flink內存管理
- 1 內存分配
- 1.1 JVM 進程總內存(Total Process Memory)
- 1.2 Flink 總內存(Total Flink Memory)
- 1.3 JVM 堆外內存(JVM Off-Heap Memory)
- 1.4 JVM 堆內存(JVM Heap Memory)
- 1.5 托管內存(Managed Memory)
- 1.6直接內存(Direct Memory)
- 1.7 JVM 元空間(JVM Metaspace)
- 1.8 JVM 運行時開銷(JVM Overhead)
- 來自flink 1.12的per-job模式下jobmanager的 內存分配
- 2 內存設置思路
- 2.1 配置舉例
- 2.2 配置思路
- 2.2.1 并行度,slot,taskmanager數量三者的關系
- 2.2.2 資源大小選擇
- 2.2.2.1 舉例:
- 2.2.2.1 計算過程
- 3.OOM Killed 常見原因
- 3.1 RocksDB Native 內存的不確定性
- 3.2 Glibc Thread Arena 問題
- 3.3 JDK8 Native 內存泄漏
- 3.4 YARN mmap 內存算法
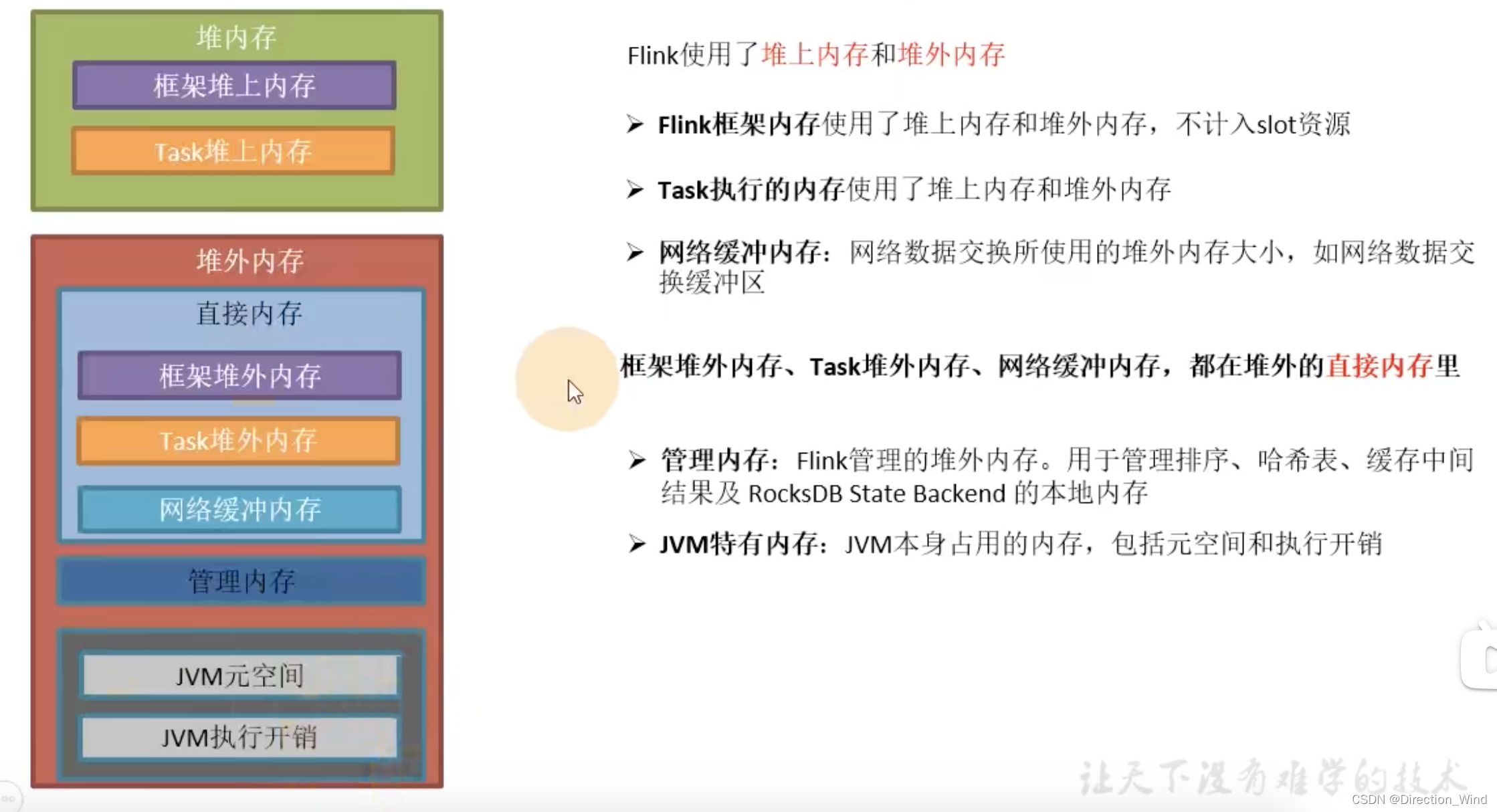
這里以flink1.12 的 flink webUI 來展示內存管理,后續版本的內存可能會有變更不一致的地方,詳細的解釋主要放在taskManager中
1 內存分配
下圖的左邊標注了每個區域的配置參數名,右邊則是一個調優后的、使用 HashMapStateBackend 的作業內存各區域的容量限制:它和默認配置的區別在于 Managed Memory 部分被主動調整為 0,后面我們會講解何時需要調整各區域的大小,以最大化利用內存空間。
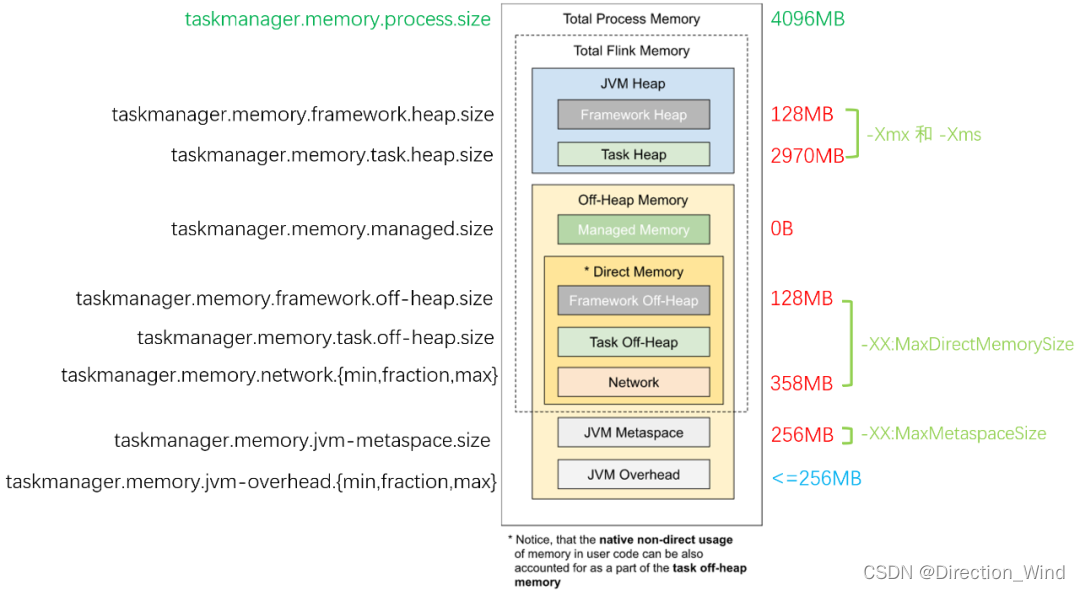
1.1 JVM 進程總內存(Total Process Memory)
- 該區域表示在容器環境下,TaskManager 所在 JVM 的最大可用的內存配額,包含了本文后續介紹的所有內存區域,超用時可能被強制結束進程。我們可以通過 taskmanager.memory.process.size 參數控制它的大小。
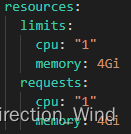
- 例如我們設置 JVM 進程總內存為 4G,TaskManager 運行在 Kubernetes 平臺,則 Pod 配置的 spec -> resources -> limits -> memory 項會被設置為 4Gi,源碼見 org.apache.flink.kubernetes.kubeclient.decorators.InitTaskManagerDecorator#decorateMainContainer,運行時的 YAML 配置如下圖:
- 而對于 YARN,如果 yarn.nodemanager.pmem-check-enabled 設為 true, 則也會在運行時定期檢查容器內的進程是否超用內存。
- 如果進程總內存用量超出配額,容器平臺通常會直接發送最嚴格的 SIGKILL 信號(相當于 kill -9)來中止 TaskManager,此時不會有任何延期退出的機會,可能會造成作業崩潰重啟、外部系統資源無法釋放等嚴重后果。
- 因此,在 有硬性資源配額檢查 的容器環境下,請務必妥善設置該參數,對作業充分壓測后,盡可能預留一部分安全余量,避免 TaskManager 頻繁被 KILL 而導致的作業頻繁重啟。
1.2 Flink 總內存(Total Flink Memory)
- 該內存區域指的是 Flink 可以控制的內存區域,即上述提到的 JVM 進程總內存 減去 Flink 無法控制的 Metaspace(元空間)和 Overhead(運行時開銷)區域。Flink 隨后又把這部分內存區域劃分為堆內、堆外(Direct)、堆外(Managed)等不同子區域,后面我們會逐一講解他們的配置指南。
- 對于沒有硬性資源限制的環境,我們建議使用 taskmanager.memory.flink.size 參數來配置 Flink 總內存的大小,然后 Flink 自己也會會自動根據參數,計算得到各個子區域的配額。如果作業運行正常,則無需單獨調整。
- 例如 4G 的 進程總內存 配置下,JVM 運行時開銷(Overhead)占 進程總內存 的 10% 但最多 1G(下圖是 409.6M),元空間(Metaspace)占 256M;堆外直接(Direct)內存網絡緩存占 Flink 總內存 的 10% 但最多 1G(下圖是 343M),框架堆和框架堆外各占 128M,堆外管控(Managed)內存占 Flink 總內存 的 40%(下圖是 1372M 即 1.34G),其他空間留給任務堆,即用戶程序代碼可以使用的內存空間(1459M 即 1.42G),我們接下來會講到它。
1.3 JVM 堆外內存(JVM Off-Heap Memory)
- 廣義上的 堆外內存 指的是 JVM 堆之外的內存空間,而我們這里特指 JVM 進程總內存除了元空間(Metaspace)和運行時開銷(Overhead)以外的內存區域。因為上述兩個區域是 JVM 自行管理,Flink 無法介入,我們后面單獨劃分和講解。
1.4 JVM 堆內存(JVM Heap Memory)
- 堆內存大家想必都不陌生,它是由 JVM 提供給用戶程序運行的內存區域,JVM 會按需運行 GC(垃圾回收器),協助清理失效對象。
- 當任務啟動時,ProcessMemoryUtils#generateJvmParametersStr 方法會通過 -Xmx -Xms 參數設置堆內存的最大容量。
- Flink 將堆內存從邏輯上劃分為 “框架堆”、“任務堆” 兩個子區域,分別通過 taskmanager.memory.framework.heap.size 和 taskmanager.memory.task.heap.size 來指定其大小:框架堆默認是 128m,任務堆如果未顯式設置其大小,則會通過扣減其他區域配額來計算得到。例如對于 4G 的進程總內存,扣除了其他區域后,任務堆可用的只有不到 1.5G。
- 但需要注意的是,Flink 自身并不能精確控制框架自身及任務會用多少堆內存,因此上述配置項只提供理論上的計算依據。如果實際用量超出配額,且 JVM 難以回收對象釋放空間,則會拋出 OutOfMemoryError,此時 Flink TaskManager 會退出,導致作業崩潰重啟。因此對于堆內存的監控是必須要配置的,當堆內存用量超過一定比率,或者 Full GC 時長和次數明顯增長時,需要盡快介入并考慮擴容。
- 高級內容:對于使用 HashMapStateBackend(舊版本稱之為 FileSystem StateBackend)的流作業用戶,如果在進程總內存固定的前提下,希望盡可能提升任務堆的空間,則可以減少 托管內存(Managed Memory)的比例。我們接下來也會講到它。
1.5 托管內存(Managed Memory)
- 文章開頭的總覽圖中,把托管內存區域設為 0,此時任務堆空間約 3G;而使用 Flink 默認配置時,任務堆只有 1.5G。這是因為默認情況下,托管內存占了 40% 的 Flink 總內存,導致堆內存可用的量變的相當少。因此我們非常有必要了解什么是托管內存。
從官方文檔和 Flink 源碼上來看,托管內存主要有三大使用場景:
- 批處理算法,例如排序、HashJoin 等。他們會從 Flink 的 MemoryManager 請求內存片段(MemorySegment),而 MemoryManager 則會調用 UNSAFE.allocateMemory 分配堆外內存。
- RocksDB StateBackend,Flink 只會預留一部分空間并扣除預算,但是不介入實際內存分配。因此該類型的內存資源被稱為 OpaqueMemoryResource. 實際的內存分配還是由 JNI 調用的 RocksDB 自己通過 malloc 函數申請。
- PyFlink。與 JNI 類似,在與 Python 進程交互的過程中,也會用到一部分托管內存。
- 顯然,對于普通的流式 SQL 作業,如果啟用了 RocksDB 狀態后端時,才會大量使用托管內存。因此如果您的業務場景并未用到 RocksDB,那么可以調小托管內存的相對比例(taskmanager.memory.managed.fraction)或絕對大小(taskmanager.memory.managed.size),以增大任務堆的空間。
- 對于 RocksDB 作業,之所以分配了 40% Flink 總內存,是因為 RocksDB 的內存用量實在是一個很頭疼的問題。早在 2017 年,就有 FLINK-7289: Memory allocation of RocksDB can be problematic in container environments [6] 這個問題單,隨后社區對此做了大量的工作(通過 LRUCache 參數、增強 WriteBufferManager 的 Slot 內空間復用等),來盡可能地限制 RocksDB 的總內存用量。有些文章中,也有提到 RocksDB 內存調優的各項參數,其中 MemTable、Block Cache 都是托管內存空間的用量大戶。
- 為了避免手動調優的繁雜,Flink 新版內存管理默認將 state.backend.rocksdb.memory.managed 參數設為 true,這樣就由 Flink 來計算 RocksDB 各部分需要用多少內存 [8],這也是 ”托管“ 的含義所在。如果仍然希望精細化手動調整 RocksDB 參數,則需要將上述參數設為 false.
1.6直接內存(Direct Memory)
直接內存是 JVM 堆外的一類內存,它提供了相對安全可控但又不受 GC 影響的空間,JVM 參數是 -XX:MaxDirectMemorySize. 它主要用于
- 框架自身(taskmanager.memory.framework.off-heap.size 參數,默認 128M,例如 Sort-Merge Shuffle 算法所需的內存)
- 用戶任務(taskmanager.memory.task.off-heap.size 參數,默認設為 0)
- Netty 對 Network Buffer 的網絡傳輸(taskmanager.memory.network.fraction 等參數,默認 0.1 即 10% 的 Flink 總內存)。
- 在生產環境中,如果作業并行度非常大(例如大于 500 甚至 1000),則需要調大 taskmanager.network.memory.floating-buffers-per-gate(例如從 8 調整到 1000)和 taskmanager.network.memory.buffers-per-channel(例如從 2 調整到 500),避免 Network Buffer 不足導致作業報錯。
1.7 JVM 元空間(JVM Metaspace)
- JVM Metaspace 主要保存了加載的類和方法的元數據,Flink 配置的參數是 taskmanager.memory.jvm-metaspace.size,默認大小為 256M,JVM 參數是 -XX:MaxMetaspaceSize.
- 如果用戶編寫的 Flink 程序中,有大量的動態類加載的需求,例如我們之前遇到過一個用戶作業,動態編譯并加載了 44 萬個類,此時就容易出現元空間用量遠超預期,發生 OOM 報錯。此時就需要適當調大元空間的大小,或者優化用戶程序,及時卸載無用的 Classloader。
1.8 JVM 運行時開銷(JVM Overhead)
- 除了上述描述的內存區域外,JVM 自己還有一小塊 “自留地”,用來存放線程棧、編譯的代碼緩存、JNI 調用的庫所分配的內存等等,Flink 配置參數是 taskmanager.memory.jvm-overhead.fraction,默認是 JVM 總內存的 10%。
- 對于舊版本(1.9 及之前)的 Flink,RocksDB 通過 malloc 分配的內存也屬于 Overhead 部分,而新版 Flink 把這部分歸類到托管 內存(Managed),但由于 FLINK-15532 Enable strict capacity limit for memory usage for RocksDB [9] 問題仍未解決,RocksDB 仍然會少量超用一部分內存。
- 因此在生產環境下,如果 RocksDB 頻繁造成內存超用,除了調大 Managed 托管內存外,也可以考慮調大 Overhead 區空間,以留出更多的安全余量。
來自flink 1.12的per-job模式下jobmanager的 內存分配
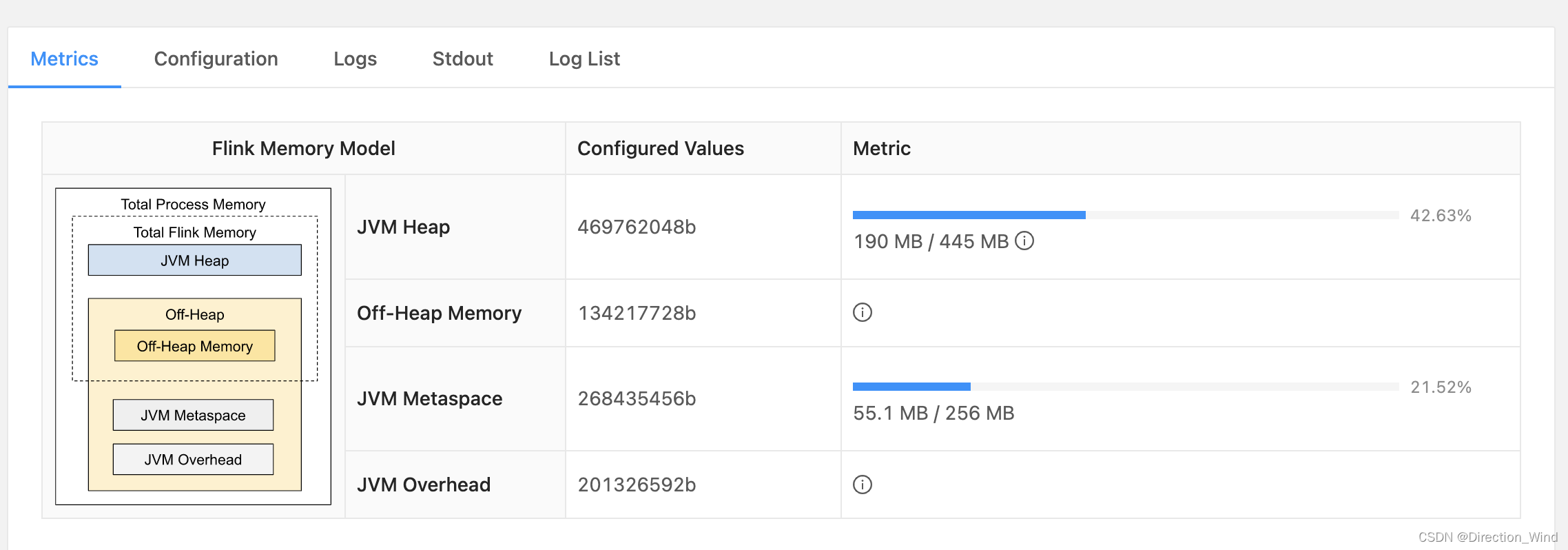
jvm metaspace存放jvm加載的類的元數據
還有一些想 Network 這種網絡開銷,一半不涉及修改的內存,沒有標出來。
內存數據結構:
flink最小內存分配單元 是內存段MemorySegment 默認32k。
2 內存設置思路
2.1 配置舉例
在yarn提交名利中 可以對yarn進行配置來修改內存大小
如使用的是fs memory state,并且沒有什么哈希排序操作,就可以修改managed Memory的大小,讓更多的資源運用于task的堆上內存中
-yD taskmanager.memory.size=8192 \
-yD taskmanager.memory.fraction=0.3
-yD taskmanager.memory.managed.size=0.3
具體參數可以參考flink官網 :
https://nightlies.apache.org/flink/flink-docs-release-1.3/setup/config.html#managed-memory
2.2 配置思路
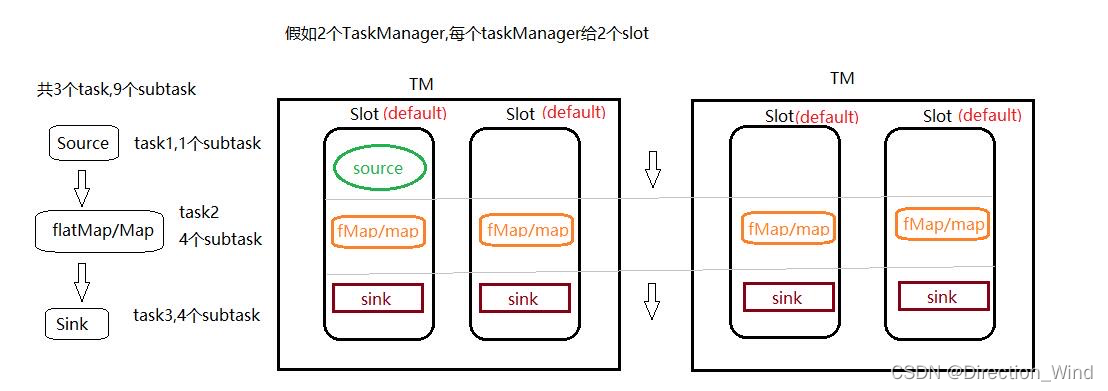
2.2.1 并行度,slot,taskmanager數量三者的關系
在這里我們先說一下基本概念:
? 用戶通過算子 api 所開發的代碼,會被 flink 任務提交客戶端解析成 jobGraph
? 然后,jobGraph 提交到集群 JobManager,轉化成 ExecutionGraph(并行化后的執行圖)
? 然后,ExecutionGraph 中的各個 task 會以多并行實例(subTask)部署到 taskmanager 上執行;
? subTask 運行的位置是 taskmanager 所提供的槽位(task slot),槽位簡單理解就是線程;
一個算子的邏輯,可以封裝在一個獨立的 task 中(可以有多個運行時實例:subTask);
也可把多個算子的邏輯 chain 在一起后封裝在一個獨立的 task 中(可以有多個運行時實例:subTask);
簡單點說 并行度=slot*taskmanager ;
例如下圖,2個tm 2個 slot 并行度就是4
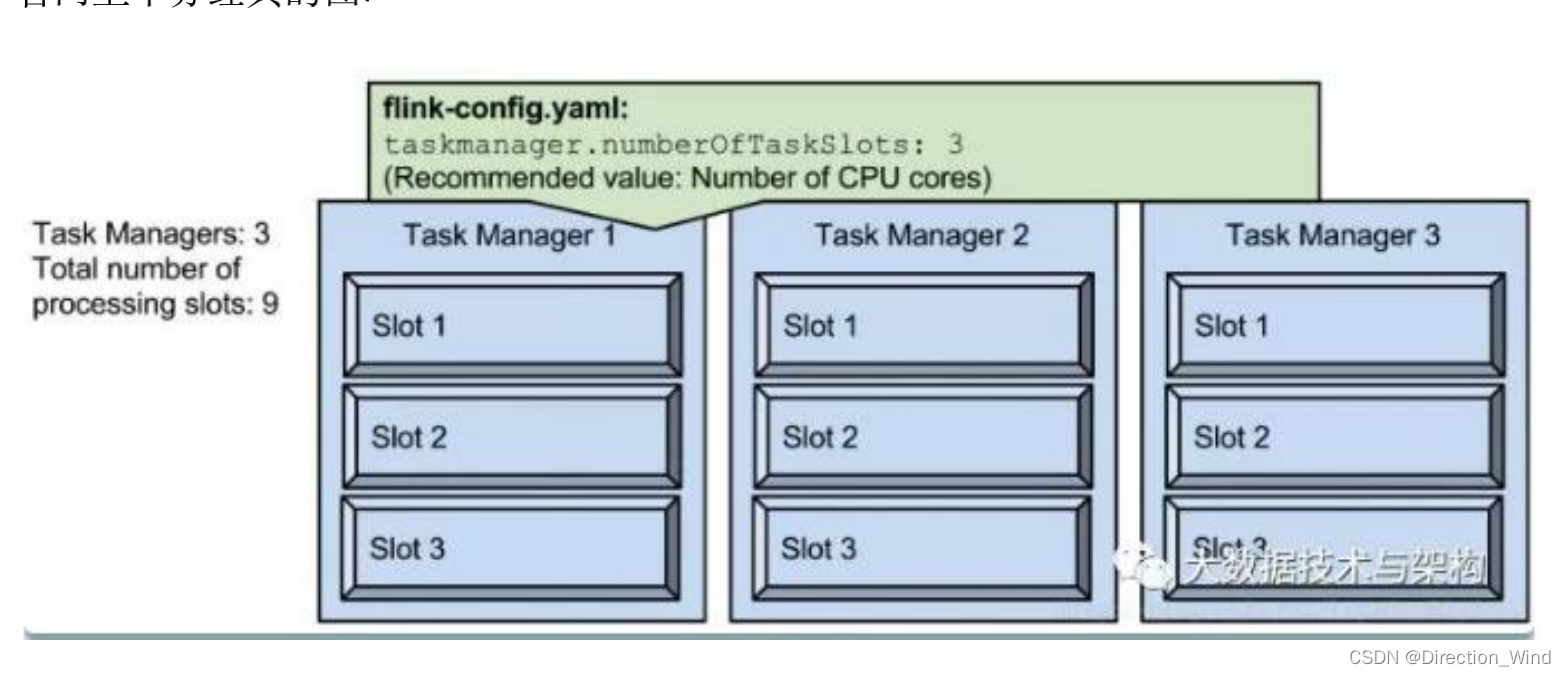
在 yarn 中提交一個 flink 任務, container 數量計算方式如下
container.num == taskmanager.num == ( parallelism.default / taskmanager.numberOfTaskSlots )
parallelism 是指 taskmanager 實際使用的并發能力。假設我們把 parallelism.default 設置
為 1,那么 9 個 TaskSlot 只能用 1 個,有 8 個空閑。 并發數<=slot*tm數 slot不夠就會自動起tm,來補充
設置parallelism有多中方式,優先級為api>env>p>file
2.2.2 資源大小選擇
2.2.2.1 舉例:
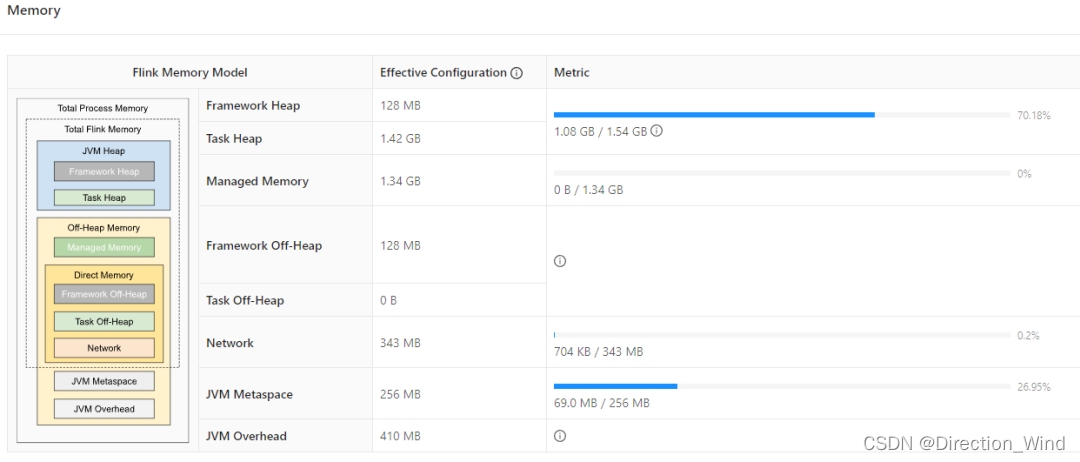
假設設置單個taskmanager為14g,taskmanager.memory.managed.fraction為0.5,將會得到以下內容:
JVM Heap Size:5.19 GB Flink Managed Memory:6.45 GB
JVM (Heap/Non-Heap) : Heap:5.19 GB Non-Heap:1.33 GB Total:6.52 GB
Outside JVM:Capacity:1.01GB
NetWork: count: xxxxx
可以計算得到6.45+6.52+1.01 = 13.98 等于14
2.2.2.1 計算過程
taskmanager.memory.process.size 設置的是容器的內存大小。
計算過程在org.apache.flink.runtime.clusterframework.TaskExecutorProcessUtils中processSpecFromConfig方法,TaskExecutorProcessSpec類展示了1.10版本整個內存的組成。
計算方法分成3種:
- 指定了taskmanager.memory.task.heap.size和taskmanager.memory.managed.size 見方法:deriveProcessSpecWithExplicitTaskAndManagedMemory
- 指定了taskmanager.memory.flink.size 見方法:deriveProcessSpecWithTotalFlinkMemory
- 指定了taskmanager.memory.process.size(容器環境一般指定這個,決定全局容量)
totalProcessMemorySize = 設置的值 14g
jvmMetaspaceSize = taskmanager.memory.jvm-metaspace.size 默認96m
這個對應參數-XX:MaxMetaspaceSize=100663296。
jvmOverheadSize:
- taskmanager.memory.jvm-overhead.min 192m
- taskmanager.memory.jvm-overhead.max 1g
- taskmanager.memory.jvm-overhead.fraction 0.1
公式 14g * 0.1 = 1.4g 必須在[192m, 1g]之間,所以jvmOverheadSize的大小是1g
-
totalFlinkMemorySize = 14g - 1g - 96m = 13216m
-
frameworkHeapMemorySize:taskmanager.memory.framework.heap.size 默認128m
-
frameworkOffHeapMemorySize:taskmanager.memory.framework.off-heap.size 默認128m
-
taskOffHeapMemorySize:taskmanager.memory.task.off-heap.size 默認0
確定好上面這些參數后,就是最重要的三個指標的計算了:taskHeapMemorySize,networkMemorySize,managedMemorySize
計算分成確定了:taskmanager.memory.task.heap.size還是沒確定。
1)確定taskmanager.memory.task.heap.size
-
taskHeapMemorySize = 設置值
-
managedMemorySize = 設置了使用設置值,否則使用 0.4 * totalFlinkMemorySize
-
如果 taskHeapMemorySize + taskOffHeapMemorySize + frameworkHeapMemorySize + frameworkOffHeapMemorySize + managedMemorySize > totalFlinkMemorySize異常
-
networkMemorySize 等于剩余的大小,之后還會check這塊內存是否充足,可以自己查看對應代碼
2)未設置heap大小
-
先確定 managedMemorySize = 設置了使用設置值,否則使用 0.4 * totalFlinkMemorySize,這里就是 0.5 * 13216m = 6608 = 6.45g (這里就是dashboard的顯示內容)
-
再確定network buffer大小,這個也是有兩種情況,不細說。 [64mb, 1g] 0.1 * totalFlinkMemorySize = 1321.6, 所以是1g
-
最后剩余的就是taskHeapMemorySize,不能為負數,這里等于 13216 - 6608 - 1024 - 128 - 128 = 5328 = 5.2g (這里約等于dashboard的顯示heap大小)
3)最后jvm的參數的計算過程:
-
jvmHeapSize = frameworkHeapSize + taskHeapSize = 5328 + 128 = 5456
-
jvmDirectSize = frameworkOffHeapMemorySize + taskOffHeapSize + networkMemSize = 128 + 1024 = 1152
-
jvmMetaspaceSize = 96m
3.OOM Killed 常見原因
本部分內容轉載自:
本文作者:林小鉑 (Paul Lin)
本文鏈接: 2021/01/02/詳解-Flink-容器化環境下的-OOM-Killed/
版權聲明: 本博客所有文章除特別聲明外,均采用 CC BY-NC-SA 3.0 CN 許可協議。轉載請注明出處!
實踐中導致 OOM Killed 的常見原因基本源于 Native 內存的泄漏或者過度使用。因為虛擬內存的 OOM Killed 通過資源管理器的配置很容易避免且通常不會有太大問題,所以下文只討論物理內存的 OOM Killed。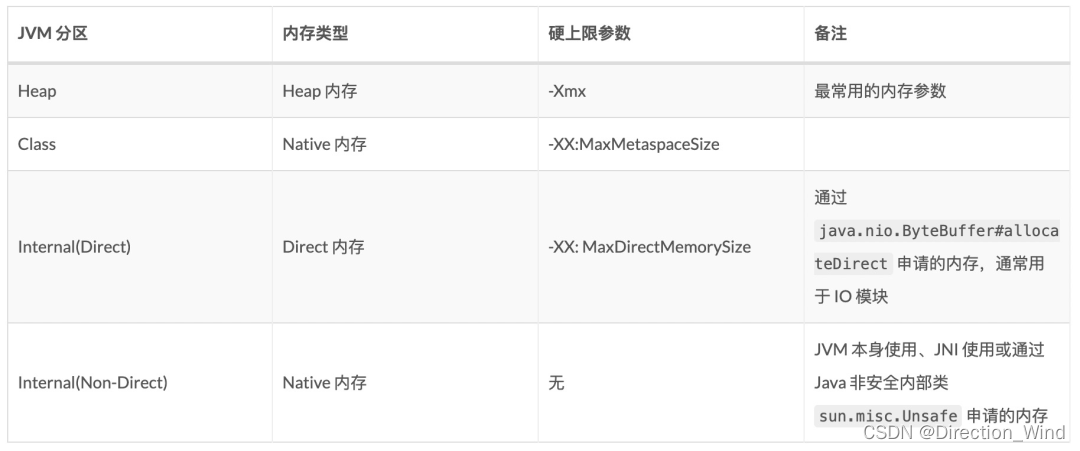
從表中可以看到,使用 Heap、Metaspace 和 Direct 內存都是比較安全的,但非 Direct 的 Native 內存情況則比較復雜,可能是 JVM 本身的一些內部使用(比如下文會提到的 MemberNameTable),也可能是用戶代碼引入的 JNI 依賴,還有可能是用戶代碼自身通過 sun.misc.Unsafe 申請的 Native 內存。理論上講,用戶代碼或第三方 lib 申請的 Native 內存需要用戶來規劃內存用量,而 Internal 的其余部分可以并入 JVM 本身的內存消耗。而實際上 Flink 的內存模型也遵循了類似的原則。
3.1 RocksDB Native 內存的不確定性
眾所周知,RocksDB 通過 JNI 直接申請 Native 內存,并不受 Flink 的管控,所以實際上 Flink 通過設置 RocksDB 的內存參數間接影響其內存使用。然而,目前 Flink 是通過估算得出這些參數,并不是非常精確的值,其中有以下的幾個原因。
首先是部分內存難以準確計算的問題。RocksDB 的內存占用有 4 個部分:
-
Block Cache: OS PageCache 之上的一層緩存,緩存未壓縮的數據 Block。
-
Indexes and filter blocks: 索引及布爾過濾器,用于優化讀性能。
-
Memtable: 類似寫緩存。
-
Blocks pinned by Iterator: 觸發 RocksDB 遍歷操作(比如遍歷 RocksDBMapState 的所有 key)時,Iterator 在其生命周期內會阻止其引用到的 Block 和 Memtable 被釋放,導致額外的內存占用。
前三個區域的內存都是可配置的,但 Iterator 鎖定的資源則要取決于應用業務使用模式,且沒有提供一個硬限制,因此 Flink 在計算 RocksDB StateBackend 內存時沒有將這部分納入考慮。
其次是 RocksDB Block Cache 的一個 bug,它會導致 Cache 大小無法嚴格控制,有可能短時間內超出設置的內存容量,相當于軟限制。
對于這個問題,通常我們只要調大 JVM Overhead 的閾值,讓 Flink 預留更多內存即可,因為 RocksDB 的內存超額使用只是暫時的。
3.2 Glibc Thread Arena 問題
另外一個常見的問題就是 glibc 著名的 64 MB 問題,它可能會導致 JVM 進程的內存使用大幅增長,最終被 YARN kill 掉。
具體來說,JVM 通過 glibc 申請內存,而為了提高內存分配效率和減少內存碎片,glibc 會維護稱為 Arena 的內存池,包括一個共享的 Main Arena 和線程級別的 Thread Arena。當一個線程需要申請內存但 Main Arena 已經被其他線程加鎖時,glibc 會分配一個大約 64 MB (64 位機器)的 Thread Arena 供線程使用。這些 Thread Arena 對于 JVM 是透明的,但會被算進進程的總體虛擬內存(VIRT)和物理內存(RSS)里。
默認情況下,Arena 的最大數目是 cpu 核數 * 8,對于一臺普通的 32 核服務器來說最多占用 16 GB,不可謂不可觀。為了控制總體消耗內存的總量,glibc 提供了環境變量 MALLOC_ARENA_MAX 來限制 Arena 的總量,比如 Hadoop 就默認將這個值設置為 4。然而,這個參數只是一個軟限制,所有 Arena 都被加鎖時,glibc 仍會新建 Thread Arena 來分配內存,造成意外的內存使用。
通常來說,這個問題會出現在需要頻繁創建線程的應用里,比如 HDFS Client 會為每個正在寫入的文件新建一個 DataStreamer 線程,所以比較容易遇到 Thread Arena 的問題。如果懷疑你的 Flink 應用遇到這個問題,比較簡單的驗證方法就是看進程的 pmap 是否存在很多大小為 64MB 倍數的連續 anon 段,比如下圖中藍色幾個的 65536 KB 的段就很有可能是 Arena。
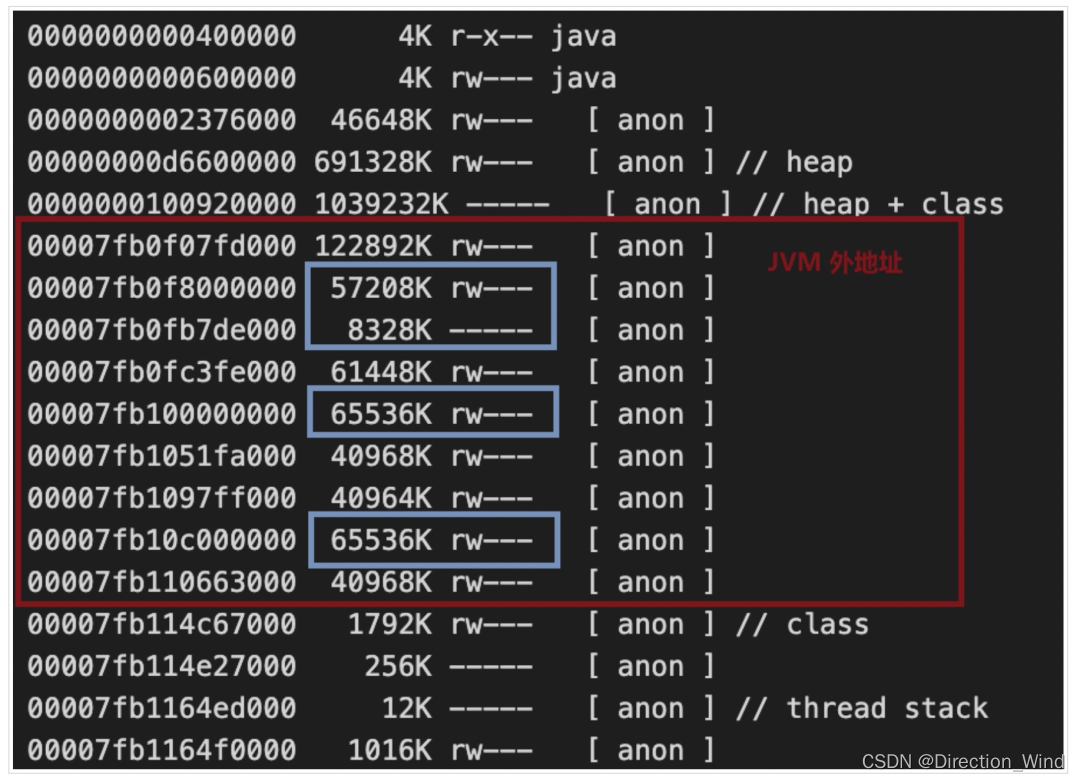
這個問題的修復辦法比較簡單,將 MALLOC_ARENA_MAX 設置為 1 即可,也就是禁用 Thread Arena 只使用 Main Arena。當然,這樣的代價就是線程分配內存效率會降低。不過值得一提的是,使用 Flink 的進程環境變量參數(比如 containerized.taskmanager.env.MALLOC_ARENA_MAX=1)來覆蓋默認的 MALLOC_ARENA_MAX 參數可能是不可行的,原因是在非白名單變量(yarn.nodemanager.env-whitelist)沖突的情況下, NodeManager 會以合并 URL 的方式來合并原有的值和追加的值,最終造成 MALLOC_ARENA_MAX=“4:1” 這樣的結果。
最后,還有一個更徹底的可選解決方案,就是將 glibc 替換為 Google 家的 tcmalloc 或 Facebook 家的 jemalloc [12]。除了不會有 Thread Arena 問題,內存分配性能更好,碎片更少。在實際上,Flink 1.12 的官方鏡像也將默認的內存分配器從 glibc 改為 jemelloc 。
3.3 JDK8 Native 內存泄漏
Oracle Jdk8u152 之前的版本存在一個 Native 內存泄漏的 bug[13],會造成 JVM 的 Internal 內存分區一直增長。
具體而言,JVM 會緩存字符串符號(Symbol)到方法(Method)、成員變量(Field)的映射對來加快查找,每對映射稱為 MemberName,整個映射關系稱為 MemeberNameTable,由 java.lang.invoke.MethodHandles 這個類負責。在 Jdk8u152 之前,MemberNameTable 是使用 Native 內存的,因此一些過時的 MemberName 不會被 GC 自動清理,造成內存泄漏。
要確認這個問題,需要通過 NMT 來查看 JVM 內存情況,比如筆者就遇到過線上一個 TaskManager 的超過 400 MB 的 MemeberNameTable。

在 JDK-8013267[14] 以后,MemeberNameTable 從 Native 內存被移到 Java Heap 當中,修復了這個問題。然而,JVM 的 Native 內存泄漏問題不止一個,比如 C2 編譯器的內存泄漏問題[15],所以對于跟筆者一樣沒有專門 JVM 團隊的用戶來說,升級到最新版本的 JDK 是修復問題的最好辦法。
3.4 YARN mmap 內存算法
眾所周知,YARN 會根據 /proc/${pid} 下的進程信息來計算整個 container 進程樹的總體內存,但這里面有一個比較特殊的點是 mmap 的共享內存。mmap 內存會全部被算進進程的 VIRT,這點應該沒有疑問,但關于 RSS 的計算則有不同標準。
依據 YARN 和 Linux smaps 的計算規則,內存頁(Pages)按兩種標準劃分:
- Private Pages: 只有當前進程映射(mapped)的 Pages
- Shared Pages: 與其他進程共享的 Pages
- Clean Pages: 自從被映射后沒有被修改過的 Pages
- Dirty Pages: 自從被映射后已經被修改過的 Pages
在默認的實現里,YARN 根據 /proc/${pid}/status 來計算總內存,所有的 Shared Pages 都會被算入進程的 RSS,即便這些 Pages 同時被多個進程映射[16],這會導致和實際操作系統物理內存的偏差,有可能導致 Flink 進程被誤殺(當然,前提是用戶代碼使用 mmap 且沒有預留足夠空間)。
為此,YARN 提供 yarn.nodemanager.container-monitor.procfs-tree.smaps-based-rss.enabled 配置選項,將其設置為 true 后,YARN 將根據更準確的 /proc/${pid}/smap 來計算內存占用,其中很關鍵的一個概念是 PSS。簡單來說,PSS 的不同點在于計算內存時會將 Shared Pages 均分給所有使用這個 Pages 的進程,比如一個進程持有 1000 個 Private Pages 和 1000 個會分享給另外一個進程的 Shared Pages,那么該進程的總 Page 數就是 1500。
回到 YARN 的內存計算上,進程 RSS 等于其映射的所有 Pages RSS 的總和。在默認情況下,YARN 計算一個 Page RSS 公式為:
Page RSS = Private_Clean + Private_Dirty + Shared_Clean + Shared_Dirty
因為一個 Page 要么是 Private,要么是 Shared,且要么是 Clean 要么是 Dirty,所以其實上述公示右邊有至少三項為 0 。而在開啟 smaps 選項后,公式變為:
Page RSS = Min(Shared_Dirty, PSS) + Private_Clean + Private_Dirty
簡單來說,新公式的結果就是去除了 Shared_Clean 部分被重復計算的影響。
雖然開啟基于 smaps 計算的選項會讓計算更加準確,但會引入遍歷 Pages 計算內存總和的開銷,不如 直接取 /proc/${pid}/status 的統計數據快,因此如果遇到 mmap 的問題,還是推薦通過提高 Flink 的 JVM Overhead 分區容量來解決。




)

【Jmeter】線程(Threads(Users))之開放模型線程組(Open Model Thread Group))



)








