 引言
引言
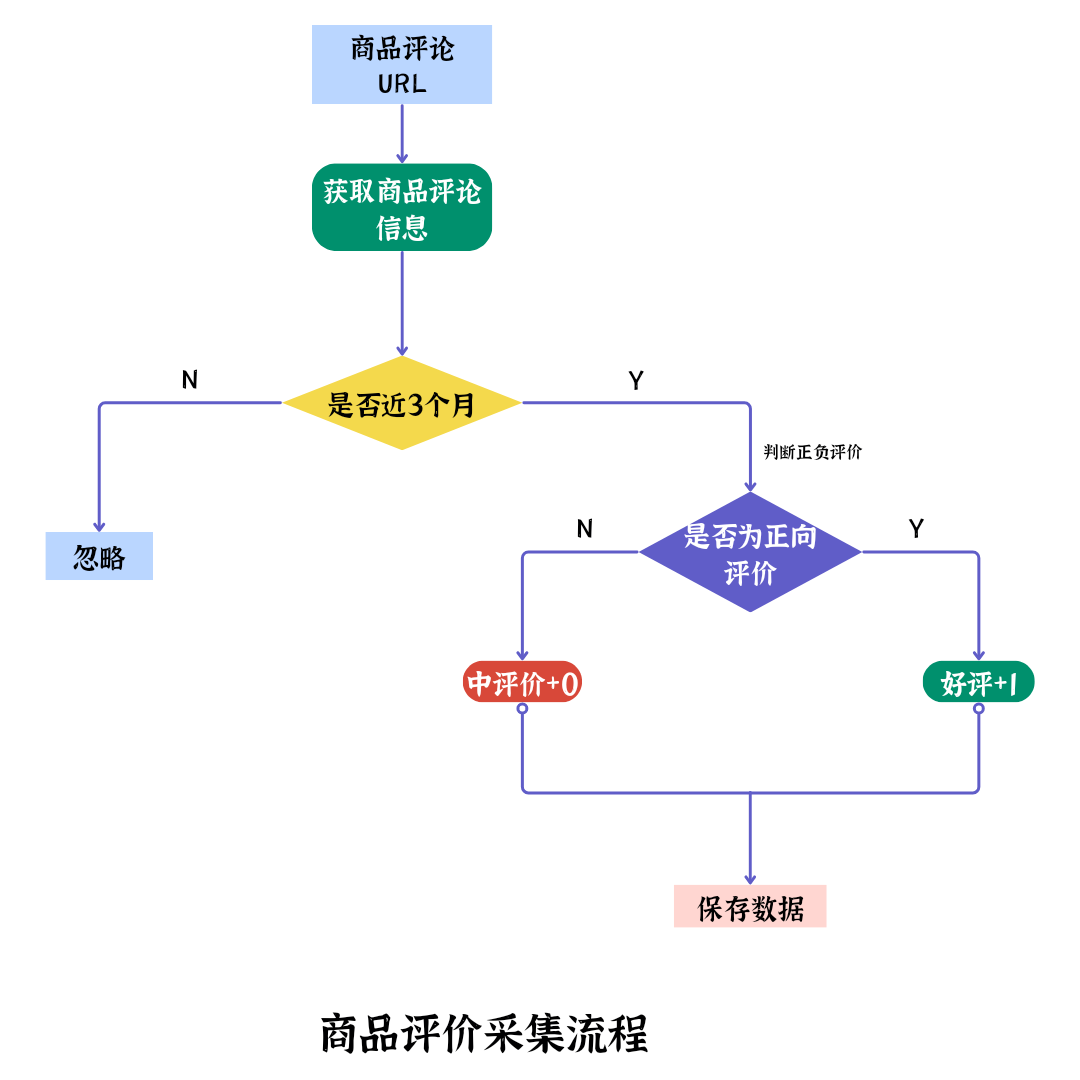
在電商競爭日益激烈的情況下,商家既要提高產品質量,又要洞悉客戶的想法和需求,關注客戶購買商品后的評論,而第三方商家獲取商品評價主要依賴于人工收集,不但效率低,而且準確度得不到保障。通過使用Python網絡爬蟲技術采集數據近期店鋪商品評論信息,進行數據清洗、分詞、去除停用詞、詞頻統計等數據預處理,最終繪制詞云圖實現數據可視化,并對數據結果進行分析,為商家提高選品質量、制定個性化的營銷策略提供依據。
數據處理
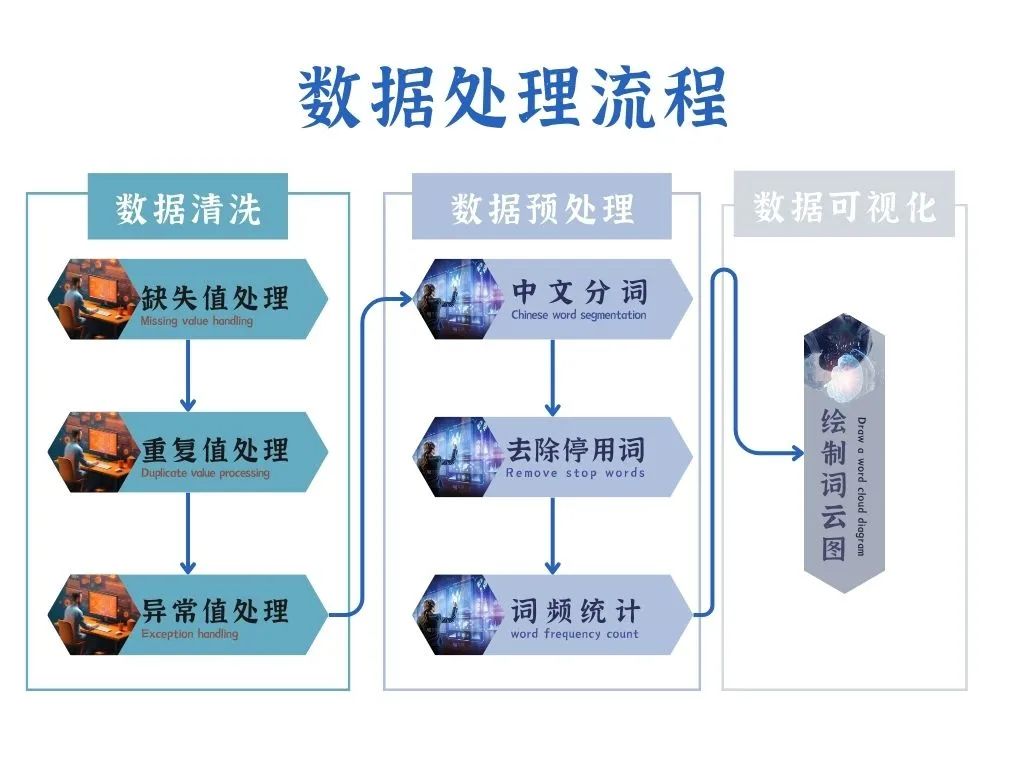
網絡爬蟲程序采集到的文本數據可能會出現“臟數據”,因此需要對其進行數據清理,包括去除缺失值、重復值及異常值,還需要對清洗過的數據進行中文分詞、去除停用詞和詞頻統計等操作,最后繪制詞云圖以實現數據可視化。
電商API接口數據采集
Data Cleaning
數據清洗
數據清洗包括對缺失值、重復值和異常值的處理。
缺失值處理
采集到的評論數據中可能存在一些空值,因此需要對其進行缺失值處理。在pandas庫中,可以使用isna()方法查找缺失值,返回缺失數據用True表示。由于缺失值占總數據量的比重比較低,將有空值的評論記錄刪除后并不會妨礙后續的數據分析,故使用dropna()方法直接刪除有缺失值的數據。
重復值處理
當不同客戶對于某個商品發布完全相同的評論時,需要對這些數據做去重處理。利用pandas庫的duplicated()方法可以查找重復數據,返回重復值用True來表示。使用drop_duplicates()方法能直接刪除重復的評論數據。
異常值處理
數據中有一個或多個數值超出了實際的限定范圍,這樣的數值稱為異常值。在爬取的評論數據中存在“此用戶沒有填寫評價”的系統自動好評,該值對后期數據分析沒有實際作用,因此需要對其進行過濾,以清除異常值。
data preprocessing
數據預處理
對清洗后的評論數據還需要做中文分詞、去除停用詞、詞頻統計等處理,為后期繪制詞云圖打下基礎。
中文分詞
中文分詞是將一個漢字序列分割成一個個單獨的詞,其過程是將連續的字序列按照一定的規范重新組合成詞序列。中文分詞的方法可以分為基于字符串匹配的分詞、基于理解的分詞和基于統計的分詞。在此使用基于字符串匹配的分詞方法,也就是按照一定的策略將待分析的漢字串與一個機器詞典中的詞條進行匹配,如果在詞典中找到某個字符串,則匹配成功,即辨識出一個詞。
去除停用詞
為節省存儲空間和提高搜索效率,搜索引擎在處理搜索請求時會自動忽略某些不重要的字或詞,這些字或詞就是停用詞。停用詞主要分為兩類,一類是應用廣泛但實際難以幫助搜索引擎縮小搜索范圍,甚至會降低搜索效率的詞,例如,“Web”;另一類是自身沒有明確意義的詞,包括助詞、副詞、介詞、連接詞等,這類詞出現的頻率較高,但對后續的數據分析沒有實際價值,因此需要去除。
詞頻統計
對評論數據去除停用詞后,需要對數據中詞出現的頻率進行統計。詞的總數為不重復的詞語數量的總和,為后續的繪制詞云圖做準備,這里用的是collection模塊的Counter方法,篩選出詞頻排名前100的詞。
Data visualization
數據可視化
詞云圖是對文本數據中出現頻率較高的關鍵詞進行視覺上的突出,形成“關鍵詞的渲染”,就像云一般的彩色圖片,從而過濾掉大量無效的文本信息,讓用戶從詞云圖中能快速感知突出的文字,迅速抓住重點,了解主旨。
數據分析
從繪制的手機正面評價詞云圖中可以看出,“漂亮”“性價比”“流暢”“滿意”“很快”“清晰”等詞出現的頻率較高,由此可知寫好評的客戶對該款手機的外觀和性能給予很高的評價。有些商家只關心中差評而忽視了好評,這種想法是不全面的,對于好評的分析能夠讓商家更深入地了解商品的使用場景及客戶對產品的關注點,這里從詞云圖中可以獲悉客戶在好評中主要關注的是手機的外觀、功能、性能、質量和價格。

從酒店負面評價詞云圖中可以看出“吵”“很差”“臟”“失望”“陳舊”“貴”“味道”等詞出現的頻率比較高,給出中差評的客戶對于酒店的設施、環境和價格表示不滿和失望。對于負面評價詞云圖的分析能夠讓賣家快速定位產品的不足之處,為進一步提升產品和服務質量指明方向。

結語
為提升電商平臺第三方商家收集商品評論信息的效率,獲取具有參考價值的選品指標和客戶需求,實現更好的收益,在此使用Python網絡爬蟲技術對店鋪商品評論數據進行采集和保存,對爬取的評論記錄進行數據清洗、中文分詞、去除停用詞、詞頻統計等預處理操作,并以此為基礎繪制詞云圖,實現數據可視化。根據正負面詞云圖對客戶評論做進一步分析,以獲取客戶的實際需求和商品需要優化的方向,幫助商家掌握核心賣。





)

:Maven 的使用)







)



