目錄
?往期精彩內容:
多變量特征序列、單序列數據預測實戰
前言
1 風速數據預處理與數據集制作
1.1 導入數據
1.2 多變量數據預處理與數據集制作
1.3 單序列數據預處理與數據集制作
2超強模型XGBoost——原理介紹
3 模型評估和對比
3.1 隨機森林預測模型
3.2 支持向量機SVM預測模型
3.3 XGBoost分類模型
代碼、數據如下:

?往期精彩內容:
時序預測:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析與比較-CSDN博客
風速預測(一)數據集介紹和預處理-CSDN博客
風速預測(二)基于Pytorch的EMD-LSTM模型-CSDN博客
風速預測(三)EMD-LSTM-Attention模型-CSDN博客
風速預測(四)基于Pytorch的EMD-Transformer模型-CSDN博客
風速預測(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
風速預測(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
CEEMDAN +組合預測模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +組合預測模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +組合預測模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
?CEEMDAN +組合預測模型(CNN-Transformer + ARIMA)-CSDN博客
多特征變量序列預測(一)——CNN-LSTM風速預測模型-CSDN博客
多特征變量序列預測(二)——CNN-LSTM-Attention風速預測模型-CSDN博客
多特征變量序列預測(三)——CNN-Transformer風速預測模型-CSDN博客
多特征變量序列預測(四)Transformer-BiLSTM風速預測模型-CSDN博客
多特征變量序列預測(五) CEEMDAN+CNN-LSTM風速預測模型-CSDN博客
多特征變量序列預測(六) CEEMDAN+CNN-Transformer風速預測模型-CSDN博客
多特征變量序列預測(七) CEEMDAN+Transformer-BiLSTM預測模型-CSDN博客
基于麻雀優化算法SSA的CEEMDAN-BiLSTM-Attention的預測模型-CSDN博客
基于麻雀優化算法SSA的CEEMDAN-Transformer-BiGRU預測模型-CSDN博客
多特征變量序列預測(八)基于麻雀優化算法的CEEMDAN-SSA-BiLSTM預測模型-CSDN博客
多特征變量序列預測(九)基于麻雀優化算法的CEEMDAN-SSA-BiGRU-Attention預測模型-CSDN博客
多特征變量序列預測(10)基于麻雀優化算法的CEEMDAN-SSA-Transformer-BiLSTM預測模型-CSDN博客
風速預測(七)VMD-CNN-BiLSTM預測模型-CSDN博客?
多變量特征序列、單序列數據預測實戰
前言
XGBoost是一種強大的機器學習算法,適用于預測任務。它通過梯度提升樹的方式有效地處理復雜數據,并在許多領域中取得了令人矚目的成果。本文基于前期介紹的風速數據(文末附數據集),利用XGBoost模型分別對多變量序列、單序列的數據進行建模,來實現精準預測。
風速數據集的詳細介紹可以參考下文:
風速預測(一)數據集介紹和預處理_風速預測時序數據-CSDN博客
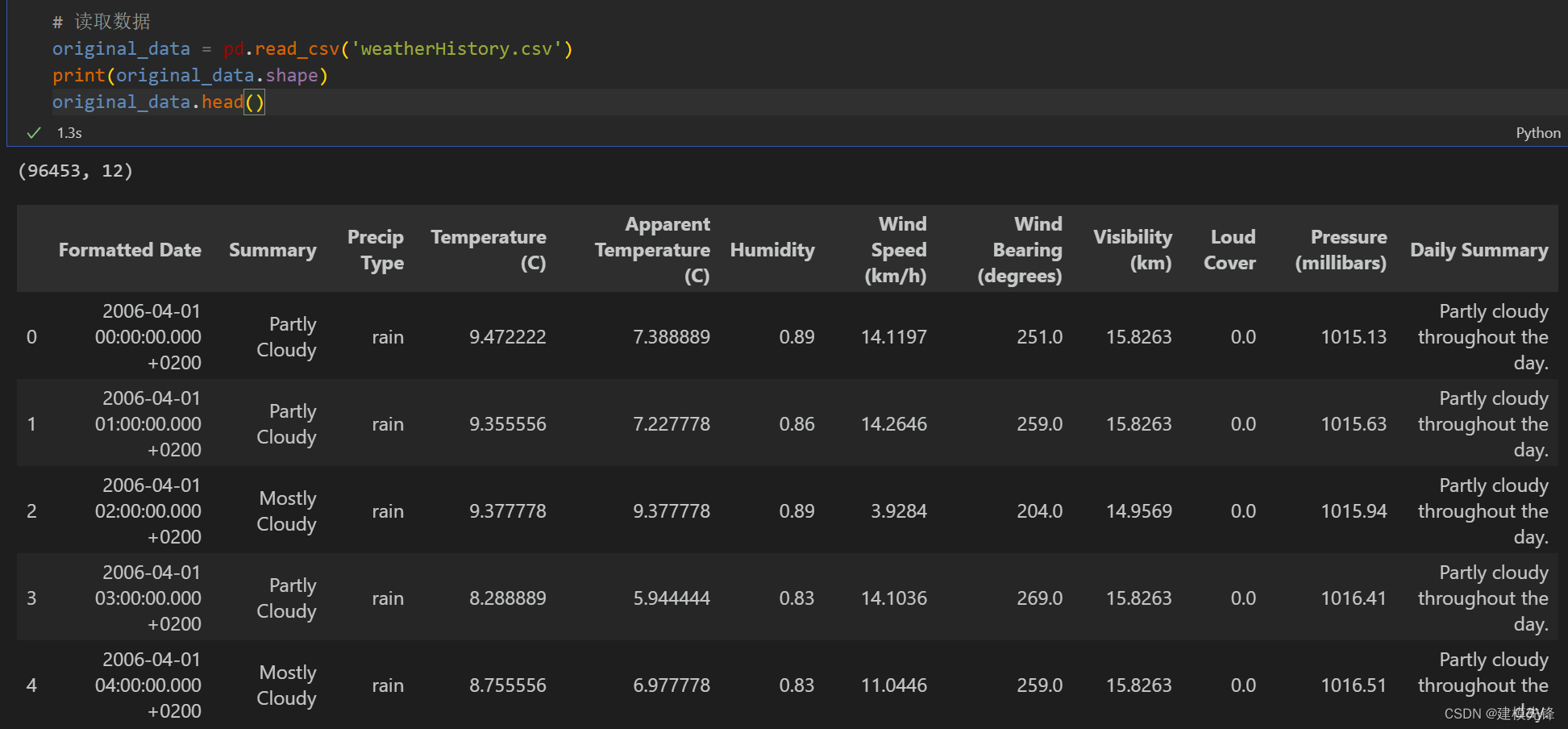 ?
?
數據集一共有天氣、溫度、濕度、氣壓、風速等九個變量
我們通過對比實驗來探索,在此數據集上多變量預測和單序列預測的效果
1 風速數據預處理與數據集制作
1.1 導入數據
 ?
?
1.2 多變量數據預處理與數據集制作
多變量數據預測 采用7個特征變量來預測風速數據
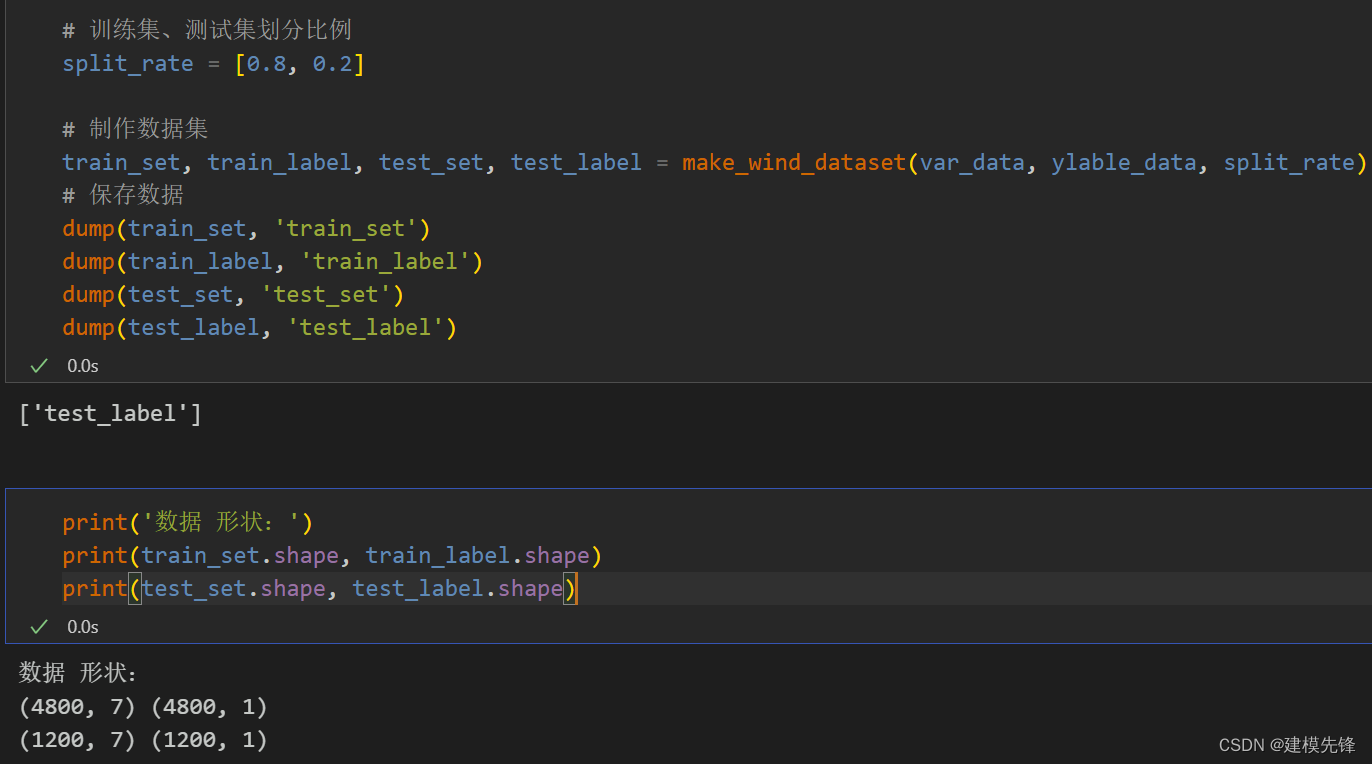 ?
?
1.3 單序列數據預處理與數據集制作
僅使用風速一個變量來構建數據集和預測模型
通過滑動窗口來制作數據集
 ?
?
2超強模型XGBoost——原理介紹
論文鏈接:
XGBoost | Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
GBoost模型(eXtreme Gradient Boosting)是一種梯度提升框架,由Tianqi Chen在2014年開發,并在機器學習領域廣泛應用。XGBoost的核心思想是通過迭代地訓練多個弱學習器,并將它們組合起來,實現強大的預測能力。它在梯度提升算法的基礎上進行了改進和優化,具有高效、靈活和可擴展的特點。
下面是XGBoost的一些關鍵特性和原理:
1. 梯度提升:XGBoost使用了梯度提升算法,也稱為增強學習(Boosting)算法。它通過迭代地訓練多個弱學習器,并通過梯度下降的方式來優化模型的預測能力。每個弱學習器都是在前一個弱學習器的殘差上進行訓練,從而逐步減小預測誤差。
2. 基于樹的模型:XGBoost采用了基于樹的模型,即決策樹。決策樹是一種非常靈活和可解釋的模型,能夠學習到復雜的非線性關系。XGBoost使用了CART(Classification and Regression Trees)作為默認的基學習器,每個決策樹都是通過不斷劃分特征空間來實現分類或回歸任務。
3. 正則化策略:為了防止過擬合,XGBoost引入了正則化策略。它通過控制決策樹的復雜度來限制模型的學習能力。常用的正則化策略包括限制決策樹的最大深度、葉子節點的最小樣本數和葉子節點的權重衰減等。
4. 特征選擇和分裂:XGBoost在構建決策樹時,通過特征選擇和分裂來最大化模型的增益。特征選擇基于某種評估準則(如信息增益或基尼系數),選擇對當前節點的劃分最有利的特征。特征分裂則是確定特征劃分點的過程,使得劃分后的子節點能夠最大程度地減小預測誤差。
5. 并行計算:為了提高模型的訓練速度,XGBoost使用了并行計算的策略。它通過多線程和分布式計算等技術,將訓練任務分解為多個子任務,并在不同的處理器上同時進行計算。這樣可以加快模型的訓練速度,特別是在處理大規模數據集時表現優異。
6. 自定義損失函數:XGBoost允許用戶自定義損失函數,以適應不同的任務和需求。用戶可以根據具體問題的特點,定義適合的損失函數,并在模型訓練過程中使用它。
XGBoost模型通過梯度提升算法和基于樹的模型,在許多機器學習任務中都取得了很好的效果,包括分類、回歸、排序和推薦等。我們利用其高效、靈活和可擴展的特性,使用XGBoost來構建一個梯度提升模型,通過迭代地訓練多個決策樹來實現風速數據的精準預測。
3 模型評估和對比
3.1 隨機森林預測模型
多特征變量預測
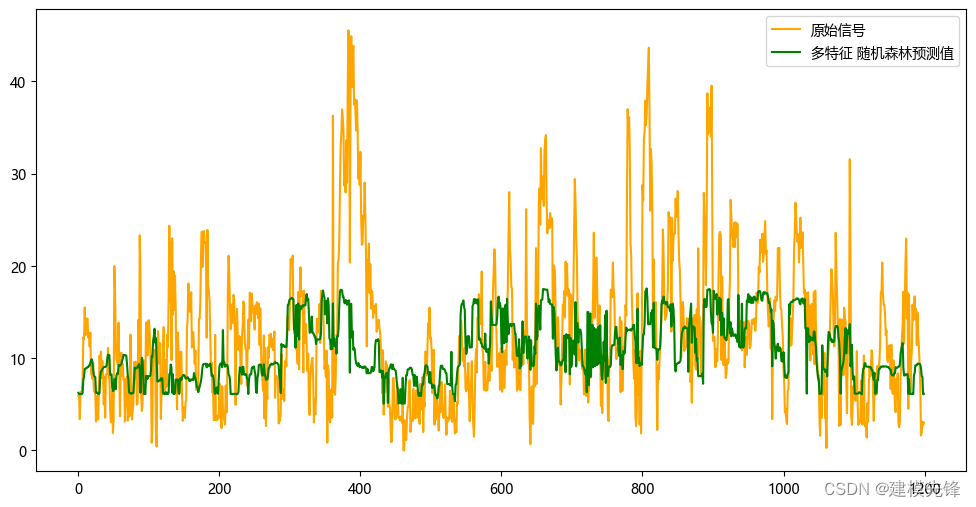 ?
?
單序列預測
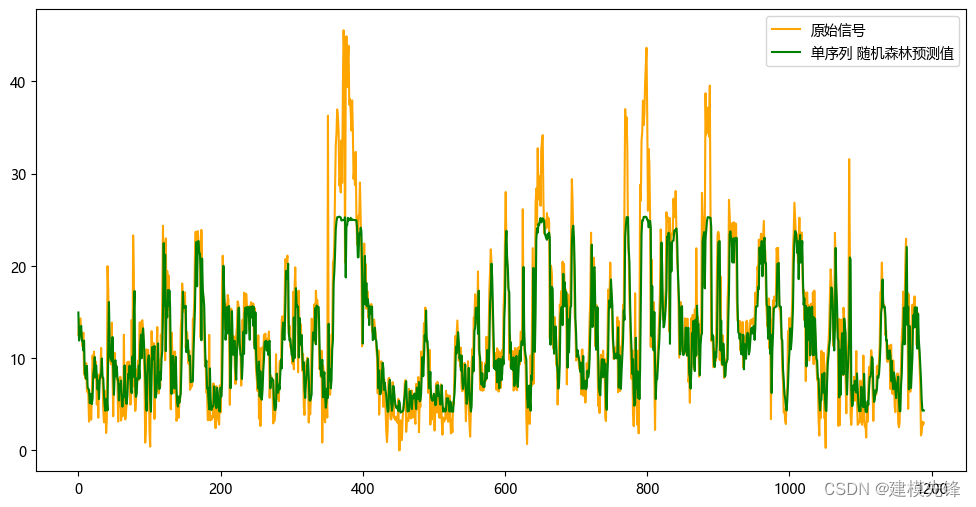 ?
?
3.2 支持向量機SVM預測模型
多特征變量預測
 ?
?
單序列預測
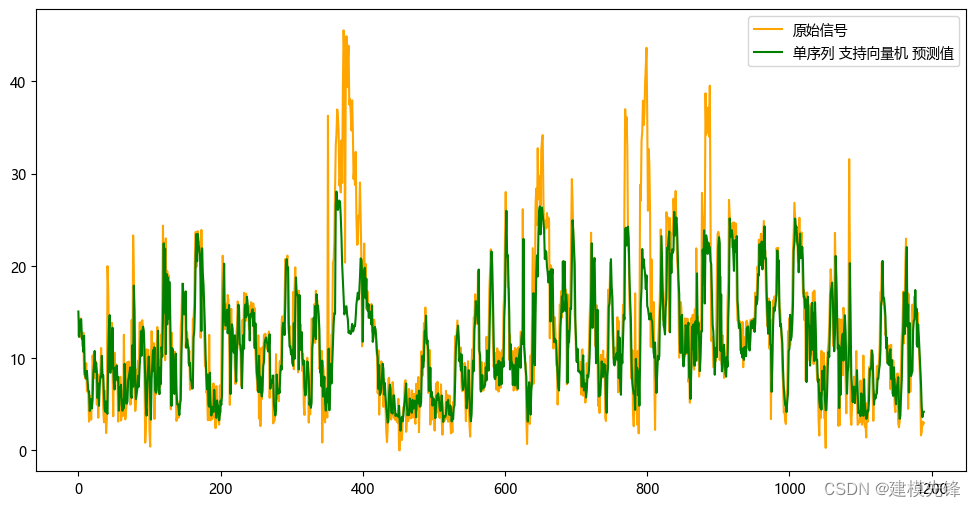 ?
?
3.3 XGBoost分類模型
多特征變量預測
 ?
?
單序列預測
 ?
?
模型評估
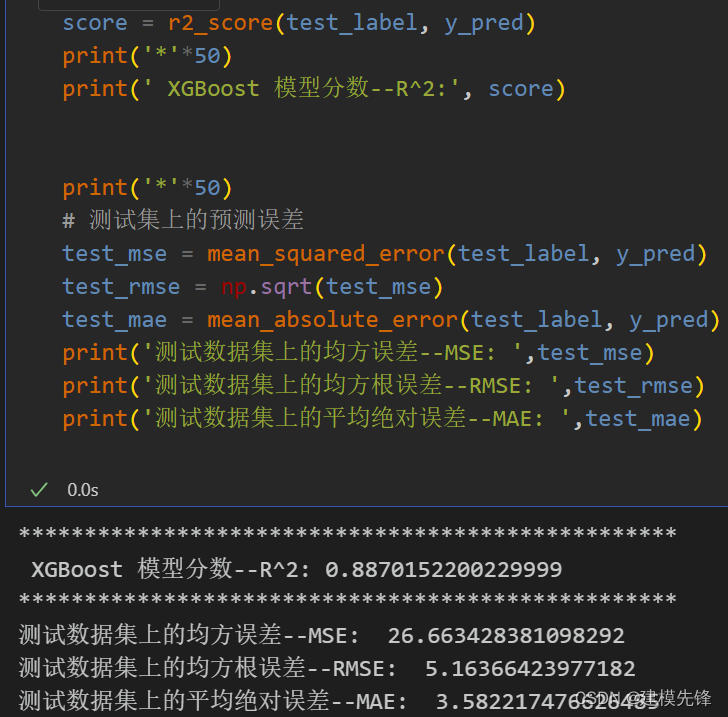 ?
?
對比隨機森林、SVM模型可以看出來,?XGBoost預測模型性能最好,在訓練集、測試集上的表現最優,模型分數也是最高,在此數據集上,單序列預測取得了良好的效果。XGBoost預測模型速度快,性能好,適當調整模型參數,還可以進一步提高模型預測表現。
代碼、數據如下:
 ?
?
 ?
?






)




二叉樹)




)

)
