

?博客主頁: https://blog.csdn.net/m0_63815035?type=blog
💗《博客內容》:大數據、Java、測試開發、Python、Android、Go、Node、Android前端小程序等相關領域知識
📢博客專欄: https://blog.csdn.net/m0_63815035/category_11954877.html
📢歡迎點贊 👍 收藏 ?留言 📝
📢本文為學習筆記資料,如有侵權,請聯系我刪除,疏漏之處還請指正🙉
📢大廈之成,非一木之材也;大海之闊,非一流之歸也?

前言&課程重點(day02)
大家好,我是程序員小羊!接下來一周,咱們將用 “實戰拆解 + 技術落地” 的方式,帶大家吃透一個完整的大數據電商項目 ——不管你是想靠項目經驗敲開大廠就業門,還是要做畢業設計、提升技術深度,這門課都能幫你 “從懂概念到能落地”。
畢竟大數據領域不缺 “會背理論” 的人,缺的是 “能把項目跑通、能跟業務結合” 的實戰型選手。咱們這一周的內容,不搞虛的,全程圍繞 “電商業務痛點→數據解決方案→技術棧落地” 展開,每天聚焦 1 個核心模塊,最后還能輸出可放進簡歷的項目成果。
進入正題:
本項目是一門實戰導向的大數據課程,專為具備Java基礎但對大數據生態系統不熟悉的同學量身打造。你將從零開始,逐步掌握大數據的基本概念、架構原理以及在電商流量分析中的實際應用,迅速融入當下熱門的離線數據處理技術。
在這門課程中,你將學會如何搭建和優化Hadoop高可用環境,了解HDFS存儲、YARN資源調度的核心原理,為數據處理打下堅實的基礎。同時,你將掌握Hive數據倉庫的構建和數倉建模方法,了解如何將海量原始數據經過層次化處理,轉化為高質量的數據資產。
課程還將引領你深入Spark SQL的世界,通過實際案例學習如何利用Spark高效計算PV、UV以及各類衍生指標,提升數據分析效率。此外,你還將學習Flume的安裝與配置,實現Web日志的實時采集和ETL入倉,確保數據傳輸的穩定與高效。
為了貼近企業實際運作,本項目還包括定時任務的設置和自動化數據管道構建,教你如何編寫Shell腳本并利用crontab定時調度Spark作業,讓數據處理過程實現自動化與智能化。最后,通過可視化展示模塊,你將學會用FineBI等工具將數據分析結果直觀呈現
總之,這是一門集大數據基礎、系統搭建、數據處理與智能分析于一體的全鏈路實戰課程。無論你是初入大數據領域的新手,還是希望提升數據處理能力的開發者,都將在這里收獲滿滿,掌握最前沿的大數據技術。
課程計劃:
| 天數 | 主題 | 主要內容 |
|---|---|---|
| Day 1 | 大數據基礎+項目分組 (ZK補充) | 大數據概念、數倉建模、組件介紹、分組;簡單介紹項目。 |
| Day 2 | Hadoop初認識+ HA環境搭建 | 初認識Hadoop,了解HDFS 基本操作,YARN 資源調度,數據存儲測試等,并且完成Hadoop高可用的環境搭建。 |
| Day 3 | Hive 數據倉庫 | Hive SQL 基礎、表設計、加載數據,搭建Hive環境并融入Hadoop實現高可用 |
| Day 4 | Spark SQL 基礎 | 講解Spark基礎,DataFrame & SQL 查詢,Hive 集成和環境的搭建 |
| Day 5 | Flume 數據采集及ETL入倉 | 安裝Flume高可用,學習基礎的Flume知識并且使用Flume 采集 Web 日志,存入 HDFS;數據格式解析,數據傳輸優化 |
| Day 6 | 數據入倉 & 指標計算 | 解析 PV、UV 計算邏輯,Hive 數據清洗、分層存儲(ODS → DWD) |
| Day 7 | Spark 計算 & 指標優化 | 使用 Spark SQL 計算 PV、UV 及衍生指標(如跳出率、人均訪問時長等) |
| Day 8 | 定時任務 & 數據管道 | 編寫 Shell 腳本,使用 crontab 實現定時任務,調度 Spark SQL |
| Day 9 | 可視化 & 數據分析 | 搭建一個簡單的項目使用 FineBI 進行數據展示,分析趨勢。 |
| Day 10 | 項目答辯 | 小組演示分析結果,可以后臺聯系程序員小羊點評 |
今日學習重點:
大數據Hadoop的三大組件:HDFS 分布式文件存儲,MapReduce 分布式計算引擎,YARN 分布式資源調度
文章將會展示:大數據的概述,Hadoop的概述,Hadoop安裝部署,HDFS Shell,HDFS Block,HDFS 工作機制,HDFS API,HDFS 命令行操作,HDFS 高級操作,MR設計思想,MR入門案例,Hadoop序列化機制,MapReduce 運行流程,MapReduce Shuffle,YARN設置思想,YARN JOB提交,YARN隊列和標簽。
Hadoop安裝
安裝并配置可用的 Hadoop 集群環境時,可以選擇不同的部署模式,包括 單機模式、偽分布式模式 和 完全分布式模式。然而,在生產環境中,為了確保 高可用性(HA),搭建 HA 集群是必不可少的。如果不配置 HA,Hadoop 的穩定性和容災能力將受到限制,從而降低其實際應用價值。因此,我們接下來將開始 安裝和配置 Hadoop 高可用集群。
目標環境:
| 節點 | NameNode01 | NameNode02 | DataNode | Zookeeper | ZKFC | JouralNode |
|---|---|---|---|---|---|---|
| node01 | ? | ? | ? | ? | ? | |
| node02 | ? | ? | ? | ? | ? | |
| node03 | ? | ? | ? |
首先,我們先下載Hadoop安裝包
文件名:hadoop-3.3.4.tar.gz 下載地址:https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(訪問碼:fad9)
- 進入 /opt/yjx/ 上傳文件
[root@node01 ~]# cd /opt/yjx
【上傳文件】
- 解壓并刪除安裝包
[root@node01 ~]# tar -zxvf hadoop-3.3.4.tar.gz -C /opt/yjx/
[root@node01 ~]# rm hadoop-3.3.4.tar.gz -rf
- 修改配置文件
# 修改環境配置文件 hadoop-env.sh:[root@node01 ~]# cd /opt/yjx/hadoop-3.3.4/etc/hadoop/
[root@node01 hadoop]# vim hadoop-env.sh# 在文件末尾添加以下內容:
export JAVA_HOME=/usr/java/jdk1.8.0_351-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root# 修改核心配置文件 core-site.xml:
[root@node01 hadoop]# vim core-site.xml# 在configuration 節點中添加以下內容<!-- 設置 NameNode 節點的 URI (包括協議、主機名稱、端口號),用于 NameNode 與 DataNode 之間的通訊 --><property><name>fs.defaultFS</name><value>hdfs://hdfs-yjx</value></property><!-- 設置 Hadoop 運行時臨時文件的存放位置,比如 HDFS 的 NameNode 數據默認存放在該目錄 --><property><name>hadoop.tmp.dir</name><value>/var/yjx/hadoop/ha</value></property><!-- 設置 Web 界面訪問數據時使用的用戶名 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 配置 HA (高可用),需要一組 Zookeeper 地址,以逗號分隔 --><!-- 該參數被 ZKFailoverController 用于自動故障轉移(Failover) --><property><name>ha.zookeeper.quorum</name><value>node01:2181,node02:2181,node03:2181</value></property><!-- 該參數表示可以通過 httpfs 接口訪問 HDFS 的 IP 地址限制 --><!-- 配置 root(超級用戶)允許通過 httpfs 方式訪問 HDFS 的主機名或域名 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 通過 httpfs 接口訪問的用戶獲得的群組身份 --><!-- 配置允許通過 httpfs 方式訪問的客戶端的用戶組 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
- 修改 HDFS 配置文件 hdfs-site.xml
[root@node01 hadoop]# vim hdfs-site.xml在configuration 節點中添加以下內容:<!-- 設置 NameService(HDFS 命名服務),支持多個 NameNode 的 HA 配置 --><property><name>dfs.nameservices</name><value>hdfs-yjx</value></property><!-- 設置 NameNode ID 列表,hdfs-yjx 對應 dfs.nameservices --><property><name>dfs.ha.namenodes.hdfs-yjx</name><value>nn1,nn2</value></property><!-- 設置 NameNode 的 RPC 地址和端口 --><property><name>dfs.namenode.rpc-address.hdfs-yjx.nn1</name><value>node01:8020</value></property><property><name>dfs.namenode.rpc-address.hdfs-yjx.nn2</name><value>node02:8020</value></property><!-- 設置 NameNode 的 Web 界面訪問地址和端口 --><property><name>dfs.namenode.http-address.hdfs-yjx.nn1</name><value>node01:9870</value></property><property><name>dfs.namenode.http-address.hdfs-yjx.nn2</name><value>node02:9870</value></property><!-- 設置 JournalNode 共享存儲,用于存放 HDFS EditLog --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node01:8485;node02:8485;node03:8485/hdfs-yjx</value></property><!-- 設置 JournalNode 日志存儲路徑 --><property><name>dfs.journalnode.edits.dir</name><value>/var/yjx/hadoop/ha/qjm</value></property><!-- 設置客戶端連接 Active NameNode 的代理類 --><property><name>dfs.client.failover.proxy.provider.hdfs-yjx</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- HDFS-HA 發生腦裂時的自動處理方法 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><value>shell(true)</value></property><!-- 失效轉移時使用的 SSH 私鑰文件 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 是否啟用 HDFS 自動故障轉移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 設置 HDFS 默認的數據塊副本數(可在文件創建時覆蓋) --><property><name>dfs.replication</name><value>2</value></property>
- 修改 workers:
[root@node01 hadoop]# vim workers
node01
node02
node03
- 把node01 已配置好的 hadoop 拷貝至 node02 和 node03。
[root@node02 ~]# scp -r root@node01:/opt/yjx/hadoop-3.3.4 /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/hadoop-3.3.4 /opt/yjx/
- 修改環境變量
三個節點修改環境變量 vim /etc/profile ,在文件末尾添加以下內容:
export HADOOP_HOME=/opt/yjx/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
修改完成后 source /etc/profile 重新加載環境變量。
- 啟動
# 首先啟動 ZooKeeper(三臺機器都需要執行)。[root@node01 hadoop]# zkServer.sh start
[root@node01 hadoop]# zkServer.sh status# 然后啟動 JournalNode(三臺機器都需要執行)。
[root@node01 hadoop]# hdfs --daemon start journalnode# 最后格式化 NameNode 等相關服務并啟動集群
# 格式化 node01 的 namenode(第一次配置的情況下使用)
[root@node01 ~]# hdfs namenode -format# 啟動 node01 的 namenode
[root@node01 ~]# hdfs --daemon start namenode# node02 節點同步鏡像數據
[root@node02 ~]# hdfs namenode -bootstrapStandby# 格式化 zkfc(第一次配置的情況下使用)
[root@node01 ~]# hdfs zkfc -formatZK# 啟動 HDFS
[root@node01 ~]# start-dfs.sh
后期只需要先啟動 ZooKeeper 然后再啟動 HDFS 即可。
瀏覽器訪問:http://192.168.100.101:9870/ 和 http://192.168.100.102:9870/
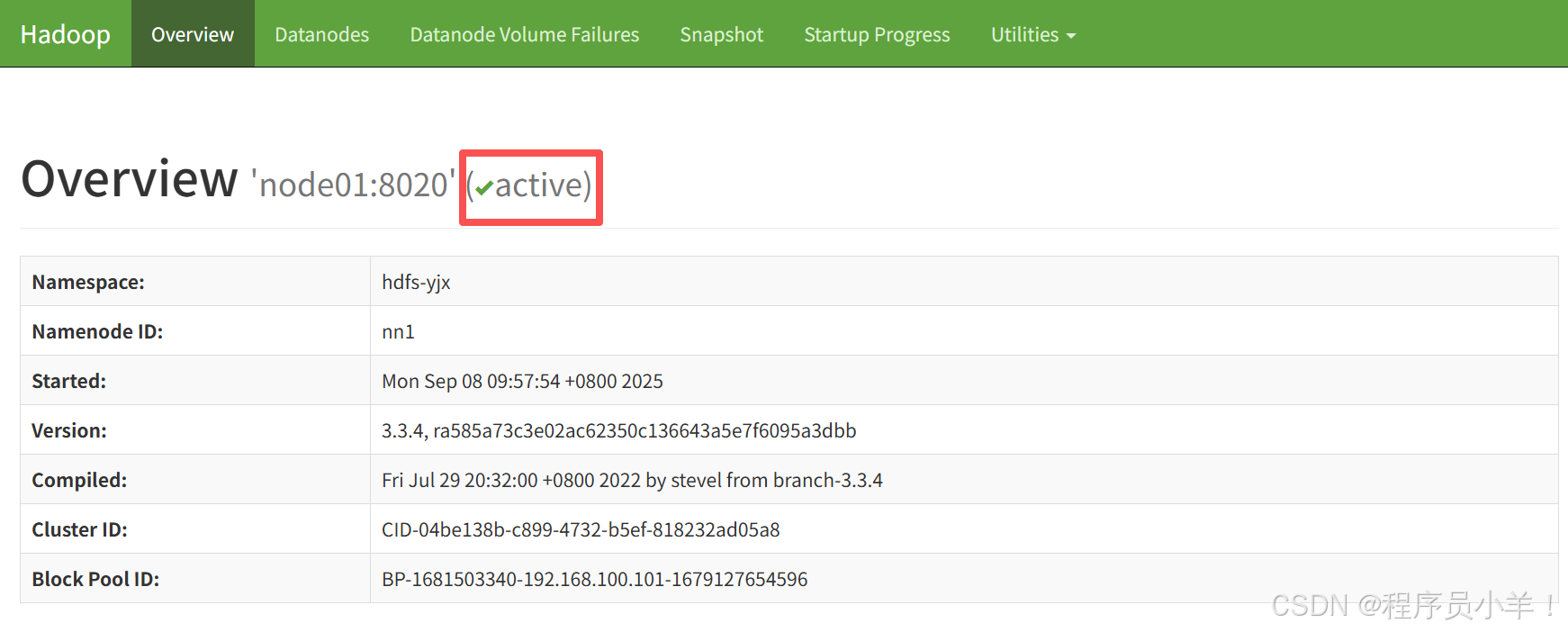
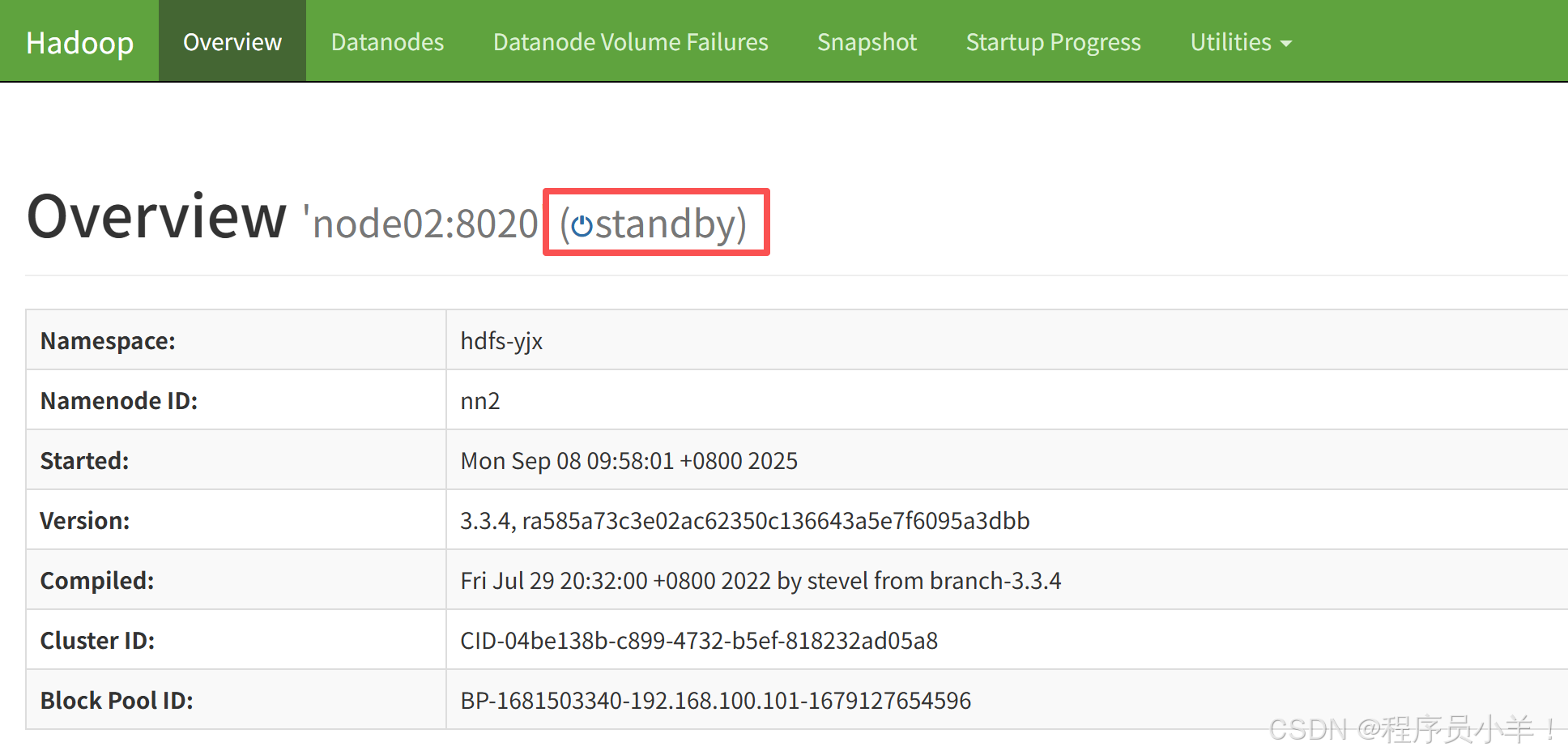
關閉hadoop
# 先關閉 HDFS。
[root@node01 ~]# stop-dfs.sh# 再關閉 ZooKeeper(三臺機器都需要執行)。
[root@node01 ~]# zkServer.sh stop# 啟動|關閉 所有節點和進程
[root@node01 ~]# start-all.sh
[root@node01 ~]# stop-all.sh[root@node01 ~]# mapred --daemon start historyserver
好,現在你搭建成功了,我們去拍一個快照準備者。
Hadoop介紹
Hadoop 是一個開源的分布式計算框架,主要用于存儲和處理海量數據。它能夠將大數據分散存儲在普通硬件上,并通過并行計算高效處理數據。Hadoop 的核心價值在于實現了高容錯、高擴展性和低成本的大數據處理能力。
狹義上來說,hadoop就是單獨指代hadoop這個軟件, 廣義上來說,hadoop指代大數據的一個生態圈,包括很多其他的軟件。
官網:https://hadoop.apache.org/
Hadoop的生態系統概述
Hadoop本身有三個核心組件,分別為 HDFS,MapReduce,Yarn 。
HDFS(Hadoop Distributed File System)
- 用于分布式存儲數據,將數據切分成多個塊(Block),存儲在集群的各個節點上,并通過副本機制保證數據的可靠性和高可用性。
MapReduce
- 一種編程模型和計算框架,用于大規模數據處理。它將任務分為兩步:Map 階段(將輸入數據拆分并并行處理)和 Reduce 階段(對 Map 階段的結果進行聚合)。
YARN(Yet Another Resource Negotiator)
- 資源管理層,負責調度和管理集群資源。YARN 將計算資源分配給各種應用程序,協調任務的執行,提升集群利用率和靈活性。
Hadoop 的設計思想主要受到谷歌兩篇論文的啟發:
《The Google File System (GFS)》
介紹了一種為大規模數據存儲設計的分布式文件系統,強調數據冗余、容錯和高吞吐量的思想。
《MapReduce: Simplified Data Processing on Large Clusters》
提出了 MapReduce 編程模型,用以簡化大規模數據并行處理的復雜性,使開發者能夠專注于數據處理邏輯,而不必關心底層的分布式并行執行細節。
當然Hadoop生態系統也不僅僅是Hadoop的一枝獨秀,講的是指的是圍繞Hadoop核心組件(如HDFS、MapReduce和YARN)構建的一系列工具、框架和項目,這些組件共同協作來處理、管理、分析和利用大數據。它不僅包括分布式存儲和批處理計算,還涵蓋了數據倉庫、實時流處理、數據導入導出、數據挖掘、機器學習等各個方面。
簡單來說,Hadoop生態系統提供了一個完整的大數據解決方案,從數據采集、存儲、處理到分析,都有專門的組件來支持,這些組件互相配合,共同構成了一個功能全面的大數據處理平臺。常見的生態系統組件包括:
-
Hive:數據倉庫,用SQL查詢數據。
-
HBase:NoSQL數據庫,用于實時隨機讀寫。
-
Spark:快速內存計算框架,用于實時和批處理。
-
Flume、Sqoop:用于數據采集和數據遷移。
-
ZooKeeper:分布式協調服務,保證系統一致性和高可用性。
……
HDFS
在 HDFS 的主從架構中,主要的進程分為主節點(Master)和從節點(Slave),它們各自承擔不同的職責。下面詳細介紹各個關鍵進程及其作用:
NameNode(主節點)
作用:NameNode 是整個 HDFS 的核心,負責存儲整個文件系統的元數據,包括目錄結構、文件與數據塊的映射、權限信息以及文件的狀態。
職責:接收客戶端的文件操作請求(如創建、刪除、重命名等),協調 DataNode 讀寫數據,并管理編輯日志。
注意:在傳統的 HDFS 架構中,NameNode 是單點故障(SPOF,Single Point of Failure),如果 NameNode 宕機,整個 HDFS 就無法使用。因此,為了保證 Hadoop 運行的高可用性,HDFS HA(High Availability,高可用)架構 通過 雙 NameNode 機制 來消除單點故障,確保集群穩定運行。
兩個namenode在開啟的時候總是一個激活一個備用,如果當前主namenode死亡后,從namenode會立刻頂替。
Active NameNode(主 NameNode):負責處理客戶端的所有請求,如文件的創建、刪除、重命名、讀取元數據等。維護整個 HDFS 的元數據(Metadata),如文件目錄結構、文件到塊的映射、DataNode 存儲信息等。
Standby NameNode(備用 NameNode):作為 Active NameNode 的備機,不直接處理客戶端請求。實時同步 Active NameNode 的元數據,以便在 Active 宕機時能立即接管。
DataNode(數據節點)
HDFS 的數據實際存儲在 DataNode 上,每個 DataNode 負責存儲數據塊(Block)DataNode 既服務 Active NameNode,也服務 Standby NameNode,定期向兩個 NameNode 匯報自己的存儲信息(如哪些塊在該節點上)。
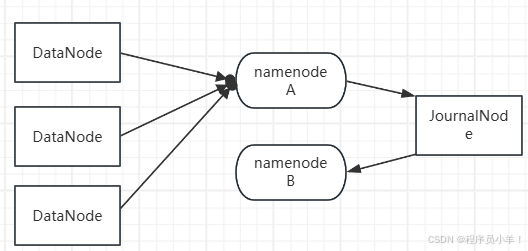
JournalNode(日志節點)
用于 NameNode 之間的狀態同步,解決 NameNode 之間的元數據一致性問題。他會記錄 Active NameNode 的所有操作日志。
Standby NameNode 不斷從 JournalNode 讀取 EditLog,以保持和 Active NameNode 同步。當 Active NameNode 宕機,Standby NameNode 會重放 EditLog,確保切換后數據一致。
Block 塊
塊是HDFS中最小的存儲單位,多個塊存儲在不同的dataNode上,dfs會保證一個塊存在一個節點上。默認情況下的大小是128MB,這個大小是按照機械硬盤的平均讀取速度/s制定的,可以按照實際需求更改,如果最后一個塊不足128MB 這塊不會占據整個塊的大小。存儲機制 三備份進一。
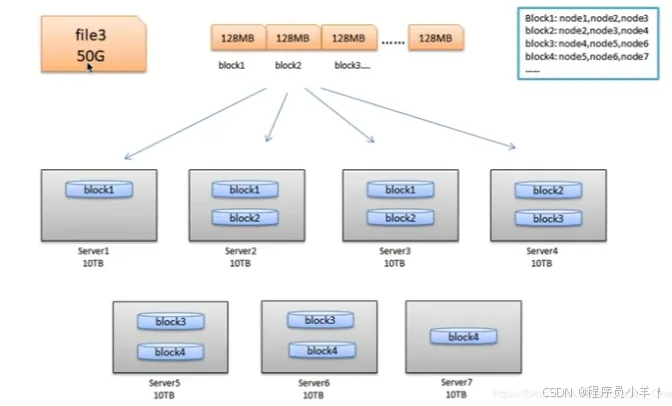
-
為什么要設置塊大小為128MB?
在hadoop1.0時代設置默認塊大小為64MB,在IO操作中最消耗時間的操作是尋址操作,將文件設置的大一些整體時間上會降低尋址的時間開銷,數據塊大找到第一個數據后就可以高效的順序讀取。
這個設計方法還可以高效地管理大規模數據。 如果數據量龐大,文件數量眾多,每個文件一個塊的做法會顯著增加元數據的管理負擔。大塊的設計能夠減少文件塊的數量,從而減輕NameNode的負擔。
加塊大小來提升傳輸效率 : 這個數值是根據硬盤的讀取速度來算的,機械硬盤的平均速度在128MB/s,可以充分的使用磁盤提高傳輸效率。
不適合存儲小文件: HDFS塊大小大,如果文件數量眾多但文件較小,會占用較多的NameNode內存資源。例如,一個文件大小不足128MB,即使文件內容只有1MB,也會占用一個完整的塊并持有相對的副本信息和塊存儲信息,導致內存浪費。
故事,128G磁盤理論每個塊都存滿128MB在這種情況下,磁盤的存儲利用率最高128G/128MB150byte = 1024 塊 約等于 0.14 MB。 每個塊只存儲1MB數據,加上150Byte的塊信息 那么每個塊大小就約等于 128G/1MB150byte = 131072 塊 元數據占用達到了 18.75MB
設置塊的大小: 在hdfs-default.xml中就有相關配置
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>默認塊大小,以字節為單位。可以使用以下后綴(不區分大小寫):k, m, g, t, p,e。例如指定大小(例如128k, 512m, 1g等)
</description>
</property><property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1048576</value>
<description>允許HDFS中的最小塊大小,由NameNode在創建時強制執行的。 這可以防止意外創建非常小的塊以降低性能。
</description>
</property><property>
<name>dfs.namenode.fs-limits.max-blocks-per-file</name>
<value>1048576</value>
<description>每個文件最多包含的塊數,由HDFS的NameNode執行。這可以防止創建降低性能的超大文件。
</description>
</property><property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>DataNode 使用的目錄用于存儲 HDFS 數據塊。這個路徑指定了DataNode 在本地文件系統上存儲數據塊的位置。通常,這個目錄應該位于具有足夠存儲空間的磁盤上,并且 DataNode 需要對其具有讀寫權限。
</description>
</property>
那么因為存在塊這個概念hdfs的優缺點就很明顯了,優點:高容錯性、適合大數據量存儲、高吞吐量、高可靠性。
缺點:不適合低延遲數據訪問: HDFS設計目標是批處理數據,故不適合處理需要低延遲的交互式應用。不適合存儲小文件: 小文件過多會導致NameNode存儲元數據的開銷較大,容易造成性能瓶頸。僅支持追加寫入: HDFS上的文件只能追加寫入,無法對文件進行隨機寫入或修改。
文件的合并和快照
在 HDFS 中,文件快照(snapshot)是一種保存文件系統某個時刻狀態的機制。創建快照時,HDFS會記錄下指定目錄及其子目錄當前的元數據狀態,而不需要將所有數據復制一遍。
快照為系統提供了數據備份和版本管理的能力,可以在數據誤刪或錯誤修改時迅速恢復到先前狀態,從而提高了整個集群的可靠性和管理的靈活性。
就比如說你做了一個修改操作,這個操作我會先記錄下來。包括最后產生的元數據變化,等到最后例如 3600 秒后或者事務執行100萬次自動 合并,拿最新的快照和日志記錄(JournalNode 負責,日志叫做 EditLog)推算出最新的 FsImage 并且發送給 備用namenode。這個過程被稱為 Checkpoint 檢查點。
此過程不會阻塞 Namenode 的使用,因為交給JournalNode 了,是異步的操作。
Checkpoint 過程將分散的小日志文件合并成一個完整的鏡像,使得后續的恢復和加載操作更加高效。另一方面,當面對大量小文件問題時,通常會通過應用層面進行合并,將多個小文件整合成一個大文件,這樣不僅能降低 NameNode 的管理負擔,也能提高數據讀取的吞吐量。
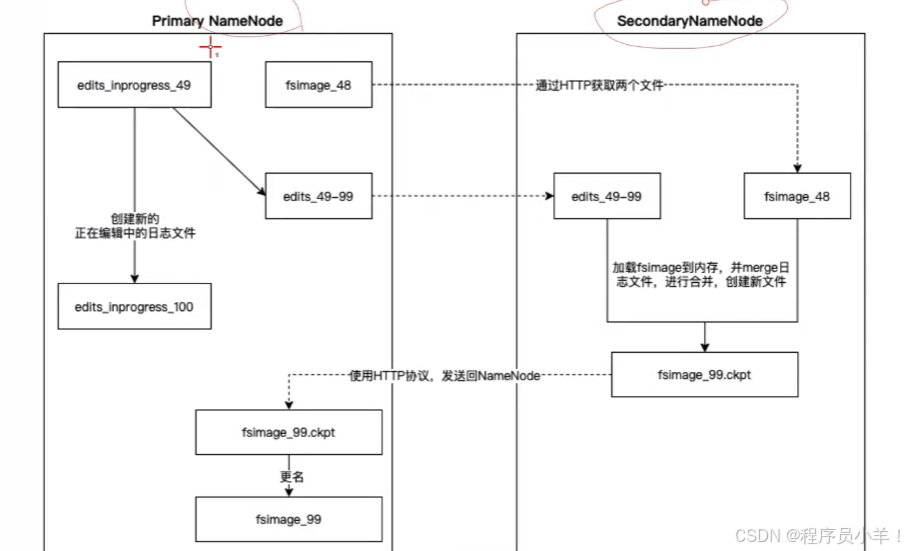
機制:注意,一般至少會留兩個 Fsimage 確保不會因為最新的丟失推不出來最新的狀態,當集群整個宕機之后重啟數據不會毀壞,而是先進入安全模式,根據最新的 快照 和 日志數據推出最新的狀態確保沒問題后才會退出安全模式允許用戶操作和訪問。
文件讀寫流程
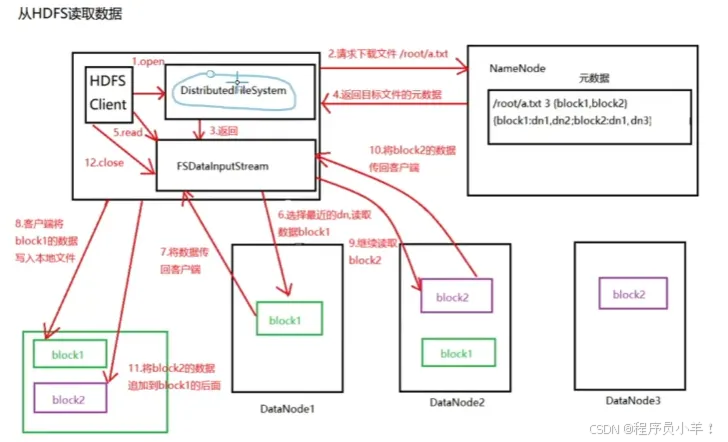
從hdfs中讀取數據,見上圖。
首先客戶端先發送一個請求給Namenode,他來判斷你有沒有權限去訪問,讀取,返回排序好的針對數據的元數據等信息通過列表返回,通過實例化的FSDelalnputStram來讀取信息,選擇最近的機器拿文件返回此對象,然后操作寫在本地文件中,然后繼續讀取塊2通過此對象寫入到剛剛的文件的后面就實現了完整的讀取文件的操作。如果出現了讀取塊中途出現錯誤會根據塊的元組信息順序去讀下一個節點標記此節點確保下次讀取此文件不在這里讀文件。
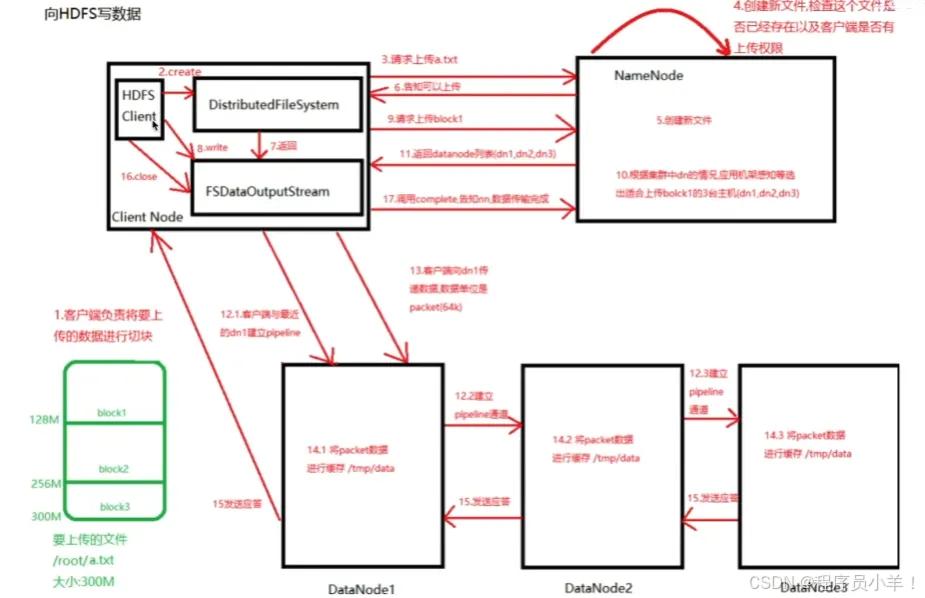
從hdfs中寫入數據
客戶端要先給文件進行切塊,然后請求文件,構建對象和Namenode通信,創建新文件,檢查當前位置文件名是否存在以及是否有權限上傳,然后創建文件,返回可以上傳的指示。溝通完畢后將獲得的數據注入FSDelalnputStram對象讓他來實現文件的寫入,將文件給對象后向Namenode請求上傳的塊信息,namenode根據壓力和機架感知策略來返回列表給寫入對象,根據這個列表先和列表中的1建立連接,然后1和2通信,2和3通信,3給2匯報,2給1 不同的服務器和節點通信將數據進行緩存 tmp/data 結束后返回應答給客戶端節點,指示關閉寫入流,最后向Namenode匯報操作結束 完整流程結束。
如果寫入斷電就先關閉管道,確認隊列中的所有數據包都添加回到數據隊列的前端確保和之前沒上傳這個block時一樣,然后根據下一個datenode寫入并且保留一個標識就存兩份,讓Namenode發現這個壞掉節點重新工作后自動刪除之前寫一半的內容,Namenode發現副本數量不足會創建一個副本
安全模式和啟動
HDFS 在啟動過程中會進入一種叫做“安全模式”的狀態。NameNode 在啟動時會自動進入安全模式,在這個階段,文件系統處于只讀狀態,不允許進行任何修改操作(如創建、刪除文件),以保證系統在恢復過程中不會有數據不一致的問題。
當 NameNode 啟動后,它首先會收集 DataNode 上各個塊的報告(Block Reports),計算每個數據塊的副本數量。NameNode 會檢查整個文件系統中塊副本的完整性,確保有足夠多的塊副本存在。只有當達到預設的閾值,比如大部分塊副本都已經成功加載并報告給 NameNode 后,NameNode 才會退出安全模式,從而允許客戶端進行寫操作。
通常,管理員也可以通過命令手動退出安全模式,例如使用 hdfs dfsadmin -safemode leave。這種設計確保了在 NameNode 剛啟動時,不會因部分數據副本缺失而出現數據損壞或不一致的問題,從而提高了 HDFS 的整體可靠性。默認閾值大概是98%接近100%
HDFS簡單操作
hdfs的操作實際上和Linux很像,只是在前面添加了 hdfs dfs的前綴,例如:hdfs dfs mkdir /etc 【在dfs根目錄下創建etc文件夾】 下面有是有關的基礎Shell命令需要掌握:
創建新目錄:!注意,操作路徑都是絕對路徑 不存在cd 相對路徑
》hdfs dfs -mkdir (-p) /目錄《
$ hdfs dfs -mkdir /test # 在根目錄下傳建一個test文件夾
$ hdfs dfs -mkdir -p /test/a/b/c # 多級創建,在一個文件夾下在創建子級文件夾多加-p上傳命令:
》hdfs dfs -put /本地文件 /dfs路徑《
$ hdfs dfs -put /sowfwares / # 上傳/sowfwares到dfs的根目錄上
$ hdfs dfs -put *.txt / # 上傳當前目錄下的txt文件到根目錄上本地移動文件到dfs:
》hdfs dfs -moveFromLocal /本地文件 /dfs路徑《
$ hdfs dfs -moveFromLocal hello.jpg / # 上傳當前目錄下的txt文件到根目錄上查看hdfs文件:
》 hdfs dfs -ls (-hR) /dfs路徑 《
$ hdfs dfs -ls / # 查看hdfs根目錄文件
$ hdfs dfs -ls -h / # 帶文件大小單位轉換的展示
$ hdfs dfs -ls -R / # 遞歸查看hdfs根目錄文件下所有文件(包括所有子文件)查看hdfs文件的內容:
》 hdfs dfs -cat /dfs路徑 《
$ hdfs dfs -cat /file/txt01.txt # 查看hdfs下的/file/txt01.txt文件
$ hdfs dfs -cat /file/*.txt # 查看hdfs下的/file/*.txt,所有txt文件夾查看文件的頭幾行:
》 hdfs dfs -head /dfs路徑 《
查看文件的后幾行:
》 hdfs dfs -tail /dfs路徑 《下載hdfs的文件到本地: []下的東西為非必寫
》 hdfs dfs -copyToLocal /dfs路徑 [本地路徑] 《 # 不寫本地路徑會下載到當前位置
$ hdfs dfs -copyToLocal /file/txt01.txt # 下載hdfs下的/file/txt01.txt文件
》 hdfs dfs -get /dfs路徑 《
$ hdfs dfs -get /file/txt01.txt # 下載hdfs下的/file/txt01.txt文件合并下載hdfs的文件到本地:
》 hdfs dfs -getmerge /dfs路徑* 文件名(位置) 《
$ hdfs dfs -getmerge /input/file* file # 合并下載/input/file*的所有文件存在file文件中刪除hdfs的文件:
》 hdfs dfs -rm (-r) /dfs路徑 《 # 刪除文件沒提示信息,注意
$ hdfs dfs -rm /file/*.txt # 刪除/file下的所有txt文件夾
$ hdfs dfs -rm -r /file # 刪除整個/file文件夾拷貝文件
》 hdfs dfs -cp /dfs路徑 /移動到的dfs路徑 《
$ hdfs dfs -cp /file/file1.txt /file2_cp.txt # 拷貝hdfs的文件到其根目錄下/file2_cp.txt的文件文件重命名和移動文件
》 hdfs dfs -mv /dfs路徑文件 /dfs(同級目錄下)新路徑文件 《
$ hdfs dfs -mv /file/file1.txt /file/txt01.txt # 把/file/file1.txt文件重命名為/file/txt01.txt
》 hdfs dfs -mv /dfs路徑文件 /dfs新路徑文件 《
$ hdfs dfs -mv /file/file1.txt / # 把/file/file1.txt文件移動到根目錄創建空文件
》 hdfs dfs -touchz /dfs文件夾名 《
$ hdfs dfs -touchz /file2 # 在dfs上創建了/file2文件夾向文件中追加內容
!HDFS中不支持你編輯文件,只能向后追加內容
》 hdfs dfs -appendToFile /本地文件 /dfs文件《
$ hdfs dfs -appendToFile /file1 /file # 向dfs文件/file上追加本地的文件/file1到文件末尾修改文件權限
》 hdfs dfs -chomd (-R) 權限符 /dfs位置 《
$ hdfs dfs -chomd 755 /file # 賦予dfs下/file文件權限為 755
$ hdfs dfs -chomd 755 /sofwares # 遞歸賦予dfs下/sofwares文件夾及其內部文件權限為 755修改文件所屬用戶、組
》 hdfs dfs -chown [所屬用戶][:所屬用戶組] /dfs位置 《
$ hdfs dfs -chown hadoop /file # dfs下的/file文件所屬用戶變為hadoop
$ hdfs dfs -chown root:superroot /file # dfs下的/file文件所屬用戶變為root,用戶組為superroot修改文本副本數量
》 hdfs dfs -setrep 整數 /dfs位置 《
$ hdfs dfs setrep 3 /file # dfs下的/file文件副本數量為3
# 作用于文件夾下的時候下面所有文件都會被修改文件的測試
參考使用:hdfs dfs -test -d /sowfares && echo "0K" || echo "no"
# /sowfares 是不是一個文件夾(-d) 如果是輸出OK,不是no
# -d 是否為文件夾 -e 是否存在 -z 是否為空查看文件夾和子文件夾數量
》 hdfs dfs -count /dfs位置 《
$ hdfs dfs -count / # 根目錄下的子文件數量磁盤利用率統計:
》 hdfs dfs -df (-h) / 《
統計文件文件夾大小:
》 hdfs dfs -du (-hs) /dfs位置 《 # -s求總和文件狀態查看:
》 hdfs dfs -stat [占位符] /dfs位置 《
# 占位符:%b 文件大小,%n 打印文件名,%o 打印block的size,%r 打印副本數量,%y 修改時間
$ hdfs dfs -stat %n-%b-%r-%o-%y /softwares/hadoop-3.3.1.tar.gz
# 查看dfs/softwares/hadoop-3.3.1.tar.gz 文件的名字,大小,副本數,修改時間和塊大小
回收站
回收站:在dfs中是有回收站概念的,默認是不開啟的,可以通過回收站找回被刪除的文件,需要修改集群中的 core-site.xml 文件 。
回收站的基本原理: 當用戶刪除文件時,HDFS 并不會立即從磁盤中刪除文件,而是將文件移動到一個稱為回收站(Trash)的特定目錄中,當保留時間設置為0代表不經過此文件夾立刻刪除無法恢復。 檢查點創建時間間隔 是防止存儲出現意外設置的檢查點將回收站的內容持久化一次。 這個值應該小于或等于 fs.trash.interval 的值。如果設置為 0,則會自動設置為與 fs.trash.interval 相同的值。
(對應配置文件名:hdfs-site.xml)
<!-- 回收站保留時間,單位是分鐘。如果設置為0表示不啟用回收站。 1440一天 -->
<property><name>fs.trash.interval</name><value>1440</value>
</property><!--這是檢查點創建的時間間隔,單位是分鐘。-->
<-- 這個值應該小于或等于fs.trash.interval,如果設置為0,則會將這個值設置為ts.trash.interval的值。-->
<property><name>fs.trash.checkpoint.interval</name><value>720/value>
</property>
回收站路徑:hdfs://hdfs-yjx/user/root/.Trash/Current/……
文件找回: hdfs dfs -mv /user/root/.Trash/Current/xx / [將 /user/root/.Trash/Current/xx 文件移動到根目錄下]
清空回收站: hdfs dfs -expunge
刪除文件夾不通過回收站:hdsf -dsf -rm (-r) -skipTrash /xx
hadoop jar $HADOOP_HOME/share/hadoop/mapr educe/hadoop-mapreduce-examples-3.3.4.jar pi 1000 1000
YARN
YARN(Yet Another Resource Negotiator)是 Hadoop 2.x 引入的資源管理和任務調度框架,它將資源管理與應用程序調度、監控分離開來,使得集群可以同時運行多種不同的計算框架(如 MapReduce、Spark、Tez 等),從而極大地提高了 Hadoop 集群的利用率和靈活性。
YARN 的架構可以分為幾個核心組件。首先是 ResourceManager,它作為集群的全局資源管理器,負責整個集群資源的分配和調度。ResourceManager 內部分為兩個主要部分:
(Scheduler)和應用管理器(ApplicationManager)。調度器負責按照一定的調度算法(如 Capacity Scheduler 或 Fair Scheduler)分配容器資源,但它不負責任務的執行;應用管理器則負責接收用戶的作業提交,并為每個應用啟動對應的 ApplicationMaster。
其次,運行在集群每個節點上的 NodeManager 是局部資源管理器,它負責管理節點上的實際資源、監控容器的運行狀態,并向 ResourceManager 定期匯報節點的資源使用情況。NodeManager 負責啟動、監控和終止在本節點上運行的容器。
在 YARN 中,每個作業或應用程序都由一個專門的 ApplicationMaster 來管理。ApplicationMaster 負責與 ResourceManager 協商所需的資源(以容器的形式分配),并在各個節點上協調任務的執行。它相當于作業的總指揮,既要對作業進度進行監控,也要處理作業中的故障恢復和資源重新分配等問題。
容器(Container)是 YARN 中資源分配的最小單元,每個容器包含一定數量的 CPU、內存等資源。當 ResourceManager 將資源分配給 ApplicationMaster 后,ApplicationMaster 會進一步將這些資源劃分給具體的任務,在 NodeManager 的協助下啟動容器來執行任務。容器使得資源隔離與管理變得更加細粒度,也方便實現多租戶環境下的資源保障。
YARN 的工作流程大致如下:
當用戶提交一個作業時,ResourceManager 接收到作業請求,并啟動一個 ApplicationMaster;ApplicationMaster 隨后向 ResourceManager 請求資源(容器),ResourceManager 根據集群資源和調度策略分配容器;得到資源后,ApplicationMaster 聯系對應節點的 NodeManager 啟動容器,并將作業任務分派到這些容器上執行;在任務執行過程中,NodeManager 監控容器狀態并將運行情況匯報給 ApplicationMaster;作業執行完成后,ApplicationMaster 通知 ResourceManager,最終釋放資源。
通過這種架構,YARN 實現了資源的集中調度與分布式執行解耦,使得集群能夠動態調配資源、運行多種計算框架,并提供更好的容錯與擴展性。總的來說,YARN 是 Hadoop 集群高效、靈活、多任務共存的關鍵所在。
MapReduce(MR)
MapReduce 是一種用于大規模數據處理的編程模型和框架,它最初由谷歌提出,旨在幫助開發者在分布式集群上以簡單的方式處理海量數據。MapReduce 把任務分為兩個主要部分:Map(映射)和 Reduce(歸約)。在 Map 階段,每個節點獨立地處理輸入數據,生成一組中間的鍵值對;在 Reduce 階段,相同鍵的中間結果被收集并進行合并或聚合,形成最終結果。
這種模型的設計理念在于將復雜的分布式計算抽象成兩個簡單的函數,使開發者無需關注底層的任務調度、數據傳輸和容錯機制。MapReduce 內部通過自動將數據分割、分配任務、并行處理以及在節點發生故障時重新調度任務來保證計算的高效性和穩定性。它支持大規模并行計算,同時具備高度的容錯能力,這使得 MapReduce 成為批量數據處理和數據分析的核心技術之一。
總的來說,MapReduce 為處理海量數據提供了一個清晰、易于理解的框架,簡化了分布式并行計算的實現,而不需要開發者深入了解各個細節。
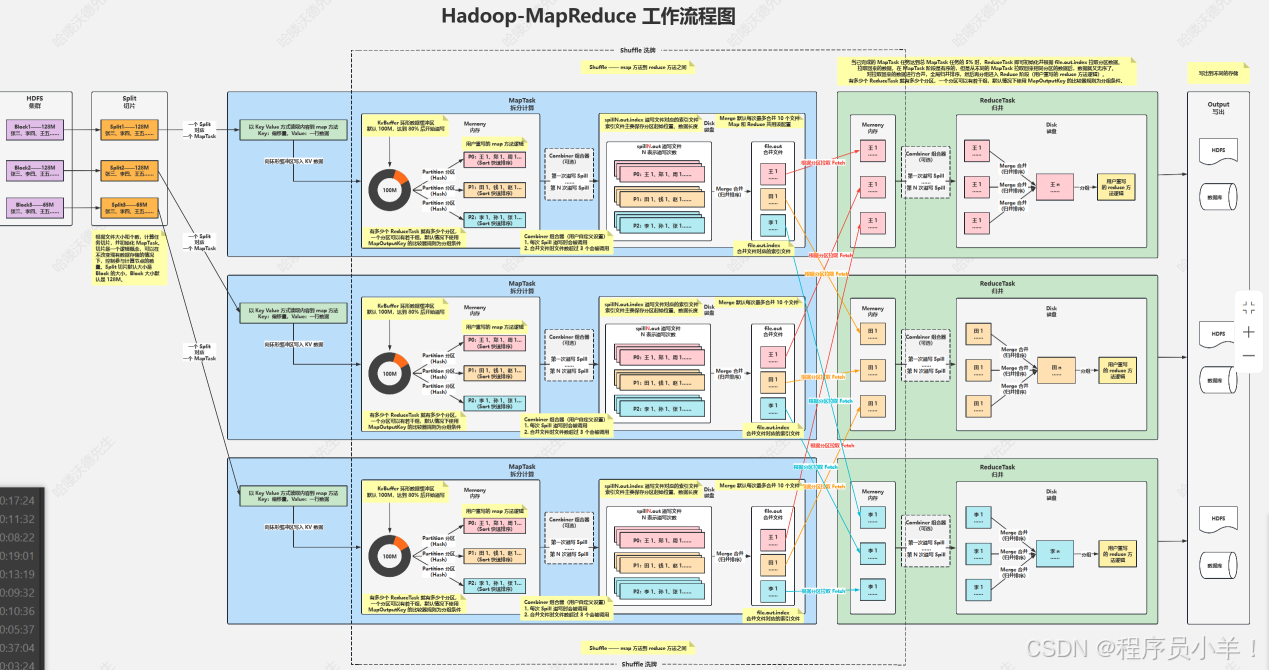
client: 客戶端通常指的是用戶或者就是我們程序員
Split:切片是一個邏輯概念,在不改變現在數據存儲的情況下,可以控制參與計算的節點數目,在通過切片大小可以達到控制計算節點數量的目的,一般切片大小為Block的整數倍 1/2。切片小了可以調用更多的工作節點,節點少了切片大于塊大小。(常見大小64,一個塊分為兩個邏輯塊,默認情況下Split切片的大小等于Block的大小) 通常來說一個切片對應一個MapTask。
MapTask: Map任務從所屬的切片(Split)中讀取數據,每次讀取一行 。它會對讀取的數據進行處理,通常是將數據轉換為鍵值對的形式 (Map<String,Integer>)臨時數據。處理后的鍵值對會被寫入內存緩沖區,等待進一步處理或傳輸到下一個階段。
環形緩沖區:這是一個索引兩邊為零偽環形的數組,可以循環利用這塊內存區域,數據循環寫到硬盤,不用擔心OOM(內存溢出)問題。在內存中構建一個環形數據緩沖區(kvBuffer),默認大小為100M,目的是為了減少數據溢寫時map的停止時間,沒有緩沖區就需要每次重新申請內存。設置緩沖區的閾值為80%,當緩沖區的數據達到80M開始向外溢寫到硬盤。存儲的時候塊一邊寫block數據半邊寫元數據,
分區Partation: 根據Key直接計算出對應的Reduce,分區的數量和Reduce的數量是相等的(hash(key) % partation = num 默認分區的算法是Hash然后取余,Hash算法可以更改)當被溢寫到磁盤之前會進行Sort快速排序。
排序Sort : 按照先Partation后Key的順序排序–>相同分區在一起,相同Key的在一起。溢寫Spill :將內存中的數據循環寫到硬盤,每次會產生一個80M的文件,如果本次Map產生的數據較多,可能會溢寫多個文件。 文件的通常命名為:spillN.out N表示溢寫的次數
組合器combiner: 預處理的組件,減輕后面的計算負擔,小Reduce。
當數據溢寫到磁盤中后會進行Merge合并(歸并排序),根據key來合并為file.out文件,此MapTask任務結束等待ReduceTask拉取。
Merge合并:Merge 是為了讓傳輸的文件數量變少,但是網絡傳輸數據量并沒有改變,只是減少了網絡 IO 次數。合并的是溢寫出來的數據,將多個小文件合并成一個大文件,在拉取的過程中減少了IO
拉取Fetch: 將MapTask的臨時結果拉取到Reduce節點,一個Reduce對應的多個MapTask。原則相同的Key必須拉取到同一個Reduce節點,一個Reduce節點可以有多個Key。
ReduceTask: 將文件中的數據讀取到內存中,一次性將相同的key全部讀取到內存中,他其實也有一個緩沖機制,緩沖量是當前內存的70%,當超過就會觸發溢寫寫入到磁盤中,在寫入的過程中會進行二級Merge合并將多個溢寫的數據合并成為一個分區,最后的結果就是當前Reduce的結果,此時數據量已經合并小了很多,但是如果有多個Reduce任務最后就會有多個reduce計算結果,將這個結果再重復寫入HDFS的零時節點轉換為ReduceTask直到可以單個節點完成任務。
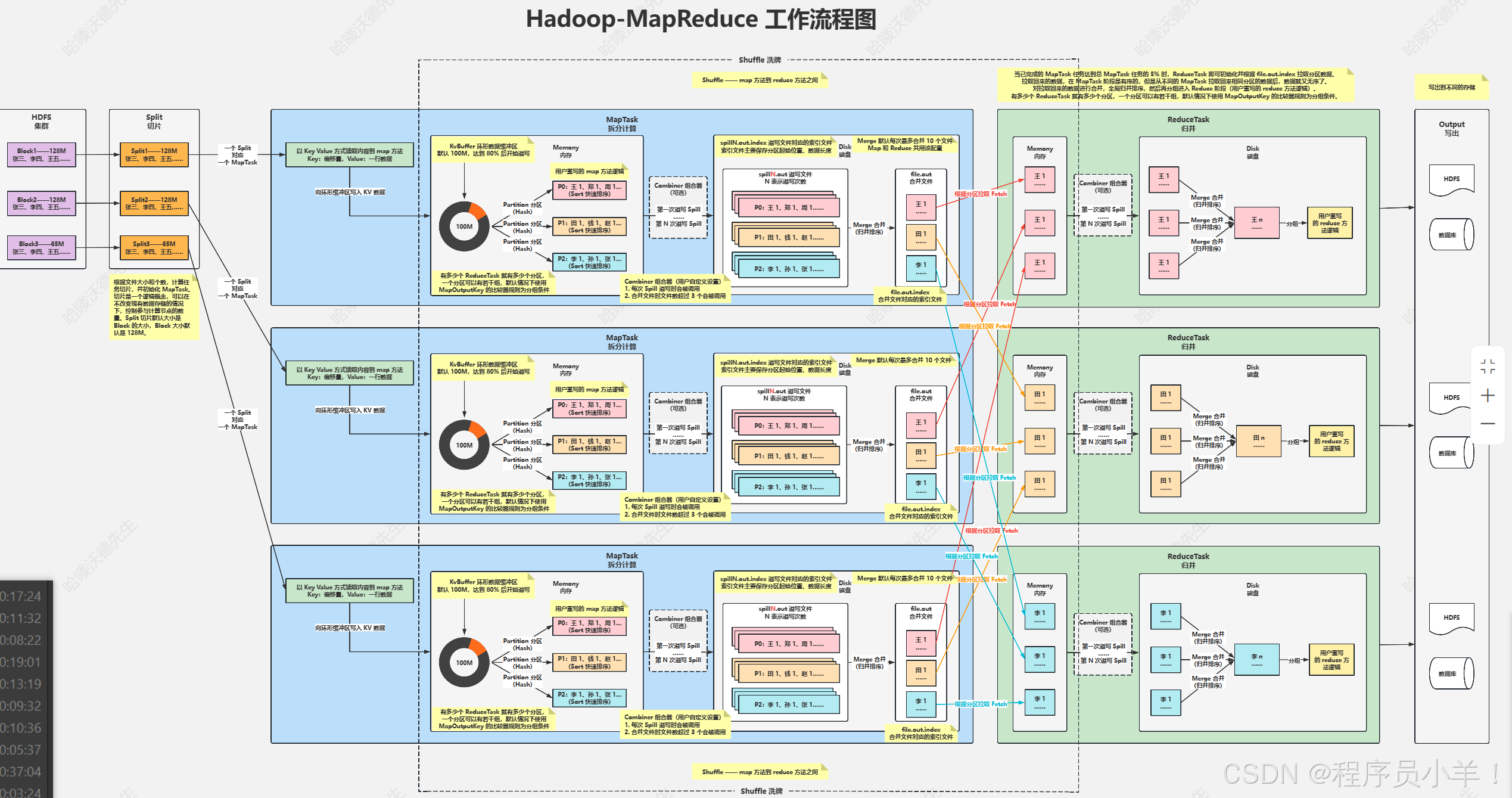
MR任務上傳的流程
客戶端發送分析的源文件和Jar包上傳到hdfs中,首先任務開始的時候會將HDFS集群中的數據塊拿出來,根據節點設置的切片大小先切片,不設置默認為128MB,每一個切片都會單獨的被MapTask單獨計算,先寫到緩沖區中,緩沖區默認大小為100M。
切片存儲的數據包含數據本體和元數據,通過環形緩沖區,當達到緩沖區大小的80%觸發溢寫合成一個分區,分區,此時會根據Key做第一次的數據排序,(排序完的數據在這里可以接入一個組合器為下一個在磁盤中的Merge做預處理準備)。溢寫出來的數據會包含:分區起始位置,數據長度。溢寫數據都準備好后會觸發合并文件的操作也就是Merge合并,采用了歸并排序,將根據相同的Key的數據合并成一個大文件,此時MapTask任務執行結束(在執行合并的時候的Map算法可以自己重寫,也可以在里面加入Combiner組合器)。
開始執行歸并操作ReduceTask,將之前在磁盤中的MapTask數據合并寫在內存中,注意同一個Key只會在一個ReduceTask下,一個ReduceTask可以處理多個不同的Key數據,當數據達到當前節點內存容量的70%觸發一次溢寫操作,會將寫入到磁盤中,(在此過程中可以插入組合器)在磁盤中合并進行計算,將結果寫成一個文件。此時ReduceTask任務已經完成。
但是如圖所示當我們有多個ReduceTask節點計算那就有多個計算結果,我們還需要把這個多個規約后的文件存在HDFS中進行臨時存儲做二次計算,邏輯切片然后轉換為MapTask開始下一個周期,直到最后結果被算到可以一個ReduceTask節點可以處理完將數據輸出出來,目的地可以是數據庫或者HDFS中。
有關ReduceTask節點是什么時候出現的? 當MapTask處理的數據任務量達到5%就會開始生成ReduceTask。
有關為什么MapTask中排序合并后的數據為什么還要在Reduce中排序一次? 因為ReduceTask面對的節點數量是不止一臺的所以多個拿過來數據不能保證又是順序的,這次的操作只需要排序MapTask的文件就可以不是針對數據 KV的。
在合并的時候Merge無論是Map還是Reduce都是最多合并10個溢寫出來的文件合并成一個。
Combiner組合器是用戶自定義的功能,在每次spill濫用的時候會被調用,默認值是合并文件超過3個,也可以自己設置。
有關shuffle洗牌
在Hadoop MapReduce中,洗牌(Shuffle) 是一個關鍵步驟,主要用于在Map階段和Reduce階段之間傳遞數據。洗牌過程解決了如何有效地將Map任務的輸出傳遞給相應的Reduce任務的問題。具體來說,它包括三個子過程:分區(Partitioning)、排序(Sorting)和合并(Merging)。
洗牌的作用 : (數據分配)將Map任務的輸出數據按鍵分配給相應的Reduce任務,確保相同鍵的數據被同一個Reduce任務處理。 (排序) 保證Reduce任務接收到的數據是有序的,便于在Reduce任務中進行高效處理。 (合并) 減少數據傳輸量,提高數據處理效率,減少網絡擁塞。
解決的主要問題:(數據分布和負載均衡) 通過分區函數,將數據均勻地分布到各個Reduce任務,避免單個Reduce任務負載過高。 (排序和合并) 通過排序和合并操作,減少網絡傳輸的數據量,提高整體處理效率。(鍵的聚合) 確保相同鍵的數據被聚合到同一個Reduce任務中,便于進行進一步的聚合操作(如求和、平均值等)。
為什么說洗牌是分布式計算的敵人?
首先你要對洗牌是做什么有清楚的認知,他主要發生在Map階段,磁盤中的邏輯分片數據寫入到緩存區的時候開始到Reduce FetchMap寫入到內存之后結束。1. 網絡開銷大: 洗牌階段需要將大量的數據從一個節點傳輸到另一個節點,這會產生巨大的網絡開銷,特別是當數據量很大時,這種開銷會顯著影響整體性能。2. 磁盤I/O開銷大:Map 階段的輸出數據通常會寫到本地磁盤,然后再讀取進行傳輸,這會產生大量的磁盤 I/O 操作,影響處理速度。3. 內存開銷大: 在處理過程中,需要在內存中維護一定的數據結構來進行排序和合并操作,這對內存資源的消耗較大。4. 數據傾斜問題: 如果某些鍵的數據量特別大,導致某些 Reduce 任務的數據量明顯超過其他任務,會導致負載不均衡,從而影響整個作業的執行時間。
為了解決這個問題我們可以優化我們的算法,避免 壓縮中間數據 過多,例如Map階段中的合并文件的數量可以寫一個組合器在合并前根據Key做一次合并。 可以自己寫分區函數,確保數據均勻的分布在各個Reduce任務重減少數據傾斜。 增加Reduce工作節點數量讓數據分布均勻,最后調整緩沖區的大小改適當大一些。
通過以上優化措施,可以有效減少洗牌階段的開銷,提高 Hadoop MapReduce 作業的整體性能。
結尾:
本課程是一門以電商流量數據分析為核心的大數據實戰課程,旨在幫助你全面掌握大數據技術棧的核心組件及其在實際項目中的應用。從零開始,你將深入了解并實踐Hadoop、Hive、Spark和Flume等主流技術,為企業級電商流量項目構建一個高可用、穩定高效的數據處理系統。
在課程中,你將學習如何搭建并優化Hadoop高可用環境,熟悉HDFS分布式存儲和YARN資源調度機制,為大規模數據存儲與計算奠定堅實基礎。隨后,通過Hive數據倉庫的構建與數倉建模,你將掌握如何將原始日志數據進行分層處理,實現數據清洗與結構化存儲,從而為后續數據分析做好準備。
借助Spark SQL的強大功能,你將通過實戰案例學會快速計算和分析關鍵指標,如頁面瀏覽量(PV)、獨立訪客數(UV),以及通過數據比較獲得的環比、等比等衍生指標。這些指標將幫助企業準確洞察用戶行為和流量趨勢,為優化營銷策略提供科學依據。
同時,本課程還包含Flume數據采集與ETL入倉的實戰模塊,教你如何采集實時Web日志數據,并利用ETL流程將數據自動導入HDFS和Hive,確保數據傳輸和處理的高效穩定。
總體來說,這門課程面向希望提升大數據應用能力的技術人員和企業項目團隊,緊密圍繞公司電商流量項目的實際需求展開。通過系統的理論講解與動手實踐,你不僅能夠構建從數據采集、存儲、處理到可視化展示的完整數據管道,還能利用PV、UV、環比、等比等關鍵指標,全面掌握電商流量數據分析的核心技能。
今天這篇文章就到這里了,大廈之成,非一木之材也;大海之闊,非一流之歸也。感謝大家觀看本文

)
)




-Ubuntu從零搭建深度學習環境)









)


