不夠均勻,如西藏新疆。
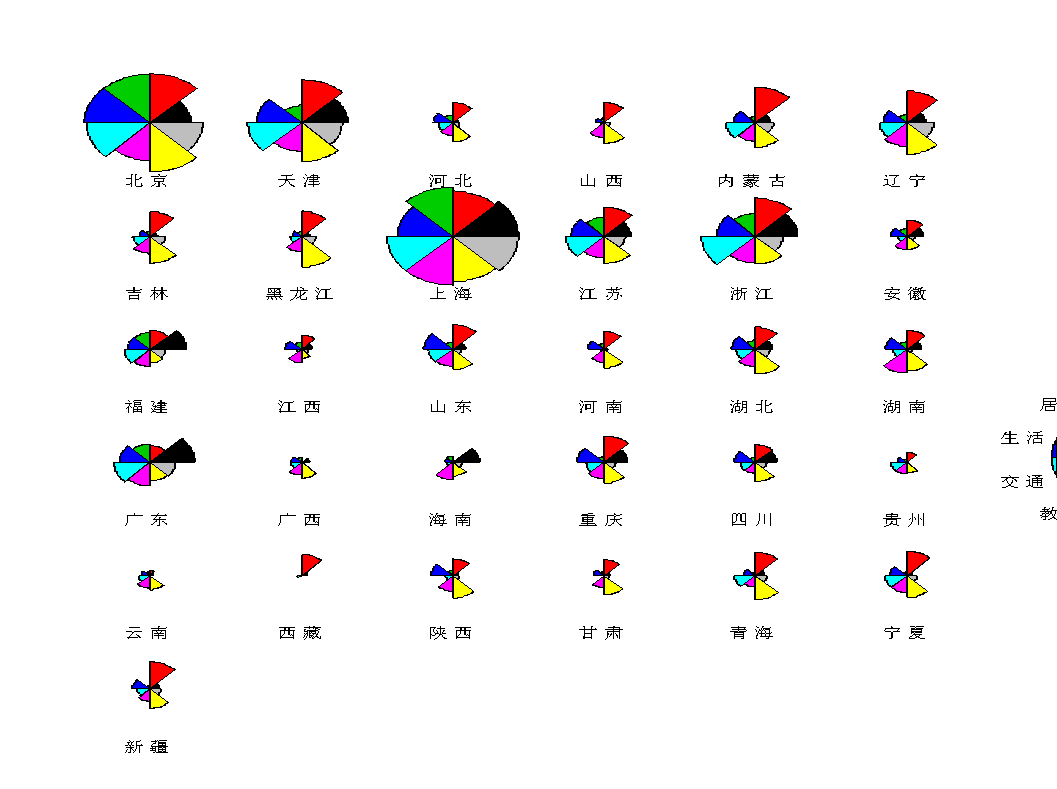
?5.臉譜圖
運用樣本各變量值構造臉的各部位,通過分析臉部位大小或形狀來分析各樣本數據特征。一般來說,較為豐滿、生動的臉譜代表比較理想的樣品數據。
#加載aplpack包
library(aplpack)
#按每行7個做臉譜圖
faces(X,ncol.plot=7)R語言TeachingDemos包 faces函數使用說明 - 愛數吧 (idata8.com)
語法\用法:
faces(xy, which.row, fill = FALSE, nrow, ncol, scale = TRUE, byrow = FALSE, main, labels)
參數說明:xy :?xy數據矩陣,行表示個體,列表示屬性
which.row :?定義輸入矩陣行的排列
fill :?如果(fill==TRUE),則僅轉換面的第一個nc屬性,nc是xy的列數
nrow :?圖形設備上的面列數
ncol :?面行數
scale :?如果(scale==TRUE),屬性將被規格化
byrow :?如果(byrow==TRUE),則xy將被轉置
main :?標題
labels :?用作面名稱的字符串?
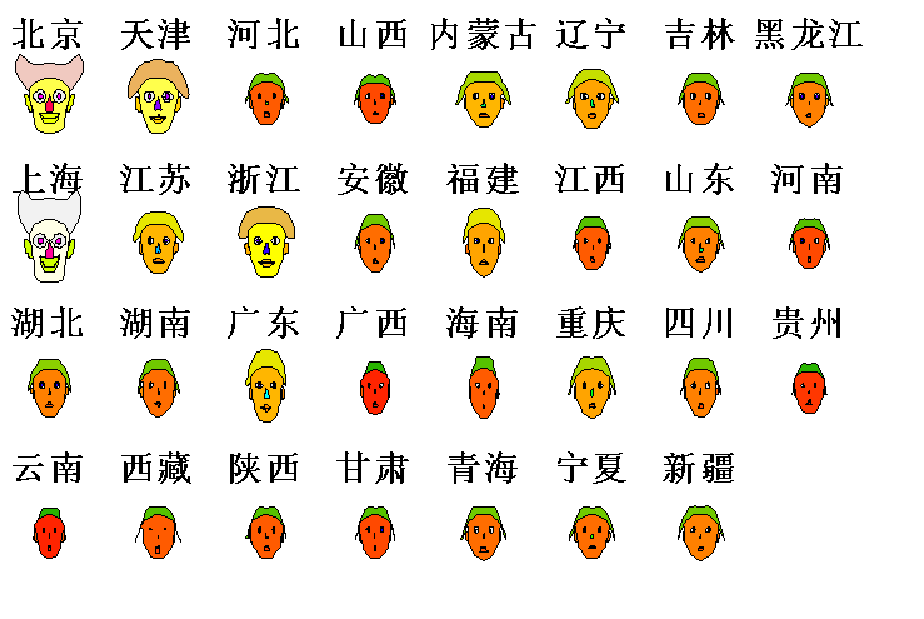
6.調和曲線圖
調和曲線圖是一種利用三角多項式進行作圖的方法,其思想是把高維空間中的一個樣品點對應于二維平面上的一條曲線。這種圖形有利于對樣品進行直觀分類,同類樣品的曲線之間比較靠近,而不同類樣品的曲線之間界限分明,非常直觀。?
#加載mvstats包
library(mvstats)
plot.andrews(X)####也可以直接從鏡像站加載andrews包繪制調和曲線圖
library(andrews)
andrews(X,type=3,clr=5,ymax=3)
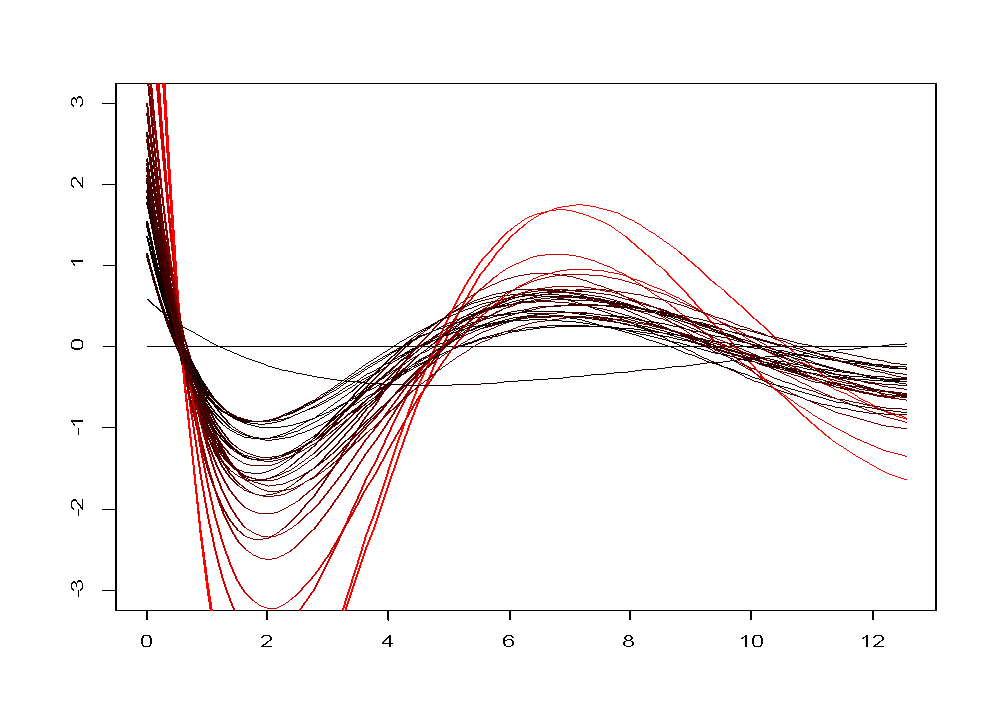
)



的革新應用)

--學習JavaEE的day14)
![[Unity3d] 網絡開發基礎【個人復習筆記/有不足之處歡迎斧正/侵刪】](http://pic.xiahunao.cn/[Unity3d] 網絡開發基礎【個人復習筆記/有不足之處歡迎斧正/侵刪】)





動態路由實現左側菜單導航)





)