pix2pix-zero:零樣本圖像到圖像轉換
論文介紹 Zero-shot Image-to-Image Translation
關注微信公眾號: DeepGoAI
項目地址:https://github.com/pix2pixzero/pix2pix-zero
論文地址:https://arxiv.org/abs/2302.03027
本文介紹了一種名為pix2pix-zero的圖像到圖像的翻譯方法,它基于擴散模型,允許用戶即時指定編輯方向(例如,將貓轉換為狗),同時保持原始圖像的結構。該方法自動發現文本嵌入空間中反映所需編輯的編輯方向,并采用跨注意力引導以在編輯過程中保留輸入圖像的一般內容結構。重要的是,這種方法不需要針對每種編輯類型和圖像進行額外的訓練,可以直接使用預訓練的文本到圖像的擴散模型。通過廣泛的實驗,證明了pix2pix-zero在真實和合成圖像編輯方面超越了現有和同時期的工作。

上圖展示了論文方法能讓用戶指定轉換方向(例如,從貓變為狗)。該方法在處理真實圖像(上兩行)和合成圖像(下兩行)的翻譯任務時,都能保留輸入圖像的結構。這種技術不需要為每個輸入圖像或每個任務進行手動文本提示或昂貴的微調。圖中顯示了不同的翻譯示例,如從貓變成狗、從馬變成斑馬、從素描變為油畫質感、給狗加上眼鏡,以及將狗變成跳躍的狗。
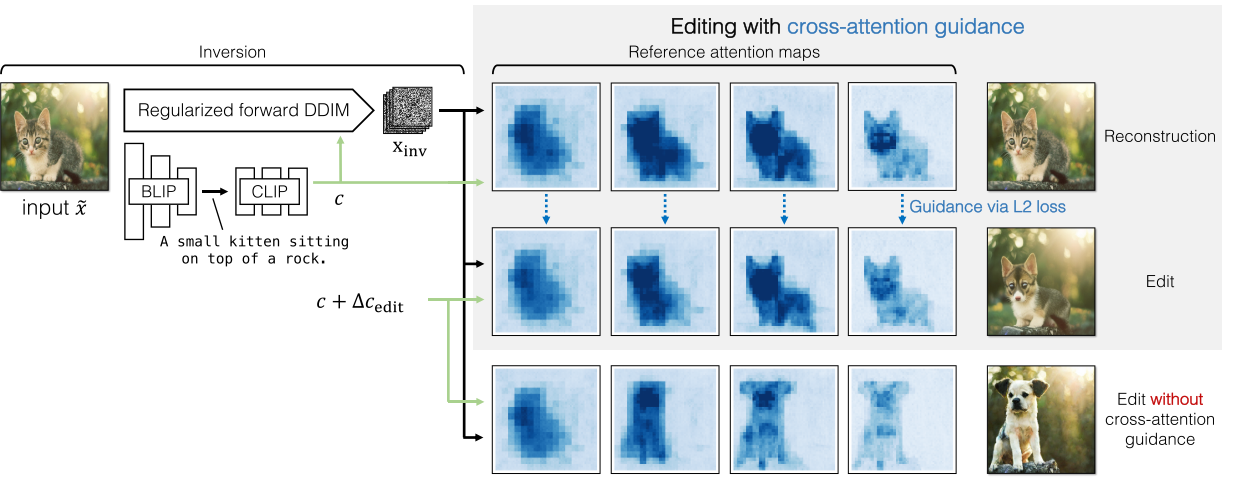
上圖展示了pix2pix-zero方法的概述,這是一個將圖片從貓變成狗的圖像到圖像的翻譯例子。首先,使用規范化的DDIM反轉來得到一個反轉的噪聲映射,這是由BLIP圖像字幕(caption)網絡和CLIP文本嵌入模型自動生成的文本嵌入引導的。然后,使用原始文本嵌入去噪以獲得交叉注意力圖,作為輸入圖像結構的參考(頂部行)。接下來,使用編輯后的文本嵌入去噪,通過損失函數確保這些交叉注意力圖與參考交叉注意力圖相匹配(第二行)。這確保了編輯圖像的結構與原始圖像相比不會發生劇烈變化。沒有交叉注意力引導的去噪示例顯示在第三行,導致結構上的大偏差。此可視化強調了在編輯過程中保持圖像原始結構的交叉注意力的重要性。
方法概述
文章提出了一種無需額外訓練即可編輯真實圖像的方法,核心技術包括:
-
規范化的DDIM反演和噪聲規范化 :文章采用確定性DDIM逆過程進行真實圖像反演,并在反演過程中使噪聲圖保持接近高斯分布,以提高可編輯性。
-
自動編輯方向發現 :為了能夠利用文本語義進行編輯,作者首先提出一種在文本嵌入空間自動找到編輯方向的方法,具體通過計算包含原始詞和編輯詞的句子組的CLIP嵌入方向。
-
交叉注意力引導 :為了保持編輯后內容的結構,方法采用了交叉注意力引導,這涉及到在擴散過程中保持輸入圖像的交叉注意力圖。
規范化的DDIM反演和噪聲規范化
確定性反演
反演的意思就是說,我們想要編輯一張圖像。如果想利用預訓練的生成模型對其進行編輯,那么就需要先把圖像嵌入到生成模型的隱空間。這個是目前比較流行的做法。
反演涉及到尋找噪聲映射 x inv x_{\text{inv}} xinv?(在生成模型中的編碼表示),該噪聲映射能夠在采樣時重建輸入的潛在代碼 x 0 x_0 x0?(輸入圖像或對應的編碼表示)。在DDPM中,這對應于固定的正向加噪聲過程,然后通過反向過程去噪。然而,DDPM的正向和反向過程都是隨機的,不會得到一致的重建。因此,作者采用如下所示的確定性DDIM反向過程:
x t + 1 = α  ̄ t + 1 f θ ( x t , t , c ) + 1 ? α  ̄ t + 1 ? θ ( x t , t , c ) x_{t+1} = \sqrt{\overline{\alpha}_{t+1}}f_{\theta}(x_t, t, c) + \sqrt{1 - \overline{\alpha}_{t+1}}\epsilon_{\theta}(x_t, t, c) \quad xt+1?=αt+1??fθ?(xt?,t,c)+1?αt+1???θ?(xt?,t,c)
其中, x t x_t xt? 是時間步 t t t 的噪聲潛在代碼, ? θ ( x t , t , c ) \epsilon_\theta(x_t, t, c) ?θ?(xt?,t,c) 是基于UNet的去噪器,它在給定時間步和編碼的文本特征 c c c 的條件下預測添加到 x t x_t xt? 中的噪聲, α  ̄ t + 1 \overline{\alpha}_{t+1} αt+1? 是DDIM中定義的噪聲縮放因子, f θ ( x t , t , c ) f_\theta(x_t, t, c) fθ?(xt?,t,c) 預測最終去噪的潛在代碼 x 0 x_0 x0?。
f θ ( x t , t , c ) = x t ? 1 ? α  ̄ t ? θ ( x t , t , c ) α  ̄ t f_{\theta}(x_t, t, c) = \frac{x_t - \sqrt{1 - \overline{\alpha}_t}\epsilon_{\theta}(x_t, t, c)}{\sqrt{\overline{\alpha}_t}} \quad fθ?(xt?,t,c)=αt??xt??1?αt???θ?(xt?,t,c)?
通過DDIM過程逐漸向初始潛在代碼 x 0 x_0 x0?添加噪聲,并在反轉結束時,最后的噪聲潛在代碼 x T x_T xT?被分配為 x i n v x_{inv} xinv?.
噪聲規范化
通過DDIM反演生成的反演噪聲圖通常不遵循不相關高斯白噪聲的統計屬性,導致可編輯性差。一個高斯白噪聲圖應該滿足:(1) 任意兩個隨機位置之間沒有相關性;(2) 每個空間位置的均值為零,方差為一,這在其自相關函數中反映為克羅內克函數。基于此,作者引導反演過程,使用由成對項 L pair L_{\text{pair}} Lpair? 和在單個像素位置的KL散度項 L KL L_{\text{KL}} LKL? 組成的自相關目標。
作者遵循文獻[29]的方法,構建一個金字塔,其中初始噪聲水平 η 0 ∈ R 64 × 64 × 4 \eta_0 \in \mathbb{R}^{64 \times 64 \times 4} η0?∈R64×64×4 是預測的噪聲圖,每個后續噪聲圖通過2x2的領域平均池化(并乘以2以保持期望的方差)。作者在特征大小8x8處停止,創建4個噪聲圖,形成集合 { η 0 , η 1 , η 2 , η 3 } \{\eta_0, \eta_1, \eta_2, \eta_3\} {η0?,η1?,η2?,η3?}。
在金字塔級別 p p p 的成對正則化是可能的 δ \delta δ 偏移處自相關系數平方和,歸一化過噪聲圖大小 S p S_p Sp?。
L pair = ∑ p 1 S p 2 ∑ δ = 1 S p ? 1 ∑ x , y , c η x , y , c p ( η x ? δ , y , c p + η x , y ? δ , c p ) , \mathcal{L}_{\text{pair}} = \sum_{p} \frac{1}{S_p^2} \sum_{\delta=1}^{S_p-1} \sum_{x,y,c} \eta^{p}_{x,y,c} \left( \eta^{p}_{x-\delta,y,c} + \eta^{p}_{x,y-\delta,c} \right), Lpair?=p∑?Sp2?1?δ=1∑Sp??1?x,y,c∑?ηx,y,cp?(ηx?δ,y,cp?+ηx,y?δ,cp?),
其中, η x y c p \eta_{xyc}^p ηxycp? 在使用圓形索引和通道的空間位置中索引。
為了使反轉噪聲圖更接近理想的高斯白噪聲,作者引入了一個自相關目標函數,它由兩部分組成:一個成對項 L pair L_{\text{pair}} Lpair? 和一個在單個像素位置上的KL散度項 L KL L_{\text{KL}} LKL?。這個自相關正則化的目的是確保在噪聲圖中的每一對隨機位置之間沒有相關性,并且每個空間位置的噪聲值都有零均值和單位方差。這種方法有助于在編輯過程中保持圖像質量,并確保編輯后的圖像更加自然和真實。總目標函數如下:
L auto = L pair + λ L KL L_{\text{auto}} = L_{\text{pair}} + \lambda L_{\text{KL}} Lauto?=Lpair?+λLKL?
在拿到確定性的噪聲映射 x inv x_{\text{inv}} xinv?之后,就可以考慮對其進行編輯了。接下來我們討論如何利用零樣本實現語義層面的編輯。
自動編輯方向發現

給定源文本和目標文本(例如貓和狗),作者使用 GPT-3 生成大量不同的句子。作者計算它們的 CLIP 嵌入并取均值差來獲得編輯方向 $\Delta_{edit} $。
具體來說,作者自動計算從源到目標的對應文本嵌入方向向量$\Delta_{edit} 。他們為源 。他們為源 。他們為源s 和目標 和目標 和目標t$生成了一大批多樣化的句子,這些句子要么使用現成的句子生成器(如GPT-3)生成,要么使用圍繞源和目標的預定義提示生成。然后,他們計算句子的CLIP嵌入的平均差異。通過向文本提示嵌入添加方向,可以生成編輯后的圖像。
該方法計算編輯方向只需要大約5秒鐘,并且只需預先計算一次。接下來,作者將編輯方向整合到圖像到圖像的翻譯方法中。這種方法的優點是使用多個句子確定文本方向比使用單個單詞更為穩健。
通過交叉注意力引導的編輯
近期的大規模擴散模型通過在去噪網絡中增加交叉注意力層來引入條件化。作者使用基于潛在擴散模型(LDM)構建的開源穩定擴散模型(Stable Diffusion)。該模型使用CLIP文本編碼器產生文本嵌入 c c c。為了根據文本條件生成圖像,模型計算編碼文本和去噪器中間特征之間的交叉注意力:
Attention ( Q , K , V ) = M ? V \text{Attention}(Q, K, V) = M \cdot V Attention(Q,K,V)=M?V
其中,
M = Softmax ( Q K T d ) M = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right) M=Softmax(d?QKT?)
查詢 Q = W Q ? ( x t ) Q = W^Q\phi(x_t) Q=WQ?(xt?),鍵 K = W K c K = W^Kc K=WKc,值 V = W V c V = W^Vc V=WVc是通過在去噪UNet的中間空間特征 ? ( x t ) \phi(x_t) ?(xt?)和文本嵌入 c c c上應用學習到的投影 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV計算得出, d d d是投影鍵和查詢的維度。
特別關注的是交叉注意力圖 M M M,它與圖像的結構有緊密的聯系。交叉注意力圖的每個條目 M i j M_{ij} Mij?代表第 j j j個文本標記對第 i i i個空間位置的貢獻。此外,交叉注意力圖是特定于時間步的,對于每個時間步 t t t我們會得到不同的注意力圖 M t M_t Mt?。
為了應用一個編輯,樸素的方式是將預先計算的編輯方向 Δ c e d i t \Delta c_{edit} Δcedit? 應用到 c c c 上,使用 c e d i t = c + Δ c e d i t c_{edit} = c + \Delta c_{edit} cedit?=c+Δcedit? 進行采樣過程以生成 x e d i t x_{edit} xedit?。這種方法能夠根據編輯成功地改變圖像,但無法保留輸入圖像的結構。如圖3所示,采樣過程中交叉注意力圖的偏差導致圖像結構的偏差。因此,作者提出了一種新的交叉注意力引導來鼓勵交叉注意力圖的一致性。
首先,重建圖像,不應用編輯方向,只使用輸入文本 c c c 來獲取每個時間步驟 t t t 的參考交叉注意力圖 M t r e f M_t^{ref} Mtref?。這些交叉注意力圖對應于我們希望保留的原始圖像的結構 e e e。接下來,作者應用編輯方向,使用 c e d i t c_{edit} cedit? 來生成交叉注意力圖 M t e d i t M_t^{edit} Mtedit?。然后作者采取梯度步驟與 x t x_t xt? 匹配參考 M t r e f M_t^{ref} Mtref?,減少下面的交叉注意力損失 L x a L_{xa} Lxa?:
L x a = ∣ ∣ M t e d i t ? M t r e f ∣ ∣ 2 2 L_{xa} = ||M_t^{edit} - M_t^{ref}||_2^2 \quad Lxa?=∣∣Mtedit??Mtref?∣∣22?
這個損失鼓勵 M t e d i t M_t^{edit} Mtedit? 不偏離 M t r e f M_t^{ref} Mtref?,在應用編輯的同時保留原始結構。
實驗結果
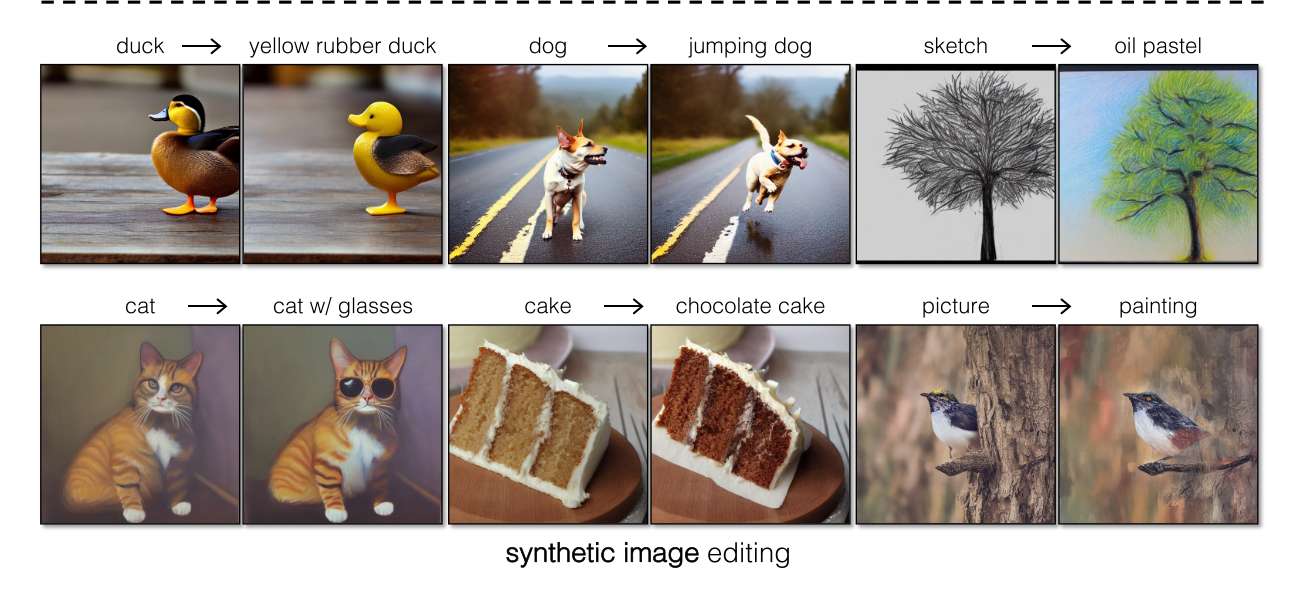
這里進一步展示了更多的編輯。可以看到編輯結果還是非常逼真且自然的。
 當然了這個算法也有缺陷。比如說非常復雜的圖,可能還是沒辦法實現高質量編輯。另一問題是他對原始的結構姿態保持的不是很完美。原因是算法是在低尺度的特征圖上進行編輯,所以對原來結構的保持并不完美。
當然了這個算法也有缺陷。比如說非常復雜的圖,可能還是沒辦法實現高質量編輯。另一問題是他對原始的結構姿態保持的不是很完美。原因是算法是在低尺度的特征圖上進行編輯,所以對原來結構的保持并不完美。
總結
本文介紹了一種基于擴散的圖像到圖像的翻譯方法,可以在不需要手動文本提示的情況下保持原始圖像的內容。它自動發現反映所需編輯的文本嵌入空間中的編輯方向,并通過交叉注意力引導來保持編輯后的內容結構。此方法無需為每次編輯額外訓練,可直接使用預訓練的文本到圖像擴散模型。實驗表明,該方法在真實和合成圖像編輯方面優于現有和同時期的工作。
其他更多細節請參閱論文原文






)





)
 技術應用實踐)


)


