1 理解解碼器
假設我們想把英語句子I am good(原句)翻譯成法語句子Je vais bien(目標句)。首先,將原句I am good送入編碼器,使編碼器學習原句,并計算特征值。在前文中,我們學習了編碼器是如何計算原句的特征值的。然后,我們把從編碼器求得的特征值送入解碼器。解碼器將特征值作為輸入,并生成目標句Je vais bien,如下圖所示。
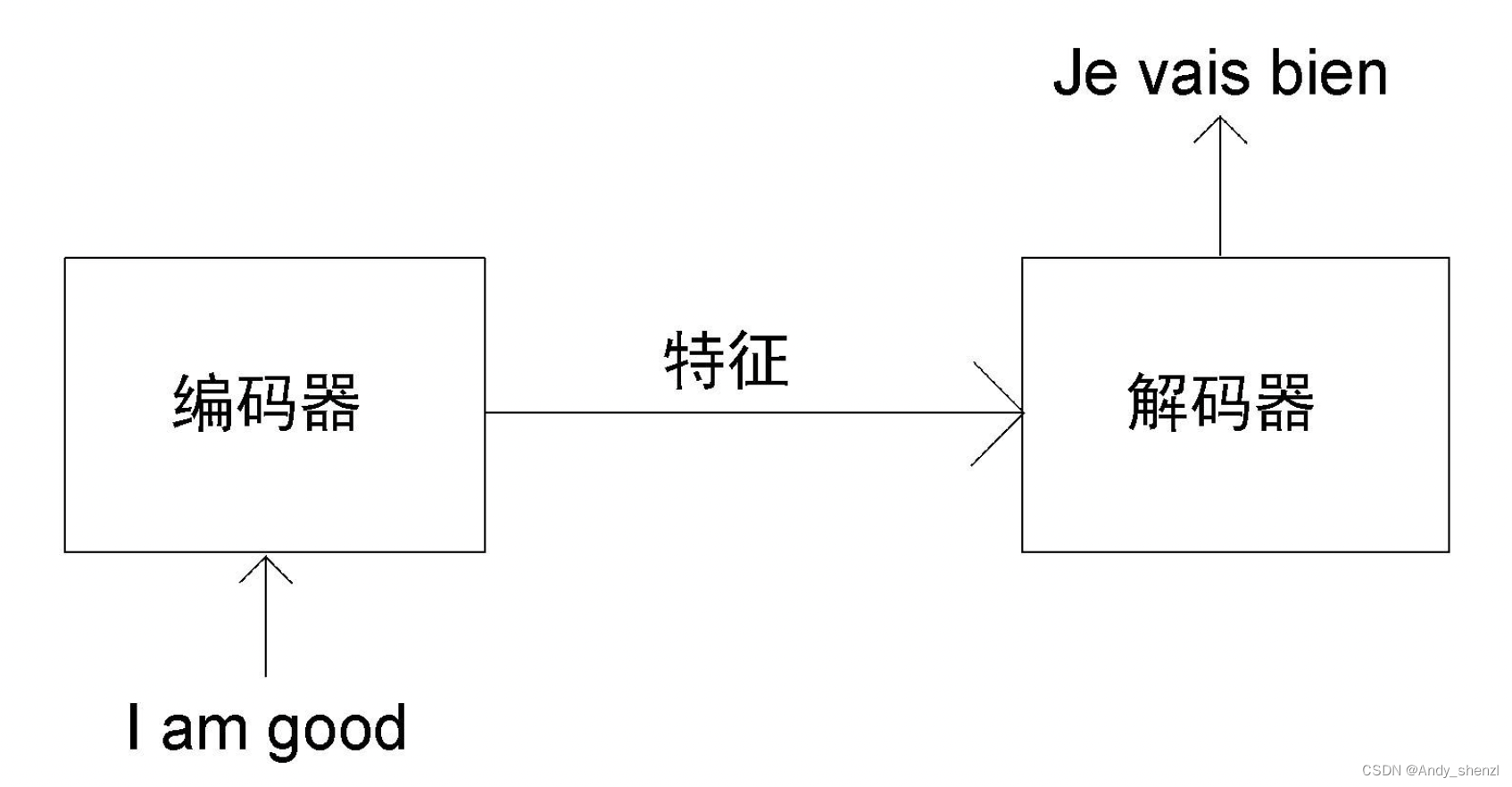
在編碼器部分,我們了解到可以疊加N個編碼器。同理,解碼器也可以有N個疊加在一起。為簡化說明,我們設定N=2。如圖所示,一個解碼器的輸出會被作為輸入傳入下一個解碼器。我們還可以看到,編碼器將原句的特征值(編碼器的輸出)作為輸入傳給所有解碼器,而非只給第一個解碼器。因此,一個解碼器(第一個除外)將有兩個輸入:一個是來自前一個解碼器的輸出,另一個是編碼器輸出的特征值。

2 工作步驟
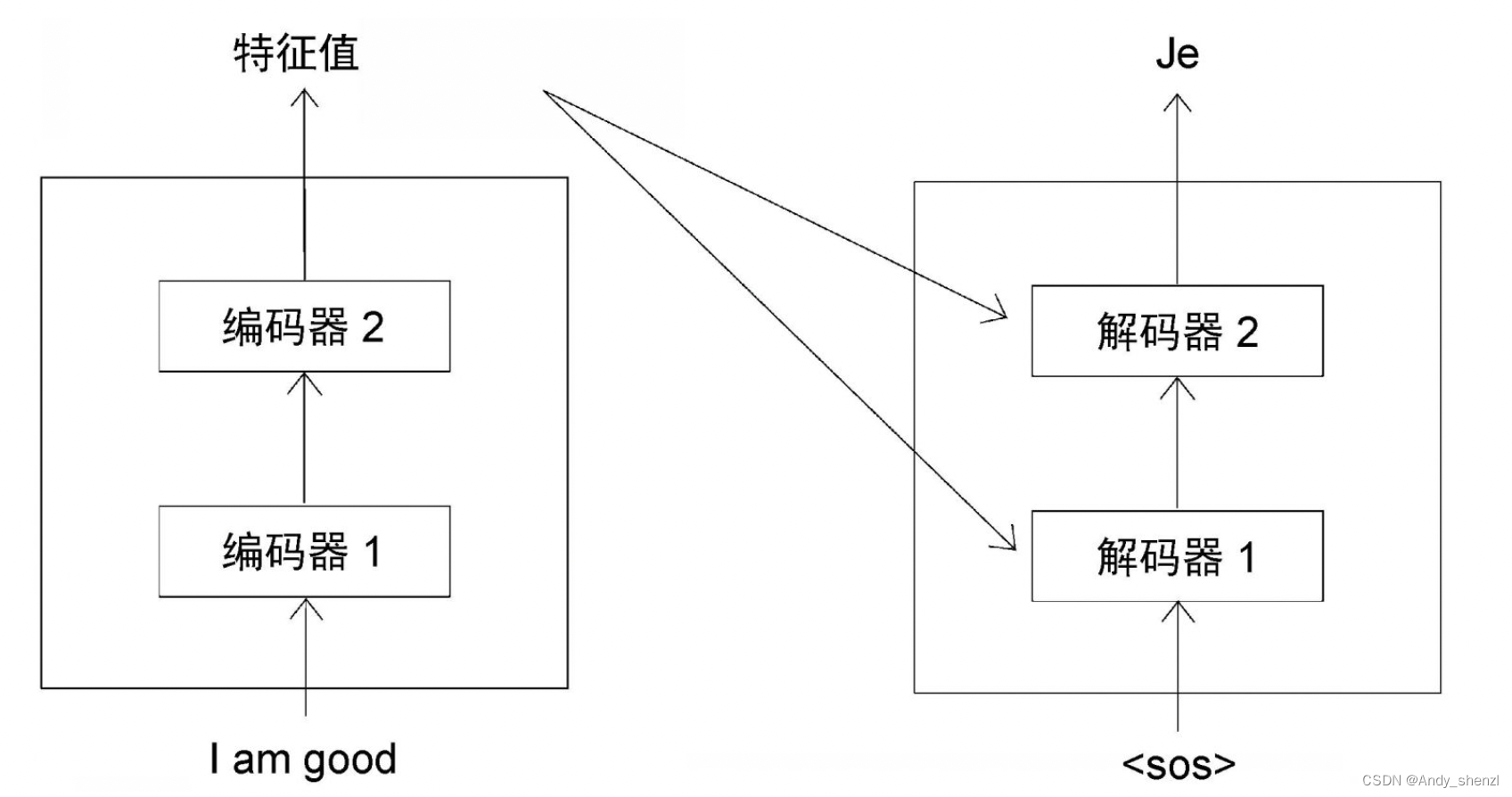
接下來,我們學習解碼器究竟是如何生成目標句的。當 t = 1 t=1 t=1時(t表示時間步),解碼器的輸入是<sos>,這表示句子的開始。解碼器收到<sos>作為輸入,生成目標句中的第一個詞,即Je,如圖所示。
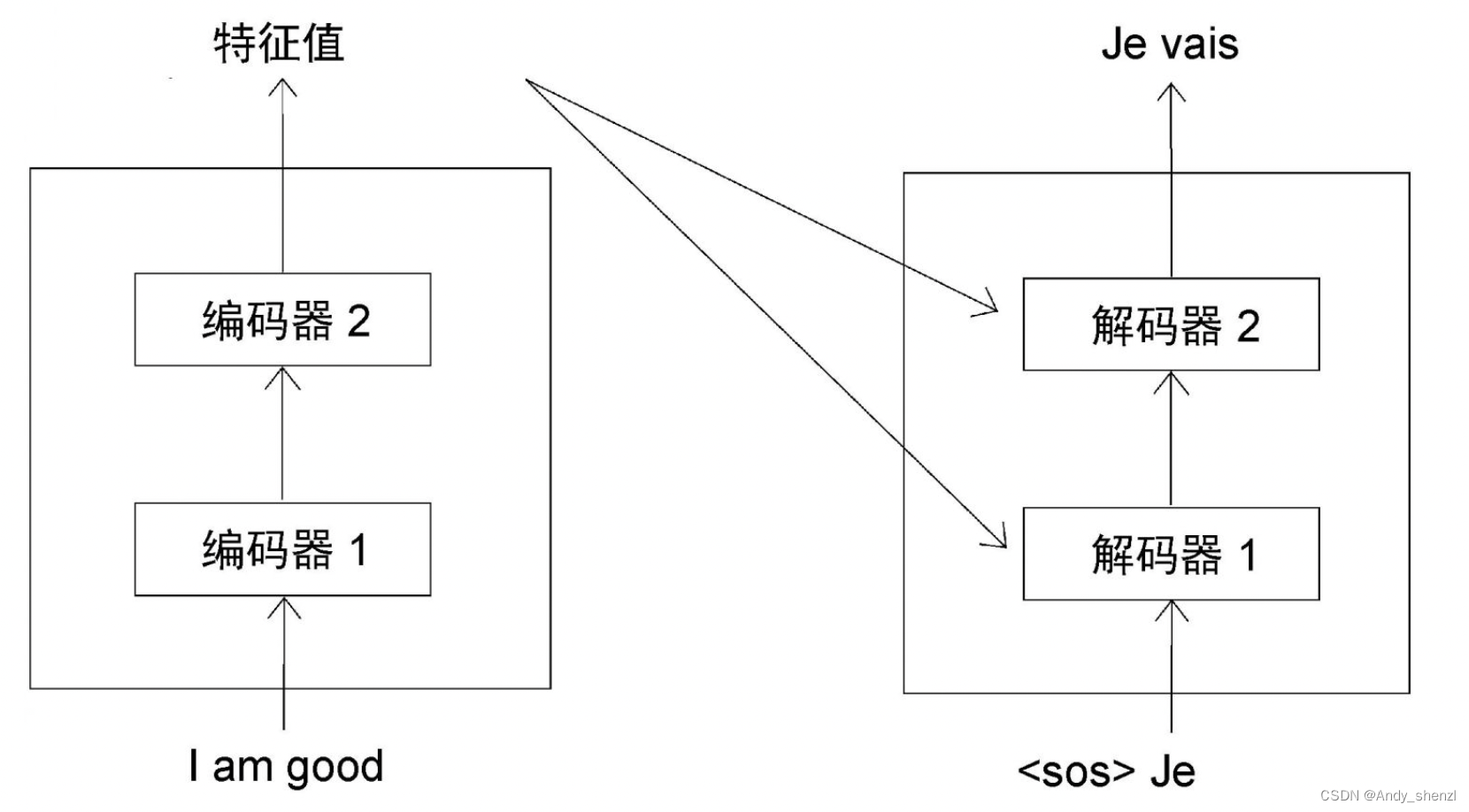
當 t = 2 t=2 t=2時,解碼器使用當前的輸入和在上一步( t = 1 t=1 t=1)生成的單詞,預測句子中的下一個單詞。在本例中,解碼器將<sos>和Je(來自上一步)作為輸入,并試圖生成目標句中的下一個單詞,如圖所示。
同理,可以推斷出解碼器在 t = 3 t=3 t=3時的預測結果。此時,解碼器將<sos>、Je和vais(來自上一步)作為輸入,并試圖生成句子中的下一個單詞,如圖所示

在每一步中,解碼器都將上一步新生成的單詞與輸入的詞結合起來,并預測下一個單詞。因此,在最后一步( t = 4 t=4 t=4),解碼器將<sos>、Je、vais和bien作為輸入,并試圖生成句子中的下一個單詞,如圖所示。
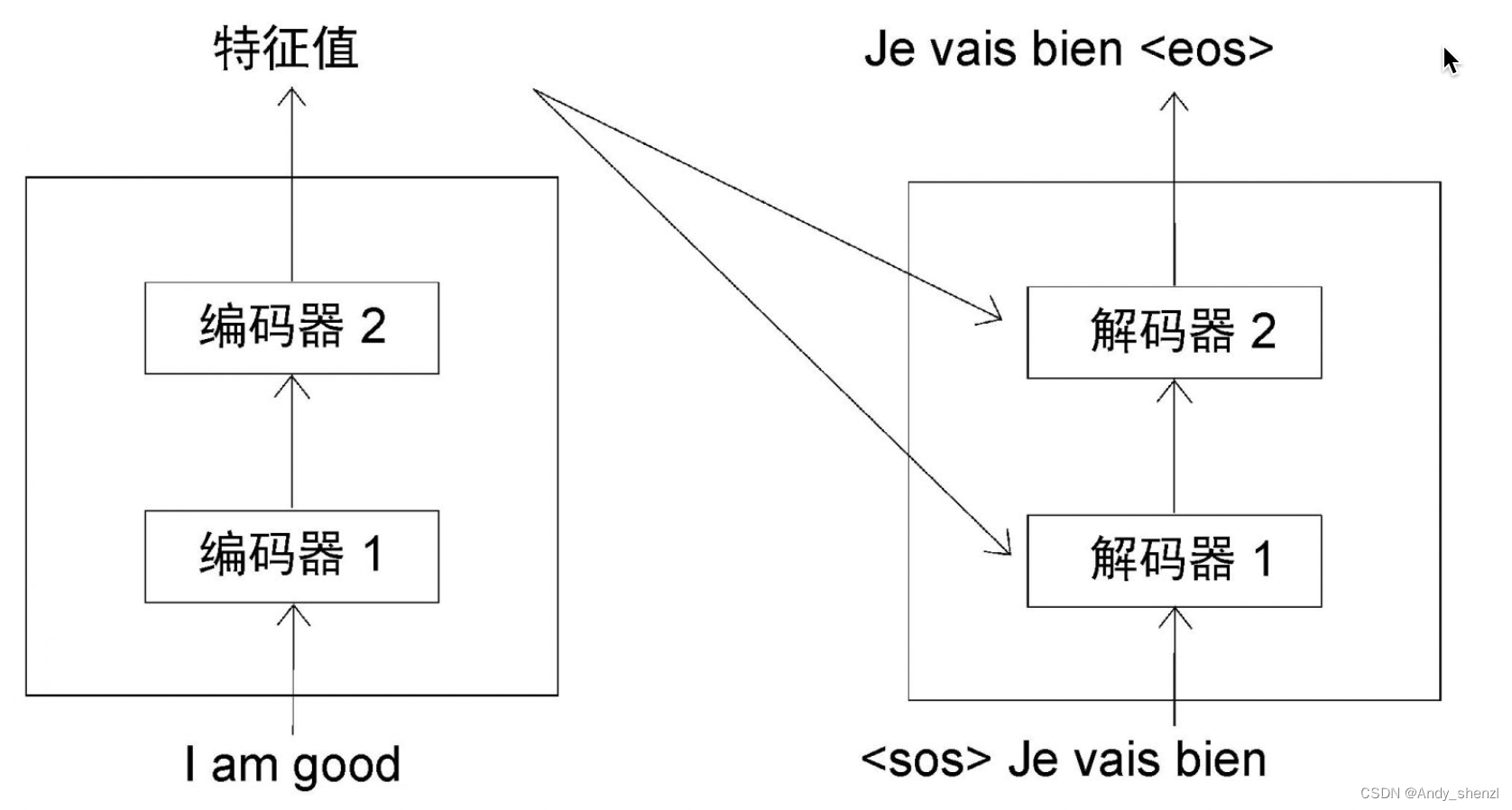
從上圖中可以看到,一旦生成表示句子結束的<eos>標記,就意味著解碼器已經完成了對目標句的生成工作。
3 位置編碼
在編碼器部分,我們將輸入轉換為嵌入矩陣,并將位置編碼添加到其中,然后將其作為輸入送入編碼器。同理,我們也不是將輸入直接送入解碼器,而是將其轉換為嵌入矩陣,為其添加位置編碼,然后再送入解碼器。
如下圖所示,假設在時間步 t = 2 t=2 t=2,我們將輸入轉換為嵌入(我們稱之為嵌入值輸出,因為這里計算的是解碼器在以前的步驟中生成的詞的嵌入),將位置編碼加入其中,然后將其送入解碼器。

接下來,讓我們深入了解解碼器的工作原理。一個解碼器模塊及其所有的組件如圖:
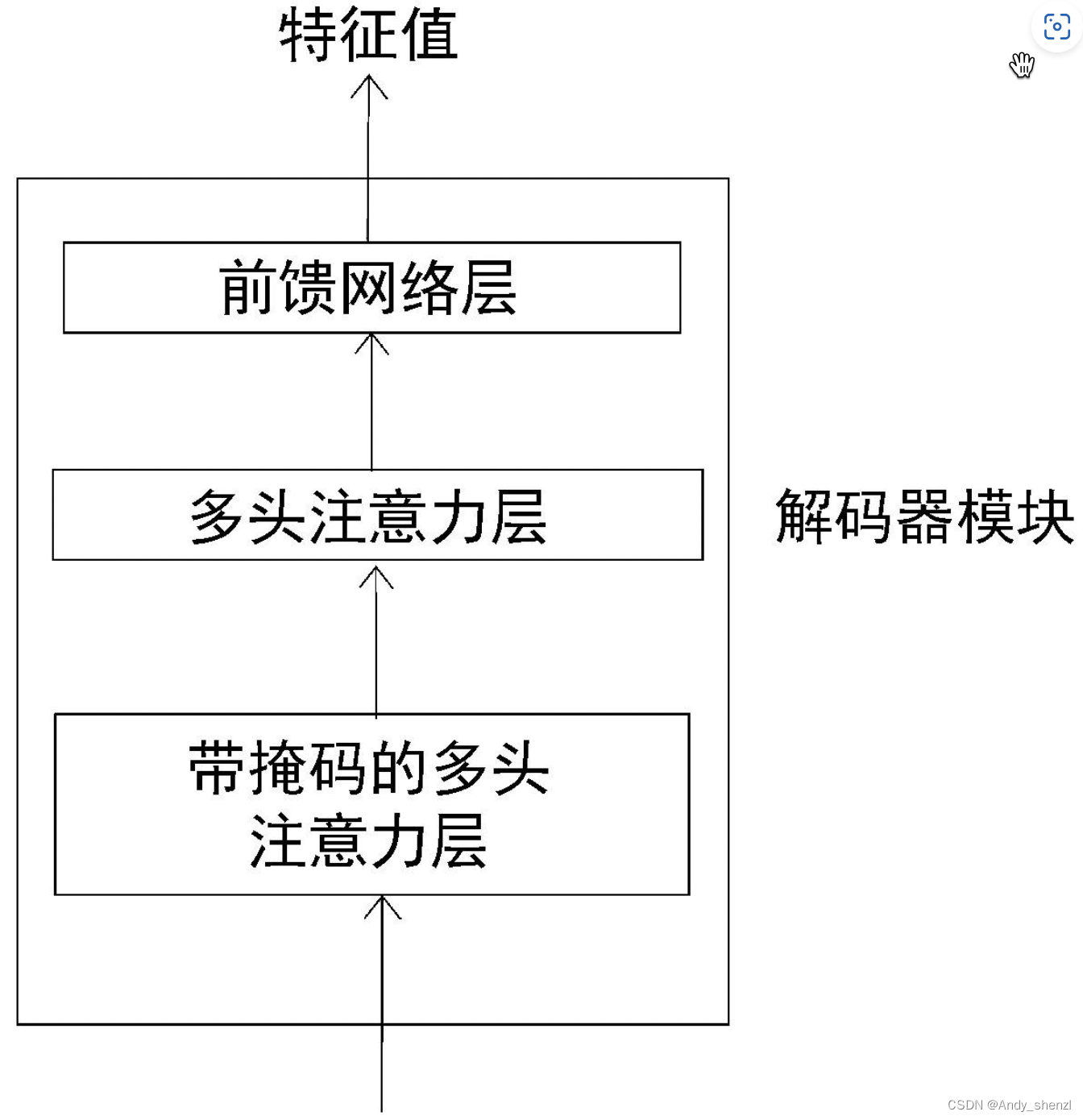
從圖中可以看到,解碼器內部有3個子層。
- 帶掩碼的多頭注意力層
- 多頭注意力層
- 前饋網絡層
與編碼器模塊相似,解碼器模塊也有多頭注意力層和前饋網絡層,但多了帶掩碼的多頭注意力層。現在,我們對解碼器有了基本的認識。接下來,讓我們先詳細了解解碼器的每個組成部分,然后從整體上了解它的工作原理。
4 帶掩碼的多頭注意力層
以英法翻譯任務為例,假設訓練數據集樣本如圖所示

數據集由兩部分組成:原句和目標句。在前面,我們學習了解碼器在測試期間是如何在每個步驟中逐字預測目標句的。
在訓練期間,由于有正確的目標句,解碼器可以直接將整個目標句稍作修改作為輸入。解碼器將輸入的<sos>作為第一個標記,并在每一步將下一個預測詞與輸入結合起來,以預測目標句,直到遇到<eos>標記為止。因此,我們只需將<sos>標記添加到目標句的開頭,再將整體作為輸入發送給解碼器。
比如要把英語句子I am good轉換成法語句子Je vais bien。我們只需在目標句的開頭加上<sos>標記,并將<sos>Je vais bien作為輸入發送給解碼器。解碼器將預測輸出為Je vais bien<eos>,如圖所示。

為什么我們需要輸入整個目標句,讓解碼器預測位移后的目標句呢?下面來解答。
首先,我們不是將輸入直接送入解碼器,而是將其轉換為嵌入矩陣(輸出嵌入矩陣)并添加位置編碼,然后再送入解碼器。假設添加輸出嵌入矩陣和位置編碼后得到圖所示的矩陣X。

然后,將矩陣X送入解碼器。解碼器中的第一層是帶掩碼的多頭注意力層。這與編碼器中的多頭注意力層的工作原理相似,但有一點不同。
為了運行自注意力機制,我們需要創建三個新矩陣,即查詢矩陣Q、鍵矩陣K和值矩陣V。由于使用多頭注意力層,因此我們創建了h個查詢矩陣、鍵矩陣和值矩陣。對于注意力頭 i i i的查詢矩陣 Q i Q_i Qi?、鍵矩陣 K i K_i Ki?和值矩陣 V i V_i Vi?,可以通過將X分別乘以權重矩陣 W i Q , W i K , W i V W_i^Q, W_i^K, W_i^V WiQ?,WiK?,WiV?而得。
下面,讓我們看看帶掩碼的多頭注意力層是如何工作的。假設傳給解碼器的輸入句是<sos>Je vais bien。我們知道,自注意力機制將一個單詞與句子中的所有單詞聯系起來,從而提取每個詞的更多信息。但這里有一個小問題。在測試期間,解碼器只將上一步生成的詞作為輸入。
比如,在測試期間,當 t = 2 t=2 t=2時,解碼器的輸入中只有[<sos>, Je],并沒有任何其他詞。因此,我們也需要以同樣的方式來訓練模型。模型的注意力機制應該只與該詞之前的單詞有關,而不是其后的單詞。要做到這一點,我們可以掩蓋后邊所有還沒有被模型預測的詞。
比如,我們想預測與<sos>相鄰的單詞。在這種情況下,模型應該只看到<sos>,所以我們應該掩蓋<sos>后邊的所有詞。再比如,我們想預測Je后邊的詞。在這種情況下,模型應該只看到Je之前的詞,所以我們應該掩蓋Je后邊的所有詞。其他行同理,如圖所示。

像這樣的掩碼有助于自注意力機制只注意模型在測試期間可以使用的詞。但我們究竟如何才能實現掩碼呢?我們學習過對于一個注意力頭 Z 1 Z_1 Z1?的注意力矩陣[插圖]的計算方法,公式如下。
Z i = s o f t m a x ( Q i ? K i T d k ) V i Z_i = softmax(\frac{Q_i·K_i^T}{\sqrt{d_k}})V_i Zi?=softmax(dk??Qi??KiT??)Vi?
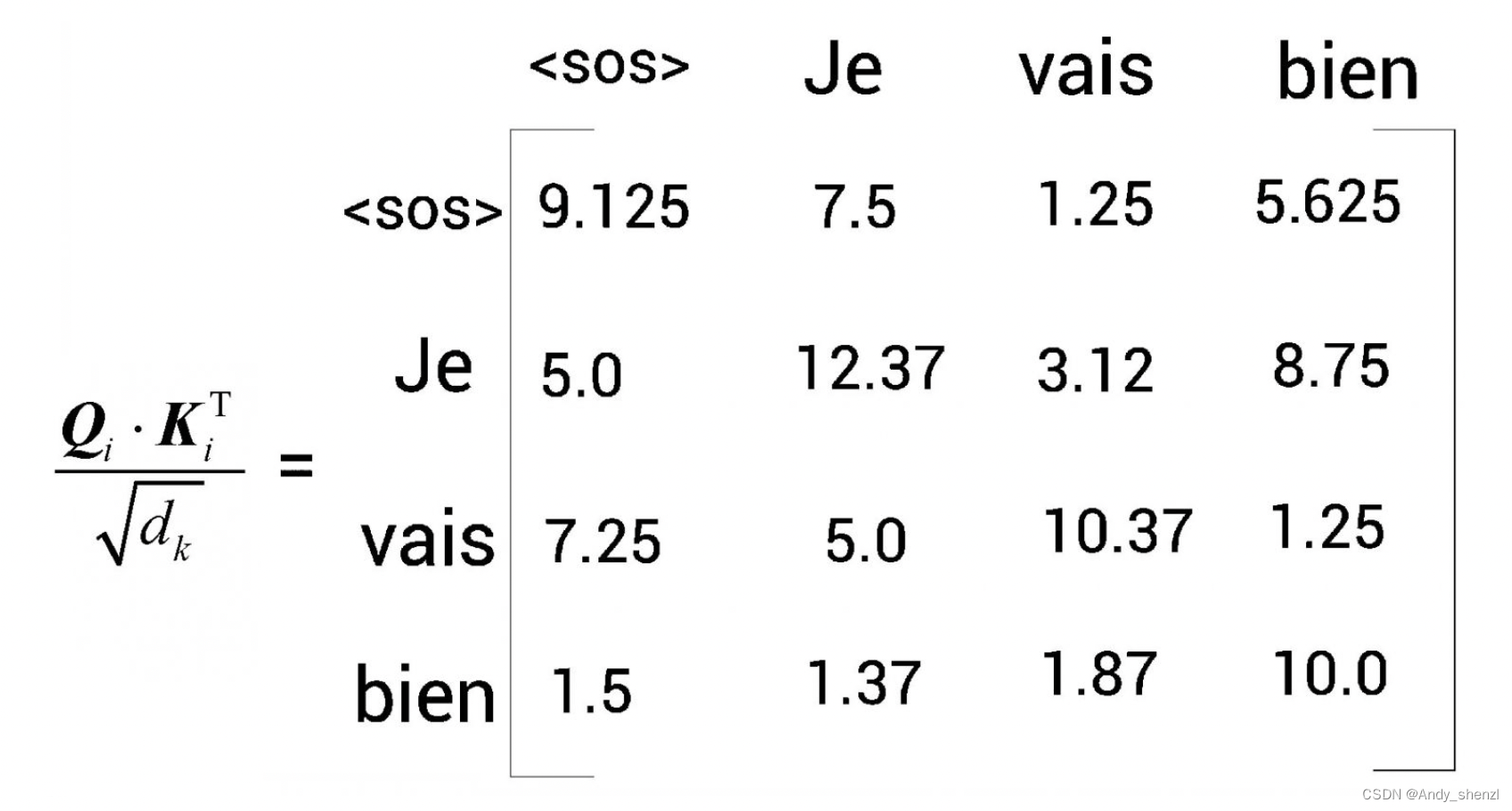
計算注意力矩陣的第1步是計算查詢矩陣與鍵矩陣的點積。下圖顯示了點積結果。需要注意的是,這里使用的數值是隨機的,只是為了方便理解。

第二步是將 Q i ? K i T Q_i·K_i^T Qi??KiT?矩陣除以鍵向量維度的平方根 d k \sqrt{d_k} dk??。假設下圖是 Q i ? K i T / d k Q_i·K_i^T/\sqrt{d_k} Qi??KiT?/dk??的結果。
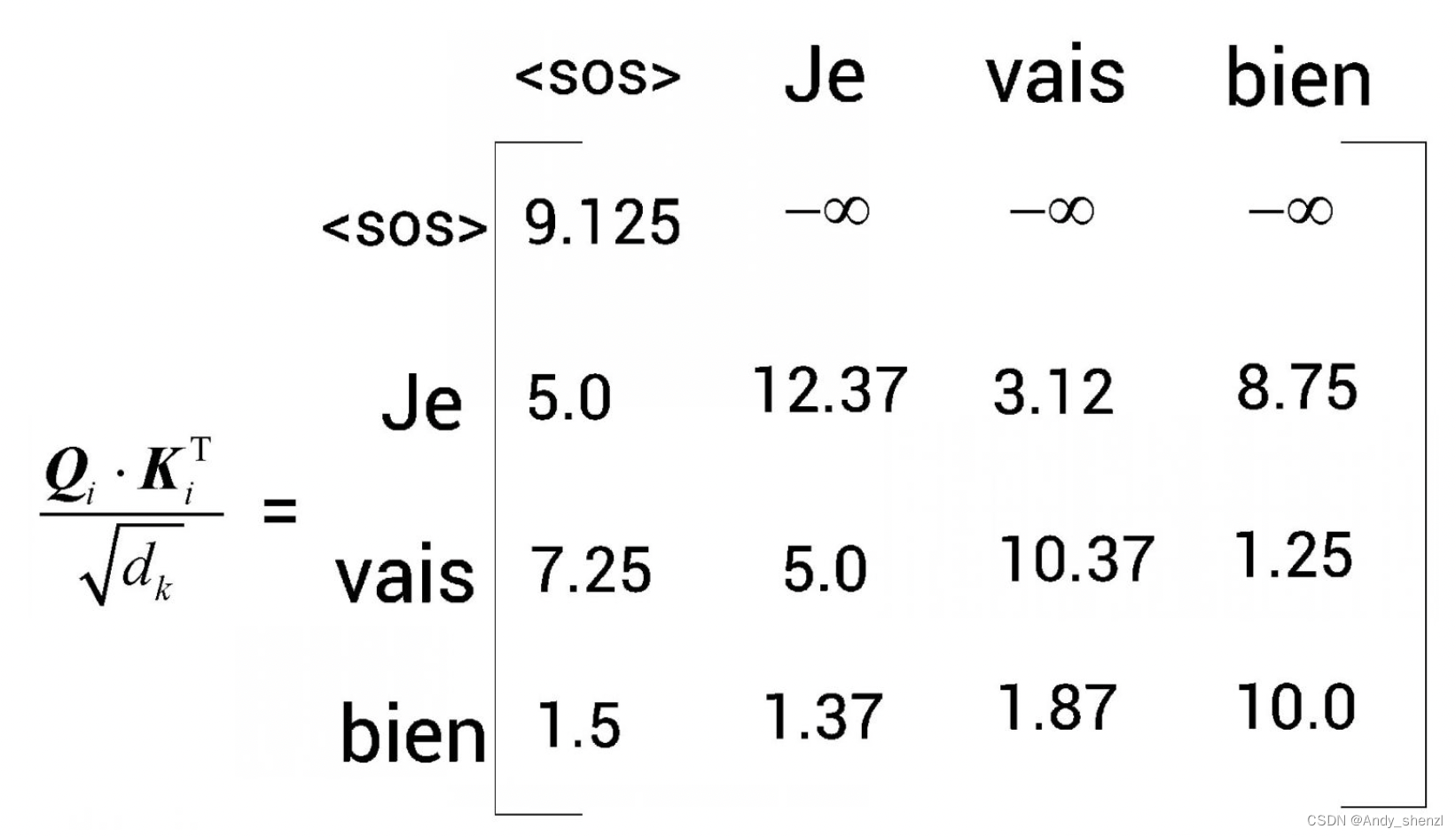
第3步,我們對上圖所得的矩陣應用softmax函數,并將分值歸一化。但在應用softmax函數之前,我們需要對數值進行掩碼轉換。以矩陣的第1行為例,為了預測<sos>后邊的詞,模型不應該知道<sos>右邊的所有詞(因為在測試時不會有這些詞)。因此,我們可以用 ? ∞ - \infty ?∞掩蓋<sos>右邊的所有詞,如圖所示。
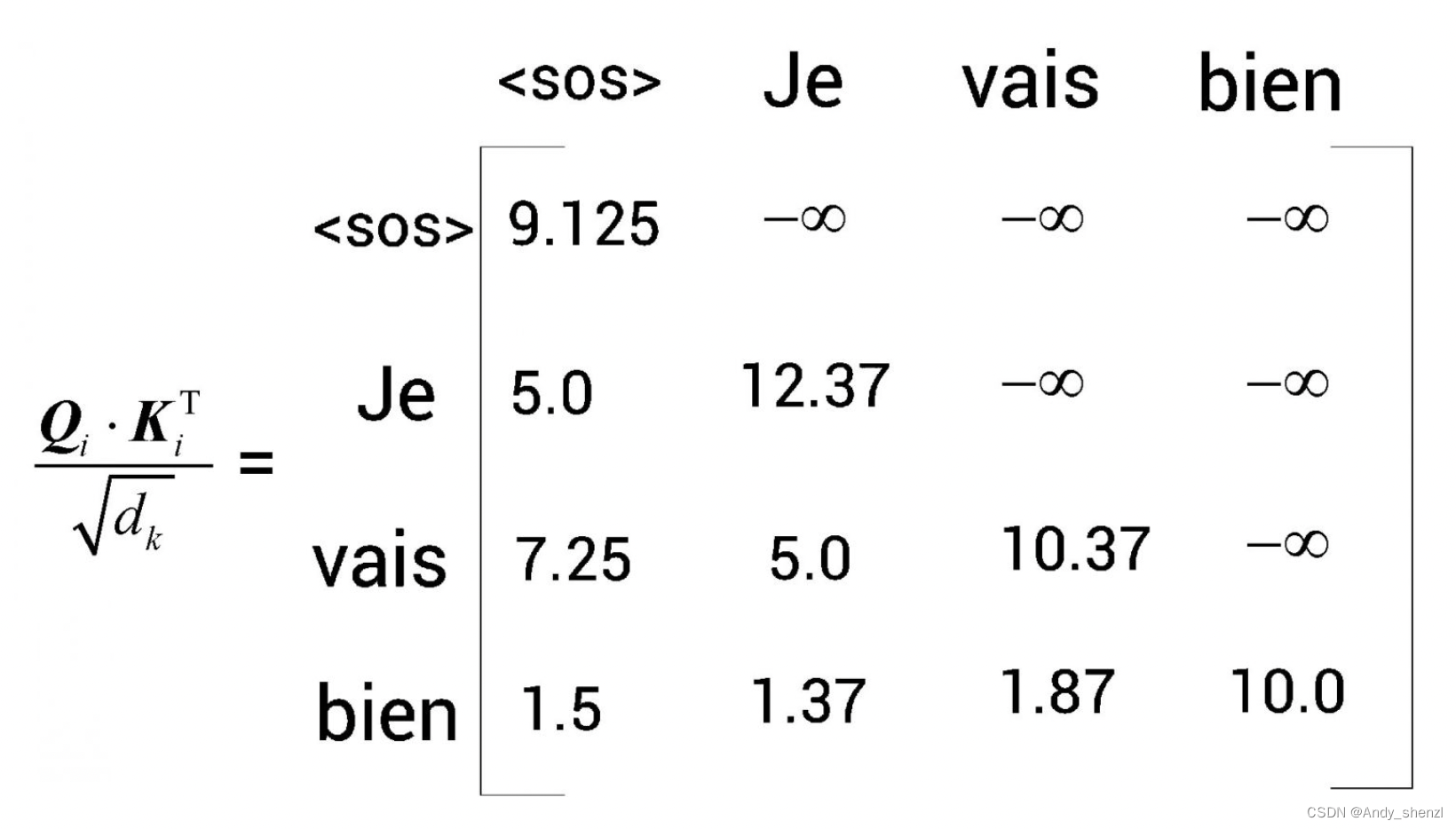
接下來,讓我們看矩陣的第2行。為了預測Je后邊的詞,模型不應該知道Je右邊的所有詞(因為在測試時不會有這些詞)。因此,我們可以用 ? ∞ - \infty ?∞掩蓋Je右邊的所有詞,如圖所示。

同理,我們可以用 ? ∞ - \infty ?∞掩蓋vais右邊的所有詞,如圖所示。
現在,我們可以將softmax函數應用于前面的矩陣,并將結果與值矩陣 V i V_i Vi?相乘,得到最終的注意力矩陣 Z i Z_i Zi?。同樣,我們可以計算h個注意力矩陣,將它們串聯起來,并將結果乘以新的權重矩陣 W 0 W_0 W0?,即可得到最終的注意力矩陣M,如下所示
M = C o n c a t e n a t e ( Z 1 , Z 2 , … … , Z h ) W 0 M = Concatenate(Z_1, Z_2,……,Z_h)W_0 M=Concatenate(Z1?,Z2?,……,Zh?)W0?
最后,我們把注意力矩陣M送到解碼器的下一個子層,也就是另一個多頭注意力層。
待更。。。






)

【Jmeter】線程(Threads(Users))之開放模型線程組(Open Model Thread Group))



)






