英文名稱: CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
中文名稱: CodeGeeX:一種用于代碼生成的預訓練模型,并在HumanEval-X上進行多語言評估
鏈接: https://arxiv.org/abs/2303.17568
代碼: https://github.com/THUDM/CodeGeeX 7.6k Starhttps://github.com/THUDM/CodeGeeX2 6.5k Star
作者: Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, Jie Tang
機構: 清華大學, Zhipu.AI, 華為
日期: 2023-03-30
引用次數: 89
1 讀后感
這是一篇比較早的論文,于 2022 年 4 月至 6 月期間,在 1,536 個 Ascend 910 AI 處理器集群上,對 23 種編程語言進行了訓練,總共使用了超過 850B 個 token,模型于 2022 年 9 月公開發布。
該論文介紹了 CodeGeeX 的第一代技術,而 CodeGeeX2 則基于 ChatGLM2,底層結構轉向了 llama2。新版本沒有附帶新的論文和開源代碼。
通過閱讀這篇論文,我們可以了解到開發代碼生成的起始階段,包括:現有對基礎架構的調整、數據組織和模型評估的過程。從代碼實現的角度來看,CodeGeeX 是完全開源的。它使用 Mindspore 作為深度學習框架,而非主流的 torch。不過,它提供了類似于 torch 的調用方法,所以只需簡單瀏覽即可。
與 copilot 相比,CodeGeeX 免費使用的。我的使用體驗是:功能差異不大,只是質量稍遜色一些。
2 摘要
目標:介紹 CodeGeeX,一個擁有 130 億參數的,支持多編程語言的代碼生成模型。
方法:CodeGeeX 用 850 B 個 token 進行了模型預訓練,涵蓋了 23 種編程語言。
結論:實驗結果表明,CodeGeeX 在性能上優于規模相似的多語言代碼模型。
3 引言

主要貢獻
- 推出了 CodeGeeX,一個 13B 參數的 23 語言代碼生成模型,其在代碼生成和翻譯上超過了同等規模的多語言基線。
- 為 VS Code、JebBrains 和 Tencent Cloud Studio 開發了 CodeGeeX 擴展插件,比 Copilot 有更多功能,包括代碼完成、生成、翻譯和解釋,且能提高 83.4% 用戶的編碼效率。
- 創建了 HumanEval-X 基準測試,以評估多語言代碼模型在代碼生成和翻譯任務的功能正確性,推動對預訓練代碼模型的理解和發展。
4 實現
4.1 模型架構
基于 Transformer 框架,采用了僅解碼器網絡進行自回歸語言建模。CodeGeeX 的核心架構是一個 39 層的轉換器解碼器。在每個 Transformer 層中,應用了多頭自注意力機制,然后是 MLP 層、層歸一化和殘差連接。并使用了 FastGELU 激活函數。
采用 GPT 范式,在大量未標記的代碼數據上訓練模型。
在頂部查詢層和解碼方面,原始的 GPT 模型使用池函數來獲取最終輸出。而文中模型在所有其他轉換器層之上使用了一個額外的查詢層,并通過注意力來獲得最終的嵌入。

4.2 預訓練
4.2.1 訓練數據
訓練語料庫包含兩部分:
第一部分來自開源代碼數據集,包括 Pile(Gao 等人,2020 年)和 CodeParrot3。Pile 包含了 GitHub 上星級超過 100 的公共倉庫的子集,從中選擇了 23 種流行編程語言的文件,包括 C++,Python,Java,JavaScript,C,Go 等。根據每個文件的后綴和它所屬倉庫的主要語言來確定編程語言。CodeParrot 是來自 BigQuery 的另一個公開的 Python 數據集。
第二部分是直接從 GitHub 公共倉庫中抓取的 Python,Java 和 C++ 的補充數據,這些數據在第一部分中沒有出現。選擇的倉庫至少有一個星級,總大小在 10MB 以內,然后過濾掉那些:1)平均每行超過 100 個字符的文件,2)自動生成的文件,3)字母比例小于 40% 的文件,4)大于 100KB 或小于 1KB 的文件。按照 PEP8 標準格式化 Python 代碼。
4.2.2 Tokenization
考慮到 1)代碼數據中存在大量自然語言注釋,2)變量、函數和類的命名通常是有意義的詞,將代碼數據與文本數據相同,并應用 GPT-2 標記器。由于詞匯表包含來自各種自然語言的標記,因此它允許 CodeGeeX 處理英語以外的語言的標記,如中文、法語、俄語、日語等。最終的詞匯量為?52,224?。
4.2.3 輸入詞和位置嵌入
在給定 tokens 后,每個 token 會與一個詞嵌入相關聯,同時也會獲取位置信息的嵌入。這兩種嵌入相加后形成模型的輸入嵌入,最后整個序列被轉換為輸入嵌入。
4.3 訓練
在 Ascend 910 上進行并行訓練。CodeGeeX 在帶有 Mindspore(v1.7.0)的 Ascend 910 AI 處理器(32GB)集群上進行了訓練。與 NVIDIA GPU 和 PyTorch/TensorFlow 相比,Ascend 和 Mindspore 相對較新。整個預訓練過程需要兩個月的時間,在 192 個節點和 1,536 個 AI 處理器上,850B 代幣,相當于 5+ 個 epoch(213,000 步)。
4.4 快速推理
為了提供預訓練的 CodeGeeX,實現了一個純 PyTorch 版本的 CodeGeeX,它支持在 NVIDIA GPU 上進行推理。為了實現快速且節省內存的推理,將量化和加速技術應用于預訓練的 CodeGeeX。
量化前后對比如下:

5 評測
主實驗結果如下:

后面的 CodeGeeX2 相比 CodeGeeX 又好很多,下圖取自 CodeGeeX2 github。
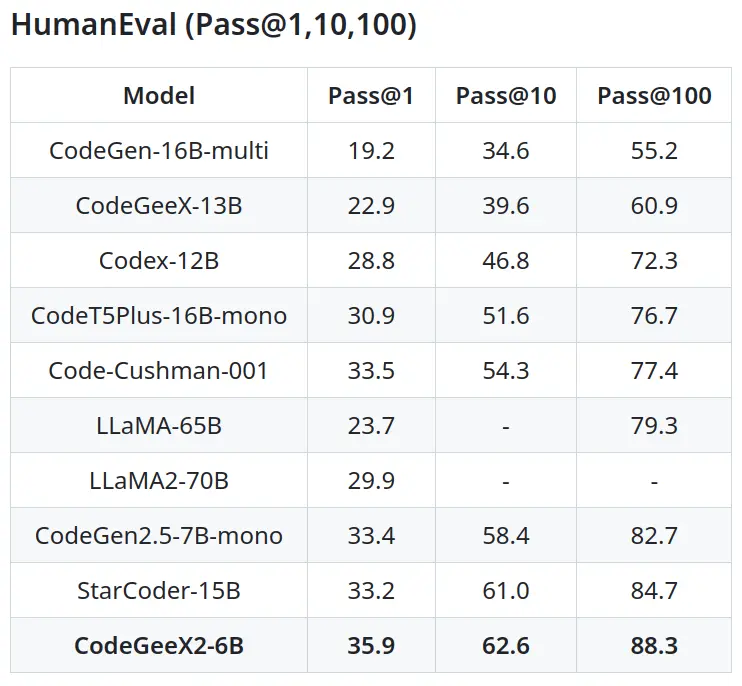


)

及其常見組件)





)








