計算機原理系列
歡迎大家關注「海拉魯知識大陸」 多交流不迷路
Linux入門(二)
在上一章Linux入門(一)中rm -rf /是比較簡單的哈,那么升級一下:xargs指令的作用是啥呢?
1.進程
應用的可執行文件是放在文件系統里,把可執行文件啟動就會在操作系統里(具體來說就是在內存中)形成一個應用的副本,這個副本就是一個進程。
那進程就是應用的執行副本,進程也是操作系統分配資源的最小單位(前者是定義,后者是作用。)。
ps
如果你要看進程的情況,可以用ps指令。p代表processes,也就是進程;s代表snapshot,也就是快照。
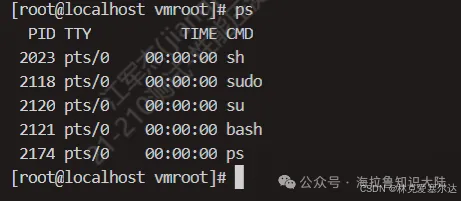
當然操作系統也不可能只有這么幾個進程,這是因為不帶任何參數的ps指令顯示的是同一個電傳打字機(TTY上)的進程。TTY這個概念是一個歷史的概念哈,用來傳遞信息,現在已經被傳真、郵件、微信等取代。
操作系統上的TTY是一個輸入輸出終端的概念,比如用戶打開bash,操作系統就為用戶分配了一個輸入輸出終端。沒有加任何參數的ps只顯示在同一個TTY的進程。
如果想看到所有的進程,可以用ps -e,-e沒有特殊含義,只是為了和-A區分開。我們通常不直接用ps -e而是用ps -ef,這是因為-f可以帶上更多的描述字段,如下圖所示:
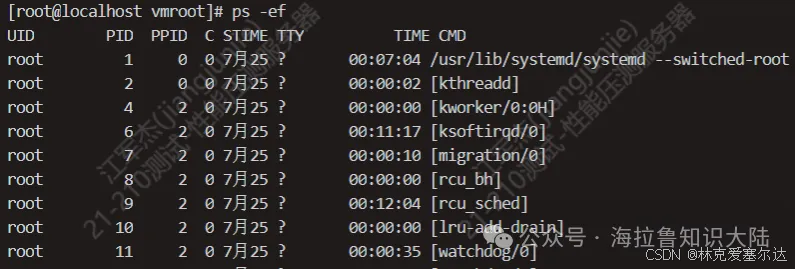
- UID指進程的所有者;
- PID是進程的唯一標識;
- PPID是進程的父進程ID;
- C是CPU的使用率;
- STIME是開始時間;
- TTY是進程所在的TTY,如果沒有TTY就是?號;
- TIME;
- CMD是進程啟動時的命令,如果不是一個Shell命令,而是用方括號括起來就是系統進程或者內核過程。
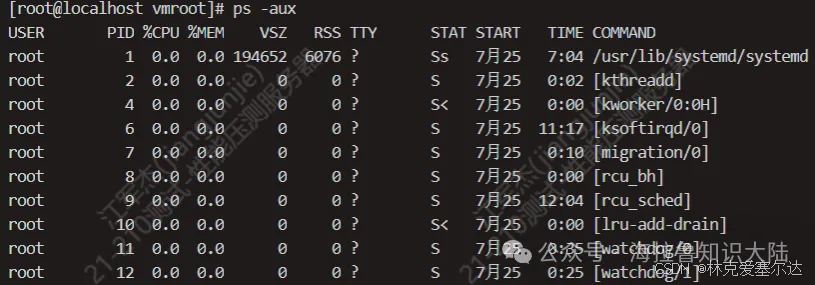
另外一個用得比較多的是ps aux,它和ps -ef差不多,感興趣可以自己了解下具體含義。
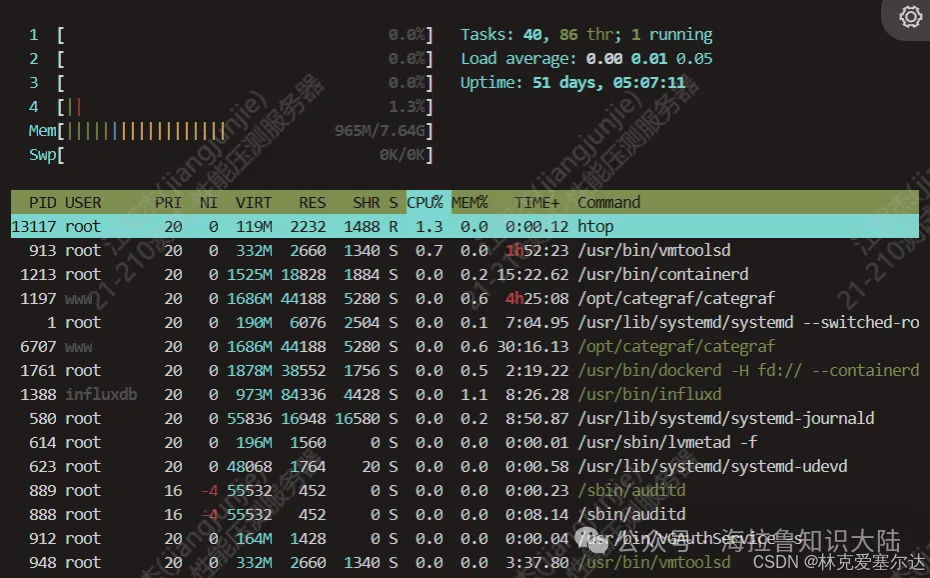
top
還有一個和ps能力差不多,是顯示的是實時更新數據的top指令。因為top顯示的內容有點少, 我用的比較多的是htop的指令。
2.管道(Pipeline)
下面我們來聊聊管道,管道(Pipeline)的作用是在命令和命令之間,傳遞數據。比如說一個命令的結果,就可以作為另一個命令的輸入。
輸入輸出流
每個進程擁有自己的標準輸入流、標準輸出流、標準錯誤流。
這幾個標準流說起來有點復雜,但你可以理解都是文件。
- 標準輸入流(用 0 表示)可以作為進程執行的上下文(進程執行可以從輸入流中獲取數據)。
- 標準輸出流(用 1 表示)中寫入的結果會被打印到屏幕上。
- 如果進程在執行過程中發生異常,那么異常信息會被記錄到標準錯誤流(用 2 表示)中。
重定向
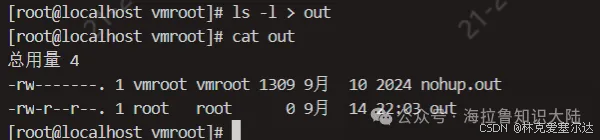
我們執行一個指令,比如ls -l,結果會寫入標準輸出流,進而被打印。這時可以用重定向符將結果重定向到一個文件,比如說ls -l > out,這樣out文件就會有ls -l的結果;而屏幕上也不會再打印ls -l的結果。
具體來說>符號叫作覆蓋重定向;>>叫作追加重定向。>每次都會把目標文件覆蓋,>>會在目標文件中追加。比如你每次啟動一個程序日志都寫入/var/log/somelogfile中,可以這樣操作,如下:
start.sh >> /var/log/somelogfile
經過這樣的操作后,每次執行程序日志就不會被覆蓋了。
另外還有一種情況,比如我們輸入:
ls1 > out
結果并不會存入out文件,因為ls1指令是不存在的。結果會輸出到標準錯誤流中,仍然在屏幕上。這里我們可以把標準錯誤流也重定向到標準輸出流,然后再重定向到文件。
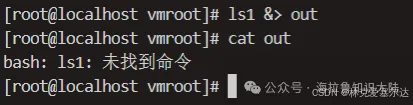
ls1 &> out
這個寫法等價于:
ls1 > out 2>&1
相當于把ls1的標準輸出流重定向到out,因為ls1 > out出錯了,所以標準錯誤流被定向到了標準輸出流。&代表一種引用關系,具體代表的是ls1 >out的標準輸出流。
管道的作用和分類
有了進程和重定向的知識,我們再梳理下管道的作用。管道(Pipeline)將一個進程的輸出流定向到另一個進程的輸入流,就像水管一樣,作用就是把這兩個文件接起來。如果一個進程輸出了一個字符X,那么另一個進程就會獲得X這個輸入。
管道和重定向很像,但是管道是一個連接一個進行計算,重定向是將一個文件的內容定向到另一個文件,所以這二者經常會結合使用。
Linux 中的管道也是文件,有兩種類型的管道:
- 匿名管道(Unnamed Pipeline),這種管道也在文件系統中,但是它只是一個存儲節點,不屬于任何一個目錄。說白了就是沒有路徑。
- 命名管道(Named Pipeline),這種管道就是一個文件,有自己的路徑。
FIFO
管道具有FIFO(First In First Out),FIFO和排隊場景一樣,先排到的先獲得。所以先流入管道文件的數據,也會先流出去傳遞給管道下游的進程。
3.使用場景分析
接下來我們聊聊幾個管道場景
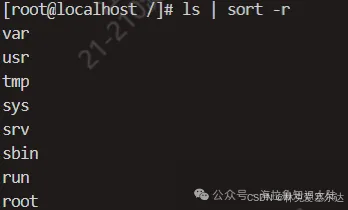
排序
比如我們用ls,希望按照文件名排序倒序,可以使用匿名管道,將ls的結果傳遞給sort指令去排序。你看,這樣ls的開發者就不用關心排序問題了。
去重
另一個比較常見的場景是去重,比如有一個字典文件,里面都是詞語。
如果我們想要去重可以使用uniq指令,uniq指令能夠找到文件中相鄰的重復行,然后去重如下。
篩選
有時候我們想根據正則模式篩選對應的內容。比如說我們想找到項目文件下所有文件名中含有jmeter的文件。就可以利用grep指令,操作如下:
find ./ | grep jmeter
find ./遞歸列出當前目錄下所有目錄中的文件。grep從find的輸出流中找出含有jmeter關鍵字的行。
如果我們希望包含jmeter但不包含jar就可以這樣操作:
find ./ | grep jmeter| grep -v jar
grep -v就是匹配不包含 jar的結果。
數行數
還有一個比較常見的場景是數行數。比如一個log文件想知道里面有多少行,就可以使用wc -l指令,如下:
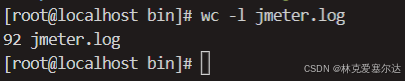
但是如果你想知道當前目錄下有多少個文件,可以用ls| wc -l,如下:
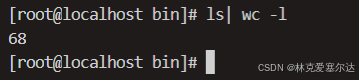
中間結果
管道一個接著一個,是一個計算邏輯。有時候我們想要把中間的結果保存下來,這就需要用到tee指令。tee指令從標準輸入流中讀取數據到標準輸出流。
tee還有一個能力,就是自己利用這個過程把輸入流中讀取到的數據存到文件中。比如下面這條指令:
find ./ -i "*.log" | tee testA | grep jmeter
這句指令的意思是從當前目錄中找到所有含有 jmeter關鍵字的log文件。tee本身不影響指令的執行,但是tee會把find指令的結果保存到testA文件中。
tee這個執行就類似英文字母“T”一樣,連通管道兩端,下面又開了口。這個開口,在函數式編程里面就叫副作用。
xargs
最后我們來看看初中難度的xargs指令。
xargs指令從標準數據流中構造并執行一行行的指令。xargs從輸入流獲取字符串,然后利用空白、換行符等切割字符串,在這些字符串的基礎上構造指令,最后一行行執行這些指令。
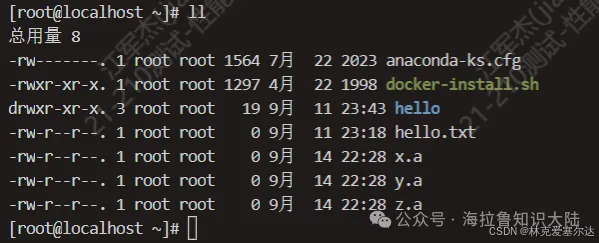
假如我們重命名當前目錄下的所有的文件,想在這些文件前面加一個前綴prefix_。比如說x.a文件需要重命名成prefix_x.a,我們就可以用xargs指令構造模塊化的指令。
現在有如下圖所示:
然后使用下圖中的指令構造我們需要的指令:
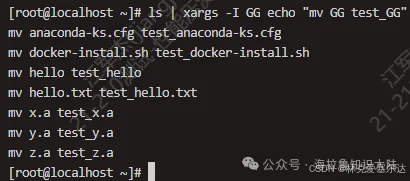
- 我們用ls找到所有的文件;
- -I參數是查找替換符,這里我們用GG替代ls找到的結果;-I GG后面的字符串GG會被替換為x.a、x.b或x.z;
- echo是一個在命令行打印字符串的指令。使用echo主要是為了安全,幫助我們檢查指令是否有錯誤。
我們用xargs構造了7條指令。
管道文件
上面我們花了較長的一段時間聊了匿名管道,用|就可以創造和使用。匿名管道也是利用了文件系統的能力,是一種文件結構。其實匿名管道是有一個inode,但不屬于任何一個文件夾。
還有一種管道叫作命名管道(Named Pipeline)。命名管道是要掛到文件夾中的,所以需要創建。用mkfifo指令可以創建一個命名管道,下面我們來創建一個叫作pipe1的命名管道,如下圖所示:

命名管道和匿名管道能力類似,但可以連接一個輸出流到另一個輸入流。
如果這時cat pipe1的時候,可以發現當前的終端處于等待狀態。因為cat pipe1的時候pipe1中沒有內容。
比如這個時候我們再找一個終端去寫一點東西到pipe中,比如說:
echo "XXX" > pipe1
這個時候,cat pipe1就會返回,并打印出xxx,如下所示:
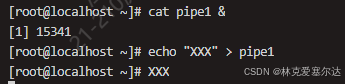
可以看到在cat pipe1后面增加了一個&符號。這個&符號代表指令在后臺執行,不會阻塞我們繼續輸入。然后echo指令往pipe1中寫入東西就會看到xxx被打印出來。
4.寫在最后
現在最開始的題目:xargs指令的作用是啥?
【解析】 xargs 將標準輸入流中的字符串分割成一條條子字符串,然后再按照我們自己想要的方式構建成一條條指令,拓展了Linux指令的能力。
比如我們可以用來按照某種特定的方式逐個處理一個目錄下所有的文件;例如弱網測試中需要根據一個IP地址列表逐個ping這些IP,收集到每個IP地址的延遲。




)














