本文來源公眾號“小白學視覺”,僅用于學術分享,侵權刪,干貨滿滿。
原文鏈接:詳解遺傳算法 GA(Python實現代碼)
轉自:機器之心
英文:www.analyticsvidhya.com/blog/2017/07/introduction-to-genetic-algorithm/
本文分享遺傳算法 (GA , Genetic Algorithm) ,也稱進化算法!
1 遺傳算法理論的由來
我們先從查爾斯·達爾文的一句名言開始:
能夠生存下來的往往不是最強大的物種,也不是最聰明的物種,而是最能適應環境的物種。
你也許在想:這句話和遺傳算法有什么關系?其實遺傳算法的整個概念就基于這句話。
讓我們用一個基本例子來解釋?:
我們先假設一個情景,現在你是一國之王,為了讓你的國家免于災禍,你實施了一套法案:
-
你選出所有的好人,要求其通過生育來擴大國民數量。
-
這個過程持續進行了幾代。
-
你將發現,你已經有了一整群的好人。
這個例子雖然不太可能,但是我用它是想幫助你理解概念。也就是說,我們改變了輸入值(比如:人口),就可以獲得更好的輸出值(比如:更好的國家)。現在,我假定你已經對這個概念有了大致理解,認為遺傳算法的含義應該和生物學有關系。那么我們就快速地看一些小概念,這樣便可以將其聯系起來理解。
2 生物學的啟發
相信你還記得這句話:「細胞是所有生物的基石。」由此可知,在一個生物的任何一個細胞中,都有著相同的一套染色體。所謂染色體,就是指由 DNA 組成的聚合體。
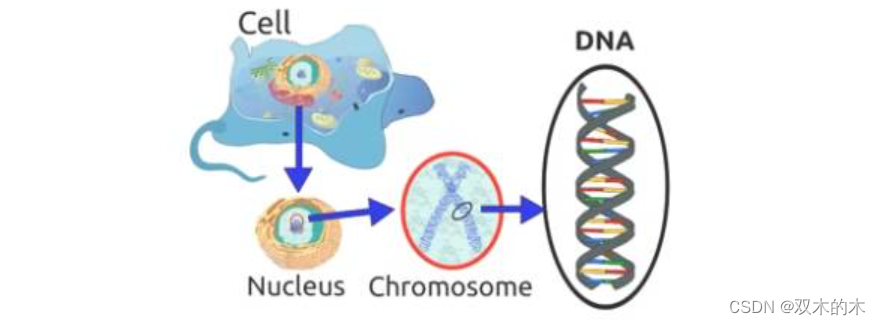
傳統上看,這些染色體可以被由數字?0?和 1 組成的字符串表達出來。

一條染色體由基因組成,這些基因其實就是組成 DNA 的基本結構,DNA 上的每個基因都編碼了一個獨特的性狀,比如,頭發或者眼睛的顏色。希望你在繼續閱讀之前先回憶一下這里提到的生物學概念。結束了這部分,現在我們來看看所謂遺傳算法實際上指的是什么?
3 遺傳算法定義
首先我們回到前面討論的那個例子,并總結一下我們做過的事情。
-
首先,我們設定好了國民的初始人群大小。
-
然后,我們定義了一個函數,用它來區分好人和壞人。
-
再次,我們選擇出好人,并讓他們繁殖自己的后代。
-
最后,這些后代們從原來的國民中替代了部分壞人,并不斷重復這一過程。
遺傳算法實際上就是這樣工作的,也就是說,它基本上盡力地在某種程度上模擬進化的過程。因此,為了形式化定義一個遺傳算法,我們可以將它看作一個優化方法,它可以嘗試找出某些輸入,憑借這些輸入我們便可以得到最佳的輸出值或者是結果。遺傳算法的工作方式也源自于生物學,具體流程見下圖:

那么現在我們來逐步理解一下整個流程。
4 遺傳算法具體步驟
為了讓講解更為簡便,我們先來理解一下著名的組合優化問題「背包問題」。如果你還不太懂,這里有一個我的解釋版本。
比如,你準備要去野游 1 個月,但是你只能背一個限重 30?公斤的背包。現在你有不同的必需物品,它們每一個都有自己的「生存點數」(具體在下表中已給出)。因此,你的目標是在有限的背包重量下,最大化你的「生存點數」。
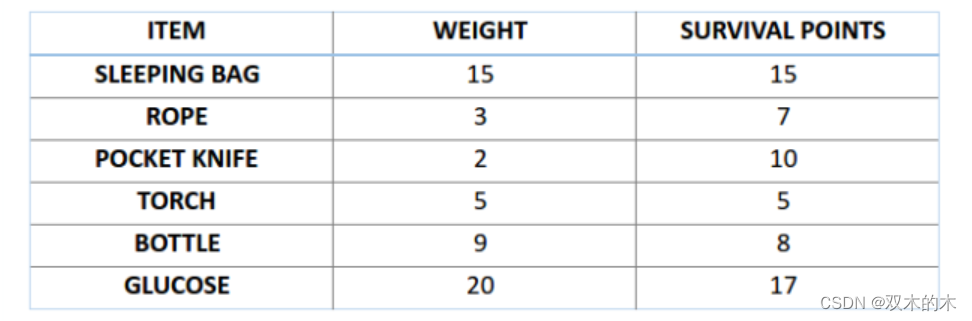
4.1?初始化
這里我們用遺傳算法來解決這個背包問題。第一步是定義我們的總體。總體中包含了個體,每個個體都有一套自己的染色體。
我們知道,染色體可表達為二進制數串,在這個問題中,1 代表接下來位置的基因存在,0?意味著丟失。(譯者注:作者這里借用染色體、基因來解決前面的背包問題,所以特定位置上的基因代表了上方背包問題表格中的物品,比如第一個位置上是 Sleeping Bag,那么此時反映在染色體的『基因』位置就是該染色體的第一個『基因』。)

現在,我們將圖中的 4 條染色體看作我們的總體初始值。
4.2?適應度函數
接下來,讓我們來計算一下前兩條染色體的適應度分數。對于 A1 染色體?[100110]?而言,有:
 類似地,對于 A2 染色體?[001110]?來說,有:
類似地,對于 A2 染色體?[001110]?來說,有:
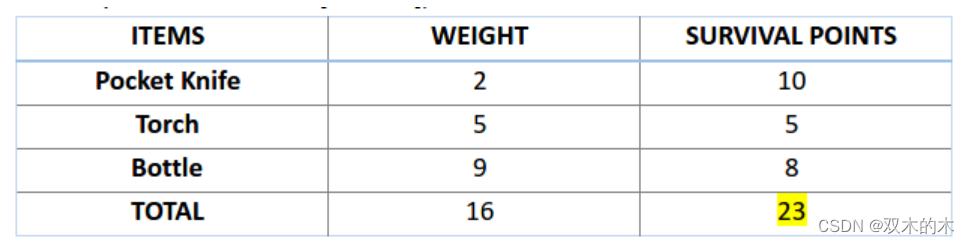 對于這個問題,我們認為,當染色體包含更多生存分數時,也就意味著它的適應性更強。
對于這個問題,我們認為,當染色體包含更多生存分數時,也就意味著它的適應性更強。
因此,由圖可知,染色體 1 適應性強于染色體 2。
4.3?選擇
現在,我們可以開始從總體中選擇適合的染色體,來讓它們互相『交配』,產生自己的下一代了。這個是進行選擇操作的大致想法,但是這樣將會導致染色體在幾代之后相互差異減小,失去了多樣性。因此,我們一般會進行「輪盤賭選擇法」(Roulette Wheel Selection method)。
想象有一個輪盤,現在我們將它分割成 m 個部分,這里的 m 代表我們總體中染色體的個數。每條染色體在輪盤上占有的區域面積將根據適應度分數成比例表達出來。
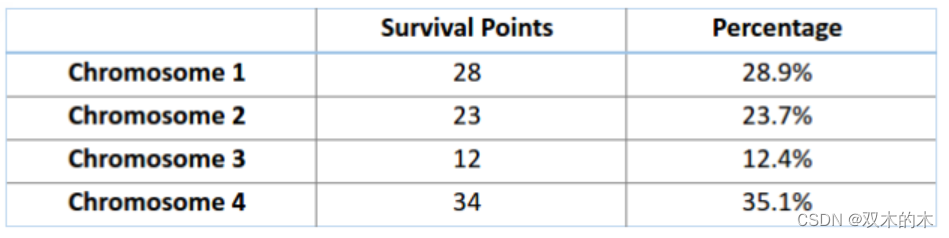
基于上圖中的值,我們建立如下「輪盤」。
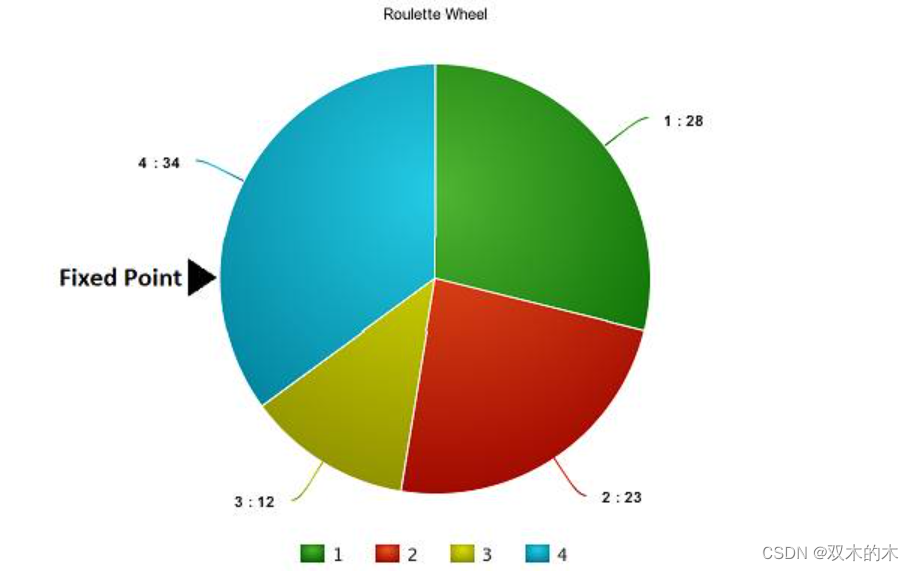
現在,這個輪盤開始旋轉,我們將被圖中固定的指針(fixed point)指到的那片區域選為第一個親本。然后,對于第二個親本,我們進行同樣的操作。有時候我們也會在途中標注兩個固定指針,如下圖:

通過這種方法,我們可以在一輪中就獲得兩個親本。我們將這種方法成為「隨機普遍選擇法」(Stochastic Universal Selection method)。
4.4?交叉
在上一個步驟中,我們已經選擇出了可以產生后代的親本染色體。那么用生物學的話說,所謂「交叉」,其實就是指的繁殖。現在我們來對染色體 1 和 4(在上一個步驟中選出來的)進行「交叉」,見下圖:
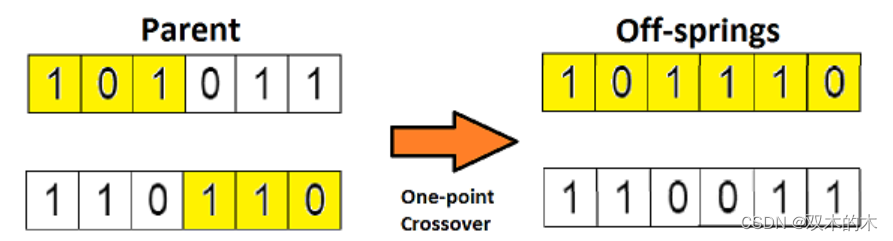
這是交叉最基本的形式,我們稱其為「單點交叉」。這里我們隨機選擇一個交叉點,然后,將交叉點前后的染色體部分進行染色體間的交叉對調,于是就產生了新的后代。
如果你設置兩個交叉點,那么這種方法被成為「多點交叉」,見下圖:

4.5?變異
如果現在我們從生物學的角度來看這個問題,那么請問:由上述過程產生的后代是否有和其父母一樣的性狀呢?答案是否。在后代的生長過程中,它們體內的基因會發生一些變化,使得它們與父母不同。這個過程我們稱為「變異」,它可以被定義為染色體上發生的隨機變化,正是因為變異,種群中才會存在多樣性。
下圖為變異的一個簡單示例:

變異完成之后,我們就得到了新為個體,進化也就完成了,整個過程如下圖:

在進行完一輪「遺傳變異」之后,我們用適應度函數對這些新的后代進行驗證,如果函數判定它們適應度足夠,那么就會用它們從總體中替代掉那些適應度不夠的染色體。這里有個問題,我們最終應該以什么標準來判斷后代達到了最佳適應度水平呢?
一般來說,有如下幾個終止條件:
-
在進行 X 次迭代之后,總體沒有什么太大改變。
-
我們事先為算法定義好了進化的次數。
-
當我們的適應度函數已經達到了預先定義的值。
好了,現在我假設你已基本理解了遺傳算法的要領,那么現在讓我們用它在數據科學的場景中應用一番。
5 遺傳算法的應用
5.1?特征選取
試想一下每當你參加一個數據科學比賽,你會用什么方法來挑選那些對你目標變量的預測來說很重要的特征呢?你經常會對模型中特征的重要性進行一番判斷,然后手動設定一個閾值,選擇出其重要性高于這個閾值的特征。
那么,有沒有什么方法可以更好地處理這個問題呢?其實處理特征選取任務最先進的算法之一就是遺傳算法。
我們前面處理背包問題的方法可以完全應用到這里。現在,我們還是先從建立「染色體」總體開始,這里的染色體依舊是二進制數串,「1」表示模型包含了該特征,「0?表示模型排除了該特征」。
不過,有一個不同之處,即我們的適應度函數需要改變一下。這里的適應度函數應該是這次比賽的的精度的標準。也就是說,如果染色體的預測值越精準,那么就可以說它的適應度更高。
現在我假設你已經對這個方法有點一概念了。下面我不會馬上講解這個問題的解決過程,而是讓我們先來用 TPOT 庫去實現它。
5.2?用?TPOT?庫來實現
這個部分相信是你在一開始讀本文時心里最終想實現的那個目標。即:實現。那么首先我們來快速瀏覽一下 TPOT 庫(Tree-based Pipeline Optimisation Technique,樹形傳遞優化技術),該庫基于 scikit-learn 庫建立。下圖為一個基本的傳遞結構。
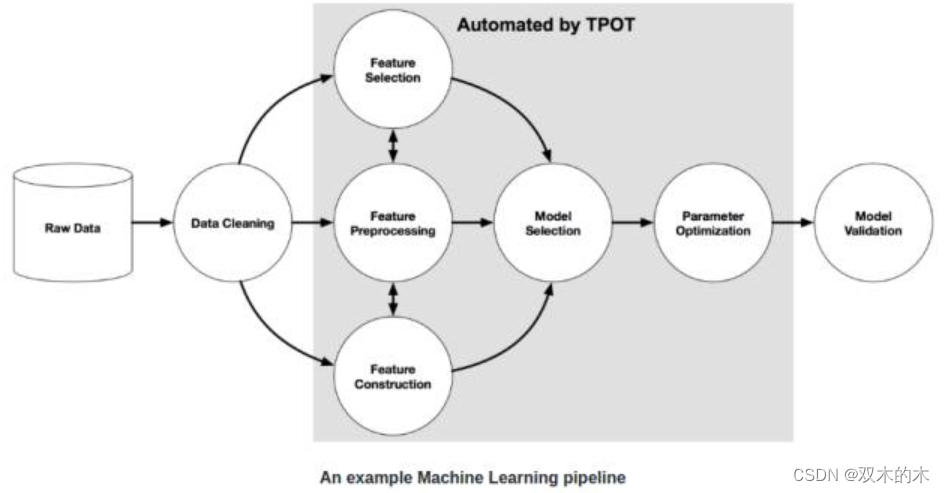
圖中的灰色區域用 TPOT 庫實現了自動處理。實現該部分的自動處理需要用到遺傳算法。
我們這里不深入講解,而是直接應用它。為了能夠使用 TPOT 庫,你需要先安裝一些 TPOT 建立于其上的 python 庫。下面我們快速安裝它們:
# installing DEAP, update_checker and tqdmpip install deap update_checker tqdm
# installling TPOT
pip install tpot這里,我用了 Big Mart Sales(數據集地址:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/)數據集,為實現做準備,我們先快速下載訓練和測試文件,以下是 python 代碼:
# import basic librariesimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
## preprocessing
### mean imputationstrain['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True)
test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### reducing fat content to only two categoriestrain['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']train['Outlet_Size'].fillna('Small',inplace=True)
test['Outlet_Size'].fillna('Small',inplace=True)train['Item_Visibility'] = np.sqrt(train['Item_Visibility'])
test['Item_Visibility'] = np.sqrt(test['Item_Visibility'])col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content']
test['Item_Outlet_Sales'] = 0combi = train.append(test)for i in col:
combi[i] = number.fit_transform(combi[i].astype('str'))
combi[i] = combi[i].astype('object')
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## removing id variablestpot_train = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
tpot_test = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
target = tpot_train['Item_Outlet_Sales']
tpot_train.drop('Item_Outlet_Sales',axis=1,inplace=True)
# finally building model using tpot libraryfrom tpot import TPOTRegressor
X_train, X_test, y_train, y_test = train_test_split(tpot_train, target,
train_size=0.75, test_size=0.25)tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')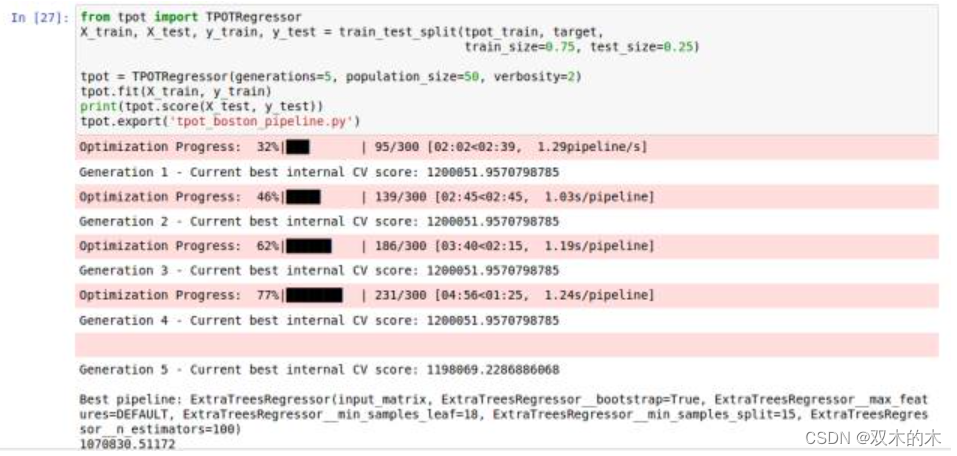
一旦這些代碼運行完成,tpot_exported_pipeline.py 里就將會放入用于路徑優化的 python 代碼。我們可以發現,ExtraTreeRegressor 可以最好地解決這個問題。
## predicting using tpot optimised pipelinetpot_pred = tpot.predict(tpot_test)
sub1 = pd.DataFrame(data=tpot_pred)
#sub1.index = np.arange(0, len(test)+1)sub1 = sub1.rename(columns = {'0':'Item_Outlet_Sales'})
sub1['Item_Identifier'] = test['Item_Identifier']
sub1['Outlet_Identifier'] = test['Outlet_Identifier']
sub1.columns = ['Item_Outlet_Sales','Item_Identifier','Outlet_Identifier']
sub1 = sub1[['Item_Identifier','Outlet_Identifier','Item_Outlet_Sales']]
sub1.to_csv('tpot.csv',index=False)如果你提交了這個 csv,那么你會發現我一開始保證的那些還沒有完全實現。那是不是我在騙你們呢?當然不是。實際上,TPOT 庫有一個簡單的規則。如果你不運行 TPOT 太久,那么它就不會為你的問題找出最可能傳遞方式。
所以,你得增加進化的代數,拿杯咖啡出去走一遭,其它的交給 TPOT 就行。此外,你也可以用這個庫來處理分類問題。進一步內容可以參考這個文檔:http://rhiever.github.io/tpot/。除了比賽,在生活中我們也有很多應用場景可以用到遺傳算法。
6?實際應用
遺傳算法在真實世界中有很多應用。這里我列了部分有趣的場景,但是由于篇幅限制,我不會逐一詳細介紹。
6.1?工程設計
工程設計非常依賴計算機建模以及模擬,這樣才能讓設計周期過程即快又經濟。遺傳算法在這里可以進行優化并給出一個很好的結果。
相關資源:
-
論文:Engineering design using genetic algorithms
-
地址:http://lib.dr.iastate.edu/cgi/viewcontent.cgi?article=16942&context=rtd
6.2?交通與船運路線(Travelling?Salesman?Problem,巡回售貨員問題)
這是一個非常著名的問題,它已被很多貿易公司用來讓運輸更省時、經濟。解決這個問題也要用到遺傳算法。

6.3?機器人
遺傳算法在機器人領域中的應用非常廣泛。實際上,目前人們正在用遺傳算法來創造可以像人類一樣行動的自主學習機器人,其執行的任務可以是做飯、洗衣服等等。
相關資源:
-
論文:Genetic Algorithms for Auto-tuning Mobile Robot Motion Control
-
地址:https://pdfs.semanticscholar.org/7c8c/faa78795bcba8e72cd56f8b8e3b95c0df20c.pdf
7 結語
希望通過本文介紹,你現在已經對遺傳算法有了足夠的理解,而且也會用 TPOT 庫來實現它了。但是如果你不親身實踐,本文的知識也是非常有限的。
所以,請各位讀者朋友一定要在無論是數據科學比賽或是生活中嘗試自己去實現它。?
THE END!
文章結束,感謝閱讀。您的點贊,收藏,評論是我繼續更新的動力。大家有推薦的公眾號可以評論區留言,共同學習,一起進步。
支持密碼登錄)





)




——初始化列表)





優化函數,學習速率與反向傳播算法--九五小龐)
:閾值處理、掩膜和重新映射圖像)
)