算法簡介
AlexNet是人工智能深度學習在CV領域的開山之作,是最先把深度卷積神經網絡應用于圖像分類領域的研究成果,對后面的諸多研究起到了巨大的引領作用,因此有必要學習這個算法并能夠實現它。
主要的創新點在于:
- 首次使用GPU進行神經網絡加速訓練
- 使用使用了非飽和的激活函數ReLU,而不是傳統的sigmoid和tanh
- 使用了數據增強手段抑制過擬合
- 提出了Dropout隨機失活抑制過擬合
- 提出了LRN局部響應歸一化
- 使用了重疊池化抑制過擬合
model.py代碼講解
import torch.nn as nn
import torchclass AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] 使用48個11*11的卷積核,步長為4,padding為2 output[48, 55, 55]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # input[48, 55, 55] output[48, 27, 27]nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6])self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)def forward(self, x):x = self.features(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return x
model.py的全部代碼如上
現在逐行進行分析
class AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] 使用48個11*11的卷積核,步長為4,padding為2 output[48, 55, 55]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # input[48, 55, 55] output[48, 27, 27]nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6])
class AlexNet(nn.Module):
定義了一個AlexNet的類,這個類繼承了nn.Module
def init(self,num_classes=1000):
定義了類的初始化函數,它有個可選的參數 num_classes是我們這個神經網絡在輸出的分類數
super(AlexNet,self).__init()
這是為了調用父類的初始化函數
self.features = nn.Sequential()
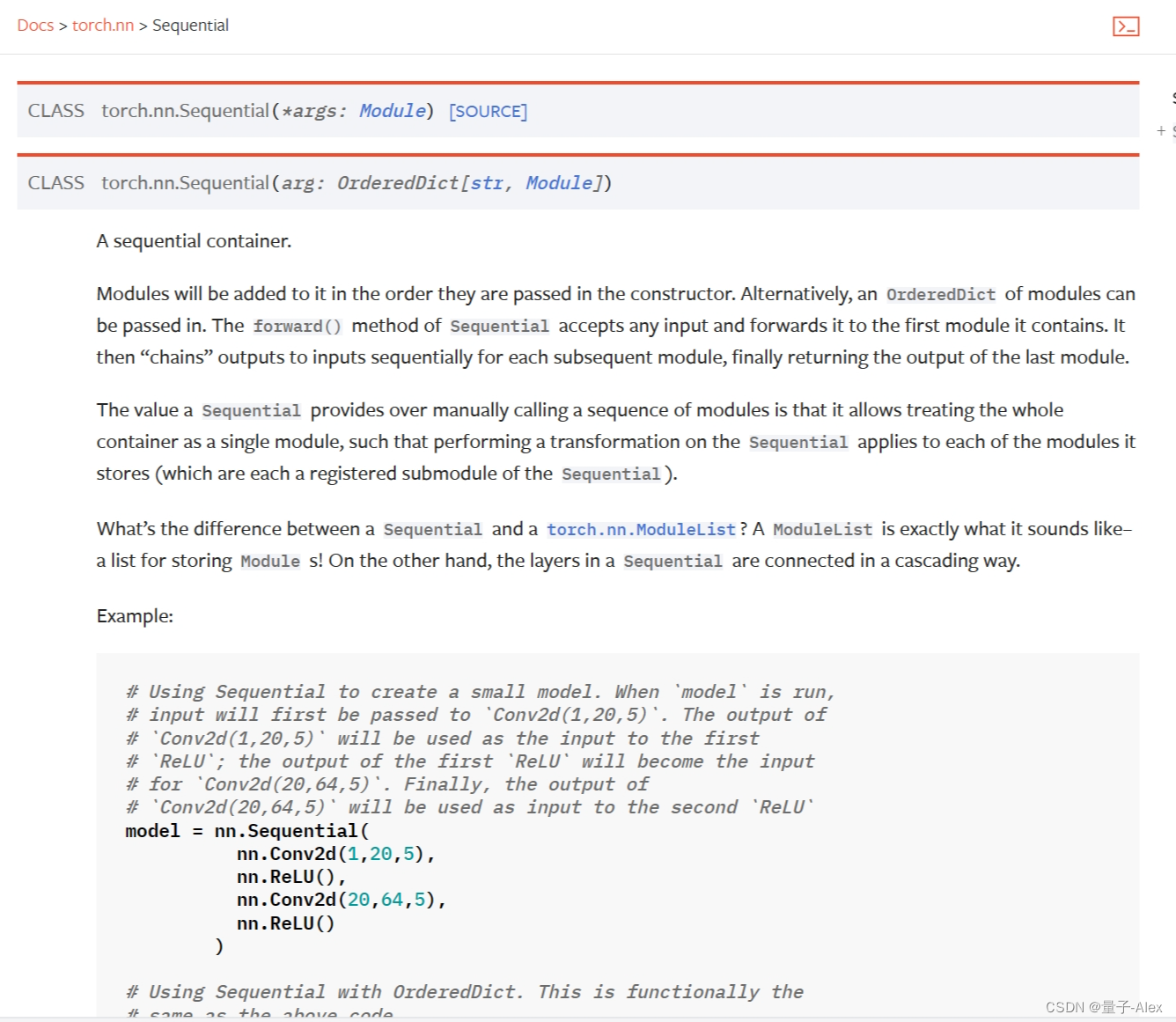
這里非常重要,我們可以去Pytorch的官方文檔上看看,
官方的解釋是:
模塊將按照傳入構造函數的順序添加到其中。另外,也可以傳入一個有序字典的模塊。Sequential的forward()方法接受任何輸入,并將其轉發給它包含的第一個模塊。然后,對于每個后續模塊,它將輸出“鏈接”到輸入,最終返回最后一個模塊的輸出。
Sequential相對于手動調用一系列模塊的優勢在于,它允許將整個容器視為單個模塊,這樣對Sequential執行的轉換將應用于其存儲的每個模塊(它們分別是Sequential的注冊子模塊)。
Sequential和torch.nn.ModuleList之間有什么區別?ModuleList就像它的名字一樣-用于存儲Module的列表!另一方面,Sequential中的層以級聯方式連接。
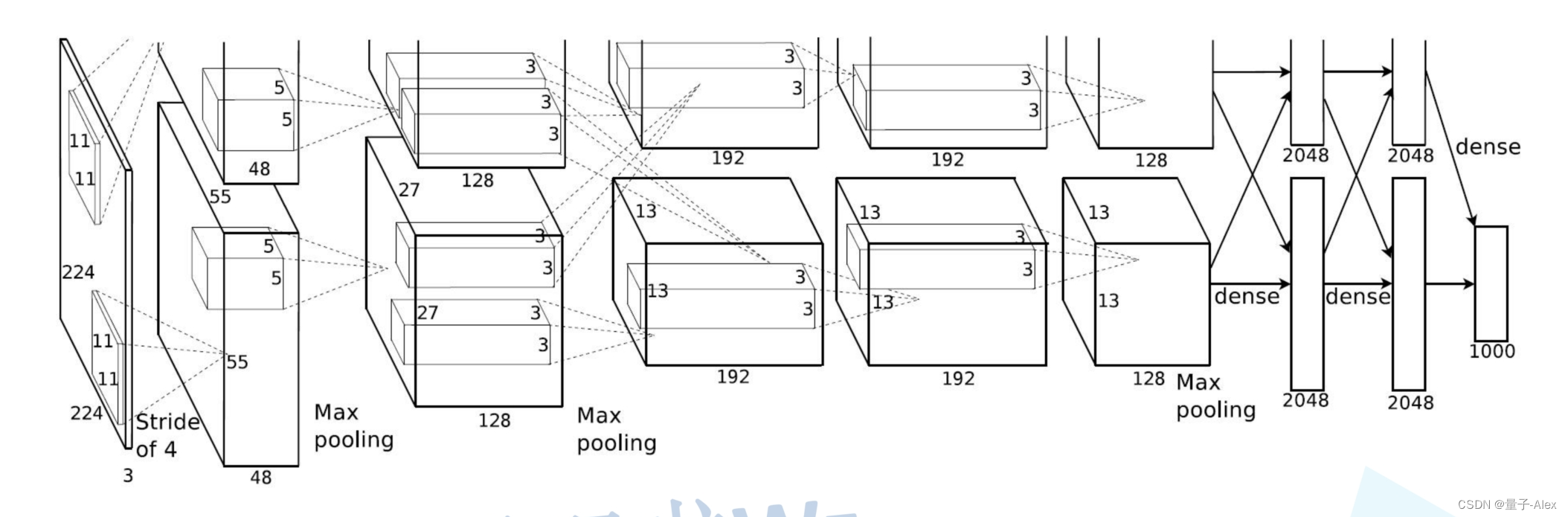
論文中的AlexNet網絡結構圖如下:
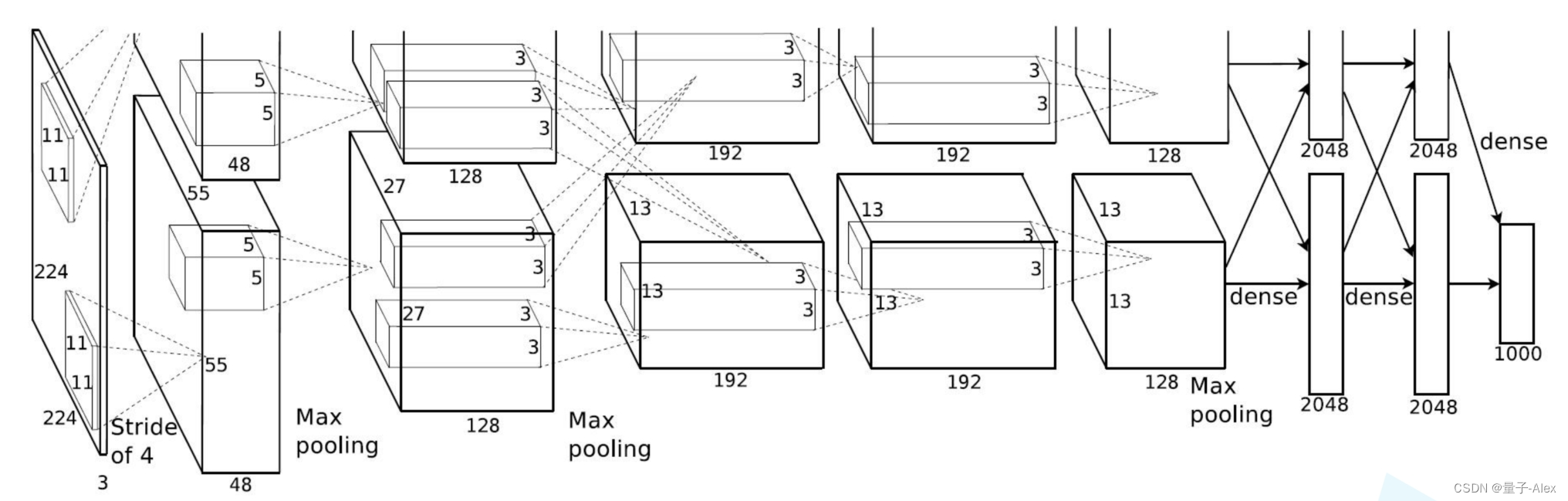
AlexNet是第一個網絡結構開始變得更加復雜的神經網絡模型(Lenet)只有兩個卷積層和兩個全連接層,而AlexNet有5個卷積層和3個全連接層,對于逐漸復雜的網絡結構,我們可以利用Sequential函數搭建序列化的網絡模塊
比如這里我們首先定義了一個features模塊
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
第一個卷積層 輸入是2242243 48個1111的卷積核 步長是4,填充是2
輸出是5555*48
nn.ReLU(inplace=True),ReLU激活函數
nn.MaxPool2d(kernel_size=3, stride=2),
定義一個最大池化層,使用3x3的池化核,步長為2。這將進一步減少特征圖的尺寸。
nn.Conv2d(48, 128, kernel_size=5, padding=2),
又是一個卷積層,輸入是272748 128個55的卷積核 填充是2,輸出是2727*128
然后以此類推
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), 又是激活函數和池化,池化后輸出 1313128
nn.Conv2d(128, 192, kernel_size=3, padding=1), 輸入1313128 輸出1313192
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),輸入1313192 輸出1313192
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), 輸入1313192
輸出1313128
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), 輸入1313128 輸出 66128
self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)
第二個模塊,上一個是5層卷積層加3層池化層提取特征
下面這個模塊就是全連接層做分類
首先是drouput隨機失活抑制過擬合的操作
然后是 nn.Linear(128 * 6 * 6, 2048),12866的原因是全連接層是接著前面的最后一個也是第三個池化層,池化層的輸出就是12866
后面再接兩個全連接層,最后一個全連接層的輸出就是對1000個類的預測結果
def forward(self, x):x = self.features(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return x
def forward(self, x):
定義一個名為forward的方法,這是PyTorch中自定義神經網絡層或模型的標準做法。這個方法描述了輸入數據x通過網絡的前向傳播過程。
x = self.features(x)
將輸入數據x傳遞給feature模塊
x = torch.flatten(x, start_dim=1)
使用PyTorch的flatten函數將特征圖x在指定的維度(start_dim=1,通常是指從第二個維度開始,即特征圖的深度維度)展平。這通常是為了將多維的特征圖轉換為一維的張量,以便輸入到全連接層。
這里要重點說明一下,在feature后輸出的x是一個四維的參數(B,C,H,W)分別是batchsize channel 高、寬 而這個函數的意思是從第二維channel開始,對后三維 通道數、寬、高進行展開,轉為一維的向量輸入全連接層
x = self.classifier(x)
將展平后的特征x傳遞給classifier
return x
返回經過分類器處理后的輸出。



——附代碼數據)
)






)



詳解)



