原文地址:Generative AI Design Patterns: A Comprehensive Guide
使用大型語言模型 (LLM) 的參考架構模式和心理模型
2024 年 2 月 14 日
對人工智能模式的需求
我們在構建新事物時,都會依賴一些經過驗證的方法、途徑和模式。對于軟件工程師來說,這個說法非常正確,但對于生成式人工智能和人工智能本身來說,情況可能并非如此。隨著生成式人工智能等新興技術的出現,我們缺乏充分驗證的模式來支撐我們的解決方案。
在這里,我分享了一些生成式人工智能的方法和模式,這些方法和模式是基于我對LLM在生產中的無數實現的評估。這些模式的目標是幫助減輕和克服生成式人工智能實現中的一些挑戰,如成本、延遲和幻覺。
設計模式列表
- Layered Caching Strategy Leading To Fine-Tuning 使用分層緩存策略驅動微調
- Multiplexing AI Agents For A Panel Of Experts 多路復用AI代理,用于專家模型組合
- Fine-Tuning LLM’s For Multiple Tasks 微調LLM的多任務優化
- Blending Rules Based & Generative 基于規則和生成的混合規則
- Utilizing Knowledge Graphs with LLM’s 利用LLM的知識圖譜
- Swarm Of Generative AI Agents 生成式人工智能代理的群體
- Modular Monolith LLM Approach With Composability 模塊化單體LLM方法與可組合性
- Approach To Memory Cognition For LLM’s LLM的記憶認知方法
- Red & Blue Team Dual-Model Evaluation 紅藍隊雙模型評估
1) 使用分層緩存策略驅動微調

在引入緩存策略和服務到我們的大型語言模型時,我們正在解決成本、冗余和訓練數據等多種因素的組合問題。
通過緩存這些初始結果,系統可以在后續查詢中更快地提供答案,提高效率。關鍵在于當我們有足夠的數據時,通過這些早期交互的反饋來優化更專業的模型。
專業模型不僅簡化了流程,還將人工智能的專業知識針對特定任務進行了定制,使其在精確性和適應性至關重要的環境中非常有效,例如客戶服務或個性化內容創作。
為了開始,有預先構建的服務,如GPTCache,或者使用常見的緩存數據庫(如Redis、Apache Cassandra、Memcached)自己構建。確保在添加額外的服務時監控和測量延遲。
2) 多路復用AI代理,用于專家小組

想象一個生態系統,其中有多個面向特定任務(”代理”)的生成式AI模型,每個生成式AI模型都是其領域的專家,他們同時工作以解決一個查詢。這種多路復用策略能夠產生多樣化的回答,然后將這些回答整合起來,就可以提供更加全面的答案。
這種設置非常適合復雜的問題解決場景,其中問題的不同方面需要不同的專業知識,就像一個團隊中的每個專家都在解決一個更大問題的一部分。
一個更大的模型,比如GPT-4,被用來理解上下文,并將其分解為特定的任務或信息請求,然后傳遞給較小的代理程序。代理程序可以是經過特定任務訓練的較小語言模型,比如Phi-2或TinyLlama,也可以是具有特定個性、上下文提示和功能調用的通用模型,比如GPT或具有特定個性的Llama。
3) 為多個任務進行LLM的微調

在這里,我們同時對多個任務而不是單個任務進行大型語言模型的微調。這種方法促進了知識和技能在不同領域之間的有力轉移,增強了模型的多功能性。
這種多任務學習對于需要處理各種高能力任務的平臺特別有用,例如虛擬助手或人工智能研究工具。這可能潛在地簡化復雜領域的培訓和測試工作流程。
一些用于培訓LLM的資源和包包括DeepSpeed,以及hugs Face ‘ s transformer庫上的訓練函數。
4) 基于混合規則和生成
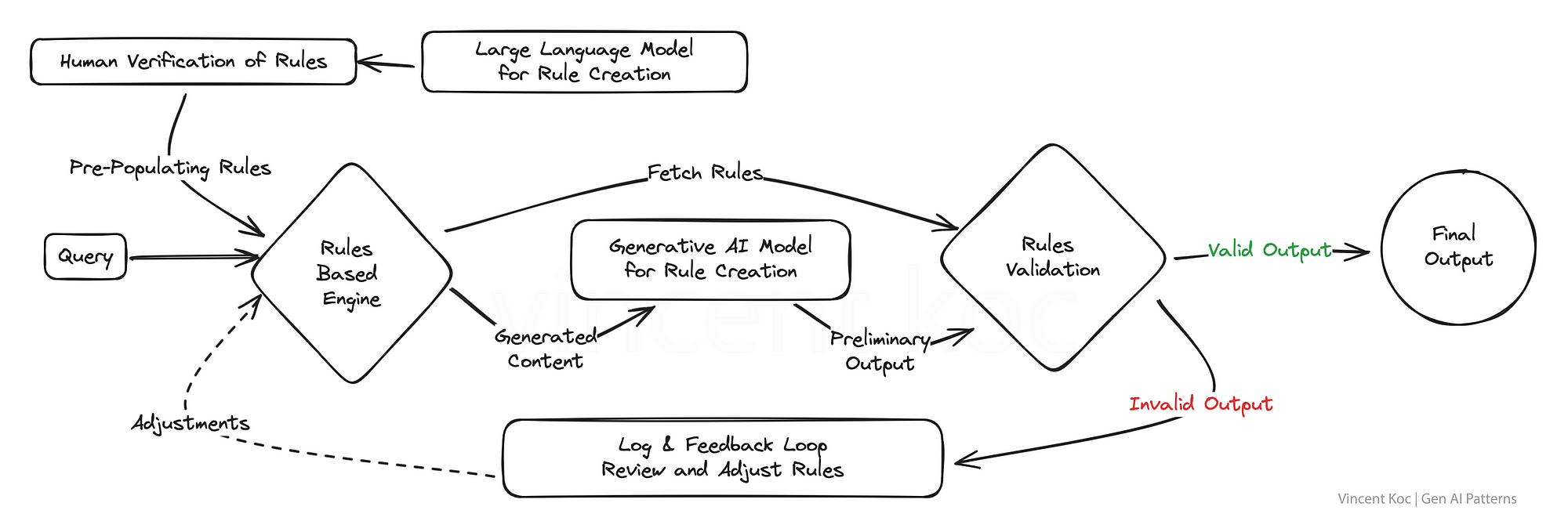
許多現有的業務系統和組織應用程序在某種程度上仍然是基于規則的。通過融合生成和基于規則的邏輯的結構化精度,該模式旨在生成既具有創造性又符合規則的解決方案。
對于輸出必須遵守嚴格標準或法規的行業來說,這是一個強大的戰略,確保人工智能保持在所需參數的范圍內,同時仍然能夠創新和參與。這方面的一個很好的例子是為電話IVR系統或傳統的(非基于llm的)聊天機器人生成意圖和消息流。
5) 結合知識圖譜使用LLM
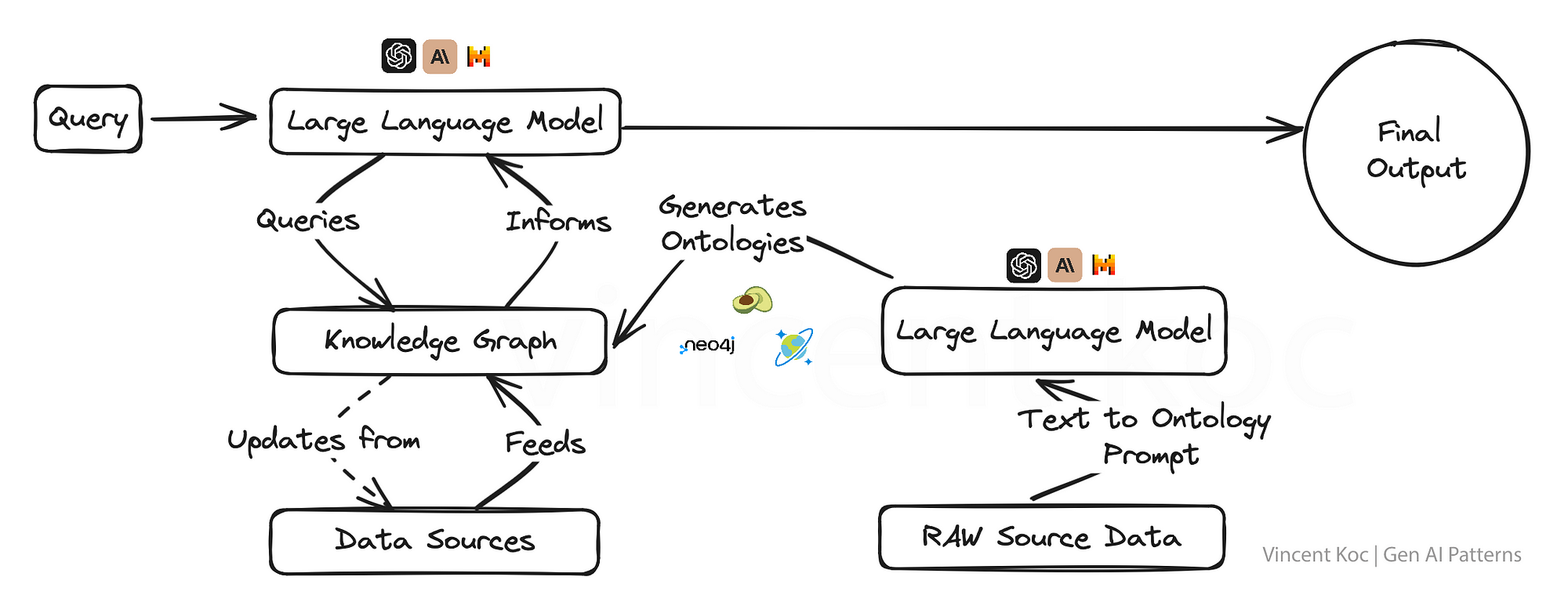
將知識圖與生成式人工智能模型集成在一起,賦予它們以事實為導向的超強能力,允許輸出不僅具有上下文意識,而且更符合事實。
這種方法對于真實性和準確性不容置疑的應用程序至關重要,例如在教育內容創建、醫療建議或任何錯誤信息可能產生嚴重后果的領域。
知識圖和圖本體(圖的概念集)允許將復雜的主題或組織問題分解為結構化格式,以幫助建立具有深度上下文的大型語言模型。您還可以使用語言模型以JSON或RDF等格式生成本體。
您可以用于知識圖譜的服務包括圖形數據庫服務,如ArangoDB,?Amazon Neptune,?Azure Cosmos DB和Neo4j。也有更廣泛的數據集和服務來訪問更廣泛的知識圖譜,包括Google企業知識圖譜API,?PyKEEN數據集和維基數據。
6) AI代理群
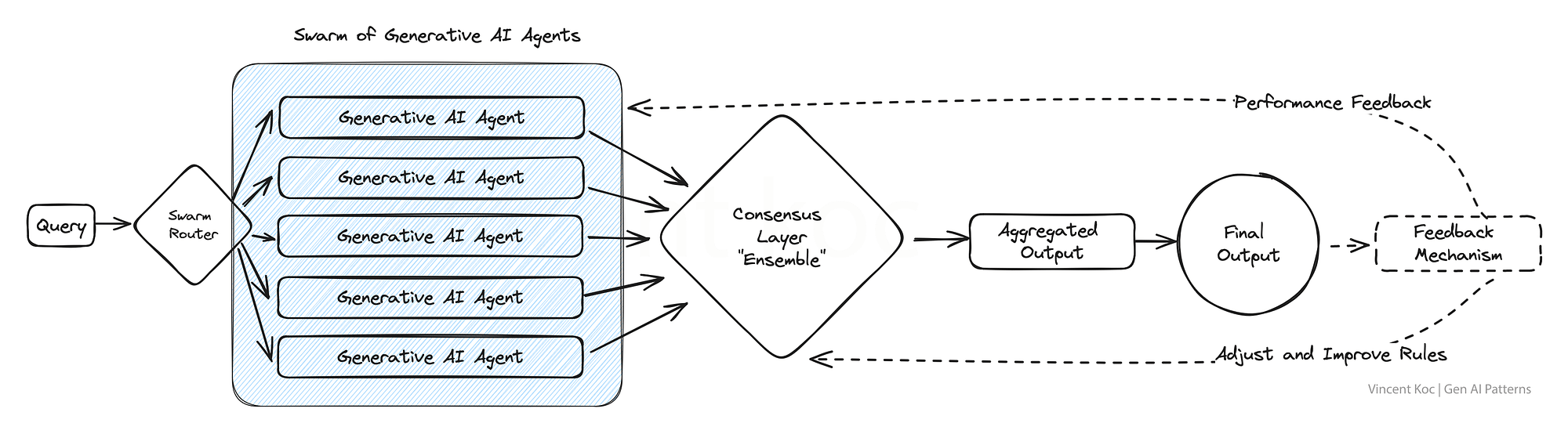
從自然的群體和群居動物中汲取靈感,這個模型采用了大量的人工智能代理,它們共同解決一個問題,每個代理都提供了一個獨特的視角。
由此產生的聚合輸出反映了一種集體智慧,超越了任何個體代理所能達到的水平。這種模式在需要廣泛的創造性解決方案或在處理復雜數據集時特別有優勢。
這方面的一個例子可能是從多“專家”的角度審查一篇研究論文,或者同時評估從欺詐到報價的許多用例的客戶交互。我們把這些集體的“代理”和他們所有的輸入組合在一起。對于大容量集群,你可以考慮部署消息服務,比如Apache Kafka來處理代理和服務之間的消息。
7) 具有可組合性的模塊化單體LLM方法(Moe)
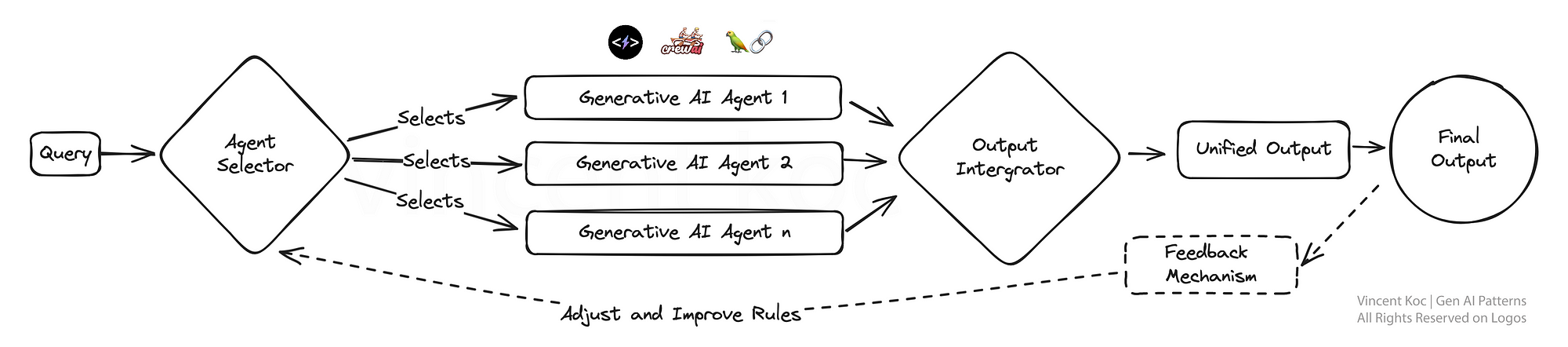
這個設計強調適應性,采用了一個模塊化的人工智能系統,可以根據任務的需要動態重新配置自己以實現最佳性能。就像擁有一把瑞士軍刀一樣,每個模塊可以根據需要選擇和激活,非常適合需要根據不同的客戶互動或產品需求定制解決方案的企業。
您可以部署使用各種自治代理框架和體系結構來開發每個代理及其工具。示例框架包括CrewAI,?Langchain,?Microsoft Autogen和SuperAGI。
對于銷售模塊化單體,這可能是專注于潛在客戶開發的代理,一個處理預訂的代理,一個專注于生成消息的代理,以及另一個更新數據庫的代理。將來,隨著專門的人工智能公司提供特定的組合服務,您可以為一組特定任務或領域特定問題替換模塊以使用外部或第三方服務。
8) LLM的記憶認知方法
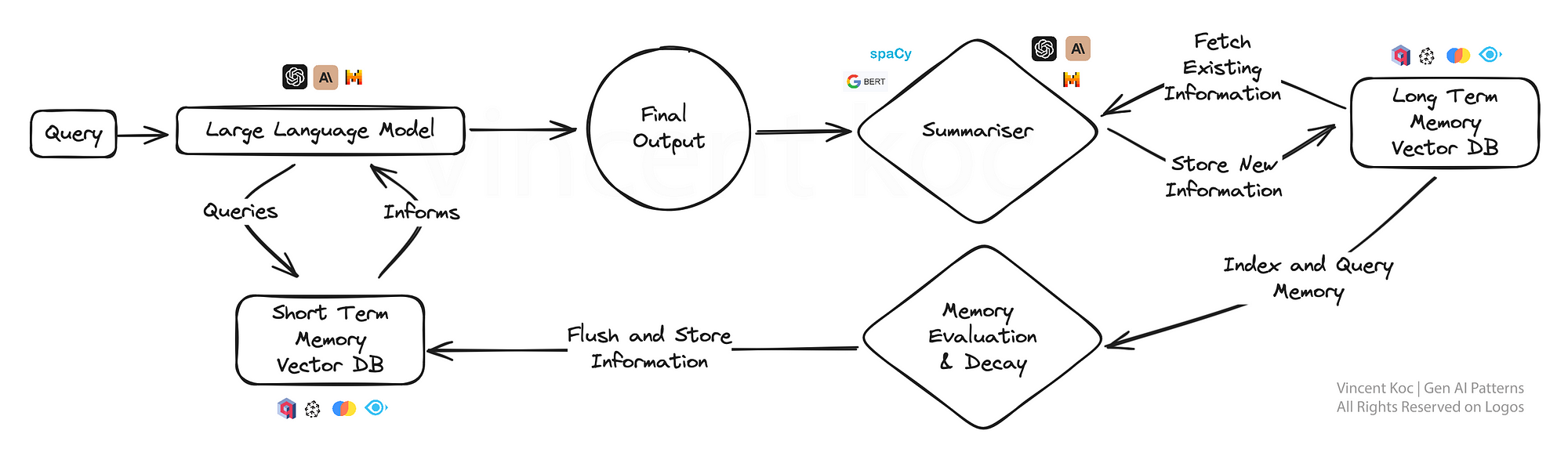
這種方法為人工智能引入了一種類似人類記憶的元素,使模型能夠回憶先前的互動,在這些互動內容的基礎上,提供更加細致入微的回應。
它對于持續的對話或學習場景特別有用,因為人工智能會隨著時間的推移逐漸形成更深入的理解,就像一個專屬的個人助理或適應性學習平臺。通過將關鍵事件和討論總結并存儲到向量數據庫中,可以開發出記憶認知方法。
為了降低總結的計算量,您可以通過較小的NLP庫,如spaCy或BART語言模型來利用求和。使用的數據庫是基于向量的,檢索在提示階段檢查短期記憶使用相似度搜索來定位關鍵的“事實”。對于那些對工作解決方案感興趣的人來說,有一個遵循類似模式的開源解決方案,稱為MemGPT。
為了保持摘要計算的效率,您可以利用較小的自然語言處理庫(如spaCy)或BART語言模型(處理大量數據時)來進行求和。所使用的數據庫是基于向量的,并且在提示階段進行檢索以檢查短期記憶時,使用相似性搜索來定位關鍵的“事實”。對于那些對工作解決方案感興趣的人,有一個名為MemGPT的開源解決方案遵循類似的模式。
9) 紅藍隊雙模型評估
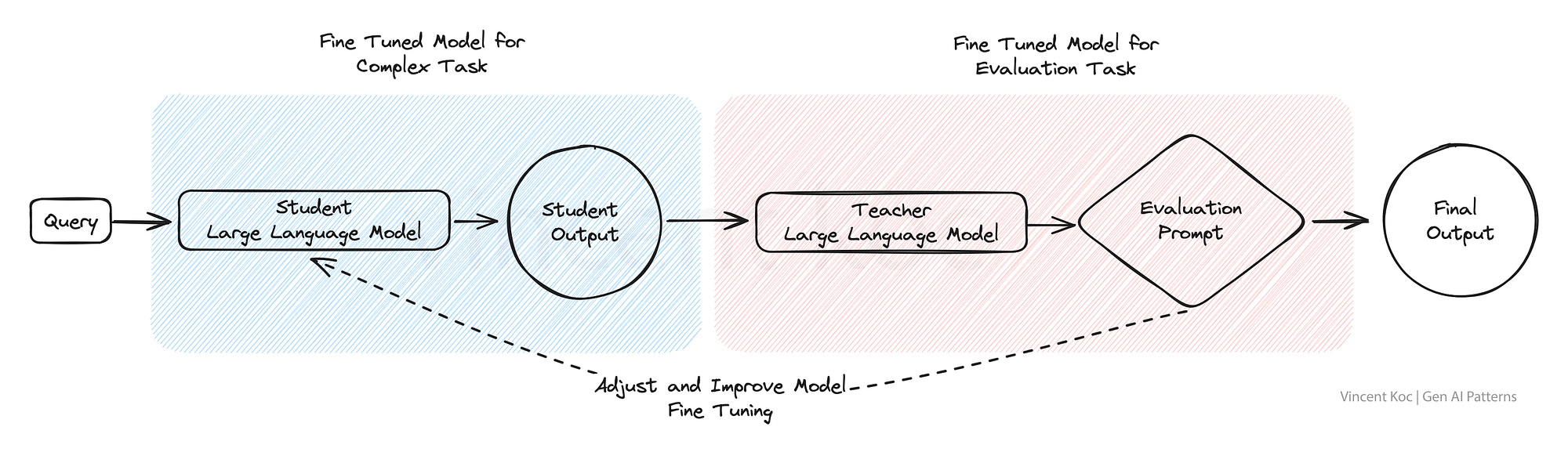
在紅藍團隊評估模型中,一個人工智能生成內容,而另一個人工智能對其進行批判性評估,類似于嚴格的同行評審過程。這種雙模型設置非常適合質量控制,使其非常適用于可信度和準確性至關重要的內容生成平臺,例如新聞聚合或教育材料制作。
此方法可用于用微調模型替換復雜任務的部分人工反饋,以模擬人工審查過程,并改進結果以評估復雜的語言場景和輸出。
要點
這些生成式AI的設計模式不僅僅是模板,而是未來智能系統賴以發展的框架。
這絕不是最終的列表,隨著生成式人工智能的模式和用例的擴展,我們將看到這個空間的發展。這篇文章的靈感來自Tomasz Tunguz發表的AI設計模式(https://tomtunguz.com/ai-design-patterns/)。


二叉樹)




)

)




——多表查詢)




