目錄
1. 線程池
模塊一:線程的封裝
模塊二:線程池的封裝
模塊三:互斥量的封裝 (RAII風格)
模塊四:任務的封裝?
模塊五:日志的封裝
模塊六:時間的封裝
模塊六:主函數
模塊七: Makefile
2. 設計模式
?3. STL, 智能指針和線程安全
3.1. STL是否是線程安全的?
?3.2.?智能指針是否是線程安全的?
4. 其它常見的鎖
4.1. 自旋 && 自旋鎖 --- spin lock
4.2.?自旋鎖的接口介紹:
初始化自旋鎖:
銷毀自旋鎖,釋放自旋鎖資源:
加鎖操作:
解鎖操作,釋放自動鎖:
4.3. 自旋鎖的使用
4.2. 讀寫鎖
4.2.1. 讀寫鎖的接口:
1. 線程池
線程池(Thread Pool)是一種用于管理和復用線程的機制,通常用于提高多線程任務處理的效率和性能。在應用程序中創建和銷毀線程是耗費資源的操作,而線程池可以在應用程序啟動時一次性創建一定數量的線程,并將任務分配給這些線程執行,從而減少線程創建和銷毀的開銷。可用線程數量應該取決于可用的并發處理器、處理器內核、內存、網絡sockets等的數量。
線程池的主要組成部分包括:
線程池管理器(Thread Pool Manager):負責創建、銷毀和管理線程池中的線程,以及分配任務給空閑線程執行。
工作隊列(Work Queue):用于存儲待執行的任務,當有線程變為空閑時,從工作隊列中取出任務分配給該線程執行。
線程池中的線程(Worker Threads):預先創建的一定數量的線程,這些線程會從工作隊列中取出任務執行,當任務執行完成后會繼續保持活躍狀態,等待下一個任務的到來。
線程池的優勢在于可以控制線程的數量,避免線程數量過多導致系統資源耗盡,同時也可以減少線程頻繁創建和銷毀的開銷。通過線程池,可以更高效地處理大量的任務,提高系統的性能和響應速度。
線程池的應用場景:
1.、需要大量的線程來完成任務,且完成任務的時間比較短。
在處理類似Web服務器的請求響應場景中,線程池技術非常適用。每個客戶端請求通常只需要短時間的處理,因此可以將請求分配給線程池中的線程來處理,而不需要為每個請求都創建一個新線程。這樣可以有效地利用系統資源,提高系統的并發處理能力和響應速度。
然而,在處理長時間任務的情況下,比如Telnet連接請求,由于任務耗時較長,如果使用線程池,可能會導致線程長時間占用,降低了線程池中其他線程的可用性,甚至可能導致線程池中的線程耗盡而無法響應其他請求。因此,在這種情況下,更好的選擇可能是為每個長時間任務創建一個單獨的線程,以避免影響其他任務的執行。
2、對性能要求苛刻的應用,比如要求服務器迅速響應客戶請求。使用線程池是一種有效的解決方案,能夠提高系統的性能和響應速度,提升用戶體驗。
3、接受突發性的大量請求但又不希望因為創建大量線程而導致系統資源消耗過大。使用多線程技術是非常合適的。在沒有線程池的情況下,當系統接收到突發性大量的客戶請求時,如果為每個請求都創建一個新線程來處理,就會導致系統中線程數量急劇增加,可能會造成系統資源(如內存)的極大消耗,甚至在極端情況下導致系統崩潰。因此可以設置一個線程池來預先創建一定數量的線程,然后在接收到突發性大量請求時,將這些請求分配給線程池中的空閑線程來處理,而不需要每個請求都創建新的線程。這樣可以有效地利用少量線程處理大量請求,避免線程數量過多帶來的資源消耗和系統負擔問題。
模塊一:線程的封裝
thread:
解釋一些功能:
構造: 創建thread線程對象時,需要傳遞 num,用以我們區分線程 (線程編號,例如1、2、3,代表著線程1、線程2、線程3); 同時需要傳遞 func,其作為線程的回調; arg,其作為線程所需要的參數,在未來,我們會將其和線程名組合在一起構成 thread_info對象,一起傳遞給線程。
create: 主要負責創建線程。對 pthread_create 進行封裝,此時,我們可以發現,線程回調函數所傳入的參數是thread_info,其包含 arg + 線程名。
thread_info:
作用的核心就是:將線程所需要的參數 (arg) 和 相應的線程名組裝在一起。
Thread.hpp 代碼如下:
#ifndef __THREAD_HPP_
#define __THREAD_HPP_#include <iostream>
#include <pthread.h>
#include <string>
#include "Log.hpp"const int BUFFER_SIZE = 64;typedef void*(*Tfunc_t)(void*);namespace Xq
{class thread_info{public:thread_info(const std::string& name = std::string (), void* arg = nullptr):_name(name),_arg(arg){}void set_info(const std::string& name, void* arg){_name = name;_arg = arg;}std::string& get_name(){return _name;}void*& get_arg(){return _arg;}private:std::string _name;void* _arg;};class thread{public:thread(size_t num, Tfunc_t func, void* arg):_func(func),_arg(arg){// 構造線程名char buffer[BUFFER_SIZE] = {0};snprintf(buffer, BUFFER_SIZE, "%s %ld", "thread", num);_name = buffer;// 設置線程所需要的信息, 線程名 + _arg_all_info.set_info(_name, _arg);}// 創建線程void create(void){pthread_create(&_tid, nullptr, _func, static_cast<void*>(&_all_info));//std::cout << "創建線程: " << _name << " success" << std::endl;LogMessage(NORMAL, "%s: %s %s", "創建線程", _name.c_str(), "success");}pthread_t get_tid(){return _tid;}private:std::string _name; // 線程名Tfunc_t _func; // 線程的回調pthread_t _tid; //線程IDthread_info _all_info; // 裝載的是 線程名 + _arg;// 線程參數, 未來我們會將其和線程名封裝到一起(thread_info),整體傳遞給線程void* _arg; };
}#endif模塊二:線程池的封裝
作為一個線程池,自然需要一批線程。
構造: 我們需要線程數目、構造線程對象 ( (此時只是構造了我們封裝的線程對象、并沒有啟動線程) ),并將其導入線程表中。 初始化我們的鎖以及條件變量。
析構: 釋放我們創建的線程對象。 并銷毀鎖以及條件變量。
線程池的四個主要接口:
run_all_thread:調動線程池中的所有線程。 通過封裝線程類的 create;
push_task:將任務push到我們的任務表中, 調用該任務的線程角色:生產者。
routine: 線程的回調 ,消費任務,調用該任務的線程角色:消費者。
join: 等待線程池中的每一個線程退出。
ThreadPool.hpp 代碼如下:?
#ifndef __THREADPOOL_HPP_
#define __THREADPOOL_HPP_#include <iostream>
#include <vector>
#include <queue>
#include <ctime>
#include "Thread.hpp"
#include "LockGuard.hpp"
#include "Task.hpp"
#include "Log.hpp"
#include "Date.hpp"
#include <unistd.h>#define TNUM 3namespace Xq
{template<class T>class thread_pool{public:pthread_mutex_t* get_lock(){return &_lock;}bool is_que_empty(){return _task_que.empty();}void wait_cond(void){pthread_cond_wait(&_cond, &_lock);}T get_task(void){T task = _task_que.front();_task_que.pop();return task;}public:// 線程池的構造函數負責實例化線程對象thread_pool(size_t tnum = TNUM):_tnum(tnum){for(size_t i = 0; i < _tnum; ++i){// 這里只是創建了我們封裝的線程對象// 事實上, 在這里,線程并沒有真正被創建//_VPthread.push_back(new thread(i, routine, nullptr));// 為了解決靜態成員函數無法訪問非靜態的成員方法和成員屬性// 因此我們在這里可以傳遞線程池對象的地址,即this指針// 我們在這里是可以傳遞this指針的// 因為走到這里,此時的線程池對象已經存在 (空間已經開辟好了)_VPthread.push_back(new thread(i, routine, this));}pthread_mutex_init(&_lock, nullptr);pthread_cond_init(&_cond, nullptr);}// 啟動所有線程池中的線程void run_all_thread(void){for(const auto& vit : _VPthread){vit->create();}}// 線程的回調/** 首先 routine函數是線程池中的線程的回調函數* 任務是獲取任務表的任務,處理任務(消費過程,消費任務)* 如果routine設計成了類的非靜態成員函數,那么其第一個* 參數就是this指針, 與線程的回調函數類型不匹配。* 因此我們在這里可以將其設置為靜態函數*//** 當我們用static可以解決了上面的問題時(非靜態成員函數的第一個參數是this指針)* 新問題又產生了,由于靜態成員函數沒有隱藏的this指針* 故靜態成員方法無法訪問成員屬性和成員方法* 而我們的routine是用來消費任務表中的任務的* 換言之,它需要訪問線程池中的成員屬性(任務表)* 可是,此時的routine沒有能力訪問,如何解決這個問題?* 我們可以將線程池對象的this指針作為參數傳遞給我們封裝的線程對象* 讓特定線程通過this指針訪問任務表*/static void* routine(void* arg){thread_info* info = static_cast<thread_info*>(arg);// 獲得this指針thread_pool<T>* TP = static_cast<thread_pool<T>*>(info->get_arg());// 通過this指針訪問任務表// 之前說了, 此時的任務表是一個臨界資源// 因此,我們需要保證它的安全性以及訪問合理性問題while(true){T task;{lock_guard lg(TP->get_lock());while(TP->is_que_empty())TP->wait_cond();// 走到這里, 臨界資源一定是就緒的// 即任務表中一定有任務// 獲取任務task = TP->get_task();} // 走到這里, 釋放鎖資源, 執行任務task(info->get_name());} return nullptr;}// 生產任務, 相當于生產者, 我們想讓主線程充當生產者角色// 生產過程本質上是向任務表生產任務// 在未來,當我們在向任務表push任務的時候,// 很有可能出現,(線程池中的) 若干個線程想要從任務表拿任務 (pop),// 因此,該任務表就是一個被多執行流共享的資源 (臨界資源),// 因此我們必須要保障它的安全問題,因此我們就可以用鎖保證它的安全性void push_task(const T& task){lock_guard lg(&_lock); // RAII風格的鎖_task_que.push(task);// 當我們將任務生產到任務表中后// 我們就可以喚醒相應的線程(線程池中的線程)來消費任務pthread_cond_signal(&_cond);}void join(){for(const auto& vit : _VPthread){pthread_join(vit->get_tid(), nullptr);}}~thread_pool(){pthread_mutex_destroy(&_lock);pthread_cond_destroy(&_cond);for(const auto& vit : _VPthread){delete vit;}}private:size_t _tnum; // 線程個數std::vector<thread*> _VPthread; // 線程對象表std::queue<T> _task_que; // 任務表pthread_mutex_t _lock;pthread_cond_t _cond; };
}
#endif模塊三:互斥量的封裝 (RAII風格)
在以前我們就說過,在這里就不再多余解釋了。
LockGuard.hpp 代碼如下:
#ifndef __LOCKGUARD_HPP_
#define __LOCKGUARD_HPP_#include <pthread.h>namespace Xq
{class mutex{public:mutex(pthread_mutex_t* lock):_lock(lock){}void lock(void){pthread_mutex_lock(_lock);}void unlock(void){pthread_mutex_unlock(_lock);}private:pthread_mutex_t* _lock;};class lock_guard{public:lock_guard(pthread_mutex_t* lock):_mtx(lock){_mtx.lock();}~lock_guard(){_mtx.unlock();}private:mutex _mtx;};
}
#endif模塊四:任務的封裝?
沒有特別重要的點,不做多余解釋。
Task.hpp 代碼如下:
#ifndef __TASK_HPP_
#define __TASK_HPP_#include <iostream>
#include <functional>
#include <string>
#include "Log.hpp"namespace Xq
{class Task{public:Task() {}Task(int x, int y, std::function<int(int,int)> func):_x(x),_y(y), _func(func){}void operator()(const std::string& name){//std::cout << name << " 正在執行任務: " << _x << " + " << _y << " = " <<//_func(_x, _y) << std::endl;LogMessage(NORMAL, "%s %s %d + %d = %d", name.c_str(), "正在執行任務", _x, _y, _func(_x,_y)) ;}private:int _x;int _y;std::function<int(int,int)> _func;};
}
#endif模塊五:日志的封裝
va_list 是 C 語言中用于處理可變數量參數的一種機制。其位于 <stdarg.h> 頭文件中。
va_start && va_end 是C語言提供的宏,用于處理可變參數的函數中。
void va_start(va_list ap, last_arg);
void va_end(va_list ap)va_start:該宏用于初始化一個 va_list 類型的變量,以便開始訪問可變數量的參數。其中,ap是一個va_list類型的變量,用于指向參數列表, last_arg 是最后一個固定的參數名。 va_start 宏會將 ap 定位到第一個可變參數的位置。
va_end: va_end 宏用于清理va_list 類型的變量,?在處理完可變參數列表后使用,其主要功能就是,清理 va_list 類型的變量,以確保進程的健壯性和內存管理的正確性。
?當有了上面的理解后,我們在看下面的函數:
#include <stdarg.h>int vprintf(const char *format, va_list ap);
int vfprintf(FILE *stream, const char *format, va_list ap);
int vsprintf(char *str, const char *format, va_list ap);
int vsnprintf(char *str, size_t size, const char *format, va_list ap);上面的這些函數都是用于處理可變參數的函數,我們以vprintf舉例:
其允許將格式化的輸出寫入到標準輸出流中 (顯示器),其接收 va_list 類型的參數列表,當我們在使用前,一般需要用 va_start 初始化這個va_list變量,?確保它指向可變參數列表中的第一個參數。具體來說:
const char* format: 其是一個格式化字符串,用戶可以指定輸出的格式,類似于printf。
va_list ap:通過使用 va_start 宏初始化后,可以在 vprintf 中對可變參數進行訪問和處理。
其他三個函數只不過將格式化輸出的內容寫入了不同的位置:
vfprintf:格式化的輸出寫入到指定的文件中。
vsprintf: 格式化的輸出寫入到字符串中。
vsnprintf: 安全地將格式化的輸出寫入到字符串中,避免溢出的風險,可以限制輸出內容的最大長度,提高進程的健壯性。
示例如下:
void demo(const char* format, ...)
{va_list ap;va_start(ap, format); vprintf(format,ap);va_end(ap);
}int main()
{// 這里用戶可以自定義信息, 與使用printf幾乎一致。demo("%s %f %c %d\n", "haha", 3.14, 'x', 111 );return 0;
}現象如下:?

在這之前,需要說明一下:
日志是需要日志級別的,不同的級別代表著不同的響應方式。
完整的日志功能,至少需要:日志等級、時間、日志內容、支持用戶自定義信息 (用戶還可以傳遞額外的信息 ) 。
Log.hpp 代碼如下:
#pragma once#include "Date.hpp"
#include <iostream>
#include <map>
#include <string>
#include <cstdarg>#define LOG_SIZE 1024// 日志等級
enum Level
{DEBUG, // DEBUG信息NORMAL, // 正常WARNING, // 警告ERROR, // 錯誤FATAL // 致命
};void LogMessage(int level, const char* format, ...)
{
// 如果想打印DUBUG信息, 那么需要定義DUBUG_SHOW (命令行定義, -D)
#ifndef DEBUG_SHOWif(level == DEBUG)return ;
#endifstd::map<int, std::string> level_map;level_map[0] = "DEBUG";level_map[1] = "NORAML";level_map[2] = "WARNING";level_map[3] = "ERROR";level_map[4] = "FATAL";std::string info;va_list ap;va_start(ap, format);char stdbuffer[LOG_SIZE] = {0}; // 標準部分 (日志等級、日期、時間)snprintf(stdbuffer, LOG_SIZE, "%s, %s, %s\n", level_map[level].c_str(), Xq::Date().get_date().c_str(), Xq::Time().get_time().c_str());info += stdbuffer;char logbuffer[LOG_SIZE] = {0}; // 用戶自定義部分vsnprintf(logbuffer, LOG_SIZE, format, ap);info += logbuffer;std::cout << info << std::endl;va_end(ap);
}模塊六:時間的封裝
其核心目的:? 將當前時間戳轉化為當前日期 + 時間。
Date.hpp 代碼如下:
#ifndef __DATE_HPP_
#define __DATE_HPP_#include <iostream>
#include <ctime>namespace Xq
{class Date{public:Date(size_t year = 1970, size_t month = 1, size_t day = 1):_year(year),_month(month),_day(day){}std::string& get_date(){size_t num = get_day();while(num--){operator++();}char buffer[32] = {0};snprintf(buffer, 32, "%ld/%ld/%ld", _year,_month, _day);_data = buffer;return _data;}private:Date& operator++(){size_t cur_month_day = month_day[_month];if((_month == 2) && ((_year % 400 == 0 )|| (_year % 4 == 0 && _year % 100 != 0)))++cur_month_day;++_day;if(_day > cur_month_day){_day = 1;_month++;if(_month > 12){_month = 1;++_year;}}return *this;}// 獲得從1970.1.1 到 今天相差的天數size_t get_day(){return (time(nullptr) + 8 * 3600) / (24 * 60 * 60);}private:size_t _year;size_t _month;size_t _day;static int month_day[13];std::string _data;};int Date::month_day[13] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};class Time{public:Time(size_t hour = 0, size_t min = 0, size_t second = 0):_hour(hour),_min(min),_second(second){}std::string& get_time(){size_t second = time(nullptr) + 8 * 3600;_hour = get_hour(second);_min = get_min(second);_second = get_second(second);char buffer[32] = {0};snprintf(buffer, 32, "%ld:%ld:%ld", _hour, _min, _second);_time = buffer;return _time;}private:size_t get_hour(time_t second){// 不足一天的剩余的秒數size_t verplus_second = second % (24 * 60 * 60);return verplus_second / (60 * 60);}size_t get_min(time_t second){// 不足一小時的秒數size_t verplus_second = second % (24 * 60 * 60) % (60 * 60);return verplus_second / 60;}size_t get_second(time_t second){// 不足一分鐘的秒數return second % (24 * 60 * 60) % (60 * 60) % 60;}private:size_t _hour;size_t _min;size_t _second;std::string _time;};
}#endif模塊六:主函數
主線程負責定義線程池, 調度線程池中的線程, 主線程定義任務,生產任務,將任務推送到線程池對象中的任務表中 (扮演者生產者的角色)。最后,主線程需要等待新線程退出。
TestMain.cc 代碼如下:
#include "ThreadPool.hpp"int main()
{//std::cout << "hello thread pool " << std::endl;srand((unsigned int)time(nullptr) ^ getpid());Xq::thread_pool<Xq::Task>* TP = new Xq::thread_pool<Xq::Task>();TP->run_all_thread();while(true){int x = rand() % 100;int y = rand() % 50;TP->push_task(Xq::Task(x, y, [](int x, int y)->int{return x + y;}));// std::cout << "Main thread: " << "生產任務: " << x << " + " << y << " = " << " ? " << std::endl;LogMessage(NORMAL, "%s%d + %d = ?", "Main thread 生產任務:", x, y);sleep(1);}TP->join();return 0;
}模塊七: Makefile
TP:TestMain.ccg++ -o $@ $^ -std=gnu++11 -l pthread
.PHONY:clean
clean:rm -f TP2. 設計模式
設計模式,我們在C++就已經說明,今天在這里,就不再是什么是設計模式的問題了。
我們以前說過,懶漢方式實現單例模式存在著線程安全問題,可是當初我們無法理解,但現在,我們就可以通過線程池這個實例用以理解了。
因此,我們想要對上面的線程池的封裝加以更改,讓其成為單例模式。
線程池的封裝 (ThreadPool.hpp) 更改后的代碼如下:?
namespace Xq
{template<class T>class thread_pool{public:pthread_mutex_t* get_lock() { // 省略, 跟原來一致 }bool is_que_empty() { // 省略, 跟原來一致 }void wait_cond(void) { // 省略, 跟原來一致 }T get_task(void) { // 省略, 跟原來一致 }private:// 將構造私有化, 用于實現單例// 線程池的構造函數負責實例化線程對象thread_pool(size_t tnum = TNUM) :_tnum(tnum) { // 省略, 跟原來一致 }public:// 因為構造已被私有化,故需要我們顯示提供一個可以獲取該唯一實例的方法static thread_pool<T>* get_ptr_only_thread_pool(int num = TNUM){if(_ptr_only_thread_pool == nullptr){_ptr_only_thread_pool = new thread_pool(num);}return _ptr_only_thread_pool;}// 同時, 我們需要將拷貝構造、賦值都設為私有或者deletethread_pool(const thread_pool& copy) = delete;private:thread_pool& operator=(const thread_pool& copy);public:// 按照我們以前懶漢實現單例的方式, 我們可以內嵌一個垃圾回收類// 回收該唯一實例class resources_recovery{public:~resources_recovery(){if(_ptr_only_thread_pool){delete _ptr_only_thread_pool;_ptr_only_thread_pool = nullptr;}}static resources_recovery _auto_delete_ptr_only_thread_pool;};public:void run_all_thread(void) { // 省略, 跟原來一致 }static void* routine(void* arg) { // 省略, 跟原來一致 }void push_task(const T& task) { // 省略, 跟原來一致 }void join() { // 省略, 跟原來一致 }~thread_pool() { // 省略, 跟原來一致 }private:std::vector<thread*> _VPthread; // 線程對象表size_t _tnum; // 線程個數std::queue<T> _task_que; // 任務表pthread_mutex_t _lock;pthread_cond_t _cond; // 因為構造已被私有化, 故我們需要定義一個靜態對象的指針static thread_pool<T>* _ptr_only_thread_pool;};// 初始化該唯一實例template<class T>thread_pool<T>* thread_pool<T>::_ptr_only_thread_pool = nullptr;// 定義一個靜態成員變量,進程結束時,系統會自動調用它的析構函數從而釋放該單例對象template<class T>typename thread_pool<T>::resources_recovery thread_pool<T>::resources_recovery::_auto_delete_ptr_only_thread_pool;
}主函數 (TestMain.cc) 更改后的代碼如下:
#include "ThreadPool.hpp"int main()
{srand((unsigned int)time(nullptr) ^ getpid());// 通過 get_ptr_only_thread_pool 接口獲得線程池唯一實例對象Xq::thread_pool<Xq::Task>* only_target = Xq::thread_pool<Xq::Task>::get_ptr_only_thread_pool();only_target->run_all_thread();while(true){int x = rand() % 100;int y = rand() % 50;only_target->push_task(Xq::Task(x, y, [](int x, int y)->int{return x + y;}));LogMessage(NORMAL, "%s%d + %d = ?", "Main thread 生產任務:", x, y);sleep(1);}only_target->join();return 0;
}有了上面的代碼,我們就將線程池實現了單例 (懶漢模式)。
如果我們假設一種場景:如果申請單例這個過程也是多線程執行的呢?換言之,多個執行流同時申請這個單例呢?
我們看看申請單例的核心代碼:
static thread_pool<T>* get_ptr_only_thread_pool(int num = TNUM)
{if (_ptr_only_thread_pool == nullptr){_ptr_only_thread_pool = new thread_pool(num);}return _ptr_only_thread_pool;
}我們學到這里了,應該可以理解,執行流在被調度的時候,任何時刻都有可能發生上下文切換。
那么我們假設一種場景:A、B兩個線程同時要申請這個唯一實例,假設A線程先被CPU調度:
- A 線程判斷唯一實例為空,準備創建新實例;
- 此時發生上下文切換,A 線程被掛起,B 線程開始運行,并成功創建了該唯一實例;
- 當再次切換回 A 線程時,A 線程繼續執行,此時 A 線程可能會誤以為唯一實例仍為空,再次嘗試創建新實例,導致違反唯一實例的要求。
這種問題的根源就是:這個唯一實例是一個臨界資源,故我們要保證它的安全性,我們可以通過互斥鎖的串行執行,保證獲取唯一實例的安全性。
因此更改后的代碼如下:
static thread_pool<T>* get_ptr_only_thread_pool(int num = TNUM)
{{// 通過加鎖保證這個唯一實例的安全性lock_guard lock(&_only_target_lock);if (_ptr_only_thread_pool == nullptr){_ptr_only_thread_pool = new thread_pool(num);}}return _ptr_only_thread_pool;
}
當我們上面用互斥量保證了該唯一實例的安全性,即保證了單例模式的安全問題。但是仍舊存在問題。
場景: 假設有很多個線程,都要獲取這個唯一實例對象。
當第一個線程被調度的時候,獲取到鎖,進入臨界區,獲取這個唯一實例,那么此時這個唯一實例就不為空了。
因此當接下來的眾多線程都會做著一樣的工作, 申請釋放鎖,但無法獲得這個唯一實例,甚至由于互斥鎖會導致執行流串行執行,降低了并發能力,從而導致執行效率被降低。
上面的問題雖然不會產生錯誤,但是不太合理。
為了解決這個問題,我們可以使用雙重檢查鎖定(Double-Checked Locking)模式,在保證線程安全的同時盡可能減少鎖的持有時間。這種模式可以在第一次訪問時使用鎖保護,而在后續訪問時避免不必要的加鎖釋放鎖操作。
因此我們更改后的代碼如下:
static thread_pool<T>* get_ptr_only_thread_pool(int num = TNUM)
{// 雙重檢查, 避免不必要的加鎖和釋放鎖if (_ptr_only_thread_pool == nullptr){lock_guard lock(&_only_target_lock);if (_ptr_only_thread_pool == nullptr){_ptr_only_thread_pool = new thread_pool(num);}}return _ptr_only_thread_pool;
}通過這種方式,第一次訪問時會加鎖創建唯一實例,之后的訪問會避免重復加鎖釋放鎖操作,進一步提高了性能。雙重檢查鎖定模式是一種常見的優化手段,可以在保證線程安全的同時提高進程的并發性能。
至此,我們更改后的 ThreadPool.hpp 代碼如下:
namespace Xq
{template<class T>class thread_pool{public:pthread_mutex_t* get_lock() { // 省略, 跟原來一致 }bool is_que_empty() { // 省略, 跟原來一致 }void wait_cond(void) { // 省略, 跟原來一致 }T get_task(void) { // 省略, 跟原來一致 }private:// 將構造私有化, 用于實現單例// 線程池的構造函數負責實例化線程對象thread_pool(size_t tnum = TNUM) :_tnum(tnum) { // 省略, 跟原來一致 }public:// 因為構造已被私有化,故需要我們顯示提供一個可以獲取該唯一實例的方法static thread_pool<T>* get_ptr_only_thread_pool(int num = TNUM){// 雙重檢查鎖定模式if(_ptr_only_thread_pool == nullptr){// 這把鎖保證唯一實例lock_guard lock(&_only_target_lock);if(_ptr_only_thread_pool == nullptr){_ptr_only_thread_pool = new thread_pool(num);}}return _ptr_only_thread_pool;}// 同時, 我們需要將拷貝構造、賦值都設為私有或者deletethread_pool(const thread_pool& copy) = delete;private:thread_pool& operator=(const thread_pool& copy);public:// 按照我們以前懶漢實現單例的方式, 我們可以內嵌一個垃圾回收類// 回收該唯一實例class resources_recovery{public:~resources_recovery(){if(_ptr_only_thread_pool){delete _ptr_only_thread_pool;_ptr_only_thread_pool = nullptr;}}static resources_recovery _auto_delete_ptr_only_thread_pool;};public:void run_all_thread(void) { // 省略, 跟原來一致 }static void* routine(void* arg) { // 省略, 跟原來一致 }void push_task(const T& task) { // 省略, 跟原來一致 }void join() { // 省略, 跟原來一致 }~thread_pool() { // 省略, 跟原來一致 }private:std::vector<thread*> _VPthread; // 線程對象表size_t _tnum; // 線程個數std::queue<T> _task_que; // 任務表pthread_mutex_t _lock;pthread_cond_t _cond; // 因為構造已被私有化, 故我們需要定義一個靜態對象的指針static thread_pool<T>* _ptr_only_thread_pool;// 這把鎖保證獲取唯一實例的安全性static pthread_mutex_t _only_target_lock;};// 初始化該唯一實例template<class T>thread_pool<T>* thread_pool<T>::_ptr_only_thread_pool = nullptr;// 定義一個靜態成員變量,進程結束時,系統會自動調用它的析構函數從而釋放該單例對象template<class T>typename thread_pool<T>::resources_recovery thread_pool<T>::resources_recovery::_auto_delete_ptr_only_thread_pool;// 初始化這把靜態鎖 (保證獲取唯一實例的安全)template<class T>pthread_mutex_t thread_pool<T>::_only_target_lock = PTHREAD_MUTEX_INITIALIZER;
}?3. STL, 智能指針和線程安全
3.1. STL是否是線程安全的?
STL不保證線程安全。 STL的設計初衷就是將性能挖掘到極致,而不是為了解決多線程并發訪問的問題,且一旦涉及到加鎖保證線程安全,會對性能造成巨大的影響。
因此,STL默認不是線程安全的, 如果在多線程場景下使用, 需要調用者自身保證線程安全。
?3.2.?智能指針是否是線程安全的?
對于 unique_ptr, 由于只是在當前代碼塊范圍內生效,因此不涉及線程安全問題。 但有些場景下, 如果 unique_ptr 和其他容器一并使用,可能設計線程安全問題。因此,我們只能說,一般情況下, unique_ptr 不涉及線程安全問題。
對于 shared_ptr, 多個對象共用一個引用計數變量, 所以會存在線程安全問題。 但是標準庫實現的時候考慮到了這一點, 解決方案是: 基于原子操作如 ( CAS,Compare-And-Swap )?的方式來確保引用計數的安全性。
4. 其它常見的鎖
悲觀鎖:在每次取數據時,總是擔心數據會被其他線程修改,所以會在取數據前先加鎖,當其他線程想要訪問數據時,被阻塞掛起。
樂觀鎖:每次取數據時候,總是樂觀的認為數據不會被其他線程修改,因此不上鎖。但是在更新數據前,會判斷其他數據在更新前有沒有對數據進行修改。主要采用兩種方式:版本號機制和CAS操作。
CAS操作:當需要更新數據時,判斷當前內存值和之前取得的值是否相等。如果相等則用新值更新。若不等則失敗,失敗則重試,一般是一個自旋的過程,即不斷重試。
4.1. 自旋 && 自旋鎖 --- spin lock
首先,我們談一下我們以前學過的互斥鎖。
在多線程場景下,多個執行流通過加鎖方式進入臨界區訪問臨界資源,當鎖被某個線程占有的時候,其他線程想要進入臨界區,而由于要進入臨界區,就要先獲得這把鎖,因此,我們以前說過,這些線程會被掛起阻塞,更具體地講就是:這些 task_struct 對象會等待這把鎖資源,同時這些執行流狀態被設置為非R狀態 (掛起等待)。
而為了理解自旋這個概念,我們列出兩個場景:?
場景一:
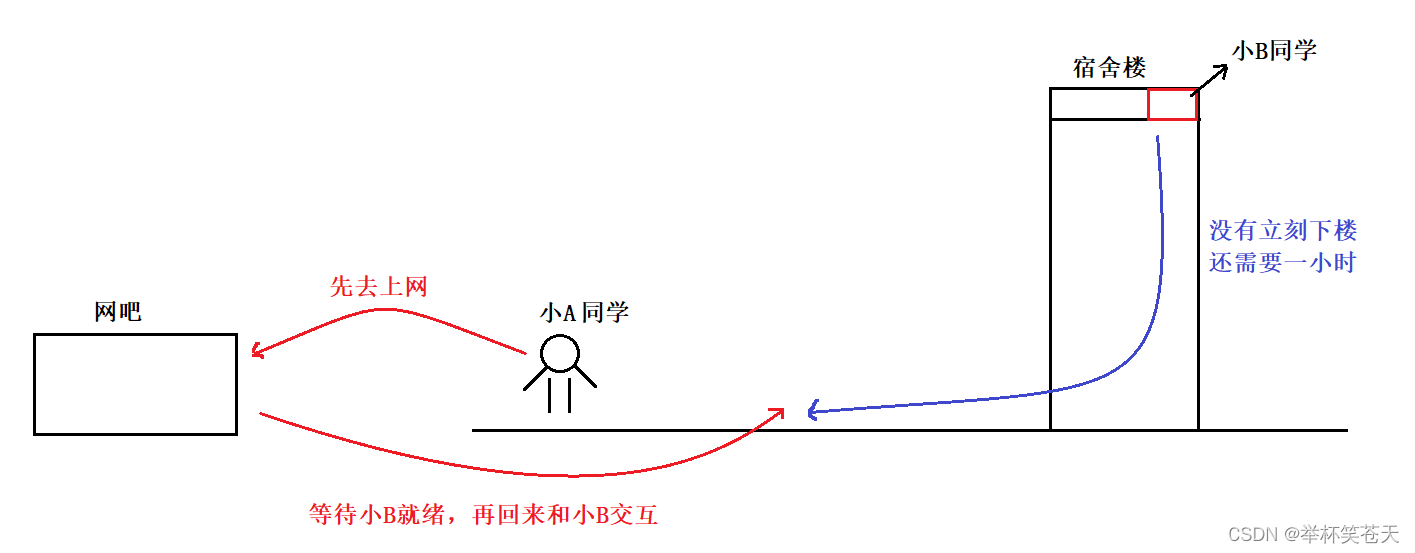
小A和小B是一屆的兩個同學,小B是努力型學霸 (筆記做得特別好,學習成績名列前茅),小A成天曠課,上網打游戲。?
臨界期末考試 (比如考操作系統),小A就急壞了,就來找小B,想要借小B的筆記用一用,用完再還給小B,于是小A就通過電話聯系了小B, 小B一聽, 可以啊,但是我還有一些地方沒有準備好,你能等我一個小時嗎?小A就答應了,正常情況下,小A一聽還有一個小時,自然不會一直在這里干等小B,于是小A就對小B說, 這樣,你不還有一個小時嗎? 我先去上個網,打幾把游戲,你到時間了,叫我一聲,我在過來到宿舍樓下等你,怎么樣? 小B就同意了。
場景二:
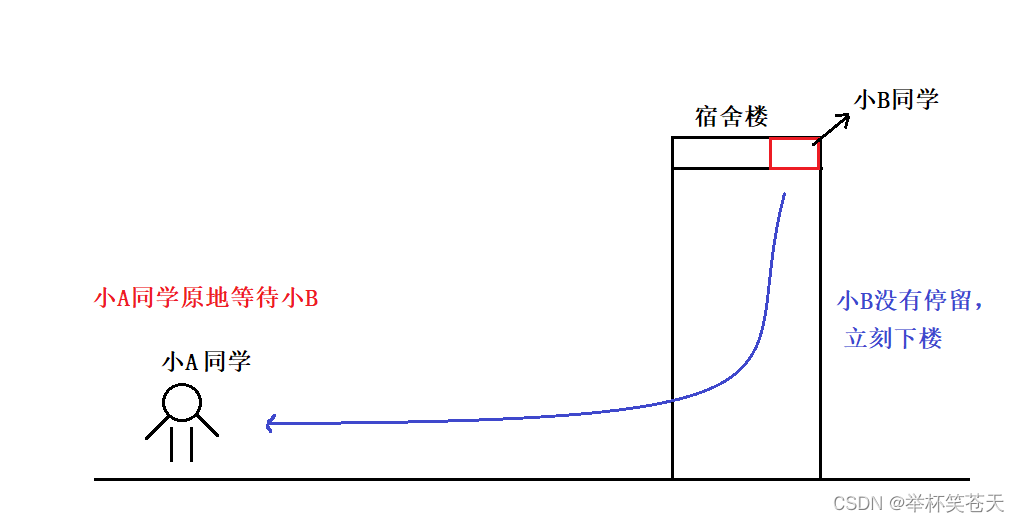
上次的操作系統考試,由于小A借了小B的筆記,啥知識點應有盡有,因此小A考完感覺非常良好,這不,又臨界考試 (計算機網絡)。
小A就又來找小B,問小B能不能借筆記用一用, 小B一聽,就同意了,并且說,我馬上下樓給你。 此時,小A會不會說,那行,我先去上個網,你下樓了叫我一聲,我在過來。 答案是:不可能,如果小A這樣說了,小B一定說小A有病,我馬上都下樓了,你還要去上網,可能你在去的路上我就可能到樓下了,因此,正常情況下,小A只會說,那行,我在你樓下等你。
綜合上面兩種情況,提出一個問題:
是什么決定了小A同學在樓下等待的策略? 是先去上網,再來找小B? 還是在樓下原地等待呢?
答案是: 小B同學 (臨界資源) 就緒的時間。
類比到我們的線程:
當執行流在獲取鎖資源,進入臨界區訪問臨界資源時,如果在臨界區訪問時間長 (臨界資源就緒時間長),那么其他執行流如果要訪問這把鎖,那么應該要掛起等待,就好比上面,先去上一會網,再來訪問這把鎖資源。
當執行流在獲取鎖資源,進入臨界區訪問臨界資源時,如果在臨界區訪問時間短 (臨界資源就緒時間短),那么其他執行流如果要訪問這把鎖,那么就不應該讓這些線程掛起等待。
接著場景二,故事繼續,小B說1分鐘就下樓了,小A就在樓下等他。 可是一分鐘過去了,小A還是沒有看到小B,就有給小B打了個電話,小B說,快了快了。 于是小A繼續等。 一分鐘又過去了,小A又給小B打電話,小B說: 馬上到了。 就這樣重復了好幾次。?
在上面這段例子中,小A為什么不先去上個網呢? 因為小B說他馬上下樓了;?可小A為什么輪詢式的給小B打電話呢? 因為小A要確認小B的狀態。
而上面這種檢測方式我們就稱之為自旋式的檢測臨界資源是否就緒。
自旋鎖:本質就是通過不斷 (輪詢) 檢測鎖狀態來判斷臨界資源是否就緒的方案!
什么時候使用自旋鎖呢??我們可以根據臨界資源就緒的時間來判定。
在并發編程中,當多個線程競爭同一把鎖時。
如果臨界區訪問時間較短,即鎖的占有時間短暫,那么其他線程就可以選擇自旋等待來競爭鎖,避免頻繁地掛起和喚醒線程 (避免線程頻繁地上下文切換),從而提高效率。
而當臨界區訪問時間較長時,其他線程應該及時放棄自旋等待,轉而掛起等待,避免資源浪費和性能下降。
4.2.?自旋鎖的接口介紹:
初始化自旋鎖:
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);pshared參數:
PTHREAD_PROCESS_PRIVATE:?表示自旋鎖是進程私有的,只能被創建它的進程中的線程使用。
PTHREAD_PROCESS_SHARED:表示自旋鎖是可跨進程共享的,可以被同一進程中的不同線程或不同進程中的線程使用。
銷毀自旋鎖,釋放自旋鎖資源:
int pthread_spin_destroy(pthread_spinlock_t *lock);加鎖操作:
int pthread_spin_lock(pthread_spinlock_t *lock);int pthread_spin_trylock(pthread_spinlock_t *lock);pthread_spin_lock:?加鎖操作。如果自旋鎖已被占用,則當前線程將自旋等待直到獲取自旋鎖。
pthread_spin_trylock:嘗試加鎖,如果自旋鎖已被占用,則立即返回失敗,不會進入自旋等待狀態。
返回值: 上面的函數成功返回0,失敗還會錯誤碼。
解鎖操作,釋放自動鎖:
int pthread_spin_unlock(pthread_spinlock_t *lock);4.3. 自旋鎖的使用
在使用自旋鎖時,需要注意的是,自旋鎖適合用于資源占用時間短、競爭情況不頻繁的場景,避免長時間占用 CPU 或者造成 CPU 浪費。另外,要確保在解鎖前先加鎖,以保證線程安全性。
我們就以前我們寫的搶票邏輯來舉例:
#include <iostream>
#include <pthread.h>
#include <unistd.h>#define PTHREAD_NUM 3
#define BUFFER_SIZE 32int ticket = 1000;class PTHREAD_INFO
{
public:PTHREAD_INFO(const std::string& name, pthread_spinlock_t* Plock):_name(name),_Plock(Plock){}
public:std::string _name;pthread_spinlock_t* _Plock;
};void* GetTicket(void* arg)
{PTHREAD_INFO* info = static_cast<PTHREAD_INFO*>(arg);while(true){pthread_spin_lock(info->_Plock);if(ticket > 0){usleep(1000);std::cout << info->_name << " get a ticket " << ticket << std::endl;ticket--;pthread_spin_unlock(info->_Plock);}else{pthread_spin_unlock(info->_Plock);break;}usleep(rand() % 500);}delete info;return nullptr;
}void Test1(void)
{pthread_t tid[PTHREAD_NUM];// 定義局部自旋鎖pthread_spinlock_t myspinlock;// 初始化局部自旋鎖, 且線程間共享pthread_spin_init(&myspinlock, PTHREAD_PROCESS_PRIVATE); char buffer[BUFFER_SIZE] = {0};for(size_t i = 0; i < PTHREAD_NUM; ++i){snprintf(buffer, BUFFER_SIZE, "%s-%ld", "thread", i + 1);PTHREAD_INFO* info = new PTHREAD_INFO(buffer, &myspinlock);pthread_create(tid + i, nullptr, GetTicket, static_cast<void*>(info));}for(size_t i = 0; i < PTHREAD_NUM; ++i){pthread_join(tid[i], nullptr);}// 局部自旋鎖需要我們手動釋放pthread_spin_destroy(&myspinlock);
}int main()
{srand((size_t)time(nullptr));Test1();return 0;
}4.2. 讀寫鎖
在編寫多線程的時候,有一種情況是十分常見的。那就是,有些公共數據修改的機會比較少。相比較改寫,它們讀的機會反而高的多。通常而言,在讀的過程中,往往伴隨著查找的操作,中間耗時很長。給這種代碼段加鎖,會極大地降低我們程序的效率。那么有沒有一種方法,可以專門處理這種多讀少寫的情況呢? 有,那就是讀寫鎖。
讀寫鎖,我們用分析生產者消費者模型的思路進行理解: 即讀寫鎖也可以用321原則理解。
三種關系: 讀者和讀者 (共享關系)、 寫者和寫者? (互斥)、讀者和寫者 (同步、互斥)。
兩個角色, 讀者、寫者。
一個交易場所,本質就是用戶自己定義的數據緩沖區。
讀者寫者問題 vs 生產者消費者模型的本質區別是什么?
消費者會取走數據,因此消費者之間才需要互斥。
讀者不會取走數據,因此讀者之間不需要互斥。
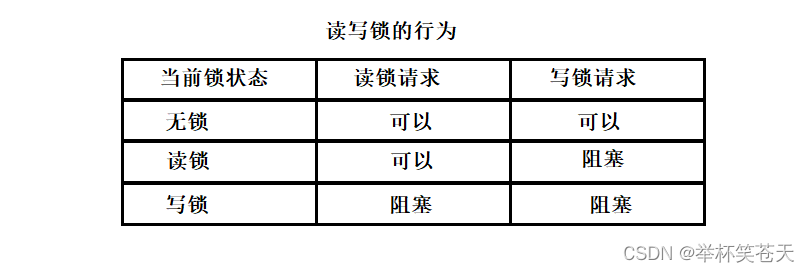
讀寫鎖的應用場景:數據被讀取的頻率非常高, 而被修改的頻率特別低。
當沒有鎖的時候: 讀鎖請求和寫鎖請求都可以滿足。
當有讀鎖的時候: 由于讀者和讀者是共享的,因此讀鎖請求可以滿足;而由于讀者和寫者是互斥的,因此寫鎖請求會被阻塞。
當有寫鎖的時候: 由于讀者和寫者是互斥的,因此讀鎖請求會被阻塞;而由于寫者和寫者是互斥的,因此寫鎖請求也會被阻塞。
寫鎖優先級高,當讀鎖和寫鎖同時到來的時候,優先獲得寫鎖。
總結:?寫獨占,讀共享,寫鎖優先級高。
4.2.1. 讀寫鎖的接口:
// 初始化讀寫鎖
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t *restrict attr);// 釋放讀寫鎖
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);//加鎖:
// 讀者加鎖
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
// 寫者加鎖
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);// 解鎖
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);

:模擬算法真題 ★★★★☆《卡牌游戲》《移動距離》)
)
)










)
支持密碼登錄)


