過擬合
- 即模型在訓練集上表現的很好,但是在測試集上效果卻很差。也就是說,在已知的數據集合中非常好,再添加一些新數據進來效果就會差很多
欠擬合
- 即模型在訓練集上表現的效果差,沒有充分利用數據,預測準確率很低,擬合結果嚴重不符合預期
dropout層
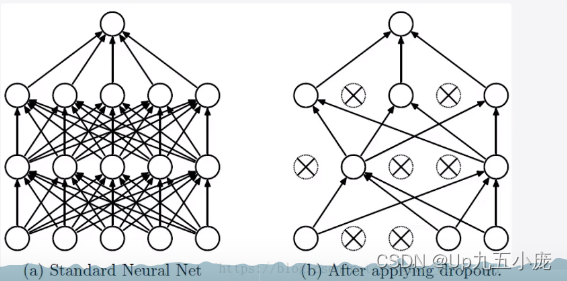
為什么說Dropout可以解決過擬合
- 取平均的作用
先回到標準的模型即沒有dropout,我們用相同的訓練數據去訓練5個不同的神經網絡,一般會得到5個不同的結果,此時我們可以采取“5個結果取均值”或者“多數取勝的投票策略”去決定最終結果。 - 減少神經元之間復雜的共適應關系
因為dropout程序導致兩個神經元不一定每次都在一個dropout網絡中出現。這樣權值的更新不再依賴于有固定關系的隱含節點的共同作用,阻止了某些特征僅僅在其他特征下才有效果的情況。 - dropout類似于性別在生物進化中的角色
物種為了生存往往會傾向于適用這種環境,環境突變則會導致物種難以做出及時的反應,性別的出現可以繁衍出適用新環境的變種,有效的阻止過擬合,即避免環境改變時物種可能面臨的滅絕
參數選擇原則
- 理想的模型剛好在欠擬合和過擬合的界線上,也就是正好擬合數據。
首先開發一個過擬合的模型
- 添加更多的層
- 讓每一層變得更大
- 訓練更多的輪次
然后抑制過擬合
- dropout
- 正則化
- 圖像增強
- 增大訓練數據是抑制過擬合的最好辦法,在沒有數據的前提下,上面三種方法可以來抑制過擬合
再次調節超參數
- 學習速率
- 隱藏單層神經元數
- 訓練輪次
- 超參數的選擇是一個經驗與不斷測試的結果。經典機器學習的方法,如特征工程,增加訓練數據也要做
- 交叉驗證
構建網絡的總原則
- 總的原則是:保證神經網絡容量組個擬合數據
- 增大網絡容量,直到過擬合
- 采取措施抑制過擬合
- 繼續增大網絡容量,直到過擬合
(一))


——選擇角色菜單——順利收到服務器的數據)
)



)





項目引入Element-UI)
(25))



