2024 年伊始,Kyligence 聯合創始人兼 CEO 韓卿(Luke)分享了對 AI 與數據行業的一些戰略思考,以及對中美企業服務市場的見解,引發業界同仁的廣泛共鳴。正值 Kyligence 成立 8 周年,恰逢 AI 技術應用風起云涌之際,我們特此公開 Luke 在去年的一封全員信,一起回顧 Kyligence 在 AI 浪潮中的關鍵思考與決策:
-
在 AI 領域蓬勃發展的背景下,Kyligence 將如何布局發展戰略?
-
面對已經深度使用的眾多客戶,如何依托 AI 技術創造更大的價值?
-
深耕多年的大數據 OLAP 技術,如何在 AI 時代持續發揮優勢?
我們非常歡迎行業內的朋友們進一步交流和探討。我們期待各位在評論區留下您的見解和體會!
初心:聰明的神獸
2016 年,我們創立了 Kyligence,名字來自 Kylin 和 Intelligence,我們希望讓神獸變得更加聰明。在當年 Strata 北京大數據峰會上,Intel 和 Kyligence 一起成了“Intelligence”組合,那時候經常開玩笑說,Intel 搶了“智能”的前半個單詞,我們搶了后半個單詞,一起成就智能世界。

之所以要讓神獸變得更加聰明,是因為 Apache Kylin 最初在 eBay 內部誕生時,我們就希望這個項目能夠讓數據分析師、業務人員等更加簡單、方便、高效地使用數據。當年 eBay 內部分析師想要分析 Hadoop 上的數據要經歷非常痛苦和冗長的過程,而 Apache Kylin 的出現使得分析師能夠輕松且快速地訪問 PB 級別的數據。
當時,數據倉庫依然是主流,而 Hadoop 為核心的數據湖生態,缺乏標準、好用、高性能的 SQL 引擎,更無法和 BI 系統進行方便快速的交互。在打敗了內部其他 6 個相關項目(當時 eBay 內部發起了 Fast Analytics Program,同時驗證 7 種技術方向)后,Kylin 成為 Extreme OLAP on Hadoop,為分析師提供了方便快速的 SQL 交互能力,并在2014年開源并貢獻給Apache 軟件基金會,隨后在2015年成功畢業,成為中國團隊主導貢獻到 Apache 軟件基金會(ASF)的第一個頂級開源項目,獲得了全世界大量用戶的認可。因此,我們創業后的第一個 slogan 就是“釋放大數據生產力”,希望能夠借助 Kylin 打下的開源社區基礎,在企業級市場,通過提供提升效率讓客戶充分釋放大數據的潛力。
隨著 Kyligence 的成立,我們一直在提升性能、交互能力以及易用性等方面不斷進行投入,使得我們的商業版產品越來越好用。性能方面,開源的 Kylin 已經在各大互聯網廠商的大規模數據上得以驗證。而在走向商業客戶,尤其是金融客戶的過程中,我們更深刻理解了“生產力”的重要性。在傳統的數據倉庫方法論中,需要大量的 ETL 和建模工作來搭建數據基礎架構,而 Kyligence 大大改變了這里的工藝流程,使得用戶只需關心數據模型,而無需再建立各層 Summary Table 等,整個跑批、調整的過程可以通過配置方便進行,無需大量的開發、測試、上線等復雜流程。
2018年,在美國市場的實踐讓我們意識到,我們需要在“自動化”方面進行更多的投入。原因是我們發現在和美國的客戶進行交流、POC 和上線的過程中,我們依然需要大量的人工來完成底層模型的調優,這在美國這個人力成本極高的市場顯然不合適。同時我們也發現服務國內客戶上線的過程中,太多重復性的工作其實可以通過自動化來完成。經過艱苦卓絕的幾輪迭代(多次推倒重來,創新是建立在不斷的假設驗證改進的過程上),在2019年,我們發布了 AI 增強引擎,應該也是行業首個通過底層機器學習能力進行自動化建模和推薦的 OLAP 系統。
2019年 Kyligence 用戶大會 Luke 演講圖
正如右圖所示,Kyligence 后續幾年持續在自動化、智能化方面的不斷探索:解決指數級增長的數據和應用,與極其短缺的產業工人(數據分析師)之間的矛盾。我們深知,依靠誕生于70年代的傳統數據倉庫方法論已經無法適應支持每個人用好數據,必須依靠創新,才能進一步幫助我們的客戶完成數智化轉型。
從不斷迭代底層技術平臺,從 Hadoop 技術棧到 Spark 技術棧,再到云計算和全面容器化,我們同時也在不斷強化 AI 增強引擎方面的能力。隨著越來越多客戶使用該能力改善模型建設、系統調優和平臺運維等后,我們一直在思考,如何能夠更上一層樓,如何從后臺系統往前走一步,如何通過引入新技術、新方法,來改變人類使用數據的習慣。

2021年 Kyligence 用戶大會演講圖
浪潮:AI,AI,AI
2022 年底,隨著 ChatGPT 的橫空出世,通用化 AI 突然展現了巨大的能力,短短幾個月使得全世界為之瘋狂,大部分技術型創業公司如果沒有和大模型相關的產品和戰略,可能就得開始擔憂自己是否會 AI 淘汰了。2023 年初,我和管理層分享過一個我的思考:It's not our game, but we have to be part of the game, and we need to build our own game. 我們身處技術發展的漩渦,大模型并非我們的戰場,但 AI 最有可能幫助我們突出重圍。
| It's not our game
這句話說的是基礎大模型,這不是我們的 Game。工業級的大模型,需要三樣能力:算法、數據和算力。算法其實不難,很多開源的大模型早就存在,近一年我們看到更多開源框架跑分也越來越好。那么壁壘主要就在數據和算力了。
微軟的布局,使得 OpenAI(尤其是微軟版本)能夠訪問過去互聯網所有公開數據,以及微軟多年積累的獨特且私有的數據集,例如 MSDN、MSN、Office、LinkedIn、Github 等。在世界范圍內幾乎也是獨一無二了,即使是 Google、Facebook 等企業也都不算是企業級數據集。這使得 OpenAI 能夠學習的知識是獨一無二的,這是一個幾乎不可逾越的壁壘,除了微軟,沒有哪個公司擁有更多的互聯網級別的企業級數據集了。
而算力,實實在在的“鈔能力”,則是另一個無法逾越的壁壘。尤其是 OpenAI 使用 Azure 平臺,不僅使得 ChatGPT 能夠如此驚艷,Azure 平臺也能夠更好地提供大模型的云能力,再加上難搞到的 GPU,這里的壁壘高不可攀。
而這些,不是我們的領域。
| Be part of the game
革命性技術出現的時候,需要一些定力,沒看清楚就沖上去,容易成為先烈。而我們其實從未停止 AI 這方面的思索和試驗,從各個團隊到非正式的興趣小組,一直不斷探索。我們也深知 Kyligence 必須參與這場革命,但在沒有找到可以和 Kyligence 產品現有積累與優勢有機結合的觸點之前,我們選擇待時而動,即使當時已經完成了 ZEN 對 OpenAI 的集成。有不少創業公司甚至一夜之間變成了“AI 公司”,但卻講不清楚 AI 與其產品的故事,這當然不是我們的選擇。
那么,到底如何結合 Kyligence 產品優勢與大模型的強大能力?如何規劃一條別人難以復制的產品路線圖?我們過去多年積累的,一方面是 OLAP 技術的深度,在性能、并發、自動化、安全、高可用等企業級能力方面,我們一直處于行業領先位置;另一方面,我們的客戶群體,是中國最具商業價值的客群,以大型銀行、保險公司、跨國公司、頭部制造業、藥企等為主,付費能力、付費意愿和合規性等都很高。我們的信心在于 Kyligence 有堅實的技術和用戶基礎。基于我們的優勢,積極將 AI 能力引入以提升我們的產品和能力,用我們的方式參與這個 Game。
而如何將大模型能力結合進來,將是我們的 Game。
| Our game
Copilot in Kyligence Zen,是我們的答案。
Kyligence 從 2021 年開始戰略轉型,一直在往指標平臺方向演進,以充分發揮我們在 OLAP 領域的積累。通過指標平臺,我們向上支持用戶直接充分使用到 Kyligence 的底層能力;向下延伸有強大的向量化計算底座作為支撐。隨著 Zen 路線圖的日益清晰,我們在指標平臺這個領域取得了相當不錯的進展,從客戶項目的落地,到 Gartner 等權威報告等,都可以看到我們正引領著這個賽道。
同時,隨著基于 OpenAI 的原型推出,統一的指標平臺將是支撐 AI 在企業級數據和分析領域落地的基礎。在和大量行業先鋒客戶交流后,他們一致的反饋是:Copilot 這一形式正是他們想要的、甚至急迫看到落地的 AI 在數據和分析領域的應用。

2023年 Kyligence Zen 預覽版產品截圖
Copilot 是人機交互新方式,其使得普通人能夠以自然語言的方式,來指揮計算機系統完成復雜、專業的工作。以前必須依賴專業團隊(例如數據分析師、數據工程師等)完成的工作,現在完全可以由普通人+Copilot 來完成,大大降低了人類使用數據的門檻,也將改變人類使用數據的習慣。而指數級增長的用量和數據積累,則要求底層平臺能夠擁有強大的能力,同時以自動化、最低的成本來運行,而這些正好都是 Kyligence 長期積累的優勢。
而此前朝著指標平臺的及時轉型,也為我們今天快速構建滿足市場需求的 Copilot 奠定了基礎。在既定的戰略方向上,我們大大縮短了從早期市場進入主流市場的時間,加速跨越鴻溝。舉個例子,假如說 OLAP 到指標平臺是從 1 到 10 的改變,從普通汽車換成了跑車;而疊加了 Copilot 能力,則是增加了氮氣加速器,直接從 10 拉到了 1000,已經是另一個數量級的變革。
使命:釋放數智生產力
數智化轉型的關鍵,是賦能每個人使用數據進行運營和決策。
當前經濟形勢嚴峻,全球企業尤其是中國企業,都在降本增效,都要求更精細化的運營,希望數據賦能到一線業務,每個人都能用數據來加速日常的業務流程和決策。幫助客戶通過指標平臺和 Copilot 賦能每一個員工,釋放數智生產力,是我們一直以來的使命。數據與人工智能,必然能夠大大提升生產效率,甚至進一步改善生產關系。
| 人機交互新模式
首先,Copilot 帶來了人機交互模式的突破,自然語言能被理解、機器能夠推理,從而達到了人和機器之間的和諧,這是 OpenAI 等大模型帶來的顛覆式創新。
回到企業的日常作業或業務決策,往往需要獲取來自多個系統的不同數據和指標。傳統的報表和儀表盤模式,是難以讓普通員工快速、簡單使用的。在實踐中,我們往往會聽到業務的抱怨,為了獲得 3 - 5 個指標,不得不在各個系統間切換,一級一級找到某個報表,摘出某個指標,然后再在另一個平臺重復再重復,而業務使用數據的終點,永遠都是在 Excel。
在過去的 3 年里,Kyligence 一直致力于構建統一的指標平臺,而今天,通過 Kyligence Zen,無論大型企業還是中小型企業,普通員工都可以方便、快速地檢索和使用指標,用戶無需關心背后具體的系統、項目、報表,如果說 Cube 是對底層數據的索引,那 Zen 則是對業務指標的索引。
而基于 AI 的 Copilot,更使得這個能力有了指數級的提升。近一年里,我們看到 AI 已經可以完成各種語言理解、內容生成、自動轉化等,幾乎無需專業人員的參與,就能實現以往各種復雜的任務,這是人機交互的革命。
在數據分析領域,以往需要將需求描述給分析師,分析師再解釋給數據工程師,再由數據工程師完成復雜的數據處理,這個模式已經被顛覆。通過自然語言,將需求描述給 Copilot,AI 能夠準確理解意圖,并轉換為系統調用,基于系統結果,再進一步完成解釋。以往需要幾天、幾周以及多個角色的復雜工作,在今天,只需要幾句話,在幾分鐘甚至幾秒鐘內即可完成,這個改變非常的驚人。
而對于客戶而言,他們正期待這樣的交互能力,能夠早日賦能到業務一線,讓員工充分利用好數據,從而在激烈競爭的市場上,建立新的競爭壁壘。面對同樣的問題,一個公司用 Copilot 即可快速利用數據完成決策、采取行動,而另一個公司可能還在提需求、拉數據、做報表,那結果不言而喻。
回到 Kyligence 的產品架構,Kyligence Enterprise 提供企業級 OLAP 能力,Kyligence Zen 構建統一指標平臺,而 Kyligence Copilot 將提供基于大模型的 AI 能力,在 Copilot 里,企業可以充分調用指標推薦、分析、轉換、歸因等各種能力,同時還可內部使用和對外提供數據產品。
| 統一指標平臺
基于 OpenAI(或者其他大模型能力)構建 Copilot 從技術上來講并不難。然而,讓 AI 能夠在企業級客戶落地,統一的指標平臺是重要的先決條件。對于企業級用戶,如果沒有統一定義和標準的指標,如果指標不能被追溯和治理,容易產生“幻覺”的 AI 是無法被信任的。Kyligence Zen 提供的企業級指標平臺能力,從指標目錄,到指標定義、展現、歸因、標簽等,都是賦能 Copilot 的基礎。
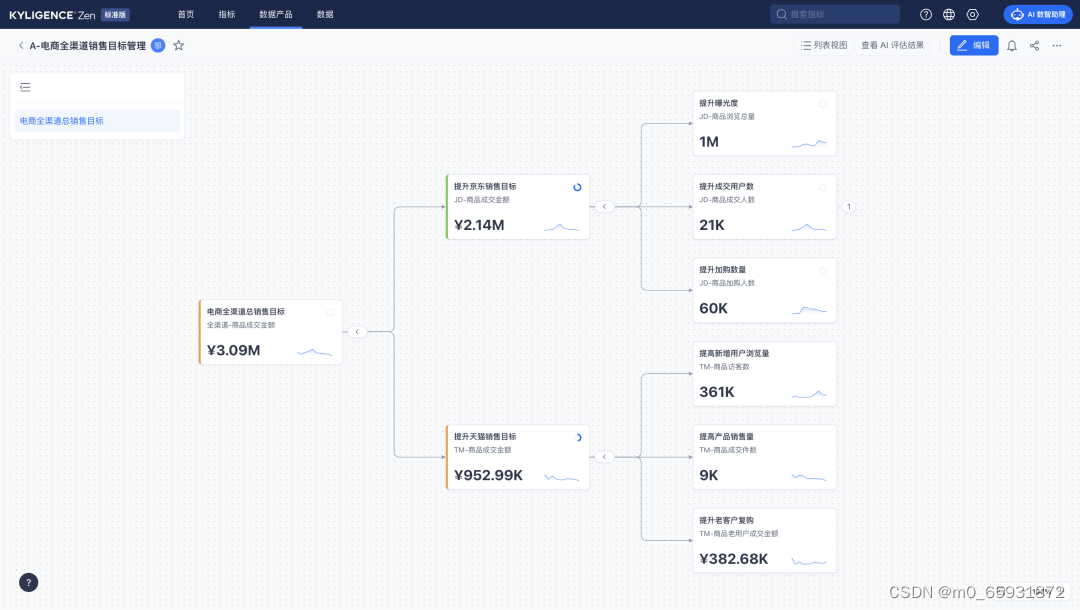

通過指標平臺構建企業共同的數據語言(Common Data Language),再由 Copilot 完成普通用戶的觸達和賦能,讓他們能夠方便地和系統交互,一方面大大增加了業務用戶使用指標的意愿,滿足他們個性化的數據需求,同時也能大大減少數據分析師、BI 工程師、數據分析師等的投入。
| ZenML - 指標定義語言
Zen Metrics Language(ZenML)是 Zen 指標的定義語言,也將是指標定義的標準。
在大部分企業內,已經現存一批業務或者管理的指標,沉淀了多年積攢的業務邏輯、分析思路以及管理思想等。這些數字資產廣泛存在于 BI、報表以及其他各種不同的系統中。如何更好地管理、復用和釋放這里的潛力,是大部分組織面臨的挑戰,也是很多組織不愿意遷移的顧慮。而 ZenML 通過統一的語言和自動化的工具,能夠幫助客戶快速將已有數據資產遷移到指標平臺,進一步釋放數據的潛力。
ZenML 詳細定義了指標的相關信息,基于 YAML 文件格式,得以在各個系統之間用同一種格式對數據和指標進行交互,并能夠使用版本管理工具進行版本管理,解決指標定義歷史的難題。將復雜的指標定義通過文件形式交互,這相比完全基于數據庫定義指標的系統,帶來了更開放的能力,使得用戶可以非常方便的從其他系統中抽取并轉義成 ZenML,也能支撐企業通過導出、導入功能和指標模版能力,在企業內外部復用或者遷移相關業務邏輯和數字資產,大大加速系統的上線時間。
| 高性能 & 高并發 OLAP
高性能是指標平臺的剛性需求。瞬息萬變的世界,用戶不愿意花長時間去等待 AI “loading”,只有為業務用戶提供快速的數據獲取和分析能力,才能讓組織在激烈的競爭中構建業務敏捷性以應對各種變化和挑戰。
高并發是滿足支持大規模/全量員工使用數據的基礎。大量的業務用戶涌入,將對系統的并發度有非常高的要求,一個國內企業,幾萬乃至幾十萬員工是正常的規模,為如此多的用戶提供指標分析能力,高性能和高并發 OLAP 基座幾乎是唯一的選擇。傳統的數據倉庫架構一方面無法應對可能產生的高成本 SQL(比如笛卡爾積),從而影響整個系統的性能甚至宕機;另一方面,大規模的并發訪問一向也是其弱點,在多個節點之間交換大量數據更容易導致系統崩潰。而高性能+高并發卻一直是 Kyligence OLAP 的領先優勢,通過分布式架構,在高性能和高并發場景上見長,在 AI 場景下,可以預見我們架構的優勢也將進一步拉大。
Kyligence 多年來不斷積累、打磨企業級 OLAP 引擎,經歷了國內外各種規模、各種苛刻場景的考驗,是當前行業內領先的系統。基于此推出的智能一站式指標平臺 Kyligence Zen 和 AI 數智助理 Copilot 更實現了新的人和數據交互模式,也是我們脫穎而出的競爭壁壘和巨大優勢。
沉潛蓄勢,厚積而薄發,不鳴則已,一鳴則驚人!
| 數據產品 - 構建生態
Kyligence Copilot 將直接能夠幫助用戶創建各種數據產品,可視化、報表、儀表盤、Excel、看板等,都是 Kyligence Zen 中數據產品的能力,數據產品以更開放的形態,將指標和工作流、應用等結合起來,完成特定的業務邏輯或管理需求。同時,可插拔的架構也支持引入第三方,為客戶提供各種基于數據和指標的能力,來不斷豐富我們的生態和邊界。
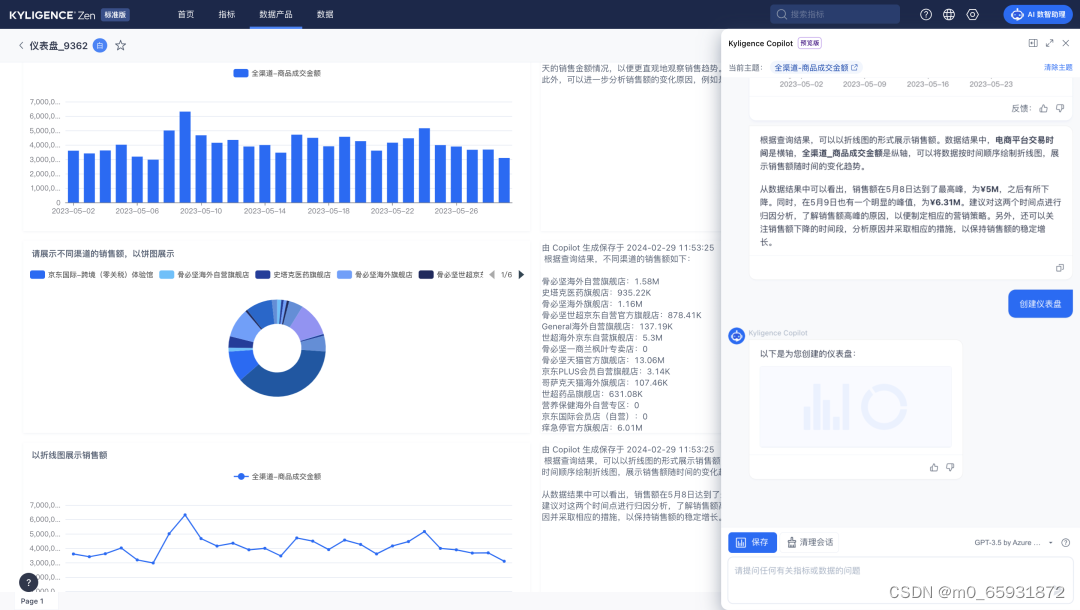
系統可自動創建 Dashboard
借助 AI 的能力,用戶只需和 Copilot 進行對話,就能幾秒創建一個儀表盤,這將大大提升數據和分析的效率,把大量的重復勞動轉為 AI 去實現,真正提升生產力。
| 成本、成本、成本
賦能普通用戶大規模使用數據最后的挑戰一定是成本,組織需要在賦能更多人使用和相應成本之間衡量 ROI。隨著數據湖、云計算等技術的迭代,今天使用大數據、數據倉庫的成本已經越來越低。而我們所代表的 MOLAP 流派,一直以空間換時間的方式,為客戶提供成本最優的解。考慮到 AWS S3 1TB 的費用不過幾十美元一年,可以看到我們產品和架構,在大規模使用場景下的成本優勢。
同時,我們的不斷創新,我們的向量化 Spark 能力已經能夠提升至少一倍的性能,也就是說在同樣場景下,能夠節省一半的資源,這對于絕大部分客戶來說,都是一筆非常可觀的費用節省。成本優化也將是我們長期的研究方向。
方法論:邊使用邊治理
數據倉庫是一個專業且復雜的工程,沒有合適的方法論,是無法順利幫助客戶實現價值的。
在過去,傳統的數據倉庫方法論,強調為決策層提供決策支持的能力(DSS,決策支持系統),其假設是決策只需要由管理層或少部分決策者進行,但數據必須精準(傳統制造業確實只需要中高層完成決策即可)。同樣因為技術的限制,即使是昂貴的硬件,也無法滿足廣泛的數據需求。從而在過去幾十年,數據倉庫領域一直遵循的是“先治理后使用”的方法論。組織建設數據倉庫等系統是為了更好地利用數據進行決策,通常都會先找咨詢公司等先把數據治理咨詢做好,定義規范,最后再開始建立系統,周期往往需要6-9個月,甚至用年計算。
比如談到指標,先要起個咨詢項目來規劃指標體系,明確每個指標的加工口徑,然后才是考慮引入 IT 系統進行落地。但這種方式通常有幾個問題:
-
咨詢費時費力反且不討好,管理層長時間看不到效果;
-
IT 很難牽頭負責,業務部門配合困難,過程涉及數據主權、管理歸屬等,而業務部門沒有動力去做牽頭做這樣的系統;
-
咨詢項目的結果通常以固定的文檔呈現,而指標定義和系統則是不斷變化和發展的,遇到新的業務發展形態,還是會出現口徑不一致的指標,所謂的治理永遠是跟在業務后面“擦屁股”,費力且不討好。
而現在,新的商業、經濟模式、企業形態不斷涌現,傳統的數據倉庫理論已經無法滿足當前日益增長的人人用數需求。如 2021 年 Kyligence 用戶大會提到:
-
數據已經無法全部集中化,必須通過連接的方式來訪問全部內外部數據 ;
-
使用數據的人群從少數據決策者和分析師,轉變成了一線人員、人人都需要使用數據;
-
從 Known 到 Unknown,大部分人是不知道組織有什么指標可以使用,也不知道如何使用,需要系統告訴他們發生了什么,如何解決等。
在和全球諸多大型客戶多年的合作后,我們發現必須對數據倉庫方法論進行創新和突破,新的技術和能力,也使得新的方法論成為可能。“邊使用邊治理”是我們的方法論,Kyligence 的 AI 增強引擎,則使得這種方法論得以實現。
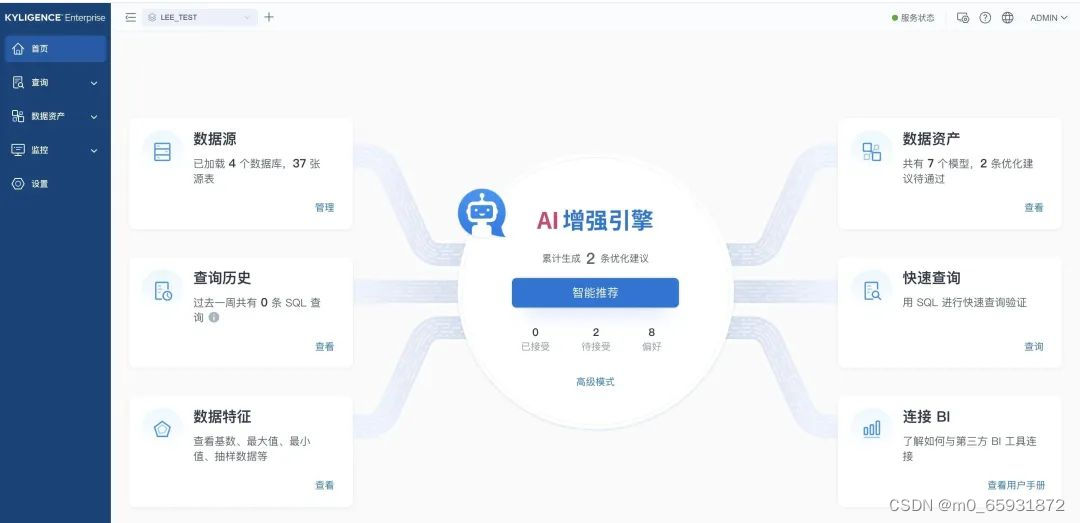
將混亂轉變為有序,即是治理。以往,治理需要專家,以及消耗非常多的資源和時間來完成,另一方面,以往的數據倉庫極其昂貴,無法忍受混亂帶來的冗余和浪費。而今天,以對象存儲為核心的云計算模式,存儲已經極其低廉,能夠接受非常大程度的冗余,大大增加了個性化服務的可能性。而得益于技術的發展,尤其是 Kyligence 的 AI 增強引擎,能夠自動化地從 SQL 歷史和使用記錄中,推薦出相關模型,從而自動化完成治理,大大降低了“治理”的難度。
通過“邊使用邊治理”模式,我們已經幫助各行各業的客戶,在支持業務靈活性和系統良好治理之間,實現動態平衡。
結語:世界級軟件公司
通過 Kyligence Copilot 帶來的人機交互新模式,將使用數據的門檻降到了最低,數據和分析行業正在迎來巨大的變革。通過統一指標平臺,使得基于 AI 的人和數據之間的交互得以輕松實現;通過高性能、高并發 OLAP 引擎和其他技術,使得能夠支撐大規模的數據使用,實現人人用數,幫助我們的客戶釋放數智生產力,這是我們的使命。
成為一家世界級軟件公司(👈點擊查看原文),一直是我們的愿景。從創業伊始,我們就相信來自中國的技術,一定可以改變世界,一定可以被全世界的客戶認可。在過去幾年,我們已經贏得了大量的國際客戶和國內客戶,驗證了我們的產品和技術。隨著 Kyligence ZEN 和 Copilot 的推出,我們正實現“把簡單留給用戶,把復雜交給 AI”,更有信心進一步引領數據和分析行業。道阻且長,但充滿了各種可能和榮耀,希望和各位同學一起,我們齊心協力,積跬步,智千里!
CEO Luke
2023-06-05
關于 Kyligence
跬智信息(Kyligence)由 Apache Kylin 創始團隊于 2016 年創辦,是領先的大數據分析和指標平臺供應商,提供企業級 OLAP(多維分析)產品 Kyligence Enterprise 和智能一站式指標平臺 Kyligence Zen,為用戶提供企業級的經營分析能力、決策支持系統及各種基于數據驅動的行業解決方案。
Kyligence 已服務中國、美國、歐洲及亞太的多個銀行、證券、保險、制造、零售、醫療等行業客戶,包括建設銀行、平安銀行、浦發銀行、北京銀行、寧波銀行、太平洋保險、中國銀聯、上汽、長安汽車、星巴克、安踏、李寧、阿斯利康、UBS、MetLife 等全球知名企業,并和微軟、亞馬遜云科技、華為、安永、德勤等達成全球合作伙伴關系。Kyligence 獲得來自紅點、寬帶資本、順為資本、斯道資本、Coatue、浦銀國際、中金資本、歌斐資產、國方資本等機構多次投資。



docker netty OOM問題記錄)
:2024.01.01-2024.01.10)
)



![[Android View] 可繪制形狀 (Shape Xml)](http://pic.xiahunao.cn/[Android View] 可繪制形狀 (Shape Xml))





:視頻超分讓像素細膩生動)



