目錄
圖像基本操作
閾值與平滑處理
圖像閾值
圖像平滑處理
圖像形態學操作
圖像梯度計算
Sobel 算子
Canny 邊緣檢測
圖像金字塔與輪廓檢測?
?圖像輪廓
接口定義
?輪廓繪制
輪廓特征與相似
模板匹配
?傅里葉變換
傅里葉變換的作用
濾波
圖像基本操作
- 讀取圖像: 使用cv2.imread()函數可以讀取圖像文件,并將其存儲為一個NumPy數組。
import cv2
image = cv2.imread('image.jpg')
#圖像的顯示,也可以創建多個窗口
cv2.imshow('image',img)
# 等待時間,毫秒級,0表示任意鍵終止
cv2.waitKey(0)
cv2.destroyAllWindows()- 讀取視頻:cv2.VideoCapture可以捕獲攝像頭,用數字來控制不同的設備,例如0,1。
# 讀取視頻
vc = cv2.VideoCapture('./img/test.mp4')
# 檢查是否打開正確
if vc.isOpened():oepn, frame = vc.read()
else:open = Falsewhile open:ret, frame = vc.read()if frame is None:breakif ret == True:# 彩色圖轉換為灰度圖gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)cv2.imshow('result', gray)if cv2.waitKey(100) & 0xFF == 27:break
vc.release()
cv2.destroyAllWindows()- 剪裁圖像:使用數組切片操作可以裁剪圖像的一部分
# 截取部分圖像數據
img=cv2.imread('./img/cat.jpg')
# [起始x坐標:寬度,起始y坐標:高度]
cat=img[0:200,0:200]
cv2.imshow('cat', cat)
cv2.waitKey(0)
cv2.destroyAllWindows()- 邊界填充:cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
top_size,bottom_size,left_size,right_size = (50,50,50,50)replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)
- 圖像融合:cv2.addWeighted(圖像1, 0.4(權重), 圖像2, 0.6(權重), 0(偏置項))
img_cat=cv2.imread('cat.jpg')
img_dog=cv2.imread('dog.jpg')# 圖像變換
img_dog = cv2.resize(img_dog, (500, 414))
img_dog.shape# 圖像融合
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)
plt.imshow(res)- 調整圖像:使用cv2.resize()函數可以調整圖像的大小
- 圖像保存:使用cv2.imwrite()函數可以將圖像保存到指定的文件路徑
# 讀取灰度圖
img1=cv2.imread('./img/cat.jpg',cv2.IMREAD_GRAYSCALE)
print(img1)
print(img1.shape) # h,w# 圖像保存
cv2.imwrite('./img/mycat1.png',img1)- 顯示圖像: 使用cv2.imshow()函數可以在窗口中顯示圖像
閾值與平滑處理
圖像閾值
圖像閾值是一種圖像處理術,用于將圖像中的像素值分為兩個或多個不同的類別。閾值可以用來分割圖像、提取感興趣的目標或者進行圖像增強等操作。
在圖像閾值處理中,首先需要選擇一個閾值,然后將圖像中的像素值與該閾值進行比較。如果像素值大于閾值,則將其歸為一類;如果像素值小于等于閾值,則將其歸為另一類。這樣就可以將圖像中的像素分為不同的區域或者進行二值化處理。
常見的圖像閾值處理方法包括全局閾值法、自適應閾值法和多閾值法等。全局閾值法是指在整個圖像上使用一個固定的閾值進行處理;自適應閾值法是指根據圖像局部的特性來選擇不同的閾值;多閾值法是指使用多個閾值將圖像分成多個不同的類別。
圖像閾值處理可以應用于很多領域,如圖像分割、目標檢測、字符識別等。通過調整閾值的選擇和處理方法,可以實現對圖像的不同特征進行提取和分析。

圖像平滑處理
圖像平滑處理是一種常用的圖像處理技術用于減少圖像中的噪聲和細節,使圖像變得更加平滑和模糊。以下是幾種常見的圖像平滑處理方法:
1. 均值濾波:將圖像中每個像素的值替換為其周圍像素的平均值。這種方法可以有效地去除高頻噪聲,但可能會導致圖像細節的模糊。
2. 高斯濾波:使用高斯函數對圖像進行卷積操作,以減少噪聲。高斯濾波器在中心像素周圍的像素上施加較大的權重,而在邊緣像素周圍施加較小的權重。這種方法可以平滑圖像并保留邊緣信息。
3. 中值濾波:將圖像中每個像素的值替換為其周圍像素值的中值。中值濾波器對于去除椒鹽噪聲等椒鹽噪聲非常有效,但可能會導致圖像細節的丟失。
4. 雙邊濾波:結合了空間域和灰度值域的信息,對圖像進行平滑處理。雙邊濾波器考慮了像素之間的空間距離和像素值之間的差異,以保留邊緣信息的同時減少噪聲。
5. 維納濾波:基于信號和噪聲的統計特性,通過最小均方誤差準則對圖像進行濾波。維納濾波器可以根據圖像的噪聲特性進行自適應調整,以實現更好的平滑效果。
img = cv2.imread('lenaNoise.png')cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()# 均值濾波
# 簡單的平均卷積操作
blur = cv2.blur(img, (3, 3))cv2.imshow('blur', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()# 方框濾波
# 基本和均值一樣,可以選擇歸一化
box = cv2.boxFilter(img,-1,(3,3), normalize=True) cv2.imshow('box', box)
cv2.waitKey(0)
cv2.destroyAllWindows()# 方框濾波
# 基本和均值一樣,可以選擇歸一化,容易越界
box = cv2.boxFilter(img,-1,(3,3), normalize=False) cv2.imshow('box', box)
cv2.waitKey(0)
cv2.destroyAllWindows()# 高斯濾波
# 高斯模糊的卷積核里的數值是滿足高斯分布,相當于更重視中間的
aussian = cv2.GaussianBlur(img, (5, 5), 1) cv2.imshow('aussian', aussian)
cv2.waitKey(0)
cv2.destroyAllWindows()# 中值濾波
# 相當于用中值代替
median = cv2.medianBlur(img, 5) # 中值濾波cv2.imshow('median', median)
cv2.waitKey(0)
cv2.destroyAllWindows()# 展示所有的
res = np.hstack((blur,aussian,median))
#print (res)
cv2.imshow('median vs average', res)
cv2.waitKey(0)
cv2.destroyAllWindows()圖像形態學操作
圖像形態學是一種基于數學理論的圖像處理方法,主要用于圖像的形狀分析和特征提取。它通過結構元素與圖像進行卷積運算,從而改變圖像的形狀和結構。
常見的圖像形態學操作包括腐蝕、膨脹、開運算、閉運算、擊中擊不中變換等。
1. 腐蝕(Erosion):腐蝕操作可以使圖像中的物體邊界向內部收縮。它通過將結構元素與圖像進行逐像素的比較,只有當結構元素完全包含在圖像中時,該像素才保留,否則被置為背景值。
pie = cv2.imread('pie.png')cv2.imshow('pie', pie)
cv2.waitKey(0)
cv2.destroyAllWindows()kernel = np.ones((30,30),np.uint8)
erosion_1 = cv2.erode(pie,kernel,iterations = 1)
erosion_2 = cv2.erode(pie,kernel,iterations = 2)
erosion_3 = cv2.erode(pie,kernel,iterations = 3)
res = np.hstack((erosion_1,erosion_2,erosion_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
2. 膨脹(Dilation):膨脹操作可以使圖像中的物體邊界向外部擴張。它也是通過將結構元素與圖像進行逐像素的比較,只要結構元素與圖像中的任意一個像素相交,該像素就被保留。
pie = cv2.imread('pie.png')kernel = np.ones((30,30),np.uint8)
dilate_1 = cv2.dilate(pie,kernel,iterations = 1)
dilate_2 = cv2.dilate(pie,kernel,iterations = 2)
dilate_3 = cv2.dilate(pie,kernel,iterations = 3)
res = np.hstack((dilate_1,dilate_2,dilate_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
3. 開運算(Opening):開運算是先進行腐蝕操作,再進行膨脹操作。它可以消除小的噪點,并保持物體的整體形狀。
# 開:先腐蝕,再膨脹
img = cv2.imread('dige.png')kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)cv2.imshow('opening', opening)
cv2.waitKey(0)
cv2.destroyAllWindows()4. 閉運算(Closing):閉運算是先進行膨脹操作,再進行腐蝕操作。它可以填充物體內部的小孔,并保持物體的整體形狀。
# 閉:先膨脹,再腐蝕
img = cv2.imread('dige.png')kernel = np.ones((5,5),np.uint8)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)cv2.imshow('closing', closing)
cv2.waitKey(0)
cv2.destroyAllWindows()5. 擊中擊不中變換(Hit-or-Miss Transform):擊中擊不中變換是一種用于檢測特定形狀的圖像操作。它通過定義兩個結構元素,分別表示要擊中的形狀和要排除的形狀,從而實現對特定形狀的檢測。
6. 梯度計算:梯度計算基于形態學操作,通過對圖像進行膨脹和腐蝕操作,然后計算兩幅圖像之間的差異來獲取邊緣信息。
具體而言,圖像形態學梯度計算的步驟如下:
- 首先,選擇一個結構元素(也稱為核或模板),它定義了形態學操作的形狀和大小。
- 對原始圖像進行膨脹操作,膨脹操作將結構元素與圖像進行卷積,得到一個膨脹后的圖像。
- 對原始圖像進行腐蝕操作,腐蝕操作同樣將結構元素與圖像進行卷積,得到一個腐蝕后的圖像。
- 將膨脹后的圖像減去腐蝕后的圖像,得到梯度圖像。
梯度圖像中的亮點表示邊緣或輪廓的位置,亮點的強度表示邊緣或輪廓的強度。通過調整結構元素的形狀和大小,可以控制梯度計算的敏感度和精度。
# 梯度=膨脹-腐蝕
pie = cv2.imread('pie.png')
kernel = np.ones((7,7),np.uint8)
dilate = cv2.dilate(pie,kernel,iterations = 5)
erosion = cv2.erode(pie,kernel,iterations = 5)res = np.hstack((dilate,erosion))cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)cv2.imshow('gradient', gradient)
cv2.waitKey(0)
cv2.destroyAllWindows()7. 禮帽與黑帽:
圖像形態學中的禮帽(top hat)和黑帽(black hat)是兩種常用的形態學操作,用于圖像的亮區域和暗區域的提取。
禮帽操作是通過對原始圖像進行開運算(opening)后再與原始圖像相減得到的結果。開運算是先進行腐蝕操作,再進行膨脹操作,用于平滑圖像并保留較大的亮區域。因此,禮帽操作可以提取出原始圖像中較小的、明亮的細節部分。
黑帽操作則是通過對原始圖像進行閉運算(closing)后再與原始圖像相減得到的結果。閉運算是先進行膨脹操作,再進行腐蝕操作,用于平滑圖像并保留較大的暗區域。因此,黑帽操作可以提取出原始圖像中較小的、暗的細節部分。
這兩種形態學操作可以用于圖像增強、噪聲去除、邊緣檢測等應用。禮帽操作可以突出圖像中的細節部分,而黑帽操作可以突出圖像中的暗部分。
#禮帽 = 原始輸入-開運算結果
#黑帽 = 閉運算-原始輸入#禮帽
img = cv2.imread('dige.png')
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('tophat', tophat)
cv2.waitKey(0)
cv2.destroyAllWindows()#黑帽
img = cv2.imread('dige.png')
blackhat = cv2.morphologyEx(img,cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('blackhat ', blackhat )
cv2.waitKey(0)
cv2.destroyAllWindows()這些圖像形態學操作在圖像處理中有廣泛的應用,例如邊緣檢測、形狀分析、圖像重建等。
圖像梯度計算
Sobel 算子
Sobel算子是一種常用的圖像梯度算子,用于檢測圖像中的邊緣。它是一種離散型的差分算子,通過計算圖像中每個像素點的梯度來確定邊緣的位置和方向。
Sobel算子分為水平和垂直兩個方向的算子,分別用于計算圖像在水平和垂直方向上的梯度。水平方向的Sobel算子通常表示為:
```
-1 ?0 ?1
-2 ?0 ?2
-1 ?0 ?1
```
垂直方向的Sobel算子通常表示為:
```
-1 -2 -1
?0 ?0 ?0
?1 ?2 ?1
```
對于圖像中的每個像素點,分別將其與周圍像素點進行加權求和,得到水平和垂直方向上的梯度值。通過計算這兩個方向上的梯度值,可以得到每個像素點的梯度幅值和梯度方向,從而實現邊緣檢測。
使用Sobel算子進行邊緣檢測時,通常需要先將圖像轉換為灰度圖像,然后對灰度圖像應用Sobel算子。最后,可以根據梯度幅值進行閾值處理,將邊緣提取出來。

dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
- ddepth:圖像的深度
- dx和dy分別表示水平和豎直方向
- ksize是Sobel算子的大小
def cv_show(img,name):cv2.imshow(name,img)cv2.waitKey()cv2.destroyAllWindows()img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
cv_show(img,'img')# 計算dx
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
# 將負值轉換為正值
sobelx = cv2.convertScaleAbs(sobelx)
# 計算dy
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobely = cv2.convertScaleAbs(sobely)
分別計算x和y,再求和
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelxy')"""
不建議直接計算
sobelxy=cv2.Sobel(img,cv2.CV_64F,1,1,ksize=3)
sobelxy = cv2.convertScaleAbs(sobelxy)
cv_show(sobelxy,'sobelxy')
"""
#不同算子的差異
img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
sobely = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0) scharrx = cv2.Scharr(img,cv2.CV_64F,1,0)
scharry = cv2.Scharr(img,cv2.CV_64F,0,1)
scharrx = cv2.convertScaleAbs(scharrx)
scharry = cv2.convertScaleAbs(scharry)
scharrxy = cv2.addWeighted(scharrx,0.5,scharry,0.5,0) laplacian = cv2.Laplacian(img,cv2.CV_64F)
laplacian = cv2.convertScaleAbs(laplacian) res = np.hstack((sobelxy,scharrxy,laplacian))
cv_show(res,'res')
Canny 邊緣檢測
?Canny邊緣檢測是一種經典的圖像處理算法,用于檢測圖像中的邊緣。它由John F. Canny在1986年提出,并被廣泛應用于計算機視覺和圖像處理領域。
Canny邊緣檢測算法的主要步驟包括:
1.噪聲抑制:使用高斯濾波器對圖像進行平滑處理,以減少噪聲的影響。

2.計算梯度:使用Sobel算子計算圖像中每個像素點的梯度幅值和方向。梯度幅值表示像素點的灰度變化程度,而梯度方向表示變化最快的方向。

3.非極大值抑制:在梯度方向上進行非極大值抑制,即對每個像素點,只保留沿著梯度方向上幅值最大的像素點,以細化邊緣。


4.雙閾值檢測:根據設定的高閾值和低閾值,對非極大值抑制后的圖像進行閾值分割。高于高閾值的像素點被認為是強邊緣,低于低閾值的像素點被認為是弱邊緣,介于兩者之間的像素點根據其與強邊緣的連通性進行判斷。

5.邊緣連接:通過連接強邊緣像素點和與之相連的弱邊緣像素點,形成完整的邊緣。
Canny邊緣檢測算法具有以下優點:
- 對噪聲具有較好的抑制能力。
- 檢測到的邊緣具有良好的連續性。
- 可以通過調整閾值來控制檢測到的邊緣數量。
img=cv2.imread("lena.jpg",cv2.IMREAD_GRAYSCALE)# minvel maxval
v1=cv2.Canny(img,80,150)
v2=cv2.Canny(img,50,100)res = np.hstack((v1,v2))
cv_show(res,'res')
img=cv2.imread("car.png",cv2.IMREAD_GRAYSCALE)v1=cv2.Canny(img,120,250)
v2=cv2.Canny(img,50,100)res = np.hstack((v1,v2))
cv_show(res,'res')
圖像金字塔與輪廓檢測?
圖像金字塔是一種用于圖像處理和計算機視覺的技術,它可以通過對原始圖像進行多次縮放和降采樣來構建一系列不同分辨率的圖像。每個分辨率的圖像被稱為金字塔的一層,而金字塔的結構類似于由大到小的金字塔形狀。
圖像金字塔有兩種類型:高斯金字塔和拉普拉斯金字塔。高斯金字塔通過對原始圖像進行重復的平滑和下采樣操作來生成不同分辨率的圖像。而拉普拉斯金字塔則是通過從高斯金字塔中恢復原始圖像并與下一層高斯圖像相減得到的。
輪廓檢測是一種用于檢測圖像中物體邊界的技術。它可以通過分析圖像中的亮度、顏色或紋理等特征來提取出物體的輪廓信息。常用的輪廓檢測算法包括Canny邊緣檢測、Sobel算子、Laplacian算子等。


?圖像輪廓
圖像輪廓是指圖像中物體的邊界線或者輪廓線。它是由物體與背景之間的灰度或顏色差異形成的。圖像輪廓可以用于物體檢測、形狀分析、目標跟蹤等計算機視覺任務中。
在圖像處理中,常用的方法來提取圖像輪廓包括邊緣檢測和閾值分割。邊緣檢測算法可以通過檢測圖像中灰度或顏色的變化來找到物體的邊界。常見的邊緣檢測算法有Sobel算子、Canny算子等。閾值分割則是將圖像根據灰度或顏色的閾值進行分割,得到物體的二值圖像,然后通過連通區域分析等方法找到物體的輪廓。
圖像輪廓可以表示為一系列的點或者線段,也可以通過多邊形或曲線來近似表示。常見的表示方法有邊界框、最小外接矩形、最小外接圓等。
圖像輪廓在計算機視覺和圖像處理領域有廣泛的應用。例如,可以通過輪廓提取來進行物體識別和分類,可以通過輪廓匹配來進行目標跟蹤和姿態估計,還可以通過輪廓分析來進行形狀分析和測量等。
接口定義
cv2.findContours(img,mode,method)
mode:輪廓檢索模式
- RETR_EXTERNAL :只檢索最外面的輪廓;
- RETR_LIST:檢索所有的輪廓,并將其保存到一條鏈表當中;
- RETR_CCOMP:檢索所有的輪廓,并將他們組織為兩層:頂層是各部分的外部邊界,第二層是空洞的邊界;
- RETR_TREE:檢索所有的輪廓,并重構嵌套輪廓的整個層次;
method:輪廓逼近方法
- CHAIN_APPROX_NONE:以Freeman鏈碼的方式輸出輪廓,所有其他方法輸出多邊形(頂點的序列)。
- CHAIN_APPROX_SIMPLE:壓縮水平的、垂直的和斜的部分,也就是,函數只保留他們的終點部分。

import cv2
def cv_show(name,img):cv2.imshow(name,img)cv2.waitKey(0)cv2.destroyAllWindows()
# 輸入圖像
img = cv2.imread('image.jpg')
# 將圖像變為灰度圖
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 為了更高的準確率,使用二值圖像
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)# # 顯示圖像
# cv_show('thresh',thresh)
# # 圖像輪廓
# # binary二值類結果 contours輪廓點 hierarchy層級信息
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# print(contours.shape)
# #傳入繪制圖像,輪廓,輪廓索引,顏色模式,線條厚度
# # 注意需要copy,要不原圖會變。。。
draw_img = img.copy()
# # 繪制輪廓圖 圖像 輪廓點 全部點 G B R 線條寬度
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
cv_show('res',res)輪廓特征與相似
# 輪廓特征
# 獲取輪廓點
cnt = contours[0]
#面積
cv2.contourArea(cnt)
#周長,True表示閉合的
cv2.arcLength(cnt,True)# 輪廓近似img = cv2.imread('contours2.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]draw_img = img.copy()
res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
cv_show(res,'res')epsilon = 0.15*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True)draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')# 邊界矩陣
img = cv2.imread('contours.png')gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show(img,'img')area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('輪廓面積與邊界矩形比',extent)# 外接圓(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show(img,'img')模板匹配
模板匹配是一種在圖像處理和計算機視覺中常用的技術,用于在一幅圖像中尋找與給定模板最相似的部分。它可以用于目標檢測、物體識別、圖像對齊等應用。
模板匹配的基本思想是將一個固定大小的模板圖像與待匹配圖像進行比較,通過計算它們之間的相似度來確定最佳匹配位置。常用的相似度度量方法包括平方差匹配、相關性匹配和歸一化互相關匹配。
在平方差匹配中,模板圖像與待匹配圖像的對應像素值之間的差異被計算,并求和得到一個匹配度量值。最小匹配度量值對應的位置即為最佳匹配位置。
在相關性匹配中,模板圖像與待匹配圖像的對應像素值之間的相關性被計算,并求和得到一個匹配度量值。最大匹配度量值對應的位置即為最佳匹配位置。
在歸一化互相關匹配中,模板圖像與待匹配圖像的對應像素值之間的歸一化互相關性被計算,并求和得到一個匹配度量值。最大匹配度量值對應的位置即為最佳匹配位置。
模板匹配的實現可以使用各種圖像處理庫或者計算機視覺庫,如OpenCV。在實際應用中,還可以通過使用多尺度模板匹配、旋轉不變模板匹配等技術來提高匹配的準確性和魯棒性。

# 模板匹配
img = cv2.imread('lena.jpg', 0)
template = cv2.imread('face.jpg', 0)
h, w = template.shape[:2] img.shape
template.shapemethods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR','cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
res.shape#最小差異 最大差異 最小距離坐標 最大距離坐標
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)for meth in methods:img2 = img.copy()# 匹配方法的真值method = eval(meth)print (method)res = cv2.matchTemplate(img, template, method)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)# 如果是平方差匹配TM_SQDIFF或歸一化平方差匹配TM_SQDIFF_NORMED,取最小值if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:top_left = min_locelse:top_left = max_locbottom_right = (top_left[0] + w, top_left[1] + h)# 畫矩形cv2.rectangle(img2, top_left, bottom_right, 255, 2)plt.subplot(121), plt.imshow(res, cmap='gray')plt.xticks([]), plt.yticks([]) # 隱藏坐標軸plt.subplot(122), plt.imshow(img2, cmap='gray')plt.xticks([]), plt.yticks([])plt.suptitle(meth)plt.show()
?傅里葉變換
傅里葉變換是一種數學變換,它將一個函數從時域(時間域)轉換到頻域(頻率域)。通過傅里葉變換,我們可以將一個信號分解成一系列不同頻率的正弦和余弦函數的疊加。這種變換在信號處理、圖像處理、通信等領域中廣泛應用。
傅里葉變換的數學表達式為:
F(ω) = ∫[?∞,+∞] f(t) * e^(-jωt) dt
其中,F(ω)表示頻域中的復數函數,f(t)表示時域中的函數,e^(-jωt)是一個復指數函數,ω是角頻率。
傅里葉變換有兩種形式:連續傅里葉變換(CTFT)和離散傅里葉變換(DFT)。連續傅里葉變換適用于連續信號,而離散傅里葉變換適用于離散信號。
在實際應用中,傅里葉變換可以用來分析信號的頻譜特性,提取信號中的頻率信息,濾波、壓縮、編碼等。同時,傅里葉變換也有逆變換,可以將頻域信號轉換回時域信號。

傅里葉變換的作用
-
高頻:變化劇烈的灰度分量,例如邊界
-
低頻:變化緩慢的灰度分量,例如一片大海
濾波
-
低通濾波器:只保留低頻,會使得圖像模糊
-
高通濾波器:只保留高頻,會使得圖像細節增強
- opencv中主要就是cv2.dft()和cv2.idft(),輸入圖像需要先轉換成np.float32 格式。
- 得到的結果中頻率為0的部分會在左上角,通常要轉換到中心位置,可以通過shift變換來實現。
- cv2.dft()返回的結果是雙通道的(實部,虛部),通常還需要轉換成圖像格式才能展示(0,255)
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 灰度圖轉換
img = cv2.imread('lena.jpg',0)
# 輸入圖像需要先轉換成np.float32 格式
img_float32 = np.float32(img)
# 先dft
dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
# 轉換到中心位置
dft_shift = np.fft.fftshift(dft)rows, cols = img.shape
crow, ccol = int(rows/2) , int(cols/2) # 中心位置# 低通濾波
mask = np.zeros((rows, cols, 2), np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 1# IDFT
fshift = dft_shift*mask
# 從中心位置還原
f_ishift = np.fft.ifftshift(fshift)
# 后idft
img_back = cv2.idft(f_ishift)
# 得到灰度圖能表示的形式
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Result'), plt.xticks([]), plt.yticks([])plt.show() 
img = cv2.imread('lena.jpg',0)img_float32 = np.float32(img)dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)rows, cols = img.shape
crow, ccol = int(rows/2) , int(cols/2) # 中心位置# 高通濾波
mask = np.ones((rows, cols, 2), np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 0# IDFT
fshift = dft_shift*mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Result'), plt.xticks([]), plt.yticks([])plt.show() 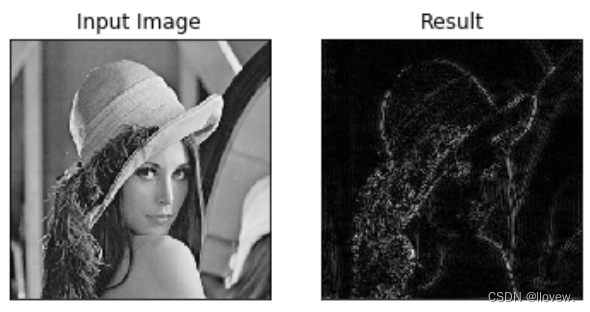

:Maven 的使用)







)









