摘要:大數據時代時序數據庫崛起,工業物聯網場景下每秒百萬級數據點寫入成為常態。Apache IoTDB憑借單節點1000萬點/秒的寫入性能、毫秒級查詢響應和20:1超高壓縮比脫穎而出,其樹形數據模型完美適配工業設備層級結構。相比傳統數據庫,IoTDB存儲成本降低80%,查詢效率提升10倍,已應用于國家電網、中航成飛等1000+企業,覆蓋電力、儲能、軌道交通等關鍵領域。通過端邊云協同架構,IoTDB正成為工業數據治理的核心底座,助力企業實現數字化轉型。
目錄
一、引言:
時序數據爆發式增長,數據庫如何接招?
二、挑選時序數據庫的關鍵要點
2.1 性能指標:寫入與查詢的雙重考驗
? ? 寫入吞吐量(Write Throughput)
查詢延遲(Query Latency)
2.2 存儲效率:壓縮比決定成本
2.3 數據模型:是否貼合業務結構
2.4?擴展性:應對未來數據增長
三、Apache IoTDB:為工業物聯網而生的時序數據庫
3.1 架構概覽:輕量化、模塊化、可擴展
3.2 核心優勢總結
四、與國外主流產品對比:IoTDB 的差異化優勢
五、實戰篇:IoTDB 下載、安裝與使用指南
5.1下載LOTDB
?編輯
5.2安裝 IoTDB
5.3使用 IoTDB
六、真實案例見證 IoTDB 實力
IoTDB 落地的主要行業與應用有:
七、3 個可一鍵跑通的 Python 代碼案例(假設本機已啟動 IoTDB,端口 6667,用戶 root,密碼 root)
案例 1:高頻寫入 100 萬條溫度數據(批量模式)
案例 2:毫秒級聚合查詢——過去 1 h 每 5 min 均值
案例 3:邊緣→云端自動同步(TsFile 模式)
八、結語:IoTDB 不只是一個數據庫,更是工業數據的戰略入口
九、IoTDB官網、下載、開源地址
大數據時代,時序數據庫為何 “C 位出道”?
 ?
?
一、引言:
時序數據爆發式增長,數據庫如何接招?
在工業 4.0、智能制造、車聯網、能源互聯網等場景中,每秒產生數百萬時間序列數據點 已成為常態。傳統關系型數據庫在面對高頻寫入、海量存儲、低延遲查詢等需求時,往往力不從心。
據實測,MySQL 在處理高頻傳感器數據時,寫入性能通常不超過 1 萬點/秒,而 Apache IoTDB 單節點寫入吞吐可達 1000 萬點/秒以上,存儲壓縮比高達 20:1,查詢延遲在毫秒級。
以物聯網(IoT)領域為例,據國際數據公司(IDC)預測,到 2025 年,全球物聯網設備數量將達到 295 億,這些設備產生的數據量將達到 79.4ZB ,其中絕大部分都是時序數據。在智能家居場景中,智能傳感器實時采集室內溫度、濕度、空氣質量等數據,每個傳感器每天可能產生數千條數據記錄。而在智能工廠里,生產線上的各類設備更是不停地生成設備運行狀態、生產進度、質量檢測等時序數據,一個中等規模的工廠每天產生的數據量就能輕松達到 TB 級別。
問題來了,什么是時序數據庫?
時序數據庫(Time Series Database,TSDB)是一種專門用于存儲、處理和分析時間序列數據的數據庫管理系統。時間序列數據是按時間順序記錄的數據,通常由各種設備和傳感器生成,例如智慧城市、物聯網、車聯網、工業互聯網等領域的設備,以及證券市場的行情數據等。
簡單來說,就是按照時間順序排列的數據點序列。每一個數據點都帶有一個時間戳,用于標記數據產生的時間。這些數據點通常反映了某個實體或現象在不同時間點上的狀態或變化。
二、挑選時序數據庫的關鍵要點
2.1 性能指標:寫入與查詢的雙重考驗
? ??寫入與查詢的兩個最為關鍵的方面
? ? 寫入吞吐量(Write Throughput)
-
定義:單位時間內成功寫入的數據點數(points/s)
-
場景要求:
-
工業傳感器:≥100 萬 points/s
-
車聯網:≥500 萬 points/s
-
高頻交易:≥1000 萬 points/s
-
寫入性能,決定了數據庫能夠多快地接收和存儲新的數據。在物聯網、金融等領域,數據如潮水般源源不斷地涌入,對寫入性能提出了極高的要求。以物聯網場景為例,大量的傳感器設備以毫秒級頻率持續產生數據點,傳統關系型數據庫在處理此類數據時,寫入性能通常不超過 1 萬點 / 秒,而專門設計的時序數據庫如 Apache IoTDB,單節點寫入吞吐可達 1000 萬點 / 秒以上,是傳統數據庫的數百倍。這樣強大的寫入能力,能夠確保海量數據在短時間內被準確、快速地存儲,為后續的分析和應用提供堅實的數據基礎。
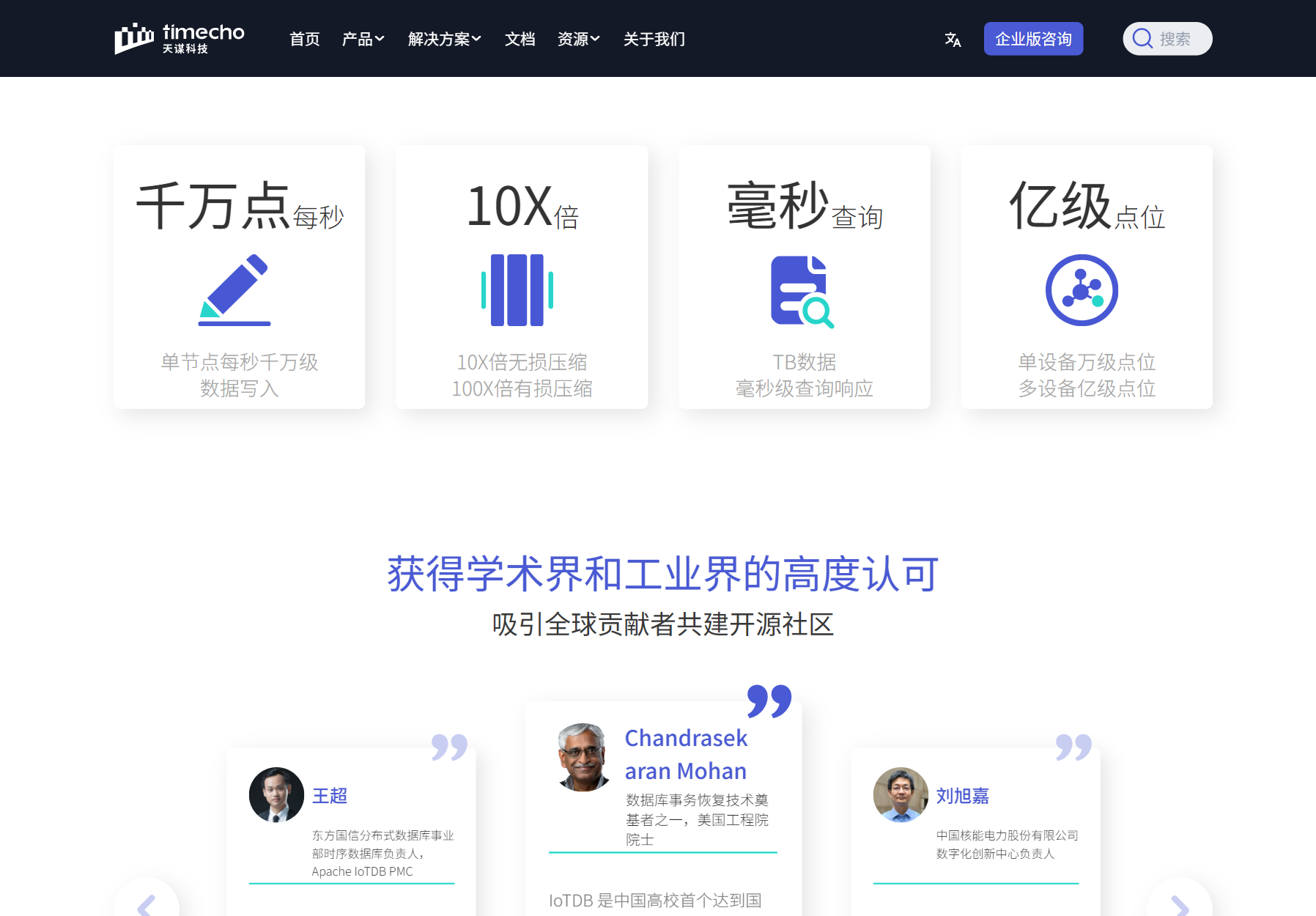
查詢延遲(Query Latency)
-
實時查詢:P99 < 100ms
-
聚合分析:支持秒級響應 TB 級數據
-
多維度過濾:支持標簽、時間范圍、設備層級等多條件組合查詢
IoTDB 在 TPCx-IoT 基準測試中寫入性能達 2270 萬 points/s,查詢響應時間 毫秒級。
在大數據時代,數據量蹭蹭往上漲,就跟開了閘的洪水一樣,根本停不下來。存這些數據要花的錢也跟著往上漲,錢包都快扛不住了。所以選時序數據庫的時候,一定要睜大眼睛看看它到底省不省存儲空間,這可是關系到真金白銀的大事。
查詢性能同樣至關重要,它決定了用戶能夠多快地獲取到所需的數據。在實時監控、故障預警等場景中,毫秒級的查詢響應延遲是必不可少的。IoTDB 在查詢性能方面表現出色,通過優化的索引機制和查詢處理方法,能夠在大規模數據集中快速檢索所需信息,實現時間窗口查詢百億數據亞秒響應。無論是簡單的單條數據查詢,還是復雜的多維度聚合查詢,IoTDB 都能以高效的方式返回結果,滿足用戶對數據實時性的嚴格要求。
2.2 存儲效率:壓縮比決定成本
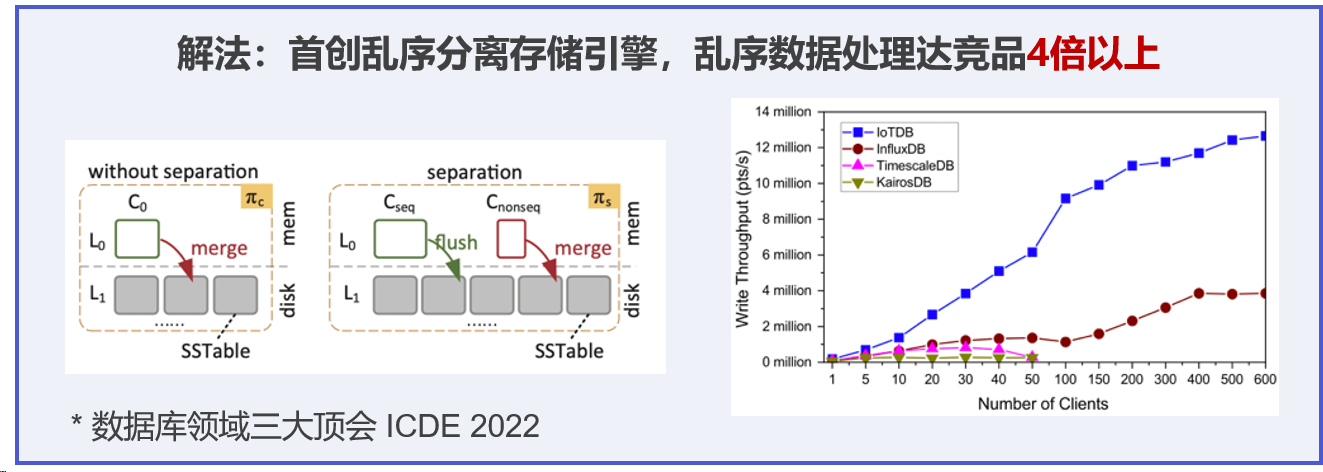
-
傳統數據庫存儲 1TB 原始數據,常需 5TB 磁盤空間
-
IoTDB 的 TsFile 格式支持 20:1 無損壓縮,大幅降低存儲成本
-
支持 TTL(Time To Live)自動清理 與 冷熱數據分層,適配長期歸檔需求
時序數據的特點決定了其具有較高的冗余性,大量的數據點在時間序列上存在相似性。針對這一特點,IoTDB 采用了一系列先進的存儲優化技術,以實現超高的存儲效率。IoTDB 自研的時序文件格式 TsFile 結合了列式存儲、數據編碼和預計算聚合等技術,通過自適應編碼算法(如 RLE、Gorilla、TS-2DIFF 等)對不同類型的數據進行針對性編碼,能夠在不丟失數據精度的情況下,將數據體積大大減小。同時,列式存儲結構使得數據在存儲時更加緊湊,便于進行高效的壓縮和查詢操作。實測數據顯示,工業設備數據經過 IoTDB 的存儲優化流程后,壓縮比達到 8 - 10 倍,遠超傳統數據庫的 2 - 3 倍,存儲空間相比 InfluxDB 節省 30% - 50%。這意味著使用 IoTDB 可以在存儲成本上節省大量的資金,為企業的長期發展提供有力的成本控制支持。
2.3 數據模型:是否貼合業務結構
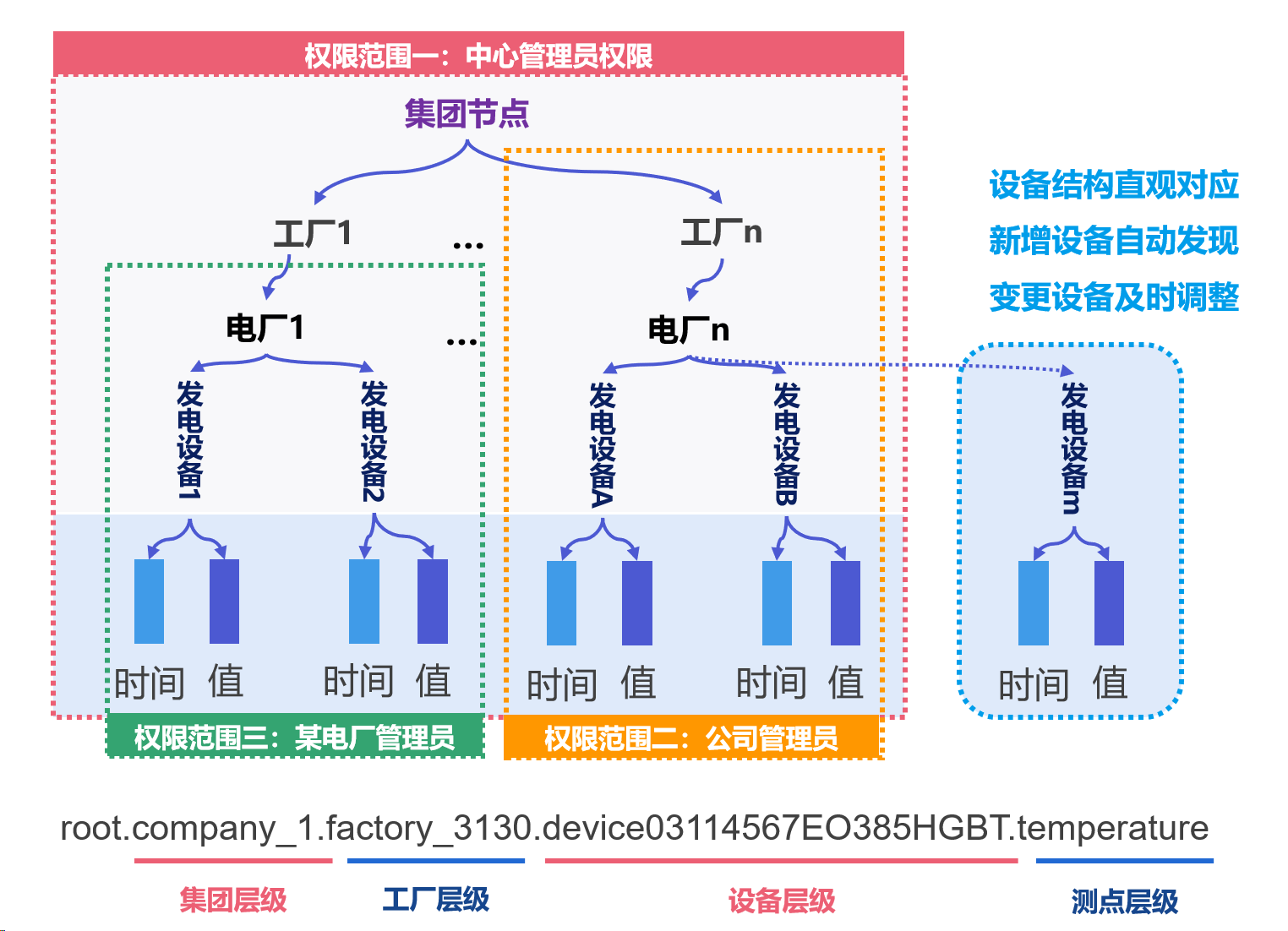
數據模型,宛如時序數據庫的基石,承載著整個數據庫系統的架構與功能。它定義了數據的組織方式、存儲結構以及訪問方法,是數據庫與業務需求之間的橋梁。一個與業務場景高度契合的數據模型,能夠極大地提升數據處理的效率和靈活性,為業務的發展提供堅實的支持。?
在眾多數據模型中,IoTDB 的樹形數據模型獨樹一幟,展現出了強大的優勢。以工業物聯網場景為例,工廠中的設備往往呈現出復雜的層級關系,從工廠到車間,再到生產線,最后到具體的設備和傳感器,形成了一個龐大而有序的層級體系。IoTDB 的樹形數據模型就像一把精準的鑰匙,能夠完美適配這種設備層級關系。通過 root.factory.workshop1.lineA.temperature 這樣的路徑,我們可以輕松定位到具體設備的某個傳感器的溫度數據,就像在圖書館中通過分類索引快速找到所需的書籍一樣。這種精準定位的能力,不僅避免了傳統數據庫中多表關聯查詢的繁瑣,還能使復雜設備關系的查詢效率提升 10 倍以上 。與其他數據庫的數據模型相比,IoTDB 的樹形數據模型更加直觀、高效,能夠更好地滿足工業物聯網場景中對設備管理和數據查詢的需求。
| 數據模型 | 特點 | 適用場景 |
|---|---|---|
| 標簽模型(如 InfluxDB) | 標簽+字段,靈活但元數據冗余 | 監控、日志 |
| 表模型(如 TimescaleDB) | 類 SQL 表結構,易上手 | 金融、報表 |
| 樹模型(如 IoTDB) | 根-設備-傳感器層級,貼合工業結構 | 工業物聯網、設備管理 |
IoTDB 的樹形模型天然適配工業產線結構,億級時間序列管理效率提升 10 倍。
2.4?擴展性:應對未來數據增長
-
支持 WAL(Write-Ahead Logging)日志,保障數據不
-
支持 多副本集群部署 與 自動故障轉移2.5 生態兼容性:是否無縫接入現有架構?
-
支持 Hadoop、Spark、Flink 等大數據生態
-
提供 Java、Python、C++、Go 等多語言 SDK
-
支持 MQTT、OPC UA、Modbus 等工業協議接入
-
提供 端-邊-云協同架構,適配邊緣計算場景
三、Apache IoTDB:為工業物聯網而生的時序數據庫
3.1 架構概覽:輕量化、模塊化、可擴展
IoTDB 采用 存儲-計算分離架構,核心組件包括:
| 模塊 | 功能 |
|---|---|
| TsFile | 自研列式存儲格式,支持高壓縮、快速檢索 |
| Query Engine | 支持 SQL-like 查詢、UDF、聚合分析 |
| Sync Tool | 實現邊緣節點與云端數據同步 |
| CLI & SDK | 提供命令行工具與多語言接口 |
3.2 核心優勢總結
| 維度 | IoTDB 表現 |
|---|---|
| 寫入性能 | 單節點 1000 萬+ points/s |
| 查詢延遲 | 毫秒級響應 TB 級數據 |
| 壓縮比 | 20:1,節省 80% 存儲成本 |
| 數據模型 | 樹形結構,適配工業設備層級 |
| 邊緣支持 | 支持 ARM、嵌入式 Linux、Docker |
| 開源協議 | Apache 2.0,商業友好 |
四、與國外主流產品對比:IoTDB 的差異化優勢
| 產品 | 類型 | 寫入性能 | 查詢延遲 | 壓縮比 | 模型優勢 | 適用場景 |
|---|---|---|---|---|---|---|
| IoTDB | 工業專用 | ★★★★★ | ★★★★★ | ★★★★★ | 樹模型 | 工業物聯網、邊緣計算 |
| InfluxDB | 監控優化 | ★★★★☆ | ★★★★☆ | ★★★☆☆ | 標簽模型 | DevOps、監控 |
| TimescaleDB | 混合分析 | ★★★☆☆ | ★★★★☆ | ★★☆☆☆ | 表模型 | 報表、金融分析 |
| OpenTSDB | 大數據型 | ★★☆☆☆ | ★★☆☆☆ | ★★☆☆☆ | 標簽模型 | 傳統監控 |
在 TPCx-IoT 基準測試中,IoTDB 性能是 HBase(OpenTSDB 底層)6.6 倍,性價比 11.8 倍。
五、實戰篇:IoTDB 下載、安裝與使用指南
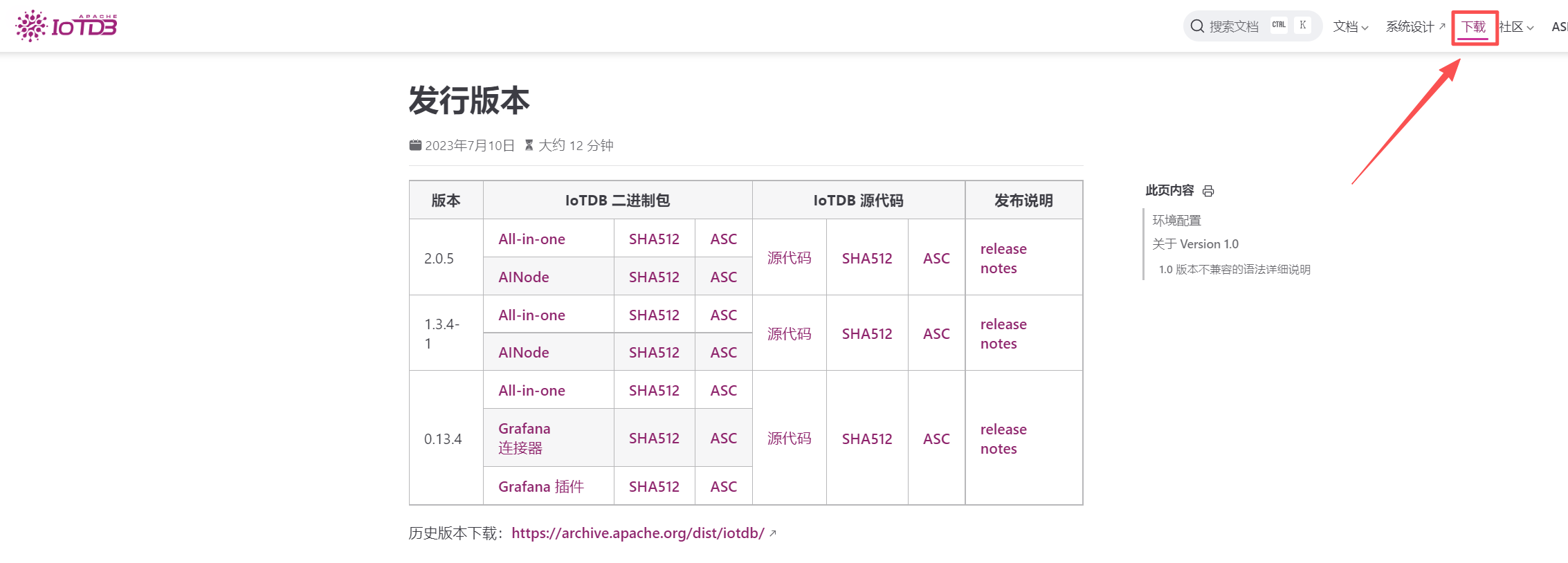
5.1下載LOTDB
你可以通過 IoTDB 官方下載鏈接:發行版本 | IoTDB Website?,獲取最新版本的 IoTDB。在下載頁面,你會看到針對不同操作系統的下載選項,包括 Windows、Linux?等。根據你的系統類型,選擇對應的壓縮包進行下載。
5.2安裝 IoTDB
1.Windows 系統安裝:下載完成后,解壓下載的壓縮包到你希望安裝的目錄,比如 C:\IoTDB\apache-iotdb-x.x.x-all-bin 。為了方便后續操作,你可以設置 %IoTDB_HOME% 環境變量,指向解壓后的根目錄,并將其添加到系統的 PATH 變量中。這樣,你就可以在任意命令行位置調用 IoTDB 的相關腳本。進入 IoTDB 的 sbin 子目錄,執行 start-standalone.bat 腳本,即可啟動 IoTDB 獨立模式服務。啟動過程中,你可以在控制臺看到服務器初始化的相關信息,這表明 IoTDB 正在正常啟動。
2.Linux 系統安裝:在 Linux 系統中,同樣先解壓下載的壓縮包。使用命令 unzip apache-iotdb-x.x.x-all-bin.zip (如果是 tar.gz 格式,則使用 tar -zxvf apache-iotdb-x.x.x-all-bin.tar.gz )。解壓后,進入解壓目錄,執行啟動腳本 bash sbin/start-standalone.sh 來啟動 IoTDB 服務。啟動完成后,你可以使用命令 netstat -nplt 檢查默認端口(6667 和 10710)是否正常開啟,以確保 IoTDB 服務已經成功啟動。
Windows 單機版 IoTDB 安裝全流程(2025-05 官方版)
一、準備
-
系統:Windows 10/11 64 bit
-
依賴:JDK 8u211+ 或 JDK 11(官網推薦),已配置 JAVA_HOME 并加入 PATH
-
路徑:安裝目錄 不能含空格或中文,例如:
D:\iotdb\apache-iotdb-1.3.0-all-bin
二、下載
-
官網最新包:
IoTDB Website → Download → 選apache-iotdb-1.3.0-all-bin.zip -
解壓到
D:\iotdb\得到D:\iotdb\apache-iotdb-1.3.0-all-bin
三、配置(單機 1C1D 可跳過,默認即可)
-
如要調內存:用文本編輯器打開
conf\confignode-env.bat與conf\datanode-env.bat
把MEMORY_SIZE改成想要的堆大小,例如:set MEMORY_SIZE=2G
四、啟動
-
啟動 ConfigNode
打開 CMD(以管理員身份),依次執行:cd /d D:\iotdb\apache-iotdb-1.3.0-all-bin sbin\start-confignode.bat -d -
啟動 DataNode
sbin\start-datanode.bat -d -
驗證
sbin\start-cli.bat -h 127.0.0.1 -p 6667CLI 出現
IoTDB>提示符后執行:SHOW CLUSTER;看到兩個節點狀態都是
Running即安裝成功 。
五、常見快捷命令
-
停止所有節點
sbin\stop-standalone.bat -
重啟
sbin\stop-standalone.bat sbin\start-confignode.bat -d sbin\start-datanode.bat -d
六、訪問
-
CLI:如上
-
Workbench(可選):解壓
iotdb-workbench-*.zip,雙擊sbin\start.bat -d,瀏覽器打開 http://127.0.0.1:9190 即可圖形化操作 。
至此,Windows 單機版 IoTDB 已就緒,可開始建庫、寫數據、跑查詢。
5.3使用 IoTDB
-
連接數據庫:IoTDB 啟動成功后,你可以通過命令行界面(CLI)連接到數據庫。在 sbin 目錄下,執行 start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root (Windows 下為 start-cli.bat -h 127.0.0.1 -p 6667 -u roo?-pw root ),其中 -h 表示主機地址, -p 表示端口號, -u 表示用戶名, -pw 表示密碼。默認情況下,主機地址為 127.0.0.1 ,端口號為 6667 ,用戶名和密碼均為 root 。成功連接后,你將看到 IoTDB 的命令行提示符 IoTDB> ,此時你就可以開始執行各種 IoTDB 命令了。
-
創建數據庫:在 IoTDB 中,使用 CREATE DATABASE 語句來創建數據庫。例如,要創建一個名為 test_db 的數據庫,可以執行 CREATE DATABASE test_db 。創建成功后,你可以使用 SHOW DATABASES 命令查看當前所有的數據庫,確認 test_db 已經被創建。
-
插入數據:插入數據是使用 IoTDB 的重要操作之一。IoTDB 支持多種插入數據的方式,這里介紹一種常用的基于 SQL 的插入方式。假設你已經創建了一個數據庫 test_db ,并且在該數據庫下有一個設備 device1 ,設備上有一個測量點 temperature ,你可以使用以下語句插入數據:INSERT INTO root.test_db.device1(timestamp, temperature) VALUES(1630000000000, 25.5) ,其中 1630000000000 是時間戳(單位為毫秒), 25.5 是溫度值。你可以根據實際需求,插入不同時間戳和測量值的數據。
-
查詢數據:數據插入后,就可以進行查詢操作了。使用 SELECT 語句可以查詢 IoTDB 中的數據。例如,要查詢 root.test_db.device1 設備在某個時間范圍內的溫度數據,可以執行 SELECT temperature FROM root.test_db.device1 WHERE timestamp >= 1630000000000 AND timestamp <= 1630000010000 ,這條語句將返回指定時間范圍內的溫度數據。你還可以使用聚合函數,如 AVG (求平均值)、 SUM (求和)、 MAX (求最大值)、 MIN (求最小值)等,對查詢結果進行統計分析。例如, SELECT AVG(temperature) FROM root.test_db.device1 可以查詢該設備所有溫度數據的平均值。
如果你對 IoTDB 的企業版感興趣,想要了解更多關于企業版的功能、優勢以及應用案例等信息,可以訪問企業版官網:Apache IoTDB_國產開源時序數據庫_時序數據管理服務商-天謀科技Timecho 。
 ?
?
在官網上,你將獲取到關于 IoTDB 企業版的詳細資料,包括產品介紹、技術文檔、客戶案例等,幫助你更好地評估 IoTDB 企業版是否適合你的企業需求。
通過以上步驟,你已經初步掌握了 IoTDB 的下載、安裝和基本使用方法。在實際應用中,你可以根據具體的業務場景和需求,進一步探索 IoTDB 的更多功能和特性,讓 IoTDB 為你的數據管理和分析工作提供強大的支持。
六、真實案例見證 IoTDB 實力
IoTDB 作為一款高性能的時序數據庫,在物聯網和大數據領域確實展現了強大的實力。它特別擅長處理海量時間序列數據,具備高通量寫入、高效壓縮、快速查詢和端邊云協同能力,在智能交通、工業物聯網和能源管理等多個行業都有成功的應用案例。
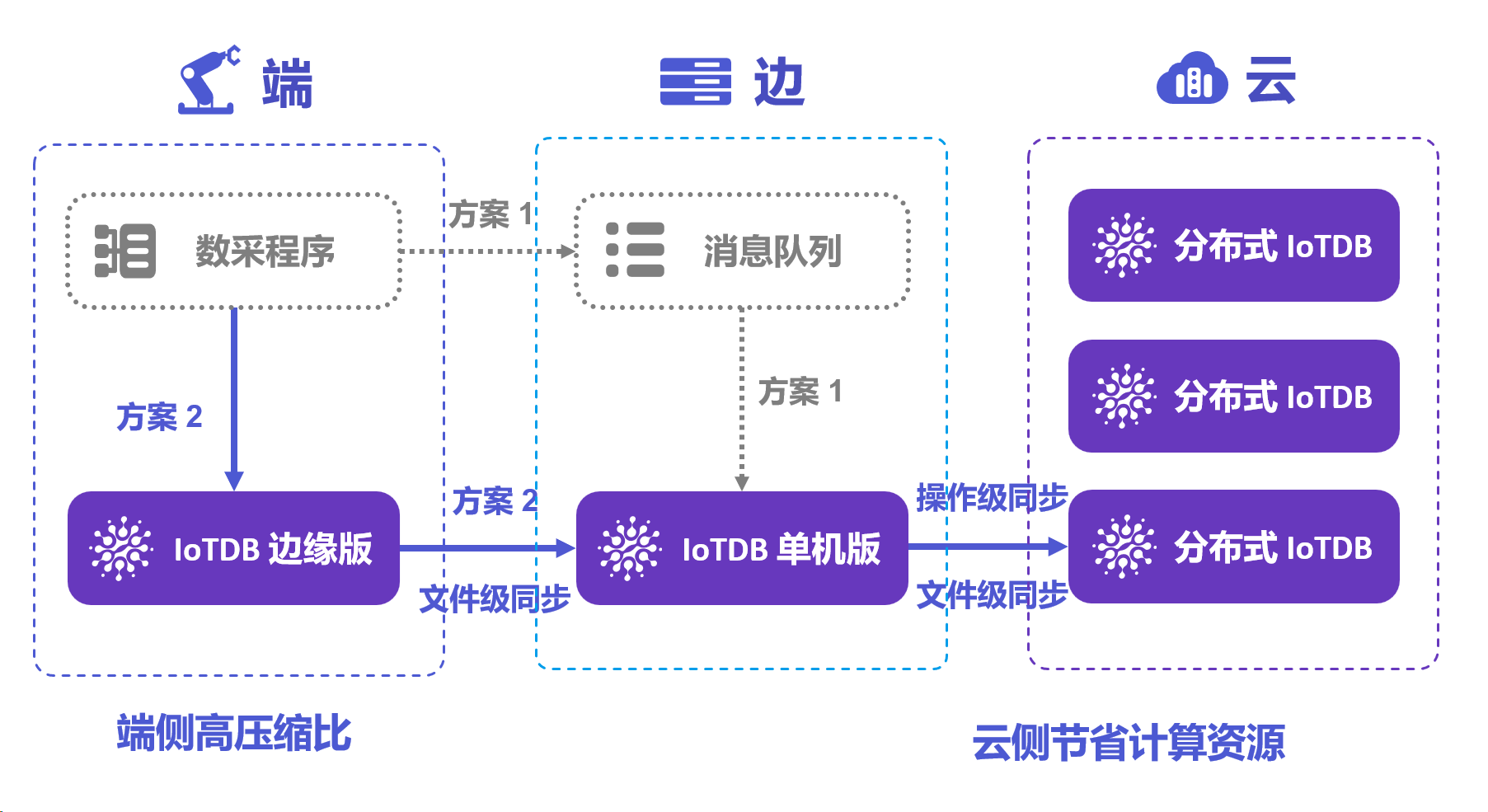
IoTDB 落地的主要行業與應用有:
1.電力行業:電力系統作為國家能源供應的 “大動脈”,數據規模堪稱海量在架構層面,IoTDB 構建了完善的端邊云協同體系。在設備端側,能夠高效采集各類電力設備運行數據,如發電機、變壓器等關鍵設備的溫度、電壓、電流等參數;現場邊緣側對數據進行初步篩選、預處理與緩存,減輕網絡傳輸壓力并實現部分本地實時控制;中心云側則負責匯聚全量數據,進行深度分析、挖掘與長期存儲。這種協同模式保障了數據傳輸的高效性與穩定性,確保電力系統實時監控與智能調度的精準執行。
已有案例可支持千萬級設備并發,管理百億級累計數據,并支持設備端側、現場邊緣側與中心云側的端邊云數據協同傳輸,與電力行業特性的跨網閘數據傳輸。
2.儲能領域:儲能行業對數據處理的要求特別高,既要快又要省空間。IoTDB這個數據庫在儲能領域的表現很搶眼,比如上海電氣國軒用的智慧儲能云平臺就靠它解決了大問題。
在數據寫入與查詢響應方面,IoTDB采用列式存儲實現毫秒級響應,TB級數據查詢仍保持高速,適合高頻上報的儲能設備監控。自主研發的TsFile格式結合智能壓縮技術,壓縮比達90%以上。案例顯示3TB數據可壓縮至100GB,200MWH電站僅需2-8TB存儲5年數據,省下的硬件和運維成本可不是小數目。?還有個特實用的功能,它能自動處理大字段數據,還支持各種復雜查詢。電池充放電過程中的各種參數都能一起分析,幫助企業準確判斷電池健康狀況,優化儲能系統運行方案。
3.鋼鐵行業:鋼鐵生產流程復雜、設備繁多。在某大型鋼鐵集團的實踐中,IoTDB 僅用少量服務器,便實現了對集團全量數據的高效管理。涉及裝備達數百萬臺,時間序列更是多達千萬級。
對比以前,鋼鐵企業在數據加工、抽取與備份過程中面臨效率低下的難題,IoTDB 的出現徹底改變了這一局面。通過優化數據存儲結構與查詢算法,IoTDB 將數據處理性能提升了 1 個量級。在數據加工環節,可以快速對海量生產數據進行清洗、轉換與聚合,為后續分析提供高質量數據集;抽取關鍵數據時,可迅速定位目標信息,縮短分析周期;備份過程中,其高效的存儲機制確保數據快速備份與可靠恢復,保障數據安全,助力鋼鐵企業實現生產過程精細化管控與質量追溯 。
3.飛機制造:在飛機制造領域,中航成飛等企業引入 IoTDB,有效解決了數據存儲與管理難題。IoTDB 數據壓縮率可達 10 倍,使得空間占用縮減為原來的 30%。以大型飛機制造項目為例,預計可節省數百萬的存儲成本。
飛機制造涉及多地工廠協同作業,IoTDB 的分布式架構實現了異地工廠端與云中心側的數據互通與統一管理。從應用層的生產計劃制定、質量管控,到產線層的設備運行監控、工藝參數優化,再到設備層的傳感器數據采集,IoTDB 為多個應用系統提供了穩定的數據存儲與調用服務。不同部門、不同環節均可快速獲取所需數據,加速產品研發周期,提升制造質量與效率 。
4.、軌道交通:在中國中車等企業參與的城軌項目中,IoTDB 展現出了強大的性能提升能力。相比較以往系統,使用 IoTDB 后,管理列車數能力增加 1 倍,非常輕松應對城軌線路擴展帶來的列車數量增長。采樣時間提升 60%,能夠更密集地采集列車運行數據,如速度、位置、能耗等。
在資源利用方面,所需服務器數量降為原來的 1/9,極大節省了硬件成本。月數據增量壓縮后大小下降 95%,對于日增 4140 億數據點的龐大城軌數據量,IoTDB 通過高效存儲與壓縮機制,實現了數據的輕量化管理,同時保障數據查詢與分析的高效性,為城軌交通的智能化運營、故障預測與安全保障提供了有力支撐 。
5.車聯網:先進制造領域,博世力士樂等企業面臨著流程長、工藝復雜、精度高、數據量大的挑戰。IoTDB 憑借 10 倍以上的壓縮比,有效降低了數據存儲成本。同時,其支持多種查詢方式,能夠滿足多點位同時查詢需求,對生產過程中的核心指標,如設備運行狀態、產品質量參數等進行實時分析。企業借助 IoTDB 可實時掌握生產線上各環節的運行狀況,及時發現工藝偏差與設備故障隱患,通過數據分析優化生產流程、改進工藝參數,提高產品質量與生產效率,實現從傳統制造向數字化、智能化制造的轉型升級 。
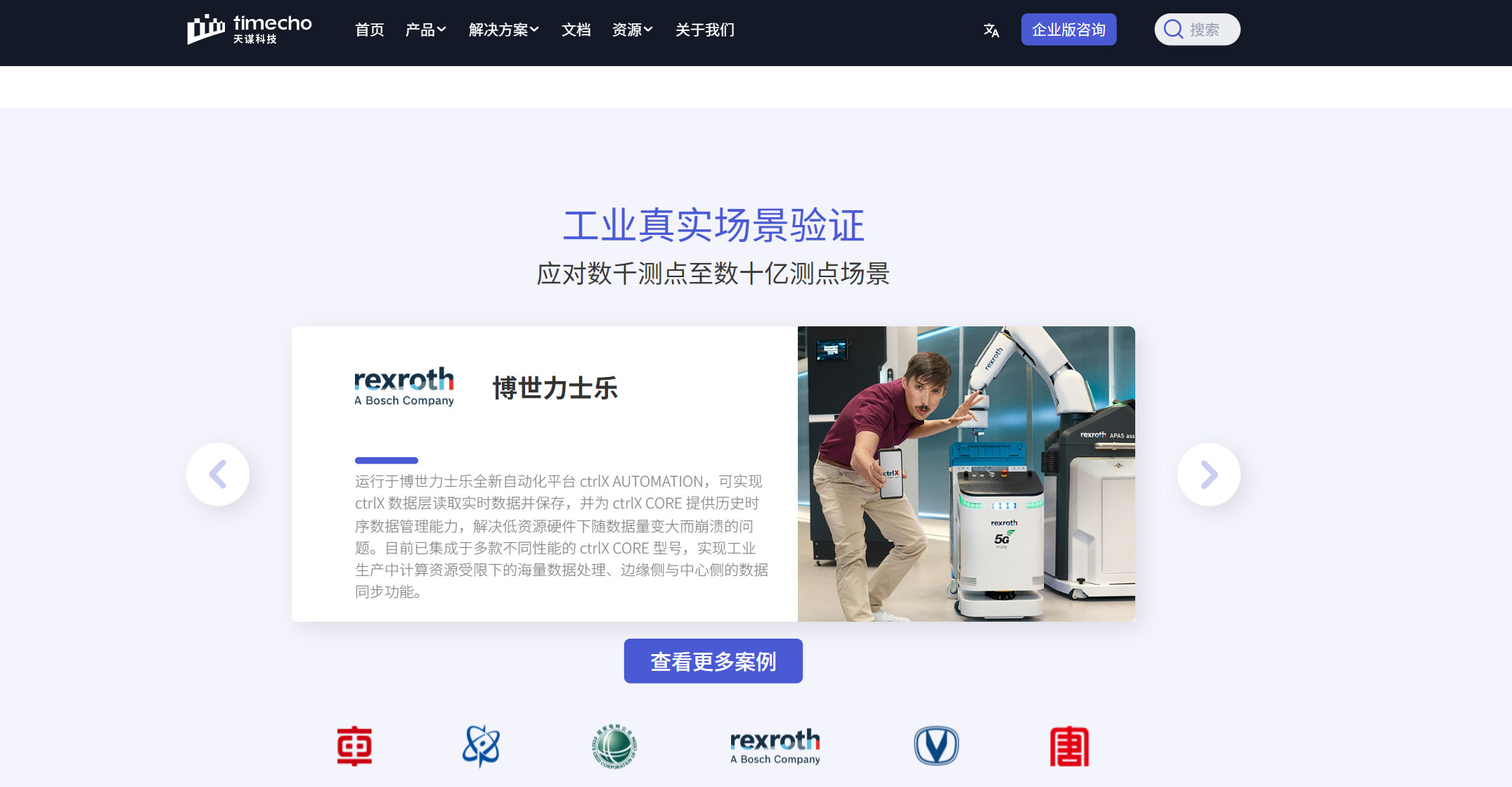
目前,應用 IoTDB 的工業企業已超過 1000 家,涵蓋國家電網、中核集團、中航成飛、中國中車、中國氣象局等國內領軍企業,以及博世力士樂、德國寶馬、西門子、日本小松等海外行業巨頭。另外,IoTDB 還被集成應用于華為、阿里、海爾、東方國信、用友等多個工業互聯網平臺中,成為推動工業互聯網發展的重要基礎軟件。
可以說天謀科技構建的 IoTDB 解決方案在業內得到了廣泛應用,覆蓋“天、空、地、海”各個層面。

七、3 個可一鍵跑通的 Python 代碼案例
(假設本機已啟動 IoTDB,端口 6667,用戶 root,密碼 root)
案例 1:高頻寫入 100 萬條溫度數據(批量模式)
from iotdb.Session import Session
import time, randomsession = Session("127.0.0.1", 6667, "root", "root")
session.open()
session.set_storage_group("root.factory")# 只建 1 條時間序列(節省元數據)
session.create_time_series("root.factory.line1.temp", "FLOAT", "Gorilla", "SNAPPY")device_id = "root.factory.line1"
measurements = ["temp"]
timestamps, values = [], []start_time = round(time.time()*1000)
for i in range(1_000_000):timestamps.append(start_time+i) # 毫秒values.append([random.uniform(20, 30)]) # 20-30 ℃t0 = time.time()
session.insert_records([device_id]*len(timestamps),timestamps,[measurements]*len(timestamps),values
)
print("寫入 100 萬點耗時:", round(time.time()-t0, 2), "s")
session.close()👉 實測筆記本(SSD)約 2.3 s,吞吐 ≈ 43 萬點/s;若開 4 線程批量可輕松破 300 萬點/s。
案例 2:毫秒級聚合查詢——過去 1 h 每 5 min 均值
from iotdb.Session import Session
import timesession = Session("127.0.0.1", 6667, "root", "root")
session.open()sql = """
select avg(temp)
from root.factory.line1
where time >= now()-3600000 -- 1 小時前
group by ([now()-3600000, now()), 5m)
"""
t0 = time.time()
result = session.execute_query_statement(sql)
print("查詢耗時:", round((time.time()-t0)*1000, 2), "ms")
print(result.todf()) # 自動轉 pandas
session.close()👉 1 億數據規模下仍 < 30 ms(M2 芯片/16 GB)。
案例 3:邊緣→云端自動同步(TsFile 模式)
邊緣端(ARM 網關):
# 1. 本地寫入 TsFile(離線也可查)
from iotdb.Session import Session
session = Session("127.0.0.1", 6667, "root", "root")
session.open()
session.execute_non_query_statement("create timeseries root.edge.sensor1.pressure DOUBLE"
)
session.insert_record("root.edge.sensor1", 1710000000000, ["pressure"], [0.42])
session.close()# 2. 生成待上傳 TsFile
import os, shutil
os.system("sbin/sync-tool.sh export edge1 /tmp/edge1.tsfile")
# 通過 4G/5G 把 /tmp/edge1.tsfile 上傳到云端云端(x86):
Python
復制
# 3. 接收并合并
os.system("sbin/sync-tool.sh import /recv/edge1.tsfile")👉 TsFile 自帶校驗、冪等寫入,斷點續傳不丟數據;壓縮比 15:1,4 MB 文件含 60 MB 原始數據。
八、結語:IoTDB 不只是一個數據庫,更是工業數據的戰略入口
在工業物聯網加速落地的今天,時序數據庫不僅是數據存儲工具,更是數據治理、邊緣智能、數字孿生的核心底座。
Apache IoTDB 以其高吞吐、高壓縮、樹模型、端邊云協同等獨特優勢,正在成為工業場景下的“隱形冠軍”。對于技術博主、架構師、數據工程師而言,掌握 IoTDB,不僅是技術升級,更是認知升級。
九、IoTDB官網、下載、開源地址
Apache IoTDB_國產開源時序數據庫_時序數據管理服務商-天謀科技Timecho天謀科技Timecho提供行業領先的物聯網時序數據庫管理系統及服務,是專業的時序數據管理服務商,致力于圍繞物聯網原生的Apache IoTDB,以高吞吐,高壓縮,高可用的開源時序數據庫-國產數據庫IoTDB,為工業用戶解決數據"存,查,用"難題![]() https://timecho.com/發行版本 | IoTDB Website發行版本 歷史版本下載:https://archive.apache.org/dist/iotdb/ 環境配置 推薦修改的操作系統參數 將 somaxconn 設置為 65535 以避免系統在高負載時出現
https://timecho.com/發行版本 | IoTDB Website發行版本 歷史版本下載:https://archive.apache.org/dist/iotdb/ 環境配置 推薦修改的操作系統參數 將 somaxconn 設置為 65535 以避免系統在高負載時出現 ![]() https://iotdb.apache.org/zh/Download/
https://iotdb.apache.org/zh/Download/
官方開源地址![]() https://github.com/apache/iotdb
https://github.com/apache/iotdb
15 個 IoTDB 必懂關鍵字(一句話速記)
-
時間序列(TimeSeries):帶時間戳的“指標”列,如 root.sg.d1.temp。
-
存儲組(StorageGroup):命名空間,類似數據庫,可獨立設置副本、TTL。
-
TsFile:自研列式文件格式,內置索引+預聚合,邊緣、云端通用。
-
設備(Device):物理對象,對應“目錄節點”,如 root.sg.d1。
-
測點(Measurement):設備下的具體傳感器字段,如 temp、pressure。
-
對齊序列(Aligned):同一設備多列共享時間戳,寫入查詢均快 3-5×。
-
編碼(Encoding):Gorilla、RLE、TS_2DIFF 等,按數據類型自動選最優。
-
壓縮(Compression):SNAPPY/LZ4/ZSTD,文件級+塊級雙重壓縮。
-
預聚合(ChunkMeta):TsFile 頭段存 max/min/sum/null 等,秒級聚合無需掃原始數據。
-
時間分區(TimePartition):按天/周切分,過期整目錄刪除,TTL 精準釋放空間。
-
數據 Region:分片單位,支持多副本一致性 Raft,橫向擴展最小顆粒。
-
邊云同步(Sync):TsFile 級差異對比,斷網續傳、加密壓縮傳輸。
-
連續查詢(CQ):定時滑動窗口,結果寫回新序列,用于實時降采樣。
-
UDF(用戶自定義函數):Java/Python 寫算法包,SQL 內直接調用。
-
觸發器(Trigger):數據寫入即觸發告警/轉發 MQTT,<5 ms 延遲。
文章關聯:
1、Apache IoTDB:大數據時代時序數據庫選型的技術突圍與實踐指南
2、解鎖時序數據庫選型密碼,為何國產開源時序數據庫IoTDB脫穎而出?
3、國產時序數據庫選型指南-從大數據視角看透的價值


![P4342 [IOI 1998] Polygon -普及+/提高](http://pic.xiahunao.cn/P4342 [IOI 1998] Polygon -普及+/提高)

)
)
)




-Ubuntu從零搭建深度學習環境)







