視覺AIGC識別——人臉偽造檢測、誤差特征 + 不可見水印
- 前言
- 視覺AIGC識別
- 【誤差特征】DIRE for Diffusion-Generated Image Detection
- 方法
- 擴散模型的角色
- DIRE作為檢測指標
- 實驗結果
- 泛化能力和抗擾動
- 人臉偽造監測(Face Forgery Detection)
- 人臉偽造圖生成
- 其他類型假圖檢測(Others types of Fake Image Detection)

前些天發現了一個人工智能學習網站,內容深入淺出、易于理解。如果對人工智能感興趣,不妨點擊查看。
前言
續篇:一文速覽深度偽造檢測(Detection of Deepfakes):未來技術的守門人
參考:https://mp.weixin.qq.com/s/inGjMdX9TTUa3hKWaMkd3A
視覺AIGC識別
根據已有的研究工作調研,將視覺AIGC識別粗略劃分為:
- 人臉偽造檢測(Face Forgery Detection):包含人臉的AIG圖片/視頻的檢測,例如AI換臉、人臉操控等。此類方法主要關注帶有人臉相關的檢測方法,檢測方法可能會涉及人臉信息的先驗。
- AIG整圖檢測(AI Generated-images Detection):檢測一整張圖是否由AI生成,檢測更加的泛化。這類方法相對更關注生成圖與真實圖更通用的底層區別,通常專注于整張圖,比如近年爆火的SD、Midjounery的繪圖;
- 其他類型假圖檢測(Others types of Fake Image Detection):此類方法更偏向于 局部偽造、綜合偽造等一系列更復雜的圖片造假,當然人臉偽造也屬于局部、復雜,但是是人臉場景。將AIG圖與真實圖拼湊、合成的圖片識別也屬于這一類。
這三種類型之間劃分并不明晰,很多方法同時具有多種檢測能力,可劃分為多種類型。嚴格意義上說AIG整圖和其他造假圖檢測類型可能都會包含人臉信息,但三種類型方法往往技術出發點也不同。
【誤差特征】DIRE for Diffusion-Generated Image Detection
Arxiv 2023
方法
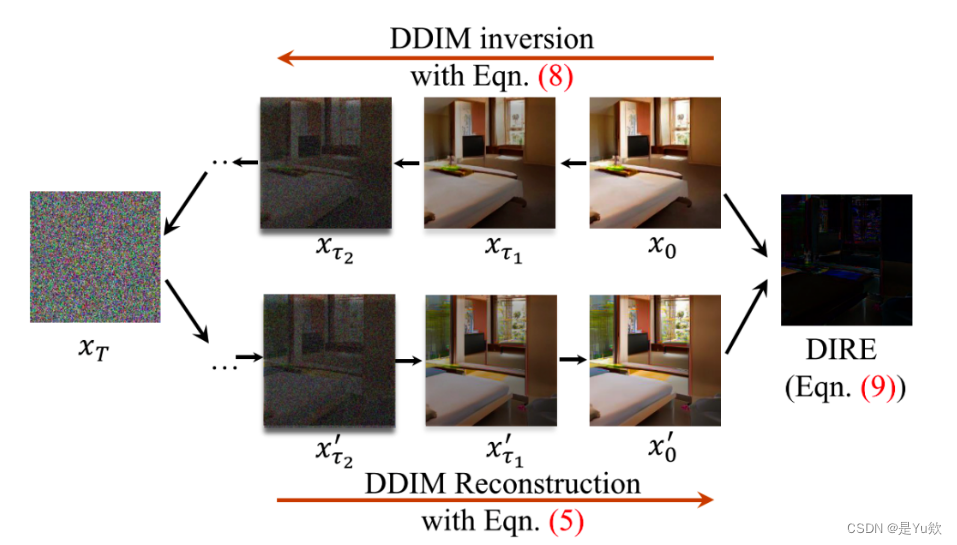
作者發現DM 圖可以被近似地被擴散模型重建,但真實圖片不行。將重建圖和原圖的圖片差異記為擴散重建差(DIffusion Reconstruction Error,DIRE),則DIRE可以作為特征進行2分類訓練,判斷是否虛假,泛化性會高很多;
擴散模型的角色
擴散模型在這里充當了一種“數字時間機器”的角色,通過將圖像“倒帶”回過去的某個狀態,然后再“快進”到現在,來重建圖像。對于合成圖像而言,這種“時間旅行”的過程中丟失的信息較少,因為它們本身就是由類似的深度學習模型生成的,因此它們與擴散模型重建的版本更為接近。相反,真實圖像在這一過程中會丟失更多的細節,因為它們包含了更復雜和多樣的信息,這些信息在通過擴散模型的“濾鏡”時難以保留。
DIRE作為檢測指標
將DIRE視作一種“指紋差異儀”,它可以測量一個圖像經過時間機器旅行前后的變化量。對于合成圖像,這種變化相對較小,因為它們本質上已經是“時間旅行”的產物。對于真實圖像,變化較大,因為時間旅行過程中它們失去了更多的原始信息。
重建圖像差DIRE可以區分真實圖和合成圖的原因如下圖:
- 合成圖在重建后變化往往較小;
- 真實圖在重建后變化相對較大;
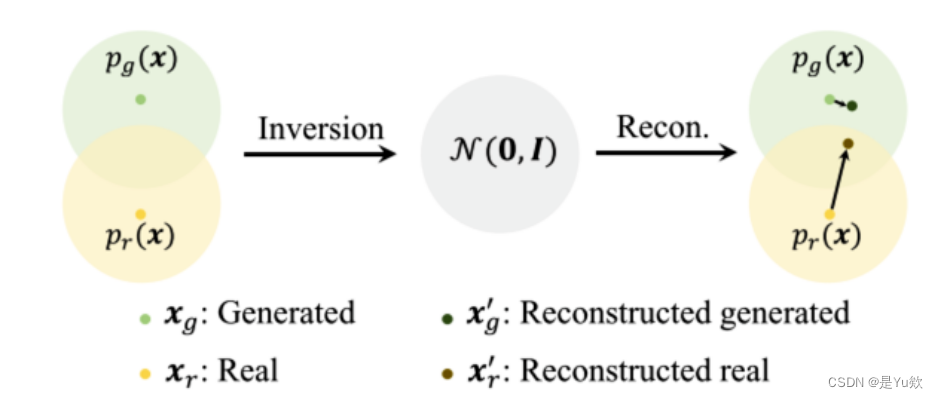
我的理解是,真實圖在重建時會丟失很多信息,而生成圖由于本身就是模型生成的,重建時信息變化相對不大。因此差異可以反映其真假。
該方法通過預訓練的擴散模型(Denoising Diffusion Implicit Models,DDIMs[7])對圖片進程重建,測量輸入圖像與重建圖像之間的誤差。其實這個方法和梯度特征的方法LGrad很像,區別在于上面是通過 Transformation Model轉換模型獲得圖像梯度,這里通過 DDIM 重建圖計算差。
實驗結果
此外,作者提出了一個數據集 DiffusionForensics,同時復現了8個擴散模型對提出方法進行識別(ADM、DDPM、iDDPM, PNDM, LDM, SD-v1, SD-v2, VQ-Diffusion);
- 跨模型泛化較好:比如ADM的DIRE 對 StyleGAN 也支持,
- 跨數據集泛化:LSUN-B訓練模型在ImageNet上也很好;
- 抗擾動較好:對JPEG壓縮 和 高斯模糊的圖,性能很好;
最后看下實驗指標,看起來在擴散模型上效果很好,這ACC/AP都挺高的,不知道在GAN圖上效果如何。
實驗結果顯示,這種基于擴散重建差的方法在區分真實與合成圖像上表現出色,這就像是在深度偽造的海洋中擁有了一張精確的導航圖。這種方法在不同的擴散模型上都展現了高度的準確性,這表明了它作為一種檢測工具的潛力。
總的來說,這篇研究為深度偽造檢測領域提供了一個新的視角和工具,其通過利用擴散模型的獨特能力,提出了一個既直觀又有效的方法來區分真實與合成圖像。這種方法的成功展示了深度學習領域中“以毒攻毒”的潛力,即使用生成技術的原理來反擊深度偽造的問題。
泛化能力和抗擾動
這一方法之所以具有較好的跨模型和跨數據集泛化能力,可以類比于一種“通用翻譯器”,它不僅能理解不同語言(即由不同模型生成的圖像)之間的差異,還能在不同的環境(即不同的數據集)中有效工作。此外,其良好的抗擾動性能表明,這種方法像是具有一種“穩定的免疫系統”,能夠在面對圖像質量下降(如JPEG壓縮)或視覺干擾(如高斯模糊)時,依然保持高效的檢測能力。
人臉偽造監測(Face Forgery Detection)
人臉偽造圖生成
人臉偽裝圖根據身份信息是否更改劃分為身份信息不變類和身份替換類。
身份不變類偽造圖在圖片修改/生成時不修改圖片中人物的身份信息,包括:
- 人臉編輯:編輯人臉的外部屬性,如年齡、性別或種族等。
- 人臉再制定:保留源主體的身份,但操縱其口部或表情等固有屬性;
https://github.com/harlanhong/awesome-talking-head-generation
https://github.com/Rudrabha/Wav2Lip - 身份替換類偽造圖在圖片修改時同時改變其中人的身份信息:
- 人臉轉移:它將源臉部的身份感知和身份不相關的內容(例如表情和姿勢)轉移到目標臉部,換臉也換表情等等,相當于把自己臉貼在別人的頭上;
- 換臉:它將源臉部的身份信息轉移到目標臉部,同時保留身份不相關的內容。即換臉,但不換表情,自己的臉在別人臉上做不變的事情;
- 人臉堆疊操作(FSM):指一些方法的集合,其中部分方法將目標圖的身份和屬性轉移到源圖上,而其他方法則在轉移身份后修改交換后圖的屬性,多種方法的復合;
其他類型假圖檢測(Others types of Fake Image Detection)
- 社交媒體中發的篡改圖:Robust Image Forgery Detection Against Transmission Over Online Social Networks, CVPR 2022: Paper Github
- 通用圖片造假檢測(局部造假等):Hierarchical Fine-Grained Image Forgery Detection and Localization, CVPR 2023: Paper Github

)

)




——多表查詢)










