
論文名稱: LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
文章鏈接:https://arxiv.org/abs/2309.12307
代碼倉庫:?https://github.com/dvlab-research/LongLoRA
現階段,上下文窗口長度基本上成為了評估LLM能力的硬性指標,上下文的長度越長,代表大模型能夠接受的用戶要求越復雜,近期OpenAI剛發布的GPT-4 Turbo模型甚至直接支持到128K的上下文窗口,相當于用戶可以直接喂給模型一部長達300頁的小說。但是從模型實現角度來看,訓練具有長上下文大小的LLM的成本很高。例如在8192的上下文長度上訓練參數規模相同的模型,自注意力層的計算成本是2048的16倍。
本文介紹一篇來自CUHK和MIT合作完成的工作,本文結合LoRA方法提出了長上下文LLM微調框架LongLoRA,本文從兩個方面對LLM的上下文窗口進行了優化,首先提出了shift short attention(S2-Attn)模塊替代了原始模型推理過程中的密集全局注意力,可以節省大量的計算量,同時保持了與普通注意力微調相近的性能。此外作者重新審視了LLM上下文窗口參數的高效微調機制,提出了LongLoRA策略,LongLoRA可以在單個8×A100機器上實現LLaMA2-7B模型的上下文從4k擴展到100k,或LLaMA2-70B模型的上下文擴展到32k。LongLoRA具有很強的普適性,其可以保持LLM的原始架構,并且與大多數現有技術兼容,例如FlashAttention-2等,此外,為了讓LongLoRA的模型具有對話能力,作者團隊專門收集了一個LongAlpaca數據集(包含9k長上下文問答對和3k短問答對),用于監督微調。
01. 引言
訓練或微調一個LLM所需的計算資源對于普通的研究人員來說通常難以承受,因此研究更輕量的模型微調方案已經成為學術界的熱點話題,目前最直接的手段是使用微軟提出的低秩適應方法(LoRA)[1],LoRA可以通過學習一個低秩矩陣來修改自注意力塊中的線性投影層,達到高效減少模型可訓練參數規模的效果。

但是LoRA在遇到超長上下文的查詢時,提升效果不夠明顯,并且會帶來模型困惑度增加的問題,本文作者以LLaMA2-7B模型進行了模型困惑度實驗,實驗結果如上表所示,可以看到,LoRA方法相比完整微調方法(Full FT)會帶來更明顯的困惑現象,即使將LoRA矩陣的秩提升到256也不能緩解這種問題。此外在模型效率方面,無論是否采用LoRA,隨著上下文窗口長度的擴展,模型的計算成本都會急劇增加,這主要是由于自注意力機制的計算量導致的,如下圖所示,作者展示了三種不同方法在訓練相同的LLaMA2模型時,模型的訓練復雜度、GPU占用和訓練時間隨著上下文窗口長度增加的變化情況。
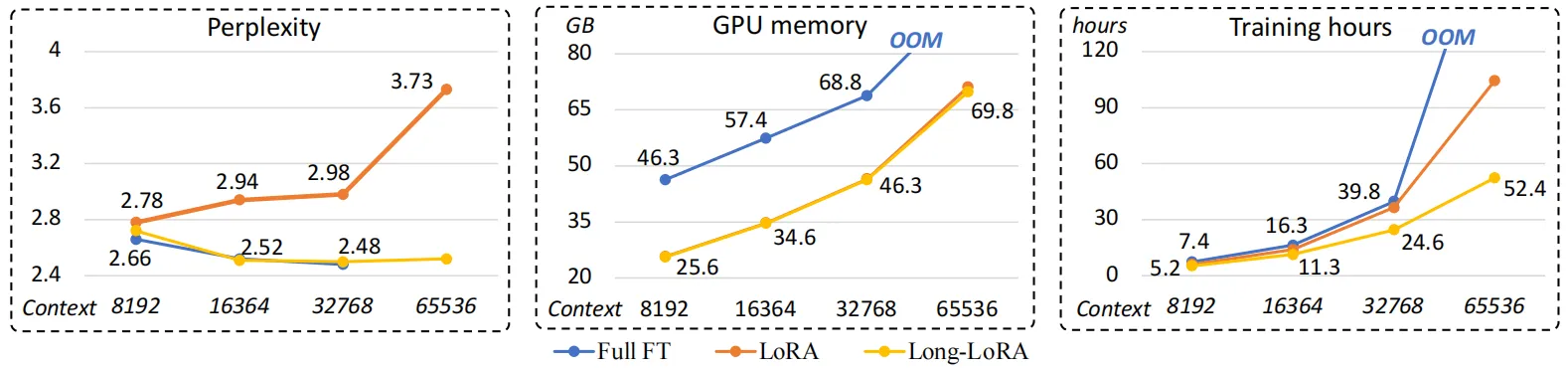
為了解決上述問題,本文引入了一種專門解決長上下文訓練難題的LongLoRA微調方法,同時為了應對標準自注意力機制龐大的計算量,作者提出了一種短時注意力S2-Attn來減少計算成本,從上面三個圖中的結果來看,LongLoRA可以有效的提升模型各方面的微調性能。
02. 本文方法
2.1 shift short attention(S2-Attn)


其首先將模型的輸入分為幾組,并在每個組中分別進行注意力計算,同時在每個組中,將原有的token移動組大小的一半來保證相鄰注意力頭之間的信息交互,作者進行了如下的實驗來觀察S2-Attn在不同上下文窗口中的性能變化,其中參與實驗的baseline方法還包括一些無需進行微調的位置編碼優化方法。可以看到,微調對于模型處理長上下文輸入的效果起到了非常重要的作用。
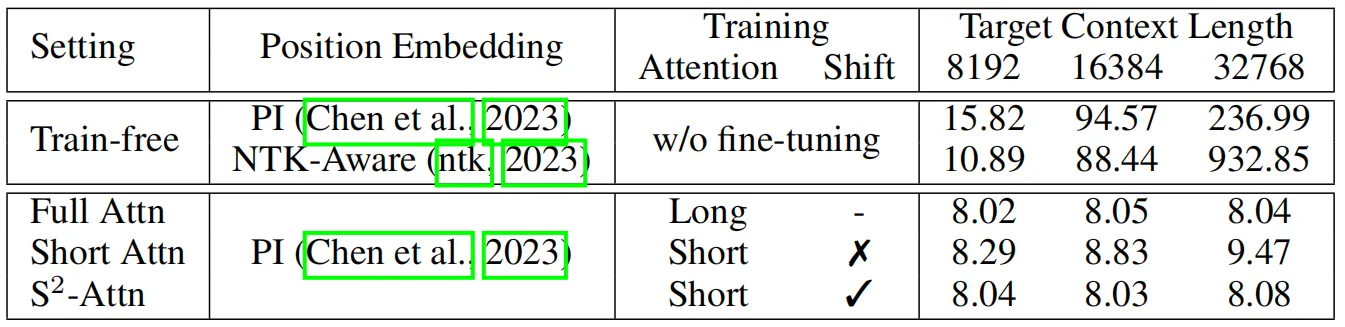
上表中的第一種注意力模式是只使用短時注意力進行訓練(Pattern 1),由于對于長上下文,模型的計算成本主要來自自注意力模塊。因此,在這個試驗中,作者將自注意力模塊分為4組。例如,在模型的訓練和測試階段均采用8192個token作為輸入,而每個組中的注意力計算的token大小為2048,如上表所示,這種模式相比普通方法已經能夠提升模型性能,但是隨著上下文長度的增加,模型的困惑程度變得更嚴重,作者分析造成這種情況的原因是不同的組之間沒有信息交互。
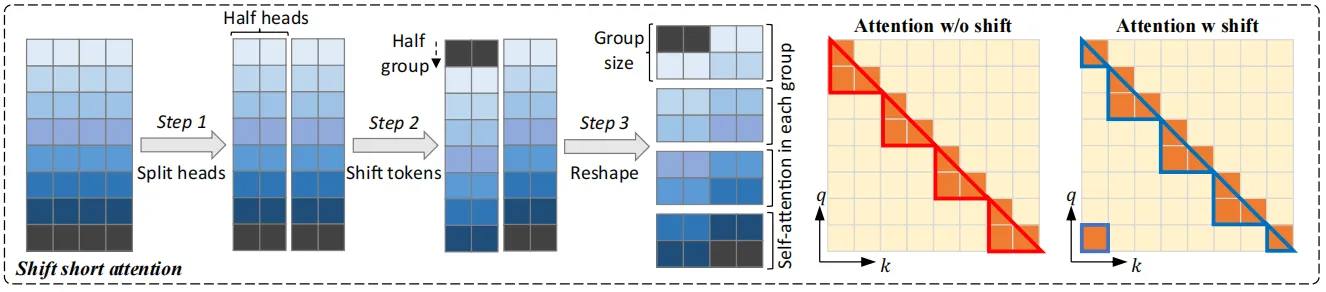
為了促進不同注意力組之間的信息交互,作者提出了一種shift模式,如上圖所示,即在進行組劃分時將注意力頭移動組長度的一半距離,以上下文窗口長度8192為例,在Pattern 1中,第一組從第1個到第2048 個token進行自注意力計算。在Pattern 2中,組劃分移動長度為1024,這樣就導致另一個注意力組從第1025個token開始,到第3072個token結束,而第一個和最后1024個token屬于同一組,這種方式不會增加額外的計算成本,但可以實現不同組之間的信息流動。

此外,shift short attention非常容易在代碼中實現,上圖展示了其在注意力塊計算時的偽代碼,只需要在原始自注意力計算的基礎上添加兩行代碼。
2.2 面向長上下文改進LoRA算法到LongLoRA
LoRA算法是目前LLM社區中非常常用的微調方法,幾乎是微調一個基座模型到下游垂直領域中的首選算法,與完全微調相比,它節省了大量可訓練參數和顯存占用的成本。然而,使用LoRA算法在較長上下文的場景中進行訓練仍然存在一些問題,微調后的模型性能會略遜色于完全微調方法,這種性能差距會隨著目標上下文長度變大而增大。
為了彌補這一差距,作者在訓練時允許模型嵌入層和歸一化層的參數進行更新。最終效果如上表所示,雖然這些層只占用少量的參數(特別是歸一化層的參數量占比在整個LLaMA2-7B模型中僅為0.004%),但它們卻對模型在長上下文場景中的適應起到有益幫助,上表中的LoRA+Norm+Embed獲得了最佳性能,作者在后續的實驗中將這種LoRA的改進版本表示為LoRA+。
03. 實驗效果
本文的實驗基座模型選用了預訓練的LLaMA2模型,分別包含7B、13B和70B的版本,其中7B版本的最大上下文窗口大小為100k,13B版本為65536,70B版本為32768。對于實驗數據集,作者使用Redpajama數據集進行訓練,隨后使用圖書語料庫數據集PG19和Arxiv Math數據集來評估微調模型的長序列語言建模性能,還使用PG19的測試集專門評估模型的困惑度。此外,作者團隊還提出了一個用于監督微調長上下文模型的數據集LongAlpaca,LongAlpaca包含了9k個長問題和相應的答案,以及3k短問答,共計12k問答數據。
3.1 長序列語言建模性能
下表中展示了本文方法在LLaMA2-7B和LLaMA2-13B模型上的長序列建模實驗結果,模型的性能通過困惑度指標來體現,可以看到,對于相同的訓練和評估上下文長度的情況,隨著上下文窗口長度的增加,模型的困惑度會降低。通過將LLaMA2-7B模型的上下文窗口大小從8192增加到32768時,模型困惑度從2.72降低到2.50,降低了0.22。對于LLaMA2-13B模型,可以觀察到困惑度從2.60降低到2.32,降低了0.28。
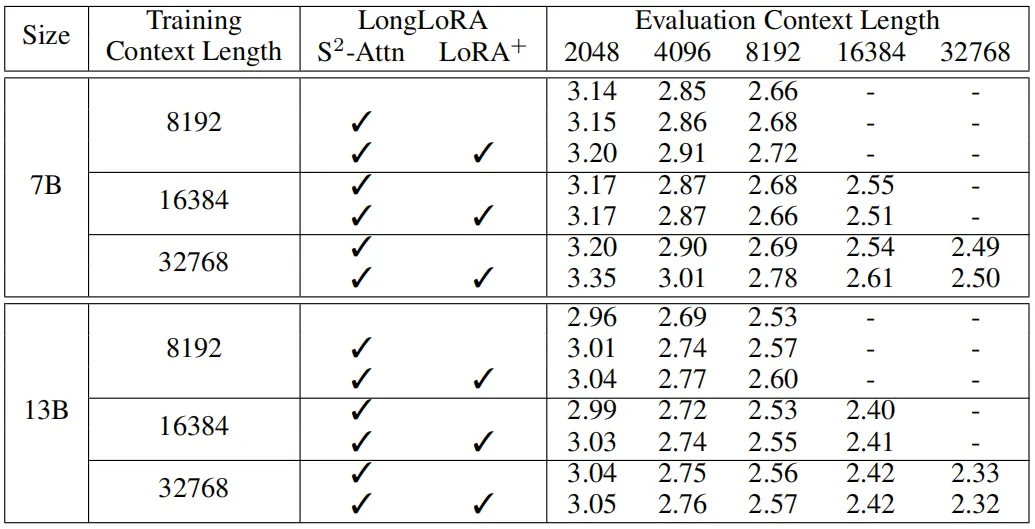
在下表中,作者進一步探索了LongLoRA可以在單個 8 x A100 機器上微調的最大上下文窗口長度。這里將LLaMA2 7B、13B 和 70B 的上下文長度分別擴展到 100k、65536、32768,可以看到,LongLoRA在這些極端的設置上仍然取得了較好的結果,此外也可以觀察到,擴展模型的上下文窗口大小會導致模型的困惑度下降。

3.2 基于檢索的性能評估
為了保證實驗的完整性,作者在長序列語言建模性能評估之外還引入了基于長上下文檢索的實驗。在下表中,作者將本文方法與其他開源LLMs在LongChat[2]中設置的主題檢索任務上進行了對比實驗。該任務要求模型從很長的對話數據中檢索到目標主題,長度從 3k、6k、10k、13k 到 16k 不等。由于數據集中的一些問題的長度超過了16k,因此作者選擇對LLaMA2-13B模型進行微調,上下文窗口長度為18k。
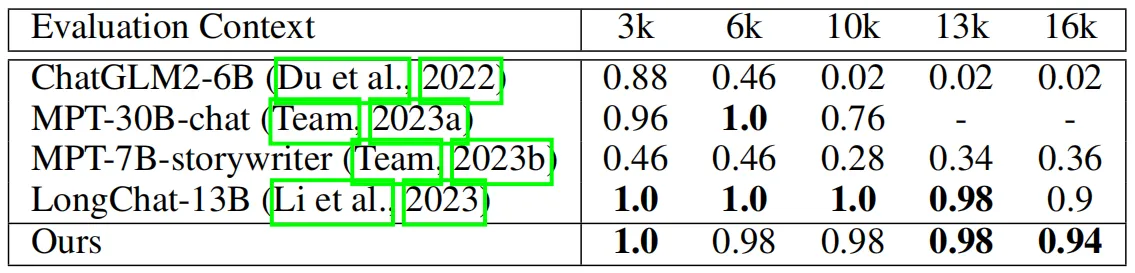
從上表中可以看出,本文方法實現了與該任務中SOTA方法LongChat-13B相當的性能,甚至在極端長度16k的場景評估中性能超過了LongChat-13B。
04. 總結
本文針對LLM微調訓練提出了一種名為LongLoRA的方法,它可以有效地將LLM的上下文窗口長度擴展到更長的范圍。LongLoRA與標準完全微調方法相比,所使用的GPU顯存成本和訓練時間更少,并且精度損失也很小。在架構層面,作者將原始笨重的自注意力計算轉換為更加輕量的shift short attention(S2-Attn),S2-Attn以獨特的注意力頭劃分模式實現了局部的信息交互,從而帶來更高效的性能,更關鍵的是,S2-Attn只需要兩行代碼就可以實現。在模型訓練層面,作者在傳統LoRA微調模式中加入了可訓練的標準化和嵌入層參數,這被證明在長上下文場景中是有效的。從實際操作層面來看,LongLoRA是一種通用的方法,可以兼容到更多類型的LLMs中,進一步降低開發者微調LLM的難度和成本。
參考
[1] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022.
[2] Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica,Xuezhe Ma, and Hao Zhang. How long can open-source llms truly promise on context length? June 2023.
??關于TechBeat人工智能社區
▼
TechBeat(www.techbeat.net)隸屬于將門創投,是一個薈聚全球華人AI精英的成長社區。
我們希望為AI人才打造更專業的服務和體驗,加速并陪伴其學習成長。
期待這里可以成為你學習AI前沿知識的高地,分享自己最新工作的沃土,在AI進階之路上的升級打怪的根據地!
更多詳細介紹>>TechBeat,一個薈聚全球華人AI精英的學習成長社區
)

)




)


)








