根據論文:Semantic Parsing on Freebase from Question-Answer Pairs,分析其代碼和步驟,以加強對這一流程的深入理解,重點關注模型的輸入、輸出和具體方法。
前言
提供閱讀本文的前提知識,引用自Semantic Parsing on Freebase from Question-Answer Pairs這篇論文。
語義解析
知識庫由大量的三元組組成,并且這些三元組的實體和實體關系都是形式化的語言。
比如(BarackObama, PlaceOfBirth, Honolulu),給定一個自然語言的問題 “Where was Obama born?”,我們面臨的第一個挑戰就是,如何建立問題到知識庫的映射?
語義解析KBQA的思路是通過對自然語言進行語義上的分析,轉化成為一種能夠讓知識庫理解的語義表示,進而通過知識庫中的知識,進行推理(Inference)和查詢(Query),得出最終的答案。
簡而言之,語義解析就是將自然語言的問題,轉化為一種能夠讓知識庫“看懂”的語義表示,這種語義表示即邏輯形式(Logic Form)。
邏輯形式
為了能夠對知識庫進行查詢,我們需要一種能夠“訪問”知識庫的邏輯語言,Lambda-DCS是一種經典的邏輯語言,它用于處理邏輯形式而實際操作中我們經常用SPARQL,它通常可以在Virtuoso engine上對Freebase進行查詢。如果把知識庫看作是一個數據庫,邏輯形式則可以看作是查詢語句的表示。
我們用 z 表示一個邏輯形式,用 k 表示知識庫,e 表示實體,p 表示實體關系(有的也稱謂語或屬性)。邏輯形式分為一元形式(unary)和二元形式(binary)。對于一個一元實體 e ,我們可以查詢出對應知識庫中的實體;給定一個二元實體關系 p ,可以查到它在知識庫中所有與該實體關系 p 相關的三元組中的實體對。
并且,我們可以像數據庫語言一樣,進行連接Join,求交集Intersection和聚合Aggregate(如計數,求最大值等等)操作。具體來說,邏輯形式有以下形式和操作:
?

?
有了上面的定義,我們就可以把一個自然語言問題表示為一個可以在知識庫中進行查詢的邏輯形式,
比如對于問句 “Number of dramas starring Tom Cruise?”
它對應的邏輯形式是 count(Genre.Drama \cap Performance.Actor.TomCruise)
當自然語言問題轉化為邏輯形式之后,通過相應的邏輯語言(轉化為SPARQL query)查詢知識庫就可以得到答案。
所以接下來就是我們要學習和研究的重點:語義解析如何把自然語言問題正確地轉化為相應的邏輯形式?
1. 概要
該論文該方法來自斯坦福的 Jonathan Berant,發表于2013年的EMNLP會議,是一個經典的語義解析baseline。
論文在Freebase上提出訓練一個語義解析器,并基于該語義解析器進行KBQA,不再依賴于代價大的標注邏輯形式,而直接從問題-答案對中學習。給定自然語言問句,KBQA最棘手的問題就是存在相關的大量可能的邏輯謂詞,對于怎么從問題句子中降低可能的邏輯謂詞(logical predicates),作者提出了兩種方法:
(1)短語到謂詞的映射(mapping):通過將大型文本語料庫與Freebase對齊,構建一個語句到謂詞的粗糙映射
(2)橋接操作(bridging operation):基于相鄰謂詞生成與之兼容的邏輯謂詞
2. 模型
該模型為使用本文所將方法而實現的一個小的demo模型,具體流程和框架與原論文基本一致,其中2.1解析器方法會重點介紹論文中使用的Sempre源代碼和方法
2.1 模型架構

輸入:英語自然語言查詢
輸出:從Freebase中檢索出的自然語言答案
示例: Who did Obama marry? -> (SBARQ (WHNP (WP Who)) (SQ (VBD did) (NP (NNP Obama)) (VP (VB marry))) (. ?))
-> {'subject': 'Obama', 'property': 'marry'}
-> SELECT ?valLabel WHERE { { wd:Q76 p:P26 ?prop . ?prop ps:P26 ?val . } SERVICE wikibase:label { bd:serviceParam wikibase:language "en"} }
-> Michelle Obama
2.2 解析器方法—Sempre 1.0
源代碼文件框架
主要源文件:
-
Main.java:Sempre 主類,包含了 Sempre 的入口點。
-
Master.java:Sempre 主控類,負責調度和管理解析任務。
-
Session.java:Sempre 會話類,表示一個解析任務的會話。
-
Builder.java:Sempre 構建器類,用于構建語義解析器的各個組件。
解析器相關:
-
Parsers.java:解析器管理類,用于管理不同類型的解析器。
-
Parser.java:解析器接口,定義了解析器的基本行為。
-
BeamParser.java:Beam 解析器類,實現了基于 Beam Search 的解析算法。
語法和特征提取:
-
Grammar.java:語法類,用于管理語法規則。
-
FeatureExtractor.java:特征提取器類,用于從輸入中提取特征。
-
FeatureVector.java:特征向量類,用于表示特征。
執行器相關:
-
Executor.java:執行器接口,定義了執行器的基本行為。
-
SparqlExecutor.java:SPARQL 執行器類,用于執行 SPARQL 查詢。 其他支持類:
-
LanguageInfo.java:語言信息類,用于表示語言相關信息。
-
StringCacheServer.java:字符串緩存服務器類,用于管理字符串緩存。
-
FreebaseSearch.java:Freebase 搜索類,用于在 Freebase 中進行實體搜索。
輸入:給定 i)一個知識庫K ii)問題-答案對訓練集\{(x i, y i)\}_{i=1}^{n}
輸出:通過潛在邏輯形式z和知識庫K將問題x映射到答案y上的語義解析器
整體是一個自底向上構造語法樹的過程,樹的根節點,就是該自然語言問題最終的邏輯形式表達。可以分為兩個步驟:
-
1. 詞匯映射(Lexicon):即構造底層的語法樹節點。將單個自然語言短語或單詞映射到知識庫實體或知識庫實體關系所對應的邏輯形式。作者通過構造一個詞匯表(Lexicon)來完成這樣的映射。
-
2. 構建(Composition):即自底向上對樹的節點進行兩兩合并,最后生成根節點,完成語法樹的構建。這一步有很多種方法,諸如構造大量手工規則,組合范疇語法(Combinatory Categorical Grammars,CCG)等等,本方法中作者采用了最暴力的方法:對于任何兩個節點都可以執行上面所談到的連接Join,求交Intersection,聚合Aggregate三種操作。以及使用獨創的橋接操作進行結點合并。缺點是這種合并方式復雜度是指數級的,最終會生成很多棵語法樹,因此還需要通過對訓練數據進行訓練,訓練一個分類器,對語法樹進行篩選。
自然語言—>邏輯形式流程如下圖所示:
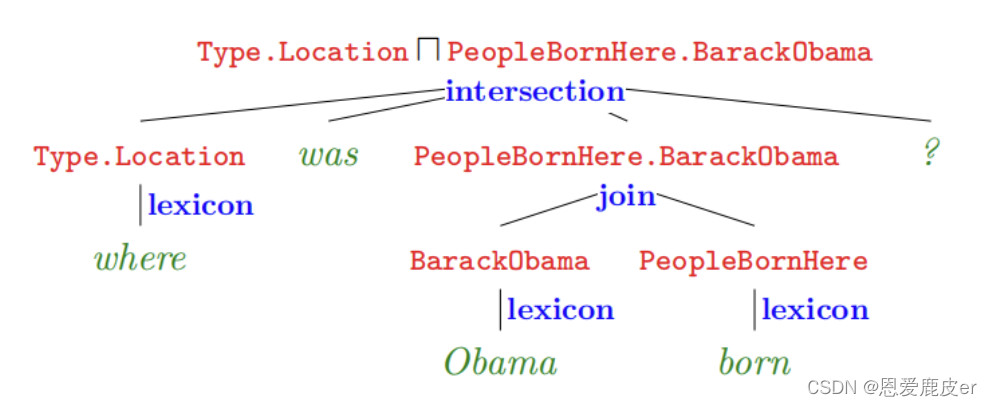
- 紅色部分即邏輯形式
- 綠色部分where was Obama born 為自然語言問題
- 藍色部分為詞匯映射(Lexicon)和構建(Composition)的操作
- 最終形成的語義解析樹的根節點為語義解析結果。
針對上面的方法,有三個待解決的細節問題:(1)如何訓練分類器?(2)如何構建詞匯表?(3)什么是橋接操作?
2.2.1 訓練分類器
分類器的任務是計算每一種語義解析結果d(Derivation)的概率,對于對每個 d ∈ D(x),使用判別對數線性模型discriminative log-linear model進行建模,使用Softmax進行概率歸一化,公式如下:
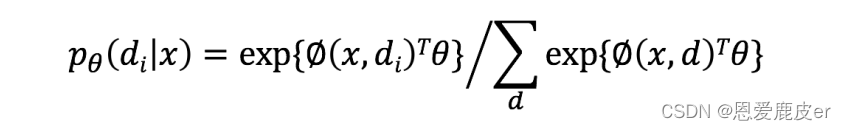
其中?是b維的參數向量,它是一個從語義解析結果
和x中提取出來的b維特征向量(該特征向量包含了構造該語法樹所有操作的對應特征,每種操作的具體特征之后會提到),
對于訓練數據對,訓練的目標是最大化Log-likelihood損失函數,通過AdaGrad算法(一種動態調整學習率的隨機梯度下降算法)進行參數更新。
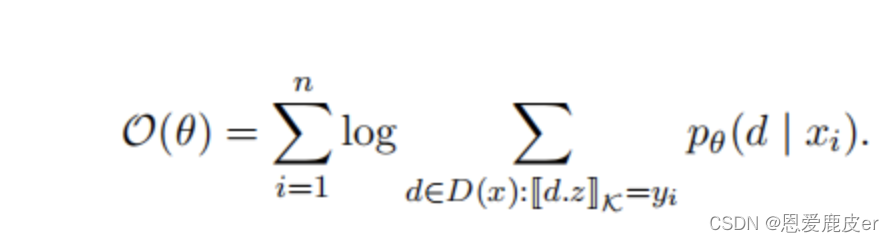
2.2.2 構建詞匯表
詞匯表即自然語言與知識庫實體或知識庫實體關系的單點映射,這一操作也被稱為對齊(Alignment)。
將自然語言實體映射到知識庫實體相對比較簡單,比如將“Obama was also born in Honolulu.”中的實體Obama映射為知識庫中的實體BarackObama,可以使用一些簡單的字符串匹配方式進行映射。
但是要將自然語言短語如“was also born in”映射到相應的知識庫實體關系,如PlaceOfBirth, 則較難通過字符串匹配的方式建立映射。
可以進行統計,如果有較多的實體對(entity1,entity2)作為主語和賓語出現在was also born in的兩側,并且在知識庫中,這些實體對也同時出現在包含PlaceOfBirth的三元組中,那么我們可以認為“was also born in”這個短語可以和PlaceOfBirth建立映射。簡而言之就是:如果一個句子兩端實體和知識庫謂詞兩端實體重復很多,則將這兩者對齊。
比如(“Barack Obama”,“Honolulu”),(“MichelleObama”,“Chicago”)等實體對在文檔中經常作為“was also born in”這個短語的主語和賓語,并且它們也都和實體關系PlaceOfBirth組成三元組出現在知識庫中。
本論文在ClueWeb09上抽取15millions個三元組構成一個數據集,如(“Obama”, “was also born in”, “August 1961”),可以看出三元組的實體和關系都是自然語言的形式,取出其中的一個三元組子集,對里面的每一個三元組的主語實體和賓語實體通過字符匹配的方式替換為知識庫的實體,并對數據進行歸一化。
如(“Obama”, “was also born in”, “August 1961”) 經過預處理后轉化為 (BarackObama, “was also born in”, 1961-08)。
接著對每一個三元組中的自然語言短語r_{1} 兩邊的實體對(entity1,entity2)進行統計。
注意?? 由于自然語言短語具有多義性,和知識庫實體關系
的對應關系是多對多的,比如“was also born in”可能對應PlaceOfBirth或DateOfBrith,我們需要對每一個
進行區分。可以通過知識庫查詢到每一個實體的類型(type),比如1961-08的類型是date,而Honolulu的類型是place,我們對
兩邊的實體類型進行查詢可以得到主語實體的類型
和賓語實體的類型t_{2},因此
可以進一步表示為
,我們對其所在三元組兩邊的實體進行統計,得到實體對集合
。對齊構造主要如下圖:
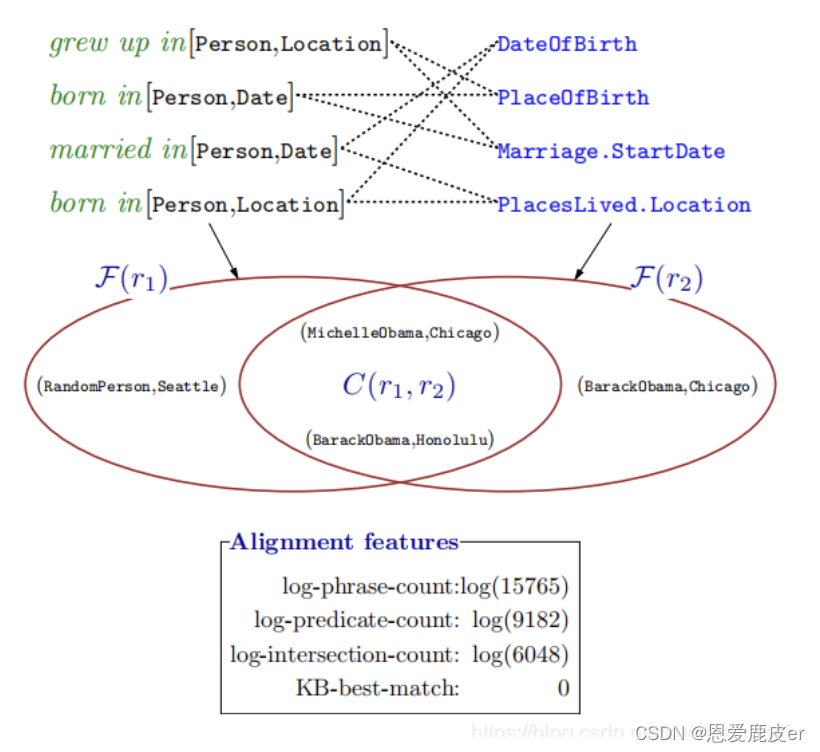
圖中綠色字體為r_{1},藍色字體為r_{2}。作者定義了詞匯映射操作的三種特征用于訓練分類器:對齊特征(Alignment features),文本相似度特征(Text similarity features),和詞匯化特征(Lexicalized features),具體內容如下表所示:
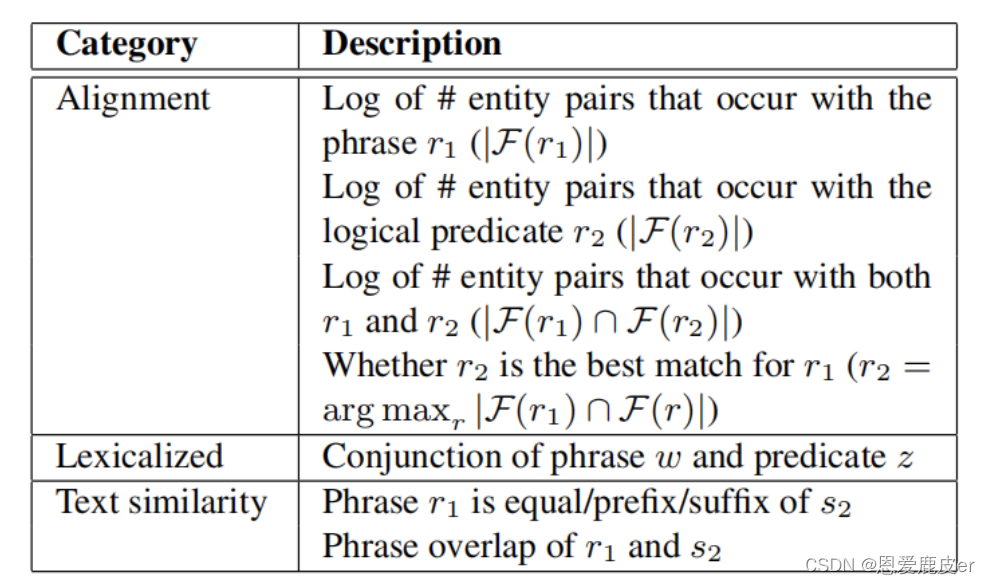
其中文本相似度特征中的s_{2}指r_{2}的freebase name。
在實際使用中,我們可以通過詞性標注(POS)和命名實體識別(NER)來確定哪些短語和單詞需要被詞匯映射(Lexicon),從而忽略對一些skipped words進行詞匯映射。并且,作者還建立了18種手工規則,對問題詞(question words)進行邏輯形式的直接映射,如“where,how many”映射為Type.Location 和 Count。
構建詞匯表/對齊部分的代碼位于文件:sempre/src/edu/stanford/nlp/sempre/paraphrase/Aligner.java
其中對齊操作在
align()方法中:public?Alignment?align(ParaphraseExample?example,?Params?params) {example.ensureAnnotated();Alignment?alignment?=?new?Alignment(example);alignment.buildAlignment(example,?params);example.setAlignment(alignment);return?alignment; }構建對齊結果,包括計算同義詞替換、刪除、添加等操作在Alignment 內部類的
buildAlignment()方法中:public?void?buildAlignment(ParaphraseExample?example,?Params?params) {computeIdentityAlignments(example);computePhraseTableAlignments(example);computeSubstitutionsAlignment(example);computeDerivationsAlignment(example);//this needs to be done lastmarkDeletions(example);if(opts.useSyntax)computeSyntacticAlignment(example);if(opts.verbose>=1) {printFeaturesAndWeights(params);}score?=?featureVector.dotProduct(params);}
2.2.3 橋接操作
完成詞匯表的構建后,仍然存在一些問題。比如,對于go,have,do這樣的輕動詞(light verb)難以直接映射到一個知識庫實體關系上,其次,有些知識庫實體關系極少出現,不容易通過統計的方式找到映射方式,還有一些詞比如actress,實際上是兩個知識庫實體關系進行組合操作后的結果 。因此需要找到一個額外的二元關系來將當前的邏輯形式連接起來,這就是橋接。
舉個具體的例子,比如 “Which college did Obama go to?”
假設“Obama”和“college”可被詞匯映射映射為 BarackObama和 Type.University,這里"go to"卻難以找到一個映射,所以這里我們需要去尋找一個中間二元關系b(即Education)使得上面的句子可以被解析為(Type.University Education.BarackObama),如下圖所示:
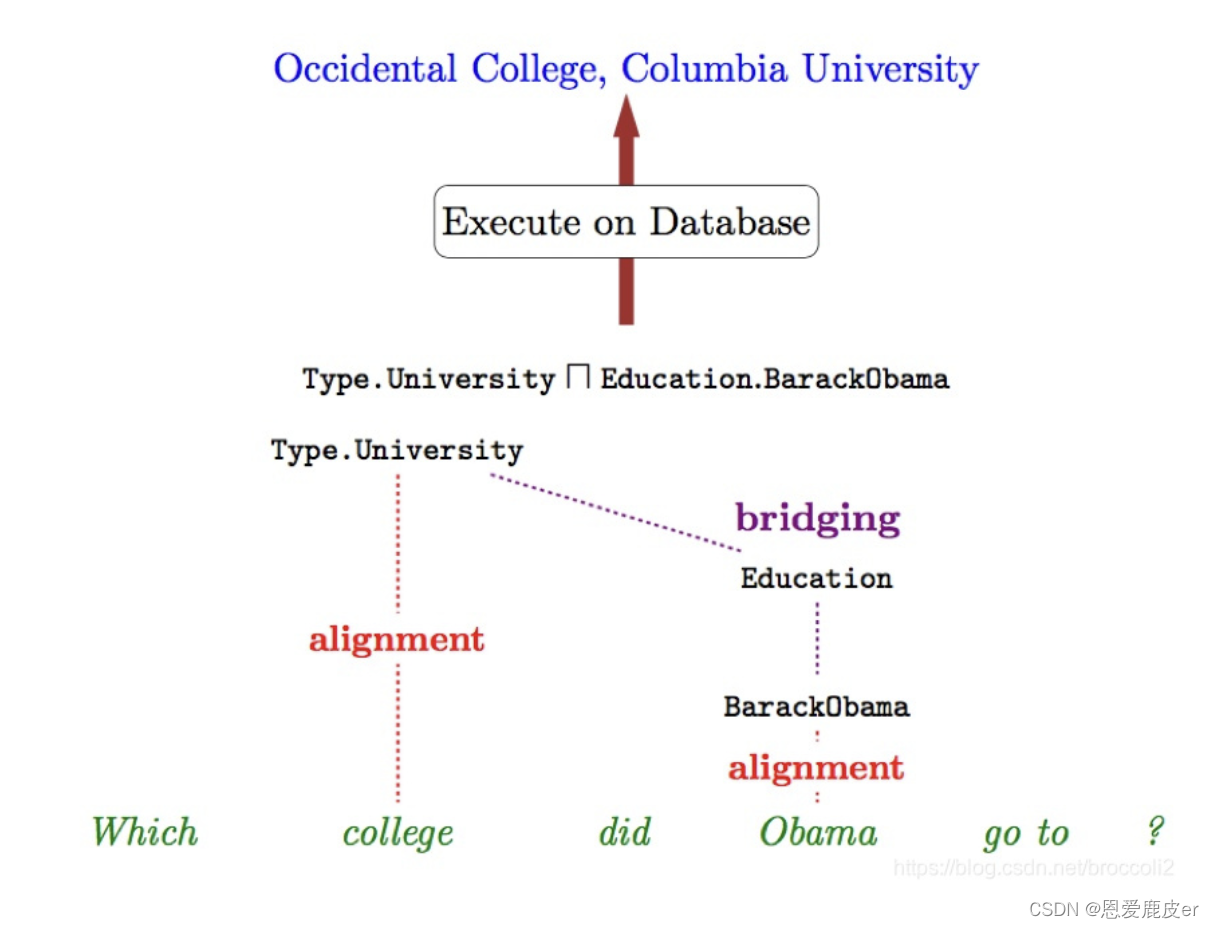
具體來說就是給定兩個一元邏輯形式,它們的類型分別為
,對于每個二元關系b如果它的主語賓語類型和
相同,則在b對應的實體類型滿足
的條件下,生成邏輯形式
橋接部分的代碼位于:sempre/src/edu/stanford/nlp/sempre/BridgeFn.java,其中
bridgeUnary()方法處理一元關系的橋接,它根據候選上下文和問題上下文的類型信息,以及二元關系的信息,將一元關系與二元關系連接起來;
bridgeEntity方法處理實體的橋接操作,它根據問題上下文的類型信息和二元關系的信息,將實體與相應的二元關系連接起來;
injectIntoCvt方法處理將實體注入到復合關系中的橋接操作,它找到復合關系中的待填充位置,并將實體與相應的二元關系連接起來。
3. 模型代碼
模型主要實現代碼位于nlquery代碼的nlquery/nlquery/nlquery.py文件,其中:
NLQueryEngine類包含了整個查詢流程的實現:
-
__init__方法會創建一個StanfordServerParser對象,用于將自然語言問題解析成樹狀結構。 -
subject_query方法的作用是將匹配到的上下文轉換為查詢參數,并執行查詢操作。這個方法主要用于處理主語查詢,即從自然語言問題中提取出主語、動詞動作、屬性等信息,然后根據這些信息執行查詢操作,最終返回查詢結果。 -
find_entity_query方法的作用是將匹配到的上下文轉換為查詢參數,并執行查詢以找到實體。該方法通常用于解析自然語言查詢,提取查詢中的實體、屬性和限定條件,并將其轉換為可以用于查詢實體的參數。最終,該方法將返回一個包含查詢結果的Answer對象。 -
get_property方法的作用是獲取給定主題的屬性。該方法通常用于根據給定的主題和屬性查詢相應的信息,比如查詢某個人的年齡、職業等屬性。根據查詢的結果,該方法會返回一個包含查詢結果的Answer對象。 -
preprocess方法的作用是對查詢語句進行預處理,主要是添加必要的標點符號,確保查詢語句的格式正確。通常情況下,查詢語句應以問號結尾,如果查詢語句缺少問號,則該方法會自動在末尾添加問號。
4.細節
-
對于知識庫的存儲,常見采用的是Virtuoso SPARQL engine,配合lambda-DCS進行查詢。
-
知識庫存儲也可采用jena+sparql框架實現,環境搭建https://jena.apache.org/download/
3. 參考/代碼資料
-
論文閱讀:Semantic Parsing on Freebase from Question-Answer Pairs-CSDN博客
-
解析器Sempre第一版代碼: Sempre 1.0 Webquestions training · Issue #47 · percyliang/sempre · GitHub
-
KBQA_Demo代碼:GitHub - ayoungprogrammer/nlquery: Natural Language Engine on WikiData

深度神經網絡的結構與設計)


 案例)





docker netty OOM問題記錄)
:2024.01.01-2024.01.10)
)



![[Android View] 可繪制形狀 (Shape Xml)](http://pic.xiahunao.cn/[Android View] 可繪制形狀 (Shape Xml))


