文章目錄
- 1 :peach:初識 ProtoBuf:peach:
- 1.1 :apple:序列化概念:apple:
- 1.2 :apple:ProtoBuf 是什么:apple:
- 1.3 :apple:ProtoBuf 的使用特點:apple:
- 2 :peach:創建 .proto ?件:peach:
- 3 :peach:編譯 .proto 文件:peach:
- 3 :peach:序列化與反序列化的使用:peach:
1 🍑初識 ProtoBuf🍑
1.1 🍎序列化概念🍎
序列化和反序列化
- 序列化:把對象轉換為字節序列的過程稱為對象的序列化。
- 反序列化:把字節序列恢復為對象的過程稱為對象的反序列化。
什么情況下需要序列化
- 存儲數據:當你想把的內存中的對象狀態保存到?個?件中或者存到數據庫中進行持久化時。
- ?絡傳輸:?絡直接傳輸數據,但是?法直接傳輸對象,所以要在傳輸前序列化,傳輸完成后反序列化成對象。例如我們之前學習過 socket 編程中發送與接收數據。
如何實現序列化
常見的有xml、yml、json、 protobuf
1.2 🍎ProtoBuf 是什么🍎
我們先來看看官?給出的答案是什么?
- Protocol Buffers 是 Google 的?種語??關、平臺?關、可擴展的序列化結構數據的?法,它可?于(數據)通信協議、數據存儲等。
- Protocol Buffers 類?于 XML,是?種靈活,?效,?動化機制的結構數據序列化?法,但是?XML 更?、更快、更為簡單。
- 你可以定義數據的結構,然后使?特殊?成的源代碼輕松的在各種數據流中使?各種語?進?編寫和讀取結構數據。你甚?可以更新數據結構,?不破壞由舊數據結構編譯的已部署程序。
簡單來講, ProtoBuf(全稱為 Protocol Buffer)是讓結構數據序列化的?法,其具有以下特點:
- 語??關、平臺?關:即 ProtoBuf ?持 Java、C++、Python 等多種語?,?持多個平臺。
- ?效:即? XML 更?、更快、更為簡單。
- 擴展性、兼容性好:你可以更新數據結構,?不影響和破壞原有的舊程序。
1.3 🍎ProtoBuf 的使用特點🍎
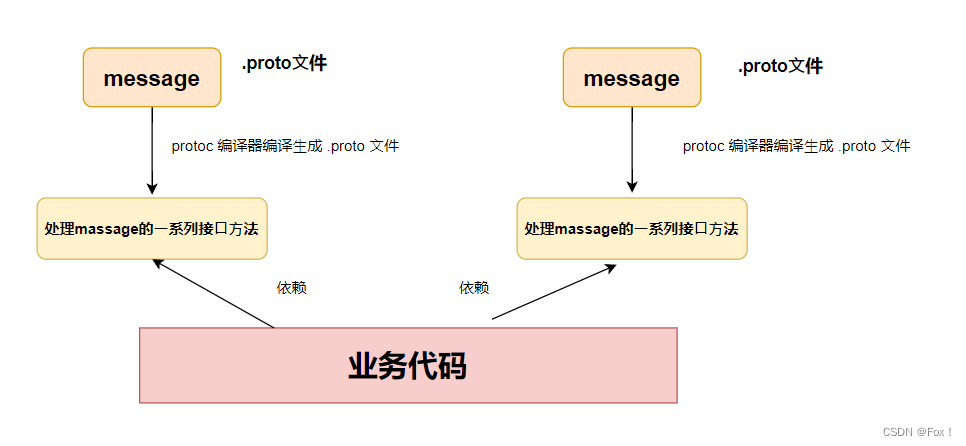
- 編寫
.proto?件,?的是為了定義結構對象(message)及屬性內容。 - 使? protoc 編譯器編譯
.proto?件,?成?系列接?代碼,存放在新?成頭?件和源?件中。 - 依賴?成的接?,將編譯?成的頭?件包含進我們的代碼中,實現對
.proto?件中定義的字段進?設置和獲取,和對message對象進?序列化和反序列化。
總的來說:ProtoBuf 是需要依賴通過編譯?成的頭?件和源?件來使?的。
2 🍑創建 .proto ?件🍑
?件規范
- 創建
.proto?件時,?件命名應該使?全?寫字?命名,多個字?之間? _ 連接。比如:lower_snake_case.proto - 書寫
.proto?件代碼時,應使? 2 個空格的縮進。
指定 proto3 語法
Protocol Buffers 語?版本3,簡稱 proto3,是 .proto ?件最新的語法版本。proto3 簡化了 ProtocolBuffers 語?,既易于使?,?可以在更?泛的編程語?中使?。它允許你使? Java,C++,Python等多種語??成 protocol buffer 代碼。
在 .proto ?件中,要使? syntax = "proto3"; 來指定?件語法為 proto3,并且必須寫在除去注釋內容的第??。 如果沒有指定,編譯器會使?proto2語法。
package 聲明符
package 是?個可選的聲明符,能表? .proto ?件的命名空間,在項?中要有唯?性。它的作?是為了避免我們定義的消息出現沖突。(類似于C++中的namespace)
比如我們就可以像這么寫:
syntax = "proto3";
package contacts;
定義消息(message)
消息(message): 要定義的結構化對象,我們可以給這個結構化對象中定義其對應的屬性內容。
這?再提?下為什么要定義消息?在?絡傳輸中,我們需要為傳輸雙?定制協議。定制協議說?了就是定義結構體或者結構化數據,?如,tcp,udp 報?就是結構化的。再?如將數據持久化存儲到數據庫時,會將?系列元數據統??對象組織起來,再進?存儲。
消息類型命名規范:使?駝峰命名法,?字??寫。
定義消息字段
在 message 中我們可以定義其屬性字段,字段定義格式為:字段類型 字段名 = 字段唯?編號;
- 字段名稱命名規范:全小寫字?,多個字?之間?
_連接。 - 字段類型分為:標量數據類型 和 特殊類型(包括枚舉、其他消息類型等)。
- 字段唯?編號:?來標識字段,?旦開始使?就不能夠再改變。
該表格展?了定義于消息體中的標量數據類型,以及編譯 .proto ?件之后?動?成的類中與之對應的字段類型。在這?展?了與 C++ 語?對應的類型:
| .proto Type | Notes | C++ Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使?變?編碼[1]。負數的編碼效率較低?若字段可能為負值,應使? sint32 代替 | int32 |
| int64 | 使?變?編碼[1]。負數的編碼效率較低?若字段可能為負值,應使? sint34 代替 | int64 |
| uint32 | 使?變?編碼[1]。 | uint32 |
| uint64 | 使?變?編碼[1]。 | uint64 |
| sint32 | 使?變?編碼[1]。符號整型。負值的編碼效率?于常規的 int32 類型 | int32 |
| sin64 | 使?變?編碼[1]。符號整型。負值的編碼效率?于常規的 int64 類型 | int64 |
| fixed32 | 定? 4 字節。若值常?于228 則會? uint32 更?效 | uint32 |
| fixed64 | 定? 8 字節。若值常?于228 則會? uint32 更?效 | uint64 |
| sfixed32 | 定? 4 字節 | int32 |
| sfixed64 | 定? 8 字節 | int64 |
| bool | bool | |
| string | 包含 UTF-8 和 ASCII 編碼的字符串,?度不能超過232 | string |
| bytes | 可包含任意的字節序列但?度不能超過 232 | string |
[1] 變?編碼是指:經過protobuf 編碼后,原本4字節或8字節的數可能會被變為其他字節數。
此時我們就可以這樣寫:
syntax = "proto3";
package contacts;
message PeopleInfo
{string name = 1; int32 age = 2;
}
在這?還要特別講解?下字段唯?編號
1 ~ 536,870,911 (229 - 1) ,其中 19000 ~ 19999 不可?。
9000 ~ 19999 不可?是因為:在 Protobuf 協議的實現中,對這些數進?了預留。如果?要在.proto?件中使?這些預留標識號,例如將 name 字段的編號設置為19000,編譯時就會報警。
值得?提的是,范圍為 1 ~ 15 的字段編號需要?個字節進?編碼, 16 ~ 2047 內的數字需要兩個字節進?編碼。編碼后的字節不僅只包含了編號,還包含了字段類型。所以 1 ~ 15 要?來標記出現?常頻繁的字段,要為將來有可能添加的、頻繁出現的字段預留?些出來。
3 🍑編譯 .proto 文件🍑
編譯命令?格式為:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.protoprotoc是 Protocol Buffer 提供的命令?編譯?具。--proto_path指定 被編譯的.proto?件所在?錄,可多次指定。可簡寫成-I,IMPORT_PATH如不指定該參數,則在當前目錄進行搜索。當某個.proto ?件import其他.proto ?件時,或需要編譯的.proto?件不在當前?錄下,這時就要?-I來指定搜索?錄。--cpp_out=指編譯后的?件為 C++ ?件。.表示當前路徑。OUT_DIR編譯后?成?件的?標路徑。path/to/file.proto要編譯的.proto?件。
當我們編譯成功后就會生成兩個文件,一個頭文件,一個源文件:

對于編譯?成的 C++ 代碼:
- 對于每個 message ,都會?成?個對應的消息類。
- 在消息類中,編譯器為每個字段提供了獲取和設置?法,以及?下其他能夠操作字段的?法。
- 編輯器會針對于每個
.proto?件?成.h和.cc?件,分別?來存放類的聲明與類的實現。
我們在VSCode下觀察 .h文件: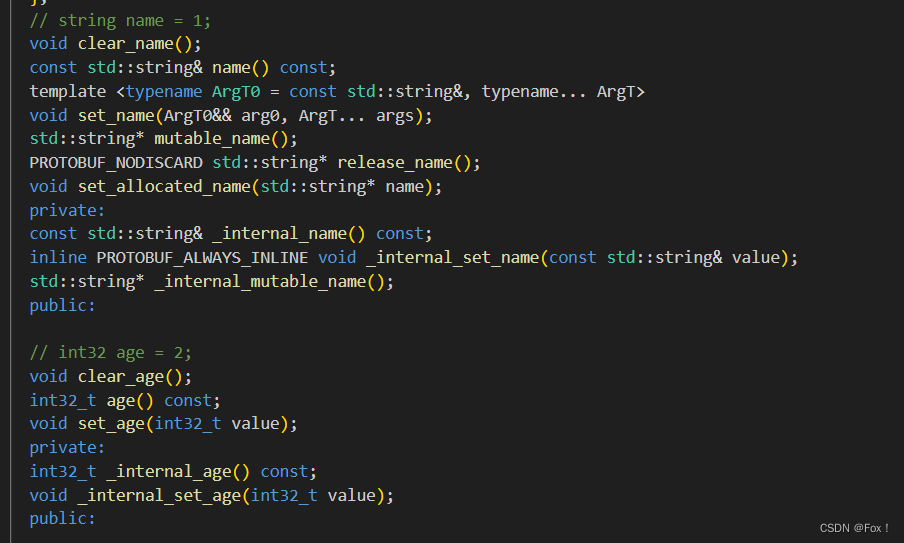 提示:有時候在查看時會出現大量飄紅現象,這是由于插件的原因,本身是沒有錯誤的。
提示:有時候在查看時會出現大量飄紅現象,這是由于插件的原因,本身是沒有錯誤的。
- 每個字段都有設置和獲取的?法,
get的名稱與?寫字段完全相同,set?法以set_開頭。 - 每個字段都有?個
clear_?法,可以將字段重新設置回 empty 狀態。
除此之外包括序列化?法和反序列化?法,這里列舉小部分供參考:
class MessageLite
{
public://序列化:bool SerializeToOstream(ostream* output) const; // 將序列化后數據寫??件流bool SerializeToArray(void *data, int size) const;bool SerializeToString(string* output) const;//反序列化:bool ParseFromIstream(istream* input); // 從流中讀取數據,再進?反序列化動作bool ParseFromArray(const void* data, int size);bool ParseFromString(const string& data);
};
注意:
- 序列化的結果為?進制字節序列,???本格式。
- 以上三種序列化的?法沒有本質上的區別,只是序列化后輸出的格式不同,可以供不同的應?場景使?。
- 序列化的 API 函數均為const成員函數,因為序列化不會改變類對象的內容, ?是將序列化的結果保存到函數?參指定的地址中。
查看更加詳細的API點擊這里:【API】
3 🍑序列化與反序列化的使用🍑
創建?個測試?件 main.cc,?法中我們實現:
- 對?個聯系?的信息使? PB 進?序列化,并將結果打印出來。
- 對序列化后的內容使? PB 進?反序列,解析出聯系?信息并打印出來。
參考代碼:
#include <iostream>
#include "contacts.pb.h" // 引?編譯?成的頭?件
using namespace std;int main()
{string people_str;{contacts::PeopleInfo people;people.set_age(21);people.set_name("蝦頭男");// 調?序列化?法,將序列化后的?進制序列存?string中if (!people.SerializeToString(&people_str)){cout << "序列化聯系?失敗." << endl;}// 打印序列化結果cout << "序列化后的 people_str: " << people_str << endl;}{contacts::PeopleInfo people;// 調?反序列化?法,讀取string中存放的?進制序列,并反序列化出對象if (!people.ParseFromString(people_str)){cout << "反序列化出聯系?失敗." << endl;}// 打印結果cout << "Parse age: " << people.age() << endl;cout << "Parse name: " << people.name() << endl;}
}
makefile:
test:main.ccg++ -o $@ $^ contacts.pb.cc -std=c++11 -lprotobuf
.PHONY:clean
clean:rm -r test
執行:

我們發現報了一個錯誤,原因是系統找不到共享庫,我們執行下面命令即可:
sudo vim /etc/ld.so.conf
#添加以下路徑
/usr/local/lib
修改/etc/ld.so.conf需要root權限。
然后執行:
sudo ldconfig
我們重新編譯生成:
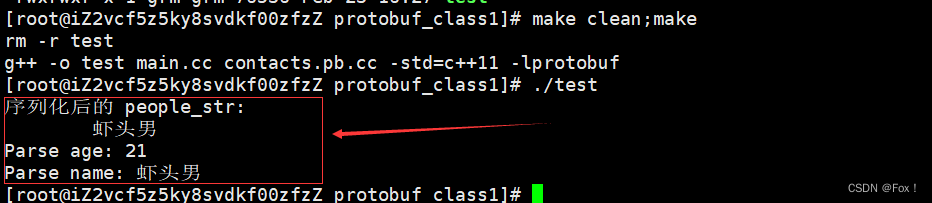
發現符合預期結果。由于序列化的結果是二進制,所以有些內容沒有打印出來亂碼很正常。
所以相對于 xml 和 JSON 來說,因為被編碼成?進制,破解成本增?,ProtoBuf 編碼是相對安全的。

網絡優化與超參數選擇--九五小龐)
![LeetCode 刷題 [C++] 第45題.跳躍游戲 II](http://pic.xiahunao.cn/LeetCode 刷題 [C++] 第45題.跳躍游戲 II)
)















