C++ --- priority_queue
- 前言
- 一、priority_queue的使用
- 二、priority_queue的簡單實現
- 1.整體結構
- 2.主要方法
- push
- pop
- top
- empty
- size
- 三、構造
- 迭代器區間構造
- 默認構造
- 四、仿函數
前言
priority_queue是C++容器之一,意為優先級隊列,雖說叫做隊列,但是其底層結構是堆,唯一和隊列有關是使用此容器時包含的標準頭文件是queue,通過此容器的學習,會學習到一個新的知識,仿函數。
一、priority_queue的使用
priority_queue的接口和stack與queue的基本一樣,主要是push,pop,top,empty,size這些接口,只是底層的結構不同。
需要注意的是底層默認創建大堆結構,需要變成創建小堆結構,這里需要使用新的知識,仿函數,仿函數的詳細介紹留在簡單實現板塊;還有同樣因為數據有特殊的順序,所以底層不支持迭代器遍歷。
// 在這里仿函數是第三個模板參數,控制的是創建堆的結構
// greater --- 更大的
// less --- 更小的
// 不過標準庫里的是less控制大堆,greater控制小堆,是反過來的,這一點需要注意一下
// 標準庫提供的接口和前面的stack,queue相似,主要就是push,pop,top,size,empty這幾個
// 使用起來也是差不多的,同樣因為數據有特殊的順序,所以底層不支持迭代器遍歷
// 盡管堆的底層是數組,但是底層沒有實[]的重載。// 創建一個堆的對象
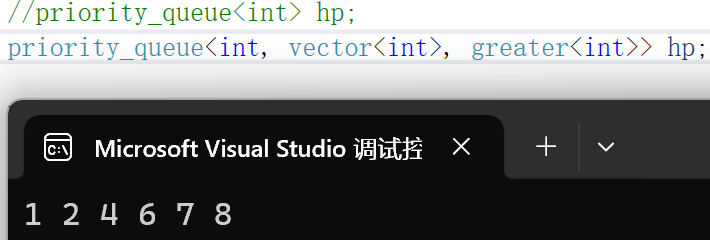
//priority_queue<int> hp;
priority_queue<int, vector<int>, greater<int>> hp;hp.push(4);
hp.push(2);
hp.push(6);
hp.push(7);
hp.push(1);
hp.push(8);// 循環取堆頂元素打印
while (!hp.empty())
{cout << hp.top() << " ";hp.pop();
}
cout << endl;
打印結果:
此時仿函數是greater,創建的是小堆,循環取堆頂元素則是升序排列。
二、priority_queue的簡單實現
1.整體結構
priority_queue的底層是一個堆結構,并且堆結構是由數組實現的完全二叉樹,所以這里直接使用容器適配器,默認適配vector,來作為priority_queue的結構。
template<class T, class Container = vector<T>>
class priority_queue
{
public://………………// 各種方法
private:Container _con;
};
2.主要方法
priority_queue的主要接口就是push,pop,top,empty,size。
push
由于堆結構本身就有性質,要么是大堆,要么就是小堆,所以這里在堆尾插入完數據后需要調整數據的位置,以滿足堆的結構。
// 在堆尾入數據
void push(const T& x)
{// 插入數據_con.push_back(x);// 向上調整算法Adjust_up(size() - 1);}// 向上調整算法
void Adjust_up(size_t child)
{// 已知孩子節點求雙親節點size_t parent = (child - 1) / 2;// 最壞的情況child調整至根節點才結束while (child > 0){// 大堆,誰大誰向上調整// 小堆,誰小誰向上調整if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
在向上調整算法中,參數接收的是孩子節點的下標,根據二叉樹的性質可知雙親節點的下標 = (孩子節點 - 1)/ 2,求出雙親節點的下標后比較它們兩個的大小,孩子節點大(大堆)/ 小(小堆)于雙親節點,則進行交換,隨后更新child和parent的位置,指向下一棵子樹,若插入后滿足所需要的堆結構,則直接跳出循環,最壞的情況下child調整至根節點才結束,所以這里的循環結束條件是child <= 0。
pop
由于堆底層是數組,并且堆的pop操作是在堆頂進行的,所以相當于進行頭刪操作,這樣效率較低,首先先將堆頂數據和堆尾數據進行交換,這樣一來需要刪除的數據就在堆尾,而數組刪除最后一個數據效率很高,直接將其刪除掉即可,然后調整堆結構即可,這里使用向下調整算法。
// 在堆頂出數據
void pop()
{// 刪除堆頂元素,先將堆頂和堆尾元素交換,再刪除swap(_con[0], _con[_con.size() - 1]);_con.pop_back();// 向下調整算法Adjust_down(0);
}// 向下調整算法
void Adjust_down(size_t parent)
{// 已知雙親節點求左孩子節點,右孩子節點即左孩子 + 1size_t child = parent * 2 + 1;// 最壞的情況是根節點調整到葉子節點while (child < size()){// 首先右孩子得存在合法// 如果右孩子大于/小于左孩子,則child走到大/小的一方if (child+1 < size() && _con[child + 1] < _con[child]){++child;}// 大堆,誰大誰向上調整// 小堆,誰小誰向上調整if (_con[child] < _con[parent]){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
在向下調整算法中,參數接收的是根節點的下標,根據二叉樹的性質可知左孩子節點 = 雙親節點 * 2 + 1,右孩子則是左孩子 + 1;在此算法中額外多出一步是比較左右孩子的大小關系,當堆結構為大堆時,child走到大的那一個孩子處,同理當堆結構為小堆時,child走到小的那一個孩子處(這一步要注意右孩子的下標需要存在合法),之后就和向上調整算法里的一樣,孩子節點和雙親結點比較,誰大 / 小 就進行交換,隨后更新child和parent的位置,走到下一棵子樹的位置繼續進行調整,若滿足所需要的堆結構,則直接跳出循環,最壞的情況是根節點調整到葉子節點才結束,所以這里的循環結束條件是child >= 堆的szie。
top
此接口和下面的兩個接口都直接使用適配即可。
// 取堆頂元素
const T& top() const
{return _con[0];
}
empty
// 判空
bool empty()
{return _con.empty();
}
size
// 取有效元素個數
size_t size()
{return _con.size();
}
三、構造
迭代器區間構造
priority_queue支持迭代器區間構造,并且底層實現的是函數模板形式,所以我們也去實現函數模板形式。
// 迭代器區間構造
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last)// 先將此迭代器區間入堆 --- _con是容器,支持直接迭代器區間構造:_con(first,last)
{// 然后就是向下調整建堆 --- 因為此時還不是堆結構for (size_t i = (size() - 1 - 1) / 2; i > 0; i--){Adjust_down(i);}
}
這里初始化列表里直接復用適配器的迭代器區間構造即可,然后雖入了數據,但是此時不是一個堆結構,同樣需要進行調整,這里采用的是向下調整算法,至于為什么不使用向上調整算法,因為向上調整算法的時間復雜度高于向下調整算法,時間復雜度詳情請回顧我的數據結構 — 堆 的這篇博客(link)
在向下調整建堆中,由于是向下調整,雙親節點和孩子節點進行比較向下調整,所以這里的for循環的循環變量 i 也就是雙親節點的下標,并且二叉樹的最后一層節點是葉子節點,所以雙親節點的最后一層是倒數第二層,size() - 1 是最后一個位置的下標(不能保證此位置上有節點,此位置是右孩子),再減一就是左孩子的下標,已知孩子求雙親就是:(size() - 1 - 1) / 2,直至調整至根節點,所以循環結束條件就是i <= 0。
默認構造
由于我們自己寫了一種構造,編譯器就不再生成默認構造了,而默認構造能滿足我們的需求,所以這里強制讓編譯器生成默認構造。
// 由于我們自己寫了一種構造,編譯器就不生成默認構造了
// 所以這里強制讓編譯器生成
priority_queue() = default;
四、仿函數
所謂仿函數,也叫做函數對象,它其實是一個類,其中重載了運算符operator(),使得這個類能夠像函數一樣被調用。
回到堆的代碼中,在向上或者向下調整算法里面,我們控制大堆小堆結構是通過孩子和雙親大小關系來確定的,但是這個關系是固定死的,要么大于,要么小于,這里就可以使用仿函數,不用寫死關系,通過調用仿函數創建的對象去調用運算符(),在此重載內部再去確定比較關系即可。
// 這個就是仿函數 / 函數對象
// 仿函數代替的就是C語言的函數指針
// 簡單來說就是一個類,通過這個類類型創建的對象去模擬函數那樣被調用
template<class T>
struct less
{bool operator()(const T& x, const T& y){return x < y;}
};template<class T>
struct greater
{bool operator()(const T& x, const T& y){return x > y;}
};// 使用仿函數控制大小比較關系
// 需要多增加一個模板參數
template<class T, class Container = vector<T>,class Compare = less<T>>
class priority_queue
回到向上調整算法中,在方法內部通過Compare創建了一個對象com,在孩子和雙親比較的邏輯里替換了之前的固定寫死一方的大小關系,變成通過com對象去調用運算符(),這樣就看起來像是調用了函數,這就是仿函數。
// 向上調整算法
void Adjust_up(size_t child)
{Compare com;size_t parent = (child - 1) / 2;while (child > 0){//if (_con[child] < _con[parent])if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
調用關系如下圖所示:
這里的參數x接收的就是parent,參數y接收的就是child。

同理向下調整算法里parent和child的比較邏輯,child和child+1的比較邏輯也是如此替換。
需要注意的是對于類模板而言使用仿函數時這里傳遞的是類型,而對函數模板而言使用仿函數時傳遞的則是對象。

P129+P130+P131+P132+P133)






)





![[spring-cloud: 服務發現]-源碼解析](http://pic.xiahunao.cn/[spring-cloud: 服務發現]-源碼解析)




