一、根頁面萬年不動
在之前的文章里,為了方便理解,都是先畫存儲用戶記錄的葉子節點,然后再畫出存儲目錄項記錄的內節點。
但實際上 B+ 樹的行成過程是這樣的:
-
每當為某個表創建一個 B+ 樹索引,都會為這個索引創建一個根節點頁面。最開始表里沒數據,所以根節點中既沒有用戶記錄,也沒有目錄項記錄。
-
當往表里插入用戶記錄時,先把用戶記錄存儲到這個根節點上。
-
當根節點頁空間用完,繼續插入記錄,此時會將根節點中所有記錄復制到一個新頁(比如頁 a),然后對這個新頁進行頁分裂,得到另一個新頁(頁 b)。這時候新插入的記錄就根據鍵值大小分配到頁 a 和 頁 b 中。于是,根節點頁就升級成了存儲目錄項記錄的頁,就需要把頁a 和 頁b 對應的目錄項記錄插入到根節點中。
另外,當一個B+樹索引的根節點創建后,它的頁號就不會再變。
所以只要我們對某個表建立一個索引,那么它的根節點的頁號就會被記錄到某個地方,后續只要 innodb引擎需要用這個索引,就會從那個固定的地方取出根節點的頁號,從而訪問這個索引。
二、內節點中目錄項記錄的唯一性
在B+樹索引的內節點中,目錄項記錄的內容是索引列+頁號。但是對于二級索引來說,不太嚴謹。
因為二級索引的索引列可能存在相同的值,比如某張表里有這4條記錄,其中c1列是主鍵 :

現在為c2列建立索引:

如果這時候繼續插入一條記錄,3個列分別為9、1、'c',就會遇到問題:
- 新記錄中 c2的值也是1,那么這個新記錄到底應該放在頁 4,還是放到頁 5?
所以,為了能讓新插入的記錄可以找到自己應該到哪個頁中,就需要保證B+樹同一層內節點的目錄項記錄是唯一的。
那么,實際上二級索引的內節點的目錄項記錄應該由 3 個部分組成:
- 索引列的值
- 主鍵值
- 頁號
所以實際上給c2建立的索引應該是這樣:
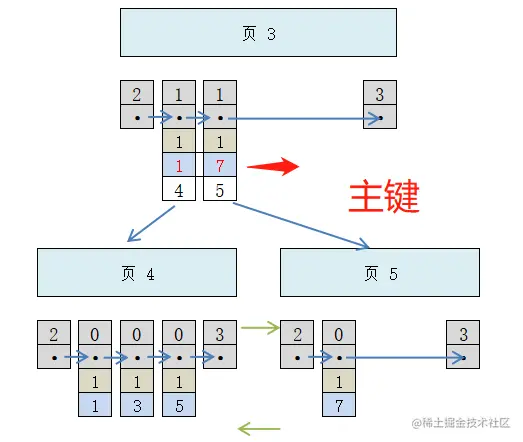
現在,當插入新記錄9、1、'c'時:
- 可以先把新記錄的 c2 列的值和頁 3 中各目錄項記錄的 c2 列的值進行比較。
- 如果 c2 列的值相同,就接著比較主鍵值。
所以,對于二級索引來說,給 c2 列建索引,其實就相當于用c2、c1建立了一個聯合索引。先按照二級索引的值進行排序,在二級索引列值相同的情況下,再按照主鍵值進行排序。
三、一個頁面至少容納 2 條記錄
在之前的文章里提到過,B+ 樹其實只需要很少的層級就可以輕松存儲數億條記錄,查詢速度還很快。
這是因為 B+ 樹本質上就是一個大的多層級目錄。每經過一個目錄時都會過濾許多無效的子目錄,直到最后訪問到存儲真正數據的目錄。
那么現在不妨設想一下:還是同樣的數據量,如果一個大的目錄只存放一個子目錄,又是什么樣子?
- 目錄層級非常多
- 最后那個存放真正數據的目錄中只能存放一條記錄
如果是這樣的話,這種B+ 樹結構就沒什么意義了,不能形成一個有效的索引。于是,設計 innoDB的大佬為了避免 B+樹的層級增長得過高,要求所有數據頁都至少可以存放2條記錄。
最后感謝每一個認真閱讀我文章的人,禮尚往來總是要有的,這些資料,對于【軟件測試】的朋友來說應該是最全面最完整的備戰倉庫,雖然不是什么很值錢的東西,如果你用得到的話可以直接拿走:

這些資料,對于【軟件測試】的朋友來說應該是最全面最完整的備戰倉庫,這個倉庫也陪伴上萬個測試工程師們走過最艱難的路程,希望也能幫助到你!?

及其常見組件)





)












